【MySQL】索引基础
文章目录
- 1. 索引介绍
- 2. 创建索引 create index…on…
- 2.1 explain
- 2.2 创建索引create index … on…
- 2.3 删除索引 drop index … on 表名
- 3. 查看索引 show indexes in …
- 4. 前缀索引
- 4.1 确定最佳前缀长度:索引的选择性
- 5. 全文索引
- 5.1 创建全文索引 create fulltext index … on…
- 5.2 全文索引的优点
- 5.3 全文搜索的两种模式
- 5.3.1 自然语言模式
- 5.3.2 布尔模式 in boolean mode
- 6. 复合索引
- 6.1 创建复合索引
- 6.2 复合索引中列的顺序
- 6.2.1 基本规则
- 6.2.2 强制使用其他索引进行查询
- 7. 索引无效
- 7.1 重写查询以优化查询
- 7.2 将列单独提出
- 8. 使用索引排序
- 9. 覆盖索引
- 10. 维护索引
- 10.1 重复索引
- 10.2 多余索引
1. 索引介绍
- 索引本质上是数据库引擎用来快速查找数据的数据结构
- 索引能显著提高查询的性能
- 索引内部通常被存储为二进制树
- 在多数情况下,索引很小,足以放进内存,所以使用索引查找数据更快。因为从内存中读取数据总是比从磁盘中读取数据更快。
- 使用索引会带来的问题
- 索引会增加数据库的大小,因为索引必须永久存储在表旁。
- 每次添加、更新或删除记录时,MySQL必须更新对应的索引,这会影响正常操作的性能。
- 因此,应为性能关键的查询保留索引。
- 不应基于表来创建索引,而是基于查询创建索引。因为使用索引的目的是为了加快运行较慢的查询。
2. 创建索引 create index…on…
2.1 explain
-
查看MySQL是如何执行语句的:explain
- type类型:all,全表扫描,读取表中的每一条记录
- rows行数: 扫描的记录条数
use sql_store; explain select customer_id from customers where sql_store.customers.state = 'CA'
2.2 创建索引create index … on…
-
命名:idx_列名
create index idx_state on customers(state); -
创建索引后执行explain:

- type:ref,没有再做全表扫描;
- rows:行数从1010变为112;
- possible_keys:可能的键。表中可能会存在多个索引,MySQL为执行这个查询可能会考虑到的索引,MySQL最终挑选性能最佳的索引执行。
- key:实际使用的索引或键。
-
练习:查询积分大于1000的顾客
-
没有创建索引时:type为all,row为1010
explain select customer_id from customers where points > 1000;
-
为points列创建索引:type为range,rows为529
create index idx_points on customers(points);explain select customer_idfrom customerswhere points > 1000;
-
2.3 删除索引 drop index … on 表名
drop index idx_state on customers;
3. 查看索引 show indexes in …
show indexes in customers;

-
key_name:索引 / 键名
- 聚集索引:每张表最多有1个聚集索引。 在表中添加主键, MySQL会自动创建一个索引,可以快速查找记录。
- 二级索引:创建二级索引时,MySQL会自动将对应的id或主键也纳入二级索引中。例如,积分列上有一个二级索引,但在此索引中,每条记录里都有两个值,为每个顾客的积分和id。
-
collation:排序方式,A为升序,D为降序。
-
cardinality:基数。
-
表示索引中唯一值的估计数量。此数值是估量,不是真实值。
-
analyze table 表名:生成关于此表的统计信息;执行后再执行查看索引语句即可获取真实值。
analyze table customers;
-
-
index_type:索引类型
- btree:二进制树
-
为两张表创建一组关系时,MySQL会自动为外键创建索引,这样就可以快速连接表。
-
查看orders表的索引,发现外键都有二级索引。
show indexes in orders;
-
4. 前缀索引
-
使用前缀索引的原因:
- 为字符串列创建索引,如char、varchar、text、blob,索引会占用大量空间,无法达到较好的性能。索引越小越好,可以存在内存中使搜索更快。
- 索引字符串列时,不想在索引中包含整个列,只想包含列的前几个字符或列前缀,这样能使索引更小。
-
创建前缀索引:
- 在创建索引语句中的列名后的括号中输入数字以指定索引包含此列的字符数
create index idx_lastname on customers(last_name(20))- char、varchar可不指定括号中的数字;
- text、blob必须指定括号中的字符数
4.1 确定最佳前缀长度:索引的选择性
-
索引的选择性指不重复的索引值与数据总量的比值
select count(*) from customers; selectcount(distinct left(last_name, 1))/count(*) as selectivity1,count(distinct left(last_name, 5))/count(*) as selectivity5,count(distinct left(last_name, 10))/count(*)as selectivity10 from customers;
截取前5个字符时由95.6%的数据不同,可以选择前5个字符为前缀创建前缀索引。 -
索引的选择性在80%以上适合建立,否则不建议建立索引,例如性别等。
5. 全文索引
- 情景:搜索博客文章。
- 随着文章数量越来越多,查询会越来越慢。
- 用like查询,只会返回完全按照单词顺序排列的关键词的文章
use sql_blog; select * from posts where title like '%react redux%' orbody like '%react redux%'; - 全文索引
- 包括整个字符串列,而不只是存储前缀
- 会忽略任何停止词,如in、on、the等
5.1 创建全文索引 create fulltext index … on…
use sql_blog;
create fulltext index idx_title_body on posts(title, body);select *
from posts
where match(title, body) against('react redux');

