MongoDB聚合:$bucket
$bucket将输入文档按照指定的表达式和边界进行分组,每个分组为一个文档,称为“桶”,每个桶都有一个唯一的_id,其值为文件桶的下线。每个桶中至少要包含一个输入文档,也就是没有空桶。
使用
语法
{$bucket: {groupBy: <表达式>,boundaries: [ <下边界1>, <下边界2>, ... ],default: <literal>,output: {<output1>: { <$accumulator 表达式> },...<outputN>: { <$accumulator 表达式> }}}
}
groupBy
对文档进行分组的表达式。若指定字段路径,需要在字段名前加上美元符号$并用引号引起来,如:$field_name。
除非指定了default,否则所有输入文档的groupBy的值都必须在boundaries指定边界的范围内。
boundaries
分组边界数组,数组中相邻的两个值分别作为桶的上下边界,输入文档根据groupBy表达式的值,确定被分配到哪个桶。数组至少要有两个元素,并按照升序从左到右排列,除数值混合类型外(如:[10, NumberLong(20), NumberInt(30)]),数组元素类型必须一致。
举例:
一个数组 [ 0, 5, 10 ] 创建了两个桶:
[0,5),下界为 0,上界为 5。
[5,10),下界为 5,上界为 10。
default
可选,指定缺省桶的_id,不符合boundaries范围的文档都会放在缺省桶内。如果不指定default,所有输入文档的groupBy表达式的值必须落在boundaries区间,否则会抛出异常。
缺省值必须小于boundaries数组中最小的值或大于boundaries数组中的最大值。default值的类型可以不同于boundaries数组元素的类型。
out
可选,指定输出文档内容中除_id字段外要包含的其他字段,指定的字段必须使用汇总(累加器)表达式。
<outputfield1>: { <accumulator>: <expression1> },
...
<outputfieldN>: { <accumulator>: <expressionN> }
如果未指定output文档,默认返回桶内文档数量count字段,如果指定了output文档的字段,则只返回_id和指定的字段,count字段默认不会输出。
例子
按年分桶并对桶的结果进行筛选
创建artists集合并插入下面的记录
db.artists.insertMany([{ "_id" : 1, "last_name" : "Bernard", "first_name" : "Emil", "year_born" : 1868, "year_died" : 1941, "nationality" : "France" },{ "_id" : 2, "last_name" : "Rippl-Ronai", "first_name" : "Joszef", "year_born" : 1861, "year_died" : 1927, "nationality" : "Hungary" },{ "_id" : 3, "last_name" : "Ostroumova", "first_name" : "Anna", "year_born" : 1871, "year_died" : 1955, "nationality" : "Russia" },{ "_id" : 4, "last_name" : "Van Gogh", "first_name" : "Vincent", "year_born" : 1853, "year_died" : 1890, "nationality" : "Holland" },{ "_id" : 5, "last_name" : "Maurer", "first_name" : "Alfred", "year_born" : 1868, "year_died" : 1932, "nationality" : "USA" },{ "_id" : 6, "last_name" : "Munch", "first_name" : "Edvard", "year_born" : 1863, "year_died" : 1944, "nationality" : "Norway" },{ "_id" : 7, "last_name" : "Redon", "first_name" : "Odilon", "year_born" : 1840, "year_died" : 1916, "nationality" : "France" },{ "_id" : 8, "last_name" : "Diriks", "first_name" : "Edvard", "year_born" : 1855, "year_died" : 1930, "nationality" : "Norway" }
])
下面的操作对文档按照year_born字段进行分组放入桶中,并根据桶内文档数量进行筛选:
db.artists.aggregate( [// 阶段1{$bucket: {groupBy: "$year_born", // 分组字段boundaries: [ 1840, 1850, 1860, 1870, 1880 ], // 桶边界default: "Other", // 边界外的桶的IDoutput: { // 指定桶的输出文档"count": { $sum: 1 },"artists" :{$push: {"name": { $concat: [ "$first_name", " ", "$last_name"] },"year_born": "$year_born"}}}}},// 阶段2{$match: { count: {$gt: 3} } //过滤出文档数量大于3的桶}
] )
阶段1
$bucket阶段对文档根据year_born分组把文档放入桶,桶的边界为:
- [1840, 1850):下限
1840(含),上限1850(不含)。 - [1850, 1860):下限
1840(含),上限1850(不含)。 - [1860, 1870):下限
1840(含),上限1850(不含)。 - [1870, 1880):下限
1840(含),上限1850(不含)。 - 如果输入文档中
year_born字段不存在或者值在边界外,文档将被放到_id值为"other"的缺省桶中。
阶段1的output指定了输出文档的字段:
| 字段 | 描述 |
|---|---|
| _id | 包含了桶的边界下限 |
| count | 桶内文档数量 |
| artists | 文档数组,包含了桶内所有文章,每个文档的artists字段都包含了拼接后的first_name和last_name,以及`year_born’字段 |
通过该阶段后,下面的文档进入下个阶段:
{ "_id" : 1840, "count" : 1, "artists" : [ { "name" : "Odilon Redon", "year_born" : 1840 } ] }
{ "_id" : 1850, "count" : 2, "artists" : [ { "name" : "Vincent Van Gogh", "year_born" : 1853 },{ "name" : "Edvard Diriks", "year_born" : 1855 } ] }
{ "_id" : 1860, "count" : 4, "artists" : [ { "name" : "Emil Bernard", "year_born" : 1868 },{ "name" : "Joszef Rippl-Ronai", "year_born" : 1861 },{ "name" : "Alfred Maurer", "year_born" : 1868 },{ "name" : "Edvard Munch", "year_born" : 1863 } ] }
{ "_id" : 1870, "count" : 1, "artists" : [ { "name" : "Anna Ostroumova", "year_born" : 1871 } ] }
阶段2
$match阶段使用count>3的条件,对$bucket阶段out的文档进行筛选,筛选后的结果如下:
{ "_id" : 1860, "count" : 4, "artists" :[{ "name" : "Emil Bernard", "year_born" : 1868 },{ "name" : "Joszef Rippl-Ronai", "year_born" : 1861 },{ "name" : "Alfred Maurer", "year_born" : 1868 },{ "name" : "Edvard Munch", "year_born" : 1863 }]
