【存储】存储特性
存储特性
- 精简配置技术(SmartThin)
- SmartThin主要功能
- 容量虚拟化
- 存储空间写时分配:Capacity-on-Write
- 读写重定向:Direct-on-Time
- 应用场景及配置流程
- 存储分层技术(SmartTier)
- 存储分层
- 工作原理
- 关键技术
- 容量初始分配
- 迁移策略
- I/O监控统计分析
- 数据迁移
- 服务质量控制技术(SmartQoS)
- 工作原理
- IO优先级调度技术
- IO流量控制技术
- 缓存分区技术(SmartPartition)
- 工作原理
- 应用场景
- 快照技术
- 映射表
- COW技术
- 快照功能原理
- 应用场景
- 文件系统配额管理技术(SmartQuota)
- 在Quota Tree目录上进行资源管控
- Quota Tree的资源用量
- 应用场景
精简配置技术(SmartThin)

- 上图展示了SmartThin提供的Thin LUN与传统LUN在空间分配上的差异。
- SmartThin技术做了如下改进:
- 改进一:采用SmartThin技术的LUN空间在创建时不真正分配具体空间,而在需要真正使用空间时,再分配具体空间。
- 改进二:有了改进一的基础后,采用SmartThin技术的LUN空间可以在创建后动态调整大小。
- 当出现数据容量超过预期的情况时,可以动态调整该LUN的空间。未使用的空间作为公共的空间可以分配给任何需要空间的LUN。这样,不存在私有的一直不能被使用到的空间,提高了利用率和效能比。同时,动态空间调整提供了在线调整LUN空间大小的能力,可以做到扩容的同时不影响业务。
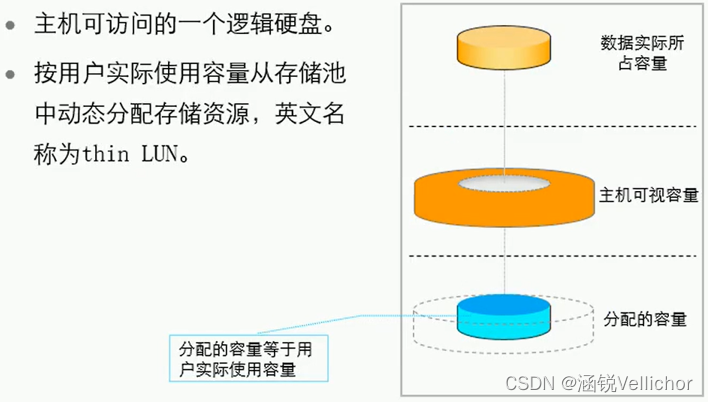
- 数据集合:对存储阵列来说是可映射给主机的LUN。
- 完全可用:可以正常读写。
- 动态分配:写时分配资源。
SmartThin主要功能
- 支持Thin LUN容量虛拟化。SmartThin允许主机可感知容量大于Thin LUN实际占用存储空间。
- 支持存储空间写时分配,SmartThin允许主机在向Thin LUN写入数据时才给Thin LUN分配实际空间,写入多少分配多少。
- 支持Thin LUN在线扩容。SmartThin提供两种在线扩容方式,分别是存储池间接扩容和Thin LUN直接扩容。
- 支持Thin LUN空间回收。SmartThin提供两种空间回收方式,分别是标准SCSI命令空间回收和零数据释放空间回收。
容量虚拟化
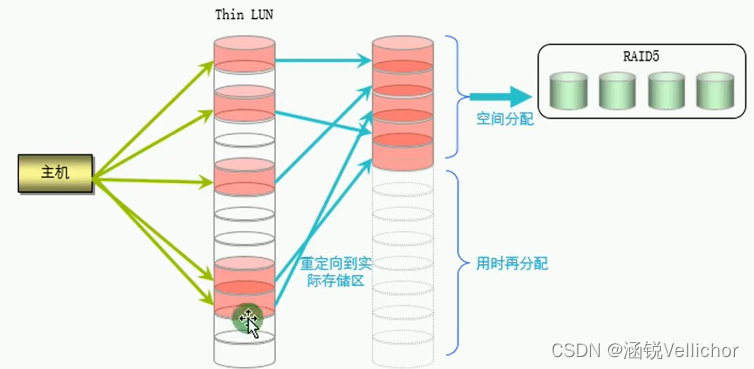
- SmartThin基于RAID2.0+存储虚拟资源池创建Thin LUN,即Thin LUN和传统的Thick LUN共存于同一个存储资源池中。
- 精简LUN(Thin LUN)是在存储池中创建的并可以映射为主机直接访问的逻辑单元。
- Thin LUN的容量大小并不是实际的物理空间,而是一个虚拟值,只有在对Thin LUN进行真正I/O读写时,才通过写时分配的策略从存储资源池中申请物理空间。
- 在RAID2.0+环境中,系统会将存储池空间(即POOL)划分成一个个小粒度的数据块(即CHUNK),基于数据块来构建RAID组(即CKG),使得数据均匀的分布到存储池的所有硬盘上,然后以数据块为单位来进行资源管理。SmartThin使用将CKG切分为更小粒度的Extent(卷中可用于分配的最小存储单元)为单位来进行空间组织。
- 因此,Thin LUN与Thick LUN共存在一个存储池中,同时使用该存储池中的物理存储容量,使得存储规划更加灵活和便利,避免了为Thin LUN和Thick LUN分别提供不同的存储池空间。
存储空间写时分配:Capacity-on-Write
- Thin LUN的写I/O请求会触发空间分配。
- Thin LUN的当前可分配物理空间低于阈值后会向存储池申请新的空间。
Capacity-on-write:当Thin LUN接收到主机写数据请求,首先会通过direct-on-time技术判断该写数据请求的逻辑存储区域是否已经分配了实际存储区,如果尚未分配就会触发空间分配,分配的最小粒度称为Grain, Grain大小为64k,然后将数据写入到新分配的实际存储区域中。
读写重定向:Direct-on-Time

