利用python将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中
将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中
注意的点
(1)先判断写入的txt文件是否存在,如果不存在就需要创建路径
(2)如果txt文件已经存在,那么先将对应的文件进行删除后再写入txt数据
(3)excel文件中有可能第一行是字段名,需要跳过
(版本1 :本地版本)
1.利用python将excel转成txt文件
from datetime import datetime, timedelta
import os
import pytz
import pandas as pddef excel_to_txt(name, date):# Read Excel file into a DataFramedf = pd.read_excel(f'data/excel/{name}.xlsx', header=None, skiprows=1)# Define output directory and pathoutput_directory = os.path.join('data', 'txt', date)os.makedirs(output_directory, exist_ok=True) # Create directory if it doesn't existoutput_path = os.path.join(output_directory, f'{name}.txt')# Check if the file already exists, if so, remove itif os.path.exists(output_path):os.remove(output_path)print(f'Existing file {output_path} removed.')# Write DataFrame to a new text fileprint('开始写入txt文件')df.to_csv(output_path, header=None, sep='\t', index=False)print('文件写入成功!')return output_pathif __name__ == '__main__':current_time = datetime.now(pytz.timezone('Asia/Shanghai'))one_day_ago = (current_time - timedelta(days=1)).strftime('%Y-%m-%d')local_file_path = excel_to_txt('IS_GS_Recruitment_Data_20231211', one_day_ago)print(local_file_path)2.上传到hdfs
3.在hive中创建表
drop table if exists ticket.test_text;
create external table IF NOT EXISTS ticket.test_text
(name string,age int
) comment ''row format delimited fields terminated by '\t'lines terminated by '\n'NULL DEFINED AS ''stored as textfileLOCATION '/warehouse/ticket/ods/test_text';
4.将hdfs数据写入hive
load data inpath '/origin_data/test.txt' overwrite into table ticket.test_text;
(2)服务器版本
先把excel_to_txt脚本上传到服务器
excel_to_txt.py
from datetime import datetime, timedelta
import os
import pytz
import pandas as pddef excel_to_txt(name, date):# Read Excel file into a DataFramedf = pd.read_excel(f'/opt/module/data/excel/{name}.xlsx', header=None,skiprows=1)# df = pd.read_excel(f'hdfs://mycluster:8020/origin_data/hr_cn/db/is_gs_recruitment_data_full/excel/{name}.xlsx', header=None,skiprows=1)# df = pd.read_excel(f'data/excel/{name}.xlsx', header=None,skiprows=1)# Define output directory and pathoutput_directory = os.path.join('/opt/module/data', 'txt', date)os.makedirs(output_directory, exist_ok=True) # Create directory if it doesn't existoutput_path = os.path.join(output_directory, f'{name}.txt')# Check if the file already exists, if so, remove itif os.path.exists(output_path):os.remove(output_path)print(f'Existing file {output_path} removed.')# Write DataFrame to a new text fileprint('开始写入txt文件')df.to_csv(output_path, header=None, sep='\t', index=False)print('文件写入成功!')return output_pathif __name__ == '__main__':current_time = datetime.now(pytz.timezone('Asia/Shanghai'))one_day_ago = (current_time - timedelta(days=1)).strftime('%Y-%m-%d')local_file_path = excel_to_txt('IS_GS_Recruitment_Data_20231211', one_day_ago)print(local_file_path)
2.安装python3环境,安装链接:
https://editor.csdn.net/md/?articleId=129627849
3.执行python脚本
recruitment_excel_to_txt.sh
#!/bin/bash
/opt/module/miniconda3/bin/python /opt/module/data/excel/excel_to_txt.py
4.上传到hdfs,并将数据导入hive
recruitment_hdfs_to_ods.sh
#!/bin/bash
DATAX_HOME=/opt/module/datax# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;thendatestr=$2
elsedatestr=$(date -d "-1 day" +%F)
fi# 处理目标路径,检查目标路径是否存在且不为空,如果不为空,则清空目录内容
handle_target() {content_size=$(hadoop fs -count $1 | awk '{print $3}')if [[ $content_size -ne 0 ]]; thenecho "路径$1不为空,正在清空......"hadoop fs -rm -r -f $1/*fi
}# 整合处理目标路径和上传文件的逻辑
handle_target_and_put() {handle_target $2echo "上傳文件"hadoop fs -put $1 $2
}function import_data(){
# $*: 获取所有参数,如果使用""包裹之后,$*当做整体
# $#: 获取参数个数
# $@: 获取所有参数,如果使用""包裹之后,把每个参数当做单独的个体
# $?: 获取上一个指令的结果tableNames=$*sql="use hr_cn;"#遍历所有表,拼接每个表的数据加载sql语句for table in $tableNamesdosql="${sql}load data inpath '/origin_data/hr_cn/db/${table:4}/${datestr}/*' overwrite into table ${table} partition (dt='$datestr');"done#执行sql/opt/module/hive/bin/hive -e "$sql"
}case $1 in
"all")handle_target_and_put /opt/module/data/txt/${datestr}/ /origin_data/hr_cn/db/recruitment_info_full/import_data "ods_recruitment_info_full";;
"recruitment_info")handle_target_and_put /opt/module/data/txt/${datestr}/ /origin_data/hr_cn/db/recruitment_info_full/import_data "ods_recruitment_info_full";;
esac相关文章:

