大模型学习与实践笔记(五)
一、环境配置
1. huggingface 镜像下载 sentence-transformers 开源词向量模型
import os# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')2.下载 NLTK 相关资源
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pagescd nltk_datawget -O averaged_perceptron_tagger.zip https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/taggers/averaged_perceptron_tagger.zipwget -O punkt.zip https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/tokenizers/punkt.zip二、检索库构建
1.构建知识向量库
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os# 获取文件路径函数
def get_files(dir_path):# args:dir_path,目标文件夹路径file_list = []for filepath, dirnames, filenames in os.walk(dir_path):# os.walk 函数将递归遍历指定文件夹for filename in filenames:# 通过后缀名判断文件类型是否满足要求if filename.endswith(".md"):# 如果满足要求,将其绝对路径加入到结果列表file_list.append(os.path.join(filepath, filename))elif filename.endswith(".txt"):file_list.append(os.path.join(filepath, filename))return file_list# 加载文件函数
def get_text(dir_path):# args:dir_path,目标文件夹路径# 首先调用上文定义的函数得到目标文件路径列表file_lst = get_files(dir_path)# docs 存放加载之后的纯文本对象docs = []# 遍历所有目标文件for one_file in tqdm(file_lst):file_type = one_file.split('.')[-1]if file_type == 'md':loader = UnstructuredMarkdownLoader(one_file)elif file_type == 'txt':loader = UnstructuredFileLoader(one_file)else:# 如果是不符合条件的文件,直接跳过continuedocs.extend(loader.load())return docs# 目标文件夹
tar_dir = ["/root/data/InternLM","/root/data/InternLM-XComposer","/root/data/lagent","/root/data/lmdeploy","/root/data/opencompass","/root/data/xtuner"
]# 加载目标文件
docs = []
for dir_path in tar_dir:docs.extend(get_text(dir_path))# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 构建向量数据库
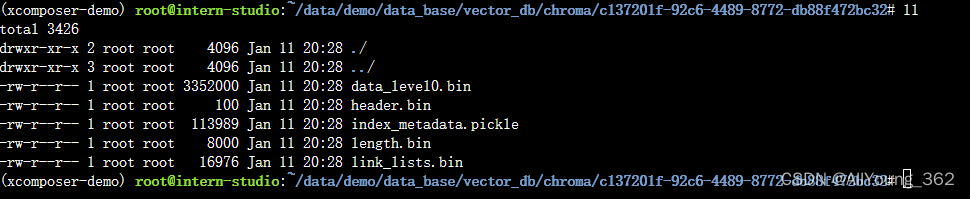
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(documents=split_docs,embedding=embeddings,persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
运行效果
