docker 安装elasticsearch、kibana、cerebro、logstash
安装步骤
第一步安装 docker
第二步 拉取elasticsearch、kibana、cerebro、logstash 镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.2
docker pull docker.elastic.co/kibana/kibana:7.10.2
docker pull lmenezes/cerebro:latest
docker pull logstash:7.5.1第三步、创建 容器
创建elasticsearch 容器
docker run -itd --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.2
该命令会创建一个名为 elasticsearch 的容器,并将主机的 9200 端口与容器内部的 9200 端口关联起来。同时设置 discovery.type 参数为 single-node,表示单节点模式。
可能出现的问题
问题一
Docker容器启动时报错ERROR: for elasticsearch Cannot start service elasticsearch: driver failed programm.
错误原因:
docker服务启动时定义的自定义链docker,由于centos7 firewall 被清掉
firewall的底层是使用iptables进行数据过滤,建立在iptables之上,这可能会与 Docker 产生冲突。 当
firewalld 启动或者重启的时候,将会从 iptables 中移除 docker的规则,从而影响了 Docker 的正常工作。
当你使用的是 systemd 的时候, firewalld 会在 Docker 之前启动,但是如果你在 Docker 启动之后再启动
或者重启 firewalld ,你就需要重启 Docker 进程了。 重启docker服务及可重新生成自定义链docker。
解决方法:
使用systemd关闭firewalld 之后要重启docker 重启docker服务后再启动容器
systemctl restart docker
创建kibana容器
- 首先运行kibana容器
docker run --name kibana -d -p 5601:5601 docker.elastic.co/kibana/kibana:7.10.2
- 然后copy kibana 的配置文件 到宿主机,修改kibana 的零配置文件kibana.yml 修改kibana连接的elasticsearch 连接地址配置
docker cp kibana:/usr/share/kibana /home/test

- 重启 kibana 容器
使用数据卷方式重新挂载 kibana 的配置目录文件,重启kibana 容器
docker run --name kibana -itd -p 5601:5601 -v /home/test/kibana/config:/usr/share/kibana/config docker.elastic.co/kibana/kibana:7.10.2
-
可能遇到的问题
kibana解决Kibana server is not ready yet问题- 第一种
将配置文件kibana.yml中的elasticsearch.url改为正确的链接,默认为: http://elasticsearch:9200,改为http://自己的IP地址:9200
- 第一种
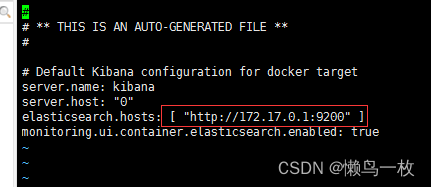
我这里是将原本的elasticsearch改成了docker内部的IP,查看docker内部的IP命令如下
ip address
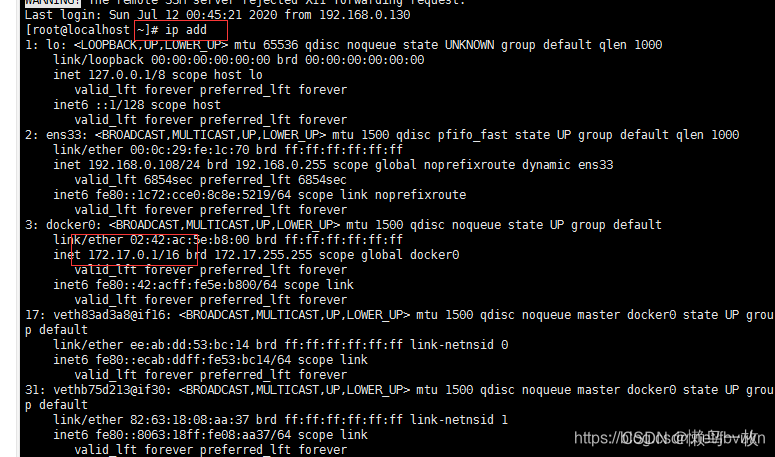
- 第二种
如果上面的配置都没有问题的话,可能是因为防火墙的问题,我们需要把防火墙关掉(我就是这么解决的)
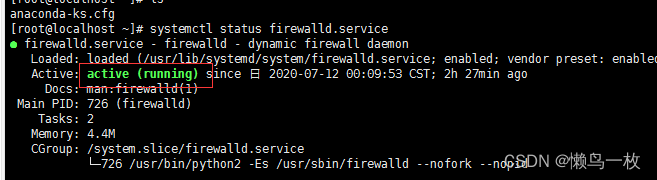
- 查看防火墙状态
systemctl status firewalld.service
如果结果显示为图中这样,则防火墙是启动了的
接下来需要关闭防火墙,关闭之后再查看防火墙状态
systemctl stop firewalld.service
systemctl status firewalld.service
这样就是显示,就表明防火墙已经关闭

