Large Language Models Paper 分享
论文1: ChatGPT's One-year Anniversary: Are Open-Source Large Language Models Catching up?
简介
2022年11月,OpenAI发布了ChatGPT,这一事件在AI社区甚至全世界引起了轰动。首次,一个基于应用的AI聊天机器人能够提供有帮助、安全和有用的答案,遵循人类指令,甚至承认并纠正之前的错误。作为第一个这样的应用,ChatGPT在其推出仅两个月内,用户数量就达到了1亿,远远快于其他流行应用如TikTok或YouTube。因此,它也吸引了巨额的商业投资,因为它有望降低劳动成本,自动化工作流程,甚至为客户带来新的体验。
但ChatGPT的闭源特性可能引发诸多问题。首先,由于不了解内部细节,比如预训练和微调过程,很难正确评估其潜在风险,尤其是考虑到大模型可能生成有害、不道德和虚假的内容。其次,有报道称ChatGPT的性能随时间变化,妨碍了可重复的结果。第三,ChatGPT经历了多次故障,仅在2023年11月就发生了两次重大故障,期间无法访问ChatGPT网站及其API。最后,采用ChatGPT的企业可能会关注API调用的高成本、服务中断、数据所有权和隐私问题,以及其他不可预测的事件,比如最近有关CEO Sam Altman被解雇并最终回归的董事会闹剧。
此时,开源大模型应运而生,社区一直在积极推动将高性能的大模型保持开源。然而,截至2023年末,大家还普遍认为类似Llama-2或Falcon这样的开源大模型在性能上落后于它们的闭源模型,如OpenAI的GPT3.5(ChatGPT)和GPT-4,Anthropic的Claude2或Google的Bard3,其中GPT-4通常被认为是最出色的。然而,令人鼓舞的是差距正在变得越来越小,开源大模型正在迅速赶上。
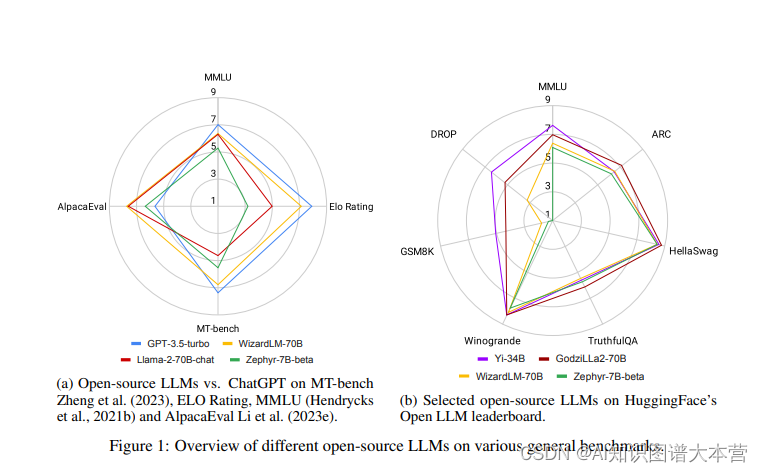
地址:[2311.16989] ChatGPT's One-year Anniversary: Are Open-Source Large Language Models Catching up? (arxiv.org)
更有趣的 AI Agent
-
Generative Agents: Interactive Simulacra of Human Behavior https://arxiv.org/abs/2304.03442
-
RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models https://arxiv.org/abs/2310.00746
-
Role play with large language models https://www.nature.com/articles/s41586-023-06647-8
-
Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf https://arxiv.org/abs/2309.04658
-
MemGPT: Towards LLMs as Operating Systems https://arxiv.org/abs/2310.08560
-
Augmenting Language Models with Long-Term Memory https://arxiv.org/abs/2306.07174
-
Do LLMs Possess a Personality? Making the MBTI Test an Amazing Evaluation for Large Language Models https://arxiv.org/pdf/2307.16180.pdf
更有用的 AI Agent
-
The Rise and Potential of Large Language Model Based Agents: A Survey https://arxiv.org/abs/2309.07864
-
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework https://arxiv.org/abs/2308.00352
-
Communicative Agents for Software Development https://arxiv.org/pdf/2307.07924.pdf
-
Large Language Models Can Self-Improve https://arxiv.org/abs/2210.11610
-
Evaluating Human-Language Model Interaction https://arxiv.org/abs/2212.09746
-
Large Language Models can Learn Rules https://arxiv.org/abs/2310.07064
-
AgentBench: Evaluating LLMs as Agents https://arxiv.org/abs/2308.03688
-
WebArena: A Realistic Web Environment for Building Autonomous Agents https://arxiv.org/abs/2307.13854
-
TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT https://arxiv.org/abs/2307.08674
任务规划与分解
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models https://arxiv.org/abs/2201.11903
-
Tree of Thoughts: Deliberate Problem Solving with Large Language Models https://arxiv.org/abs/2305.10601
-
Implicit Chain of Thought Reasoning via Knowledge Distillation https://arxiv.org/abs/2311.01460
-
ReAct: Synergizing Reasoning and Acting in Language Models https://arxiv.org/abs/2210.03629
-
ART: Automatic multi-step reasoning and tool-use for large language models https://arxiv.org/abs/2303.09014
-
Branch-Solve-Merge Improves Large Language Model Evaluation and Generation https://arxiv.org/abs/2310.15123
-