}
使用$bucket和$facet按多个字段分类
使用$facet可以在一个阶段执行多个$bucket聚合。使用mongosh创建artwork集合并添加下面的文档:
db.artwork.insertMany([{ "_id" : 1, "title" : "The Pillars of Society", "artist" : "Grosz", "year" : 1926,"price" : NumberDecimal("199.99") },{ "_id" : 2, "title" : "Melancholy III", "artist" : "Munch", "year" : 1902,"price" : NumberDecimal("280.00") },{ "_id" : 3, "title" : "Dancer", "artist" : "Miro", "year" : 1925,"price" : NumberDecimal("76.04") },{ "_id" : 4, "title" : "The Great Wave off Kanagawa", "artist" : "Hokusai","price" : NumberDecimal("167.30") },{ "_id" : 5, "title" : "The Persistence of Memory", "artist" : "Dali", "year" : 1931,"price" : NumberDecimal("483.00") },{ "_id" : 6, "title" : "Composition VII", "artist" : "Kandinsky", "year" : 1913,"price" : NumberDecimal("385.00") },{ "_id" : 7, "title" : "The Scream", "artist" : "Munch", "year" : 1893/* No price*/ },{ "_id" : 8, "title" : "Blue Flower", "artist" : "O'Keefe", "year" : 1918,"price" : NumberDecimal("118.42") }
])
下面的操作在一个$facet阶段中使用两个$bucket,一个使用price字段,另一个使用year字段分组:
db.artwork.aggregate( [{$facet: { // 顶层 $facet 阶段"price": [ // 输出字段1{$bucket: {groupBy: "$price", // 分组字段boundaries: [ 0, 200, 400 ], // 桶边界数组default: "Other", // 缺省桶Idoutput: { // 桶输出内容"count": { $sum: 1 },"artwork" : { $push: { "title": "$title", "price": "$price" } },"averagePrice": { $avg: "$price" }}}}],"year": [ // 输出字段2{$bucket: {groupBy: "$year", // 分组字段boundaries: [ 1890, 1910, 1920, 1940 ], // 桶边界数组default: "Unknown", // 缺省桶Idoutput: { // 桶输出内容"count": { $sum: 1 },"artwork": { $push: { "title": "$title", "year": "$year" } }}}}]}}
] )
方面1
第一个方面按price对输入文档进行分组,桶的边界有:
- [0,200),含下限0,不含上限200。
- [200, 400),含下限200,不含上限400。
- “Other”,缺省桶包含了所有不在以上桶内的文档。
$bucket阶段的输出out文档包含下面的字段:
| 字段 | 描述 |
|---|---|
| _id | 桶边界下限值 |
| count | 桶内文档数量 |
| artwork | 包含所有艺术品信息的文档数组 |
| averagePrice | 使用$avg运算符显示水桶中所有艺术品的平均价格。 |
方面2
第二个方面按year对输入文档进行分组,桶的边界有:
- [1890, 1910),含下限1890,不含上限1910。
- [1910, 1920),含下限1890,不含上限1910。
- [1920, 1940),含下限1890,不含上限1910。
- “Unknown”,缺省桶包含了所有不在以上桶内的文档。
$bucket阶段的输出out文档包含下面的字段:
| 字段 | 描述 |
|---|---|
| count | 桶内文档数量 |
| artwork | 桶内每件艺术品信息的文件数组。 |
输出
操作返回下面的结果:
{"price" : [ // Output of first facet{"_id" : 0,"count" : 4,"artwork" : [{ "title" : "The Pillars of Society", "price" : NumberDecimal("199.99") },{ "title" : "Dancer", "price" : NumberDecimal("76.04") },{ "title" : "The Great Wave off Kanagawa", "price" : NumberDecimal("167.30") },{ "title" : "Blue Flower", "price" : NumberDecimal("118.42") }],"averagePrice" : NumberDecimal("140.4375")},{"_id" : 200,"count" : 2,"artwork" : [{ "title" : "Melancholy III", "price" : NumberDecimal("280.00") },{ "title" : "Composition VII", "price" : NumberDecimal("385.00") }],"averagePrice" : NumberDecimal("332.50")},{// Includes documents without prices and prices greater than 400"_id" : "Other","count" : 2,"artwork" : [{ "title" : "The Persistence of Memory", "price" : NumberDecimal("483.00") },{ "title" : "The Scream" }],"averagePrice" : NumberDecimal("483.00")}],"year" : [ // Output of second facet{"_id" : 1890,"count" : 2,"artwork" : [{ "title" : "Melancholy III", "year" : 1902 },{ "title" : "The Scream", "year" : 1893 }]},{"_id" : 1910,"count" : 2,"artwork" : [{ "title" : "Composition VII", "year" : 1913 },{ "title" : "Blue Flower", "year" : 1918 }]},{"_id" : 1920,"count" : 3,"artwork" : [{ "title" : "The Pillars of Society", "year" : 1926 },{ "title" : "Dancer", "year" : 1925 },{ "title" : "The Persistence of Memory", "year" : 1931 }]},{// Includes documents without a year"_id" : "Unknown","count" : 1,"artwork" : [{ "title" : "The Great Wave off Kanagawa" }]}]
}
注意
跟很多阶段类似,$bucket阶段也有100M内存的限制,缺省情况下如果超出100M将会抛出异常。可使用allowDiskUse选项,让聚合管道阶段将数据写入临时文件。
相关文章:

MongoDB聚合:$bucket
$bucket将输入文档按照指定的表达式和边界进行分组,每个分组为一个文档,称为“桶”,每个桶都有一个唯一的_id,其值为文件桶的下线。每个桶中至少要包含一个输入文档,也就是没有空桶。 使用 语法 {$bucket: {groupBy…...

从优化设计到智能制造:生成式AI在可持续性3D打印中的潜力和应用
可持续性是现代工业中一个紧迫的问题,包括 3D 打印领域。为了满足环保制造实践日益增长的需求,3D 打印已成为一种有前景的解决方案。然而,要使 3D 打印更具可持续性,还存在一些需要解决的挑战。生成式人工智能作为一股强大的力量&…...
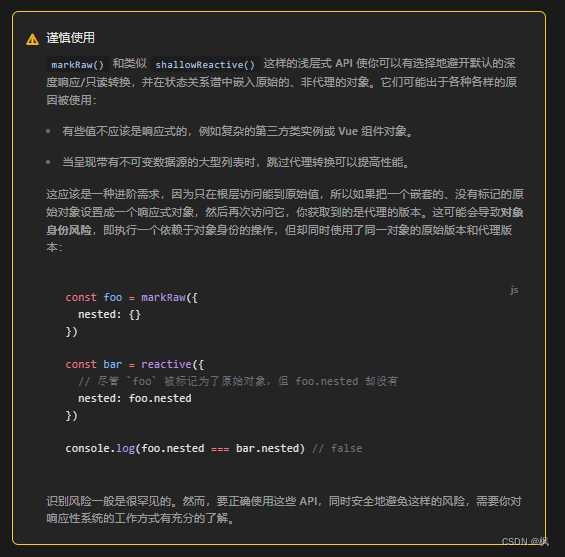
vue3 响应式api中特殊的api
系列文章目录 TypeScript 从入门到进阶专栏 文章目录 系列文章目录一、shallowRef()二、triggerRef()三、customRef()四、shallowReactive()五、shallowReadonly()六、toRaw()七、markRaw()八、effectScope()九、getCurrentScope() 一、shallowRef() shallowRef()是一个新的响…...