kibana 教程、界面和相关操作
https://www.cnblogs.com/jthr/p/17415787.html
创建cerebro 容器
docker run --name cerebro -itd -p 9000:9000 lmenezes/cerebro
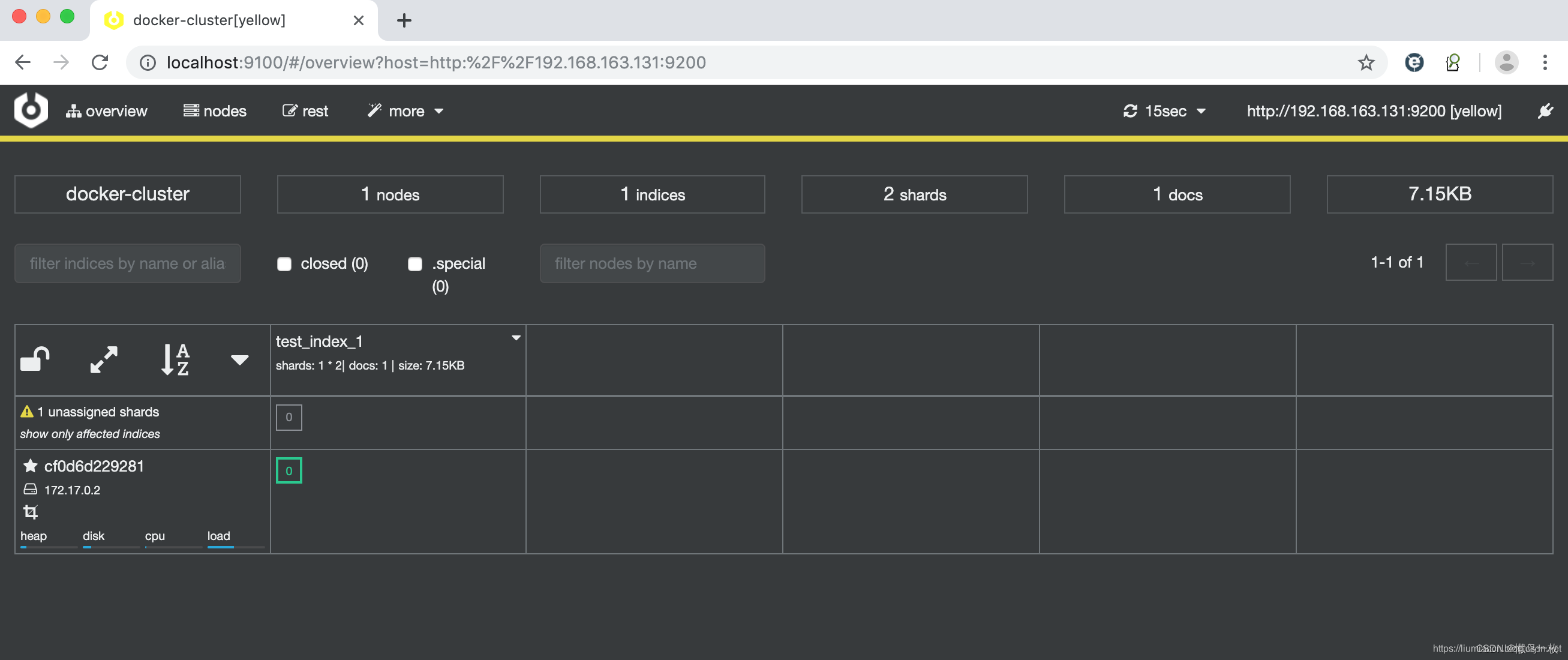
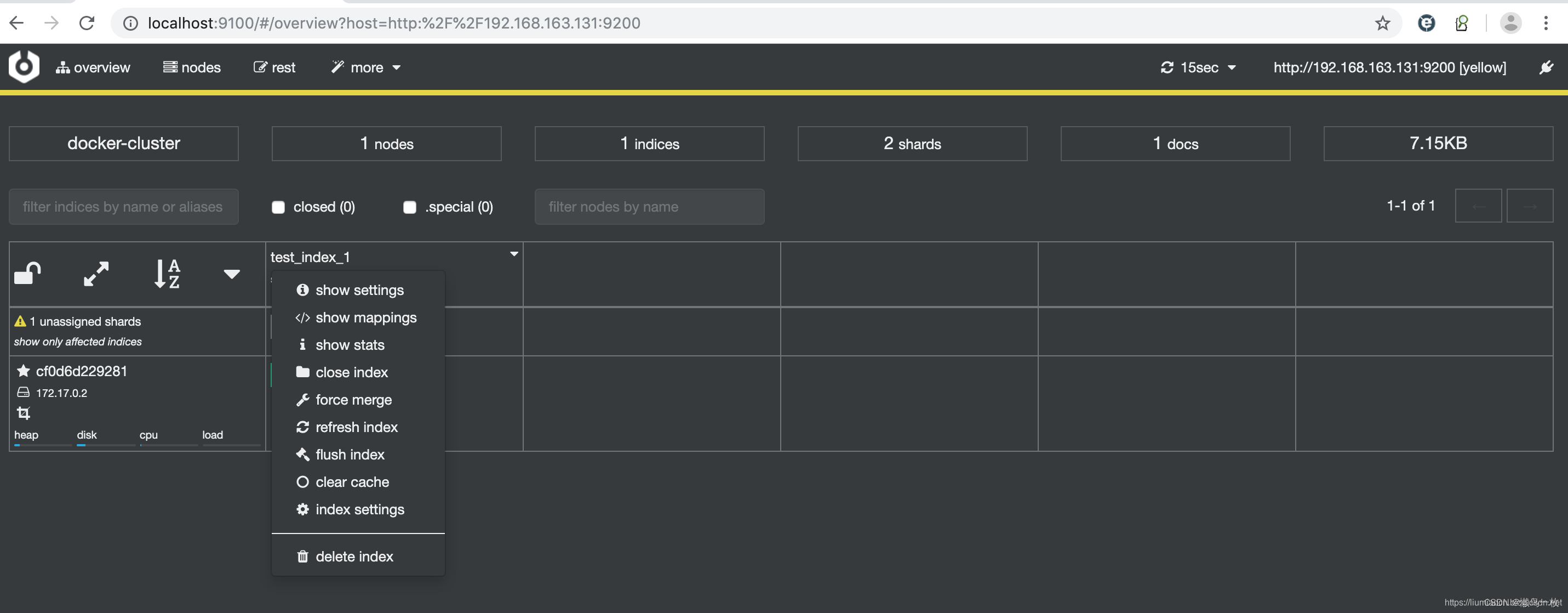
cerebro 的默认端口是9000 ,创建成功后,就可以通过http://localhost:9000/ 进行访问