- 查询时,两个内置函数支持全文索引
- match()函数,要搜索的列
- against()函数,要搜索的关键词
5.2 全文索引的优点
- 相关性得分。MySQL会基于若干因素,为包含了要搜索的词的每一行计算相关性得分。
- 相关性得分:介于0到1的浮点数,0表示没有相关性。
- 计算相关性得分:在select中写上mathc…against…计算相关性得分。查询结果按照相关性得分降序排序。
select *,match(title, body) against('react redux') as score from posts where match(title, body) against('react redux');
5.3 全文搜索的两种模式
5.3.1 自然语言模式
-
默认情况的模式。只包含react、只包含redux、包含react和redux,以上三种情况。
select *,match(title, body) against('react redux') as score from posts where match(title, body) against('react redux');
5.3.2 布尔模式 in boolean mode
-
可以包括或排除某些单词
-
against(‘text1 -text2 -text3’ in boolean mode)
- 负号:-text1, 不包括text1
- 正号:+text1,必须包括text1
- 双引号:“xuwuuu is a student”,必须包括引号中的短语
-
例如:
-
负号:包括react,不包含redux的行
select * from posts where match(title, body) against('react -redux' in boolean mode);
-
正号:包括react,不包含redux,每一行必须有form
select * from posts where match(title, body) against('react -redux +form' in boolean mode);
-
6. 复合索引
-
场景:搜索位于加州且积分大于1000的顾客
use sql_store; show indexes in customers; explain select customer_id from customers where state = 'CA' and points > 1000;
- 先把搜索范围缩小到位于加州的顾客。按照state索引进行搜索,找到位于‘CA’的所有数据。
- 然后扫描所有位于加州的顾客,并查看积分。此时的查询需要表扫描,因为state索引中没有顾客的积分。但如果加州有1000万顾客,查询还是会很慢。
6.1 创建复合索引
-
允许对多列建立索引,可优化查询。
-
可以在state列和points列上创建复合索引,可以快速找到位于任何州、拥有任意积分的数据
use sql_store; create index idx_state_points on customers(state, points); explain select customer_id from customers where state = 'CA' and points > 1000;
此时的查询需要扫描58行,之前需要扫描112行。可能的键:有3个,state上、points上、state和points上的复合索引,复合索引在优化查询上更好,因此最后选择了复合索引进行查询
-
一个索引中最多可包含16列,一般在4-6列能达到很好的性能,但最终应根据实际查询和数据量进行确定。
6.2 复合索引中列的顺序
6.2.1 基本规则
- 应该对列进行排序,让更频繁使用的列排在最前面。
- 如有5个查询,大多数或全部的查询都按state查找顾客,把state放在最前面就很合理,这有助于缩小搜索范围
- 把基数更高的列排在最前面
- 基数表示索引中唯一值的数量
- 基数更高的列排在前面能把搜索范围缩小到更少的数量
- 只是基本规则,而不是硬性规则。还应充分考虑实际的查询和数据。
6.2.2 强制使用其他索引进行查询
-
在from和where中间使用use index(索引名称)
explain select customer_id from customers use index(idx_lastname_state) where state = 'NY' and last_name like 'A%';
7. 索引无效
有些情况下,即使有索引,但仍会遇到性能问题
-
用 or 进行条件查询:
- type类型为index,是全索引扫描。
- 全索引扫描比表扫描快,因为它不涉及从磁盘读取每个记录
- rows为1010。但还是需要扫描1010条记录。
explain select customer_id from customers where state = 'CA' or points > 1000;
7.1 重写查询以优化查询
- 优化上述查询:
-
重写查询,以尽可能最好的方式利用索引。把查询拆分成两段更小的查询。
-
选择所有位于加州的顾客,和另一个选择了超过1000积分的数据进行联合查询。
-
但第二段points查询,在idx_state_points索引上位于第二列,查询效率也不高。因此要在points列上创建单独的索引。
-
两端查询rows为112+529,比1010少了很多。
create index idx_points on customers(points); explainselect customer_id from customerswhere state = 'CA'unionselect customer_id from customerswhere points > 1000;
-
7.2 将列单独提出
-
想要利用索引,需要单独把列提出来
- 以下两段查询使用的索引不同
- 第一段使用的是index全索引扫描;第二段是range范围扫描。
explain select customer_id from customers where points - 10 > 2010;explain select customer_id from customers where points > 2000;

