Devops相关问题及答案(2024)
1、DevOps 的理念是什么?
DevOps是一种组织文化、流程和工具的集合,旨在提高软件交付的速度和质量,通过自动化和持续改进的方法来促进开发(Dev)和运维(Ops)的协作。
DevOps的核心理念包括:
-
文化变革:
- 协作:鼓励开发和运维团队更紧密地合作,打破团队之间的障碍。
- 共享责任:团队成员集体对整个软件的生命周期和公司的最终产品负责。
- 透明度:通过通信和共享信息来推进项目,促进了解和信任。
-
自动化流程:
- 持续整合(CI):自动化的软件构建、测试,使得代码更频繁地合并到主分支。
- 持续交付(CD):自动化的部署过程,使得新的代码改动更快地部署到生产环境。
- 配置管理:使用代码进行系统配置的管理,确保环境之间的一致性和可复制性。
- 监控和日志:自动化的监控和日志记录,确保即时发现问题并快速反应。
-
持续反馈和改进:
- 反馈循环:通过监控和度量,实时了解系统的表现和反馈用户体验。
- 快速迭代:鼓励快速而又频繁地发布小的改动,支持业务持续和稳定地增长。
- 持续学习:从成功和失败中学习,不断改进工具和流程。
-
加强工具链的使用:
- 采用合适的工具来支持上述流程,如版本控制系统、自动化部署工具、配置管理工具、监控系统、容器化以及编排平台等。
-
系统思维:
- 识别和理解开发、测试和运维之间复杂的相互作用,促进跨部门、多学科的整体优化,而不是局部最优化。
DevOps的实施
要实践DevOps,组织通常遵循几个实施步骤:
- 评估现状:理解当前的开发和部署流程。
- 设定目标:明确实施DevOps所期望达到的目标。
- 小步快走:采用迭代的方法逐步实施变革。
- 跨职能协作:让跨职能团队共同工作,突破传统边界。
- 培训和指导:加强团队能力,尤其是对新工具和新流程的培训。
- 持续改进:通过度量和反馈来持续优化流程。
DevOps的效益
通过DevOps实践,组织可以获得多个方面的益处:
- 更快的交付时间:通过自动化和改良流程,可以更快地推动新功能和修补到生产环境。
- 更高的可靠性:通过持续的测试和监控,可以确保部署的质量,并快速修复问题。
- 改善协作:共享目标和工作流程提高了团队之间的协作。
- 成本节约:自动化和优化流程减少了必要的手工劳动,降低了运维成本。
- 技术和业务协同:使技术决策更加支持业务目标,反之亦然。
DevOps不是一个工具或是一个具体的方法论,它是融合文化、工具、流程和实践到一起的集合体,旨在缩短从开发到操作的软件开发生命周期,并提升持续交付的能力。
2、持续集成(CI)和持续部署(CD)?
持续集成(Continuous Integration,简称CI)和持续部署(Continuous Deployment,简称CD)是现代软件开发中使用的实践方法,特别是在遵循敏捷和DevOps原则的团队中。它们旨在提高软件开发和发布的速度和效率。另外,持续交付(也称为CD,有时用于区分持续部署)是这一实践的一个弱化版本。
持续集成(CI)
持续集成是一种开发实践,开发人员经常(通常是每日多次)将代码变更合并到共享仓库(如Git)中。每次代码合并后,都会自动触发一系列快速的构建和测试步骤,以确保新代码的变更不会引入错误,并且系统作为一个整体仍能正常工作。
深入CI的关键组件:
-
自动化构建:
- 创建一致的方式来编译源代码成可执行文件的过程,这通常包括编译、链接和打包。
-
质量检查:
- 代码质量分析工具检查代码标准遵守情况和潜在的缺陷。
- 静态分析和动态分析工具用于识别安全漏洞。
-
测试自动化:
- 单元测试验证代码片段如方法和函数是否按预期工作。
- 集成测试确保不同的代码块和服务在一起工作时表现正常。
- 系统测试验证整个系统的行为和功能。
-
反馈机制:
- 快速提供反馈给开发团队,以便于及时识别和修复问题。
- 集成错误报告和测试失败的实时通知。
-
版本控制集成:
- 版本控制工具(如Git)用于追踪每一次代码的变更和合并。
持续部署(CD)
持续部署是一种实践,它确保软件可以被自动部署到生产环境中。这意味着对应用程序的变更—无论是新的功能、bug修复还是配置变更—一旦完成且通过所有的测试和质量检查,它们就可以立即部署到用户可以访问的环境中。
深入CD的关键组件:
-
持续交付:
- CD的第一部分通常指的是持续交付,这确保了可以随时将代码的新版本手动部署到生产环境。
- 包含自动化的构建和测试,但是进入生产环境前需要人工批准。
-
持续部署:
- 当提到CD时,它也可以指代持续部署,这进一步自动化了从开发到生产的整个流程,不需要人工干预。
-
自动化部署管道:
- 一系列自动化的步骤,包括应用程序的部署、额外的自动化测试(如性能测试、用户界面UI测试)和上线准备。
-
监控和回滚
- 在生产环境中,监控工具确保即时捕获问题。
- 自动化回滚流程可以在检测到错误时将应用恢复到前一个版本。
-
基础设施即代码(IaC):
- 使用代码来管理和设置服务器、网络和其他基础架构的配置,以确保部署环境的一致性。
实施CI/CD时的考虑因素:
- 环境一致性:确保开发、测试和生产环境尽可能一致,减少环境差异引起的问题。
- 高质量的测试套件:持有一个全面覆盖的、自动化的、高质量的测试套件是CI/CD的核心。
- 特征开关和蓝绿部署:这些技术允许团队对新变更进行渐进式发布,最小化风险。
- 文化和心态改变:团队需要采纳快速失败、快速修复的理念,并且习惯于高频率的变更。
实施CI/CD可以显著减少软件交付时间,增强开发的灵活性和系统的稳定性,提高产品质量,这成为现代软件开发的重要组成部分。
3、什么是基础设施即代码(IaC),并解释其优势?
基础设施即代码(Infrastructure as Code,缩写为IaC)是一种使用机器可读的定义文件来管理和自动配置硬件和虚拟化平台的技术。基于文本的脚本或定义文件充当了传统硬件信息技术基础结构手动配置和交互操作的替代品。
基础设施即代码的核心概念:
-
代码管理:
- 使用声明式或命令式编程来定义基础设施,声明式(如Terraform、AWS CloudFormation)定义了“目标状态”,而命令式(如Ansible、Chef)定义了“达成目标状态的过程”。
-
版本控制:
- 与应用程序代码一样,基础设施代码也使用版本控制系统(如Git)进行管理,提供历史追踪、变更审核、回滚等功能。
-
自动化:
- 自动化基础设施的配置、部署、管理以减少人为错误和提高效率。
-
幂等性:
- 通过IaC工具实施的配置管理和自动化确保幂等性,即多次应用同一配置不会改变系统状态。
-
系统抽象:
- 对复杂系统进行高级抽象,这意味着同样的配置可以用于管理不同的环境(开发、测试、生产等)。
基础设施即代码的实现方法:
-
声明式IaC:
- 您只需描述最终应达到的“目标状态”,IaC工具会自动处理到达该状态的过程。
-
命令式IaC:
- 您需要列出一系列步骤或命令来创建所需的环境,IaC工具会按照这些步骤来执行。
-
不可变基础设施:
- 一旦部署,基础设施就不会被更改。任何更新都是通过替换现有资源的方式来实现。
-
配置管理:
- 使用工具(如Puppet、Chef、Ansible、SaltStack)来管理和应用配置。
基础设施即代码的优势:
-
一致性与标准化:通过代码确保基础设施在各个环境之间的一致性,减少环境之间的差异。
-
速度与效率:自动化基础设施的配置快速且高效,加快部署和交付时间。
-
可扩展性:代码基础的基础设施易于扩展和复制,只需调整配置文件即可。
-
文档化的基础设施:基础设施的代码本身就是最准确的文档,因为它描述了基础设施的准确状态。
-
改进治理与合规性:使用代码来管理基础设施,可以轻松跟踪合规性和审计。
-
成本效益:通过自动化减少了手工参与,从而降低了运营成本。
-
风险管理:版本控制和自动化提供了快速回滚机制,帮助更好地管理风险。
-
灾难恢复:通过代码定义的基础设施,可以快速重建整个环境。
-
弹性:易于横向扩展基础设施,可以根据需求快速增删资源。
实践中的IaC工具:
-
Terraform:声明式IaC工具,允许用户定义资源,并为跨多个云平台的资源管理提供统一的工作流程。
-
AWS CloudFormation:允许用户在Amazon Web Services(AWS)中使用JSON或YAML来模型化和设置资源。
-
Ansible:命令式IaC工具,强调简便易用,通过YAML语法的剧本来配置管理。
-
Puppet:模型驱动的配置管理工具,它使用自己的声明式语言来描述配置。
-
Chef:命令式IaC工具,使用自己的语言Ruby来定义系统配置。
基础设施即代码已经成为现代云计算环境和DevOps实践中的关键组成部分,为软件开发与运营带来了革命性的改变。通过IaC,组织可以更快、更有效、更安全地建立和管理复杂的基础设施。
4、Docker 和 Kubernetes 的区别?
Docker 和 Kubernetes 是现代软件部署中常见的两个关键技术。虽然它们在容器化领域有所交叉,但它们扮演的角色和它们解决的问题有很大的不同。
Docker
概述:
Docker 是一个开源平台,用于开发、交付和运行应用程序。它使您可以将应用与基础设施分离,以便您可以快速交付软件。Docker 使用容器来实现这一点,容器是由 Dockerfiles 定义的轻量级、可移植、自给自足的包,包含所有需要运行一个应用的代码、运行时、系统工具、系统库和设置。
关键特性:
-
容器化:
- Docker 提供便捷的方式来打包应用及其依赖关系到一个隔离的、可移植的容器中,并可以在任何支持 Docker 的环境中运行。
-
Docker Hub:
- Docker 提供一个称为 Docker Hub 的中心化资源库,用于存放和分发容器镜像。
-
Dockerfile和镜像:
- Dockerfile 是构建 Docker 镜像的指令集,而镜像则是一个不可变的文件,是容器的模板。
-
容器管理:
- Docker 提供了启动、停止、构建和管理单个容器的多种命令行工具。
优势:
- 易于使用和快速部署。
- 提高了应用的可携带性和一致性。
- 支持自动化的应用部署和扩展。
- 可以在一个主机上高效地运行多个容器。
Kubernetes
概述:
Kubernetes 是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用。Kubernetes 不直接与容器交互,而是管理用于容器运行的工具,如 Docker 或 rkt。
关键特性:
-
集群管理:
- Kubernetes 允许您将物理或虚拟机组合成集群,这个集群的计算资源可以被容器化应用统一使用。
-
高可用性:
- Kubernetes 能够确保应用不会因为单点故障而中断服务,可以跨主机提供冗余和故障转移。
-
自我修复:
- 如果容器失败,它会重启,如果节点死亡,容器会被重调度到其他节点。
-
自动扩展:
- 根据资源使用情况(如CPU和内存)自动调整应用的容器数量。
-
负载均衡:
- 服务发现和负载均衡功能,可以自动分配网络流量和负载,以确保稳定性。
优势:
- 管理大规模的容器部署。
- 自动化的回滚与扩展。
- 适合多租户应用。
- 处理服务发现和负载均衡。
- 资源的自动优化和分配。
Docker vs Kubernetes:
- 容器运行 vs 容器编排:Docker 专注于容器的创建和运行,而 Kubernetes 专注于容器的编排。
- 单机 vs 集群:您可以在单一机器上使用 Docker 来管理容器。与此相反,Kubernetes 被设计为跨一组机器(集群)运行和协调容器。
- 直观性 vs 可扩展性:Docker 直观易用,容易上手,但在原生支持多主机、大规模集群面前有所欠缺;Kubernetes 提供了大规模、跨主机的容器编排能力,但学习曲线比较陡峭。
- 独立和配合使用:Docker 可以独立使用来管理容器,而 Kubernetes 常常与 Docker(或其他容器化工具)一起使用,来提升容器管理的水平。
在现代云原生环境中,Docker 和 Kubernetes 结合使用已成为主流,Docker 用于容器化应用,而 Kubernetes 用于容器管理和编排。
