python-日志模块以及实际使用设计
python-日志模块以及实际使用设计
1. 基本组成
日志模块四个组成部分:
- 日志对象:产生日志信息
- 日志处理器:将日志信息输出到指定地方,例如终端、文件。
- 格式器:在日志处理器输出之前,对信息进行各方面的美化。
- 过滤器:在日志处理器输出之前,将信息按照过滤器的条件过滤一遍。比如按照日志级别进行过滤。
日志本质上就是如下流程:
日志级别:
- logging.DEBUG,是个int数,等于10
- logging.INFO == 20
- logging.WARNING == 30
- logging.ERROR == 40
- logging.CRITICAL == 50
2. 基本使用-在终端打印日志
logging.StreamHandler将日志信息输出到终端上。
import logging # 1,创建日志对象
logger = logging.getLogger() # 2,设置日志对象级别,INFO以及INFO以上信息被输出。
# 本质上就是自己规定哪些信息属于INFO级别,比如正常运行的记录。
logger.setLevel(logging.INFO) # 3,创建日志处理器
# 将日志处理器加入到日志对象中,可以绑定多个。
# 绑定终端处理器,将日志信息输出到终端上。
stream_handler_1 = logging.StreamHandler()
stream_handler_2 = logging.StreamHandler()
logger.addHandler(stream_handler_1)
# 绑定第二个终端处理器。
logger.addHandler(stream_handler_2)# 4,日志对象产生日志信息
# 日志对象可以产生五种级别的日志信息。
logger.debug('这是一个debug级别的日志信息')
logger.info('这是一个info级别的日志信息')
logger.warning('这是一个warning级别的日志信息')
logger.error('这是一个error级别的日志信息')
logger.critical('这是一个critical级别的日志信息')
3. 基本使用-日志打印到文件
本质就是更换日志处理器,利用logging.FileHandler()将日志信息输出到文件内。
import logginglogger = logging.getLogger()
# 设置日志最低级别。
logger.setLevel(logging.INFO)# 绑定第一个文件处理器, 将日志信息输出到文件内。
file_handler = logging.FileHandler(filename='../logs/test.log', mode='a', encoding='utf8')
logger.addHandler(file_handler)
# 绑定第二个终端处理器,将日志信息输出到终端上。
stream_handler = logging.StreamHandler()
logger.addHandler(stream_handler)# 日志对象产生日志信息
logger.debug('这是一个debug级别的日志信息')
logger.info('这是一个info级别的日志信息')
logger.warning('这是一个warning级别的日志信息')
logger.error('这是一个error级别的日志信息')
logger.critical('这是一个critical级别的日志信息')
4. 基本使用-使用格式器美化日志信息
- 创建方法:使用logging.Formatter()。
- 使用方法:处理器绑定格式器。通过setFormatter()方法进行绑定。
- 使用目的:日志信息需要提供功能:查看什么时间哪个文件的哪一行发生了什么情况。
import logginglogger = logging.getLogger()# 设置日志最低级别。
logger.setLevel(logging.INFO)# 绑定终端处理器
stream_handler = logging.StreamHandler()
logger.addHandler(stream_handler)# 绑定文件处理器
file_handler = logging.FileHandler(filename='../logs/test.log', mode='a', encoding='utf8')
logger.addHandler(file_handler)# 创建格式器
# asctime:时间。
# levelname: 日志信息级别。
# filename: 输出日志信息代码所在的文件名称。
# lineno:输出语句所在文件的行数。
# message: 日志信息。
fmt = logging.Formatter('%(asctime)s - [%(levelname)s] - %(filename)s[%(lineno)d]:%(message)s')# 将格式器绑定到处理器上
stream_handler.setFormatter(fmt)
file_handler.setFormatter(fmt)# 日志对象产生日志信息
logger.debug('这是一个debug级别的日志信息')
logger.info('这是一个info级别的日志信息')
logger.warning('这是一个warning级别的日志信息')
logger.error('这是一个error级别的日志信息')
logger.critical('这是一个critical级别的日志信息')# 终端中会输出如下信息:
'''
2024-01-06 18:42:43,755 - [INFO] - 1.py[25]:这是一个info级别的日志信息
2024-01-06 18:42:43,756 - [WARNING] - 1.py[26]:这是一个warning级别的日志信息
2024-01-06 18:42:43,756 - [ERROR] - 1.py[27]:这是一个error级别的日志信息
2024-01-06 18:42:43,757 - [CRITICAL] - 1.py[28]:这是一个critical级别的日志信息
'''
5. 基本使用-使用过滤器过滤日志信息
- 创建方法:继承重写一下logging.Filter类的filter方法。
- 使用方法:处理器通过addFilter()方法绑定过滤器。
- 使用目的:一般情况都是按照日志级别进行过滤,目的在于对将不同级别的日志信息输出到不同的文件中,方便进行查看。