8. 使用索引排序
-
例子,按顾客所在的州对其进行排序
-- 按使用了索引的列进行排序 explain select customer_id from customers order by state;-- 按没有使用索引的列进行排序 explain select customer_id from customersorder by first_name;结果:第一个type是index,按照state在前的索引进行排序。第二个type为all,进行全表扫描,使用外部排序。


-
基本规则
- order by子句中的列的顺序,应该与索引中列的顺序相同
- 基于两列的复合索引,如A列和B列,可以按A排序、按A和B排序、按A降序和B降序排序。但不能改变顺序,也不能在A和B中间添加一列
9. 覆盖索引
- 覆盖索引:一个包含所有满足查询所需要的数据的索引。通过此索引,MySQL可以在不读取表的情况下就执行查询。
- 先查看where子句,看最常用的列,将其包含在索引中;
- 看order by子句中的列,看是否在索引中能包含这些列;
- 最后看select子句中使用的列,如果也包含了这些列,就会得到一个覆盖索引。
- 得到覆盖索引后,MySQL就可以用索引满足查询。
- 例子:当选择 * 时,使用的是全表扫描
- 在state_points上的复合索引包含了3列,id列、state列和points列。MySQL会自动把主键包括在二级索引中。
explain select * from customersorder by state;
10. 维护索引
- 在创建新索引之前检查现有索引,避免创建重复索引和多余索引。
- 确保删除重复索引、多余索引和未使用的索引。
10.1 重复索引
- 同一组的列且顺序一致的索引,如ABC和ABC
10.2 多余索引
- 在A和B两列上有一个复合索引,再在A上创建另外一个索引,这就会被判定为多余索引。因为原来的索引也可以优化包含列A的查询。
- 在A和B两列上有复合索引的情况下,创建B和A的复合索引或单独创建B的索引是可以的。
相关文章:
【MySQL】索引基础
文章目录 1. 索引介绍2. 创建索引 create index…on…2.1 explain2.2 创建索引create index … on…2.3 删除索引 drop index … on 表名 3. 查看索引 show indexes in …4. 前缀索引4.1 确定最佳前缀长度:索引的选择性 5. 全文索引5.1 创建全文索引 create fulltex…...

精确管理Python项目依赖:自动生成requirements.txt的智能方法
在Python中,可以使用几种方法来自动生成requirements.txt文件。这个文件通常用于列出项目所需的所有依赖包及其版本,使其他人或系统可以轻松地重现相同的环境。下面是几种常见的方法: 使用pip freeze: 这是最常见的方法。pip free…...
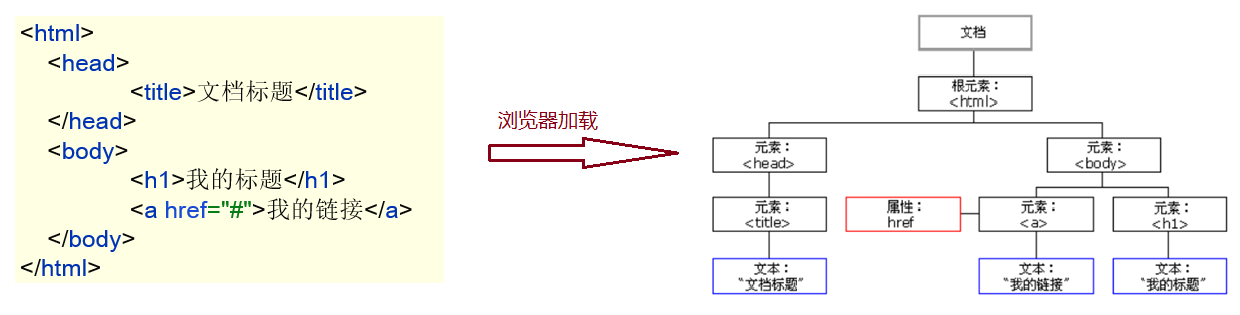
JavaWeb基础(1)- Html与JavaScript(JavaScript基础语法、变量、数据类型、运算符、函数、对象、事件监听、正则表达式)
JavaWeb基础(1)- Html与JavaScript(JavaScript基础语法、变量、数据类型、运算符、函数、对象、事件监听、正则表达式) 文章目录 JavaWeb基础(1)- Html与JavaScript(JavaScript基础语法、变量、数据类型、运算符、函数、对象、事件…...
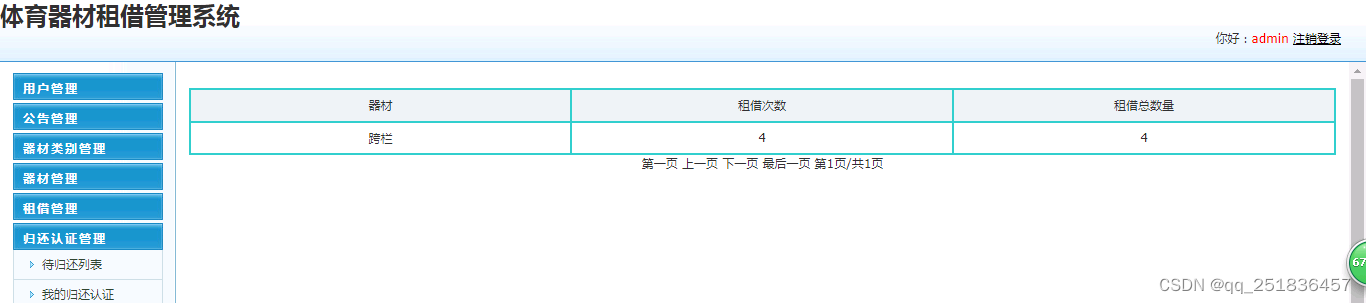
java SSM体育器材租借管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM体育器材租借管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要…...