- 由于采用了Capacity-on-write技术,数据的实际存储区域和逻辑存储区域的关系不再是按照确定的公式可以固定不变计算出来的,而是按照写时分配的原则随机映射确定的。
- 所以在对Thin LUN进行读写时需要重定向实际存储区域和逻辑存储区域的关系,重定向依赖于映射表。
- 映射表的主要作用是用来记录实际存储区域和逻辑存储区域的映射关系。在写过程中动态更新映射表,在读过程中查询映射表。因此,Direct-on-time重定向操作也就分为读重定向和写重定向。
- 读重定向:Thin LUN接收到主机读数据请求后,先查询映射表,如果该读数据的逻辑存储区域已分配对应的实际存储区域,则将该读数据的逻辑存储区域重定向到实际存储区域,然后从实际存储区域中读取到数据后,将该数据返回给主机;如果该读数据的逻辑存储区域尚未分配空间,则将该逻辑存储区域的数据置为全0返回给主机。
- 写重定向:Thin LUN接收到主机写数据请求后,先查询映射表,如果该写数据的逻辑存储区域已分配对应的实际存储区域,则将该写数据的逻辑存储区域重定向到实际存储区域,然后将数据写入到实际存储区域中,并返回写成功给主机;如果该写数据的逻辑存储区域尚未分配空间,则通过Capacity-on-write技术操作。
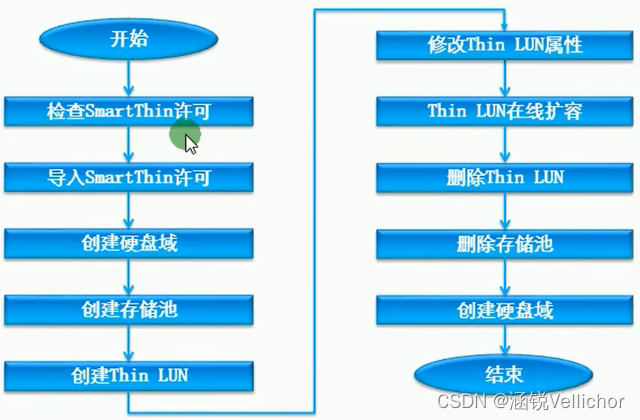
应用场景及配置流程
应用场景:
- 对业务连续性要求较高的系统核心业务,使用智能精简配置,可以在线对系统进行扩容,不会中断业务。例如:银行票据交易系统。
- 应用系统数据增长速度无法准确评估的业务,使用智能精简配置,可以按需分配物理存储空间,避免浪费,例如: E-mail邮箱服务、网盘服务等。
- 多种业务系统混杂并且对存储需求不-的业务,使用智能精简配置,可以让不同业务去竞争物理存储空间,实现物理存储空间的优化配置,例如:运营商服务等。
配置流程:
存储分层技术(SmartTier)

- SmartTier(智能数据分级)是华为公司在RAID2.0+技术之上自主研发的分级存储软件,它自动将不同活跃度的数据和不同特点的存储介质动态匹配,从而提高存储系统性能并降低用户成本。
- 分级存储技术通过数据迁移完成数据的分级存储。目前,分级存储技术主要分手工迁移和自动迁移两类。
- 手工迁移是系统维护人员根据当前存储系统运行的状态、各个业务系统的压力情况,手动将数据从一个LUN中迁移到另外一个LUN中。
- 自动迁移是根据系统当前对某些文件或者块的访问频率,识别出热点与非热点数据,根据热点与非热点数据分配不同的存储介质,将频繁访问的热点数据自动迁移到高性能的存储介质中,而将低周期访问的非热点数据自动迁移到大容量,低成本的存储介质中。
存储分层
| 存储层级 | 硬盘类型 | 硬盘特点 | 数据特点 |
|---|---|---|---|
| 高性能层 | SSD盘 | SSD盘的响应时间很短,每单位存储容量成本很高。 | 高性能层适宜存储访问频率非常高的数据。 |
| 性能层 | SAS盘 | SAS盘的响应时间短,每单位存储容量成本适中。 | 性能层适宜存储访问频率适中的数据。 |
| 容量层 | NL-SAS盘 | NL-SAS盘的响应时间长,每单位存储容量成本低。 | 容量层适宜存储访问频率低的数据。 |
- SmartTier将不同存储介质按性能高低划分为三个存储层,由高至低分别是SSD盘组成的层(简称高性能层)、SAS盘组成的层(简称性能层)、NL-SAS盘组成的层(简称容量层)。
- 每个存储层分别使用相同的硬盘类型和RAID策略。
工作原理

- 存储池是一个或多个存储层的逻辑组合,最多可支持三个级别的存储层。存储池包含的硬盘类型决定其可以创建的存储层。由单一硬盘类型组成的存储池无法创建不同存储层,因此不能应用SmartTier进行智能化数据存储管理。
- LUN创建在存储池中,在应用SmartTier特性之前其数据分布在同一个存储池的不同存储层。
- SmartTier将LUN数据按照一定粒度划分,该粒度被称为“数据迁移粒度”或“数据块”。数据迁移粒度在创建存储池时设置,且设置后不可更改。
- 当存储池中存在两种或以上的硬盘类型时,用户可以应用SmartTier特性充分利用存储池中的每个存储层。数据迁移过程中,存储池以数据块为单位识别数据活跃度并将整个数据块迁移至其他存储层。
- 存储系统经历I/O监控、数据排布分析、数据迁移三个阶段实现SmartTier。
- 新数据写入LUN时,存储系统根据初始容量分配策略,将新写入的数据分配在相应存储层。
- 随着数据生命周期的推移,数据的活跃度会发生变化。SmartTier将不同活跃度的数据迁移至不同性能的存储层,为存储系统提供更高的性能,并且数据迁移过程不会影响其他新数据的写入。
关键技术