5、如何实施监控以确保基础设施的健康状况?
实施监控以确保基础设施的健康状况是维持系统稳定性和及时响应潜在问题的关键。以下步骤为您提供了一个详细深入的框架,帮助您建立一个全面的监控策略。
1. 建立监控目标
确定需要监控的关键性能指标(KPIs)与基础设施组件,如计算资源、存储系统、网络设施以及应用程序本身。你的目标可能包括系统的可用性、性能、容量、安全性和合规性。
2. 设计监控架构
结合监控目标,设计一个多层次的监控架构,通常包括:
- 基础设施监控:监控硬件资源和网络基础设施。
- 服务监控:关注操作系统和服务的状况。
- 应用监控:应用程序级别的性能监控,包括日志、事务追踪和用户体验。
- 业务流程监控:业务重要指标的实时监控。
3. 选择监控工具
挑选适合你的环境和需求的监控工具和平台。许多工具同时支持基础设施监控和服务监控,如:
- 开源工具:如 Nagios、Prometheus、Graphite、ELK Stack(Elasticsearch, Logstash, Kibana)和 Grafana。
- 商业工具:如 Datadog、New Relic、Dynatrace、SolarWinds 和 Splunk。
4. 实施日志管理
日志数据是监控的重要组成部分。日志管理解决方案如 ELK Stack 或 Splunk 可以帮助集中、分析和存储日志数据,并从中提取重要见解。
5. 建立阈值和警报
为KPIs设置阈值,并为超过这些阈值的事件建立警报。警报应该能够通过电子邮件、短信或即时消息快速通知到系统管理员或自动响应系统。
6. 构建自动化响应机制
对于常见问题,可以开发自动化脚本和工作流来响应警报,实现缩放、回滚或其他自恢复行为。
7. 部署监控代理和集成数据收集
在您的基础设施中部署必要的监控代理,并配置它们以发送指标到您的监控工具。此外,利用 API 集成那些不支持传统代理的现代应用和基础设施组件。
8. 数据可视化
使用数据可视化工具如 Grafana 来创建控制面板,实时展示重要的监控数据。控制面板应该包括关键指标的概述并允许用户深入了解具体问题。
9. 进行压力测试和容量规划
定期进行压力和负载测试以确保基础设施可以承受预期的峰值流量。基于监控数据进行容量规划以优化资源配置。
10. 持续审计和优化
监控是一个持续的过程。定期审查监控目标、收集的数据和监控策略的有效性,并作出相应的调整。
11. 文档和培训
为团队成员提供操作手册、监控策略文档和培训,确保他们了解监控系统的运作和如何响应警报。
12. 符合合规性和安全性需求
确保你的监控策略遵守所有适用的法规要求,如GDPR、HIPAA等,并实施适当的安全措施,以保护监控数据。
总结
实施和维持健康的基础设施监控是一个涉及策略制定、工具选择、实践应用和持续改进的过程。监控的目标是保障系统的稳定运行,预防问题发生及时响应和解决故障,同时通过对采集到的数据进行深入分析,指导未来基础设施的优化和决策。
6、无服务器架构并提供一个使用场景
无服务器架构是一种云计算执行模型,在该模型中,云提供商运行服务端逻辑和服务器资源管理,而不是传统的、显式分配的、持久的云虚拟机。这里的“无服务器”并不意味着没有服务器,而是指开发人员不需要管理服务器。这种架构通常与"后端即服务"(BaaS)和"功能即服务"(FaaS)联系在一起。
关键特点
-
事件驱动性:服务由特定事件(如HTTP请求、数据库事件等)激活。
-
自动弹性:云服务商自动扩展处理容量以匹配需求。
-
微支付模型:只需为实际耗用的计算和资源付费,无需预支付静态服务器资源。
-
管理责任减少:服务提供商负责基础设施的维护、补丁和可靠性。
组件
- 函数即服务(FaaS):一个平台,允许开发人员部署单个函数,而不是完整的应用,这些函数在被触发时运行。
- 后端即服务(BaaS):云服务模型,在这种模型中,后端服务通过互联网暴露出来,由第三方维护。
优势
- 可扩展性:应用可以自动扩展以应对需求,无须手动增减资源。
- 成本效益:开发人员不用为闲置资源支付费用,因为他们只为实际使用的资源付费。
- 速度和敏捷性:开发人员可以快速部署和更新代码,无需管理服务器。
- 运维工作的减少:由于云提供商负责大部分管理工作,所以减轻了工作负担。
缺点
- 控制权的丧失:开发人员可能无法完全控制底层基础设施。
- 冷启动问题:由于资源不是持久化分配的,未经预热的函数可能会有初始化延迟。
- 本地测试和调试问题:由于架构依赖于云提供商,本地开发环境中的测试可能更为复杂。
使用场景:在线图片处理服务
设想一家公司需要建立一个在线图片处理服务,它允许用户上传图片并将其转换为不同的格式或应用不同的滤镜。使用无服务器架构来实现这一点有诸多优势。
实施步骤:
-
上传触发事件:用户通过前端接口上传图片到云存储服务,如Amazon S3。这个上传动作触发一个事件。
-
函数即服务(FaaS):云存储服务的这个事件触发FaaS平台上的函数,如AWS Lambda或Azure Functions。这个函数被调用以处理上传的图片。
-
图片处理逻辑:函数内的代码执行所需的图片处理任务,例如改变尺寸、格式转换或应用图像过滤器。
-
资源自动化和容错:无服务器平台自动管理执行函数所需的资源,按请求自动扩展,并在请求增多时自动增加实例。
-
存储与传递结果:处理完成的图片存储回云服务,并生成一个下载链接或直接将图片发送至用户。
这个简单的服务因为使用了无服务器架构,因此开发人员仅需专注于编写图片处理代码,而不必担心服务器配置、容量规划或负载平衡。由于处理可能是断断续续的,无服务器模型使得公司仅在函数调用时才付费,而不用为了保持服务器整天在线而支付不必要的费用。无论用户上传的图片是每天几张还是每秒几千张,无服务器架构都能够自动扩展以应对负载,保证服务的性能。这提高了资源利用率和成本效率,同时还减少了时间上的浪费和操作复杂度。
7、云提供商之间的多云策略是什么?
多云策略是一种在多个云计算服务提供商之间分布IT资源、应用和服务的方法。它通过跨不同云(包括公共、私有和混合云)进行操作来最大化效益,可以增强业务的灵活性,降低风险,并可能降低成本。一个良好的多云策略考虑了不同云提供商的优势,并利用它们提供的不同服务和地理位置来满足企业具体的业务需求。
多云策略的关键组成部分:
1. 部署决策
- 负载分布:将工作负载根据性能、数据主权、合规性要求或成本效益在不同云提供商间进行分布。
- 服务匹配:选择每个云提供商最擅长的服务,例如某个云可能对AI有更好支持,而另一个云可能在IaaS上更具优势。
2. 应用架构
- 云原生开发:设计应用程序,使其能够在多个云环境中运行,通常涉及容器化与微服务架构。
- API管理:确保应用和服务能够通过适当的API与多个云环境通信和集成。
3. 数据管理
- 数据同步:数据和状态需要在云之间保持同步,以实现无缝操作。
- 遵从性与数据主权:确保数据传输和存储满足各种地域性法规要求。
4. 运营和自动化
- 跨云管理:使用云管理平台实现跨不同云提供商的集中式监控、管理和优化。
- 自动化部署:通过基础设施即代码(IaC)等工具自动化资源配置和服务部署。
5. 成本效益
- 成本监控:持续跟踪不同云提供商的使用情况和成本,优化资源使用和费用。
- 合同谈判:与多个供应商谈判价格和服务水平协议(SLA)。
6. 安全性和合规性
- 统一安全策略:建立符合所有云环境的安全措施。
- 身份和访问管理:使用跨云的身份认证和访问控制策略。
使用多云策略的优势:
- 避免供应商锁定:不完全依赖单一云提供商,降低由于服务中断、价格变化或技术退役带来的风险。
- 优化性价比:通过选择不同云提供商中成本最优的服务和资源。
- 灵活性与冗余:分散风险,提高业务连续性和容灾能力。
- 合规性满足:能更容易地满足全球化业务的数据主权和合规性要求。
使用场景举例:
国际金融服务公司
一家国际金融服务公司需满足不同地区的数据存储法规,同时希望优化其全球资产管理应用程序的性能和成本。
多云策略实施:
-
数据存储合规性:在欧洲使用支持GPDR的云提供商存储当地客户的数据,在美国则使用另一家支持美国法规的云提供商。
-
性能优化:通过混合公有云服务与私有云环境,并使用CDN等技术,为全球各地的终端用户优化访问速度和响应时间。
-
成本管理:不同区域内,根据服务费用与性能要求选择最合适的云服务提供商。
-
容灾和备份:为关键应用程序在不同区域的多个云服务提供商之间制定备份和容灾计划。
通过这种方式,公司可以确保全球客户的服务连续性,同时优化成本和满足不同地区规定的合规性要求。多云策略使它们能够在各个云提供商之间灵活地移动资源,减少对单个提供商的依赖,从而降低业务风险。
8、什么是微服务架构?
微服务架构是一种软件架构风格,它鼓励将单一应用程序划分为一组较小、独立、松耦合的服务,每个服务围绕业务能力构建,并且可以独立部署、扩展和维护。每个微服务都是围绕业务功能开发的单一功能模块,它们通过定义良好的API进行通信。微服务可以用不同的编程语言编写,并且可以使用不同的数据存储技术。
微服务架构的关键特征:
责任分离:
- 单一责任原则:每个微服务包含了相关的业务功能,并拥有所需的数据、依赖及资源,实现服务的独立性。
独立部署:
- 自治服务: 微服务可以独立于其他服务进行部署,因此可以有其特定的持续集成/持续部署(CI/CD)流程。
技术多样性:
- 多技术兼容性:由于服务的独立性,团队可以根据服务的具体需求选择最佳的编程语言和数据存储方案。
分散治理:
- 分散的决策制定:不同的团队可能负责不同的服务,每个团队可以独立作出技术和设计决策。
灵活性:
- 易于扩展和维护:只要暴露的接口保持一致,团队可以轻松地更新或替换微服务,而不影响其他服务。
可伸缩性:
- 按需伸缩:可以根据每个服务的需求,独立地调整服务的规模。
弹性:
- 容错性:一个服务的故障不必导致整个应用程序的崩溃,符合故障隔离的概念。
微服务架构的优势:
敏捷开发和部署:
- 加速迭代:较小的代码库和服务范围可以缩短开发周期,实现快速迭代。
可靠性:
- 改善稳定性:如果设计得当,即使单个微服务失败,系统作为整体也能继续运行。
伸缩性:
- 高度伸缩性:可以针对特定服务对资源进行调整,应对负载变化。
微服务架构的挑战:
复杂性:
- 增加的管理负担:每个服务可能需要不同的数据库、运行环境和配置,增加了系统的复杂性。
数据一致性:
- 维护数据一致性:在分布式系统中,确保数据一致性是一个挑战。
网络延迟:
- 通信开销:服务间需要通过网络进行通信,网络延迟可能影响性能。
测试:
- 集成测试复杂性:测试互联的微服务比测试单一应用程序更复杂。
跟踪和监控:
- 分布式监控和日志聚合:跟踪多个独立服务之间的交互需要全面的监控系统。
微服务使用场景举例:
假设有一家在线电商平台,它由几个相互作用的模块组成:用户接口、产品目录、订单处理、账户管理和支付处理。在微服务架构中,每个模块将作为独立的服务来实现。
- 产品目录服务:管理产品信息和库存。
- 订单处理服务:处理用户订单及其生命周期。
- 账户管理服务:处理用户信息和权限。
- 支付服务:处理支付和交易。
这样的架构允许团队独立地更新和扩展每个服务,例如,在繁忙的购物季可以单独扩展订单处理和支付服务,同时仍然维持产品目录和账户管理服务的常态规模。此外,如果支付服务因故障停机,用户仍可浏览产品目录并管理其账户,从而提高了用户体验和系统的整体韧性。
9、如何管理和保密敏感的运维数据,如密码或秘钥?
管理和保密运维数据,尤其是密码、秘钥和其他敏感信息,是维护企业安全的关键部分。以下是一套详细的策略和实践方法,用以确保此类信息的安全性:
1. 数据分类
首先要识别哪些数据是敏感的,应当接受特别保护。这通常包括:
- 用户名和密码
- API密钥
- 私钥和公钥对
- 证书
- 配置文件中的敏感信息
2. 使用密码管理器
使用可信赖的、专业的密码管理器来存储和管理密码和秘钥,例如:
- 1Password
- LastPass
- Keeper
- Bitwarden
这些工具提供加密的存储并支持复杂密码的生成,能够帮助组织集中管理凭据。