西电期末1030.函数的最大值
一.题目 二.分析与思路 函数打擂台,注意数据类型和保留精度 三.代码实现 #include<bits/stdc.h>//万能头 double f(double x,double a){return a*x*x-x*x*x; }//f(x) int main() {double a;scanf("%lf",&a);double max-1000001;//打擂台for(…...

在Docker中安装Tomact
目录 前言: 一.安装Tomact 查找指定的tomact版本 下载tomact9.0 查看该镜像是否安装成功 安装成功之后就开始运行镜像了 ps(用于列出正在运行的Docker容器) 编辑 测试(虚拟机ip:8080) 编辑 解决措施 编辑 完成以上步骤&…...

【书生大模型00--开源体系介绍】
书生大模型开源体系介绍 0 通用人工智能1 InternLM性能及模型2 从模型到应用 大模型成为目前很热的关键词,最热门的研究方向,热门的应用;ChatGPT的横空出世所引爆,快速被人们上手应用到各领域; 0 通用人工智能 相信使…...

基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理
文章目录 一、内容简介二、前言2.1 Transformer 模型标志着AI 新时代的开始2.2 Transformer 架构具有革命性和颠覆性2.3 Google BERT 和OpenAI GPT-3 等Transformer 模型将AI 提升到另一个层次2.4 本书将带给你的“芝士”2.5 本书面向的读者 三、本书内容简介3.1 第一章3.2 第二…...