利用python将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中
将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中 注意的点 (1)先判断写入的txt文件是否存在,如果不存在就需要创建路径 (2)如果txt文件已经存在,那么先将对应的文件进行…...
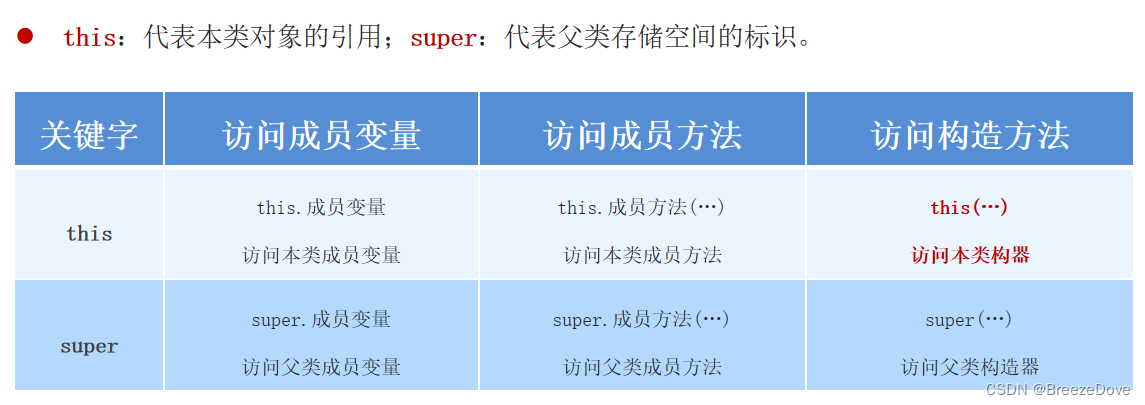
【自学笔记】01Java基础-07面向对象基础-02继承
记录学习Java基础中有关继承、方法重写、构造器调用的基础知识,学习继承之前建议学习static关键字的内容【自学笔记】01Java基础-09Java关键字详解 1 继承概述 1.1 什么是继承? 1.2 继承的特点 子类可以继承父类的属性和行为,但是子类不能…...

二分查找(一)
算法原理 原理:当一个序列有“二段性”的时候,就可以使用二分查找算法。 适用范围:根据规律找一个点,能将这个数组分成两部分,根据规律能有选择性的舍去一部分,进而在另一个部分继续查找。 除了最普通的…...

【华为OD真题 Python】精准核酸检测
文章目录 题目描述输入描述输出描述示例1输入输出说明备注代码实现题目描述 为了达到新冠疫情精准防控的需要,为了避免全员核酸检测带来的浪费,需要精准圈定可能被感染的人群。 现在根据传染病流调以及大数据分析,得到了每个人之间在时间、空间上是否存在轨迹的交叉。 现…...