import logging# 1. 创建过滤器
class LogFilter(logging.Filter):def __init__(self, name, low_level=10, high_level=50):super().__init__(name=name)self.low_level = low_levelself.high_level = high_leveldef filter(self, record):return True if self.low_level <= record.levelno <= self.high_level else Falselogger = logging.getLogger()# 2. 设置日志最低级别。
logger.setLevel(logging.DEBUG)# 3. 绑定终端处理器
stream_handler = logging.StreamHandler()
logger.addHandler(stream_handler)
# 绑定文件处理器
file_handler = logging.FileHandler(filename='./test.log', mode='a', encoding='utf8')
logger.addHandler(file_handler)# 4. 创建格式器
fmt = logging.Formatter('%(asctime)s - [%(levelname)s] - %(filename)s[%(lineno)d]:%(message)s')
# 将格式器绑定到处理器上
stream_handler.setFormatter(fmt)
file_handler.setFormatter(fmt)# 5. 创建过滤器
normal_filter = LogFilter('normal', logging.DEBUG, 20)
nonormal_filter = LogFilter('nonormal', logging.WARNING, logging.CRITICAL)# 6. 终端处理器绑定正常过滤器
stream_handler.addFilter(normal_filter)# 7. 文件处理器绑定非正常过滤器
file_handler.addFilter(nonormal_filter)# 日志对象产生日志信息
logger.debug('这是一个debug级别的日志信息')
logger.info('这是一个info级别的日志信息')
logger.warning('这是一个warning级别的日志信息')
logger.error('这是一个error级别的日志信息')
logger.critical('这是一个critical级别的日志信息')# 终端中打印以下信息:
'''
2024-01-06 20:40:14,689 - [DEBUG] - 1.py[46]:这是一个debug级别的日志信息
2024-01-06 20:40:14,689 - [INFO] - 1.py[47]:这是一个info级别的日志信息
'''# 文件中打印以下信息
'''
2024-01-06 20:40:14,689 - [WARNING] - 1.py[48]:这是一个warning级别的日志信息
2024-01-06 20:40:14,689 - [ERROR] - 1.py[49]:这是一个error级别的日志信息
2024-01-06 20:40:14,689 - [CRITICAL] - 1.py[50]:这是一个critical级别的日志信息
'''
6. 进阶使用-日常工作中的日志模块设计
日常工作中日志模块设计思路:
- 使用时只需要配置日志文件存放地址就可以。
- 日志文件的存放时间间隔:每小时或者每天。
- 设置日志的输出级别。
- 在服务模块中,存放间隔、存放路径都可以放在配置文件中。
- 日志模块一般情况下放在工程中的util文件中。看自己习惯。
util/logger.py,设计如下,也可以按照自己的额外思路进行设计。
import logging
import time
import os# 一个logging.Logger()对象
class Logging:def __init__(self):self.logger = logging.getLogger()self.logger.setLevel(logging.INFO)# 一个自定义过滤器
class Filter(logging.Filter):def __init__(self, name, low_level, high_level):super().__init__(name=name)self.low_level = low_levelself.high_level = high_leveldef filter(self, record):return True if self.low_level <= record.levelno <= self.high_level else False# 主函数,从logger.py文件汇总引人get_logger函数
def get_logger(log_root_path, low_level=logging.INFO, high_level=logging.CRITICAL):logger = Logging().loggerlog_file_name = f"{time.strftime('%Y%m%d-%H', time.localtime())}.log"handler = logging.FileHandler(filename=os.path.join(log_root_path, log_file_name),mode='a',encoding='utf-8')fmt = logging.Formatter('%(asctime)s - [%(levelname)s] - %(filename)s[%(lineno)d]:%(message)s')filter = Filter('dev', low_level, high_level)handler.setFormatter(fmt)handler.addFilter(filter)logger.addHandler(handler)return loggerif __name__ == "__main__":# 正常情况下只需要输入日志路径即可。logger = get_logger('./')logger.info('这是一个测试')相关文章:

