pytorch12:GPU加速模型训练

目录
- 1、CPU与GPU
- 2、数据迁移至GPU
- 2.1 to函数使用方法
- 3、torch.cuda常用方法
- 4、多GPU并行运算
- 4.1 torch.nn.DataParallel
- 4.2 torch.distributed加速并行训练
- 5、gpu总结
1、CPU与GPU
CPU(Central Processing Unit, 中央处理器):主要包括控制器和运算器
GPU(Graphics Processing Unit, 图形处理器):处理统一的,无依赖的大规模数据运算
cpu的控制单元和存储单元要比GPU多,比如我们加载的数据缓存一般都在cpu当中,GPU的计算单元到比cpu多,在算力方面要远远超过cpu
注意:运算的数据必须在同一个处理器上,如果一个数据在cpu一个在gpu上,则两个数据无法进行相关的数学运算。

2、数据迁移至GPU
如果想要将数据进行处理器迁移,所使用的工具是to函数,并在中间选择想要迁移的处理器类型。
data一般有两种数据类型:tensor、module。

2.1 to函数使用方法
to函数:转换数据类型/设备
- tensor.to(args, kwargs)
- module.to(args, kwargs)
区别: 张量不执行inplace,要构建一个新的张量,模型执行inplace,不需要等号赋值。
inplace操作:"inplace"操作是指对数据进行原地修改的操作,即直接在原始数据上进行更改,而不是创建一个新的副本。在深度学习框架中,许多函数和方法都支持"inplace"操作,这意味着它们可以直接修改输入的张量或数组,而不需要额外的内存来存储结果。

1、将tensor数据放到gpu上
import torch
import torch.nn as nn
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #调用gpu只需要一行代码
# ========================== tensor to cuda
# flag = 0
flag = 1
if flag:x_cpu = torch.ones((3, 3))print("x_cpu:\ndevice: {} is_cuda: {} id: {}".format(x_cpu.device, x_cpu.is_cuda, id(x_cpu)))x_gpu = x_cpu.to(device)print("x_gpu:\ndevice: {} is_cuda: {} id: {}".format(x_gpu.device, x_gpu.is_cuda, id(x_gpu)))
打印结果:
发现数据id地址发生了变化,说明创建的新的变量存储数据。

2、module转移到gpu上
flag = 1
if flag:net = nn.Sequential(nn.Linear(3, 3))print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))net.to(device)print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))
打印结果:
id地址没有发生变化,执行了inplace操作。

3、torch.cuda常用方法
- torch.cuda.device_count():计算当前可见可用gpu数
- torch.cuda.get_device_name():获取gpu名称
- torch.cuda.manual_seed():为当前gpu设置随机种子
- torch.cuda.manual_seed_all():为所有可见可用gpu设置随机种子
- torch.cuda.set_device():设置主gpu为哪一个物理gpu(不推荐)
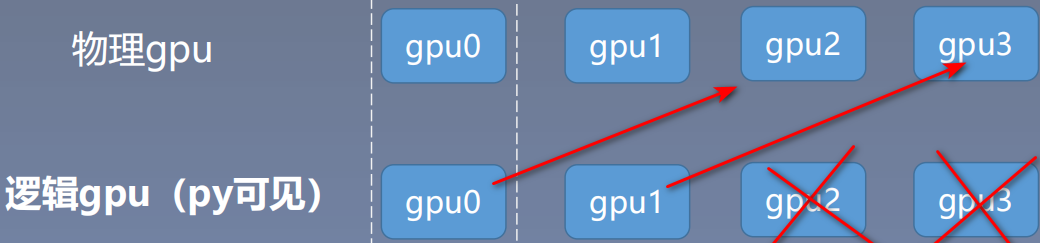
推荐:== os.environ.setdefault(“CUDA_VISIBLE_DEVICES”, “2, 3”)==
该方法要如何理解呢?
需要理解两个概念:物理gpu和逻辑gpu;物理gpu是我们电脑真实存在的0、1、2、3等显卡,逻辑gpu是Python脚本可见的gpu。
当我们设置2,3时,我们物理gpu连接的是我们真实电脑存在的第2号和第3号gpu。
4、多GPU并行运算
分发 → 并行运算 →结果回收
在AlexNet这篇网络中,使用了多gpu训练,在第三层卷积开始,每个特征图的信息都是从2个gpu获取,在2个gpu提取特征并进行训练,最后再将信息汇总到一起;