Springboot使用logback
文章目录 目录 文章目录 前言 一、添加依赖 二、使用步骤 三 、测试使用 总结 前言 Logback 是log4j 框架的作者开发的新一代日志框架,它效率更高、能够适应诸多的运行环境,同时天然支持 SLF4J。 Logback 的定制性更加灵活,同时也是 Sprin…...
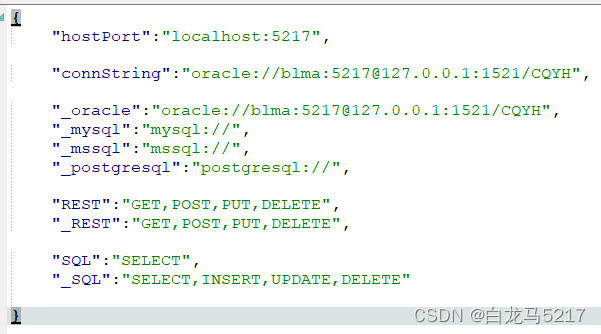
【REST2SQL】03 GO读取JSON文件
REST2SQL需要一些配置信息,用JSON文件保存,比如config.json 1 创建config.json配置文件 {"hostPort":"localhost:5217","connString":"oracle://blma:5217127.0.0.1:1521/CQYH","_oracle":"ora…...
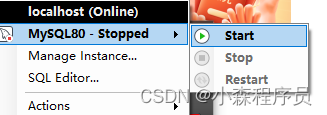
数据库-MySQL 启动方式
以管理员身份运行命令行 或者Shell net start //查看所有服务 net start MYSQL80 //启动服务 net stop MYSQL80 //停止服务完整安装MySQL社区版本的 会有这个 启动服务 停止服务 重启服务...

YAML使用
yaml yaml是类型aml,json的标记性语言,它强调以数据为中心 yaml的语法主要是如下几个: 大小写敏感 使用缩进表示层级关系 缩进不允许使用tab、只允许空格(低版本限制,高版本不限制) 缩进时空格数不重要&a…...
)
读书之深入理解ffmpeg_简单笔记2(初步)
再回看第一遍通读后的笔记,感觉还有很多的细节需要一一攻克,。 mp4的封装格式,解析方式。 flv的封装格式,解析方式。 ts的封装格式,解析方式。 第四章 封装和解封装 4.2 视频文件转flv (头文件和文件内容࿰…...

ELK+kafka+filebeat企业内部日志分析系统搭建
看上面的拓扑图,我们至少准备七台机器进行下面的实验项目。 机器主要作用分布如下: 三台安装elasticsearch来搭建ES集群实现高可用,其他机器就依次安装filebeat,kafka,logstash和kibana软件 一、部署elasticsearch来搭建ES集群 1.安装jdk 由于ES运行…...
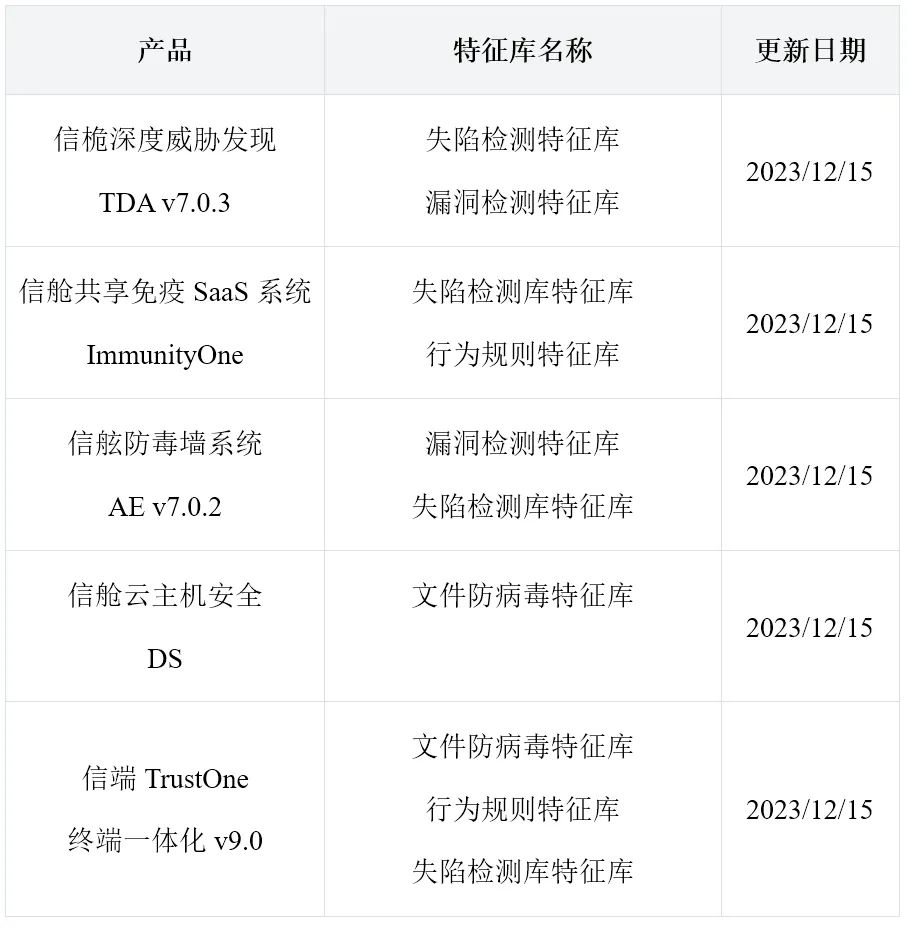
勒索检测能力升级,亚信安全发布《勒索家族和勒索事件监控报告》
评论员简评 近期(12.08-12.14)共发生勒索事件119起,相较之前呈现持平趋势。 与上周相比,近期仍然流行的勒索家族为lockbit3和8base。在涉及的勒索家族中,活跃程度Top5的勒索家族分别是:lockbit3、siegedsec、dragonforce、8base和…...