3. 使用密钥管理系统
为了更进一步的管理密钥和其他秘密信息,可使用以下工具:
- HashiCorp Vault
- AWS Secrets Manager
- Azure Key Vault
- Google Cloud Secret Manager
这些系统可以集中管理秘钥,提供对敏感数据访问的精细控制,并通常支持自动旋转密钥,以降低密钥泄露的风险。
4. 最小权限原则
授权时应遵循最小权限原则,即仅提供完成任务所需的最小权限。这意味着用户、程序或服务只能访问必要的资料,并进行必要的操作。
5. 加密传输
当存储或传输敏感数据时,确保使用了适当的加密:
- 使用TLS/SSL对网络传输进行加密。
- 为敏感数据文件使用磁盘加密技术,如使用AES的dm-crypt、BitLocker等。
- 使用应用层加密确保数据在传输过程中的安全。
6. 定期更换密钥
制定密钥更换策略,并坚持实施。自动密钥轮换可以减少一个被泄露密钥的潜在影响。
7. 审计与监控
部署日志和监控系统跟踪对敏感数据的所有访问尝试和使用情况:
- 定期审计日志文件,检查未授权的访问或异常行为。
- 利用SIEM(安全信息和事件管理)系统来集中日志数据,并进行实时分析。
8. 访问控制
为所有存储和访问敏感信息的系统制定严格的身份认证和授权策略:
- 多因素认证(MFA)的使用。
- ACL(访问控制列表)和RBAC(基于角色的访问控制)的实施。
9. 员工培训
教育员工关于敏感数据的重要性,并提供安全最佳实践培训:
- 密码创建和管理。
- 钓鱼诈骗和社会工程学的识别。
- 报告和相应处理数据泄露的程序。
10. 应急响应计划
为数据泄露制定并演练一个应急响应计划,确保在发生安全事件时可以迅速采取行动。
11. 安全策略的设计与评审
定期评审安全策略,确保它符合当前组织的安全要求、业务需求和法律法规。
12. 本地加密
在将秘密数据写入磁盘之前对其进行加密,确保即使存储介质被盗也不会有信息泄露。这通常通过代码库外部的加密解决方案来实现。
13. 环境隔离
在开发、测试和生产环境之间保持严格的隔离,并确保敏感数据不会在不安全的环境中出现。
14. 持续监测与更新
关注相关安全漏洞的最新动态和加密技术的更新,对策略和工具进行定期的评估和更新。
应用上述实践方法,可以确保敏感运维数据得到恰当的管理和保护,从而在保证安全操作的同时支持业务的发展。
10、蓝绿部署和金丝雀部署的区别?
蓝绿部署和金丝雀部署都是现代软件工程中常见的风险缓解策略,用于减少新版本应用程序发布时可能引发的问题。尽管它们都是为了同一目标而制定,即实现无缝的用户体验和减少停机时间,但它们各自采用不同的方法和技术。
蓝绿部署
蓝绿部署通过两个几乎相同的生产环境(一个蓝色,一个绿色)来降低部署风险。这两个环境在硬件和软件配置上尽可能地相同。
流程:
- 蓝色环境包含运行当前版本的应用程序的生产服务。
- 绿色环境则部署了改动之后的新版本的应用程序。
- 一旦绿色环境的新版本经过足够测试并且准备好了,流量就会从蓝色环境切换到绿色环境。
- 如果新版本运行良好,那么绿色环境会成为主要的生产环境,直到下一次部署又会重复这个过程。
优点:
- 快速回滚,如果新版本(绿色)有问题,可以立即切换回旧版本(蓝色)。
- 无缝切换,用户几乎感觉不到切换过程。
缺点:
- 需要运维两套相同的环境,可能增加成本。
- 没有渐进性,所有用户在切换时都会直接用上新版本。
金丝雀部署
金丝雀部署是一种更进步且渐进的部署方法。它将新版本的应用程序先行部署给一小部分用户,观察表现,如果一切正常,再逐步扩大到更多用户。
流程:
- 部署新版本的应用程序,但仅向少部分用户提供服务(例如5%的流量)。
- 监控新版本的表现。这涉及到错误率、性能指标和用户反馈的详细监测。
- 如果指标正常,逐步增加流量百分比,直至新版本完全取代旧版本。
- 如遇到问题,新版本可以迅速回滚,影响范围较小。
优点:
- 降低风险,因为新版本最初仅影响少量用户。
- 获取反馈的能力,可以基于实际用户行为优化新版本。
缺点:
- 部署过程更复杂,需要仔细计划和监控。
- 潜在的不一致性,部分用户可能遇到问题而其他用户则不会。
比较
- 风险管理:金丝雀部署在管理新版本发布风险方面提供更细粒度的控制,而蓝绿部署提供了快速的全量切换方案。
- 资源成本:蓝绿部署通常资源成本更高,因为它需要两个生产环境;而金丝雀部署可以在相同的生产环境中逐步替换服务。
- 测试与反馈:金丝雀部署可以使用生产流量进行测试,提供更真实的用户反馈;而蓝绿部署通常在全量切换之前在绿色环境进行全面测试。
- 复杂度:金丝雀部署在操作上更为复杂,需要仔细监控多个版本并同时处理多个流量。
- 用户体验:蓝绿部署为所有用户提供一致的体验,而金丝雀部署则在过渡期间分散用户体验。
选择哪一种部署策略通常取决于组织对风险、成本、技术能力和业务目标的考虑。一些组织甚至可能结合使用这两种策略,以获得两者的优点。
11、GitOps 是什么,以及它如何与 DevOps 协作?
GitOps 是一个基于 Git 的 IT 运维管理的实践,它使用 Git 作为声明式基础设施和应用配置的单一来源。GitOps 的核心思想是使用 Git pull 请求来自动化基础设施的更新和应用部署,此实践围绕版本控制、合作和持续改进的 DevOps 原则进行构建。
GitOps 的关键组成部分:
-
声明式基础设施:系统的当前和所需状态在 Git 仓库中以代码的形式声明,这俗称“基础设施即代码”。
-
版本控制:所有的更改都通过 Git 提交记录,提供了完整的变更历史和可追溯性。
-
自动化部署:使用自动化工具(例如 Kubernetes 的操作员和控制器)来确保实际状态匹配 Git 中的声明状态。
-
持续集成/持续部署(CI/CD):促进了代码与依赖的自动化构建、测试和部署流程。
-
回滚与审计:如果部署出现问题,可以轻松地回滚到 Git 中的之前版本,所有更改都有记录,便于审计。
GitOps 与 DevOps 的关系:
GitOps 可以看作是 DevOps 原则应用于基础设施管理和运维流程的延伸和细化。GitOps 强调的是版本控制和自动化的应用,与 DevOps 促进开发和运维高度协同的目标是一致的。
如何协作:
-
分工合作:开发者、运维和安全团队使用 Git 作为协同平台,使得工作流程透明化和协作性增强。
-
流程自动化:从代码提交到生产部署,整个流程都可以自动化进行,以快速、一致的方式推出新功能和修复。
-
风险降低:GitOps 提供了一个审计跟踪,可以清楚地回溯任何更改,降低了人为错误的风险。
-
安全和合规性:通过自动合并和拉取请求的流程,确保了只有经过审查和批准的更改才会进入生产环境,提高了安全性。
GitOps 的优势:
-
提升透明度:由于所有变更都通过 Git 进行,团队成员可以清晰地看到每一个更改,增加了工作的透明度。
-
改进可追溯性:历史记录和审计轨迹的存在使得每一个操作都可追溯性和可审计性。
-
增加一致性:通过声明式基础设施,系统的状态是可预测的,并且在多环境中保持一致性。
-
增强可靠性:自动化流程减少了人为错误,提高了整个系统的稳定性和可靠性。
-
加强安全性:使用 Git 管理基础设施可以加强安全性,因为变更都需要通过代码审查过程。
实践举例:
在 Kubernetes 环境中,GitOps 常常与操作员模式一起使用。假设开发人员想要更新应用程序:
- 他们将新的应用配置提交到 Git 仓库。
- CI/CD 系统检测到新的提交,并启动构建和测试流程。
- 一旦 CI/CD 流程结束,自动化的部署工具(如 Flux 或 ArgoCD)监测到 Git 仓库的状态变化。
- 部署工具将更改自动推送到 Kubernetes 集群,使用声明的配置更新或回滚服
务。
通过这种方式,GitOps 可以加快和简化云原生应用的部署和运维过程,同时还带来了 DevOps 的所有好处。
12、灾难恢复计划的重要组成部分?
灾难恢复计划 (Disaster Recovery Plan, DRP) 是组织在发生重大破坏性事件时确保业务连续性和数据恢复的详细策略和程序。这些事件可能包括自然灾害、网络攻击、系统故障或人为错误。一个全面的灾难恢复计划通常包含以下关键组成部分:
1. 风险评估与业务影响分析(BIA)
进行详尽的风险评估来识别可能对组织造成重大影响的威胁。业务影响分析则重点评估这些灾难情况对业务流程的影响,确定关键业务流程、关键应用程序和数据的优先级。
2. 重要业务功能的识别
确定组织运作中不可缺少的功能和服务。这将帮助定义恢复时间目标(Recovery Time Objective, RTO)和恢复点目标(Recovery Point Objective, RPO),以确保关键任务和服务可以优先恢复。
3. 定义恢复策略
针对不同的灾难情况和业务需求,制定灵活的恢复策略。这包括备份和恢复程序、备用设施、远程工作解决方案和数据保护等。
4. 灾难恢复团队
建立一个专门的灾难恢复团队,负责计划的制定、更新、测试和执行。团队成员应包括来自IT、业务运营、人力资源、法务和通讯部门的代表。
5. 紧急联系信息
安排并维护所有必要的紧急联系人列表,这包括内部团队成员、供应商、合作伙伴以及紧急服务提供方的联系方式。
6. 详细的恢复步骤
制定详细的恢复步骤以帮助团队成员在灾难发生时执行具体任务。这些步骤应当包括启动紧急操作计划、评估破坏程度、实施数据恢复和备份方案等。
7. 数据备份和复制
保证重要数据的备份在多个地理位置,防止单点故障。数据的复制策略应确保可以快速恢复到最新的数据点。
8. 备用设施和基础设施
准备可能需要的备用物理或云基础设施,以确保关键服务可以在主要设施不可用时继续运作。
9. 沟通计划
确保灾难发生时有明确的沟通计划和沟通渠道。不仅仅是内部沟通,也包括对外沟通,比如客户通知和公共关系危机管理。
10. 测试和练习
定期测试和练习灾难恢复计划,以确认恢复策略的有效性,并训练团队成员以确保他们知道在真正的灾难发生时应该做什么。
11. 文档管理和更新
文档应详细记录所有策略、程序和步骤,并随着业务发展和技术更迭持续更新。
12. 法规遵从
确保所有恢复策略和操作符合相关法规要求,如GDPR、HIPAA等。
13. 保险
验证保险政策能否涵盖灾难相关损失,并了解报销流程。
14. 反馈和持续改进
灾难恢复计划是一个持续改进的过程,应定期基于测试结果、技术革新和组织变动来更新计划。
灾难恢复计划关注于避免因灾难导致的业务中断,并最小化灾难带来的影响,它是组织整体业务连续性规划(Business Continuity Planning, BCP)的一部分。一个综合性的灾难恢复计划,可以帮助组织在面对紧急情况时快速响应,保护关键资产,并确保关键业务能力的快速恢复。
13、如何优化构建和部署流程的速度?
优化构建和部署流程的速度是提高软件交付效率、减少开发周期、增强客户满意度的关键环节。以下是一些实现此目标的策略:
1. 分析现有流程
当前状态分析:
- 对现有的构建和部署流程进行完整的审查和性能测试,确定瓶颈。
- 使用监控和日志工具来跟踪和衡量关键步骤的耗时。
性能指标定义:
- 定义关键性能指标(KPIs),比如构建时间、部署时间、失败率。
2. 采用现代化的CI/CD工具
持续集成和持续部署(CI/CD):
- 使用Jenkins、GitLab CI、GitHub Actions、CircleCI、Travis CI等工具自动化构建和部署。
- 优化CI/CD管道配置,确保资源被高效使用。
3. 优化构建工具和环境
依赖管理:
- 优化依赖解析,确保使用高效的包管理工具。
- 选择合适的依赖版本,避免不必要的重复构建。
缓存策略:
- 缓存依赖和构建过程中的中间产品,减少重复下载和编译的时间。
构建环境:
- 使用容器化(Docker)或虚拟化技术,确保团队成员之间环境一致,减少“在我机器上可以运行”的问题。
4. 代码库维护
代码库大小:
- 维护一个干净的代码库,定期剔除废弃的代码和资源文件。
模块化和微服务:
- 将大型应用分解为模块或微服务,实现单独构建和部署。
5. 并行化和分布式构建
并行构建:
- 识别可以并行执行的构建任务并配置CI/CD管道,减少总体构建时间。
分布式构建:
- 使用分布式构建系统(如Buildkite、Bazel等)来同时在多个机器上执行构建任务。
6. 调整测试策略
测试选择性执行:
- 使用测试选择性执行技术,仅运行与更改相关的测试。
并行测试:
- 测试任务应该并行运行以节约时间。
模拟和打桩:
- 当可能时,使用模拟和打桩减少测试复杂度。
7. 优化部署策略
蓝绿部署和金丝雀发布:
- 使用蓝绿部署或金丝雀发布减少部署风险同时提高速度。
无服务器和平台即服务(PaaS):
- 考虑使用无服务器计算或PaaS提供商,减少部署复杂性,实现自动扩缩容和管理。
8. 流程自动化
脚本化和自动化:
- 所有重复性高的任务都应该自动化,包括环境的设置、配置的改动、代码的部署等。
9. 监控和反馈
实时监控:
- 实时监控构建和部署流程,确保问题可以即刻发现和解决。
快速反馈:
- 流程中任何环节的失败都应该立即反馈给团队,以便快速响应。
10. 文化和实践
持续学习和改进:
- 创造一个文化,团队能不断学习新技术,并将其应用于优化构建和部署流程。
敏捷和DevOps实践:
- 鼓励质量内建、小批量交付和快速迭代的DevOps文化。
11. 利用云服务和资源
云构建服务:
- 利用云服务商提供的托管CI/CD服务,可以在需要时自动扩展资源。
12. 定期审查和优化
定期回顾:
- 定期回顾流程,根据新的数据、反馈和技术进步来进一步优化。
综合以上策略,提高构建和部署流程的速度并不仅仅是单一技术或工具的问题,它需要技术和流程两手抓,并结合团队的文化和实践来综合推进。通过刻意的优化,不断追求改进,能够显著提升软件的交付效率。
14、面临网络延迟和服务中断时,如何确保高可用性?
在面临网络延迟和服务中断的情况时,维持高可用性是确保系统可靠性和用户满意度的关键。以下是一些确保高可用性的策略:
1. 冗余设计
多区域部署:在多个数据中心或地理位置部署应用的副本,以提供故障转移能力。
负载均衡器:使用负载均衡器自动分配流量到多个服务器,这可以防止单个服务器的过载并减少故障点。
热备与冷备:配备热备(实时同步)和冷备(定期同步)系统。
2. 自动化故障转移和恢复
自动化故障检测与处理:实现自动化监控来检测服务中断,并自动重启服务或将流量切换到备用系统。
预先定义故障转移流程:开发和测试故障转移和恢复程序,确保它们在需要时能够迅速有效地执行。
3. 服务质量(QoS)策略
流量管理和优先级:实施QoS策略来管理网络流量,确保核心业务流量优先处理。
限制和配额:对服务使用限制和配额来防止任何单个消费者占用过多资源,导致服务降级。
4. 弹性和可扩展性
自动伸缩:使用自动伸缩服务(比如Kubernetes的HPA)根据需求自动增加或减少资源分配。
无状态设计:实现无状态的应用架构,使得系统能更容易横向扩展。
5. 性能优化
缓存:使用缓存降低数据库负载并减少响应时间。
数据库优化:优化数据库查询,使用索引和数据库分片来减少延迟。
6. 全球分布式CDN
内容分发网络:使用CDN来缓存静态内容,减少内容到用户的距离和响应时间。
7. 网络优化
网络协议优化:利用TCP优化、HTTP/2或gRPC等现代网络传输协议。
优化路由:采用智能DNS服务根据用户地理位置和服务节点状态优化路由。
8. 强化数据持久性和备份
持久化存储:确保数据存储在可靠的持久化系统中。
定期备份:周期性执行数据备份并测试恢复流程确保数据可以恢复。
9. 应用层策略
服务降级:在后端服务不可用时,前端依然可以提供有限的功能,通过降低服务质量来维持服务可用。
断路器模式:实现断路器模式防止级联故障。
10. 应用监控与分析
实时监控与报警:实现实时监控和报警,快速响应潜在的服务降级或中断。
日志管理:集中管理日志,监控和分析网络延迟、系统性能和流量模式。
11. 实施业务连续性计划(BCP)
灾难恢复计划(DRP):制定并定期演练DRP以确保关键业务功能在灾难发生时可以持续。
12. 安全性考虑
安全检查和更新:定期执行安全审计并应用最新的安全补丁。
防御措施:实施包括Web应用防火墙(WAF)在内的防御措施以减少攻击风险。
13. 文档与培训
详尽的文档:清晰的技术文档对于快速定位和解决问题是非常有帮助的。
团队培训:定期对团队进行培训,确保每个成员都了解在服务中断时的应对流程。
14. 持续改进
事后分析:服务中断后,进行彻底的根本原因分析并根据发现进行流程改进。
15. 供应商管理
多云策略:考虑多云部署以避免依赖单一云提供商的风险。
在实施上述策略时,应确保所有措施都与组织的整体业务目标和运营策略相一致。通过对高可用性策略的持续投资和优化,组织能够准备并应对网络延迟和服务中断,从而维持业务流程的连续性和用户的最终体验。
15、 Ansible、Chef 和 Puppet 有什么不同?
Ansible、Chef和Puppet都是自动化管理工具,主要用于配置管理、应用部署、任务自动化等。它们可以帮助系统管理员和运维工程师标准化和自动化IT环境中的资源和应用配置。以下是它们之间的一些区别:
Ansible
-
简易性:Ansible 以其简易性和易上手性而闻名。它使用YAML(Yet Another Markup Language)语法来编写Playbooks(Ansible的自动化脚本)。
-
代理程序:Ansible不需要在管理节点上安装代理程序(agent)。它通过SSH协议与你的服务器建立连接,所以只要你的服务器支持SSH,就能用Ansible进行管理。
-
推模式:默认情况下,Ansible使用推模式,意味着中央节点会将配置推送到目标机器上。
-
Idempotency:另一个Ansible的核心特性是幂等性,这意味着重复执行同一脚本不会改变系统状态或者只能产生预定的改变。
-
扩展性和可插拔:Ansible模块化设计,支持自定义模块。它的核心由Python编写,因此Python用户可以很容易地为其编写自定义模块。
Chef
-
Ruby DSL:Chef 使用一种基于Ruby的领域特定语言(DSL)进行配置编写,它的配置文件称作“recipe”。这对那些熟悉Ruby的运维工程师来说是一个好消息。
-
代理程序与主服务器架构:Chef需要在节点上安装代理程序,而且在主服务器上有一个中心管理的Chef服务器。
-
拉模式:默认情况下,Chef使用拉模式,即客户端节点定期询问Chef服务器是否有新的配置应用。
-
强大的集成和测试工具:Chef有着一系列工具配套,例如Test Kitchen、ChefSpec、Foodcritic和InSpec,它们能够帮助开发和测试配置代码。
-
企业级功能:它提供企业级功能和庞大的社区,包括自动化的dashboard,和覆盖从开发到生产的完整流程的工具集。
Puppet
-
Puppet DSL与Ruby:Puppet有自己的领域特定语言(DSL),但也支持Ruby, 这使得自动化脚本对于知道如何编写Ruby代码的人来说相对容易。
-
代理/主架构:Puppet也需要在节点上安装代理(称为puppet agent),与一个主服务器(称为Puppet master)通信。
-
拉模式:默认情况下,Puppet以拉模式运行,这意味着被管理的节点会定期向Puppet master询问更新。
-
资源抽象层:Puppet提供了一层资源抽象层,使得配置管理可以不依赖于任何具体操作系统和硬件平台。
-
企业支持和社区版本:Puppet有两个版本:Puppet Enterprise(专为企业打造、附带支持)和开源版本。两者都有活跃的社区和大量的现成模块。
综合比较
-
入门难度:Ansible通常认为入门最容易,Chef和Puppet的学习曲线相对陡峭。
-
配置语言:Ansible使用YAML,Chef和Puppet使用基于Ruby的DSL,Chef更偏向纯Ruby。
-
运行方式:Ansible通过SSH容易在远端节点上执行命令,而Chef和Puppet则依赖于各自节点上的agent。
-
执行模式:Ansible默认是推模式,而Chef和Puppet默认是拉模式。
-
社区和生态系统:所有三个工具都有庞大的社区和插件生态系统,但因为年龄和受欢迎程度的不同,这些社区的活跃度和可用资源有所不同。
每个工具都有自己的特点和专长,适合不同的组织和流程。选择哪个主要取决于团队的技能栈、现有基础设施、项目需求以及对速度与复杂度的考量。通常,中小型业务或者对速度有强烈需求的组织倾向于选择Ansible,而那些需要企业级功能、已经有Ruby经验和需要严格环境控制的组织倾向于选择Chef或Puppet。
16、如何解决合服期间的合并冲突?
在软件开发中,合并冲突通常是指在版本控制系统如Git中将两个分支合并时发生的问题。这种情况经常在多人协同开发项目时发生,尤其是当两个或更多的开发者对同一个文件的同一个部分做出了修改时。以下是解决合并冲突的步骤和最佳实践:
识别冲突:
- 运行合并命令:首先尝试运行合并命令,例如在Git中使用
git merge或git rebase。 - 查看错误消息:如果存在冲突,版本控制系统将提供错误消息,指示哪些文件发生了冲突。
分析冲突:
- 检查冲突标记:版本控制系统会在冲突文件中添加特殊的冲突标记,例如在Git中,冲突区域会被标记为
<<<<<<< HEAD(当前分支),=======(分隔线),和>>>>>>> branch-name(合并的分支)。 - 理解代码差异:检查每个冲突段落,了解不同分支中代码的差异。
解决冲突:
- 人工干预:人为地决定每处冲突代码的最终版本。
- 沟通:如果冲突涉及多个开发者的工作,与相关人员沟通讨论以确定如何合并代码。
- 编辑文件:移除所有冲突标记,并编辑文件以整合两边的修改。
- 测试修改:确保进行更改后,代码仍然按照预期工作且没有引入新的错误。
提交合并结果:
- 保存更改:一旦解决了所有冲突,并且确认代码工作正常,保存文件。
- 添加和提交:将更改后的文件标记为合并冲突已解决(例如,在Git中使用
git add命令),然后提交更改。 - 完成合并:提交合并结果后,完成合并过程。
避免未来的冲突:
- 保持频繁更新:经常从主分支获取最新更新,并将其合并到你的特性分支中,以减少未来可能出现的合并冲突。
- 明确所有权:在团队中清楚地定义谁负责代码库的哪一部分,有效地避免多人同时修改同一代码块。
- 代码审查:在合并之前,进行代码审查可以提前识别潜在的合并问题。
- 使用冲突解决工具:利用Git合并工具如
git mergetool,或其他专业的合并工具如 Beyond Compare、KDiff3,可以更容易地视觉化冲突和解决方案。 - 合理规划分支策略:实施有效的分支管理策略,例如Gitflow或GitHub Flow,以控制分支的创建和合并。
解决合并冲突可能会是一个挑战,尤其是在一个大型、活跃的开发团队中。然而,跟随上述步骤和最佳实践能够帮助到最小化冲突的发生,并有效地解决它们。重要的是要保持代码库的整洁,确保团队间的良好沟通,并提升每个开发者对版本控制系统的熟悉程度。
17、在生产环境中部署时应考虑哪些安全最佳实践?
在生产环境中部署时,安全是一个至关重要的考量。为了最大限度地保护应用和数据,以下是一些安全最佳实践:
1. 最小权限原则
- 用户和权限管理:为每个服务和用户配置最小的必要权限。
- 访问控制:确保仅授权用户和系统能够访问敏感数据和系统组件。
2. 安全配置
- 默认安全配置:采用默认的安全配置,确保系统初始化时安全。
- 硬化操作系统和服务:移除不必要的软件、服务和入口点,定期更新配置和补丁。
3. 使用安全的部署流程
- 自动化部署:使用自动化部署工具,如Ansible、Chef、Puppet或Kubernetes来部署和管理应用程序,减少人为错误。
- 不要手动编辑生产环境:禁止手动在生产服务器上编辑配置文件或代码等,确保所有的更改都通过版本控制工具。
4. 秘密管理
- 加密敏感数据:使用加密存储敏感信息,如数据库凭证、API密钥和配置文件。
- 使用密钥管理系统:使用密钥保管库,如HashiCorp Vault、AWS KMS、Azure Key Vault或Google Cloud KMS来管理秘密。