4.1 torch.nn.DataParallel
torch.nn.DataParallel(module, device_ids = None, output_device=None, dim=0)
功能:包装模型,实现分发并行机制;假设我们batch_size=16,如果有两块gpu,在训练的时候将会将数据平均分发到每一个gpu上进行训练,也就是每一块gpu训练8个数据。
主要参数:
- module: 需要包装分发的模型
- device_ids : 可分发的gpu,默认分发到所有可见可用gpu
- output_device: 结果输出设备,也就是主gpu上
代码实现:
# -*- coding: utf-8 -*-# 导入必要的库
import os
import numpy as np
import torch
import torch.nn as nn# ============================ 手动选择gpu
# flag变量用于控制是否手动选择GPU或根据内存情况自动选择主GPU
# 如果flag为1,则执行以下代码块
flag = 1
if flag:# 手动选择GPU列表,这里选择第一个GPUgpu_list = [0]# 将GPU列表转换为逗号分隔的字符串形式,并设置环境变量CUDA_VISIBLE_DEVICESgpu_list_str = ','.join(map(str, gpu_list))os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)# 根据CUDA是否可用选择设备,如果可用则使用cuda,否则使用cpudevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# ============================ 依内存情况自动选择主gpu
# flag变量用于控制是否根据显存情况自动选择主GPU
# 如果flag为1,则执行以下代码块
flag = 1
if flag:# 定义一个函数get_gpu_memory,用于获取GPU的显存情况def get_gpu_memory():import platformif 'Windows' != platform.system():import osos.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]os.system('rm tmp.txt')else:memory_gpu = Falseprint("显存计算功能暂不支持windows操作系统")return memory_gpu# 调用get_gpu_memory函数获取显存情况,如果显存可用则执行以下代码块gpu_memory = get_gpu_memory()if gpu_memory:print("\ngpu free memory: {}".format(gpu_memory))# 根据显存情况对GPU列表进行排序,取排序后的第一个GPU作为主GPU,并设置环境变量CUDA_VISIBLE_DEVICESgpu_list = np.argsort(gpu_memory)[::-1]gpu_list_str = ','.join(map(str, gpu_list))os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")class FooNet(nn.Module):def __init__(self, neural_num, layers=3):# 初始化FooNet类,继承自nn.Module,用于构建神经网络模型super(FooNet, self).__init__()# 定义一个线性层列表,用于存储多个线性层,层数为layers个self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])def forward(self, x):# 前向传播方法,输入参数为x,输出结果为x经过多个线性层和ReLU激活函数后的结果print("\nbatch size in forward: {}".format(x.size()[0])) # 打印输入张量的batch sizefor (i, linear) in enumerate(self.linears): # 遍历线性层列表中的每个元素进行循环迭代x = linear(x) # 将输入张量传入线性层进行计算,得到输出结果x'x = torch.relu(x) # 对输出结果应用ReLU激活函数,得到新的输出结果x''return x # 返回新的输出结果x''if __name__ == "__main__":# 如果是主程序运行,则执行以下代码块batch_size = 16 # 设置批量大小为16inputs = torch.randn(batch_size, 3) # 生成一个形状为(batch_size, 3)的随机张量作为输入数据labels = torch.randn(batch_size, 3) # 生成一个形状为(batch_size, 3)的随机张量作为标签数据inputs, labels = inputs.to(device), labels.to(device)# modelnet = FooNet(neural_num=3, layers=3)net = nn.DataParallel(net)net.to(device)# trainingfor epoch in range(1):outputs = net(inputs)print("model outputs.size: {}".format(outputs.size()))print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))print("device_count :{}".format(torch.cuda.device_count()))
打印结果:

4.2 torch.distributed加速并行训练
DataParallel: 单进程控制多GPU
DistributedDataParallel: 多进程控制多GPU,一起训练模型
和单进程训练不同的是,多进程训练需要注意一下事项:
- 在喂数据的时候,一个batch被分到了多个进程,每个进程在取数据的时候要确保拿到的是不同的数据(DistributedSampler)
- 要告诉每个进程自己是谁,使用哪块GPU(args.local_rank)
- 在做BN的时候注意同步数据。
使用方式
在多进程的启动方面,我们无需自己手写multiprocess进行一系列复杂的CPU、GPU分配任务,PyTorch为我们提供了一个很方便的启动器torch.distributed.launch用于启动文件,所以我们运行训练代码的方式就变成这样:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
初始化
在启动器为我们启动python脚本后,在执行过程中,启动器会将当前进行的index通过参数传递给python,我们可以这样获得当前进程的index:即通过参数local_rank来告诉我们当前进程使用的是哪个GPU,用于我们在每个进程中指定不同的device:
def parse():parser = argparse.ArgumentParser()parser.add_argument('--local_rank', type=int, default=0, help='node rank for distributed training')args = parser.parse_args()return argsdef main():args = parse()torch.cuda.set_device(args.local_rank)torch.distributed.init_process_group('nccl',init_method='env://')device = torch.device(f'cuda:{args.local_rank}')
其中torch.distributed.init_process_group用于初始化GPU通信方式(NCLL)和参数的获取方式(env代表通过环境变量)。使用init_process_group设置GPU之间通信使用的后端和端口,通过NCCL实现GPU通信
Dataloader
在我们初始化data_loader的时候需要使用到torch.utils.data.distributed.DistributedSampler这个特性:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
这样就能给每个进程一个不同的sampler,告诉每个进程自己分别取哪些数据
模型的初始化
和nn.DataParallel的方式一样,
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
使用DistributedDataParallel包装模型, 它能帮助我们为不同GPU上求得的提取进行all reduce(即汇总不同GPU计算所得的梯度,并同步计算结果)。all reduce 后不同GPU中模型的梯度均为all reduce之前各GPU梯度的均值。
5、gpu总结
我们在模型训练当中想要提高训练速率,需要在以下三个地方添加gpu
- 将模型放到gpu上:resnet18_ft.to(device)
- 训练过程中数据: inputs, labels = inputs.to(device), labels.to(device)
- 验证过程中数据: inputs, labels = inputs.to(device), labels.to(device)
常见的gpu报错:
报错1:
RuntimeError: Attempting to deserialize object on a CUDA device but
torch.cuda.is_available() is False. If you are running on a CPU -only machine, please
use torch.load with map_location=torch.device(‘cpu’) to map your storages to the
CPU.
解决: torch.load(path_state_dict, map_location=“cpu”)
报错2:RuntimeError: Error(s) in loading state_dict for FooNet:
Missing key(s) in state_dict: “linears.0.weight”, “linears.1.weight”, “linears.2.weight”.
Unexpected key(s) in state_dict: “module.linears.0.weight”,
“module.linears.1.weight”, “module.linears.2.weight”.
解决:
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict_load.items ():
namekey = k[7:] if k.startswith(‘module.’) else k
new_state_dict[namekey] = v

相关文章:
pytorch12:GPU加速模型训练
目录 1、CPU与GPU2、数据迁移至GPU2.1 to函数使用方法 3、torch.cuda常用方法4、多GPU并行运算4.1 torch.nn.DataParallel4.2 torch.distributed加速并行训练 5、gpu总结 1、CPU与GPU CPU(Central Processing Unit, 中央处理器):主要包括控制…...