容量初始分配

初始容量分配策略包括四类:自动分配、优先从高性能层分配、优先从性能层分配、优先从容量层分配。
迁移策略

- 自动迁移:LUN配置了自动迁移策略,该LUN的数据块按照访问频度做迁移,访问频度最高的迁往高性能层,访问频度适中的迁往性能层,访问频度最低的迁往容量层。无特殊要求,推荐配置自动迁移,总体性能提升最佳。
- 向高性能层迁移:LUN配置了向高性能层迁移,无论数据块访问频度是高还是低,该LUN的所有数据块都会迁往高性能层级,会占用较多高性能存储资源。只有对该LUN的性能有特殊要求时,才配置向高性能层迁移。
- 向低性能层迁移:LUN配置了向低性能层迁移,无论数据块访问频度是高还是低,该LUN的所有数据块都会迁往容量层。当某个LUN用于归档业务,或者用于对性能要求低的业务,可配置向低性能层迁移。
- 不迁移:LUN配置了不迁移,该LUN的所有数据块都不会做迁移,这是LUN创建时的默认策略,只有购买了SmartTier的License,才能修改为其他迁移策略。
I/O监控统计分析

- 热数据和冷数据并没有用一个绝对值做区分。存储池高性能层容量可以存放A个数据块,性能层容量可以存放B个数据块, 在迁移时把该存储池的所有自动迁移策略的LUN的所有数据块按访问频度拉通排序,在迁移时把访问频度最高的A个数据块存放到高性能层,把访问频度较高的B个数据块存放到性能层,访问频度排在后面的其他数据块放到容量层。
- 原则是尽量让访问频度高的数据块使用性能好的存储介质。
数据迁移
- 迁移速度可以设置为高速、中速和低速,分别对应的具体迁移速度位单控制器100M/S、20M/S和10M/S,默认的迁移速度为低。
- 为了减少SmartTier数据迁移对主机业务性能的影响,设置的迁移速度是数据迁移速度允许的上限值。数据迁移让主机业务优先,利用存储设备的空闲资源做迁移,依据主机业务压力实时调整迁移的速度。主机业务压力小时,迁移速度调大;主机业务压力小时,迁移速度调小;无论如何调整,迁移速度都不会大于设置的迁移速度。
- 低速:适合在选择的数据迁移时段有较大的业务压力时使用。
- 中速:适合在选择的数据迁移时段有较适中的业务压力时使用。
- 高速:适合在选择的数据迁移时段几乎没有业务,或主机业务对性能要求不敏感的情况下使用。
- 数据迁移粒度
- 512KB~64MB(根据业务配置,例如视频监控业务,适合大的迁移粒度)
- 数据迁移计划
- 手动方式:可在任意时刻设置时间段进行数据迁移
- 定时方式:只能在预先设置的时间计划内进行数据迁移
- 数据迁移速率
- 可提供三种不同级别的迁移速率:高、中、低
- 根据当前业务负载,动态调整速率,确保不会对当前业务造成明显影响
服务质量控制技术(SmartQoS)

- SmartQoS特性是华为OceanStor V3 融合存储系统上提供的一项存储QoS功能。
- 如图所示,它能够对存储系统中的资源进行智能分配和调节,在整个存储路径上进行端到端的细粒度控制,从而满足多种不同重要性业务在同一台存储设备上的不同QoS要求。
工作原理
- IO优先级调度技术:通过区分不同业务的重要性来划分业务响应的优先级。在存储系统为不同业务分配计算资源的时候,优先保证高优先级业务的资源分配请求。在计算资源紧张的情况下,为高优先级的资源分配较多的资源,以此尽可能保证高优先级业务的服务质量。当前用户可以配置的优先级分为高、中、低三个等级。
- IO流量控制技术:基于传统的令牌桶机制,针对用户设置的性能控制目标(IOPS、带宽)进行流量限制,通过IO流控机制,限制某些业务由于流量过大而影响其它业务。
- IO性能保障技术:基于按权重调度的方式,允许用户为高优先级业务指定最低性能目标(最小IOPS、 最小带宽、最大时延),当该业务的最低性能无法保障时,系统内部通过对保障业务与非保障业务按照权重进行调度,从而尽力使保障业务达到最低性能目标。
IO优先级调度技术

- SmartQoS特性的优先级调度技术基于LUN和文件系统的优先级实现。
- 因此每个LUN和文件系统对象都有一个优先级属性,这个属性由用户配置并保存在数据库中,当一个IO从主机发送到阵列,这个IO将会根据其归属的LUN或文件系统来获得这个优先级属性,并且在整个IO路径上携带这个优先级信息。
- 用户在创建LUN或文件系统的时候需要指定所创建的LUN或文件系统的优先级。如果用户不进行指定,则所创建的LUN或文件系统的优先级属性默认为低优先级。
LUN或文件系统创建后,其优先级属性可以根据用户的需要手动修改。
IO流量控制技术

