Springboot使用logback
文章目录
目录
文章目录
前言
一、添加依赖
二、使用步骤
三 、测试使用
总结
前言
Logback 是log4j 框架的作者开发的新一代日志框架,它效率更高、能够适应诸多的运行环境,同时天然支持 SLF4J。
Logback 的定制性更加灵活,同时也是 SpringBoot 的内置日志框架。
一、添加依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
二、使用步骤
在配置文件中 修改配置
# 日志配置
logging:level:root: infocom.wise: infoorg.springframework: infocom.baomidou.mybatisplus: info config: classpath:logback.xml在同级目录下的日志模板文件 logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration><property name="log.path" value="./logs"/><property name="console.log.pattern"value="%d{yyyy-MM-dd HH:mm:ss.SSS} %highlight(%-5level) %magenta(${PID:-}) - %green([%-21thread]) %cyan(%-35logger{30}) %msg%n" /><property name="log.pattern" value="%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n"/><!-- 控制台输出 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>${console.log.pattern}</pattern><charset>utf-8</charset></encoder></appender><!-- 文件输出 --><appender name="file_info" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 过滤的级别 --><level>INFO</level><!-- 匹配时的操作:接收(记录) --><onMatch>ACCEPT</onMatch><!-- 不匹配时的操作:拒绝(不记录) --><onMismatch>DENY</onMismatch></filter><file>${log.path}/sys-info.log</file><!-- 循环政策:基于时间创建日志文件 --><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 日志文件名格式 --><fileNamePattern>${log.path}/sys-info.%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>30</maxHistory><totalSizeCap>20KB</totalSizeCap><maxFileSize>10KB</maxFileSize><!-- appender启动时,进行一次日志文件清理(作用:有些存活很短时间的应用,没机会进行文件清理) --><cleanHistoryOnStart>true</cleanHistoryOnStart></rollingPolicy><encoder><pattern>${log.pattern}</pattern></encoder></appender><appender name="file_error" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 过滤的级别 --><level>ERROR</level><!-- 匹配时的操作:接收(记录) --><onMatch>ACCEPT</onMatch><!-- 不匹配时的操作:拒绝(不记录) --><onMismatch>DENY</onMismatch></filter><file>${log.path}/sys-error.log</file><!-- 循环政策:基于时间创建日志文件 --><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 日志文件名格式 --><fileNamePattern>${log.path}/sys-error.%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>30</maxHistory><totalSizeCap>20KB</totalSizeCap><maxFileSize>10KB</maxFileSize><!-- appender启动时,进行一次日志文件清理(作用:有些存活很短时间的应用,没机会进行文件清理) --><cleanHistoryOnStart>true</cleanHistoryOnStart></rollingPolicy><encoder><pattern>${log.pattern}</pattern></encoder></appender><!-- 系统日志输出 --><appender name="file_debug" class="ch.qos.logback.core.rolling.RollingFileAppender"> <filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 过滤的级别 --><level>DEBUG</level></filter><file>${log.path}/sys-debug.log</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>${log.path}/sys-debug.%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>30</maxHistory><totalSizeCap>20KB</totalSizeCap><maxFileSize>10KB</maxFileSize><!-- appender启动时,进行一次日志文件清理(作用:有些存活很短时间的应用,没机会进行文件清理) --><cleanHistoryOnStart>true</cleanHistoryOnStart></rollingPolicy><encoder><pattern>${log.pattern}</pattern></encoder></appender> <!-- 用户访问日志输出 --><appender name="sys_user" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/sys_user.log</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>${log.path}/sys-user.%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>30</maxHistory><totalSizeCap>20KB</totalSizeCap><maxFileSize>10KB</maxFileSize><!-- appender启动时,进行一次日志文件清理(作用:有些存活很短时间的应用,没机会进行文件清理) --><cleanHistoryOnStart>true</cleanHistoryOnStart></rollingPolicy><encoder><pattern>${log.pattern}</pattern></encoder></appender><root level="info"><appender-ref ref="console"/></root><!--系统操作日志--><root level="error"><appender-ref ref="file_error"/></root><!--系统操作日志--><root level="info"><appender-ref ref="file_info"/><appender-ref ref="file_error"/></root><!--系统操作日志--><root level="debug"><appender-ref ref="file_debug"/><appender-ref ref="file_info"/><appender-ref ref="file_error"/></root> <!--系统用户操作日志--><logger name="sys_user" level="info"><appender-ref ref="sys_user"/></logger>
</configuration>三 、测试使用
在需要日志记录的类上添加该注解@Slf4j,然后直接使用下面的就能打印日志了log.info("这是一条测试info日志");log.warn("这是一条测试info日志:{}", "warn");log.error("这是一条测试info日志", e);总结
相关文章:

Springboot使用logback
文章目录 目录 文章目录 前言 一、添加依赖 二、使用步骤 三 、测试使用 总结 前言 Logback 是log4j 框架的作者开发的新一代日志框架,它效率更高、能够适应诸多的运行环境,同时天然支持 SLF4J。 Logback 的定制性更加灵活,同时也是 Sprin…...
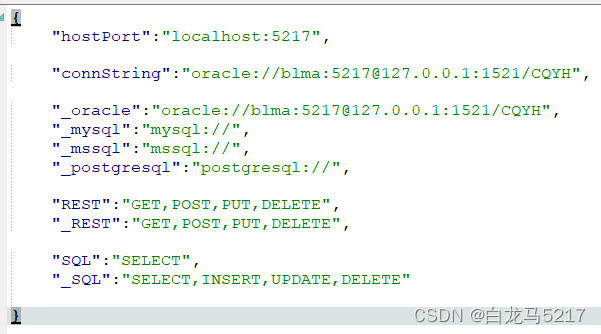
【REST2SQL】03 GO读取JSON文件
REST2SQL需要一些配置信息,用JSON文件保存,比如config.json 1 创建config.json配置文件 {"hostPort":"localhost:5217","connString":"oracle://blma:5217127.0.0.1:1521/CQYH","_oracle":"ora…...
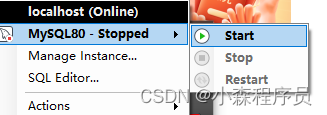
数据库-MySQL 启动方式
以管理员身份运行命令行 或者Shell net start //查看所有服务 net start MYSQL80 //启动服务 net stop MYSQL80 //停止服务完整安装MySQL社区版本的 会有这个 启动服务 停止服务 重启服务...

YAML使用
yaml yaml是类型aml,json的标记性语言,它强调以数据为中心 yaml的语法主要是如下几个: 大小写敏感 使用缩进表示层级关系 缩进不允许使用tab、只允许空格(低版本限制,高版本不限制) 缩进时空格数不重要&a…...
)
读书之深入理解ffmpeg_简单笔记2(初步)
再回看第一遍通读后的笔记,感觉还有很多的细节需要一一攻克,。 mp4的封装格式,解析方式。 flv的封装格式,解析方式。 ts的封装格式,解析方式。 第四章 封装和解封装 4.2 视频文件转flv (头文件和文件内容࿰…...