python-日志模块以及实际使用设计
python-日志模块以及实际使用设计 1. 基本组成 日志模块四个组成部分: 日志对象:产生日志信息日志处理器:将日志信息输出到指定地方,例如终端、文件。格式器:在日志处理器输出之前,对信息进行各方面的美化…...
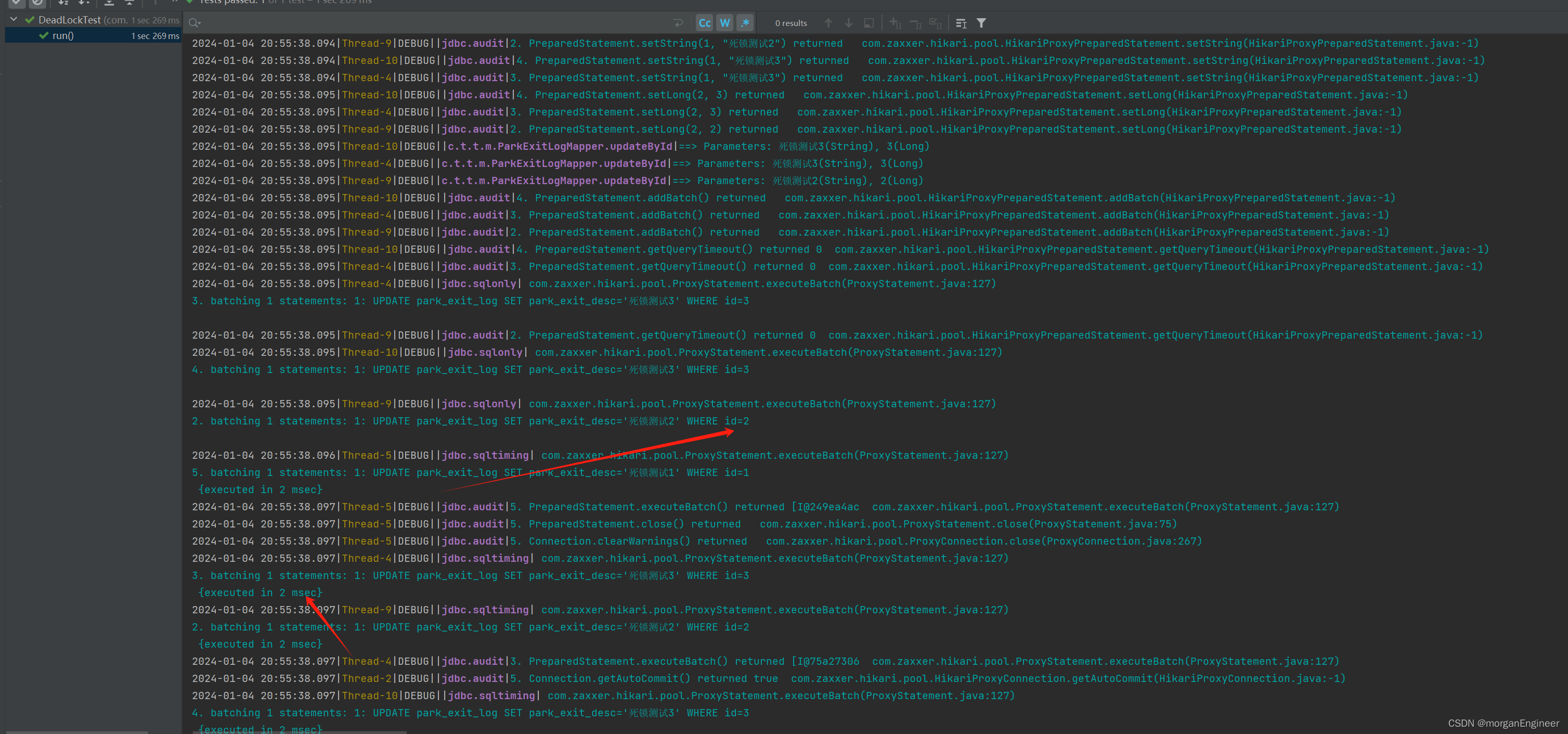
googlecode.log4jdbc慢sql日志,格式化sql
前言 无论使用原生JDBC、mybatis还是hibernate,使用log4j等日志框架可以看到生成的SQL,但是占位符和参数总是分开打印的,不便于分析,显示如下的效果: googlecode Log4jdbc 是一个开源 SQL 日志组件,它使用代理模式实…...
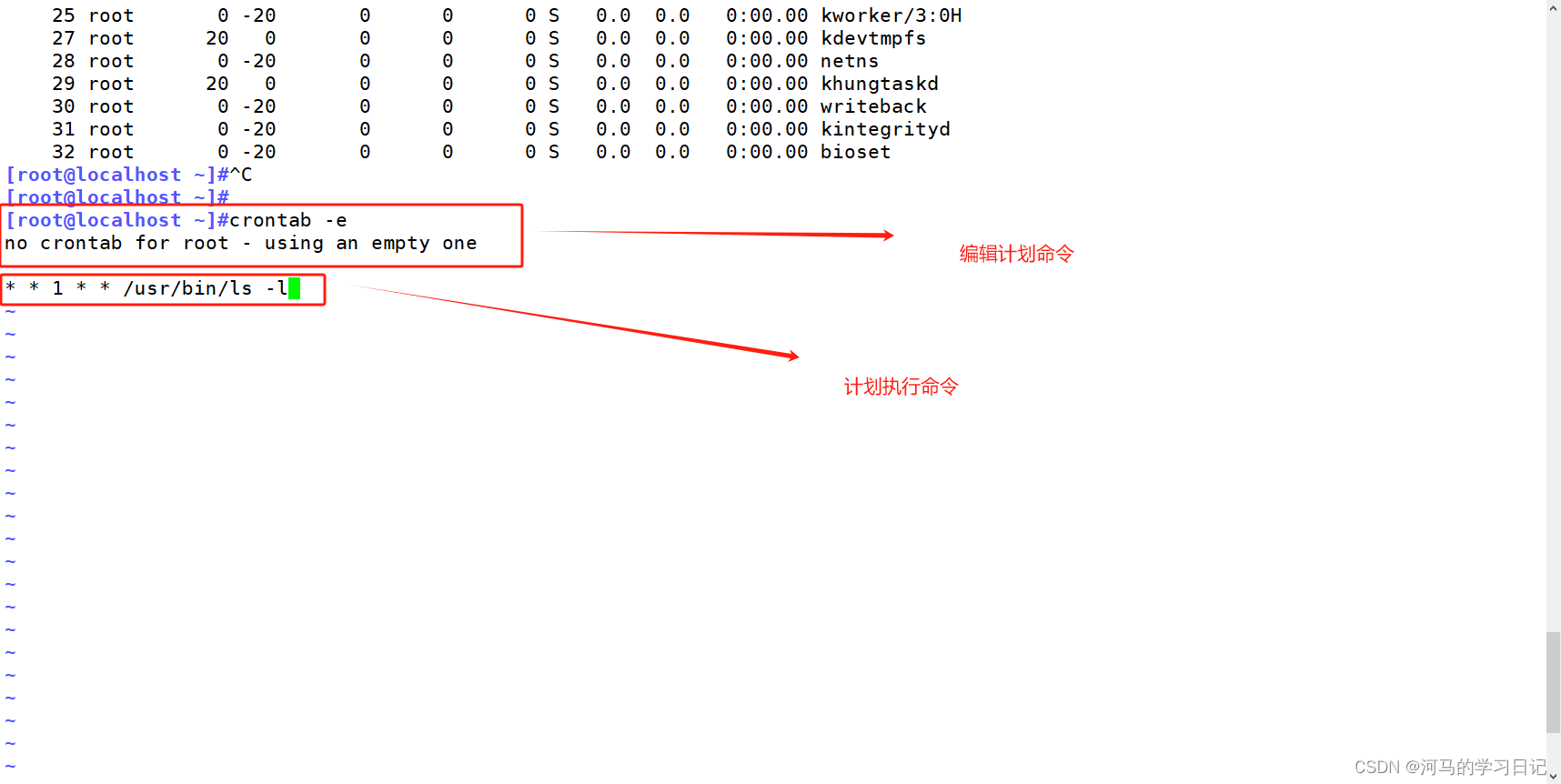
Linux程序、进程和计划任务
目录 一.程序和进程 1.程序的概念 2.进程的概念 3.线程的概念 4.单线程与多线程 5.进程的状态 二.查看进程信息相关命令: 1.ps:查看静态进程信息状态 2.top:查看动态进程排名信息 3.pgrep:查看指定进程 4.pstree&#…...