5. 安全编码实践
- 代码审计和审查:定期进行代码审计和同行审查以识别潜在的安全问题。
- 依赖管理:使用工具,如OWASP Dependency-Check来管理和更新所依赖第三方库和组件。
6. 数据保护
- 数据加密:对存储的数据与传输的数据进行加密(使用TLS/SSL)。
- 备份数据:定期备份数据,并确保备份同样的安全。
7. 防火墙和网络隔离
- 使用防火墙:使用防火墙来过滤未授权的访问。
- 网络隔离:将运行不同服务的服务器分置在不同的网络区域。
8. 持续监控和日志记录
- 实时监控:实现监控系统,以实时发现可疑活动和性能问题。
- 集中日志管理:采用集中日志管理方案,并对重要日志进行监控。
9. 应用层面的安全性
- Web应用防火墙(WAF):部署WAF来保护应用免受常见攻击,如SQL注入和跨站脚本(XSS)。
- 定期进行安全测试:包括渗透测试、漏洞扫描和静态代码分析。
10. 定期更新和补丁管理
- 安全更新:定期检查并应用安全补丁到所有的系统组件和软件。
- 自动化补丁应用:在可能的情况下,自动应用补丁以减少工作量和错误。
11. 事故响应计划
- 事故响应和恢复计划:准备好应对安全事件的详细计划并进行定期演练。
12. 安全培训
- 教育员工:定期对开发人员、运维人员进行安全最佳实践的培训。
13. 遵循行业标准与合规
- 合规性:遵守行业安全标准和法规,如PCI-DSS、HIPAA、GDPR等。
14. 使用TLS证书
- 强制HTTPS:配置Web服务器总是使用HTTPS保护所有的通信。
15. 第三方安全评估
- 安全审计:定期让第三方进行安全评估来验证你的安全防护措施。
应用这些最佳实践将强化你的生产环境,减少安全事件发生的可能性,并准备好在事件发生时作出响应。保持当前的安全态势需要持续的注意和投入,但它对于保护客户数据和你公司的声誉来说至关重要。安全是一个没有终结的过程,应随着技术的发展和威胁环境的变化不断调整和完善。
18、什么是持续监控,如何实现?
持续监控是一种IT管理策略,它侧重于实时监控企业的技术基础设施。这包括服务器、网络、软件应用、数据中心、云服务等,以确保它们的性能和安全性符合预期水平。持续监控的主要目的是提前识别和解决问题,减轻风险,防止服务中断,以及提供有关系统健康状况的洞察,从而可以制定更好的业务决策。
如何实现持续监控:
1. 设定监控目标和指标
- 定义关键性能指标(KPIs):根据业务和技术需求确定哪些性能指标是至关重要的。
- 确定服务水平协议(SLAs):明确你需要满足的服务质量标准。
2. 选择监控工具和软件
- 生态系统兼容性:选择可与现有技术栈无缝集成的监控工具。
- 功能全面:确保监控工具支持日志集中、性能跟踪、安全监控和警报系统。
- 开源与商业解决方案:根据需求和预算选择开源(如Prometheus, Nagios)或商业解决方案(如Datadog, New Relic)。
3. 配置监控系统
- 配置监控代理:在需要监控的系统上安装和配置监控代理。
- 自定义监控控制板:设置控制板来展示关键指标和警报。
- 设置警报阈值:根据历史数据和业务重要性设置警报阈值。
4. 集成日志管理
- 日志聚合:将各种源的日志数据聚合到一个中央位置。
- 日志分析:使用工具进行实时日志分析,以便于快速诊断问题。
5. 实施自动化响应
- 预设自动响应:对于常见问题,设置自动化脚本来响应和解决。
- 配置自动扩展:对于可能面临的负载增加,自动增加资源。
6. 测试监控系统
- 执行模拟测试:进行模拟故障测试以确保监控系统能有效工作。
- 评估警报系统:确保警报系统可以在问题发生时提供及时、准确的通知。
7. 文档和培训
- 编写操作手册:制定和维护一个详细的监控系统操作手册。
- 培训团队成员:培训IT团队以确保他们能有效使用监控工具。
8. 持续审计和优化
- 定期审计:定期审计监控配置以确保它们仍适用于不断变化的环境。
- 基线调整:根据新收集的数据调整性能和安全基线。
9. 遵循合规性和最佳实践
- 合规性:确保监控实践遵守所有相关的数据保护和隐私法规。
- 安全性:保护监控系统免受未经授权的访问和篡改。
10. 备份和灾难恢复计划
- 确保监控数据的备份:在数据丢失的情况下能够恢复监控配置和历史数据。
- 灾难恢复:在监控系统失败时有计划地恢复操作。
监控工具示例:
- 基础设施监控:Prometheus, Zabbix, Nagios。
- 应用性能监控(APM):New Relic, Datadog, AppDynamics。
- 日志管理:ELK Stack (Elasticsearch, Logstash, Kibana), Splunk, Graylog。
- 网络监控:Wireshark, PRTG Network Monitor, SolarWinds Network Performance Monitor。
- 安全监控:OSSEC, Snort, Security Onion。
通过使用适当的工具和实践,持续监控能够帮助团队更好地理解他们的IT环境,提前识别并解决潜在问题,并为持续改进提供洞察力。这不单单是技术实施的问题,还需要团队对监控的文化认可,定期的维护,以及对监控策略的不断演进。
19、你如何处理在编排容器时遇到的存储问题?
在容器编排环境中处理存储问题是确保数据持久化和高可用性的关键。容器本身是无状态的,意味着一旦容器停止运行,所有保存在容器文件系统上的数据都会丢失。为了解决这个问题,需要使用持久存储解决方案。下面是一些处理编排容器存储问题的步骤和建议:
1. 了解状态和无状态容器
- 无状态容器:不保存与特定实例相关的数据,可以轻松地创建或销毁而不影响应用的其他部分。
- 有状态容器:需要保存数据并在重新部署后还能访问该数据。
2. 使用持久卷
- 持久卷(Persistent Volumes, PV):是独立于容器生命周期的存储对象。
- 持久卷声明(Persistent Volume Claims, PVC):是对 PV 的请求,可以由开发人员配置。
3. 存储卷类型的选择
- 根据所使用的容器编排系统(如Kubernetes)、云供应商或本地环境,选择合适的存储类型:
- 如AWS的EBS、Google Cloud的Persistent Disk、Azure的Azure Disk Storage。
- 本地存储,如 CEHP、GlusterFS。
- 网络文件系统,如NFS。
4. 集成存储解决方案
- 存储类(StorageClasses):在 Kubernetes等编排系统中,StorageClasses定义了如何创建持久化卷。
- 动态卷分配:允许自动创建存储卷以响应 PVC。
5. 数据备份和恢复策略
- 定期备份:确保定期备份持久化存储上的数据。
- 灾难恢复策略:制定并实践一套灾难恢复计划,包括数据恢复测试。
6. 适用性能考虑
- 了解和测试存储选择的性能,特别是在高负载或高吞吐量的情况下。
- 可能需要考虑 IOPS(每秒输入/输出操作次数)限速和吞吐量上限。
7. 网络和存储优化
- 网络延迟:网络延迟可能影响存储性能,特别是在使用远程存储时。
- 调优存储性能:依据应用的需要调优存储层。
8. 可用性和冗余
- 配置多个存储实例来提高冗余性和可用性。
- 在多区域或多可用区设置副本。
9. 安全性
- 加密存储:确保在传输和静态状态下加密敏感数据。
- 访问控制:适当的访问控制可以限制谁可以访问持久化卷。
10. 更新和滚动更新的考虑
- 即使进行更新和滚动更新时,也确保有状态应用的数据持久化和一致性。
11. 监控和警报
- 配置监控系统以跟踪存储性能和可用性。
- 设置警报,当存储资源达到容量或发生故障时能够即时得到通知。
示例:在 Kubernetes 中处理存储问题
- 定义 StorageClass 来指定动态卷分配的类型和参数。
- 创建 PersistentVolumeClaim,应用程序通过 PVC 来请求存储资源。
- 配置 StatefulSet(对于有状态应用),管理其持久化存储和副本。
- 使用数据卷挂载点,确保在 Pod 中明确声明卷挂载位置。
- **使用配置映射(ConfigMaps)和密钥(Secrets)**来管理配置和敏感数据,而非硬编码。
以上是容器编排中解决存储问题的一般性建议。具体实现细节可能取决于使用的编排系统、存储技术、云服务供应商等。在处理存储问题时,同样重要的是保持灵活性,根据应用和组织的不断变化的需求进行调整。
20、12因素应用程序方法论
12因素应用(The Twelve-Factor App)是一个为构建软件即服务(SaaS)应用提出的方法论,它提供了一套最佳实践,帮助开发人员创建在现代云平台上运行的可扩展和可维护的应用程序。这些因素是由Heroku的开发人员提出的,并已成为设计微服务和分布式系统的重要参考框架。
以下是12因素应用程序方法论的详细解释:
1. 基准代码 (Codebase)
- 一份基准代码,多个部署:应用程序的每个版本都是从代码仓库的同一份基准代码构建的。不同的部署环境(如开发、测试、生产)应由同一份代码库通过不同的配置来支持。
2. 依赖项 (Dependencies)
- 显式声明并隔离依赖:应用程序依赖的任何库或工具都应明确声明,通常在一个依赖文件(如
requirements.txt或pom.xml)中,并通过项目使用的依赖工具对其进行管理。
3. 配置 (Config)
- 在环境中存储配置:应用程序的配置信息(如数据库凭证等敏感信息)应该与代码分离,并在运行环境中作为环境变量存储。
4. 后端服务 (Backing Services)
- 把后端服务当作附加资源:数据库、消息队列等后端服务应该被视为可替换的附加资源,与应用程序的绑定应该只通过配置来实现。
5. 构建、发布、运行 (Build, Release, Run)
- 严格分离构建和运行:构建阶段是将代码转换为可执行包的过程;发布阶段是将构建的应用程序与当前的配置合并;运行阶段则是实际运行发布版本的应用程序。
6. 进程 (Processes)
- 以一个或多个无状态进程运行应用程序:应用程序应该以一个或多个无状态进程运行,并且不应在本地持久化任何数据。
7. 端口绑定 (Port Binding)
- 通过端口绑定提供服务:应用程序通常应该自我包含,并通过网络端口提供服务,而不依赖于外部的Web服务器。
8. 并发 (Concurrency)
- 通过进程模型进行扩展:应用的不同部分(例如,HTTP请求处理、后台作业处理)应该在不同的进程中运行以支持并发,并允许独立的扩展。
9. 可处置性 (Disposability)
- 快速启动和优雅关闭:快速和优雅地启停能提高弹性,确保快速的部署或扩展,并保证不会因不正常关闭而产生文件写入等问题。
10. 开发环境与生产环境等价 (Dev/Prod Parity)
- 尽可能保持开发、预发布和生产环境的一致性:最小化环境之间的差异,例如使用相同的服务和工具,使得软件的行为在不同环境中更可预测。
11. 日志 (Logs)
- 把日志当作事件流:应用程序不应该对日志进行管理,而应该将日志输出为事件流并由执行环境进行捕捉、存储和分析。
12. 管理进程 (Admin Processes)
- 管理任务作为一次性进程执行:任何需要进行的管理和维护任务(数据库迁移、脚本运行等)应该在与正常应用程序相似的环境中独立运行。
遵循这些原则能够帮助开发者构建出更加健壮和灵活的云应用程序,从而易于扩展、维护和部署,同时提高开发工作效率和部署速度。这些原则特别适用于微服务架构和容器化技术(如Docker、Kubernetes)的应用,它们强调自动化、敏捷性和解耦合。尽管遵循这些原则可以带来许多好处,但实际的应用场景也需要考虑实际需求和组织条件,适度适配和实施这些原则。
相关文章:
)
Devops相关问题及答案(2024)
1、DevOps 的理念是什么? DevOps是一种组织文化、流程和工具的集合,旨在提高软件交付的速度和质量,通过自动化和持续改进的方法来促进开发(Dev)和运维(Ops)的协作。 DevOps的核心理念包括&…...

