gem5学习(11):将缓存添加到配置脚本中——Adding cache to the configuration script
目录
一、Creating cache objects
1、Classic caches and Ruby
二、Cache
1、导入SimObject(s)
2、创建L1Cache
3、创建L1Cache子类
4、创建L2Cache
5、L1Cache添加连接函数
6、为L1ICache和L1DCache添加连接函数
7、为L2Cache添加内存侧和CPU侧的连接函数
完整代码
三、Adding caches to the simple config file
1、导入caches
2、创建L1Cache
3、连接缓存和CPU
4、创建L2XBar
完整代码
四、Adding parameters to your script
测试
以上一教程的配置脚本作为起点,本章将详细介绍一个更复杂的配置。
将根据下图所示添加一个缓存层次结构到系统中。
此外,本教程还将介绍如何理解gem5的统计输出,并向你的脚本中添加命令行参数。
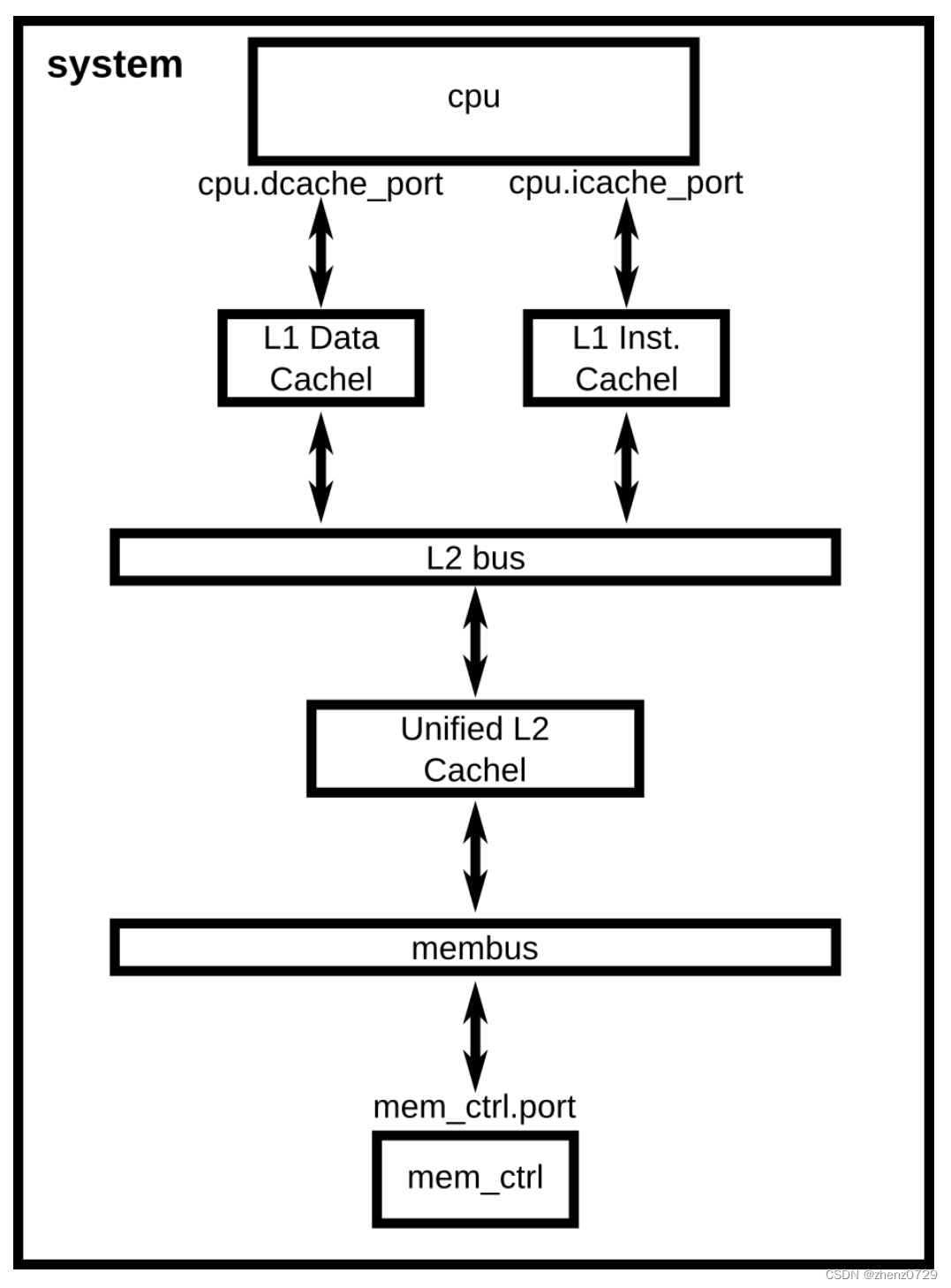
一、Creating cache objects
因为我们正在建模一个单核心CPU系统,,不关心建模缓存一致性。所以这个教程中,将使用经典缓存(Classic caches)而不是Ruby入门章节(ruby-intro-chapter)。教程将扩展Cache SimObject并对其进行系统配置。首先,需要了解用于配置Cache对象的参数。
1、Classic caches and Ruby
gem5目前有两个完全不同的子系统用于模拟系统中的片上缓存,即“经典缓存”和“Ruby”。这是由于gem5是密歇根大学的m5和威斯康辛大学的GEMS的结合体。GEMS使用Ruby作为其缓存模型,而经典缓存来自m5代码库(因此称为“经典”)。这两种模型的区别在于Ruby被设计用于详细模拟缓存一致性。Ruby的一部分是SLICC,一种用于定义缓存一致性协议的语言。而经典缓存则实现了简化且不灵活的MOESI一致性协议。
在选择使用哪个模型时,应考虑正在建模的内容侧重点。如果正在建模缓存一致性协议的更改,或者一致性协议对结果有重要影响,使用Ruby。如果一致性协议不重要,使用经典缓存。
gem5的长期目标是将这两种缓存模型统一为一个综合模型。
二、Cache
Cache SimObject的声明可以在src/mem/cache/Cache.py中找到。这个Python文件定义了可以设置SimObject的参数。在内部,当实例化SimObject时,这些参数会传递给该对象的C++实现。Cache SimObject继承自下面显示的BaseCache对象。
在BaseCache类中,有许多参数。例如,assoc是一个整数参数。一些参数,比如write_buffers,在这种情况下有一个默认值,为8。默认参数是Param.*的第一个参数,除非第一个参数是一个字符串。每个参数的字符串参数是该参数的描述(例如,tag_latency = Param.Cycles("Tag lookup latency")表示tag_latency控制着“此缓存的命中延迟”)。
许多这些参数没有默认值,所以在调用m5.instantiate()之前需要设置这些参数。
为了使用特定的参数创建缓存,首先要在与configs/tutorial/part1/simple.py相同目录中创建一个名为caches.py的新文件。
1、导入SimObject(s)
第一步是导入将在此文件中扩展的SimObject(s)。
from m5.objects import Cache2、创建L1Cache
接下来,可以像处理其他Python类一样处理BaseCache对象并进行扩展。可以根据需要给新的缓存取任意名称,创建一个L1缓存。
class L1Cache(Cache):assoc = 2tag_latency = 2data_latency = 2response_latency = 2mshrs = 4tgts_per_mshr = 20在这里,扩展了BaseCache并设置了大多数在BaseCache SimObject中没有默认值的参数。BaseCache的部分参数没有默认值,就需要设置。如果要查看所有可能的配置选项,并找出哪些是必需的,哪些是可选的,必须查看SimObject的源代码。
3、创建L1Cache子类
接下来,创建两个L1Cache的子类,一个是L1DCache,一个是L1ICache。
class L1ICache(L1Cache):size = '16kB'class L1DCache(L1Cache):size = '64kB'4、创建L2Cache
创建一个带有部分参数的L2缓存
class L2Cache(Cache):size = '256kB'assoc = 8tag_latency = 20data_latency = 20response_latency = 20mshrs = 20tgts_per_mshr = 12现在,已经指定了BaseCache所需的所有必要参数,只需要实例化子类并将缓存连接到互连网络。但如果将大量对象连接到复杂的互连网络,可能会导致配置脚本文件的规模增大,同时脚本配置文件的可读性降低。因此,首先在Cache的子类中添加一些辅助函数(上述的类都是python类)。
5、L1Cache添加连接函数
对于L1缓存,添加两个函数:connectCPU将CPU连接到缓存,connectBus将缓存连接到总线。我们需要将以下代码添加到L1Cache类中。
def connectCPU(self, cpu):# need to define this in a base class!raise NotImplementedErrordef connectBus(self, bus):self.mem_side = bus.cpu_side_ports6、为L1ICache和L1DCache添加连接函数
接下来,需要为指令缓存和数据缓存分别定义单独的connectCPU函数,因为I-cache和D-cache端口有不同的名称。此时的L1ICache和L1DCache类变成如下:
class L1ICache(L1Cache):size = '16kB'def connectCPU(self, cpu):self.cpu_side = cpu.icache_portclass L1DCache(L1Cache):size = '64kB'def connectCPU(self, cpu):self.cpu_side = cpu.dcache_port7、为L2Cache添加内存侧和CPU侧的连接函数
分别为L2Cache添加连接到内存侧和CPU侧总线的函数。
def connectCPUSideBus(self, bus):self.cpu_side = bus.mem_side_portsdef connectMemSideBus(self, bus):self.mem_side = bus.cpu_side_ports完整代码
import m5
from m5.objects import Cache# Add the common scripts to our path
m5.util.addToPath("../../")from common import SimpleOpts# Some specific options for caches
# For all options see src/mem/cache/BaseCache.pyclass L1Cache(Cache):"""Simple L1 Cache with default values"""assoc = 2tag_latency = 2data_latency = 2response_latency = 2mshrs = 4tgts_per_mshr = 20def __init__(self, options=None):super(L1Cache, self).__init__()passdef connectBus(self, bus):"""Connect this cache to a memory-side bus"""self.mem_side = bus.cpu_side_portsdef connectCPU(self, cpu):"""Connect this cache's port to a CPU-side portThis must be defined in a subclass"""raise NotImplementedErrorclass L1ICache(L1Cache):"""Simple L1 instruction cache with default values"""# Set the default sizesize = "16kB"SimpleOpts.add_option("--l1i_size", help=f"L1 instruction cache size. Default: {size}")def __init__(self, opts=None):super(L1ICache, self).__init__(opts)if not opts or not opts.l1i_size:returnself.size = opts.l1i_sizedef connectCPU(self, cpu):"""Connect this cache's port to a CPU icache port"""self.cpu_side = cpu.icache_portclass L1DCache(L1Cache):"""Simple L1 data cache with default values"""# Set the default sizesize = "64kB"SimpleOpts.add_option("--l1d_size", help=f"L1 data cache size. Default: {size}")def __init__(self, opts=None):super(L1DCache, self).__init__(opts)if not opts or not opts.l1d_size:returnself.size = opts.l1d_sizedef connectCPU(self, cpu):"""Connect this cache's port to a CPU dcache port"""self.cpu_side = cpu.dcache_portclass L2Cache(Cache):"""Simple L2 Cache with default values"""# Default parameterssize = "256kB"assoc = 8tag_latency = 20data_latency = 20response_latency = 20mshrs = 20tgts_per_mshr = 12SimpleOpts.add_option("--l2_size", help=f"L2 cache size. Default: {size}")def __init__(self, opts=None):super(L2Cache, self).__init__()if not opts or not opts.l2_size:returnself.size = opts.l2_sizedef connectCPUSideBus(self, bus):self.cpu_side = bus.mem_side_portsdef connectMemSideBus(self, bus):self.mem_side = bus.cpu_side_ports三、Adding caches to the simple config file
将上一教程的最终完整代码文件复制在同目录,并命名为two_level.py。
cp ./configs/tutorial/part1/simple.py ./configs/tutorial/part1/two_level.py1、导入caches
首先,在文件的顶部(m5.objects导入之后)添加以下内容,将caches.py文件中的名称导入到命名空间中。