【MySQL】索引基础
文章目录 1. 索引介绍2. 创建索引 create index…on…2.1 explain2.2 创建索引create index … on…2.3 删除索引 drop index … on 表名 3. 查看索引 show indexes in …4. 前缀索引4.1 确定最佳前缀长度:索引的选择性 5. 全文索引5.1 创建全文索引 create fulltex…...

精确管理Python项目依赖:自动生成requirements.txt的智能方法
在Python中,可以使用几种方法来自动生成requirements.txt文件。这个文件通常用于列出项目所需的所有依赖包及其版本,使其他人或系统可以轻松地重现相同的环境。下面是几种常见的方法: 使用pip freeze: 这是最常见的方法。pip free…...
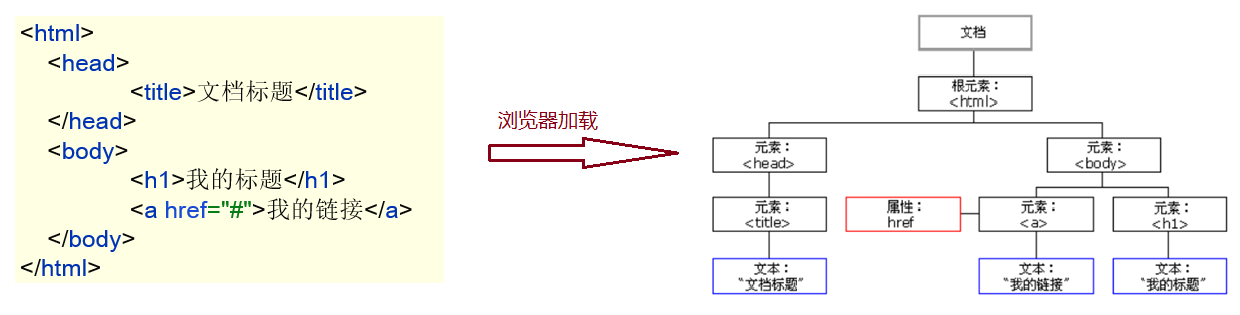
JavaWeb基础(1)- Html与JavaScript(JavaScript基础语法、变量、数据类型、运算符、函数、对象、事件监听、正则表达式)
JavaWeb基础(1)- Html与JavaScript(JavaScript基础语法、变量、数据类型、运算符、函数、对象、事件监听、正则表达式) 文章目录 JavaWeb基础(1)- Html与JavaScript(JavaScript基础语法、变量、数据类型、运算符、函数、对象、事件…...
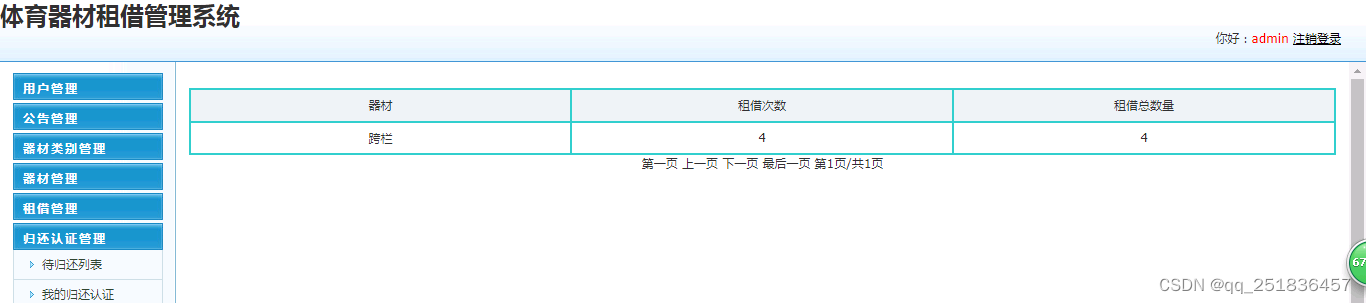
java SSM体育器材租借管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM体育器材租借管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要…...

西电期末1030.函数的最大值
一.题目 二.分析与思路 函数打擂台,注意数据类型和保留精度 三.代码实现 #include<bits/stdc.h>//万能头 double f(double x,double a){return a*x*x-x*x*x; }//f(x) int main() {double a;scanf("%lf",&a);double max-1000001;//打擂台for(…...