ELK+kafka+filebeat企业内部日志分析系统搭建
看上面的拓扑图,我们至少准备七台机器进行下面的实验项目。 机器主要作用分布如下: 三台安装elasticsearch来搭建ES集群实现高可用,其他机器就依次安装filebeat,kafka,logstash和kibana软件 一、部署elasticsearch来搭建ES集群 1.安装jdk 由于ES运行…...
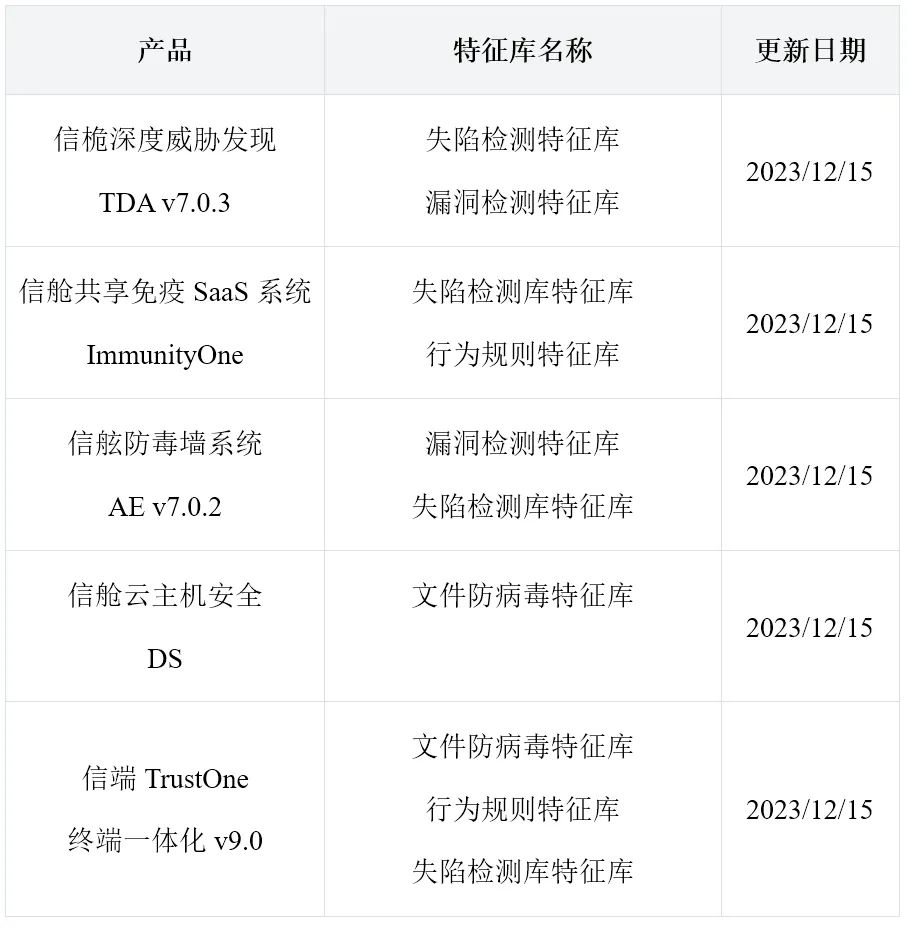
勒索检测能力升级,亚信安全发布《勒索家族和勒索事件监控报告》
评论员简评 近期(12.08-12.14)共发生勒索事件119起,相较之前呈现持平趋势。 与上周相比,近期仍然流行的勒索家族为lockbit3和8base。在涉及的勒索家族中,活跃程度Top5的勒索家族分别是:lockbit3、siegedsec、dragonforce、8base和…...