【大厂算法面试冲刺班】day2:合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 递归 class Solution {public ListNode mergeTwoLists(ListNode l1, ListNode l2) {if (l1 null) {return l2;}else if (l2 null) {return l1;}else if (l1.val < l2.…...
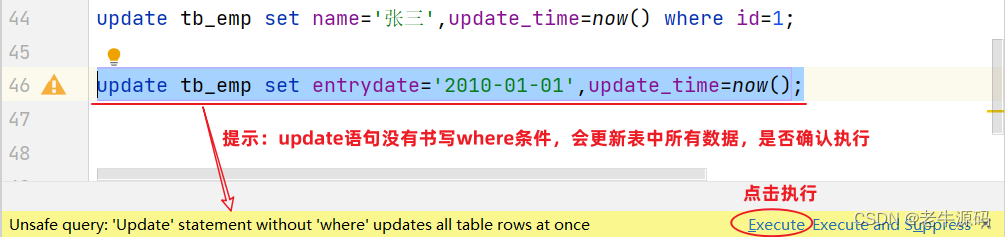
【JaveWeb教程】(19) MySQL数据库开发之 MySQL数据库操作-DML 详细代码示例讲解
目录 3. 数据库操作-DML3.1 增加(insert)3.2 修改(update)3.3 删除(delete)3.4 总结 3. 数据库操作-DML DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。 添加数据(INSERT)修改数据…...

Web前端篇——ElementUI之el-scrollbar + el-backtop + el-timeline实现时间轴触底刷新和一键返回页面顶部
ElementUI之el-scrollbar el-backtop el-timeline实现时间轴触底刷新和一键返回页面顶部。 背景:ElementUI的版本(vue.global.js 3.2.36, index.css 2.4.4, index.full.js 2.4.4) 废话不多说,先看动…...

CAS-ABA问题编码实战
多线程情况下演示AtomicStampedReference解决ABA问题 package com.nanjing.gulimall.zhouyimo.test;import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicInteger; import java.util.concurrent.atomic.AtomicStampedReference;/*** @author zho…...