只需要输入ElasticSearch的URL并点击connect按钮,成功连接即可显示如下图所示信息。需要注意的是由于cerebro运行在容器中,直接输入localhost:9200即使通过浏览器能够访问也可能无法连接,需要保证的是在cerebro的容器中能够访问到的URL,比如这里使用的本机的IP
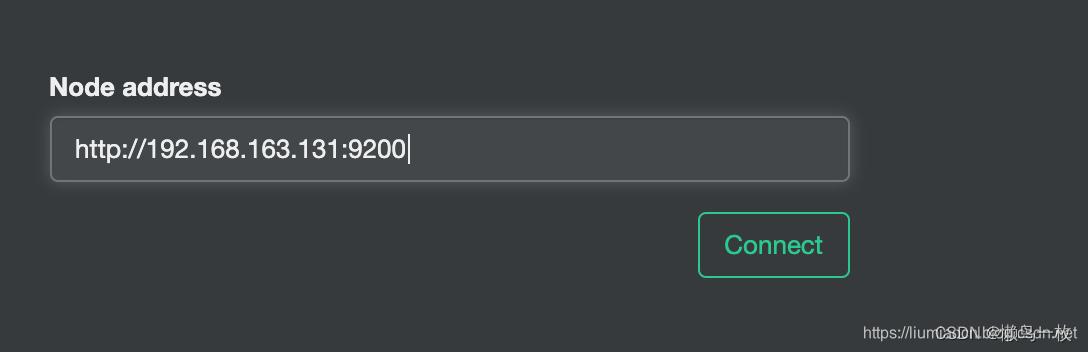
点击Connect按钮即可连接成功
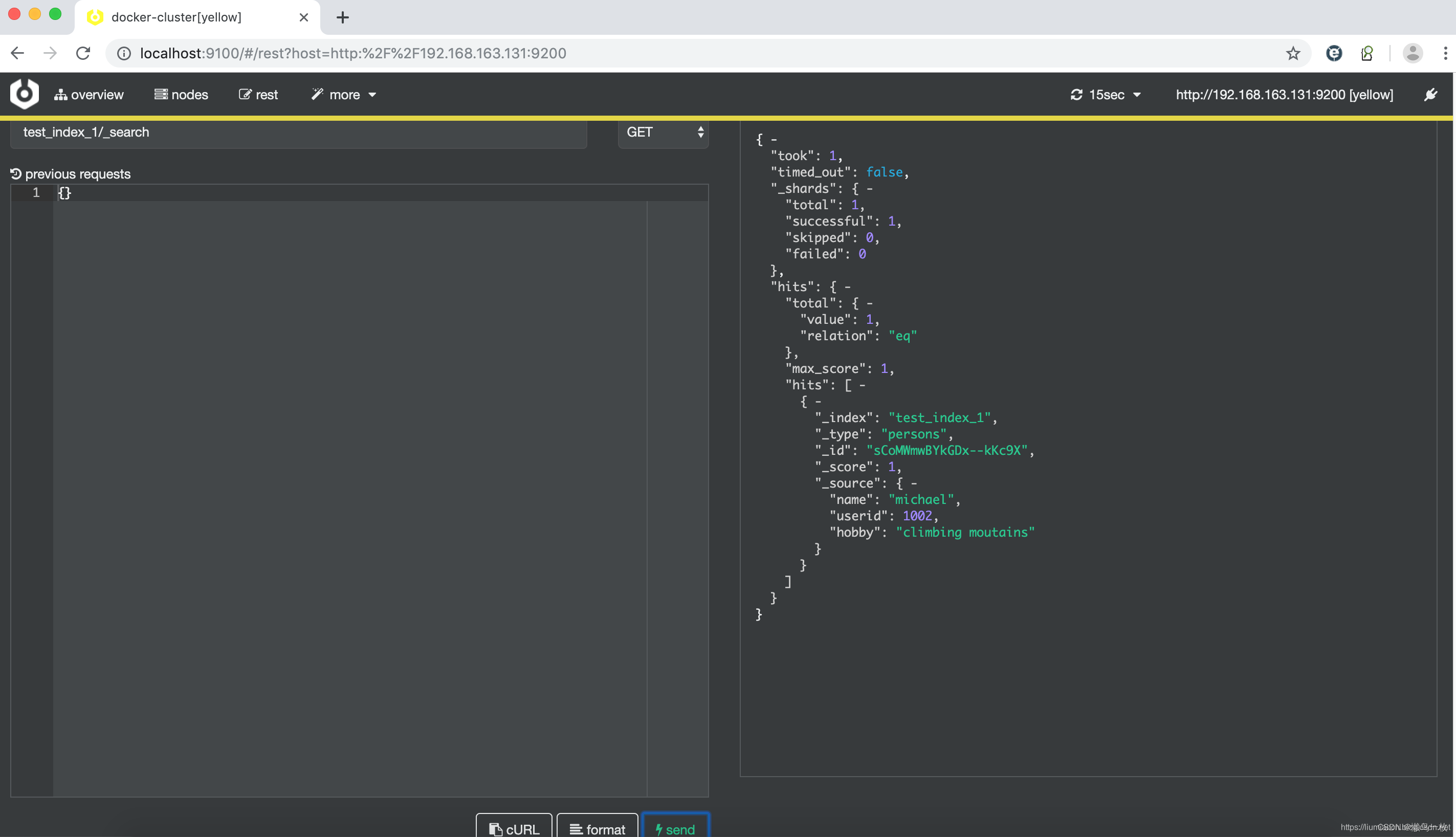
如果需要执行相应的API操作,比如查询,可直接在界面进行操作,比如
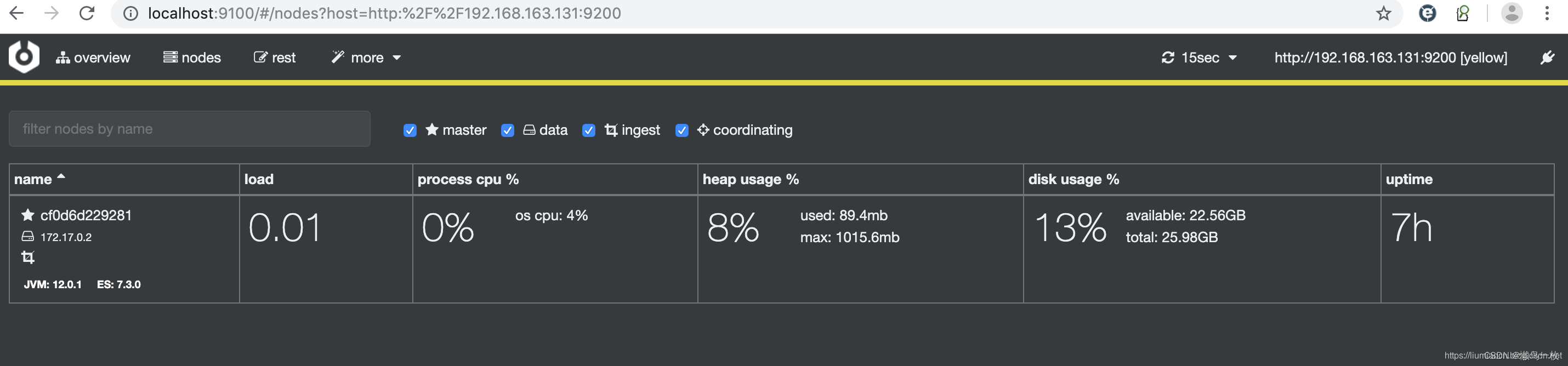
另外还可以确认节点相关的统计信息
很多操作都可以通过页面进行
总结
相较于elasticsearch-head,界面美感较好,功能也在不断更新,建议使用
cerebro 界面、操作教程
https://blog.csdn.net/liumiaocn/article/details/98517815
创建logstash 容器
参考 https://blog.csdn.net/baoshuowl/article/details/114928281
- 启动logstash 容器
docker run -itd --name=logstash logstash:7.5.1
- copy logstash的容器配置文件至 宿主机
docker cp logstash:/usr/share/logstash /home/test
- 修改 logstash 关联的elstaicSearch地址
logstash.yml
- 下载movielens 测试数据集
下载最MovieLens最小测试数据集:https://grouplens.org/datasets/movielens/
参开博客:https://blog.csdn.net/baoshuowl/article/details/114928281
- 准备 logstash.conf配置文件
https://gitee.com/geektime-geekbang/geektime-ELK/tree/master/part-1/2.4-Logstash%E5%AE%89%E8%A3%85%E4%B8%8E%E5%AF%BC%E5%85%A5%E6%95%B0%E6%8D%AE/movielens
