RNN文本分类任务实战
- 递归神经网络 (RNN):
定义:RNN 是一类专为顺序数据处理而设计的人工神经网络。
顺序处理:RNN 保持一个隐藏状态,该状态捕获有关序列中先前输入的信息,使其适用于涉及顺序依赖关系的任务。 - 词嵌入:
定义:词嵌入是捕获语义关系的词的密集向量表示。
重要性:它们允许神经网络学习上下文信息和单词之间的关系。
实现:使用预先训练的词嵌入(Word2Vec、GloVe)或在模型中包含嵌入层。 - 文本标记化和填充:
代币化:将文本分解为单个单词或子单词。
填充:通过添加零或截断来确保所有序列具有相同的长度。 - Keras 中的顺序模型:
实现:利用 Keras 库中的 Sequential 模型创建线性层堆栈。 - 嵌入层:
实现:向模型添加嵌入层,将单词转换为密集向量。
配置:指定输入维度、输出维度(嵌入大小)和输入长度。 - 循环层(LSTM 或 GRU):
LSTM 和 GRU:长短期记忆 (LSTM) 和门控循环单元 (GRU) 层有助于捕获长期依赖关系。
实现:将一个或多个 LSTM 或 GRU 层添加到模型中。 - 致密层:
目的:密集层用于最终分类输出。
实现:添加一个或多个具有适当激活函数的密集层。 - 激活功能:
选择:ReLU(整流线性单元)或tanh是隐藏层中激活函数的常见选择。 - 损失函数和优化器:
损失函数:稀疏分类交叉熵通常用于文本分类任务。
优化:Adam 或 RMSprop 是常用的优化器。 - 批处理和排序:
批处理:在批量输入序列上训练模型。
处理不同长度的物料:使用填充来处理不同长度的序列。 - 培训流程:
汇编:使用所选的损失函数、优化器和指标编译模型。
训练:将模型拟合到训练数据,在单独的集合上进行验证。 - 防止过拟合:
技术:实现 dropout 或 recurrent dropout 层以防止过拟合。
正规化:如果需要,请考虑 L1 或 L2 正则化。 - 超参数调优:
参数:根据验证性能调整超参数,例如学习率、批量大小和循环单元数。 - 评估指标:
指标:选择适当的指标,如准确率、精确率、召回率或 F1 分数进行评估。
# 文本分类任务实战
# 数据集构建:影评数据集进行情感分析
# 词向量模型:加载训练好的词向量或者自己训练
# 序列网络模型:训练好RNN模型进行识别import os
import warnings
warnings.filterwarnings('ignore')
import tensorflow as tf
import numpy as np
import pprint
import logging
import time
from collections import Counterfrom pathlib import Path
from tqdm import tqdm#加载影评数据集,可以自动下载放到对应位置
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.imdb.load_data()
# a=x_train.shape
# print(a)
# 读进来的数据是已经转换成ID映射的,一般的数据读进来都是词语,都需要手动转换成ID映射的_word2idx = tf.keras.datasets.imdb.get_word_index()
word2idx = {w: i+3 for w, i in _word2idx.items()}
word2idx['<pad>'] = 0
word2idx['<start>'] = 1
word2idx['<unk>'] = 2
idx2word = {i: w for w, i in word2idx.items()}# 按文本长度大小进行排序def sort_by_len(x, y):x, y = np.asarray(x), np.asarray(y)idx = sorted(range(len(x)), key=lambda i: len(x[i]))return x[idx], y[idx]# 将中间结果保存到本地,万一程序崩了还得重玩,保存的是文本数据,不是IDx_train, y_train = sort_by_len(x_train, y_train)
x_test, y_test = sort_by_len(x_test, y_test)def write_file(f_path, xs, ys):with open(f_path, 'w',encoding='utf-8') as f:for x, y in zip(xs, ys):f.write(str(y)+'\t'+' '.join([idx2word[i] for i in x][1:])+'\n')write_file('./data/train.txt', x_train, y_train)
write_file('./data/test.txt', x_test, y_test)# 构建语料表,基于词频来进行统计counter = Counter()
with open('./data/train.txt',encoding='utf-8') as f:for line in f:line = line.rstrip()label, words = line.split('\t')words = words.split(' ')counter.update(words)words = ['<pad>'] + [w for w, freq in counter.most_common() if freq >= 10]
print('Vocab Size:', len(words))Path('./vocab').mkdir(exist_ok=True)with open('./vocab/word.txt', 'w',encoding='utf-8') as f:for w in words:f.write(w+'\n')# 得到新的word2id映射表word2idx = {}
with open('./vocab/word.txt',encoding='utf-8') as f:for i, line in enumerate(f):line = line.rstrip()word2idx[line] = i# embedding层