WizardLM: Empowering Large Language Models to Follow Complex Instructionshttps://arxiv.org/pdf/2304.12244.pdf
幻觉
-
Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Modelshttps://arxiv.org/pdf/2309.01219.pdf
-
Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback https://arxiv.org/abs/2302.12813
-
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models https://arxiv.org/abs/2303.08896
-
WebBrain: Learning to Generate Factually Correct Articles for Queries by Grounding on Large Web Corpus https://arxiv.org/abs/2304.04358
多模态
-
Learning Transferable Visual Models From Natural Language Supervision (CLIP) https://arxiv.org/abs/2103.00020
-
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT): https://arxiv.org/abs/2010.11929
-
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learninghttps://arxiv.org/abs/2310.09478
-
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models https://arxiv.org/abs/2304.10592
-
NExT-GPT: Any-to-Any Multimodal LLM https://arxiv.org/pdf/2309.05519.pdf
-
Visual Instruction Tuning (LLaVA) https://arxiv.org/pdf/2304.08485.pdf
-
Improved Baselines with Visual Instruction Tuning (LLaVA-1.5) https://arxiv.org/abs/2310.03744
-
Sequential Modeling Enables Scalable Learning for Large Vision Models (LVM) https://arxiv.org/pdf/2312.00785.pdf
-
CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation https://arxiv.org/pdf/2311.18775.pdf
-
Neural Discrete Representation Learning (VQ-VAE) https://browse.arxiv.org/pdf/1711.00937.pdf
-
Taming Transformers for High-Resolution Image Synthesis (VQ-GAN) https://arxiv.org/abs/2012.09841
-
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows https://arxiv.org/abs/2103.14030
-
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models https://browse.arxiv.org/pdf/2301.12597.pdf
-
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning https://browse.arxiv.org/pdf/2305.06500.pdf
-
ImageBind: One Embedding Space To Bind Them All https://arxiv.org/abs/2305.05665
-
Meta-Transformer: A Unified Framework for Multimodal Learning https://arxiv.org/abs/2307.10802
图片/视频生成
-
High-Resolution Image Synthesis with Latent Diffusion Models https://arxiv.org/pdf/2112.10752.pdf
-
Structure and Content-Guided Video Synthesis with Diffusion Models (RunwayML Gen1) https://browse.arxiv.org/pdf/2302.03011.pdf
-
Hierarchical Text-Conditional Image Generation with CLIP Latents (DaLLE-2) https://arxiv.org/pdf/2204.06125.pdf
-
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning https://arxiv.org/abs/2307.04725
-
Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet) https://arxiv.org/abs/2302.05543
-
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesishttps://arxiv.org/abs/2307.01952
-
Zero-1-to-3: Zero-shot One Image to 3D Object https://arxiv.org/abs/2303.11328
-
Scaling Vision Transformers to 22 Billion Parameters https://arxiv.org/abs/2302.05442
-
Glow: Generative Flow with Invertible 1×1 Convolutions https://browse.arxiv.org/pdf/1807.03039.pdf
-
Language Model Beats Diffusion – Tokenizer is Key to Visual Generation https://arxiv.org/pdf/2310.05737.pdf
-
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generationhttps://arxiv.org/pdf/2309.06380.pdf