logstash.conf
input {file {path => "/Users/yiruan/dev/elk7/logstash-7.0.1/bin/movies.csv"start_position => "beginning"sincedb_path => "/dev/null"}
}
filter {csv {separator => ","columns => ["id","content","genre"]}mutate {split => { "genre" => "|" }remove_field => ["path", "host","@timestamp","message"]}mutate {split => ["content", "("]add_field => { "title" => "%{[content][0]}"}add_field => { "year" => "%{[content][1]}"}}mutate {convert => {"year" => "integer"}strip => ["title"]remove_field => ["path", "host","@timestamp","message","content"]}}
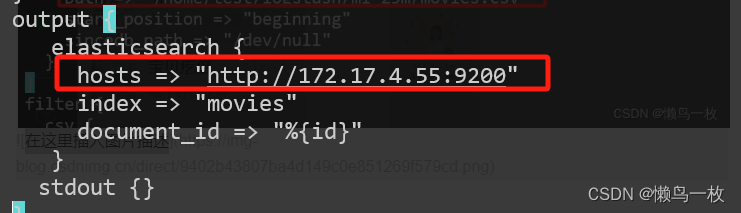
output {elasticsearch {hosts => "http://localhost:9200"index => "movies"document_id => "%{id}"}stdout {}
}
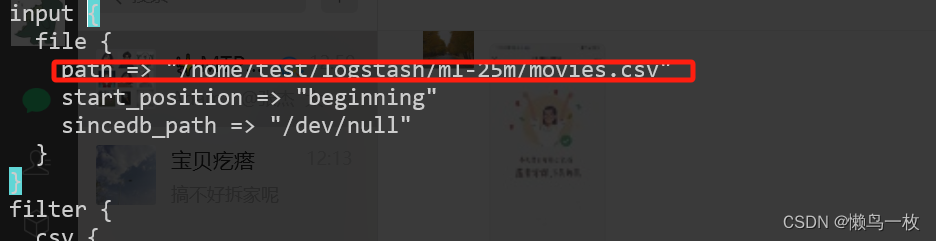
修改导入的测试数据movies.csv 路径和 logstash 输出 elstaicSearch的地址
6. 在 logstash/bin 目录下运行一下命令
sudo ./logstash -f logstash.conf
在copy出来的logstash 配置文件下bin 目录下执行,导入测试数据
./logstash -f logstash.conf

