强化学习10——免模型控制Q-learning算法
Q-learning算法
主要思路
由于 V π ( s ) = ∑ a ∈ A π ( a ∣ s ) Q π ( s , a ) V_\pi(s)=\sum_{a\in A}\pi(a\mid s)Q_\pi(s,a) Vπ(s)=∑a∈Aπ(a∣s)Qπ(s,a) ,当我们直接预测动作价值函数,在决策中选择Q值最大即动作价值最大的动作,则可以使策略和动作价值函数同时最优,那么由上述公式可得,状态价值函数也是最优的。
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + γ max a Q ( s t + 1 , a ) − Q ( s t , a t ) ] Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha[r_t+\gamma\max_aQ(s_{t+1},a)-Q(s_t,a_t)] Q(st,at)←Q(st,at)+α[rt+γamaxQ(st+1,a)−Q(st,at)]
Q-learning基于时序差分的更新方法,具体流程如下所示:
- 初始化 Q ( s , a ) Q(s,a) Q(s,a)
- for 序列 e = 1 → E e=1\to E e=1→E do:
- 得到初始状态s
- for 时步 t = 1 → T t=1\to T t=1→T do:
- 使用 ϵ − g r e e d y \epsilon -greedy ϵ−greedy 策略根据Q选择当前状态s下的动作a
- 得到环境反馈 r , s ′ r,s' r,s′
- Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a)\leftarrow Q(s,a)+\alpha[r+\gamma\max_{a^{\prime}}Q(s^{\prime},a^{\prime})-Q(s,a)] Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
- s ← s ′ s\gets s' s←s′
- end for
- end for
算法实战
我们在悬崖漫步环境下实习Q-learning算法。
首先创建悬崖漫步的环境:
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm # tqdm是显示循环进度条的库class CliffWalkingEnv:def __init__(self, ncol, nrow):self.nrow = nrowself.ncol = ncolself.x = 0 # 记录当前智能体位置的横坐标self.y = self.nrow - 1 # 记录当前智能体位置的纵坐标def step(self, action): # 外部调用这个函数来改变当前位置# 4种动作, change[0]:上, change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)# 定义在左上角change = [[0, -1], [0, 1], [-1, 0], [1, 0]]self.x = min(self.ncol - 1, max(0, self.x + change[action][0]))self.y = min(self.nrow - 1, max(0, self.y + change[action][1]))next_state = self.y * self.ncol + self.xreward = -1done = Falseif self.y == self.nrow - 1 and self.x > 0: # 下一个位置在悬崖或者目标done = Trueif self.x != self.ncol - 1:reward = -100return next_state, reward, donedef reset(self): # 回归初始状态,坐标轴原点在左上角self.x = 0self.y = self.nrow - 1return self.y * self.ncol + self.x
创建Q-learning算法