一款开源的MES系统
随着工业4.0的快速发展,制造执行系统(MES)成为了智能制造的核心。今天,将为大家推荐一款开源的MES系统——iMES工厂管家。 什么是iMES工厂管家 iMES工厂管家是一款专为中小型制造企业打造的开源MES系统。它具备高度的可定制性和灵…...
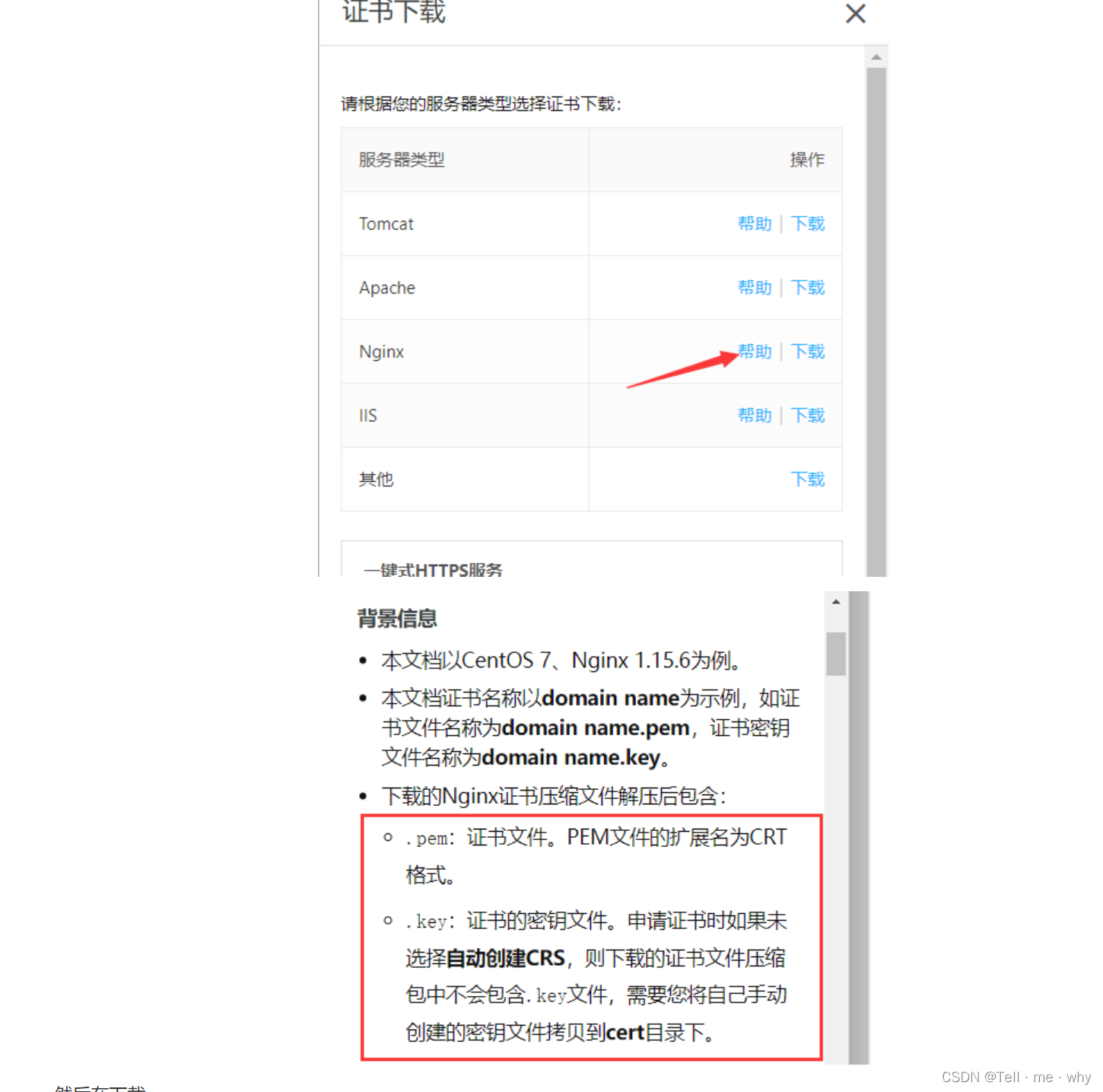
https配置证书
HTTPS 基本原理 https 介绍 HTTPS(全称:HyperText Transfer Protocol over Secure Socket Layer),其实 HTTPS 并不是一个新鲜协议,Google 很早就开始启用了,初衷是为了保证数据安全。 国内外的大型互联网…...
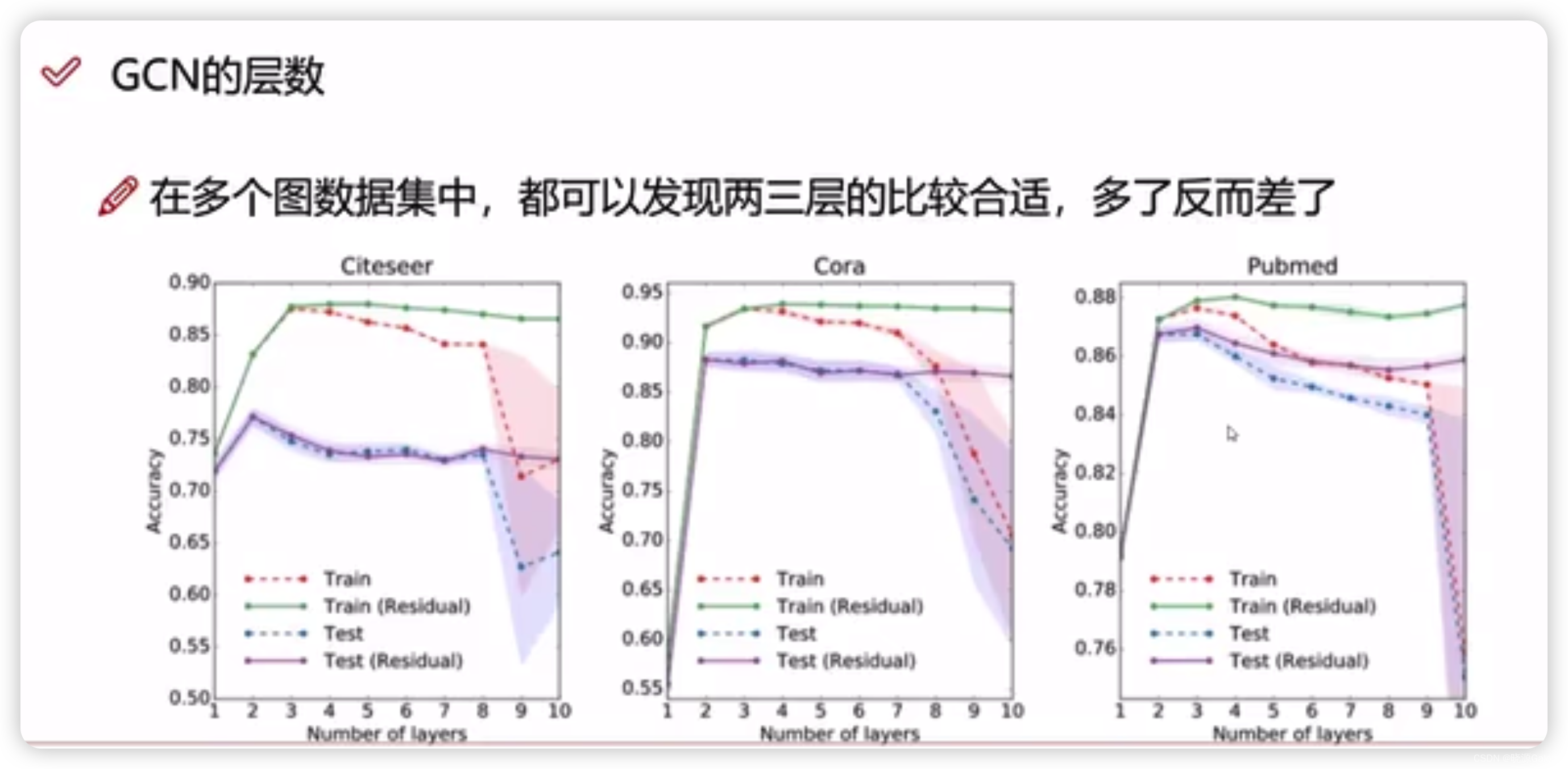
图神经网络|10.4 GCN 变换原理的解读