以下为输出信息

如果没有出现这个则数据导入有问题
在docker 容器内操作文件没有权限则需要指定 登录容器内部时候的root 用户
docker exec -ited --user=root logstash bash
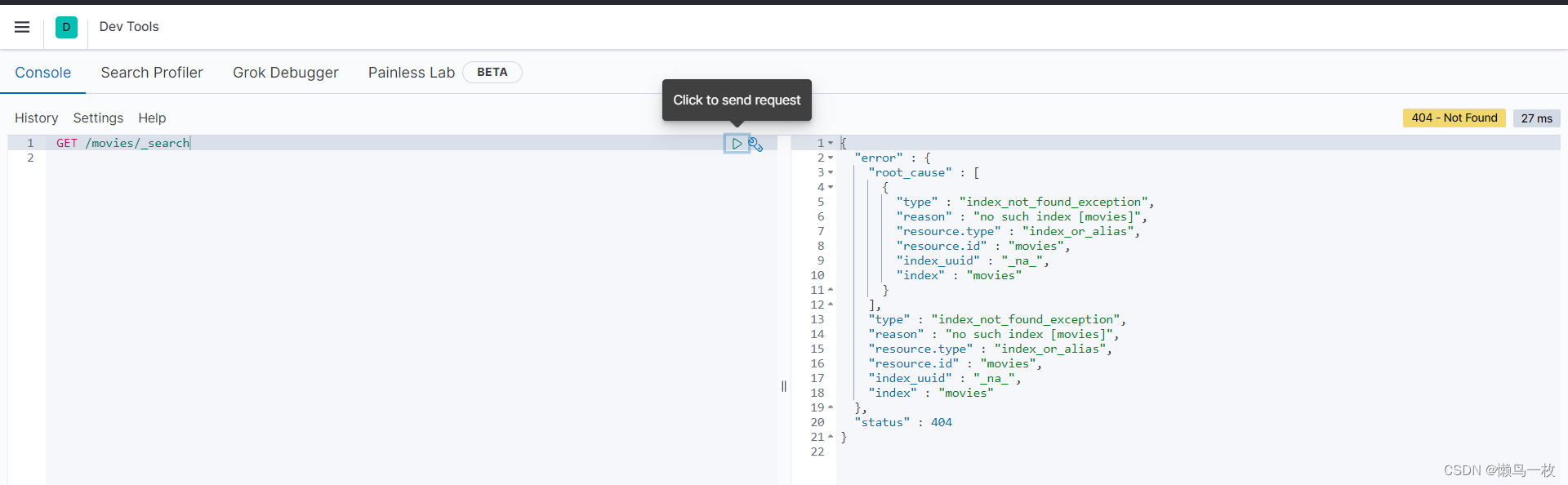
- 在kibana的dev Tool 中查看导入的测试数据
查看已经导入的数据
打开 Kibana 的 Dev Tools 并输入 GET /movies/_search
GET /movies/_search
可以看到下载的测试数据集中的数据已经全部倒入 Elasticsearch 中
相关文章:
docker 安装elasticsearch、kibana、cerebro、logstash
安装步骤 第一步安装 docker 第二步 拉取elasticsearch、kibana、cerebro、logstash 镜像 docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.2 docker pull docker.elastic.co/kibana/kibana:7.10.2 docker pull lmenezes/cerebro:latest docker pull l…...
C/C++ 联合体
目录 联合体概述 联合体的内存分配 联合体大小计算 联合体概述 联合与结构非常的相似,主要区别就在于联合这两个字。 联合的特征:联合体所包含的成员变量使用的是同一块空间。 联合体定义 //联合类型的声明 union Un {char c;int i; }; //联合变量…...
基于SSM的基金投资交易管理网站的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...

JS数据类型转换成Boolean型
在javaScript中 布尔值用到的很频繁 接下来让我稍微为大家介绍一下数据类型转换为布尔型 转换成布尔值为false的类型 console.log(Boolean("")) //falseconsole.log(Boolean(0)) //falseconsole.log(Boolean(undefined)) //falseconsole.log(Boolean(null)) //false…...