from caches import *2、创建L1Cache
在创建CPU之后,创建L1缓存:
system.cpu.icache = L1ICache()
system.cpu.dcache = L1DCache()3、连接缓存和CPU
使用上述创建的连接函数将缓存连接到CPU上:
system.cpu.icache.connectCPU(system.cpu)
system.cpu.dcache.connectCPU(system.cpu)删除原文件中用于直接将缓存端口连接到内存总线上的两行。
system.cpu.icache_port = system.membus.cpu_side_ports
system.cpu.dcache_port = system.membus.cpu_side_ports4、创建L2XBar
L2缓存只允许一个端口与其连接,所以不能直接将L1缓存连接到L2缓存。因此,需要创建一个L2总线,将L1缓存间接连接到L2缓存。然后,可以使用辅助函数将L1缓存连接到L2总线。
system.l2bus = L2XBar()system.cpu.icache.connectBus(system.l2bus)
system.cpu.dcache.connectBus(system.l2bus)需要注意的是,在system.l2cache.connectMemSideBus之前,已经定义了system.membus = SystemXBar(),因此可以将其传递给system.l2cache.connectMemSideBus。文件中的其他部分保持不变。
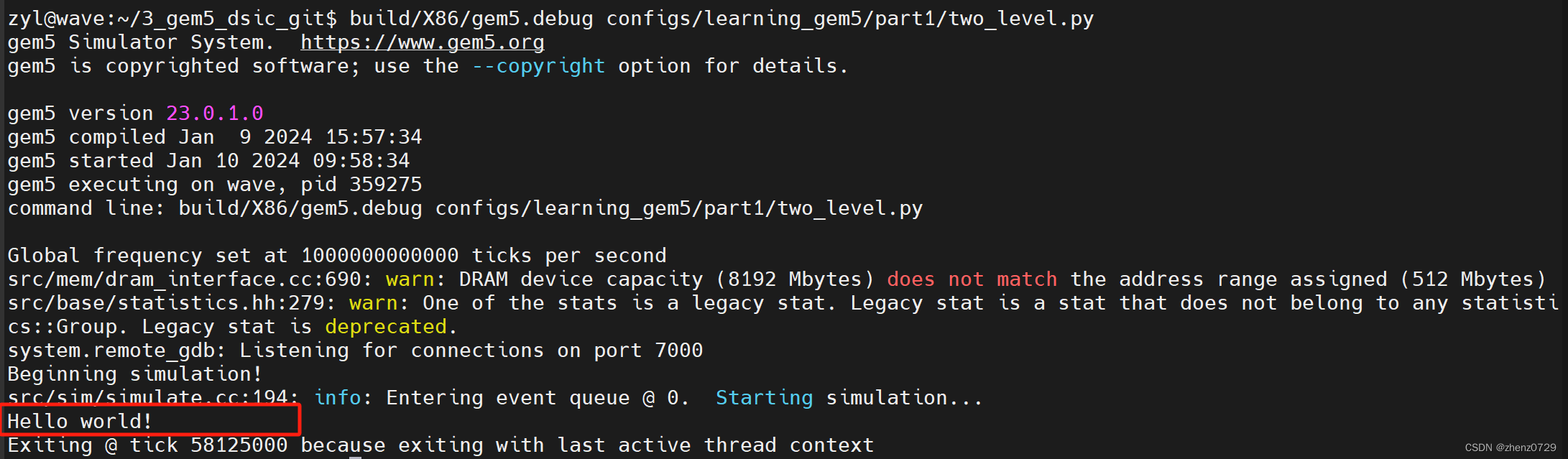
现在有了一个完整的配置,包含了一个两级缓存层次结构。如果运行当前文件,hello程序应该在57467000个时钟周期内完成。完整的脚本保存在gem5源代码的configs/learning_gem5/part1/two_level.py中。
完整代码
# import the m5 (gem5) library created when gem5 is built
import m5# import all of the SimObjects
from m5.objects import *
from gem5.runtime import get_runtime_isa# Add the common scripts to our path
m5.util.addToPath("../../")# import the caches which we made
from caches import *# import the SimpleOpts module
from common import SimpleOpts# Default to running 'hello', use the compiled ISA to find the binary
# grab the specific path to the binary
thispath = os.path.dirname(os.path.realpath(__file__))
default_binary = os.path.join(thispath,"../../../","tests/test-progs/hello/bin/x86/linux/hello",
)# Binary to execute
SimpleOpts.add_option("binary", nargs="?", default=default_binary)# Finalize the arguments and grab the args so we can pass it on to our objects
args = SimpleOpts.parse_args()# create the system we are going to simulate
system = System()# Set the clock frequency of the system (and all of its children)
system.clk_domain = SrcClockDomain()
system.clk_domain.clock = "1GHz"
system.clk_domain.voltage_domain = VoltageDomain()# Set up the system
system.mem_mode = "timing" # Use timing accesses
system.mem_ranges = [AddrRange("512MB")] # Create an address range# Create a simple CPU
system.cpu = X86TimingSimpleCPU()# Create an L1 instruction and data cache
system.cpu.icache = L1ICache(args)
system.cpu.dcache = L1DCache(args)# Connect the instruction and data caches to the CPU
system.cpu.icache.connectCPU(system.cpu)
system.cpu.dcache.connectCPU(system.cpu)# Create a memory bus, a coherent crossbar, in this case
system.l2bus = L2XBar()# Hook the CPU ports up to the l2bus
system.cpu.icache.connectBus(system.l2bus)
system.cpu.dcache.connectBus(system.l2bus)# Create an L2 cache and connect it to the l2bus
system.l2cache = L2Cache(args)
system.l2cache.connectCPUSideBus(system.l2bus)# Create a memory bus