掌握Python设计模式,SQL Alchemy打破ORM与模型类的束缚
大家好,反转软件组件之间的依赖关系之所以重要,是因为它有助于降低耦合度和提高模块化程度,进而可以提高软件的可维护性、可扩展性和可测试性。 当组件之间紧密耦合时,对一个组件的更改可能会对其他组件产生意想不到的影响&#…...

性能分析与调优: Linux 磁盘I/O 观测工具
目录 一、实验 1.环境 2.iostat 3.sar 4.pidstat 5.perf 6. biolatency 7. biosnoop 8.iotop、biotop 9.blktrace 10.bpftrace 11.smartctl 二、问题 1.如何查看PSI数据 2.iotop如何安装 3.smartctl如何使用 一、实验 1.环境 (1)主机 …...

Could not erase files or folders:
IDEA删除 git 的 localChanges 内的文件时,提示Could not erase files or folders:。 确认下这个文件是否被打开,忘记关闭了;关闭后可以被删除。(文件被打开的情况下,用操作系统自带的删除,也无法删除成功…...

算法训练营第四十四天|动态规划:完全背包理论基础 518.零钱兑换II 377. 组合总和 Ⅳ
目录 动态规划:完全背包理论基础Leetcode518.零钱兑换IILeetcode377. 组合总和 Ⅳ 动态规划:完全背包理论基础 文章链接:代码随想录 题目链接:卡码网:52. 携带研究材料 思路:完全背包问题,物品可…...