Linux 常用进阶指令
我是南城余!阿里云开发者平台专家博士证书获得者! 欢迎关注我的博客!一同成长! 一名从事运维开发的worker,记录分享学习。 专注于AI,运维开发,windows Linux 系统领域的分享! 其他…...
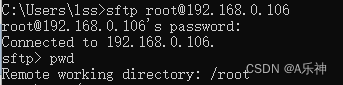
windows通过ssh连接Liunx服务器并实现上传下载文件
连接ssh 输入:ssh空格用户名ip地址,然后按Enter 有可能出现下图提示,输入yes 回车即可 输入 password ,注意密码是不显示的,输入完,再按回车就行了 以上是端口默认22情况下ssh连接,有些公司它…...

【K8S 存储卷】K8S的存储卷+PV/PVC
目录 一、K8S的存储卷 1、概念: 2、挂载的方式: 2.1、emptyDir: 2.2、hostPath: 2.3、NFS共享存储: 二、PV和PVC: 1、概念 2、请求方式 3、静态请求流程图: 4、PV和PVC的生命周期 5、…...

工业智能网关如何保障数据通信安全
工业智能网关是组成工业物联网的重要设备,不仅可以起到数据交换、通信、边缘计算的功能,还可以发挥数据安全保障功能,保障工业物联网稳定、可持续。本篇就为大家简单介绍一下工业智能网关增强和确保数据通信安全的几种措施: 1、软…...
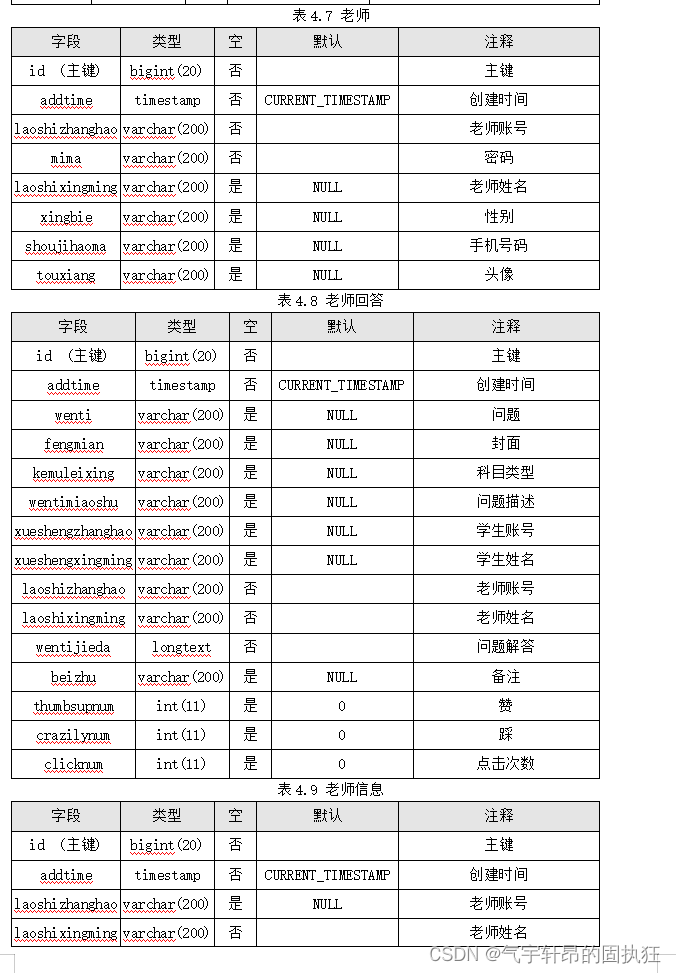
基于Springboot的课程答疑系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的课程答疑系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构&…...