system.membus = SystemXBar()# Connect the L2 cache to the membus
system.l2cache.connectMemSideBus(system.membus)# create the interrupt controller for the CPU
system.cpu.createInterruptController()
system.cpu.interrupts[0].pio = system.membus.mem_side_ports
system.cpu.interrupts[0].int_requestor = system.membus.cpu_side_ports
system.cpu.interrupts[0].int_responder = system.membus.mem_side_ports# Connect the system up to the membus
system.system_port = system.membus.cpu_side_ports# Create a DDR3 memory controller
system.mem_ctrl = MemCtrl()
system.mem_ctrl.dram = DDR3_1600_8x8()
system.mem_ctrl.dram.range = system.mem_ranges[0]
system.mem_ctrl.port = system.membus.mem_side_portssystem.workload = SEWorkload.init_compatible(args.binary)# Create a process for a simple "Hello World" application
process = Process()
# Set the command
# cmd is a list which begins with the executable (like argv)
process.cmd = [args.binary]
# Set the cpu to use the process as its workload and create thread contexts
system.cpu.workload = process
system.cpu.createThreads()# set up the root SimObject and start the simulation
root = Root(full_system=False, system=system)
# instantiate all of the objects we've created above
m5.instantiate()print("Beginning simulation!")
exit_event = m5.simulate()
print("Exiting @ tick %i because %s" % (m5.curTick(), exit_event.getCause()))
测试结果
四、Adding parameters to your script
在使用gem5进行实验时,为了避免每次想要使用不同的参数测试系统时都需要编辑配置脚本。可以在gem5配置脚本中添加命令行参数。
注意:由于配置脚本是Python代码,可以使用支持参数解析的Python库。尽管pyoptparse官方上已经被弃用,但因为gem5的最低Python版本曾经是2.5,gem5附带的许多配置脚本仍然使用它,而不是新版的pyargparse。现在gem5的最低Python版本是3.6,因此在编写不需要与当前gem5脚本交互的新脚本时,可以选择Python的pyargparse。
-
Pyargparse是Python标准库中的argparse模块,而pyoptparse是gem5自己实现的一个选项解析库。Pyargparse提供了更丰富的功能和更好的用户体验,并在Python社区中广泛使用。
-
Pyargparse在Python 2.7版本之后成为标准库的一部分,而pyoptparse是为了与较旧版本的Python兼容而创建的。由于gem5的最低Python版本现在是3.6,因此pyargparse是更好的选择,特别是对于编写新的脚本。
-
Pyargparse提供了更简洁、更直观的API,并且支持更丰富的参数类型和选项配置。它具有更好的错误处理和帮助信息生成。
为了向我们的两级缓存配置添加选项,在导入缓存之后,让我们添加一些选项。
import argparseparser = argparse.ArgumentParser(description='A simple system with 2-level cache.')
parser.add_argument("binary", default="", nargs="?", type=str,help="Path to the binary to execute.")
parser.add_argument("--l1i_size",help=f"L1 instruction cache size. Default: 16kB.")
parser.add_argument("--l1d_size",help="L1 data cache size. Default: Default: 64kB.")
parser.add_argument("--l2_size",help="L2 cache size. Default: 256kB.")options = parser.parse_args()如果想像上面所示的方式传递二进制文件的路径,并通过选项(options)使用它,可以将其指定为options.binary。
system.workload = SEWorkload.init_compatible(options.binary)使用build/X86/gem5.debug configs/learning_gem5/part1/two_level.py --help可以显示刚刚添加的选项。