- SmartQoS特性的IO流量控制技术的性能目标是基于令牌的分发和控制实现的。当用户为某个流控组设置了性能上限,那么这个性能上限会被转化成对应的令牌。在存储系统中,如果用户要限制的流量类型是IOPS,那么一个IO即对应一个令牌;如果设定的性能目标是带宽,那么一个扇区对应一个令牌。
- 每个流控队列都有一个令牌桶,SmartQoS会定期向每个流控队列的令牌桶中放入一定数量的令牌,令牌的数量取决于用户设定的这个流控组的性能上限。即如果用户设定性能上限为IOPS =10000,则令牌分发算法就会在每秒将此流控组的令牌桶中的令牌数设置为10000。
- 当流控队列进行出队处理的时候,会查看此队列的令牌桶中是否有足够的令牌,如果有,则取出一个IO进行处理,并消耗这个IO对应的令牌;如果没有令牌,则必须等待令牌桶中有足够的令牌可以用为止。
缓存分区技术(SmartPartition)
- SmartPartition (智能缓存分区)是OceanStor V3融合存储系统为应对存储融合趋势下QoS的挑战而设计的智能缓存分区技术,其核心思想是通过对系统核心资源的分区,保证关键应用的性能。管理员可以针对不同的应用配置不同大小的缓存分区,系统将保证该分区中的缓存资源被该应用独占,并根据业务实际情况实时动态调配不同分区中的其他资源,从而保证位于该分区的应用性能。
- SmartPartion本质上就是一种Cache分 区技术,Cache分 区在业界是比较成熟的一项技术,推出的时间也比较长。当前主流的存储厂商,比如EMC和HDS,均推出了各自的Cache分区特性。从技术层面来看,各大厂商实现的方式基本一致, 都是将有限的Cache资源划分为多个逻辑区域进行管理,区别主要在于Cache分区内部的具体的一些算法和调整策略。

- 典型的IT系统架构由计算、网络、存储三大部分组成,在传统的“烟囱式”架构中,不同的应用系统相对独立,单个存储需要面对的应用数量不多(一般在5个以下)。
- 图中每种颜色代表了一种不同的业务。可以看到,这些业务的I/O模式是不同的,对缓存及访盘并发的需求也是不同的。
- 多种业务混合争抢并发资源和缓存资源,导致服务质量不可保证。比如,业务N抢占的访盘并发同其主机并发并不匹配,其结果就是缓存中业务N的数据会越来越多,对其他业务性能造成影响;而业务3如果是关键业务,就意味着其业务性能不能得到保证。
工作原理

- Cache分区技术通过隔离不同的业务所需要的资源,保证某些关键业务的服务质量。
- 在存储系统中,某个业务能够使用的缓存容量是影响其服务质量的一个主要因素。
- 该业务在该存储系统上可以占有的缓存大小是影响存储系统性能的最主要因素:
- 对写业务来说,更多的缓存意味着更高的写合并率、写命中率(同一块数据在缓存中被再次写中的比率)和更好的访盘顺序度;对读业务来说,更多的缓存通常意味着更高的读命中率。
- 同时,不同类型的业务对缓存的需求也有很大不同:对顺序类业务来说,缓存不需要很大,只需要满足I/O合并要求即可;而对随机类业务来说,更大的缓存通常意味着更好的访盘顺序度,从而带来性能的提升。
- SmartPartition可以针对不同的业务(实际控制对象为LUN和文件系统)分配不同大小的缓存分区资源,从而保证关键业务的服务质量。
应用场景

- 随着存储系统的性能和容量不断增强增大,将多个应用同时部署在一台存储系统上,不仅简化用户的存储系统架构,还能减少用户配置和管理成本。部署在同一台存储系统上的多个应用,会争抢存储资源,将导致各业务的性能受到严重影响。
- 通过SmartPartition特性可以为不同的业务指定不同的缓存分区,满足关键业务的运行要求。同时,根据业务读写压力,可以分别设置相应读分区和写分区大小。如读业务量较大,可为其分配更多的读分区容量;若全是写业务,则可以配置较小的读分区容量。
快照技术
- 定义:快照是指源数据在某个时间点的一致性数据副本。快照生成后可以被主机读取,也可以作为某个时间点的数据备份。
- 快照的主要特点包括:
- 瞬间生成:存储系统可以在几秒钟内生成一-个快照, 获取源数据的一致性副本。
- 占用存储空间少:生成的快照数据并非完整的物理数据拷贝,不会占用大量存储空间。所以即使源数据量很大,也只会占用很少的存储空间。
映射表
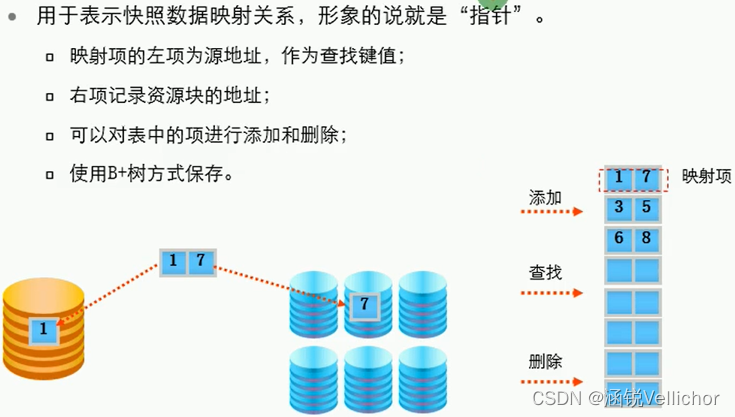
- 映射表用来表示快照的实际数据所在。
- 映射表分为两类:独享映射表和共享映射表。其原理是相同的,不同的地方在于独享映射表记录写快照发生的数据变更,共享映射表记录的是写源LUN发生的变更。
COW技术
当快照被激活时(此时刻称为快照时间点),主机读写的具体操作如下:
- 激活快照后,源LUN有数据写入。
- 首先将查询快照映射表,如果映射表中对应该地址的映射项不存在时,需要进行copy-on-write(写前拷贝),写前拷贝完成后在映射表中记录备份的源LUN数据信息。如果映射项存在,则直接覆盖写入源LUN的对应位置。
- 写前拷贝,即读取源LUN对应位置的数据写入COW卷的空间。
- COW卷空间与源LUN空间分布在同一个POOL中,写入COW卷即写入POOL的空间区域。
- 写前拷贝完成后,再将主机数据写入源LUN所在的POOL空间。
快照功能原理
- 快照创建并激活后,会生成与源卷一致的数据副本。存储系统在源卷中划分出COW数据空间并自动生成快照卷。
- 由于对源卷没有写操作,COW Meta区域和COW Data区域中均没有记录。
- 由于对快照卷没有写操作,Snapshot Meta Volume和Snapshot Data Volume中均没有记录。
- 快照激活后,当应用服务器对源卷有数据写入请求时,存储系统不会立即写入新数据。存储系统利用写前拷贝机制先将写前拷贝数据拷贝到COW数据空间中,并修改映射表中的映射关系,然后将新数据写入源卷。
- 说明:在一个快照周期内,同一位置的数据只执行一次写前拷贝,根据映射表中相应值确定。再次写入数据时,将直接覆盖。例如:对于数据“DataX”,查询到 映射表中相应值为“1”,表示已经进行过一次写前拷贝;如再有写数据请求,将直接写入,不再将“DataX”拷贝到COW数据空间中。
- 快照激活后,应用服务器可以对快照卷进行写操作。应用服务器下发的写请求后,数据将直接写入快照卷,并在映射表(独享部分)中记录数据在快照卷中的存放位置。
- 快照激活后,应用服务器可以对快读快照卷(快照卷已写入数据)进行读操作。 应用服务器下发读快照请求后,通过映射表(独享部分)确定快照数据的存放位置,并读取数据。
- 快照激活后,应用服务器可以对快读快照卷(快照卷未写入数据)进行读操作。 应用服务器下发读快照请求后,通过映射表(共享部分)确定快照数据的存放位置,并读取数据。
应用场景
直接使用快照进行数据备份。使用快照备份可以在以下场景中迅速恢复数据:
- 病毒感染。
- 人为误操作。
- 恶意篡改。
- 系统宕机造成的数据损坏。
- 应用程序BUG造成的数据损坏。
- 存储系统BUG造成的数据损坏。
- 存储介质损坏(只有基于split mirror技术的快照能够恢复数据)。
文件系统配额管理技术(SmartQuota)