uni-app页面数据传参方式
uni-app 是一个使用 Vue.js 开发所有前端应用的框架,可以编译到 iOS、Android、H5、小程序等多个平台。当你在多个页面间传递参数时,通常有多种方法,例如通过 uni.navigateTo、路由参数、本地存储等方式。下面是一些方法的说明和示例代码。 …...
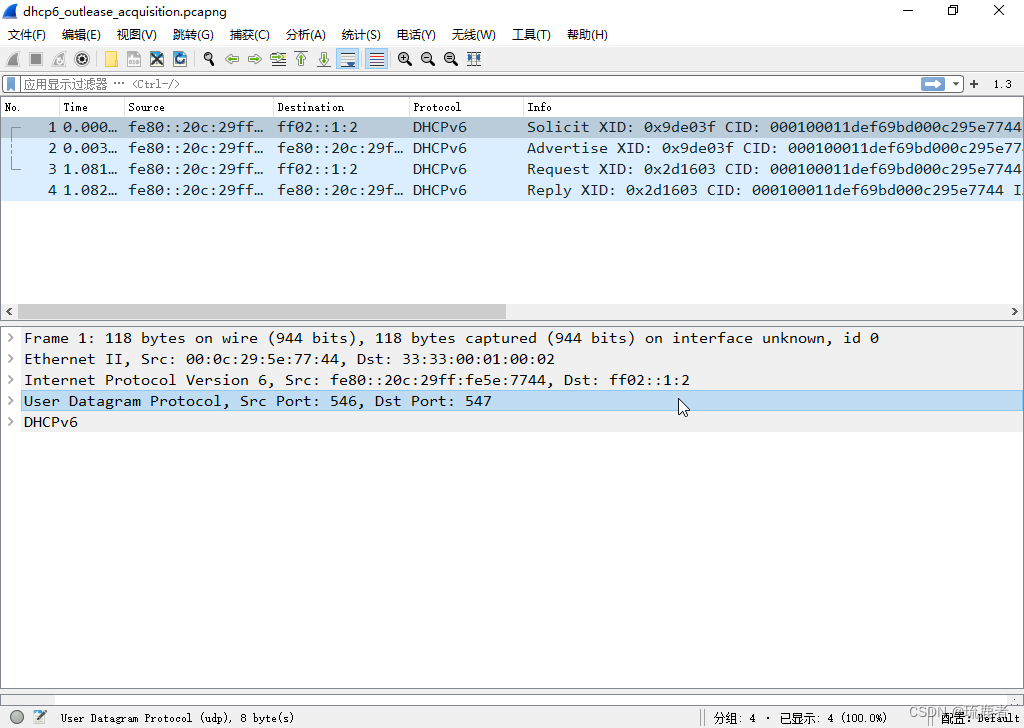
计算机网络实验(二):Wireshark网络协议分析
一、实验名称:Wireshark网络协议分析 二、实验原理 HTTP协议分析 1.超文本传输协议(Hypertext Transfer Protocol, HTTP)是万维网(World Wide Web)的传输机制,允许浏览器通过连接Web服务器浏览网页。目…...
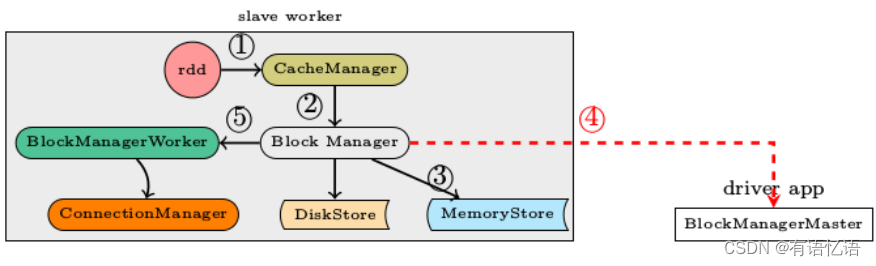
Spark内核解析-数据存储5(六)
1、Spark的数据存储 Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数据读取为例,讲述清楚存储子系统中各部件的交互关系。 1.1存储子系统概览 …...

ASP.NET Core高级之认证与授权(一)--JWT入门-颁发、验证令牌
阅读本文你的收获 了解认证和授权的作用了解在ASP.NET Core中实现身份认证的技术都有哪些学习基于JWT认证并学会颁发和验证JWT令牌 一、重要的前置概念 在一个系统中,不是所有的功能和资源都能够被自由地访问,比如你存在银行系统里面的资金,…...

实例:NodeJS 操作 Kafka
本人是C#出身的程序员,c#很简单就能实现,有需要的可以加我私聊。但是就目前流行的开发语言,尤其是面向web方向应用的,我感觉就是Nodejs最简单了。下面介绍: 本文将会介绍在windows环境下启动Kafka,并通过n…...

AI实景无人直播创业项目:开启自动直播新时代,一部手机即可实现增长
在当今社会,直播已经成为了人们日常生活中不可或缺的一部分。无论是商家推广产品、明星互动粉丝还是普通人分享生活,直播已经渗透到了各行各业。然而,传统直播方式存在着一些不足之处,如需现场主持人操作、高昂的费用等。近年来&a…...