在Docker中安装Tomact
目录 前言: 一.安装Tomact 查找指定的tomact版本 下载tomact9.0 查看该镜像是否安装成功 安装成功之后就开始运行镜像了 ps(用于列出正在运行的Docker容器) 编辑 测试(虚拟机ip:8080) 编辑 解决措施 编辑 完成以上步骤&…...

【书生大模型00--开源体系介绍】
书生大模型开源体系介绍 0 通用人工智能1 InternLM性能及模型2 从模型到应用 大模型成为目前很热的关键词,最热门的研究方向,热门的应用;ChatGPT的横空出世所引爆,快速被人们上手应用到各领域; 0 通用人工智能 相信使…...

基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理
文章目录 一、内容简介二、前言2.1 Transformer 模型标志着AI 新时代的开始2.2 Transformer 架构具有革命性和颠覆性2.3 Google BERT 和OpenAI GPT-3 等Transformer 模型将AI 提升到另一个层次2.4 本书将带给你的“芝士”2.5 本书面向的读者 三、本书内容简介3.1 第一章3.2 第二…...

一款开源的MES系统
随着工业4.0的快速发展,制造执行系统(MES)成为了智能制造的核心。今天,将为大家推荐一款开源的MES系统——iMES工厂管家。 什么是iMES工厂管家 iMES工厂管家是一款专为中小型制造企业打造的开源MES系统。它具备高度的可定制性和灵…...
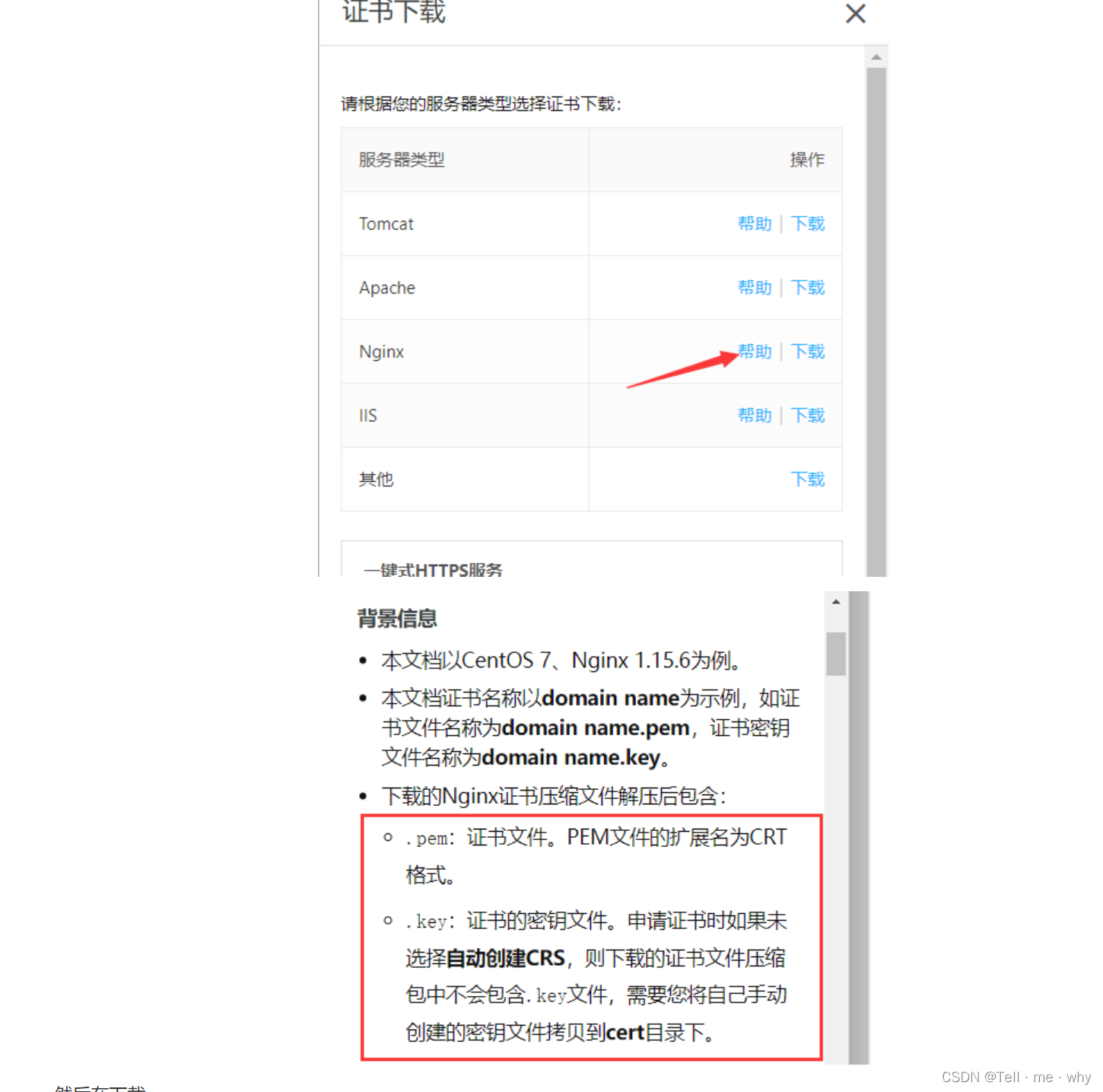
https配置证书
HTTPS 基本原理 https 介绍 HTTPS(全称:HyperText Transfer Protocol over Secure Socket Layer),其实 HTTPS 并不是一个新鲜协议,Google 很早就开始启用了,初衷是为了保证数据安全。 国内外的大型互联网…...
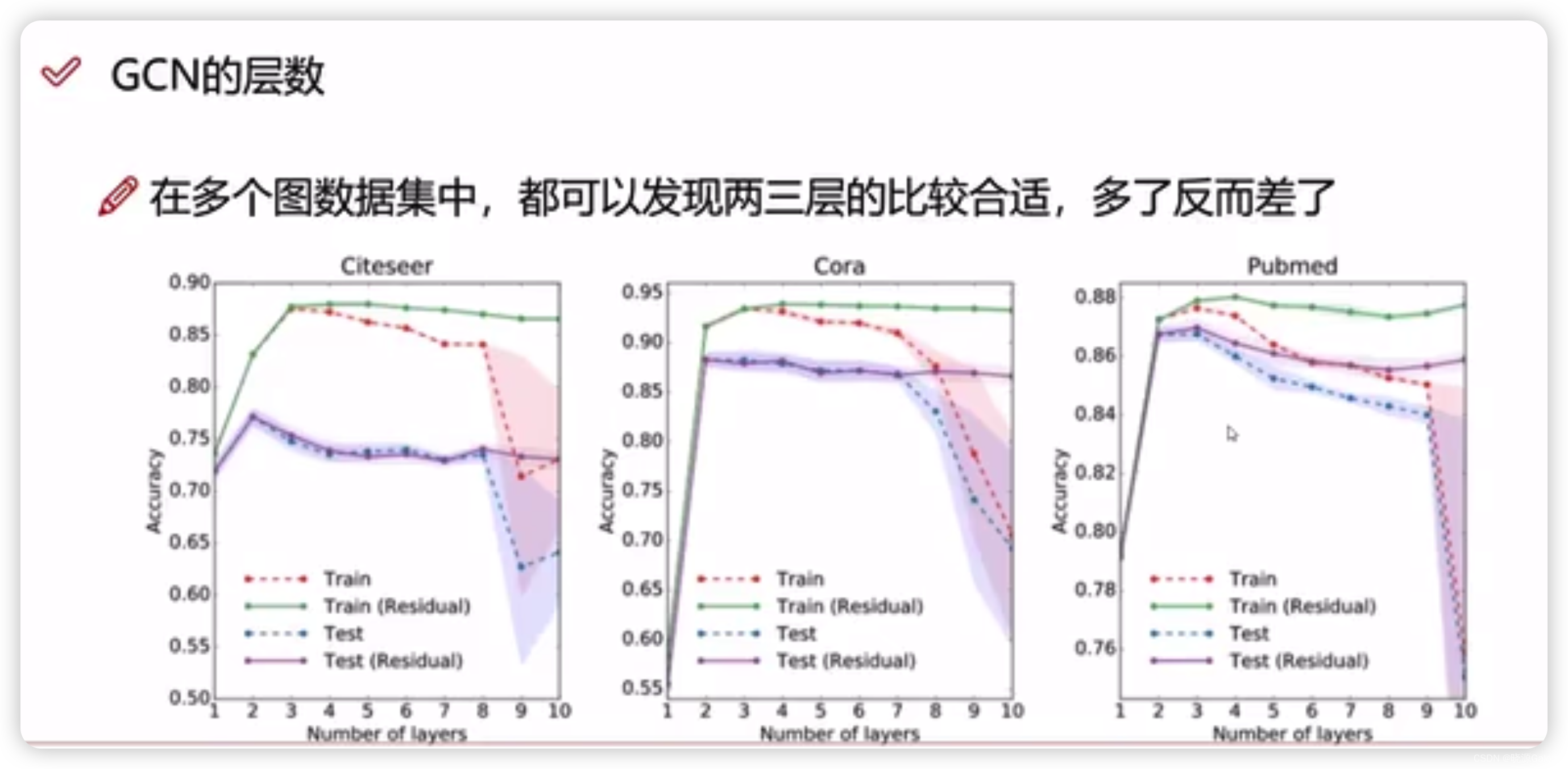
图神经网络|10.4 GCN 变换原理的解读
由9.3-邻接矩阵的变换可知,理解矩阵通过两个度矩阵的逆进行归一化。 微观上看, a i j a_{ij} aij这个元素将会乘上 1 d e g ( v i ) d e g ( v j ) \frac{1}{\sqrt{deg_(v_i)\sqrt{deg(v_j)}}} deg(vi)deg(vj) 1 其现实意义如下—— 比如…...
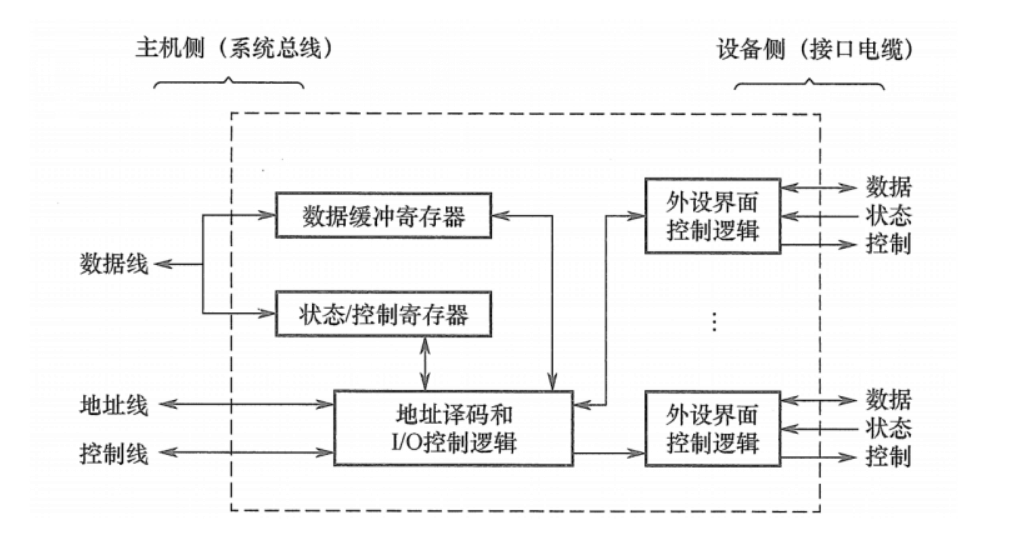
计算机组成原理 I/O方式