-
Perceptual Losses for Real-Time Style Transfer and Super-Resolution https://arxiv.org/pdf/1603.08155.pdf
-
CogView: Mastering Text-to-Image Generation via Transformers https://arxiv.org/abs/2105.13290
-
Diffusion Models for Video Prediction and Infilling https://arxiv.org/abs/2206.07696
语音合成
-
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech (VITS)https://browse.arxiv.org/pdf/2106.06103.pdf
-
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers (VALL-E)https://arxiv.org/abs/2301.02111
-
Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling (VALL-E X) https://arxiv.org/pdf/2303.03926.pdf
-
MusicLM: Generating Music From Text https://arxiv.org/abs/2301.11325
大模型基础
-
Attention Is All You Need https://arxiv.org/abs/1706.03762
-
Sequence to Sequence Learning with Neural Networks https://arxiv.org/abs/1409.3215
-
Neural Machine Translation by Jointly Learning to Align and Translate https://arxiv.org/abs/1409.0473
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/abs/1810.04805
-
Scaling Laws for Neural Language Models https://arxiv.org/pdf/2001.08361.pdf
-
Emergent Abilities of Large Language Models https://openreview.net/pdf?id=yzkSU5zdwD
-
Training Compute-Optimal Large Language Models (ChinChilla scaling law) https://arxiv.org/abs/2203.15556
-
Scaling Instruction-Finetuned Language Models https://arxiv.org/pdf/2210.11416.pdf
-
Direct Preference Optimization:
-
Your Language Model is Secretly a Reward Model https://arxiv.org/pdf/2305.18290.pdf
-
Progress measures for grokking via mechanistic interpretability https://arxiv.org/abs/2301.05217
-
Language Models Represent Space and Time https://arxiv.org/abs/2310.02207
-
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts https://arxiv.org/abs/2112.06905
-
Adam: A Method for Stochastic Optimization https://arxiv.org/abs/1412.6980
-
Efficient Estimation of Word Representations in Vector Space (Word2Vec) https://arxiv.org/abs/1301.3781
-
Distributed Representations of Words and Phrases and their Compositionality https://arxiv.org/abs/1310.4546
GPT
-
Language Models are Few-Shot Learners (GPT-3) https://arxiv.org/abs/2005.14165
-
Language Models are Unsupervised Multitask Learners (GPT-2) https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
-
Improving Language Understanding by Generative Pre-Training (GPT-1) https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
-
Training language models to follow instructions with human feedback (InstructGPT)https://arxiv.org/pdf/2203.02155.pdf
-
Evaluating Large Language Models Trained on Code https://arxiv.org/pdf/2107.03374.pdf
-
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond https://arxiv.org/abs/2304.13712
-
Instruction Tuning with GPT-4 https://arxiv.org/pdf/2304.03277.pdf
-
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) https://arxiv.org/abs/2309.17421
-
Sparks of Artificial General Intelligence: Early experiments with GPT-4 https://arxiv.org/abs/2303.12712
-
Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision https://arxiv.org/abs/2312.09390
开源大模型
-