由9.3-邻接矩阵的变换可知,理解矩阵通过两个度矩阵的逆进行归一化。 微观上看, a i j a_{ij} aij这个元素将会乘上 1 d e g ( v i ) d e g ( v j ) \frac{1}{\sqrt{deg_(v_i)\sqrt{deg(v_j)}}} deg(vi)deg(vj) 1 其现实意义如下—— 比如…...
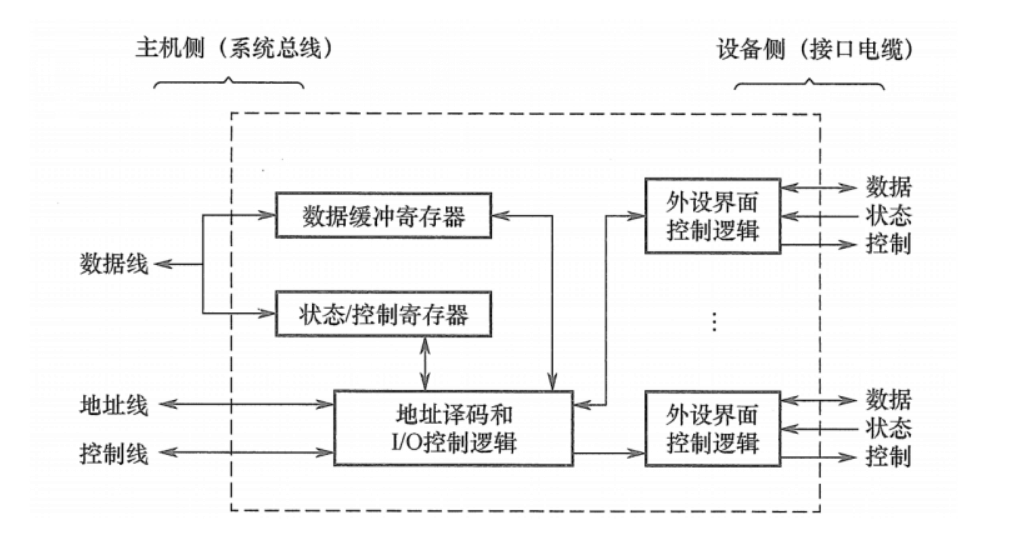
计算机组成原理 I/O方式
I/O 方式 I/O方式分类: 程序查询方式。由 CPU通过程序不断查询 /O 设备是否已做好准备,从而控制0 设备与主机交换信息程序中断方式。只在 I/0 设备准备就绪并向 CPU发出中断请求时才予以响应。DMA方式。主存和 I/O 设备之间有一条直接数据通路,当主存和…...
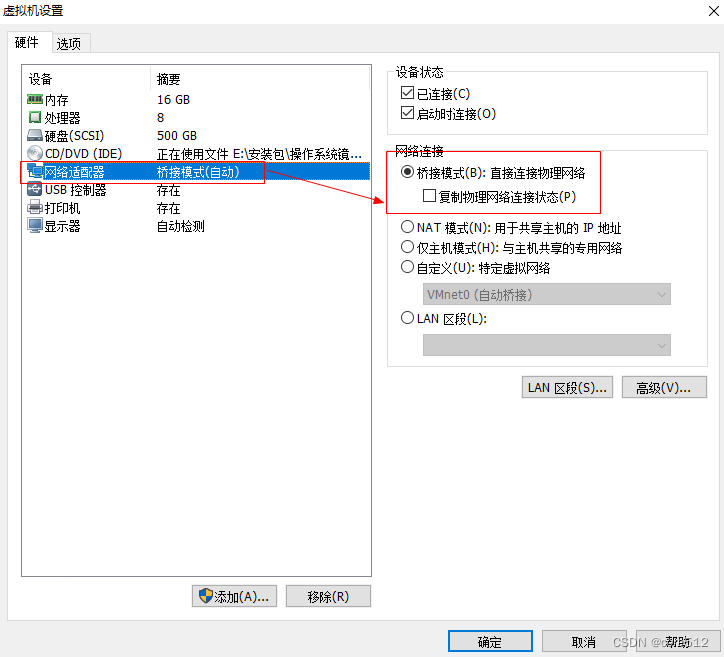