接下来,需要将这些选项传递给配置脚本中创建的缓存。为了实现这一点,我们将简单地修改two_level_opts.py脚本,将选项作为参数传递给缓存的构造函数,并添加一个合适的构造函数。
system.cpu.icache = L1ICache(options)
system.cpu.dcache = L1DCache(options)
...
system.l2cache = L2Cache(options)在caches.py文件中,需要为每个类添加构造函数(Python中的__init__函数)。从基本L1缓存开始,因为没有任何适用于基本L1缓存的参数,所以只需添加一个空的构造函数。但在这种情况下,不能忘记调用父类的构造函数。如果省略对父类构造函数的调用,gem5的SimObject属性查找函数将失败,并且在尝试实例化缓存对象时会出现"RuntimeError: maximum recursion depth exceeded"的错误。因此,在L1Cache类中,需要在静态类成员之后添加以下内容。
def __init__(self, options=None):super(L1Cache, self).__init__()pass接下来,在L1ICache中,需要使用创建的选项(l1i_size)来设置大小。在下面的代码中,对于没有将选项传递给L1ICache构造函数和在命令行上没有指定选项的情况,有相应的保护代码。在这些情况下,将使用我们指定的大小默认值。
def __init__(self, options=None):super(L1ICache, self).__init__(options)if not options or not options.l1i_size:returnself.size = options.l1i_size可以在L1DCache使用相同的代码:
def __init__(self, options=None):super(L1DCache, self).__init__(options)if not options or not options.l1d_size:returnself.size = options.l1d_size在L2Cache使用相同的代码:
def __init__(self, options=None):super(L2Cache, self).__init__()if not options or not options.l2_size:returnself.size = options.l2_size测试
build/X86/gem5.debug configs/learning_gem5/part1/two_level.py --l2_size='2MB' --l1d_size='128kB'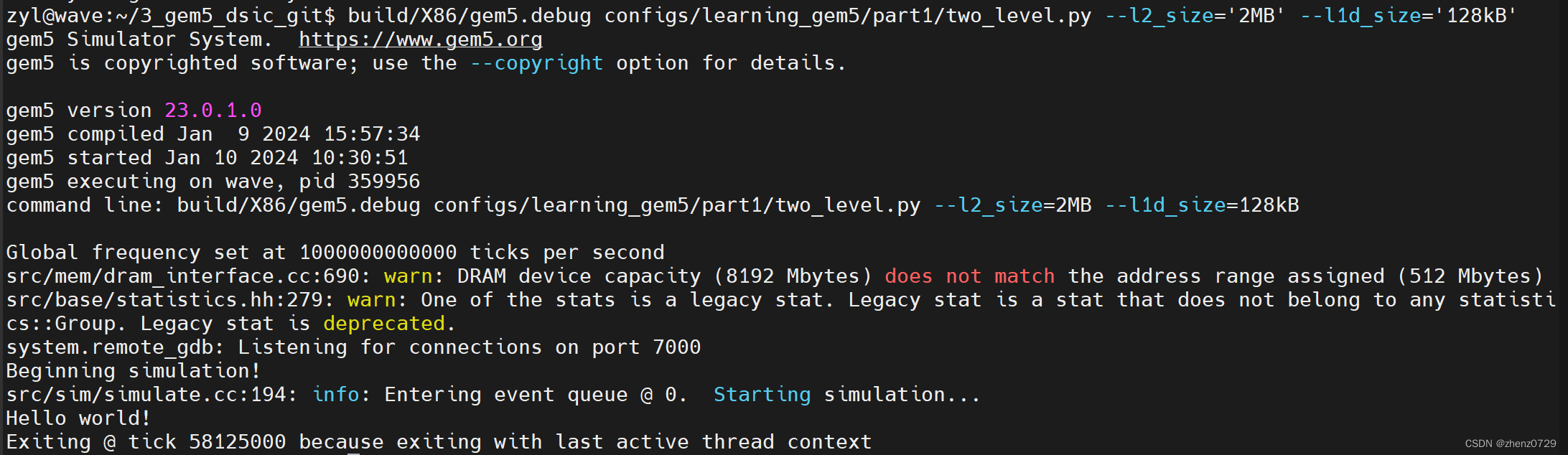
相关文章:
gem5学习(11):将缓存添加到配置脚本中——Adding cache to the configuration script
目录 一、Creating cache objects 1、Classic caches and Ruby 二、Cache 1、导入SimObject(s) 2、创建L1Cache 3、创建L1Cache子类 4、创建L2Cache 5、L1Cache添加连接函数 6、为L1ICache和L1DCache添加连接函数 7、为L2Cache添加内存侧和CPU侧的连接函数 完整代码…...