编译原理复习的有用链接
2024年1月7日,考完编译原理,是时候和考试时候的她说再见了,整理一些收藏夹里的链接和思考吧 实验看这里: 编译原理_HNU岳麓山大小姐的博客-CSDN博客 课后习题看这里: 编译原理作业答案github LL1文法复习 [编译原…...
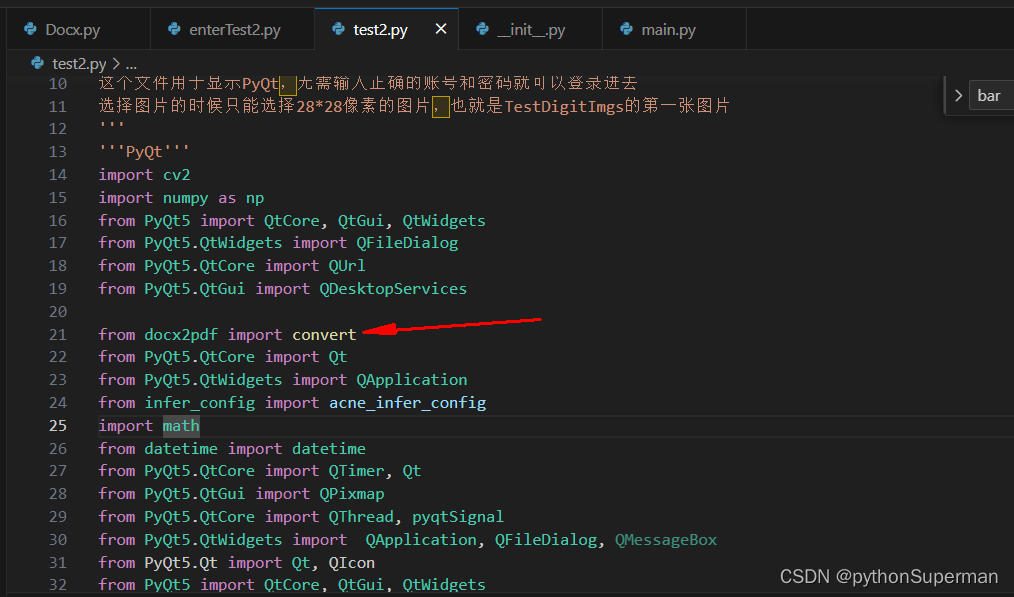
不带控制器打包exe,转pdf文件时失败的原因
加了注释的两条代码后,控制器会显示一个docx转pdf的进度条。这个进度条需要控制器的实现,如果转exe不带控制器的话,当点击转换为pdf的按钮就会导致程序出错和闪退。 __init__.py文件的入口...