VMWare网络配置
1、通用配置 选择自动,相对与选择指定网卡,能解决网卡更换导致网络不可用的问题。 2、每个虚拟机配置...
opencv期末练习题(3)附带解析
创建黑色画板,并支持两种画图功能 import mathimport cv2 import numpy as np """ 1. 创建一个黑色画板 2. 输入q退出 3. 输入m切换画图模式两种模式,画矩形和画圆形。用户按住鼠标左键到一个位置然后释放就可以画出对应的图像 "&qu…...
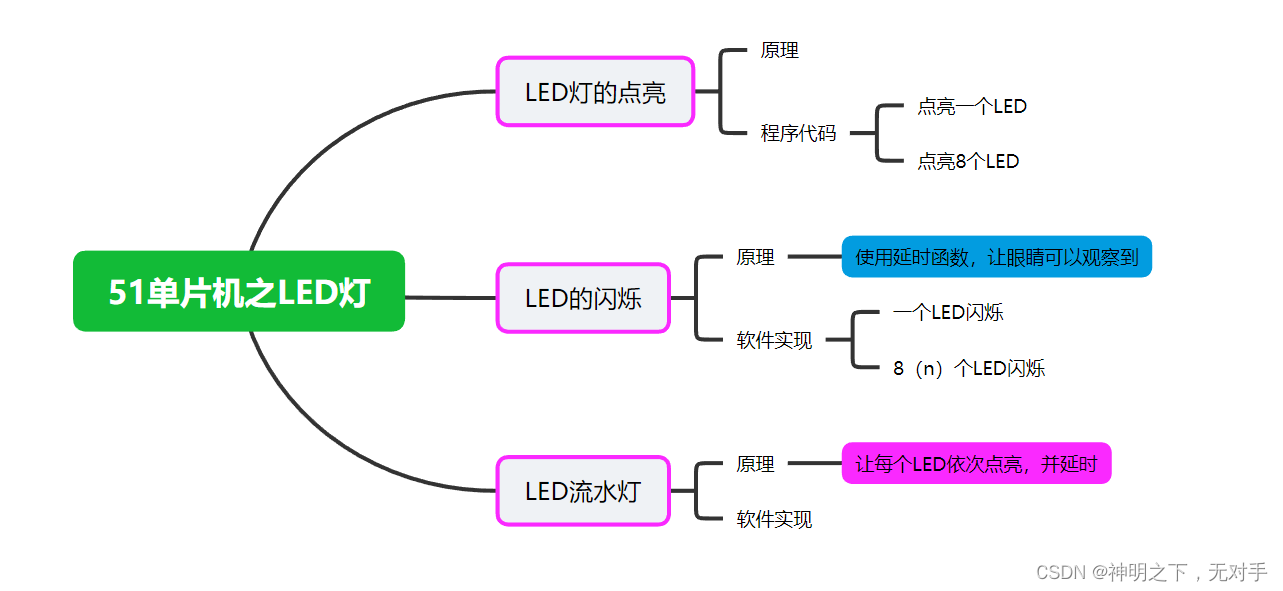
51单片机之LED灯
51单片机之LED灯 🌴前言:🏮点亮LED灯的原理💘点亮你的第一个LED灯💘点亮你的八个LED灯 📌让LED灯闪烁的原理🎽 LED灯的闪烁🏓错误示范1🏓正确的LED闪烁代码应该是这样&am…...