探索计算机网络:应用层的魅力
在当今数字化时代,计算机网络已成为我们生活和工作中不可或缺的一部分。网络的每一层都扮演着独特而重要的角色,而应用层,作为网络模型中用户最直接接触的部分,其重要性不言而喻。这篇文章旨在深入探索应用层的核心概念、功能以及…...
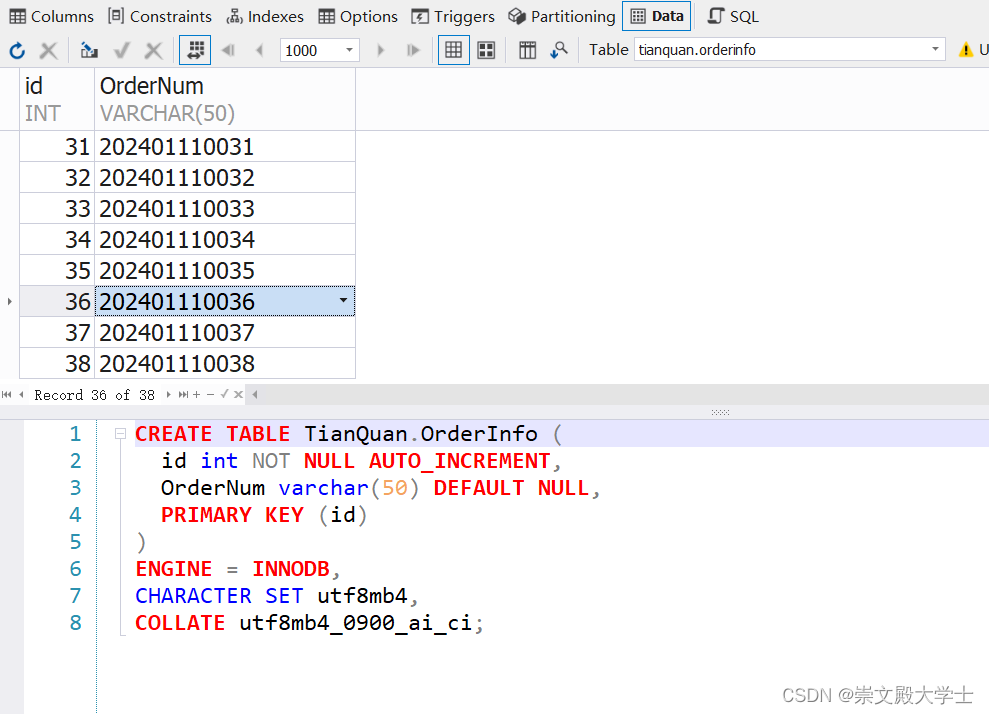
MySQL 按日期流水号 条码 分布式流水号
有这样一个场景,有多台终端,要获取唯一的流水号,流水号格式是 日期0001形式,使用MySQL的存储过程全局锁实现这个需求。 以下是代码示例。 注:所有的终端连接到MySQL服务器获取流水号,如果获取到的是 “-1”…...
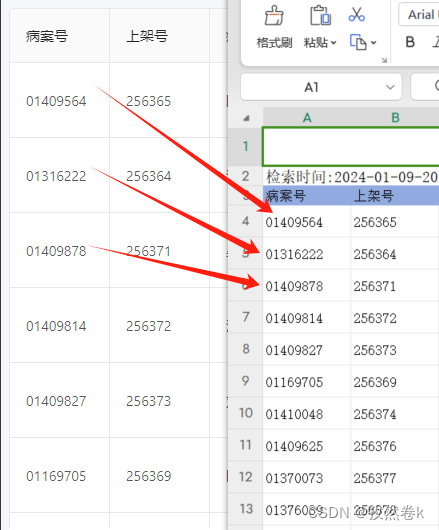
前端导出Excel文件,部分数字前面0消失处理办法
详细导出可以看之前的文章 js实现导出Excel文档_js 通过 接口 导出 xlsx 代码-CSDN博客 今天的问题是导出一些数据时,有些字段是前面带有0的字符串,而导出后再excel中就被识别成了数字 如图本来字符串前面的0 都没了 解决方案 1. 导出的时候在前面加单…...