YOLOv5改进 | 损失函数篇 | InnerIoU、InnerSIoU、InnerWIoU、FocusIoU等损失函数
一、本文介绍 本文给大家带来的是YOLOv5最新改进,为大家带来最近新提出的InnerIoU的内容同时用Inner的思想结合SIoU、WIoU、GIoU、DIoU、EIOU、CIoU等损失函数,形成 InnerIoU、InnerSIoU、InnerWIoU等新版本损失函数,同时还结合了Focus和AIpha思想,形成的新的损失函数,其…...
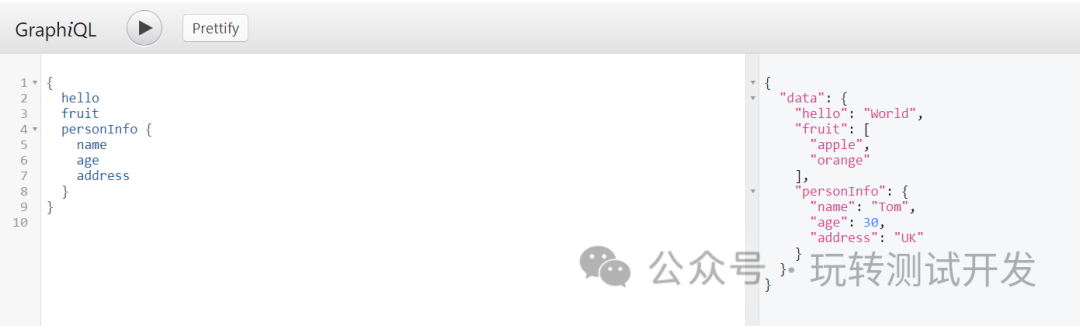
构建高效PythonWeb:GraphQL+Sanic
1.1 简介:在当今快速发展的技术时代,Web应用的性能和灵活性变得越来越重要。在众多技术中,GraphQL和Sanic以其独特的优势脱颖而出。GraphQL,作为一个强大的数据查询语言,为前端和后端之间的通信提供了极大的灵活性。而…...
-- 模型的微调【全参数微调】【LoRA方法】【Q-LoRA方法】)
【通义千问】大模型Qwen GitHub开源工程学习笔记(5)-- 模型的微调【全参数微调】【LoRA方法】【Q-LoRA方法】
摘要: 训练数据的准备 你需要将所有样本放到一个列表中并存入json文件中。每个样本对应一个字典,包含id和conversation,其中后者为一个列表。示例如下所示: [{"id": "identity_0","conversations": [{"from": "user",…...

PCL 大地坐标转空间直角坐标(C++详细过程版)
目录 一、算法原理二、代码实现三、结果展示四、测试数据本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT生成的文章。 一、算法原理 二、代码实现 头文件及读取保存函数见:PCL 空间直角坐标转大地坐标(直接求解法C…...

Linux之Shell编程
shell是什么 shell是一个命令行解释器,他为用户提供一个向linux内核发送请求以便运行程序的界面系统级程序,用户可以用shell来启动,挂起,停止甚至编写一些程序。 shell脚本的执行方式 脚本格式要求 脚本以#!/bin/bash开头脚本需…...

Unity组件开发--传送点
本组件仅实现A传送点到B传送的功能,是可以双向传送的,如果只要单向传送,可以另外改脚本实现; 先看效果: unity组件传送点演示 1.传送组件shader是怎么写的:这种效果的实现方案 shader编辑器是这样的&#…...

vue结合Cesium加载gltf模型
Cesium支持什么格式? Cesium支持的格式包括:3D模型格式(如COLLADA、gITF、OBJ)、影像格式(如JPEG、PNG、GeoTIFF)、地形格式(如STL、Heightmap)、矢量数据格式(如GeoJSON…...
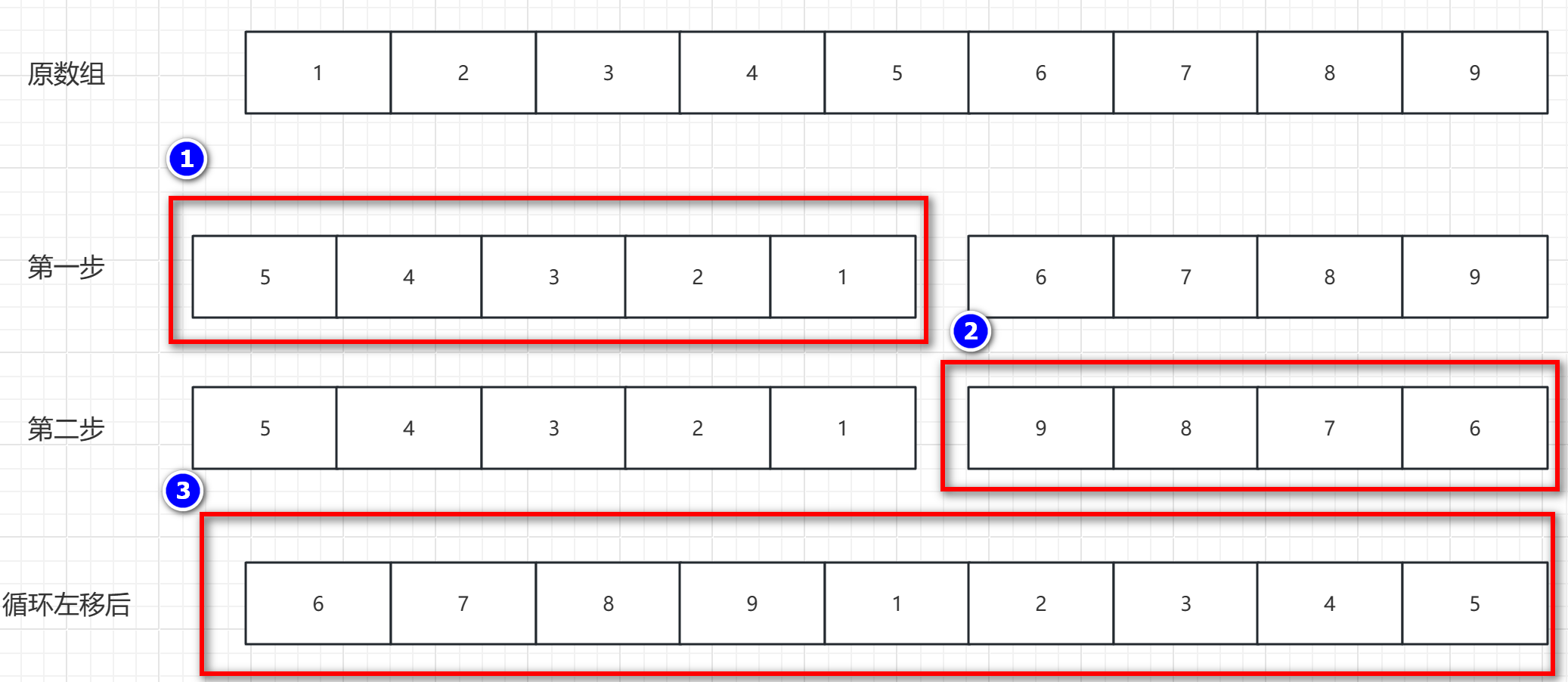
逆置算法和数组循环移动算法
元素逆置 概述:其实就是将 第一个元素和最后一个元素交换,第二个元素和倒数第二个元素交换,依次到中间位置。用途:可用于数组的移动,字符串反转,链表反转操作,栈和队列反转等操作。 逆置图解 …...