Python 注释的方法
在Python中,有两种常见的注释方法: 单行注释:使用#符号来注释一行代码。在#符号后面的内容将被视为注释,不会被解释器执行,如: # 这是一个单行注释 print(hello world!) # 打印字符串多行注释࿱…...

webman插件创建
webman插件创建 介绍 应用插件实际上是一个完整的应用,它能以插件的形式安装到主项目中,使主项目快速获得某个模块功能。 例如:主项目需要一个问答系统,则可以安装一个问答应用插件,需要一个商城系统,则安…...
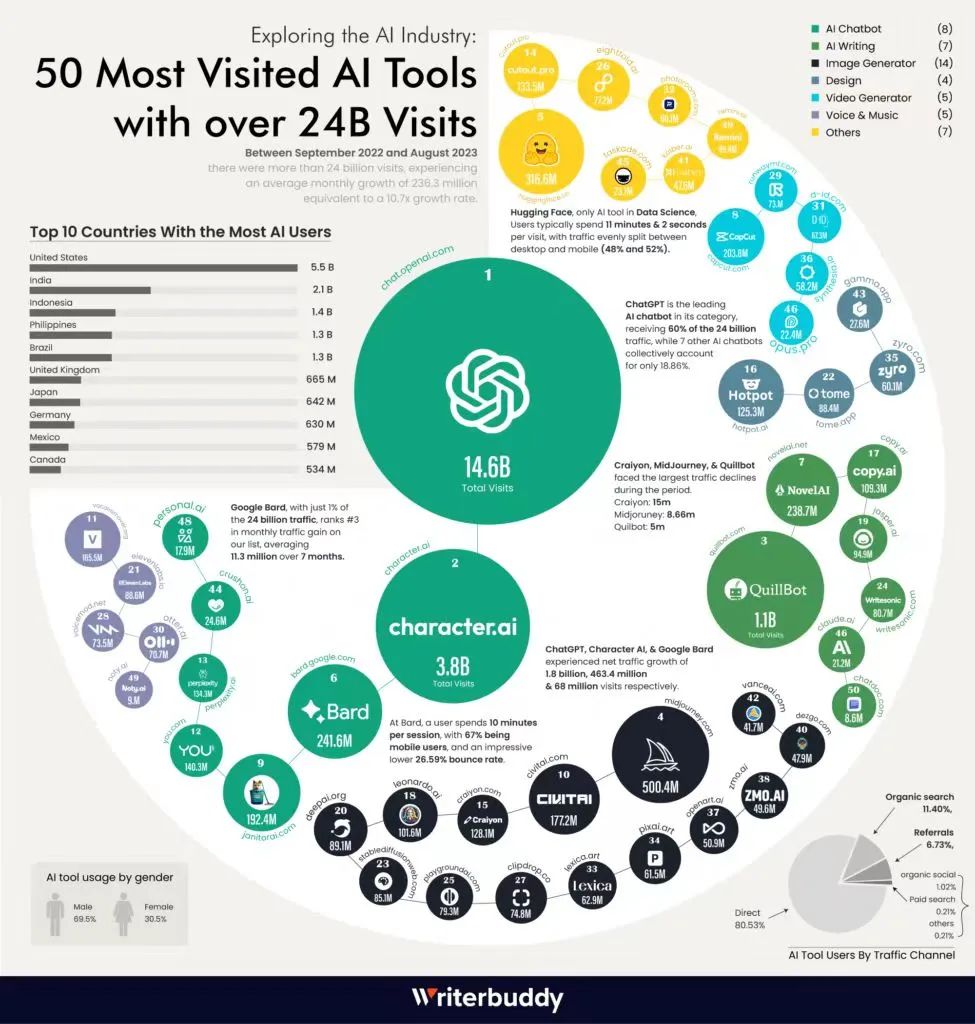
大模型迎来“AppStore时刻”,OpenAI给2024的新想象
一夜之间,OpenAI公布了多个重磅消息,引发市场关注。 钛媒体App 1月5日消息,今晨,OpenAI公司向所有GPT开发者们发布一封邮件称,下周将上线自定义的“GPT Store”商店,这有望推动ChatGPT开发者生态不断完善。…...

ubuntu解决在pycharm上使用jupyter无法导入虚拟环境中的包的问题
ubuntu解决在pycharm上使用jupyter无法导入虚拟环境中的包的问题 根本原因是jupyter 没有和他对应的kernel 需要先使用命令行建立kernel 下载ipykernel pip install ipykernel 首先激活conda conda activate然后添加你的kernel到虚拟环境 python -m ipykernel install -…...
探索2024年软件测试的几大主导趋势
进入2024年,考虑影响测试环境的问题至关重要。这种思考将成为团队了解主要瓶颈和实现当今不断提高的期望的首要因素。 01 了解关键测试瓶颈 毋庸置疑,现代团队需要不断创新、适应和拥抱最新趋势,以保持竞争力并提供以客户为中心的解决方案。尽…...