# 可以基于网络来训练,也可以直接加载别人训练好的,一般都是加载预训练模型
# 这里有一些常用的:https://nlp.stanford.edu/projects/glove/#做了一个大表,里面有20598个不同的词,【20599*50】
embedding = np.zeros((len(word2idx)+1, 50)) # + 1 表示如果不在语料表中,就都是unknowwith open('./data/glove.6B.50d.txt',encoding='utf-8') as f: #下载好的count = 0for i, line in enumerate(f):if i % 100000 == 0:print('- At line {}'.format(i)) #打印处理了多少数据line = line.rstrip()0sp = line.split(' ')word, vec = sp[0], sp[1:]if word in word2idx:count += 1embedding[word2idx[word]] = np.asarray(vec, dtype='float32') #将词转换成对应的向量# 现在已经得到每个词索引所对应的向量print("[%d / %d] words have found pre-trained values"%(count, len(word2idx)))
np.save('./vocab/word.npy', embedding)
print('Saved ./vocab/word.npy')# 构建训练数据
# 注意所有的输入样本必须都是相同shape(文本长度,词向量维度等)
# 数据生成器
# tf.data.Dataset.from_tensor_slices(tensor):将tensor沿其第一个维度切片,返回一个含有N个样本的数据集,这样做的问题就是需要将整个数据集整体传入,然后切片建立数据集类对象,比较占内存。
#
# tf.data.Dataset.from_generator(data_generator,output_data_type,output_data_shape):从一个生成器中不断读取样本def data_generator(f_path, params):with open(f_path,encoding='utf-8') as f:print('Reading', f_path)for line in f:line = line.rstrip()label, text = line.split('\t')text = text.split(' ')x = [params['word2idx'].get(w, len(word2idx)) for w in text]#得到当前词所对应的IDif len(x) >= params['max_len']:#截断操作x = x[:params['max_len']]else:x += [0] * (params['max_len'] - len(x))#补齐操作y = int(label)yield x, ydef dataset(is_training, params):_shapes = ([params['max_len']], ())_types = (tf.int32, tf.int32)if is_training:ds = tf.data.Dataset.from_generator(lambda: data_generator(params['train_path'], params),output_shapes=_shapes,output_types=_types, )ds = ds.shuffle(params['num_samples'])ds = ds.batch(params['batch_size'])ds = ds.prefetch(tf.data.experimental.AUTOTUNE) # 设置缓存序列,根据可用的CPU动态设置并行调用的数量,说白了就是加速else:ds = tf.data.Dataset.from_generator(lambda: data_generator(params['test_path'], params),output_shapes=_shapes,output_types=_types, )ds = ds.batch(params['batch_size'])ds = ds.prefetch(tf.data.experimental.AUTOTUNE)return ds# 自定义网络模型class Model(tf.keras.Model):def __init__(self, params):super().__init__()self.embedding = tf.Variable(np.load('./vocab/word.npy'),dtype=tf.float32,name='pretrained_embedding',trainable=False, )self.drop1 = tf.keras.layers.Dropout(params['dropout_rate'])self.drop2 = tf.keras.layers.Dropout(params['dropout_rate'])self.drop3 = tf.keras.layers.Dropout(params['dropout_rate'])self.rnn1 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.rnn2 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.rnn3 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.drop_fc = tf.keras.layers.Dropout(params['dropout_rate'])self.fc = tf.keras.layers.Dense(2 * params['rnn_units'], tf.nn.elu)self.out_linear = tf.keras.layers.Dense(2)def call(self, inputs, training=False):if inputs.dtype != tf.int32:inputs = tf.cast(inputs, tf.int32)batch_sz = tf.shape(inputs)[0]rnn_units = 2 * params['rnn_units']x = tf.nn.embedding_lookup(self.embedding, inputs)x = tf.reshape(x, (batch_sz * 10 * 10, 10, 50))x = self.drop1(x, training=training)x = self.rnn1(x)x = tf.reduce_max(x, 1)x = tf.reshape(x, (batch_sz * 10, 10, rnn_units))x = self.drop2(x, training=training)x = self.rnn2(x)x = tf.reduce_max(x, 1)x = tf.reshape(x, (batch_sz, 10, rnn_units))x = self.drop3(x, training=training)x = self.rnn3(x)x = tf.reduce_max(x, 1)x = self.drop_fc(x, training=training)x = self.fc(x)x = self.out_linear(x)return x# 设置参数params = {'vocab_path': './vocab/word.txt','train_path': './data/train.txt','test_path': './data/test.txt','num_samples': 25000,'num_labels': 2,'batch_size': 32,'max_len': 1000,'rnn_units': 200,'dropout_rate': 0.2,'clip_norm': 10.,'num_patience': 3,'lr': 3e-4,
}def is_descending(history: list):history = history[-(params['num_patience']+1):]for i in range(1, len(history)):if history[i-1] <= history[i]:return Falsereturn Trueword2idx = {}
with open(params['vocab_path'],encoding='utf-8') as f:for i, line in enumerate(f):line = line.rstrip()word2idx[line] = i
params['word2idx'] = word2idx
params['vocab_size'] = len(word2idx) + 1model = Model(params)
model.build(input_shape=(None, None))#设置输入的大小,或者fit时候也能自动找到
#pprint.pprint([(v.name, v.shape) for v in model.trainable_variables])#链接:https://tensorflow.google.cn/api_docs/python/tf/keras/optimizers/schedules/ExponentialDecay?version=stable
#return initial_learning_rate * decay_rate ^ (step / decay_steps)
decay_lr = tf.optimizers.schedules.ExponentialDecay(params['lr'], 1000, 0.95)#相当于加了一个指数衰减函数
optim = tf.optimizers.Adam(params['lr'])
global_step = 0history_acc = []
best_acc = .0t0 = time.time()
logger = logging.getLogger('tensorflow')
logger.setLevel(logging.INFO)while True:# 训练模型for texts, labels in dataset(is_training=True, params=params):with tf.GradientTape() as tape: # 梯度带,记录所有在上下文中的操作,并且通过调用.gradient()获得任何上下文中计算得出的张量的梯度logits = model(texts, training=True)loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)loss = tf.reduce_mean(loss)optim.lr.assign(decay_lr(global_step))grads = tape.gradient(loss, model.trainable_variables)grads, _ = tf.clip_by_global_norm(grads, params['clip_norm']) # 将梯度限制一下,有的时候回更新太猛,防止过拟合optim.apply_gradients(zip(grads, model.trainable_variables)) # 更新梯度if global_step % 50 == 0:logger.info("Step {} | Loss: {:.4f} | Spent: {:.1f} secs | LR: {:.6f}".format(global_step, loss.numpy().item(), time.time() - t0, optim.lr.numpy().item()))t0 = time.time()global_step += 1# 验证集效果m = tf.keras.metrics.Accuracy()for texts, labels in dataset(is_training=False, params=params):logits = model(texts, training=False)y_pred = tf.argmax(logits, axis=-1)m.update_state(y_true=labels, y_pred=y_pred)acc = m.result().numpy()logger.info("Evaluation: Testing Accuracy: {:.3f}".format(acc))history_acc.append(acc)if acc > best_acc:best_acc = acclogger.info("Best Accuracy: {:.3f}".format(best_acc))if len(history_acc) > params['num_patience'] and is_descending(history_acc):logger.info("Testing Accuracy not improved over {} epochs, Early Stop".format(params['num_patience']))break
相关文章:

RNN文本分类任务实战
递归神经网络 (RNN): 定义:RNN 是一类专为顺序数据处理而设计的人工神经网络。 顺序处理:RNN 保持一个隐藏状态,该状态捕获有关序列中先前输入的信息,使其适用于涉及顺序依赖关系的任务。词嵌入…...

【算法系列 | 12】深入解析查找算法之—斐波那契查找
序言 心若有阳光,你便会看见这个世界有那么多美好值得期待和向往。 决定开一个算法专栏,希望能帮助大家很好的了解算法。主要深入解析每个算法,从概念到示例。 我们一起努力,成为更好的自己! 今天第12讲,讲…...

全新的C++语言
一、概述 C 的最初目标就是成为 “更好的 C”,因此新的标准首先要对基本的底层编程进行强化,能够反映当前计算机软硬件系统的最新发展和变化(例如多线程)。另一方面,C对多线程范式的支持增加了语言的复杂度࿰…...

three.js 多通道组合
效果: 代码: <template><div><el-container><el-main><div class"box-card-left"><div id"threejs" style"border: 1px solid red"></div><div style"border: 1px so…...

编程笔记 html5cssjs 022 HTML表单概要
编程笔记 html5&css&js 022 HTML表单概要 一、<form> 元素二、HTML Form 属性三、操作小结 网页光是输出没有输入可不行,因为输出还是比输入容易,所有就先接触输出,后学习输入。html用来输入的东西叫“表单”。 HTML 表单用于搜…...

三子棋(c语言)
前言: 三子棋是一种民间传统游戏,又叫九宫棋、圈圈叉叉棋、一条龙、井字棋等。游戏规则是双方对战,双方依次在9宫格棋盘上摆放棋子,率先将自己的三个棋子走成一条线就视为胜利。但因棋盘太小,三子棋在很多时候会出现和…...
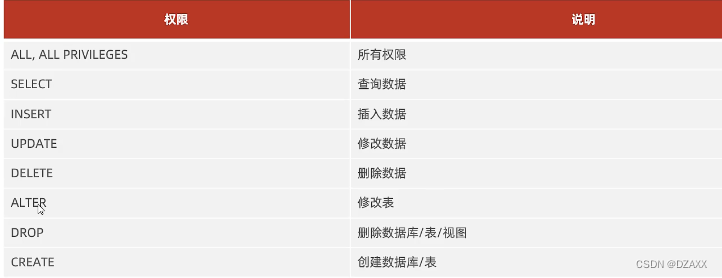
MySQL-DCL
DCL是数据控制语言,用来管理数据库用户,控制数据库的访问权限。 管理用户:管理哪些用户可以访问哪些数据库 1.查询用户 USE mysql; SELECT * FROM user; 注意: MySQL中用户信息和用户的权限信息都是记录在mysql数据库的user表中的…...

QT开源类库集合
QT开源类库集合 一、自定义控件 QSintQicsTableLongscroll-qtAdvanced Docking System 二、图表控件 QwtQCustomPlotJKQTPlotter 三、网络 QHttpEngineHTTP 四、 音视频 vlc-qt 五、多线程 tasks 六、数据库 EasyQtSql 一、自定义控件 1. QSint 源代码地址:QSint&…...
--算法(2))
C++ STL(2)--算法(2)
算法(2)----STL里的排序函数。 1. sort: 对容器或普通数组中指定范围内的元素进行排序,默认进行升序排序。 sort函数是基于快速排序实现的,属于不稳定排序。 只支持3种容器:array、vector、deque。 如果容器中存储的是自定义的对象ÿ…...
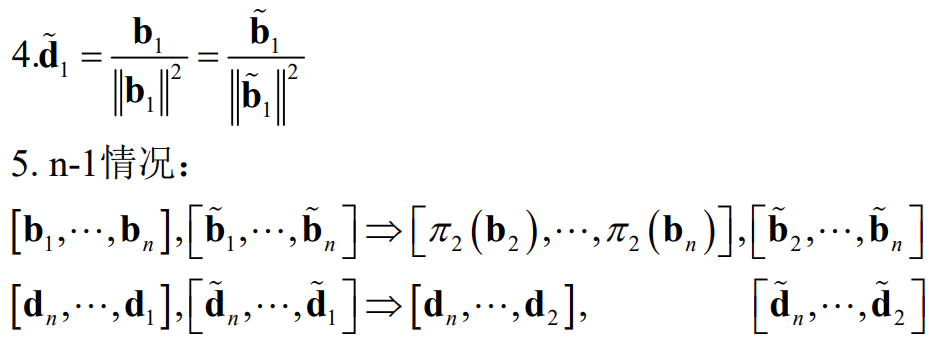
格密码基础:对偶格(超全面)
目录 一. 对偶格的格点 1.1 基本定义 1.2 对偶格的例子 1.3 对偶格的图形理解 二. 对偶格的格基 2.1 基本定义 2.2 对偶格的格基证明 三. 对偶格的行列式 3.1 满秩格 3.2 非满秩格 四. 重复对偶格 五. 对偶格的转移定理(transference theoremÿ…...