- 随着虚拟化的大行其道,云计算技术的发展,IT系统面临着资源利用效率、以及如何有效管理的挑战。在典型的IT存储系统中,只要存储资源(磁盘空间)是可用的,就会被用户使用,直至耗尽。从经济角度来说,需要一种方法控制存储资源的使用及其增长。
- 在NAS文件服务环境中,通常以共享目录的方式将资源提供给使用的部门、组织或个人。而每个部门或个人,都有其独特的资源需求或限制。因此,系统需要基于共享目录,因地制宜地对各个使用者,进行资源分配和限制。SmartQuota(文件系统配额)正是用于解决这个需求的技术,该技术可以针对目录、用户、用户组这三类资源的使用者分别进行资源控制。
- SmartQuota的主要作用是方便系统管理员管控资源使用者(包括目录、用户、用户组)的存储资源,以限制指定使用者可使用的磁盘空间,从而避免出现某些用户过度占用资源的问题。
在Quota Tree目录上进行资源管控

- 在SmartQuota特性中,Quota Tree是一个重要的概念。简单来说,Quota Tree就是文件的一级目录。但从管理角度看, Quota Tree不仅是一个目录,更是一个配置对象。这就意味着,Quota Tree只能通过管理终端(命令行或GUI管理界面)来创建、删除和修改,而不能通过客户端主机来修改。另外,作为配置配额时的载体,目录配额、用户配额、以及组配额都只能在Quota Tree上配置。我们总结一下Quota Tree与普通目录存在的差别:
- Quota Tree只能由管理员通过命令行或GUI管理界面,进行创建、删除、重命名等操作,且管理员只能删除空的Quota Tree。
- Quota Tree可以通过协议进行共享,且正在共享时,不允许被改名和删除。
- 不允许跨Quota Tree进行移动文件(NFS协议)或剪切文件(CIFS协议)操作,即不允许在两个不同Quota Tree目录之间进行文件的MV操作(NFS协议)或剪切操作(CIFS协议)。
- 不允许跨Quota Tree的硬链接,即不允许在两个不同的Quota Tree之间进行硬链接操作。
Quota Tree的资源用量

- 目录的资源用量(目录配额的统计值)。
- Quota Tree目录中所有文件的存储容量、文件数的总量。
- 用户/用户组的资源用量(用户/用户组配额的统计值)。
- Quota Tree目录中所有创建者为特定用户/用户组的文件的存储容量、文件数的总量
应用场景