P1603 斯诺登的密码题解
题目 (1)找出句子中所有用英文表示的数字(≤20),列举在下: 正规:one two three four five six seven eight nine ten eleven twelve thirteen fourteen fifteen sixteen seventeen eighteen nineteen twenty 非正规…...
YOLOv8 + openVINO 多线程数据读写顺序处理
多线程数据读写顺序处理 一个典型的生产者-消费者模型,在这个模型中,多个工作线程并行处理从共享队列中获取的数据,并将处理结果以保持原始顺序的方式放入另一个队列。 多线程处理模型,具体细节如下: 1.数据:数据里必…...
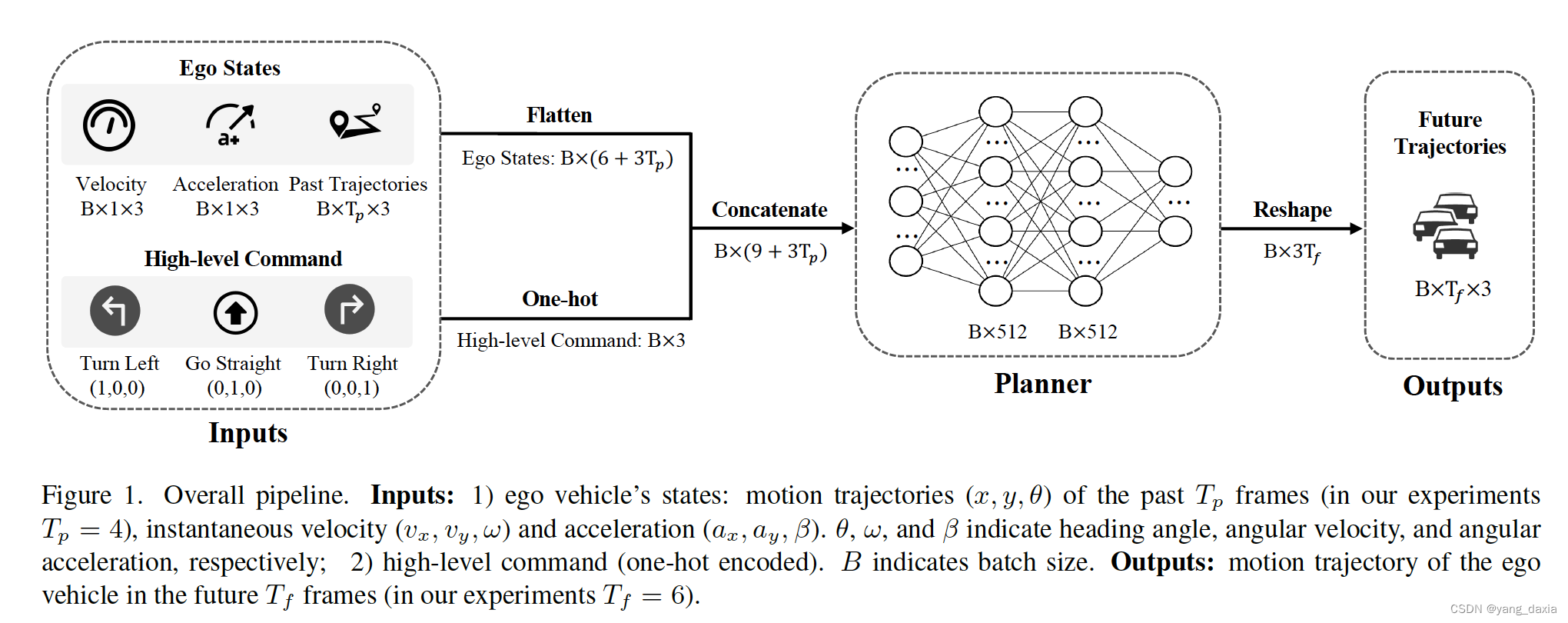
端到端自动驾驶
自动驾驶主要流程:感知->预测->规划 预测是预测周围目标(车、行人、动物等)的轨迹,规划是规划自车的运动轨迹。 UniAD[CVPR 2023]: 使用transformer架构,统一自动驾驶流程,完成所有检测,…...

Developer Tools for Game Creator 1
插件包含: 持久世界时间管理系统 单击以生成对象或预设 游戏内调试控制台 游戏内事件控制台 控制台管理控制 命令模板脚本 游戏内屏幕截图 低分辨率和高分辨率图像 缩略图生成 移动支持 使用Game Creator Action或拖放来激活和控制组件,无需编码。 通过此资产,您可以获得: …...

软件测试|好用的pycharm插件推荐(三)——Rainbow Brackets
简介 我们平时写代码的时候,括号是让我们非常头疼的地方,特别是代码逻辑很多,层层嵌套的情况。 一眼很难看出,代码是从哪个括号开始,到哪个反括号结束的。这个时候要是有一款工具能够让我们一眼就看出代码从哪个括号开…...

MyBatisPlus学习二:常用注解、条件构造器、自定义sql
常用注解 基本约定 MybatisPlus通过扫描实体类,并基于反射获取实体类信息作为数据库表信息。可以理解为在继承BaseMapper 要指定对应的泛型 public interface UserMapper extends BaseMapper<User> 实体类中,类名驼峰转下划线作为表名、名为id的…...

深入理解C#中的引用类型、引用赋值以及 `ref` 关键字
深入理解C#中的引用类型、引用赋值以及 ref 关键字 在C#编程中,理解引用类型、引用赋值以及 ref 关键字的使用对于编写高效、可靠的代码至关重要。本文将深入探讨这些概念,帮助您更好地理解C#的工作原理。 引用类型简介 在C#中,所有的类型都…...

【算法提升】LeetCode每五日一总结【01/01--01/05】
文章目录 LeetCode每五日一总结【01/01--01/05】2023/12/31今日数据结构:二叉树的前/中/后 序遍历<非递归> 2024/01/01今日数据结构:二叉树的 前/中/后 序遍历 三合一代码<非递归>今日数据结构:二叉树的 前/中/后 序遍历 三合一代…...
)
linux下驱动学习—平台总线 (3)
platform 设备驱动 在设备驱动模型中, 引入总线的概念可以对驱动代码和设备信息进行分离。但是驱动中总线的概念是软件层面的一种抽象,与我们SOC中物理总线的概念并不严格相等: 物理总线:芯片与各个功能外设之间传送信息的公共通…...