LLaMA: Open and Efficient Foundation Language Models https://arxiv.org/abs/2302.13971
-
Llama 2: Open Foundation and Fine-Tuned Chat Models https://arxiv.org/pdf/2307.09288.pdf
-
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality https://lmsys.org/blog/2023-03-30-vicuna/
-
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset https://arxiv.org/abs/2309.11998
-
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena https://arxiv.org/abs/2306.05685
-
How Long Can Open-Source LLMs Truly Promise on Context Length? https://lmsys.org/blog/2023-06-29-longchat/
-
Mixtral of experts https://mistral.ai/news/mixtral-of-experts/
-
OpenChat: Advancing Open-source Language Models with Mixed-Quality Data https://arxiv.org/abs/2309.11235
-
RWKV: Reinventing RNNs for the Transformer Era https://arxiv.org/abs/2305.13048
-
Mamba: Linear-Time Sequence Modeling with Selective State Spaces https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf
-
Retentive Network: A Successor to Transformer for Large Language Models https://arxiv.org/abs/2307.08621
-
Baichuan 2: Open Large-scale Language Models https://arxiv.org/abs/2309.10305
-
GLM-130B: An Open Bilingual Pre-trained Model https://arxiv.org/abs/2210.02414
-
Qwen Technical Report https://arxiv.org/abs/2309.16609
-
Skywork: A More Open Bilingual Foundation Model https://arxiv.org/abs/2310.19341
微调
-
Learning to summarize from human feedback https://arxiv.org/abs/2009.01325
-
Self-Instruct: Aligning Language Model with Self Generated Instruction https://arxiv.org/abs/2212.10560
-
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning https://arxiv.org/abs/2303.15647
-
LoRA: Low-Rank Adaptation of Large Language Models https://arxiv.org/abs/2106.09685
-
Vera: Vector-Based Random Matrix Adapation https://arxiv.org/pdf/2310.11454.pdf
-
QLoRA: Efficient Finetuning of Quantized LLMs https://arxiv.org/abs/2305.14314
-
Chain of Hindsight Aligns Language Models with Feedback https://arxiv.org/abs/2302.02676
-
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models https://arxiv.org/pdf/2312.06585.pdf
性能优化
-
Efficient Memory Management for Large Language Model Serving with PagedAttention (vLLM) https://arxiv.org/abs/2309.06180
-
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness https://arxiv.org/abs/2205.14135
-
S-LoRA: Serving Thousands of Concurrent LoRA Adapters https://arxiv.org/abs/2311.03285
-
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism https://proceedings.neurips.cc/paper/2019/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf
-
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism https://arxiv.org/pdf/1909.08053.pdf
-
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models https://arxiv.org/pdf/1910.02054.pdf
相关文章:
Large Language Models Paper 分享
论文1: ChatGPTs One-year Anniversary: Are Open-Source Large Language Models Catching up? 简介 2022年11月,OpenAI发布了ChatGPT,这一事件在AI社区甚至全世界引起了轰动。首次,一个基于应用的AI聊天机器人能够提供有帮助、…...
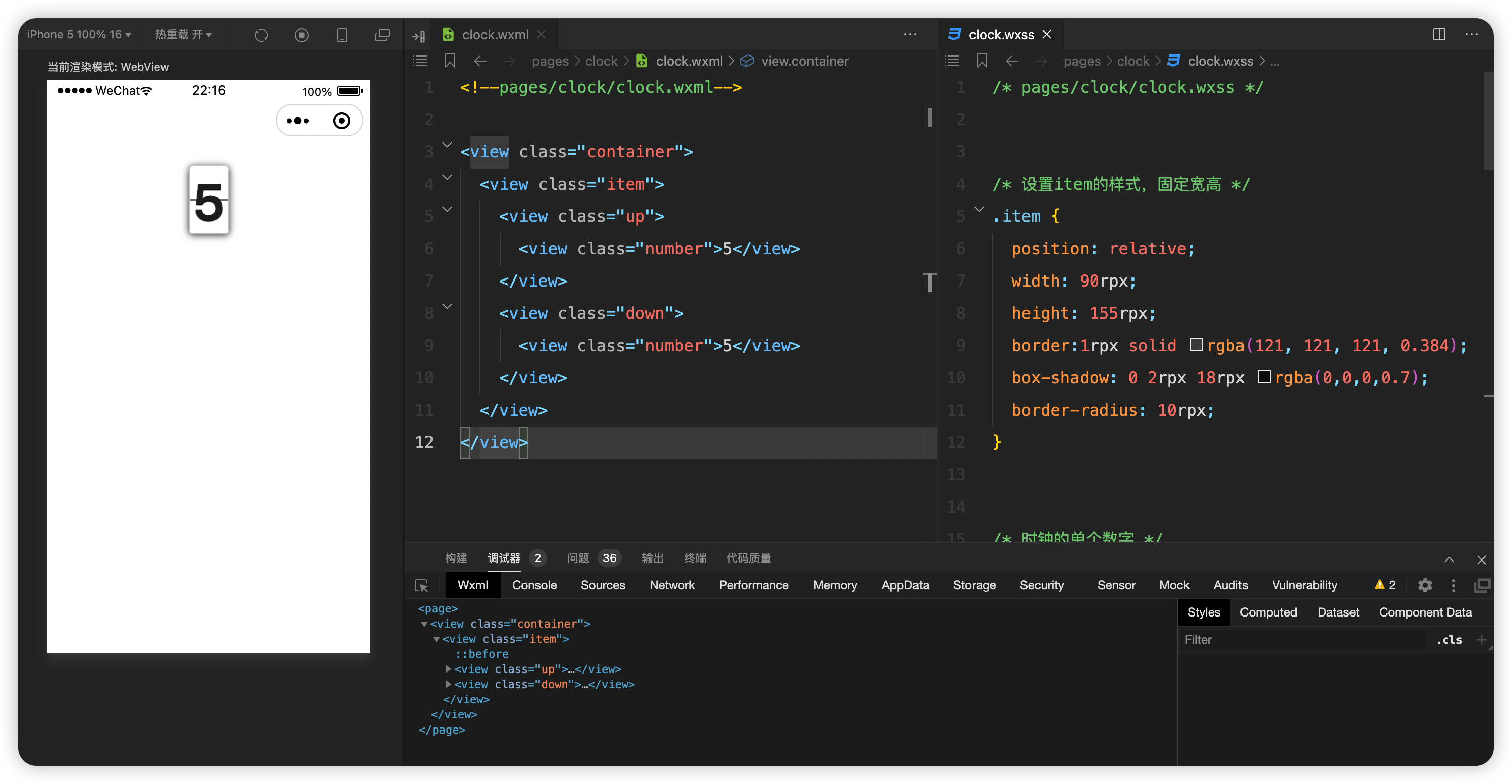
微信小程序实战-01翻页时钟-1
文章目录 前言需求分析功能设计界面设计界面结构设计界面样式设计 逻辑设计 单页功能实现运行结果 前言 我经常在手机上用的一款app有一个功能是翻页时钟,基于之前学习的小程序相关的基础内容,我打算在微信小程序中也设计一个翻页时钟功能,J…...