ECMAScript简介及特性
ECMAScript是一种由ECMA国际(前身为欧洲计算机制造商协会)制定和发布的脚本语言规范,JavaScript在它基础上进行了自己的封装。ECMAScript和JavaScript的关系是,前者是后者的规格,后者是前者的一种实现。 ECMAScript的…...
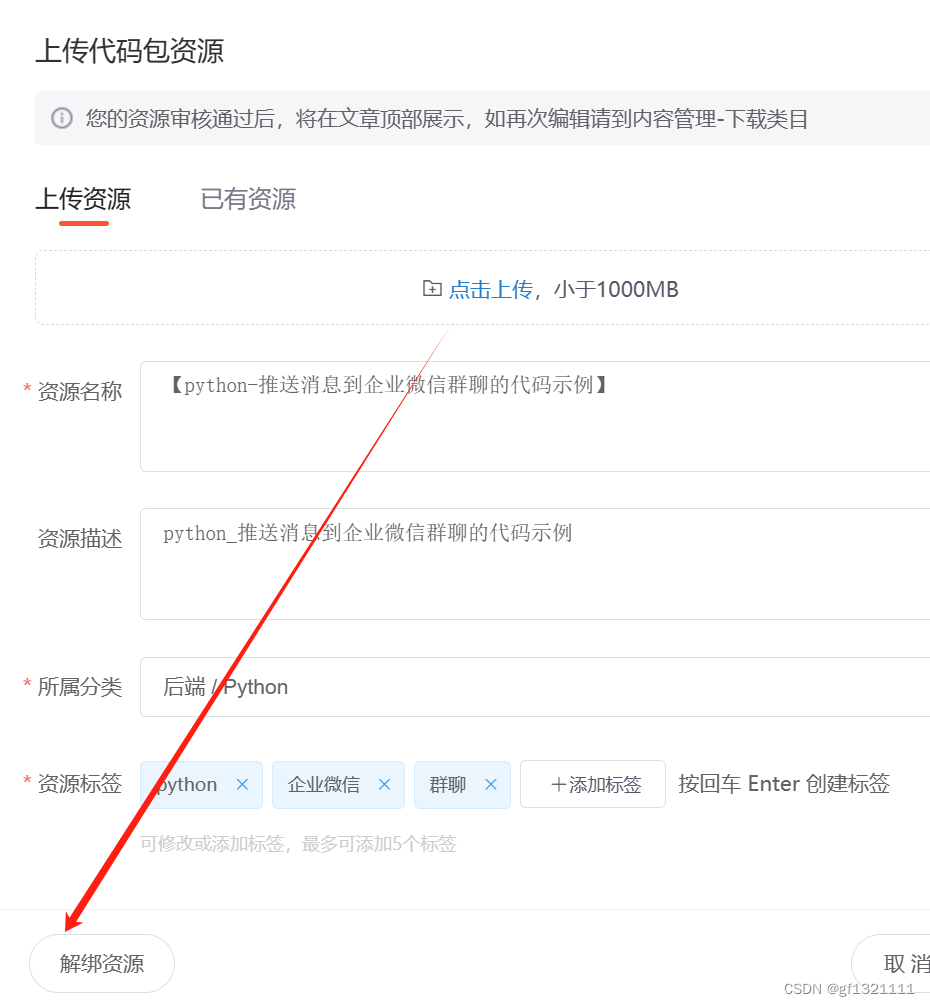
csdn中的资源文件如何删除?
csdn中的资源文件如何删除? 然后写文章的时候 点击资源绑定,解锁资源,就可以再次上传。...