【leetcode】字符串中的第一个唯一字符
题目描述 给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。 用例 示例 1: 输入: s “leetcode” 输出: 0 示例 2: 输入: s “loveleetcode” 输出: 2 示例 3: 输入: s “aabb”…...
的区别、优缺点及应用场景)
Serverless与Kubernetes(K8s)的区别、优缺点及应用场景
Serverless与Kubernetes(K8s)的区别 架构模型 Serverless是一种基于事件驱动的计算模型,它允许开发者编写应用程序时无需关心底层的基础设施。在Serverless架构中,云服务提供商会负责管理服务器、操作系统、运行时环境等基础设施&…...
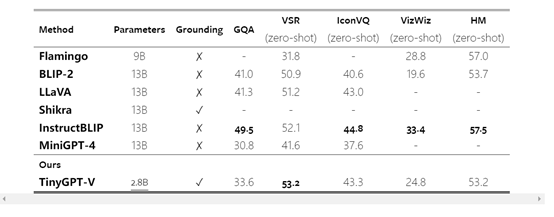
参数小,性能强!开源多模态模型—TinyGPT-V
安徽工程大学、南洋理工大学和理海大学的研究人员开源了多模态大模型——TinyGPT-V。 TinyGPT-V以微软开源的Phi-2作为基础大语言模型,同时使用了视觉模型EVA实现多模态能力。尽管TinyGPT-V只有28亿参数,但其性能可以媲美上百亿参数的模型。 此外&…...

C++系列十五:字符串
字符串 1 、创建和初始化C字符串2. C字符串的常用操作3. C字符串处理函数4. C字符串在实际开发中的应用 C中的字符串是由字符组成的序列。字符串常用于处理文本数据,例如用户输入、文件内容等。C标准库提供了一个名为std::string的类,用于表示和处理字符…...
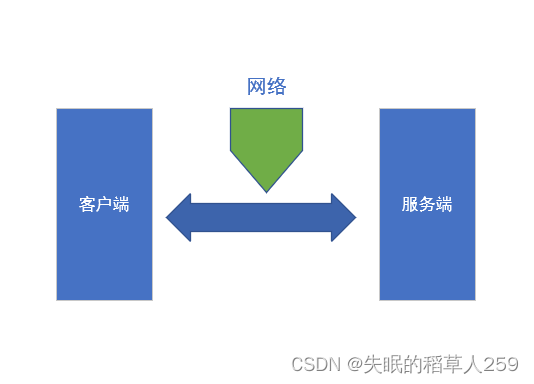
你了解计算机网络的发展历史吗?
1.什么是计算机网络 计算机网络是指将一群具有独立功能的计算机通过通信设备以及传输媒体被互联起来的,在通信软件的支持下,实现计算机间资源共享、信息交换或协同工作的系统。计算机网络是计算机技术与通信技术紧密结合的产物,两者的迅速发展…...
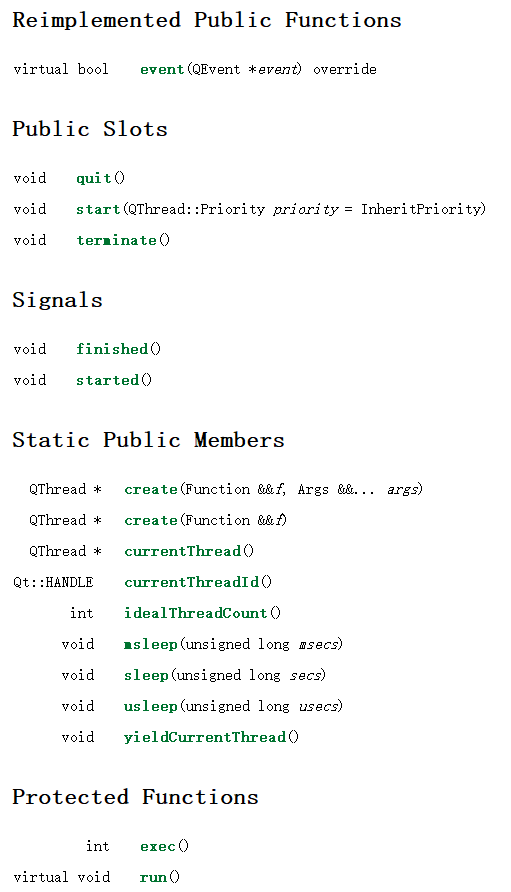
Qt/QML编程学习之心得:Linux下Thread线程创建(26)
GUI设计中经常为了不将界面卡死,会用到线程Thread,而作为GUI设计工具,Qt也提供了一个这样的类,即QThread。 QThread对象管理程序中的一个控制线程。线程QThread开始在run()中执行。默认情况下,run()通过调用exec()启动事件循环,并在线程内运行Qt事件循环。 也可以通过…...