I/O 方式 I/O方式分类: 程序查询方式。由 CPU通过程序不断查询 /O 设备是否已做好准备,从而控制0 设备与主机交换信息程序中断方式。只在 I/0 设备准备就绪并向 CPU发出中断请求时才予以响应。DMA方式。主存和 I/O 设备之间有一条直接数据通路,当主存和…...
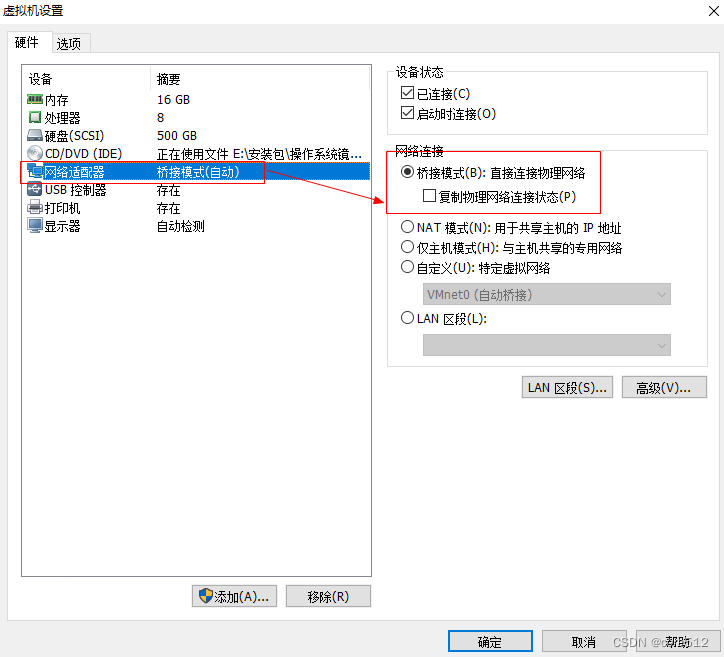
VMWare网络配置
1、通用配置 选择自动,相对与选择指定网卡,能解决网卡更换导致网络不可用的问题。 2、每个虚拟机配置...
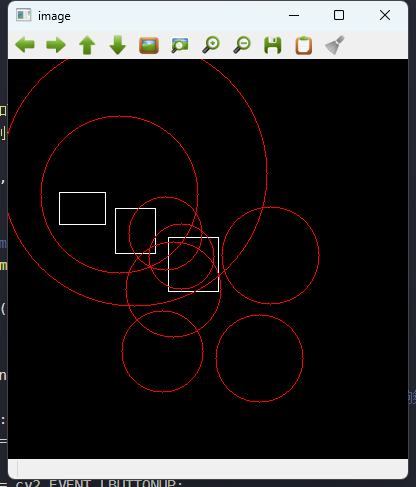
opencv期末练习题(3)附带解析
创建黑色画板,并支持两种画图功能 import mathimport cv2 import numpy as np """ 1. 创建一个黑色画板 2. 输入q退出 3. 输入m切换画图模式两种模式,画矩形和画圆形。用户按住鼠标左键到一个位置然后释放就可以画出对应的图像 "&qu…...
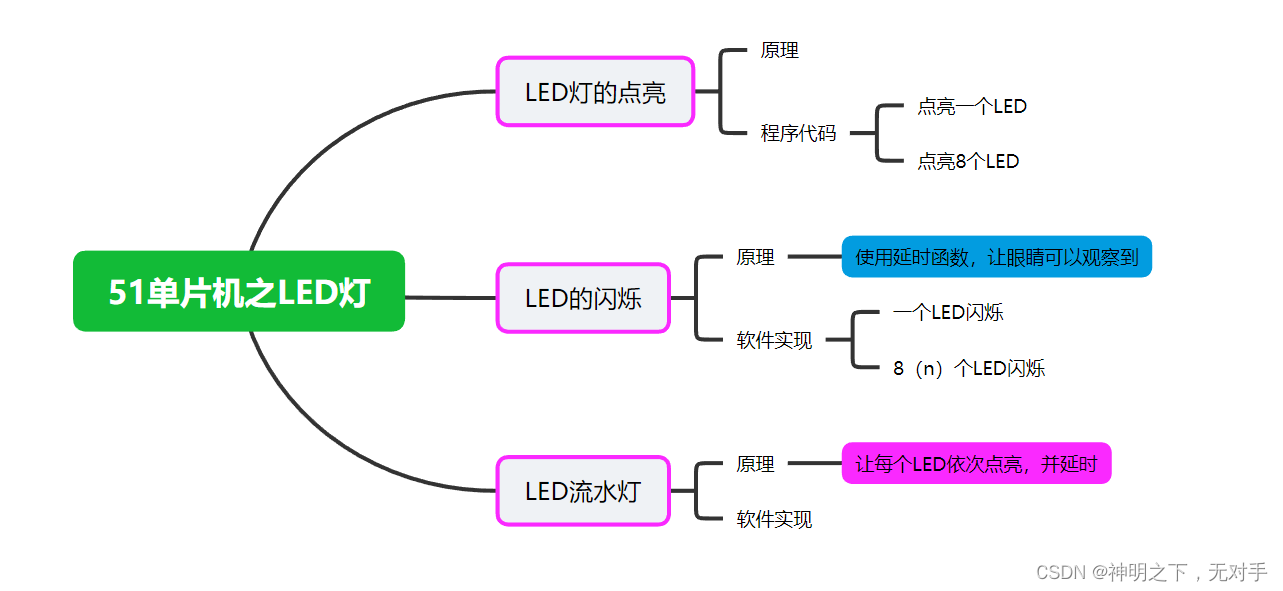
51单片机之LED灯
51单片机之LED灯 🌴前言:🏮点亮LED灯的原理💘点亮你的第一个LED灯💘点亮你的八个LED灯 📌让LED灯闪烁的原理🎽 LED灯的闪烁🏓错误示范1🏓正确的LED闪烁代码应该是这样&am…...