BigDecimal的性能问题
BigDecimal 是 Java 中用于精确计算的数字类,它可以处理任意精度的小数运算。由于其精确性和灵活性,BigDecimal 在某些场景下可能会带来性能问题。 BigDecimal的性能问题 BigDecimal的性能问题主要源于以下几点: 内存占用:BigDec…...
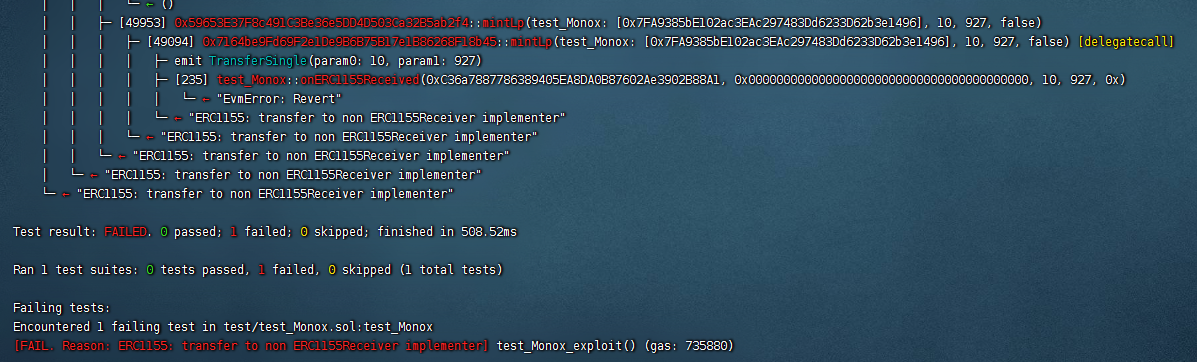
Defi安全-Monox攻击事件Foundry复现
其它相关内容可见个人主页 Mono攻击事件的介绍见:Defi安全–Monox攻击事件分析–phalconetherscan 1. 前情提要和思路介绍 Monox使用单边池模型,创建的是代币-vCash交易对,添加流动性时,只需添加代币,即可进行任意代…...
大二上总结和寒假计划
👂 Start Again - Connor Price/Chloe Sagum - 单曲 - 网易云音乐 👂 年年 - 徐秉龙 - 单曲 - 网易云音乐 目录 🌼前言 👊成长 (1)情感 (2)运动 (3)穿搭…...