class QLearning:def __init__(self, ncol, nrow, epsilon, alpha, gamma,n_action=4):self.epsilon = epsilon # 随机探索的概率self.alpha = alpha # 学习率self.gamma = gamma # 折扣因子self.n_action = n_action # 动作数量# 给每一个状态创建一个长度为4的列表。self.Q_table = np.zeros([nrow*ncol,n_action]) # 初始化Q(s,a)def take_action(self,state):# 选取下一步的操作if np.random.random()<self.epsilon:action = np.random.randint(self.n_action) # 随机探索else:action = np.argmax(self.Q_table[state]) # 贪婪策略,选择Q值最大的动作return actiondef best_action(self, state): # 用于打印策略Q_max = np.max(self.Q_table[state])a = [0 for _ in range(self.n_action)]for i in range(self.n_action):if self.Q_table[state, i] == Q_max:a[i] = 1return adef update(self,s0,a0,r,s1):td_error = r+self.gamma*self.Q_table[s1].max()-self.Q_table[s0,a0]self.Q_table[s0, a0] += self.alpha * td_error
ncol = 12
nrow = 4
np.random.seed(0)
epsilon = 0.1
alpha = 0.1
gamma = 0.9
env = CliffWalkingEnv(ncol, nrow)
agent = QLearning(ncol, nrow, epsilon, alpha, gamma)
num_episodes = 500 # 智能体在环境中运行的序列的数量
return_list = [] # 记录每一条序列的回报
# 显示10个进度条
for i in range(10):# tqdm的进度条功能with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes / 10)): # 每个进度条的序列数episode_return = 0state = env.reset()done = Falsewhile not done:action = agent.take_action(state)next_state, reward, done = env.step(action)episode_return += reward # 这里回报的计算不进行折扣因子衰减agent.update(state, action, reward, next_state)state = next_statereturn_list.append(episode_return)if (i_episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)episodes_list = list(range(len(return_list)))
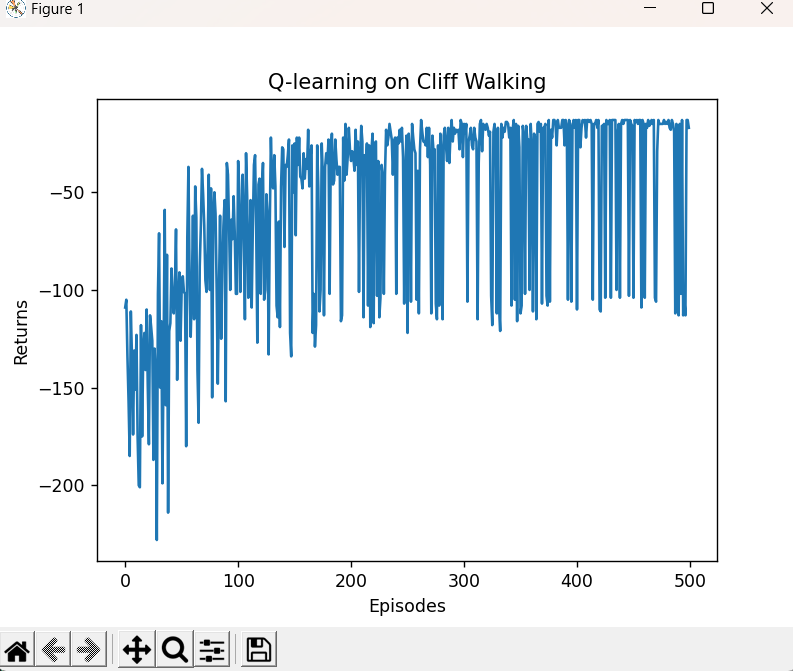
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Q-learning on {}'.format('Cliff Walking'))
plt.show()action_meaning = ['^', 'v', '<', '>']
print('Q-learning算法最终收敛得到的策略为:')
def print_agent(agent, env, action_meaning, disaster=[], end=[]):for i in range(env.nrow):for j in range(env.ncol):if (i * env.ncol + j) in disaster:print('****', end=' ')elif (i * env.ncol + j) in end:print('EEEE', end=' ')else:a = agent.best_action(i * env.ncol + j)pi_str = ''for k in range(len(action_meaning)):pi_str += action_meaning[k] if a[k] > 0 else 'o'print(pi_str, end=' ')print()action_meaning = ['^', 'v', '<', '>']