操作系统内存碎片
大家好,我叫徐锦桐,个人博客地址为www.xujintong.com,github地址为https://github.com/jintongxu。平时记录一下学习计算机过程中获取的知识,还有日常折腾的经验,欢迎大家访问。 一、前言 内存碎片是指无法被利用的内…...

三菱plc学习入门(二,三菱plc指令,触点比较,计数器,交替,四则运算,转换数据类型)
今天,进行总结对plc的学习,下面是对plc基础的学习,希望对读者有帮助,欢迎点赞,评论,收藏!!! 目录 触点比较 当数据太大了的时候(LDD32位) CMP比…...

TrollInstallerX终极指南:如何高效部署iOS越狱工具的专业解决方案
TrollInstallerX终极指南:如何高效部署iOS越狱工具的专业解决方案 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 在iOS 14.0到16.6.1系统上安装TrollStore一…...

Naftis架构设计原理:从Golang后端到React前端的完整技术栈
Naftis架构设计原理:从Golang后端到React前端的完整技术栈 【免费下载链接】naftis An awesome dashboard for Istio built with love. 项目地址: https://gitcode.com/gh_mirrors/na/naftis Naftis是一款专为Istio服务网格设计的现代化Web仪表板,…...

DeepSeek Jaeger性能压测实录:单日240亿Span写入下,存储层崩溃前的4.7秒黄金抢救窗口
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Jaeger链路追踪 DeepSeek Jaeger 是 DeepSeek 系列可观测性工具中专为分布式系统设计的轻量级链路追踪实现,深度兼容 OpenTracing 与 OpenTelemetry 协议,并针对大模型…...

基于Claude的多智能体代码编排框架:原理、实战与优化
1. 项目概述:当Claude遇上代码编排最近在GitHub上看到一个挺有意思的项目,叫0ldh/claude-code-agents-orchestra。光看名字,就能嗅到一股“组合拳”的味道——Claude、Code、Agents、Orchestra,这几个词凑在一起,指向性…...

基于Lepton AI构建对话式搜索引擎:RAG技术实践指南
1. 项目概述:用Lepton AI构建你的对话式搜索引擎 如果你对AI应用开发感兴趣,尤其是想快速搭建一个能理解自然语言、并能联网搜索的智能助手,那么“Search with Lepton”这个项目绝对值得你花时间研究。它本质上是一个开源的对话式搜索引擎框…...
)
手把手教你用OPA4377搭建一个精密电流检测电路(附AD原理图/PCB)
精密电流检测电路设计实战:基于OPA4377的完整解决方案 在工业自动化、新能源系统和医疗设备等领域,精密电流检测一直是电路设计中的关键挑战。传统方案往往面临噪声干扰、非线性失真和温度漂移等问题,而现代CMOS运算放大器如OPA4377为解决这些…...

CodeMaker完整指南:5分钟掌握IntelliJ IDEA智能代码生成插件
CodeMaker完整指南:5分钟掌握IntelliJ IDEA智能代码生成插件 【免费下载链接】CodeMaker A idea-plugin for Java/Scala, support custom code template. 项目地址: https://gitcode.com/gh_mirrors/co/CodeMaker 还在为Java和Scala项目中的重复编码工作而烦…...

6.1 图表选择指南
本章学习目标: 理解数据可视化的核心目的:探索 vs 解释掌握不同分析场景对应的图表类型了解每种图表的优势和局限学会根据数据特征和分析目标选择图表核心能力:不只会画图,更知道为什么画这张图一、为什么要做数据可视化ÿ…...

FPGA设计避坑指南:从复位电路到跨时钟域,手把手教你搞定亚稳态
FPGA实战:亚稳态问题全解析与工程级解决方案 在FPGA开发中,亚稳态问题如同潜伏的幽灵,往往在系统最不稳定的时候显现,导致数据错误、系统崩溃等难以追踪的故障。本文将从一个真实的UART接收模块案例出发,深入剖析亚稳态…...
)
基于Java的私人牙科诊所管理系统(10008)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...