编译原理复习的有用链接
2024年1月7日,考完编译原理,是时候和考试时候的她说再见了,整理一些收藏夹里的链接和思考吧 实验看这里: 编译原理_HNU岳麓山大小姐的博客-CSDN博客 课后习题看这里: 编译原理作业答案github LL1文法复习 [编译原…...
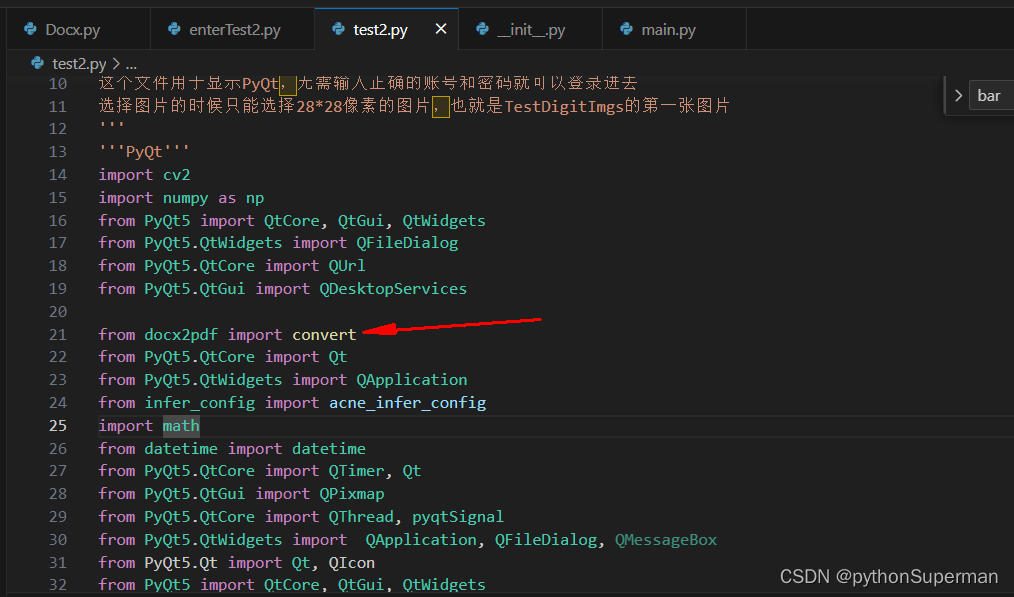
不带控制器打包exe,转pdf文件时失败的原因
加了注释的两条代码后,控制器会显示一个docx转pdf的进度条。这个进度条需要控制器的实现,如果转exe不带控制器的话,当点击转换为pdf的按钮就会导致程序出错和闪退。 __init__.py文件的入口...

Python 注释的方法
在Python中,有两种常见的注释方法: 单行注释:使用#符号来注释一行代码。在#符号后面的内容将被视为注释,不会被解释器执行,如: # 这是一个单行注释 print(hello world!) # 打印字符串多行注释࿱…...

webman插件创建
webman插件创建 介绍 应用插件实际上是一个完整的应用,它能以插件的形式安装到主项目中,使主项目快速获得某个模块功能。 例如:主项目需要一个问答系统,则可以安装一个问答应用插件,需要一个商城系统,则安…...
大模型迎来“AppStore时刻”,OpenAI给2024的新想象
一夜之间,OpenAI公布了多个重磅消息,引发市场关注。 钛媒体App 1月5日消息,今晨,OpenAI公司向所有GPT开发者们发布一封邮件称,下周将上线自定义的“GPT Store”商店,这有望推动ChatGPT开发者生态不断完善。…...

ubuntu解决在pycharm上使用jupyter无法导入虚拟环境中的包的问题
ubuntu解决在pycharm上使用jupyter无法导入虚拟环境中的包的问题 根本原因是jupyter 没有和他对应的kernel 需要先使用命令行建立kernel 下载ipykernel pip install ipykernel 首先激活conda conda activate然后添加你的kernel到虚拟环境 python -m ipykernel install -…...
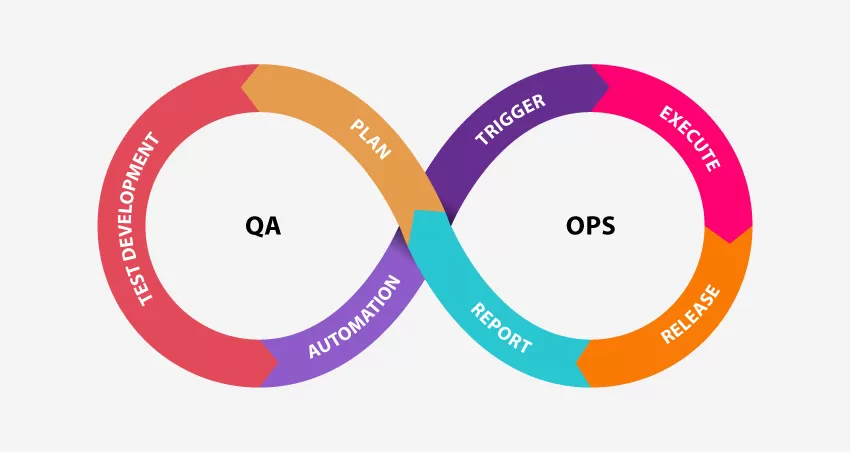
探索2024年软件测试的几大主导趋势
进入2024年,考虑影响测试环境的问题至关重要。这种思考将成为团队了解主要瓶颈和实现当今不断提高的期望的首要因素。 01 了解关键测试瓶颈 毋庸置疑,现代团队需要不断创新、适应和拥抱最新趋势,以保持竞争力并提供以客户为中心的解决方案。尽…...