- 在单个Quota Tree内部,管理员可配置目录配额限制对应部门总的资源,然后为部门内部的使用者、群组分别配置用户配额、用户组配额,灵活限制一个部门内各使用者的资源。
- Share为研发部门的共享目录(Quota Tree 0):
- 配置Quota Tree 0的目录配额,限制研发部总的可用资源。
- 配置经理A的私有用户配额,单独限制经理A的可用资源。
- 配置项目组G/E的私有用户组配额,限制项目组G/E的可用资源
相关文章:
【存储】存储特性
存储特性精简配置技术(SmartThin)SmartThin主要功能容量虚拟化存储空间写时分配:Capacity-on-Write读写重定向:Direct-on-Time应用场景及配置流程存储分层技术(SmartTier)存储分层工作原理关键技术容量初始…...
Qt使用OpenGL进行多线程离屏渲染
基于Qt Widgets的Qt程序,控件的刷新默认状况下都是在UI线程中依次进行的,换言之,各个控件的QWidget::paintEvent方法会在UI线程中串行地被调用。若是某个控件的paintEvent很是耗时(等待数据时间CPU处理时间GPU渲染时间)…...
Vue基础入门讲义(三)-指令
文章目录1.什么是指令?2.插值表达式2.1.花括号2.2.插值闪烁2.3.v-text和v-html3.v-model4.v-on4.1.基本用法4.2.事件修饰5.v-for5.1.遍历数组5.2.数组角标5.3.遍历对象6.key7.v-if和v-show7.1.基本使用7.2.与v-for结合7.3.v-else7.4.v-show8.v-bind8.1. 属性上使用v…...
)
pod资源限制,探针(健康检查)
pod资源限制,探针(健康检查)一、资源限制当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源当为 Pod 中的容器指定了 request 资源时,调度器就使用…...

Python | 蓝桥杯进阶第一卷——字符串
欢迎交流学习~~ 专栏: 蓝桥杯Python组刷题日寄 蓝桥杯进阶系列: 🏆 Python | 蓝桥杯进阶第一卷——字符串 🔎 Python | 蓝桥杯进阶第二卷——递归(待续) 💝 Python | 蓝桥杯进阶第三卷——动态…...

2023-03-03 mysql列存储-cpu占用100%-追踪思路
摘要: 最近在处理mysql列存储时, 发现在执行explain时, cpu占用达到了100%. 本文分析定位该问题的思路过程 现象: mysqld进程占用100%使用kill processlist终止会话, 无响应查看show processings; 发现一直在运行mysql> show processlist; +----+-----------------+-----…...
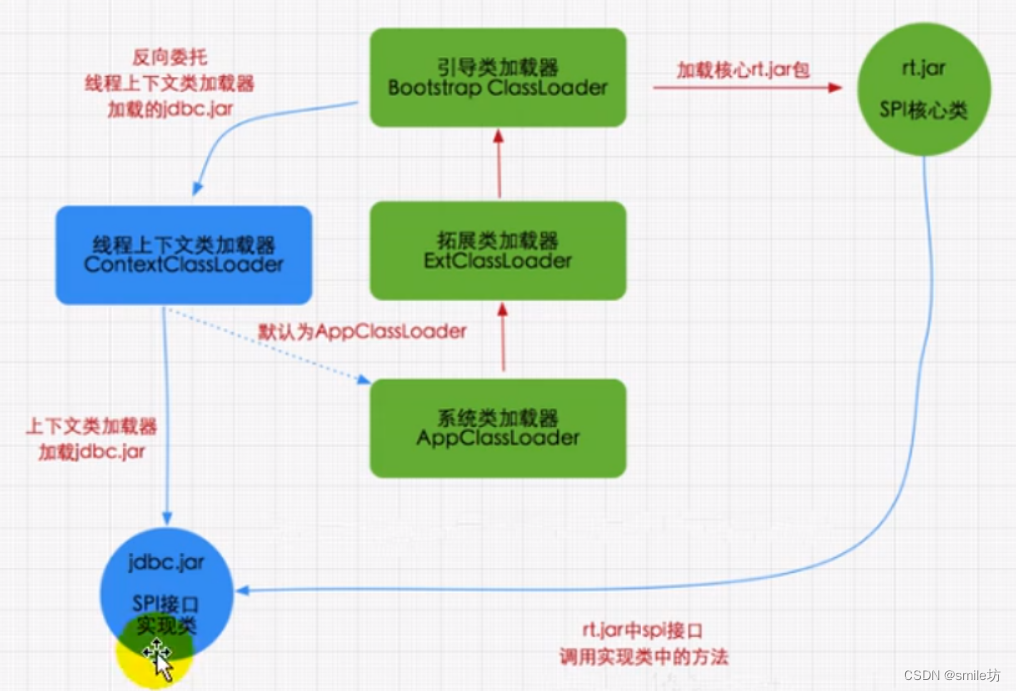
JVM—类加载子系统
JVM细节版架构图 本文针对Class Loader SubSystem这一块展开讲解类加载子系统的工作流程 类加载子系统作用 1.类加载子系统负责从文件系统或者网络中加载class文件,class文件在文件开头有特定的文件标识即16进制CA FE BA BE; 2.加载后的Class类信息…...