print('Sarsa算法最终收敛得到的策略为:')
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
Iteration 0: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2040.03it/s, episode=50, return=-105.700]
Iteration 1: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2381.99it/s, episode=100, return=-70.900]
Iteration 2: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 3209.35it/s, episode=150, return=-56.500]
Iteration 3: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 3541.95it/s, episode=200, return=-46.500]
Iteration 4: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 5005.26it/s, episode=250, return=-40.800]
Iteration 5: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 3936.76it/s, episode=300, return=-20.400]
Iteration 6: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 4892.00it/s, episode=350, return=-45.700]
Iteration 7: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 5502.60it/s, episode=400, return=-32.800]
Iteration 8: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 6730.49it/s, episode=450, return=-22.700]
Iteration 9: 100%|███████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 6768.50it/s, episode=500, return=-61.700]
Q-learning算法最终收敛得到的策略为:
Qling算法最终收敛得到的策略为:
^ooo ovoo ovoo ^ooo ^ooo ovoo ooo> ^ooo ^ooo ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ^ooo ooo> ooo> ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
^ooo ovoo ovoo ^ooo ^ooo ovoo ooo> ^ooo ^ooo ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ^ooo ooo> ooo> ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
相关文章:
强化学习10——免模型控制Q-learning算法
Q-learning算法 主要思路 由于 V π ( s ) ∑ a ∈ A π ( a ∣ s ) Q π ( s , a ) V_\pi(s)\sum_{a\in A}\pi(a\mid s)Q_\pi(s,a) Vπ(s)∑a∈Aπ(a∣s)Qπ(s,a) ,当我们直接预测动作价值函数,在决策中选择Q值最大即动作价值最大的动作&…...
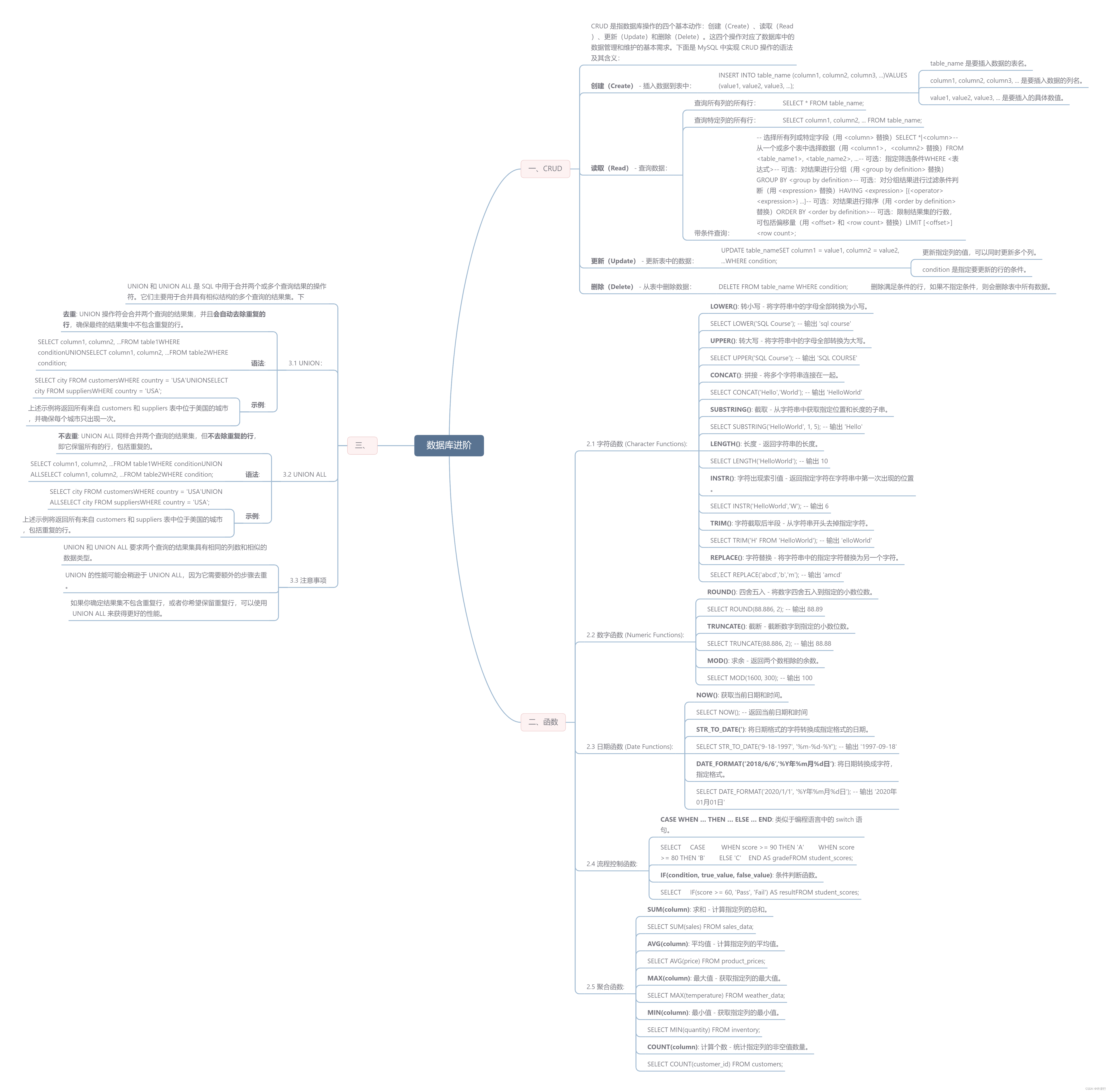
【数据库】CRUD常用函数UNION 和 UNION ALL
文章目录 一、CRUD二、函数2.1 字符函数 (Character Functions):2.2 数字函数 (Numeric Functions):2.3 日期函数 (Date Functions):2.4 流程控制函数:2.5 聚合函数: 三、UNION 和 UNION ALL3.1 UNION:3.2 UNION ALL3.3 注意事项 一、CRUD CRUD 是指数据库操作的四…...