如何在数学建模竞赛中稳定拿奖
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

Camunda Sub Process
一:内嵌子流程 repositoryService.createDeployment().name("内嵌子流程").addClasspathResource("bpmn/embed_sub_process.bpmn").deploy(); identityService.setAuthenticatedUserId("huihui"); ProcessInstance processInstance …...
golang 生成一年的周数
// GetWeekTimeCycleForGBT74082005 获取星期周期 中华人民共和国国家标准 GB/T 7408-2005 // 参数 year 年份 GB/T 7408-2005 func GetWeekTimeCycleForGBT74082005(year int) (*[]TimeCycle, error) {var yearstart time.Time //当年最开始一天var yearend time.Time //当年…...

植物大战僵尸-C语言搭建童年游戏(easyx)
游戏索引 游戏名称:植物大战僵尸 游戏介绍: 本游戏是在B站博主<程序员Rock>的视频指导下完成 想学的更详细的小伙伴可以移步到<程序员Rock>视频 语言项目:完整版植物大战僵尸!可能是B站最好的植物大战僵尸教程了&…...

轻量级工作流编排引擎:从脚本管理到自动化流程的实践指南
1. 项目概述:从单体脚本到流程编排的进化 如果你和我一样,在数据工程、自动化运维或者机器学习模型训练这些领域摸爬滚打过几年,大概率会遇到一个相似的困境:手头的任务脚本越来越多,它们之间有的有依赖关系࿰…...

百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案
百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天ÿ…...

解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南
解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中重复的…...

告别答辩PPT焦虑:百考通AI智能生成,高效搞定毕业答辩全流程
毕业季悄然来临,随着毕业论文定稿,答辩PPT成了不少同学面临的下一个挑战。不懂设计、不会梳理逻辑、找不到合适的学术模板……许多同学花费大量时间在排版调整、修改打磨上,不仅效率低下,还常常做出结构混乱、风格不统一的PPT&…...

初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发 对于预算敏感的初创团队和独立开发者而言,在开发AI应…...
基于CircuitPython与NeoPixel打造可编程LED亚克力灯牌:从硬件选型到代码实现
1. 项目概述:打造你的专属可编程光之铭牌在创客和电子爱好者的世界里,总有一些项目能完美地融合软件编程的灵活性与硬件制作的实体成就感。今天要分享的,就是这样一个让我爱不释手的小玩意儿:一个基于CircuitPython和NeoPixel的可…...

gwadd:轻量级Git仓库组管理工具,提升多项目开发效率
1. 项目概述:一个被低估的Git仓库管理利器如果你和我一样,日常工作中需要频繁地在多个Git仓库之间穿梭,处理各种依赖、子模块,或者仅仅是同步一堆相关的项目代码,那么你一定对那种重复、繁琐的切换和操作感到头疼。今天…...

Simulink模型到汽车控制器:基于模型开发的完整路径
Simulink模型到汽车控制器:基于模型开发的完整路径 一辆智能电动汽车的"灵魂",通常写在300万行以上的嵌入式代码里。但如果每一行代码都要工程师手写,开发周期会从18个月变成……永远完成不了。 一个真实的问题 2023年,…...
NeoPixel光剑制作全攻略:从WS2812B原理到实战装配
1. 项目概述:从零件到光剑的旅程如果你和我一样,是个对《星球大战》里的光剑毫无抵抗力,同时又喜欢动手折腾电子玩意儿的人,那么用NeoPixel灯带自制一把会发光、能变色的光剑,绝对是件充满成就感的事。这不仅仅是把灯塞…...

从零构建Next.js全栈应用:实战解析服务端渲染与API路由
1. 项目概述与核心价值最近在社区里看到不少朋友在讨论一个叫“panaverse/learn-nextjs”的项目,作为一个在Web开发领域摸爬滚打了十多年的老码农,我立刻来了兴趣。这个项目名直译过来就是“Panaverse的Next.js学习项目”,听起来像是一个学习…...