Linux C语言 48-信号总结
Linux C语言 48-信号总结 本节关键字:Linux、C语言、常用信号 相关C库函数:printf、signal、kill Linux中都有哪些信号 信号在Linux操作系统中是很重要的,信号的产生方式可以是来自键盘、由软件条件产生、调用硬件异常产生。来自系统函数调…...

【vue技巧】之如何让mixin的data 比本身vue的data优先级要高
GPT4.0国内站点:海鲸AI 在 Vue 中,当组件和 mixin 包含有冲突的选项时,这些选项将以一定的方式合并。对于 data 选项,组件自身的 data 会优先级更高,这意味着如果组件和 mixin 中出现了相同的字段,组件的数…...

从零构建Telegram天气机器人:Python异步编程与API集成实战
1. 项目概述:一个能聊天的天气机器人 如果你用过Telegram,大概率会见过或者用过一些机器人。它们能帮你查新闻、翻译、管理任务,甚至陪你聊天。今天要聊的这个项目, imkarimkarim/Telegram-Weather-Bot ,就是一个典型…...
)
2023B卷,阿里巴巴找黄金宝箱(4)
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:华为OD面试 文章目录 一、🍀前言 1.1 ☘️题目详情 1.2 ☘️参考解题答案 一、🍀前言 2023B卷,阿里巴巴找黄金宝箱(4)。 1.1 ☘️题目详情 题目:…...

从零上手向量数据库:基于Pinecone官方示例构建AI应用实战指南
1. 项目概述:从零上手向量数据库与AI应用开发如果你对AI应用开发感兴趣,尤其是想了解如何让大语言模型(LLM)拥有“记忆”,或者想构建一个能理解语义而非关键词的智能搜索系统,那么你很可能已经听说过“向量…...

不加机器也能提速10倍?低成本优化系统性能,才是高手真正的实力
不加机器也能提速10倍?低成本优化系统性能,才是高手真正的实力 很多公司一遇到系统卡顿。 第一反应特别统一: 加机器。CPU 不够? 加。 QPS 扛不住? 扩容。 数据库慢? 上集群。 结果最后: 服务器越来越多。 成本越来越高。 系统还是越来越慢。 最离谱的是: 有…...

如何快速构建Python量化分析系统:5步掌握通达信数据接口
如何快速构建Python量化分析系统:5步掌握通达信数据接口 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个基于Python的高效通达信数据接口封装,专为量化投资和数…...

3个步骤,用PCL2启动器彻底告别Minecraft配置烦恼
3个步骤,用PCL2启动器彻底告别Minecraft配置烦恼 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否遇到过这样的场景:好不容易下载了心仪的模组…...
)
【MySQL】《MySQL索引核心分类面试高频考点问答清单》(附:《一页纸速记版》)
文章目录《MySQL索引核心分类面试高频考点问答清单》一、基础概念类(入门必问)Q1:MySQL索引的本质是什么?核心作用有哪些?Q2:MySQL常用的索引数据结构有哪些?各自特点是什么?Q3&…...

易连EDI-EasyLink大文件传输测试报告
一、引言 在企业级数据交换场景中,大文件传输的稳定性和效率始终是核心关注点。随着供应链协同深化,企业之间在公网进行交换的数据早已超越传统订单、发票等结构化短报文,逐步扩展到:产品主数据(含高清图片/3D模型&am…...
)
Ubuntu 20.04虚拟机重启后断网?别慌,用Netplan配置静态IP一劳永逸(附避坑指南)
Ubuntu 20.04虚拟机网络配置终极指南:Netplan静态IP与持久化方案 当你兴奋地启动Ubuntu 20.04虚拟机准备大展身手时,突然发现网络连接消失了——这不是个别现象。许多开发者在本地虚拟化环境或云平台中都遭遇过类似困扰。本文将彻底解决这个"幽灵断…...

FuckAdBlock开发者指南:自定义检测逻辑和扩展功能的完整教程
FuckAdBlock开发者指南:自定义检测逻辑和扩展功能的完整教程 【免费下载链接】FuckAdBlock Detects ad blockers (AdBlock, ...) 项目地址: https://gitcode.com/gh_mirrors/fu/FuckAdBlock FuckAdBlock是一个强大的广告拦截器检测工具,专为Web开…...