在codeIgniter3中session.php中的数组追加值
如果key是字符串时,输出什么值?会直接把atime()的时间戳添加到key是字符串时,输出什么值?会直接把atime()的时间戳添加到key是字符串时,输出什么值?会直接把atime()的时间戳添加到arr[‘vars’]数组里面&am…...
Windows环境下Gpu版本的Pytorch安装
文章目录安装步骤总览(6步)1 首先看电脑有没有显卡,显卡是否支持cuda软件1.1 先看自己电脑是否有显卡1.2 两种方法看自己的电脑的显卡驱动支持的CUDA1.3 显卡,显卡驱动、CUDA、CUDNN 4者说明2 安装CUDA,就是1个软件2.1 检测自己电…...
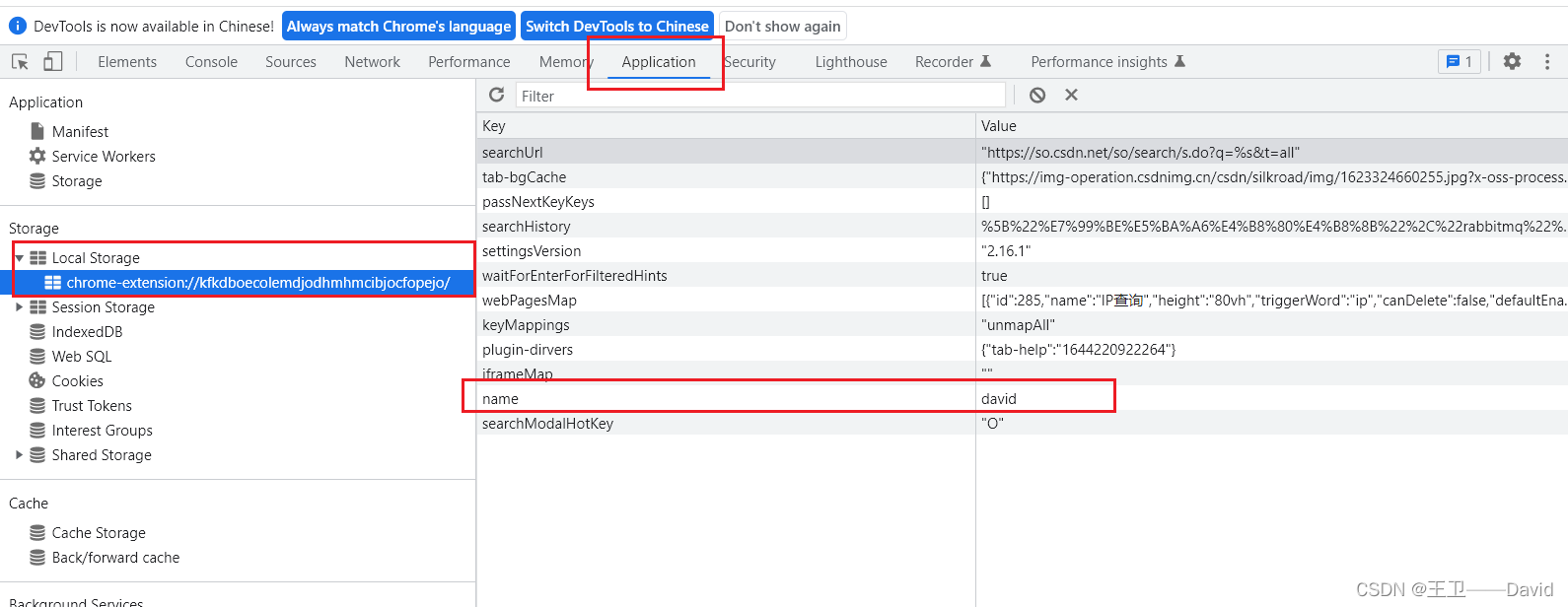
项目实战典型案例13——学情页面逻辑问题
学情页面逻辑问题一:背景介绍二:学情页面逻辑问题分析逻辑问题缓存滥用的问题三:LocalStorage基础知识数据结构特性应用场景localStorage常用方法四:总结升华一:背景介绍 本篇博客是对项目开发中出现的学情页面逻辑问…...

工作日志day02
1.云计算? 相关职位 开源软件和linux起源: 自由软件之父:理查德.斯托曼linux之父:林纳斯.本纳第克特.托瓦兹linux发行版 RHEL:Red Hat Enterprise Linux 红帽linux商业公司CentOS:Community Enterprise Operating Sys…...

C++Primer16.1.6节练习
练习16.28: 简易的shared_ptr代码如下 #include <iostream> #include <vector> #include <list> using namespace std;//shared_ptr模板 template<typename T>class SharedPtr {friend SharedPtr<T>& MakeShared(T* t); public…...

初尝并行编程
进程被分为后台进程和应用进程 大部分后台进程在系统开始运行时被操作系统启动,完成操作系统的基础服务功能。大部分应用进程由用户启动,完成用户所需的具体应用功能 进程由程序段、数据段、进程控制块三部分组成 程序段也被称为是代码段,…...

keepalived学习记录:对其vip漂移过程采用gdb跟踪
对其vip漂移过程采用gdb跟踪keepalived工具主要功能产生vip漂移过程两种情况gdb调试常用命令gdb调试时打到的函数栈(供学习参考)函数栈的图是本人理解下画的,不对请多指正 keepalived主要有三个进程,父进程是core进程,…...
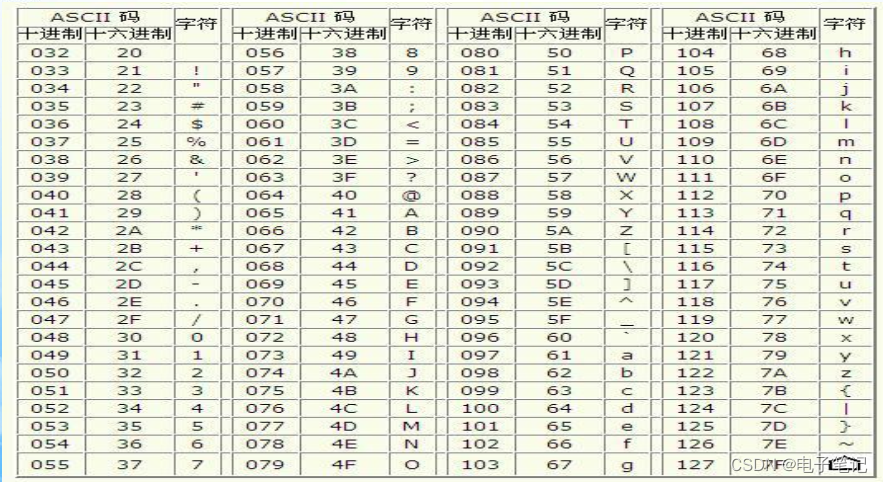
51单片机串口通讯原理及程序源码-----day8
51单片机串口通讯原理及程序源码-----day8 1.定义单片机为TTL电平:高 5V 低 0V RS232电平: 计算机的串口高 -12V 低12V 所以计算机与单片机之间通讯时需要加电平转换芯片CH340T 、 MAX232。 2.通信分类: (1)并行通信通…...
)
mongodb入门到使用(下)
mongodb中常用命令操作一、用户操作二、创建用户三、数据库操作基本操作四、扩展操作五、集合操作一、用户操作 在mongo中使用mongodb都需要在admin数据库中操作。然后在使用下面的命令 use admin二、创建用户 db.createUser({"user":"imooc", #用户名&q…...
云HIS系统源码 医院his源码 云his源码
大型医院his系统源码 SaaS运维平台多医院入驻强大的电子病历完整文档 ,有演示 一、系统概述: 基层卫生健康云是一款满足基层医疗机构各类业务需要的健康云产品。该产品能帮助基层医疗机构完成日常各类业务,提供病患挂号支持、病患问诊、电子…...