操作系统 内存相关
0 内存 cpu和内存的关系 内存覆盖 内存的覆盖是一种在程序运行时将部分程序和数据分为固定区和覆盖区的技术。这种技术的主要目的是为了解决程序较大,无法一次性装入内存导致无法运行的问题。 具体来说,内存的覆盖技术将用户空间划分为以下两个部分&…...
【模拟IC学习笔记】 PSS和Pnoise仿真
目录 PSS Engine Beat frequency Number of harmonics Accuracy Defaults Run tranisent?的3种设置 Pnoise type noise Timeaverage sampled(jitter) Edge Crossing Edge Delay Sampled Phase sample Ratio 离散时间网络(开关电容电路)的噪声仿真方法 PSS PSS…...

IPv6邻居发现协议(NDP)---路由发现
IPv6路由发现(前缀公告) 邻居发现 邻居发现协议NDP(Neighbor Discovery Protocol)是IPv6协议体系中一个重要的基础协议。邻居发现协议替代了IPv4的ARP(Address Resolution Protocol)和ICMP路由器发现(Router Discovery),它定义了使用ICMPv6报文实现地址解析,跟踪邻…...

OpenPLC v3 代码结构
OpenPLC v3 是一个基于 C 的开源实时自动化平台,主要用于控制和自动化行业中的设备。该项目具有以下主要模块: 1. Core:核心模块,提供数据结构和算法实现。 2. Master:主设备模块,实现与从设备通信的接口。…...

安全防御之备份恢复技术
随着计算机和网络的不断普及,人们更多的通过网络来传递大量信息。在网络环境下,还有各种各样的病毒感染、系统故障、线路故障等,使得数据信息的安全无法得到保障。由于安全风险的动态性,安全不是绝对的,信息系统不可能…...

条款39:明智而审慎地使用private继承
1.前言 在之前挑款32曾讨论了C如何将public继承视为is-a关系,在那个例子中我们有个继承体系,其中class Student以public形式继承class Person,于是编译器在必要时刻将Student转换为Persons。。现在,我在以原先那个例子࿰…...
查询优化概述)
【数据库原理】(20)查询优化概述
查询优化是关系数据库系统设计和实现中的核心部分,对提高数据库性能、减少资源消耗、提升用户体验有着重要影响。虽然挑战重重,但凭借坚实的理论基础和先进的技术手段,关系数据库在查询优化方面有着广阔的发展空间。 一.查询中遇到的问题 数…...
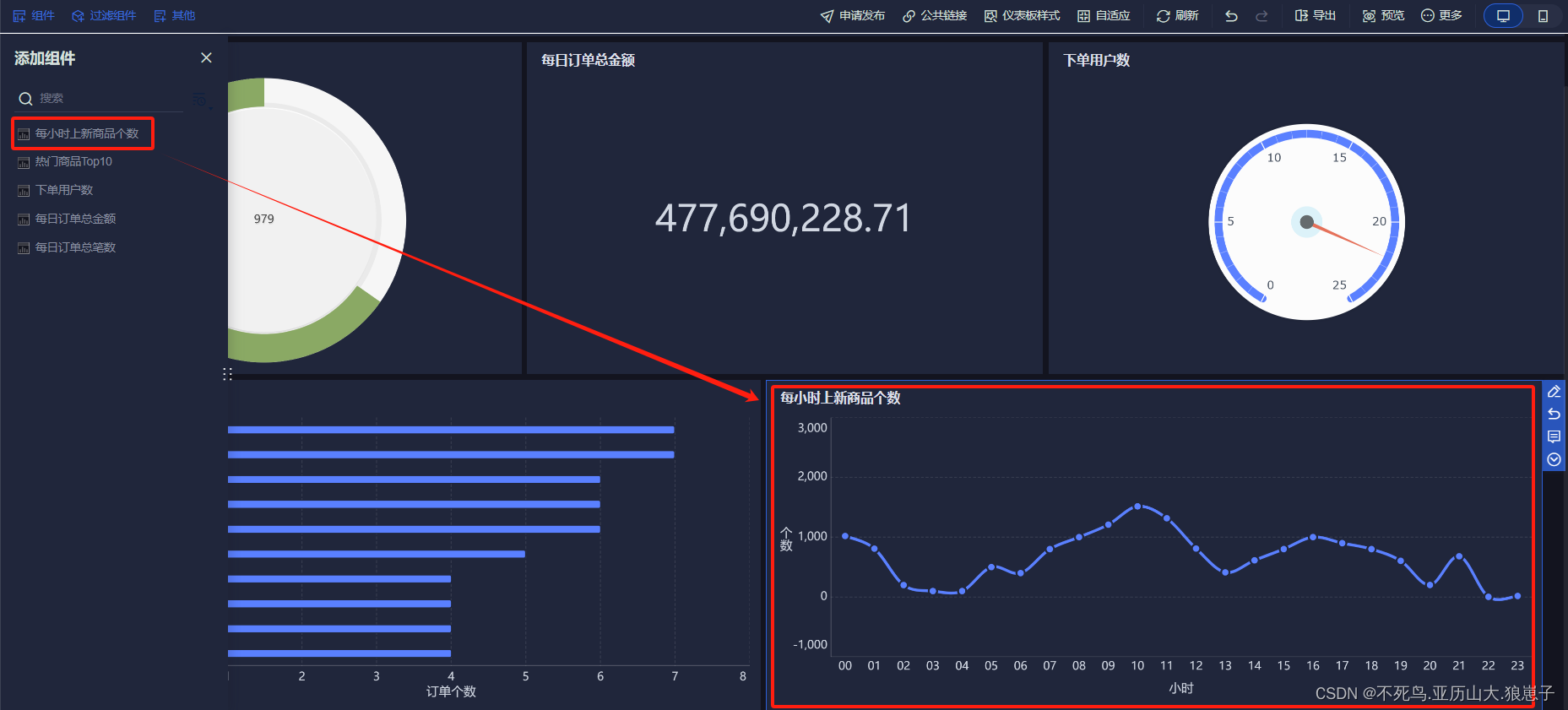
FineBI实战项目一(18):每小时上架商品个数分析开发
点击新建组件,创建每小时上架商品个数组件。 选择线图,拖拽cnt(总数)到纵轴,拖拽hourStr到横轴。 修改横轴和纵轴的文字。 调节连线样式。 添加组件到仪表板。...