Adding Conditional Control to Text-to-Image Diffusion Models——【论文笔记】
本文发表于ICCV2023 论文地址:ICCV 2023 Open Access Repository (thecvf.com) 官方实现代码:lllyasviel/ControlNet: Let us control diffusion models! (github.com) Abstract 论文提出了一种神经网络架构ControlNet,可以将空间条件控制添加到大型…...

Python与人工智能
Python 是一种广泛用于人工智能(AI)开发的编程语言。Python具有简洁的语法和强大的库支持,使其成为数据科学、机器学习和深度学习的理想选择。 Python中有许多库可以帮助实现人工智能,其中最流行的包括TensorFlow和PyTorch。这些…...
【Docker】Docker基础
文章目录 安装使用帮助启动命令镜像命令容器命令 安装 # 卸载旧版本 sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine # 设置存储库 sudo yum install -y yum-utils …...
linux异常情况,排查处理中
登录客户环境后,发现一个奇怪情况如下图,之前也遇到过,直接fuser -ck /backup操作的话,主机将会重启,因数据库运行中,等待停机维护时间,同时也在想办法不重启的情况下解决该问题 [rootdb ~]# f…...

Spring Boot参数校验方案
NotNull:值不能为null;NotEmpty:字符串、集合或数组的值不能为空,即长度大于0;NotBlank:字符串的值不能为空白,即不能只包含空格;Size:字符串、集合或数组的大小是否在指…...
【漏洞复现】ActiveMQ反序列化漏洞(CVE-2015-5254)
Nx01 产品简介 Apache ActiveMQ是Apache软件基金会所研发的开放源代码消息中间件。ActiveMQ是消息队列服务,是面向消息中间件(MOM)的最终实现,它为企业消息传递提供高可用、出色性能、可扩展、稳定和安全保障。 Nx02 漏洞描述 Re…...
面试题:MySQL误删表数据,如何快速恢复丢失的数据?
相信后端研发的同学在开发过程经常会遇到产品临时修改线上数据的需求,如果手法很稳那么很庆幸可以很快完成任务,很不幸某一天突然手一抖把表里的数据修改错误或者误删了,这个时候你会发现各种问题反馈接踵而来。 如果身边有BDA或者有这方面经…...

李沐之神经网络基础
目录 1.模型构造 1.1层和块 1.2自定义块 1.3顺序块 1.4在前向传播函数中执行代码 2.参数管理 2.1参数访问 2.2参数初始化 3.自定义层 3.1不带参数的层 3.2带参数的层 4.读写文件 4.1加载和保存张量 4.2加载和保存模型参数 1.模型构造 1.1层和块 import torch fr…...