NA原理及配置
在IP地址空间中,a;b;c类地址中各有一部分地址,被称为私有IP地址(私网地址),其余的为公有IP地址(公网地址) A:10.0.0.0 - 10.255.255.255 --- 相当于1条A类网段…...

解决:TypeError: ‘tuple’ object does not support item assignment
解决:TypeError: ‘tuple’ object does not support item assignment 文章目录 解决:TypeError: tuple object does not support item assignment背景报错问题报错翻译报错位置代码报错原因解决方法方法一:方法二:今天的分享就到…...
vue3项目中axios的常见用法和封装拦截(详细解释)
1、axios的简单介绍 Axios是一个基于Promise的HTTP客户端库,用于浏览器和Node.js环境中发送HTTP请求。它提供了一种简单、易用且功能丰富的方式来与后端服务器进行通信。能够发送常见的HTTP请求,并获得服务端返回的数据。 此外,Axios还提供…...

基础语法(一)(1)
常量和表达式 在这里,我们可以把Python当成一个计算器,来进行一些算术运算 例如: print(1 2 - 3) print(1 2 * 3) print(1 2 / 3)注意: print是一个python内置的函数,这个稍后我们会进行介绍 可以使用-*/&…...
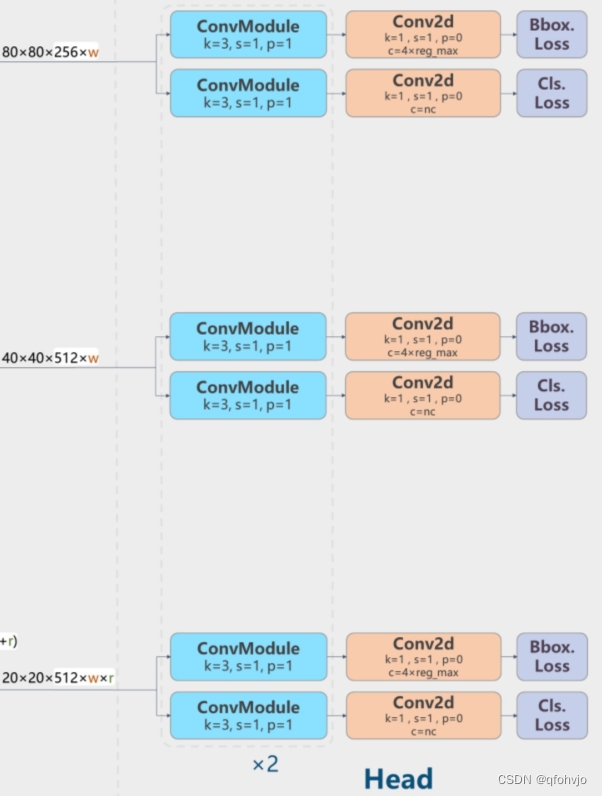
YOLOv8模型yaml结构图理解(逐层分析)
前言 YOLO-V8(官网地址):https://github.com/ultralytics/ultralytics 一、yolov8配置yaml文件 YOLOv8的配置文件定义了模型的关键参数和结构,包括类别数、模型尺寸、骨架(backbone)和头部(hea…...

【大数据】Zookeeper 集群及其选举机制
Zookeeper 集群及其选举机制 1.安装 Zookeeper 集群2.如何选取 Leader 1.安装 Zookeeper 集群 我们之前说了,Zookeeper 集群是由一个领导者(Leader)和多个追随者(Follower)组成,但这个领导者是怎么选出来的…...