上海雏鸟科技无人机灯光秀跨年表演点亮三国五地夜空
2023年12月31日晚,五场别开生面的无人机灯光秀跨年表演在新加坡圣淘沙、印尼雅加达、中国江苏无锡、浙江衢州、陕西西安等五地同步举行。据悉,这5场表演背后均出自上海的一家无人机企业之手——上海雏鸟科技。 在新加坡圣淘沙西乐索海滩,500架…...

学生备考护眼台灯怎么样选择?2024五款好用台灯安利
随着现代人生活水平的提高,人们对保护视力和眼健康的重视也日益提高。然而,长时间使用电子设备和不合适的光线环境却成为了我们眼健康的潜在威胁。所以,为了有效地保护我们的眼睛,护眼台灯成为了许多人的选择。 护眼台灯作为一种能…...

Java学习,一文掌握Java之SpringBoot框架学习文集(6)
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

美团点评秋招前端测评分享
一. 选择题 1. 甲乙二人各自加工一批同样数量的零件,甲完成一半时,乙完成150个,甲全部完成时,乙完成全部的5/6,求这批零件一共有(C)个 A. 320 B. 400 C. 360 D. 420 2. 分析如…...
docker安装nodejs,并更改为淘宝源
拉取官方 Node.js 镜像 docker pull node:latest创建 Dockerfile,并更改 NPM 下载源为淘宝源,设置为全局持久化 # 使用最新版本的Node.js作为基础镜像 FROM node:latest# 设置工作目录为/app WORKDIR /app # 更改 NPM 下载源为淘宝源,并设置…...

Vue中的class和style绑定
聚沙成塔每天进步一点点 本文内容 ⭐ 专栏简介动态绑定class对象语法数组语法 动态绑定style对象语法多重值 ⭐ 写在最后 ⭐ 专栏简介 Vue学习之旅的奇妙世界 欢迎大家来到 Vue 技能树参考资料专栏!创建这个专栏的初衷是为了帮助大家更好地应对 Vue.js 技能树的学习…...

出版实务 | 出版物的成本及其构成
文章目录 出版物成本的总体构成直接成本开发成本制作成本 间接成本期间费用 本量利分析原则特点和作用变动成本项目固定成本项目本量利分析的基本公式及其应用定价发行折扣率销售数量单位销售收入销售收入总额单位销售税金销售税金总额变动成本总额单位变动成本固定成本总额单位…...
docker 部署项目的操作文档,安装nginx
目录 1 部署环境检查2 相关知识点2.1 docker默认镜像存放地址2.2 docker 的镜像都是tar 包?2.3 Docker-compose 是直接使用镜像创建容器?2.4 Docker Compose down 就是将容器删除?2.5 删除,会删除挂载嘛2.6 DockerFile 和 docker …...

spring boot 源码解读与原理分析
一、概述 Spring Boot是一个基于Spring框架的开源项目,旨在简化Spring应用程序的创建和部署。它通过自动配置和约定大于配置的原则,使得开发者能够快速构建独立、可运行的、生产级别的Spring应用程序。本文将对Spring Boot的源码进行解读,并…...

Python基础(二十四、JSON和pyecharts)
文章目录 一、JSON1.JSON介绍2.JSON格式数据转化3.示例 二、pyecharts1.安装pyecharts包2.查看官方示例 三、开发示例 一、JSON 1.JSON介绍 JSON是一种轻量级的数据交互格式,采用完全独立于编程语言的文本格式来存储和表示数据(就是字符串)…...

Java 并发之《深入理解 JVM》关于 volatile 累加示例的思考
在周志明老师的 《深入理解 JVM》一书中关于 volatile 关键字线程安全性有一个示例代码(代码有些许改动,语义一样): public class MyTest3 {private static volatile int race 0;private static void increase() {race;}public …...

GPM合并资料整理-GEM部分
一、性能数据上报项 1. CPU模块 上报键值说明采集平台cpu当前进程cpu使用率平均值Android & iOStotcpu系统cpu总使用率平均值Android & iOScpu_temp_maxcpu最高温度Androidcpu_temp_avgcpu温度平均值Androidgpu_temp_avggpu温度平均值Androidgpu_temp_maxgpu最高温度…...