朴素贝叶斯法学习笔记
频率派和贝叶斯派 频率派认为可以通过大量实验,从样本推断总体。比如假定总体服从均值为μ\muμ,方差为σ\sigmaσ的分布。根据中心极限定理,是可以通过抽样估算总体的参数的,而且抽样次数越多,对总体的估计就越准确。…...

vscode与C++安装与使用【不好用来骂我】
网上教程很多,但是都不太好用,这是我垃圾堆里淘金淘出来的教程: 安装软件 安装 Visual Studio Code: 你需要下载并安装 Visual Studio Code,可以在官网下载 https://code.visualstudio.com/download。 安装 C 扩展: 在 Visual S…...
计算相似度实现性能优化)
C++11使用多线程(线程池)计算相似度实现性能优化
需求:图像识别中,注册的样本多了会影响计算速度,成为性能瓶颈,其中一个优化方法就是使用多线程。例如,注册了了3000个特征,每个特征4096个float。可以把3000个特征比对放到4个线程中进行计算,然…...

活动策划27年:一场手印启动,让我读懂“谨慎”二字
活动策划27年:一场手印启动,让我读懂“谨慎”二字做活动策划27年,千余场活动下来,我常跟团队说:“做活动,不怕累,就怕措手不及的意外。”每一场活动前,我都要反复推演流程࿰…...

用电脑自动玩小红书,OpenClaw+ADB让效率翻倍!附详细教程“
本文介绍了如何使用OpenClaw(运行在MacOS上)结合ADB工具实现Android手机的自动化操作。内容涵盖Android手机配置(开启开发者选项和USB调试)、MacOS环境准备(安装ADB工具和配置ADBKeyboard支持中文输入)&…...

AI智能体编排平台OpenClaw-Core:构建标准化、可复用的AI工作流
1. 项目概述:从“单打独斗”到“交响乐团”的AI协作革命 如果你和我一样,在过去几年里深度使用过各种大语言模型,那你一定经历过这种“甜蜜的烦恼”:ChatGPT在创意写作上天马行空,但在代码生成上偶尔会“一本正经地胡说…...

基于Rust构建AI智能体平台:架构设计与工程实践
1. 从零到一:构建你自己的AI智能体平台最近几年,大语言模型(LLM)的爆发式发展,让“智能体”(Agent)从一个学术概念,迅速变成了提升工作效率的利器。你可能用过一些现成的AI工具&…...

AD覆铜时引脚‘粘’在一起了?别慌,三步排查法帮你搞定Modified Polygon和覆铜粘连
AD覆铜引脚粘连问题排查指南:从现象到解决方案的完整路径 在PCB设计过程中,覆铜操作看似简单却暗藏玄机。许多Altium Designer用户都曾遭遇过这样的场景:当你信心满满地完成布线,准备进行最后的覆铜操作时,突然发现不同…...

底特律汽车产业转型:从全球平台战略到创新生态重构
1. 从废墟中重生:底特律汽车产业的韧性复苏如果你在2010年前后关注过全球汽车产业,或者对美国的工业经济史稍有了解,那么“底特律”这个名字,在当时几乎就是“衰败”与“绝望”的同义词。这座曾经的“汽车之城”,在200…...
)
从CuteCom到代码:手把手教你用I.MX6ULL实现串口双向通信(附完整工程源码)
从CuteCom到代码:手把手教你用I.MX6ULL实现串口双向通信(附完整工程源码) 在嵌入式开发中,串口通信是最基础也最常用的调试手段之一。无论是简单的数据收发,还是复杂的协议交互,串口都能提供稳定可靠的通信…...

深入解析epoll ET模式与守护进程
引言在前面的文章中,我们学习了 epoll 的基础用法和 LT 模式。本文将深入讲解两个重要主题:epoll 的 ET 模式:边缘触发模式的编程要点与完整实现守护进程:Linux 后台服务进程的原理与编写规范ET 模式是 epoll 高性能的关键&#x…...

外科医生AI认知变迁:从技术好奇到价值驱动的全球调查
1. 项目概述:一场关于外科医生与AI认知变迁的全球对话作为一名长期关注技术与医疗交叉领域的从业者,我始终对一个问题抱有浓厚兴趣:当一项颠覆性技术从实验室走向临床,真正使用它的医生们究竟在想什么?他们的期待、困惑…...

手把手教你配置Synopsys DesignWare PCIe控制器:从寄存器读写到ATU映射实战
Synopsys DesignWare PCIe控制器深度配置指南:从寄存器操作到DMA通信实战 1. PCIe控制器基础架构解析 Synopsys DesignWare PCIe控制器作为业界广泛采用的IP核,其架构设计充分考虑了灵活性和可扩展性。控制器核心由以下几个关键模块组成: Tra…...