Purpur性能调优实战指南:7大核心优化方案深度解析
Purpur性能调优实战指南:7大核心优化方案深度解析 【免费下载链接】Purpur Purpur is a drop-in replacement for Paper servers designed for configurability, and new fun and exciting gameplay features. 项目地址: https://gitcode.com/gh_mirrors/pu/Purpu…...

HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁
HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为《Honey Select 2》…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...

UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界
UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA UABEA(Unity Asset Bundle Extractor Avalonia&#…...
)
别再点‘忽略’了!开机弹出Visual C++ Runtime Library错误的终极排查指南(附Adobe软件关联排查)
Visual C Runtime Library错误:从崩溃到根治的全链路解决方案 每次开机时那个刺眼的Visual C Runtime Library错误弹窗,就像一位不请自来的访客,固执地打断你的工作节奏。对于依赖Adobe Creative Cloud或达芬奇等创意工具的专业人士来说&…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

Carapace:统一跨Shell命令行补全的Go语言引擎
1. 项目概述:一个为Shell而生的全能补全引擎 如果你和我一样,每天有超过一半的工作时间是在终端里度过的,那你一定对命令行补全这件事又爱又恨。爱的是,一个恰到好处的补全能让你行云流水,效率倍增;恨的是…...

Arm Neoverse-V2/V3缓存与内存参数优化指南
1. Arm Neoverse-V2/V3集群架构概述Arm Neoverse系列处理器作为数据中心和基础设施领域的重要计算引擎,其V2/V3代架构在缓存子系统和内存管理方面进行了显著优化。作为从业多年的系统架构师,我认为理解这些处理器的参数配置对性能调优至关重要。Neoverse…...