STM32使用1.69寸液晶显示模块使用缓冲区实现快速刷新全屏显示字符串功能
一个1.69寸SPI接口的液晶显示模块,有320*24076800个点,每个点有2个字节表示RGB的颜色,所以需要153.6K个字节的数据来刷新全屏,如果SPI口输出数据不是高速并且不紧密排列的话,刷新就会比较慢,有从下到下的肉…...

SpringBoot AOP
依赖引入 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId> </dependency>代码实现 以给公共字段注入值为例 公共字段与枚举类: private LocalDateTime createT…...
鉴源论坛 · 观模丨浅谈Web渗透之信息收集(下)
作者 | 林海文 上海控安可信软件创新研究院汽车网络安全组 版块 | 鉴源论坛 观模 社群 | 添加微信号“TICPShanghai”加入“上海控安51fusa安全社区” 信息收集在渗透测试过程中是最重要的一环,“浅谈web渗透之信息收集”将通过上下两篇,对信息收集、…...
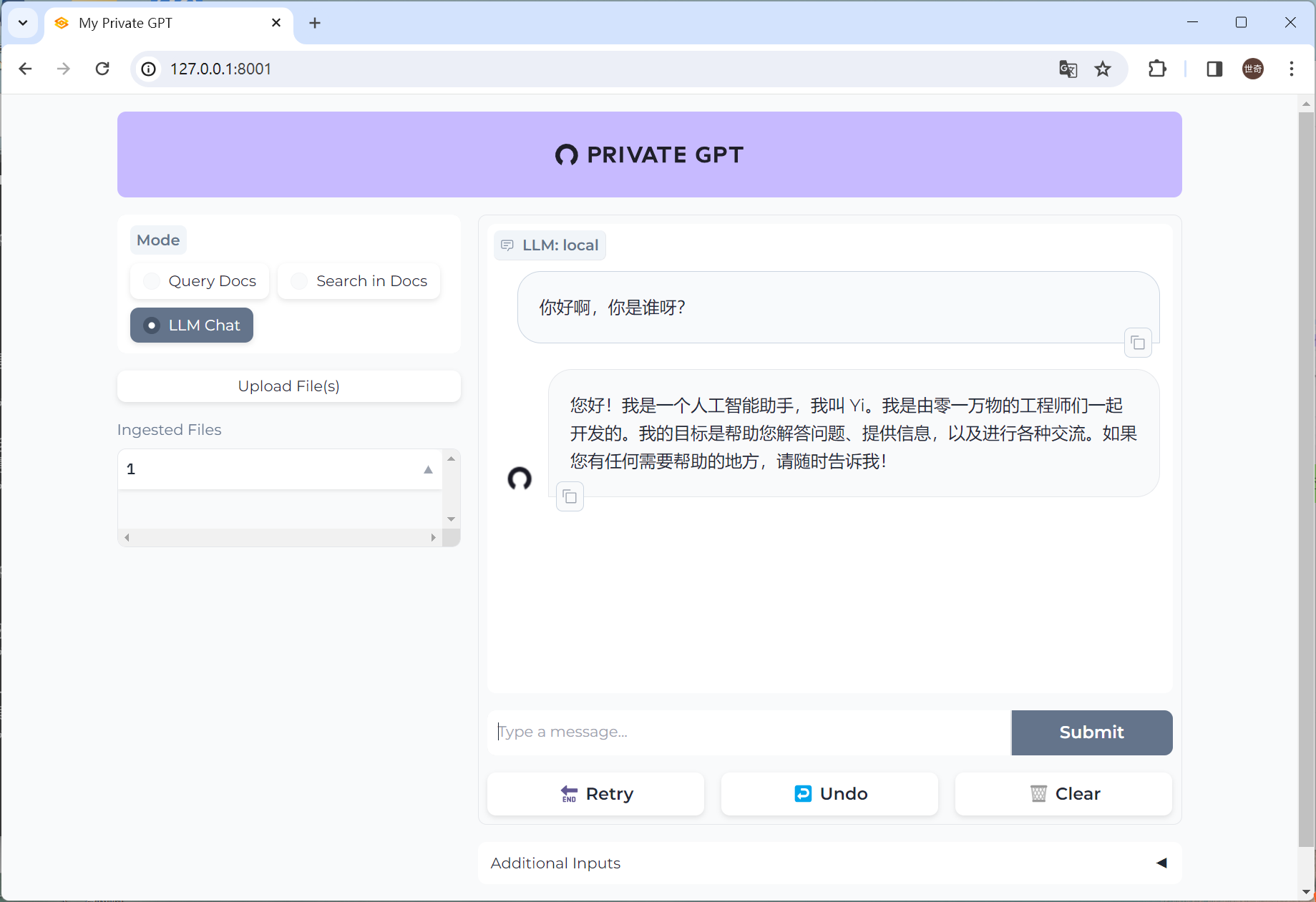
构建自己的私人GPT-支持中文
上一篇已经讲解了如何构建自己的私人GPT,这一篇主要讲如何让GPT支持中文。 privateGPT 本地部署目前只支持基于llama.cpp 的 gguf格式模型,GGUF 是 llama.cpp 团队于 2023 年 8 月 21 日推出的一种新格式。它是 GGML 的替代品,llama.cpp 不再…...
)
php将文本内容写入一个文件(面向过程写法)
一、封装2个函数,读写文件 /*** desc 读取文件内容* param string $filename* return array*/ private function readContent(string $filename): array {$text file_get_contents($filename);if (!$text) {return [];}$result json_decode($text,true);return…...