Linux C语言 48-信号总结
Linux C语言 48-信号总结 本节关键字:Linux、C语言、常用信号 相关C库函数:printf、signal、kill Linux中都有哪些信号 信号在Linux操作系统中是很重要的,信号的产生方式可以是来自键盘、由软件条件产生、调用硬件异常产生。来自系统函数调…...

【vue技巧】之如何让mixin的data 比本身vue的data优先级要高
GPT4.0国内站点:海鲸AI 在 Vue 中,当组件和 mixin 包含有冲突的选项时,这些选项将以一定的方式合并。对于 data 选项,组件自身的 data 会优先级更高,这意味着如果组件和 mixin 中出现了相同的字段,组件的数…...

全解析阿里云Alibaba Cloud Linux镜像操作系统
Alibaba Cloud Linux是基于龙蜥社区OpenAnolis龙蜥操作系统Anolis OS的阿里云发行版,针对阿里云服务器ECS做了大量深度优化,Alibaba Cloud Linux由阿里云官方免费提供长期支持和维护LTS,Alibaba Cloud Linux完全兼容CentOS/RHEL生态和操作方式…...

什么是数据结构?
1、一种非常经典的数据结构。 栈数据结构:stack 2、什么是数据结构? 数据结构通常是:存储数据的容器。而该容器可能存在不同的结构。 数据结构和 java 语言实际上是没有关系,数据结构是一门独立的学科。 在大学计算机专业中&#…...

GOOS=darwin 代表macOS环境
GOOSdarwin 是一个环境变量设置,表示目标操作系统为 macOS。 在Go语言中,可以使用环境变量 GOOS 来指定目标操作系统,用于交叉编译或跨平台开发。darwin 是指苹果公司的操作系统系列,主要是 macOS。 通过设置 GOOSdarwin&#x…...
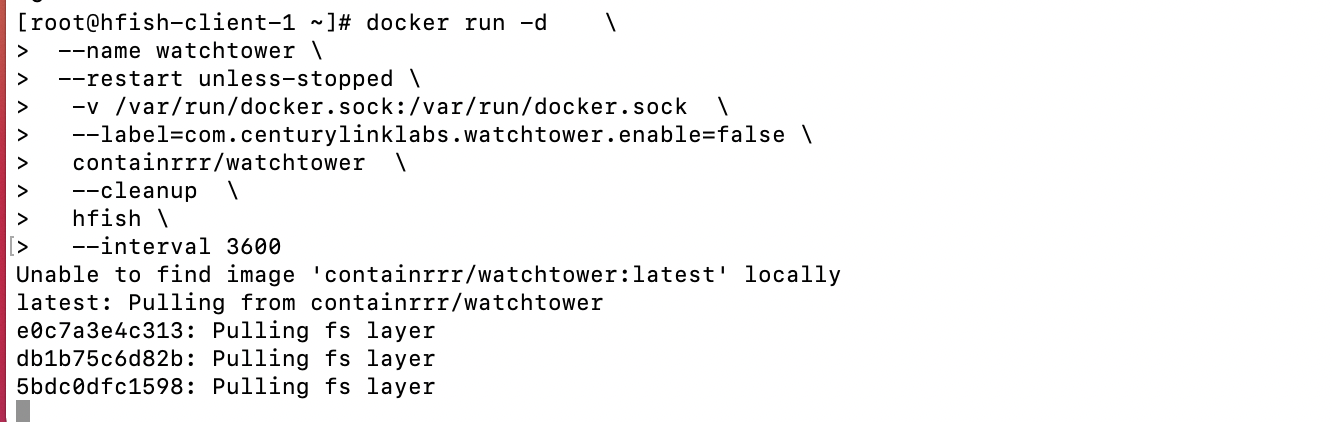
hfish蜜罐docker部署
centos 安装 docker-CSDN博客Docker下载部署 Docker是我们推荐的部署方式之一,当前的版本拥有以下特性: 自动升级:每小时请求最新镜像进行升级,升级不会丢失数据。数据持久化:在宿主机/usr/share/hfish目录下建立dat…...