零基础学Python网络爬虫案例实战 全流程详解 高级进阶篇
零基础学Python网络爬虫案例实战 全流程详解 入门与提高篇 零基础学Python网络爬虫案例实战 全流程详解 高级进阶篇 编辑推荐 本书讲解了Python爬虫技术的高级进阶知识,帮助有一定爬虫基础的读者进一步提高爬虫技术。本书详解了突破反爬机制的常用手段以及Scrapy和…...
(附MATLAB代码实现))
第十二届“中关村青联杯”全国研究生数学建模竞赛-A题:水面舰艇编队防空和信息化战争评估模型(续)(附MATLAB代码实现)
目录 5.3.3 问题三的总结 5.4 问题四的模型建立与求解 5.4.1 问题分析 5.4.2 计算方位角和航向角...

bmp图像文件格式超详解
0 BMP简介 BMP(Bitmap-File)图形文件,又叫位图文件,是Windows采用的图形文件格式,在Windows环境下运行的所有图像处理软件都支持BMP图像文件格式。Windows系统内部各图像绘制操作都是以BMP为基础的。一个BMP文件由四部分组成: B…...

Unity Meta Quest 一体机开发(十三):【手势追踪】自定义交互事件 EventWrapper
文章目录 📕教程说明📕交互事件概述📕自定义交互逻辑⭐方法一:Inspector 面板赋值⭐方法二:纯代码处理 此教程相关的详细教案,文档,思维导图和工程文件会放入 Spatial XR 社区。这是一个高质量…...

13、Redis高频面试题
1、项目中为什么用Redis 我们项目中之所以选择Redis,主要是因为Redis有下面这些优点: 操作速度快:Redis的数据都保存在内存中,相比于其它硬盘类的存储,速度要快很多数据类型丰富:Redis支持 string&#x…...

Koa学习笔记
1、npm 初始化 npm init -y生成 package.json 文件,记录项目的依赖2、git 初始化 git init生成 .git 隐藏文件夹,.git 的本地仓库创建 .gitignore 文件,添加不提交文件的名称3、创建 ReadMe.md 文件 记录项目笔记4、搭建项目 安装 Koa 框架npm install koa5、编写最基本的…...

HiDataPlus 3.3.2-005 搭建(个人的一点心得体会 x86 平台)
HDP 集群搭建 前置安装 yum -y install createrepo yum install -y lrzsz yum install -y wget yum install -y vim修改当前集群机器的主机名 hostnamectl set-hostname XXX 这里的 XXX 就是要设置的当前机器的主机名称。主机名称是集群唯一的,一定不要重复&am…...

【PHP】PHP实现与硬件串口交互,接收硬件发送的实时数据
一、前言 目的:借助虚拟串口软件(VSPD)模拟硬件串口发送数据,使用PHP语言实现接收硬件发送的数据。 我这里的需求是连接天平,把天平的称量数据实时的传送到PHP使用。 使用工具:vspd串口调试工具 使用语…...

HNU-数据库系统-作业
数据库系统-作业 计科210X 甘晴void 202108010XXX 第一章作业 10.09 1.(名词解释)试述数据、数据库、数据库管理系统、数据库系统的概念。 数据,是描述事物的符号记录。 数据库(DB),是长期存储在计算机内、有组织、可共享的大量…...

Python基础知识:整理10 异常相关知识
1 异常的捕获 1.1 基础写法 """基本语法:try:可能发生错误的代码except:如果出现异常,将执行的代码""" try:fr open("D:/abc.txt", "r", encoding"utf-8") except:print("出现异常…...
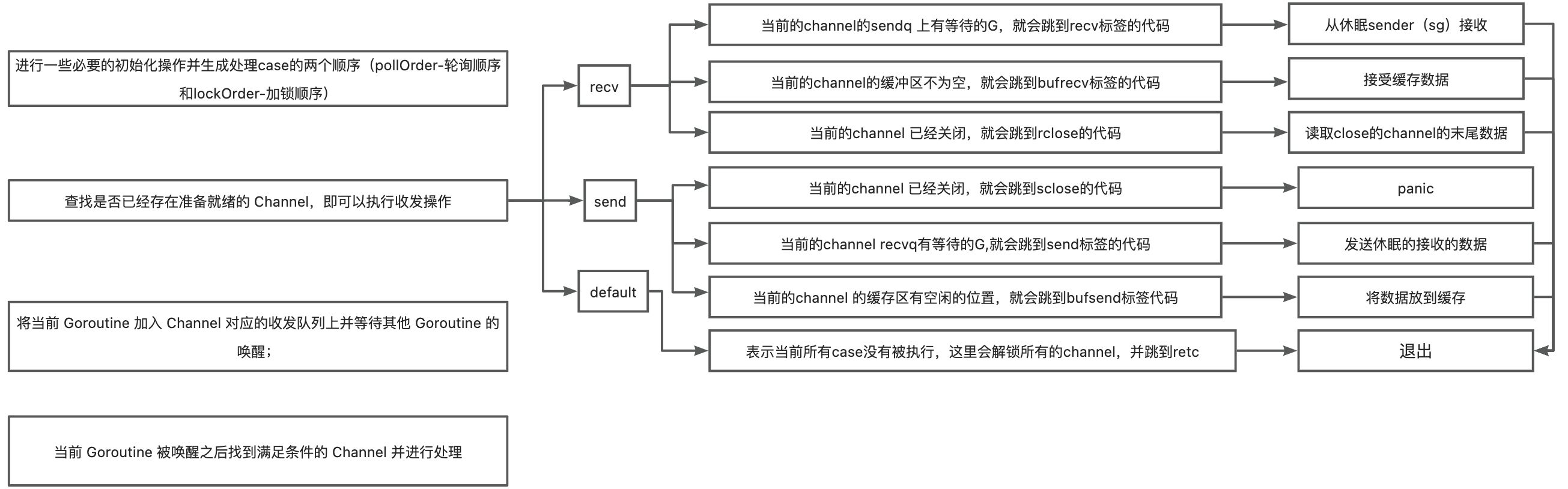
golang并发安全-select
前面说了golang的channel, 今天我们看看golang select 是怎么实现的。 数据结构 type scase struct {c *hchan // chanelem unsafe.Pointer // 数据 } select 非默认的case 中都是处理channel 的 接受和发送,所有scase 结构体中c是用来存储…...
微软Visual Studio产品之Visual C++编程进阶——一维数组(画画版)
我是荔园微风,作为一名在IT界整整25年的老兵,看到不少初学者在学习编程语言的过程中如此的痛苦,我决定做点什么,我小时候喜欢看小人书(连环画),在那个没有电视、没有手机的年代,这是…...

从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界
从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界 在计算机科学中,浮点数的表示和处理是一个既基础又关键的话题。对于从事系统编程、性能优化或逆向工程的开发者来说,理解浮点数在内存中的实际存储形式不仅能帮…...

终极指南:在Windows上直接安装安卓APK文件的5个简单步骤
终极指南:在Windows上直接安装安卓APK文件的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但又厌…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

【CH32V307实战】4P OLED屏I2C驱动移植与快速显示指南
1. CH32V307与4P OLED屏的硬件连接指南 第一次拿到CH32V307开发板和4P OLED屏时,最让我头疼的就是接线问题。这种4线制OLED(通常标注为4P或4PIN)相比传统的7线制简化了不少,但引脚定义各家厂商可能略有差异。经过多次实测…...

解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南
解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中重复的…...

从TPM到机密计算:远程证明技术原理与zap1项目实践指南
1. 项目概述与核心价值最近在整理一些零散的学习笔记时,发现了一个挺有意思的项目,叫Frontier-Compute/zap1-learning-attestation。乍一看这个标题,可能有点让人摸不着头脑,尤其是对于刚接触可信计算或者硬件安全领域的朋友来说。…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

DownKyi技术架构解析:构建高性能B站视频下载引擎的工程实践
DownKyi技术架构解析:构建高性能B站视频下载引擎的工程实践 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

基于RP2040与CircuitPython的HDMI倒计时器:RTC与DVI原生输出实践
1. 项目概述与核心价值如果你手头有一块带HDMI输出的微控制器开发板,比如Adafruit的Feather RP2040 DVI,又恰好需要一个能摆在桌面上、精确到秒的倒计时器,那么今天这个项目就是为你量身定做的。它不仅仅是一个简单的“Hello World”式显示应…...
pydantic-settings、核心BaseModel、字段约束Field()、FastAPI)
Python Pydantic介绍(数据校验、自动类型转换、结构化数据建模、序列化JSON、配置管理)pydantic-settings、核心BaseModel、字段约束Field()、FastAPI
文章目录Python 数据校验神器:Pydantic 完全指南一、什么是 Pydantic二、Pydantic 能解决什么问题1)数据校验(Validation)2)自动类型转换(Parsing)3)结构化数据建模4)序列…...