操作系统内存碎片
大家好,我叫徐锦桐,个人博客地址为www.xujintong.com,github地址为https://github.com/jintongxu。平时记录一下学习计算机过程中获取的知识,还有日常折腾的经验,欢迎大家访问。 一、前言 内存碎片是指无法被利用的内…...

三菱plc学习入门(二,三菱plc指令,触点比较,计数器,交替,四则运算,转换数据类型)
今天,进行总结对plc的学习,下面是对plc基础的学习,希望对读者有帮助,欢迎点赞,评论,收藏!!! 目录 触点比较 当数据太大了的时候(LDD32位) CMP比…...

Spring学习之——代理模式
Proxy代理模式 介绍 为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用 2. 组成 抽象角色:通过接口或抽象类声明真实角色实现的…...

【Linux】之搭建 PostgreSQL 环境
前言 在 Linux 系统下安装 PostgreSQL,可以选择快捷方便的 Docker 安装,但正常的服务器都是直接原生安装的,所以,这里我将讲解如何正常安装 PostgreSQL 以及安装之后的一些配置。如果想了解 Docker 安装的话,可以查看我…...
docker 安装elasticsearch、kibana、cerebro、logstash
安装步骤 第一步安装 docker 第二步 拉取elasticsearch、kibana、cerebro、logstash 镜像 docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.2 docker pull docker.elastic.co/kibana/kibana:7.10.2 docker pull lmenezes/cerebro:latest docker pull l…...

如何利用QGIS 3.22为机器学习任务高效构建遥感影像切片数据集
1. 为什么需要QGIS处理遥感影像数据 做机器学习项目时,最头疼的就是数据准备环节。特别是处理遥感影像这种"庞然大物",动辄几个GB的高分辨率图像,直接用Python脚本处理不仅效率低,还容易内存溢出。去年我做城市绿地识别…...

基于MCP协议构建Python文档智能查询服务器,提升AI编程助手准确性
1. 项目概述:一个为Python开发者量身定制的文档智能助手如果你和我一样,每天大部分时间都在和Python代码打交道,那你肯定也经历过这样的场景:为了查一个函数的参数顺序,或者确认某个库的版本兼容性,不得不频…...

Newhaven 5.0英寸TFT显示屏技术解析与应用指南
1. Newhaven 5.0英寸TFT显示屏核心特性解析 1.1 3M增强膜技术解析 这款5.0英寸TFT显示屏最显著的技术亮点在于采用了3M专利的增强膜技术。在实际应用中,我发现这种增强膜通过特殊的光学结构设计,能够有效提升背光利用率。具体来说,它采用了多…...

Spread.NET 10-19.1 都可以提供
关于 Spread.NET提供类似 Excel 的电子表格体验。Spread.NET 可帮助您创建电子表格、网格、仪表板和窗体。它包含一个强大的计算引擎,提供 450 多个函数,并支持导入和导出 Excel 电子表格。利用丰富的 .NET 电子表格 API 和强大的计算引擎,您…...

隔热型防火入户门 烟气阻隔密封构造原理
在高层住宅建筑消防设计体系中,防火入户门是分隔防火分区、阻断烟火蔓延的核心构件,其中隔热型防火入户门凭借优异的耐火性能与烟气阻隔能力,成为民用住宅工程的标配产品,其密封构造设计直接决定防火隔烟效果与消防验收合规性。隔…...

260513实训:路由器连接
路由器工作原理: 转发动作:路由器收到数据后,根据目的IP地址查路由器路由表(地图)转发 路由表:路由器默认会将直连网段加入路由表 查看IP路由表:display ip routing-table 127.0.0.0/8 本地环…...

大功率充电桩生产厂家:高效能产品的选择与评估标准
一、行业背景与权威数据据中国电动汽车充电基础设施促进联盟(EVCIPA)数据显示,截至2026年2月底,我国电动汽车充电基础设施(枪)总数达到2101.0万个,同比增长47.8%。其中,公共充电设施…...

运放噪声深度解析:从原理到工程实践的计算与优化
1. 项目概述:为什么我们需要关心运放的噪声?如果你曾经调试过一个高精度的信号调理电路,比如一个微弱的传感器信号放大链路,或者一个高分辨率的ADC前端,你大概率遇到过这样的场景:理论上,你的电…...

用STM32 HAL库和MPU6050 DIY平衡小车:PID参数整定实战与小车‘站起来’的调试日记
STM32平衡小车PID调参实战:从剧烈抖动到稳定站立的调试手记 1. 平衡小车的核心挑战 当我第一次按下电源开关,看着这个小家伙像醉汉一样左右摇摆然后轰然倒下时,才真正理解到平衡控制的精妙之处。基于STM32和MPU6050的平衡小车项目,…...

如何快速掌握音频频谱分析:Spek开源工具完整指南
如何快速掌握音频频谱分析:Spek开源工具完整指南 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek 想要深入了解音频文件的内部结构吗?Spek音频频谱分析器是你的理想选择!这款免费…...