Redis 过期策略
我们在set key的时候可以设置key的过期时间,哪redis是怎么处理过期的key的呢? 有三种过期策略 定时过期:每个设置过期时间的key会创建一个定时器,到过期时间就会立即对key进行清除。该策略可以立即清除过期的数据,对…...
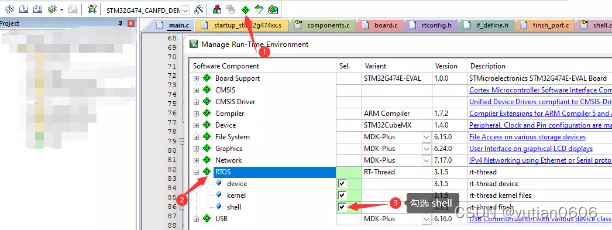
RT_Thread 调试笔记:串口打印、MSH控制台 相关
说明:记录日常使用 RT_Thread 开发时做的笔记。 持续更新中,欢迎收藏。 1.打印相关 1.打印宏定义,可以打印打印所在文件,函数,行数。 #define PRINT_TRACE() printf("-------%s:%s:%d------\r\n", __FIL…...

Checkmate:代码提交前的自动化质量检查工具实战指南
1. 项目概述:一个为开发者打造的代码质量守护者最近在梳理团队内部的代码审查流程,发现一个挺普遍的问题:很多初级开发者,甚至一些有经验的朋友,在提交代码前,对于“代码是否真的准备好了”这件事ÿ…...

基于RAG的Obsidian智能知识库:本地部署与优化实战
1. 项目概述:当知识管理遇上大语言模型 如果你和我一样,是 Obsidian 的深度用户,同时又对大语言模型(LLM)的智能涌现能力感到着迷,那么你肯定也想过一个问题:能不能让我的知识库“活”起来&…...

轨道交通条形屏电源技术分析:超薄化与高可靠性的工程平衡
一、行业背景与技术挑战在智慧城轨建设中,地铁站内条形屏是乘客信息显示系统的核心终端设备。该应用场景对配套电源提出以下技术要求:技术需求具体指标工程挑战超薄化整机厚度3-8mm传统变压器/散热器高度难以压缩高可靠性MTBF≥50000小时轨道交通振动、温…...

PhonePi-MCP:基于MCP协议实现AI智能体自动化操控Android手机
1. 项目概述:当你的手机成为AI的“眼睛”与“双手” 最近在折腾AI智能体(Agent)时,我一直在思考一个问题:如何让这些运行在云端或本地电脑上的“大脑”真正地与现实世界互动?比如,让它帮我查一…...

MVDRAM技术:利用DRAM隐藏计算潜力加速LLM推理
1. MVDRAM技术背景与核心挑战在当今大语言模型(LLM)推理场景中,矩阵向量乘法(GeMV)操作占据了超过70%的计算开销。传统CPU/GPU架构面临三个根本性瓶颈:内存墙问题(数据搬运能耗是计算的200倍&am…...

基于Google Workspace API与LLM的办公自动化技能框架设计与实现
1. 项目概述:当Google Workspace遇上AI技能 如果你和我一样,日常重度依赖Google Workspace(以前叫G Suite)来处理邮件、文档、表格和日历,那你肯定也想过:要是这些工具能更“聪明”一点就好了。比如&#…...

0.2mm间距测试探针技术解析与应用指南
1. 0.2mm间距测试探针的技术突破与应用价值在半导体测试领域,随着芯片封装尺寸的持续缩小和信号频率的不断提升,传统测试探针已难以满足高密度互连与高频测试的双重需求。Aries Electronics最新推出的0.2mm间距测试探针,采用镀金铍铜材料和特…...

深圳市2026年打造人工智能先锋城市项目扶持计划申请指南
本项目扶持计划下设十个项目类别,均采用事后奖补类支持方式。1、申报单位需同时满足基础申报条件和专项申报条件。基础申报条件如下:(一)申报单位为在深圳市内(含深汕特别合作区)从事生产经营活动ÿ…...

raylib终极指南:3天从零到一的游戏开发快速入门
raylib终极指南:3天从零到一的游戏开发快速入门 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib raylib是一款专为游戏开发设计的轻量级跨平台框架&am…...

一文读懂 .git 目录:Git 仓库的心脏与底层原理
你是否也曾好奇,Git 是如何记住我们每一次提交、每一次分支切换的?答案就藏在项目根目录下那个不起眼的 .git 文件夹里。它是 Git 仓库的 “心脏”,所有版本控制的数据、历史记录、配置信息都存储在这里。今天,我们就来深度拆解 .…...