使用 pdfh5 实现 pdf 预览功能
1. 安装 npm install pdfh5 2. 使用 html部分: <div id"showPdf" style"width: 100%;"></div> js部分: <script> //合同展示组件 import Pdfh5 from pdfh5 //合同组件样式 import pdfh5/css/pdfh5.css expo…...

HttpRunner辅助函数debugtalk.py
辅助函数debugtalk.py Httprunner框架中,使用yaml或json文件进行用例描述,无法做一些复杂操作,如保存一些数据跨文件调用,或者实现一些复杂逻辑判断等,为了解决这个问题,引入了debugtalk.py辅助函数来进行一…...

PC端扫描小程序二维码登录
1、获取二维码地址,通过请求微信开发者文档中的服务端获取无限制小程序二维码URL #controller层 import org.apache.commons.codec.binary.Base64;/*** 获取小程序二维码*/PassTokenGetMapping("/getQrCode")public AjaxResult getQrCode(BlogUserDto bl…...
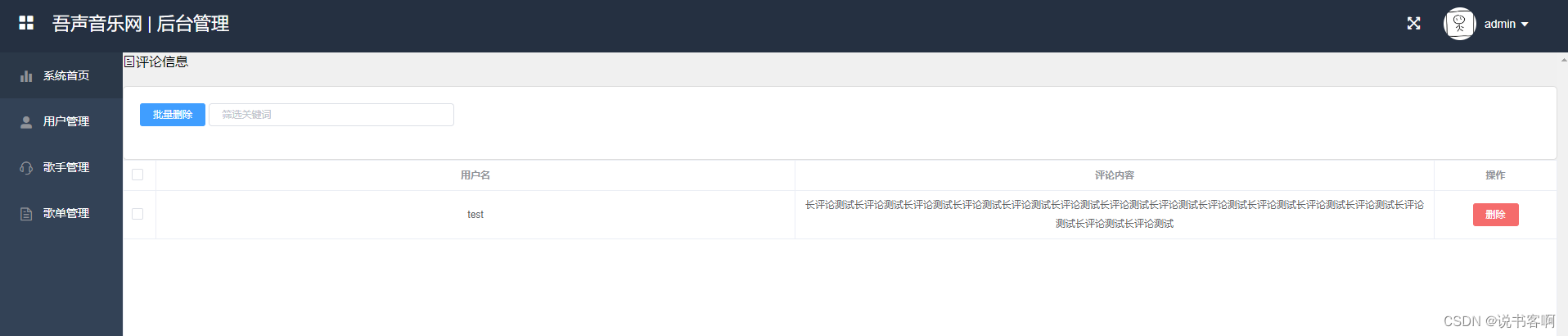
计算机毕业设计 | SpringBoot+vue移动端音乐网站 音乐播放器(附源码)
1,项目背景 随着计算机技术的发展,网络技术对我们生活和工作显得越来越重要,特别是现在信息高度发达的今天,人们对最新信息的需求和发布迫切的需要及时性。为了满足不同人们对网络需求,各种特色,各种主题的…...