【docker】使用 Dockerfile 构建镜像
一、什么是Dockerfile Dockerfile 是用于构建 Docker 镜像的文本文件。它包含了一系列的指令,用于描述如何构建镜像的步骤和配置。 通过编写 Dockerfile,您可以定义镜像的基础环境、安装软件包、复制文件、设置环境变量等操作。Dockerfile 提供了一种可…...
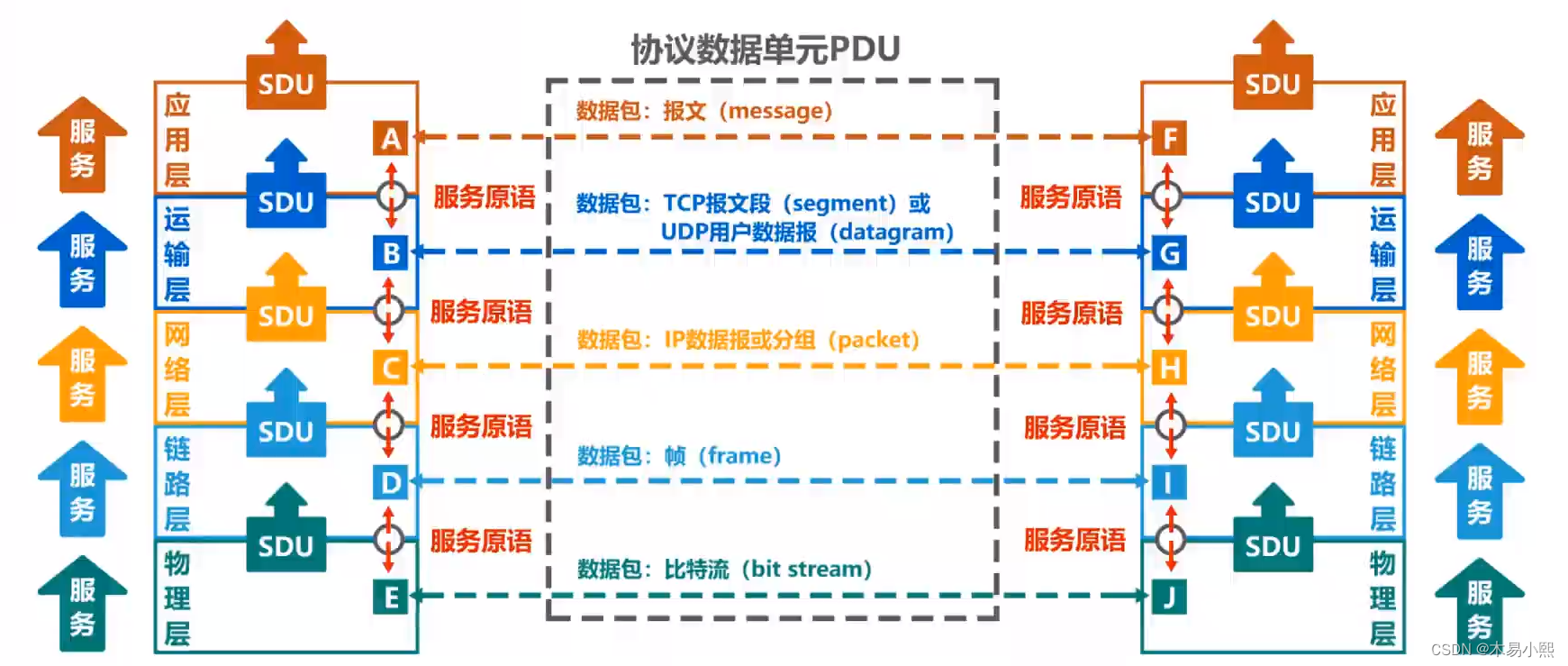
计算机网络—— 概述
概述 1.1 因特网概述 网络、互联网和因特网 网络由若干结点和连接这些结点的链路组成多个网络还可以通过路由器互联起来,这样就构成了一个覆盖范围更大的网络,即互联网(或互连网)。因特网(Internet)是世…...

“超人练习法”系列06:如何更好地掌握技能?
01 掌握的阶段 关于人类学习新事物的最生动、最精妙的比喻,我是从笑来老师那里学到的。 他指出,学习新知识、新概念犹如在构建自己大脑皮层,每个习得的概念就像是大脑皮层上的一个个微小神经元。 一个看似聪明、博学的人,总能在各…...

【华为OD机试真题2023CD卷 JAVAJS】字符串拼接
华为OD2023(C&D卷)机试题库全覆盖,刷题指南点这里 字符串拼接 知识点数组递归 时间限制:1s 空间限制:256MB 限定语言:不限 题目描述: 给定M(0<M<=30)个字符(a-z),从中取出任意字符(每个字符只能用一次)拼接成长度为N(0<N<=5)的字符串,要求相同的字…...

【算法】链表-20240109
这里写目录标题 一、141. 环形链表二、876. 链表的中间结点三、面试题 02.01. 移除重复节点 一、141. 环形链表 简单 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中…...
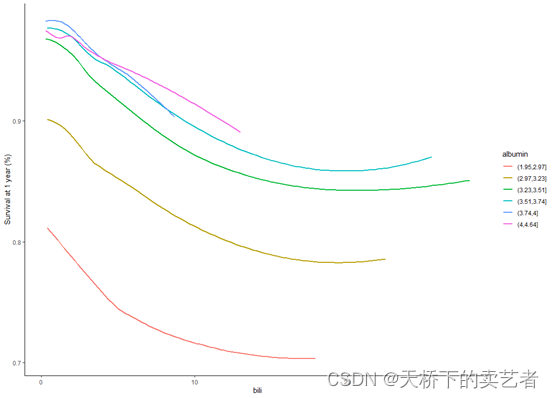
机器学习系列--R语言随机森林进行生存分析(2)
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。随机生存森林(RSF࿰…...

Flutter GetX 之 状态管理
上一篇文章为大家介绍了 GetX的 路由管理,让大家对GetX有了初步了解,今天为大家介绍一下GetX的 状态管理。 StatelessWidget 和 StatefulWidget 介绍 在介绍之前,先简单介绍一下 Flutter 页面的 StatelessWidget 和 StatefulWidget ,其实Flutter的本质是万物都是Widget,…...

e2studio开发磁力计LIS2MDL(1)----轮询获取磁力计数据
e2studio开发磁力计LIS2MDL.1--轮询获取磁力计数据 概述视频教学样品申请源码下载速率新建工程工程模板保存工程路径芯片配置工程模板选择时钟设置UART配置UART属性配置设置e2studio堆栈e2studio的重定向printf设置R_SCI_UART_Open()函数原型回调函数user_uart_callback ()prin…...