【MATLAB】数豆子
Matlab数豆子 创建一个变量来表示豆子的数量。例如,可以使用豆子数量 100;来表示有100颗豆子。 使用disp函数打印出豆子的数量。例如,可以使用disp([目前有 num2str(豆子数量) 颗豆子])来打印出当前豆子的数量。 进行豆子的计数操作。例如,…...

QT C++中调用python脚本时,import第三方库失败问题解决
QT C中调用python脚本时,import第三方库失败问题解决 文章目录 QT C中调用python脚本时,import第三方库失败问题解决前言一、问题复现二、调试过程三、问题解决1 numpy问题解决2 matplotlib问题解决 四、补充说明五、参考资料 前言 项目需要,…...
)
别再纠结了!手把手教你根据项目需求选对Intel Realsense型号(D455/D435i/D415/T265实战对比)
深度视觉硬件选型指南:Intel RealSense全系型号实战解析 在计算机视觉和机器人领域,选择合适的3D感知硬件往往决定了项目成败。面对Intel RealSense系列中D455、D435i、D415和T265等不同型号,许多开发者常陷入"参数对比陷阱"——过…...

LeetCode 118. 杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。在「杨辉三角」中,每个数是它左上方和右上方的数的和。示例 1:输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]示例 2:输入: numRows 1 输出: [[1]]提示:1 < numRows…...

HoRain云--Lua协程
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...

命令行与IM桥接工具:适配器模式实现统一消息通知
1. 项目概述与核心价值最近在折腾一个挺有意思的东西,一个叫tmwgsicp/im-cli-bridge的项目。光看这个名字,可能有点摸不着头脑,我来拆解一下。tmwgsicp大概率是作者的用户名或者组织名,im-cli-bridge才是核心。im是即时通讯&#…...

基于reflectt-node的WebSocket RPC实践:构建实时协作待办应用
1. 项目概述与核心价值 最近在折腾一个需要实时双向通信的Web应用,传统的轮询和长轮询方案在性能和资源消耗上总感觉差那么点意思。后来把目光投向了WebSocket,但原生WebSocket的API相对底层,自己管理连接、心跳、重连、消息序列化这些琐事&a…...

mmdetection环境搭建避坑指南:从CUDA版本、pip源到Gitee镜像的全流程优化
MMDetection环境搭建全流程优化:从版本匹配到镜像加速的实战指南 在计算机视觉领域,OpenMMLab系列工具包已经成为许多研究者和开发者的首选。作为其中的核心检测库,MMDetection凭借其模块化设计和丰富的预训练模型,极大地简化了目…...

auto-rednote:自动化信息整理工具的设计原理与实战应用
1. 项目概述与核心价值 最近在整理个人笔记和知识库时,我遇到了一个几乎所有内容创作者和开发者都会头疼的问题:如何高效地将散落在各处的、格式不一的“红色笔记”(比如微信收藏、网页剪藏、临时备忘录)自动整理成结构化的、可检…...

FABRK全栈框架:模块化设计与AI辅助开发实战解析
1. 项目概述:一个为AI时代而生的全栈开发框架如果你和我一样,在过去几年里反复搭建过各种SaaS应用、管理后台或者数据看板,你一定会对那种重复劳动感到厌倦。每次新项目启动,都要重新配置身份验证、集成支付、设计仪表盘组件、处理…...

Python代码格式化终极指南:使用YAPF从混乱到优雅的蜕变案例 [特殊字符]
Python代码格式化终极指南:使用YAPF从混乱到优雅的蜕变案例 🚀 【免费下载链接】yapf A formatter for Python files 项目地址: https://gitcode.com/gh_mirrors/ya/yapf YAPF(Yet Another Python Formatter)是一款强大的P…...

基于Telegram的AI聊天机器人SirChatalot部署与多模态功能配置指南
1. 项目概述:打造你的专属AI骑士 如果你厌倦了那些功能单一、反应迟钝的聊天机器人,想拥有一个既能深度对话、又能看图说话、甚至能帮你搜索网页和生成图片的“全能型”AI伙伴,那么 SirChatalot 这个项目绝对值得你投入时间。它本质上是一个…...