Flutter 中的 Stream:异步编程的利器
在Flutter中,异步编程是非常重要的一部分,特别是在处理用户输入、网络请求或其他涉及时间的操作时。Flutter提供了一种强大的工具,称为Stream,用于简化异步编程的过程。 什么是 Stream? Stream是一种用于处理异步数据…...

2023 波卡年度报告选读:Polkadot SDK 与开发者社区
原文:https://dashboards.data.paritytech.io/reports/2023/index.html#section6 编译:OneBlock 编者注:Parity 数据团队发布的 2023 年 Polkadot 年度数据报告,对推动生态系统的关键数据进行了深入分析。报告全文较长ÿ…...
:探究变量与数据类型的内存占用)
深入了解Go语言中的unsafe.Sizeof():探究变量与数据类型的内存占用
当涉及到在 Go 语言中确定变量或数据类型所占用的内存空间大小时,unsafe 包中的 Sizeof() 函数成为了一个强有力的工具。它可以用来获取变量或数据类型所占用的字节数,但需要注意的是,它不考虑内存对齐和填充的情况。因此,在使用 …...

安卓上使用免费的地图OpenStreetMap
前一段使用了微信的地图,非常的好用。但是存在的问题是海外无法使用,出国就不能用了; 其实国内三家:百度,高德,微信都是一样的问题,当涉及到商业使用的时候需要付费; 国外除了谷歌…...
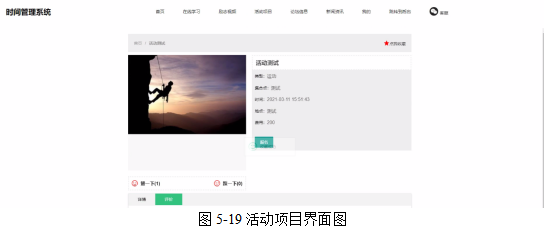
基于Java SSM框架实现时间管理系统项目【项目源码+论文说明】
基于java的SSM框架实现时间管理系统演示 摘要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于时间管理系统当然也不能排除在外,随着网络技术的不断成熟,带动了时间管理…...
Mac安装upx及不同os计算md5值
Mac安装upx 最近需要将exe文件打包到pod内部,为了减少包占用磁盘空间,需要借用upx对windows exe文件进行压缩。 1 概念:压缩工具 UPX 全称是 “Ultimate Packer for eXecutables”,是一个免费、开源、编写、可扩展、高性能的可执行…...

Qt/C++编写视频监控系统82-自定义音柱显示
一、前言 通过音柱控件实时展示当前播放的声音产生的振幅的大小,得益于音频播放组件内置了音频振幅的计算,可以动态开启和关闭,开启后会对发送过来的要播放的声音数据,进行运算得到当前这个音频数据的振幅,类似于分贝…...
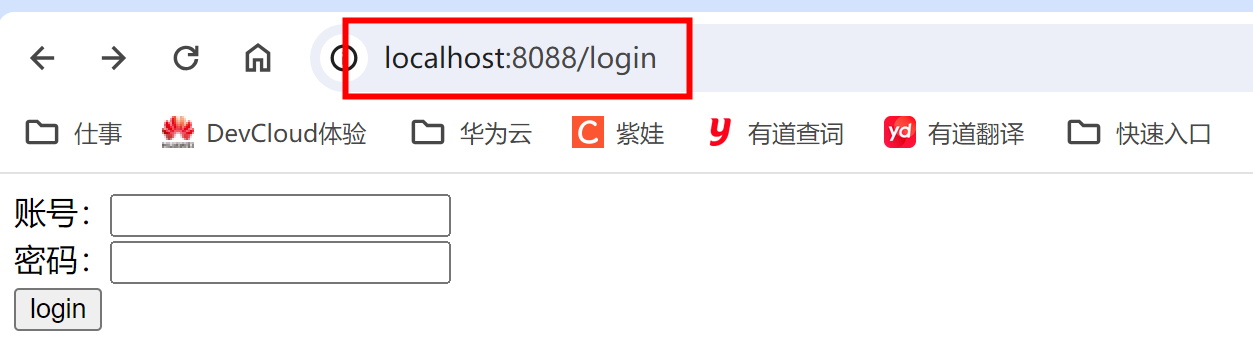
SpringBoot 如何 配置端口号
结论 server:port: 8088演示 [Ref] 快速构建SpringBoot项目...