C++ 字符串大小写转换,替换,文件保存 方法封装
此示例程序方法已经封装好使用std::islower()函数可以检查一个字符是否是小写字母,使用std::isupper()函数可以检查一个字符是否是大写字母。 如果传入的字母是小写字母,则使用std::toupper()函数将其转换为大写字母,并输出转换后的结果。 如果输入的字母是大写字母,则使…...

计算机基础面试题 |19.精选计算机基础面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

3种高效方案:让Windows直接运行Android应用的全新体验手册
3种高效方案:让Windows直接运行Android应用的全新体验手册 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想象一下这样的场景:您需要在电脑上快…...
)
Ubuntu 20.04黑屏救星:手把手教你用tty2命令行重装NVIDIA驱动(附内核更新关闭指南)
Ubuntu 20.04黑屏救援实战:从tty2命令行到图形界面恢复全指南 当你满心欢喜地启动Ubuntu 20.04,准备开始一天的工作时,迎接你的却是一片漆黑——这是许多Linux用户都曾遭遇过的噩梦场景。NVIDIA驱动问题导致的系统黑屏不仅令人沮丧࿰…...

从零配置到生产就绪,Claude深度集成Angular CLI的7个关键步骤,错过再等一年
更多请点击: https://intelliparadigm.com 第一章:Claude Angular开发支持 Claude 系列大模型虽原生不直接嵌入 Angular 框架,但可通过 REST API 与 Angular 应用高效集成,实现智能提示、代码补全、组件生成等增强开发体验。关键…...
)
双系统‘分手’指南:在UEFI模式下彻底卸载Ubuntu并回收磁盘空间(附EasyUEFI使用详解)
双系统卸载全攻略:安全移除Ubuntu并回收磁盘空间的终极指南 你是否曾经为了体验Linux而在Windows电脑上安装了Ubuntu双系统,现在却想回归单一操作系统?面对复杂的UEFI引导和磁盘分区,很多人担心操作不当会导致系统崩溃或数据丢失。…...

静态前端项目实战:从营销页到现代化门户的架构与实现
1. 项目概述:一个纯粹的静态前端项目最近在GitHub上看到了一个名为“Vibe Code”的项目,它的README写得非常漂亮,充满了各种炫酷的特性介绍,比如支持Claude Code、OpenAI Codex等AI编程助手,还有深色/亮色主题切换、多…...

芯片设计公司ISO 9001认证:从质量管理体系到流片成功的工程实践
1. 从一则旧闻聊起:ISO 9001认证对一家芯片设计公司意味着什么?前几天在整理资料时,偶然翻到一篇2011年的行业旧闻,说的是当时一家名为SiliconBlue Technologies的公司,获得了ISO 9001:2008质量管理体系认证。新闻稿写…...

AnyFlip下载器:3分钟将在线翻页电子书变为永久PDF收藏
AnyFlip下载器:3分钟将在线翻页电子书变为永久PDF收藏 【免费下载链接】anyflip-downloader Download anyflip books as PDF 项目地址: https://gitcode.com/gh_mirrors/an/anyflip-downloader 你是否曾在AnyFlip网站上发现一本精彩的电子书,想要…...

第八部分-企业级实践——39. 私有镜像仓库
39. 私有镜像仓库 1. 私有镜像仓库概述 私有镜像仓库用于存储和管理企业内部 Docker 镜像,提供镜像存储、分发、安全扫描、访问控制等功能。 ┌────────────────────────────────────────────────────────…...

第八部分-企业级实践——38. 容器化改造
38. 容器化改造 1. 容器化改造概述 容器化改造是将传统应用迁移到容器环境的过程,涉及应用架构调整、Dockerfile 编写、配置管理、数据持久化等多个方面。 ┌──────────────────────────────────────────────────…...

如何自定义 LangGraph 的 State Schema 以支持复杂业务数据流
标题选项 《LangGraph实战进阶:自定义State Schema搞定复杂业务数据流全指南》 《从零搞定LangGraph复杂工作流:State Schema自定义从原理到落地》 《告别简单Demo:自定义LangGraph State Schema支撑企业级复杂数据流》 《LangGraph核心原理解锁:State Schema自定义设计思路…...