Azure OpenAI代理:无缝迁移OpenAI应用到Azure云服务
1. 项目概述如果你正在使用或开发基于OpenAI官方API的应用,比如各种ChatGPT Web UI、LangChain应用,但同时又想利用微软Azure OpenAI Service在合规性、稳定性、网络延迟或成本控制上的优势,那么你大概率会遇到一个头疼的问题:这两…...

从灰度图到粉彩叙事,全程可复现:5个精准Prompt模板+3类LUT预设,零基础速产美术馆级Pastel印相
更多请点击: https://intelliparadigm.com 第一章:从灰度图到粉彩叙事:Pastel印相的美学本质与技术边界 Pastel印相并非简单的色彩叠加,而是一种基于人眼感知非线性响应与胶片化学特性的数字模拟范式。其核心在于将灰度图像的亮度…...

Mem Reduct:让电脑告别卡顿的必备内存清理神器
Mem Reduct:让电脑告别卡顿的必备内存清理神器 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct 你的电脑是…...

浏览器扩展革命:5分钟解锁微信网页版全功能访问
浏览器扩展革命:5分钟解锁微信网页版全功能访问 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版的各种限制而烦恼吗&…...

BetterGI:解放双手的终极原神自动化助手,每天节省2小时游戏时间
BetterGI:解放双手的终极原神自动化助手,每天节省2小时游戏时间 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一…...

从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机
从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机 虚拟样机技术正在彻底改变传统机电系统的开发流程。想象一下,你刚刚在SolidWorks中完成了一个精巧的自动门闭锁装置的设计,现在不需要花费数周时间加工金…...

国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案
国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内…...

MicroClaw:跨平台智能体运行时,统一AI助手部署与管理
1. 项目概述:一个跨平台的智能体运行时如果你曾经尝试过在不同的聊天平台上部署AI助手,比如在Telegram上搞一个,又在Discord上搞一个,你大概率会感到头疼。每个平台都有自己的一套API、认证方式和消息格式,这意味着你几…...

2026 年全球网络安全威胁态势与关键技术防御研究
摘要 本文基于 Security Affairs 2026 年第 576 期安全通讯披露的最新网络攻击事件与漏洞情报,系统分析 Linux 无文件远控、内核提权、AI 供应链投毒、钓鱼攻击工业化、关键信息基础设施入侵等新型威胁的技术机理、传播路径与危害特征。研究结合 Quasar Linux RAT、…...

PCL圆柱拟合进阶:从模型参数到完整轴线的精准计算
1. PCL圆柱拟合的核心挑战与工业需求 在工业测量和逆向工程领域,圆柱体是最常见的几何特征之一。想象一下汽车发动机的活塞杆、液压缸的活塞筒,或者机械臂的旋转轴,这些关键部件都需要精确的圆柱几何参数。PCL(Point Cloud Librar…...