跟随chatgpt从零开始安装git(Windows系统)
为什么我们要安装Git?Git有什么用? 1. 版本控制:Git 可以追踪代码的所有变化,记录每个提交的差异,使您能够轻松地回溯到任何历史版本或比较不同版本之间的差异。 2. 分支管理:通过 Git 的分支功能ÿ…...
C++类与对象基础(6)
(注:本篇文章介绍部分内容时,需要用到上盘文章中日期类的代码,文章链接如下:C类与对象基础(5)——日期类的实现-CSDN博客) 目录 1. 运算符重载的相关补充: 1.1流运算符重载出现的问题&#x…...
OS_lab——分页机制与内存管理
认真阅读章节资料,掌握什么是分页机制 调试代码,掌握分页机制基本方法与思路 代码pmtest6.asm中,212行~237行,设置断点调试这几个循环,分析究竟在这里做了什么 掌握PDE,PTE的计算方法 动手画一画这个映…...

AI智能体审批系统设计:从规则到价值网络的动态决策引擎
1. 项目概述:为什么AI需要“举手提问”?在AI智能体(Agent)日益深入业务流程自动化的今天,一个核心的、却常被忽视的问题浮出水面:这个拥有一定自主决策能力的“数字员工”,在什么情况下应该停下…...

计算机视觉数据集选型实战指南:从COCO到Roboflow的工程决策框架
1. 这份清单不是“资料库目录”,而是计算机视觉工程师的实战弹药箱如果你正在训练一个能识别工业零件表面微小划痕的模型,却在COCO数据集上反复调参;或者你刚拿到一批医院提供的CT影像,第一反应是去Kaggle搜“medical image datas…...

从格式混乱到工作流重构:Cloud Document Converter如何重塑飞书文档迁移体验
从格式混乱到工作流重构:Cloud Document Converter如何重塑飞书文档迁移体验 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 你是否曾花费数小时手动复制飞…...

收藏!小白程序员必看:从AI提效到重构产品,企业智能转型4阶段实战指南
本文深入探讨了企业如何拥抱智能时代,通过4个阶段实现AI落地。从提升内部效率开始,逐步激活沉睡数据,重构产品价值,最终形成深场景智能闭环。强调AI不应仅用于替代人工,更要关注为客户创造新价值、提升产品智能化&…...

Jellyfin智能片头检测解决方案:Intro Skipper插件技术指南
Jellyfin智能片头检测解决方案:Intro Skipper插件技术指南 【免费下载链接】intro-skipper Fingerprint audio to automatically detect and skip intro sequences in Jellyfin 项目地址: https://gitcode.com/gh_mirrors/in/intro-skipper Intro Skipper是一…...

实战指南:5分钟掌握ImageToSTL图片转3D模型技术
实战指南:5分钟掌握ImageToSTL图片转3D模型技术 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left side. 项目…...

Baetyl开源社区贡献指南:如何参与边缘计算框架的代码与文档开发
Baetyl开源社区贡献指南:如何参与边缘计算框架的代码与文档开发 【免费下载链接】baetyl Extend cloud computing, data and service seamlessly to edge devices. 项目地址: https://gitcode.com/gh_mirrors/ba/baetyl 欢迎来到Baetyl开源边缘计算框架的贡献…...

教育资源共享新范式:智能解析技术如何重塑教材获取体验
教育资源共享新范式:智能解析技术如何重塑教材获取体验 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 项目地址…...

【其他】Obsidian笔记Remotely Save插件中国科技云数据胶囊 配置免费的笔记同步
目录 一 注册中国科技云数据胶囊 二 插件下载 & 配置 三 同步测试 一 注册中国科技云数据胶囊 【1】搜索“中国科技云”,找到“数据胶囊”选项,实名注册可以领取20G的容量: 【2】选择“新数据空间”,输入库的标题…...

2026年度能耗监测系统的深度分析与展望
在当前全球可持续发展的大背景下,能耗监测系统的重要性愈发凸显。随着技术的进步和社会对节能减排的需求,2026年度的能耗监测系统将迎来一场技术革命和应用升级。本文将从市场需求、技术现状、未来发展方向及实施策略等多个方面,对2026能耗监…...