SPDK As IPU Firmware
对于不熟悉术语Infrastructure Processing Unit (IPU, 基础设施处理器)的同学,IPU是PCIe形态的卡,连接到主机系统后可以卸载主机的“基础设施”工作。它通常是面向云服务商或者超融合服务提供商的。对于熟悉SPDK的开发人员来理解,这些卡通常具…...

快速删除node_modules文件夹
文章目录 快速删除node_modules文件夹PowerShell命令快速删除使用npm提供的命令删除node_modules 快速删除node_modules文件夹 前端开发过程中,经常会遇到npm操作问题,有时候不得不需要删除node_modules目录下所有的文件,然后重新npm install npm cache clean --force rm -rf…...

【信息科学与工程学】【物理/化学科学和工程技术】知识体系 第四十篇 低空/高空领域中的力学知识 01
低空与高空(地球大气层内/地球大气层外)领域的核心力学知识。 编号:001 类别:流体力学 / 连续介质力学 领域:低空飞行器空气动力学 力学模型配方:Navier-Stokes方程组(可压缩/不可压缩) 数学分析:求解控制流体运动的质量、动量和能量守恒偏微分方程组。 定理/算法…...

DP/eDP协议深度解析--control symbol的插入时机与实现逻辑
1. 深入理解DP/eDP协议中的control symbol 第一次接触DP/eDP协议时,最让我困惑的就是那些神秘的control symbol。它们就像交通信号灯一样,指挥着视频数据的传输流程。简单来说,control symbol是嵌入在视频数据流中的特殊控制字符,…...

为什么你的NotebookLM要点召回率低于61.8%?——基于172份真实用户数据集的BERT-Chunk对齐缺陷报告
更多请点击: https://intelliparadigm.com 第一章:NotebookLM要点提取方法概览 核心原理与数据输入方式 NotebookLM 通过语义理解而非关键词匹配来提取要点,其底层依赖于 Google 的 Gemini 模型对上传文档(PDF、TXT、Google Doc…...

深度可分离CNN量化优化:PROM方法解析
1. 深度可分离CNN量化现状与挑战 在移动端和边缘计算场景中,卷积神经网络(CNN)的部署面临两大核心矛盾:模型精度与计算资源之间的权衡,以及理论计算量与实际硬件效率的差距。传统量化方法通常采用"一刀切"策略,对所有卷…...

谷歌与伊利诺伊大学联手,让AI研究助手学会“反思自己的错误“
这项由伊利诺伊大学厄巴纳-香槟分校与谷歌云AI研究院联合完成的研究,以预印本形式发表于2026年5月11日,论文编号为arXiv:2605.10899,感兴趣的读者可通过该编号检索完整论文。说到底,我们每个人在完成一件复杂任务时,都…...

RK3588平台LVGL 8.2移植实战:从FrameBuffer到DRM驱动优化
1. 项目概述与核心价值最近在RK3588平台上折腾嵌入式GUI,发现LVGL(Light and Graphics Library)这个开源图形库确实是个宝藏。它轻量、跨平台,而且从8.0版本开始,图形渲染效率和功能都有了质的飞跃。我手头正好有一块E…...

MATLAB仿真GPS调制和捕获
一,中频数据捕获: 当捕获通道状态空闲时,启动中频数据存储,此时根据当前要捕获的卫星的来选择射频通道,并将相应的载波频率和码频率写入寄存器中,使能存储操作;当一次捕获运算完成之后,需要重新存储中频数据。 卫星选择:初始化时,将所有卫星设置为待捕获状态,用一…...

宽带卫星通信系统同步与大规模阵列波束成形技术【附程序】
✨ 长期致力于符号定时恢复、频率估计、可变分数延迟滤波器、时延估计、真时延阵列研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于迭代短卷积的多…...

NotebookLM思维导图生成已进入「语义拓扑时代」:2024Q2最新Benchmark显示其节点关联准确率超越MindNode Pro 41.6%
更多请点击: https://intelliparadigm.com 第一章:NotebookLM思维导图生成已进入「语义拓扑时代」 传统基于关键词共现或规则模板的思维导图生成方式,正被 NotebookLM 的语义理解能力彻底重构。其底层 LLM 模型不再仅识别显式术语关系&#…...

VisualCppRedist AIO:Windows系统运行库终极解决方案
VisualCppRedist AIO:Windows系统运行库终极解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在安装新软件或游戏时,突…...