2.将InternLM 接入 LangChain
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchclass InternLM_LLM(LLM):# 基于本地 InternLM 自定义 LLM 类tokenizer : AutoTokenizer = Nonemodel: AutoModelForCausalLM = Nonedef __init__(self, model_path :str):# model_path: InternLM 模型路径# 从本地初始化模型super().__init__()print("正在从本地加载模型...")self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()self.model = self.model.eval()print("完成本地模型的加载")def _call(self, prompt : str, stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any):# 重写调用函数system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文."""messages = [(system_prompt, '')]response, history = self.model.chat(self.tokenizer, prompt , history=messages)return response@propertydef _llm_type(self) -> str:return "InternLM"3.构建检索问答链
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'# 加载数据库
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embeddings
)from LLM import InternLM_LLM
llm = InternLM_LLM(model_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b")
llm.predict("你是谁")from langchain.prompts import PromptTemplate# 我们所构造的 Prompt 模板
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
有用的回答:"""# 调用 LangChain 的方法来实例化一个 Template 对象,该对象包含了 context 和 question 两个变量,在实际调用时,这两个变量会被检索到的文档片段和用户提问填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)from langchain.chains import RetrievalQAqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})# 检索问答链回答效果
question = "什么是InternLM"
result = qa_chain({"query": question})
print("检索问答链回答 question 的结果:")
print(result["result"])# 仅 LLM 回答效果
result_2 = llm(question)
print("大模型回答 question 的结果:")
print(result_2)
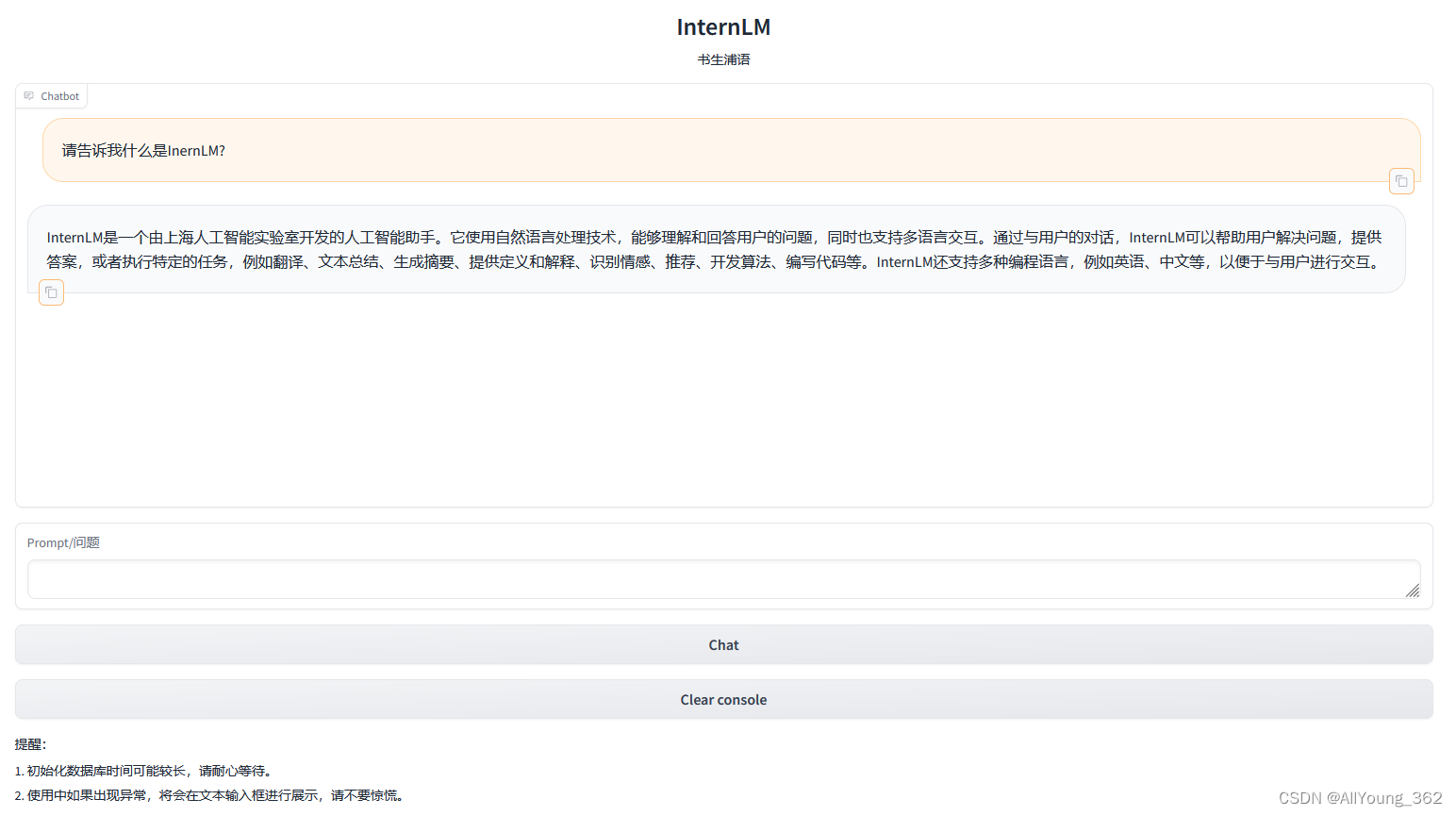
运行效果:

4.gradio 部署
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
from LLM import InternLM_LLM
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQAdef load_chain():# 加载问答链# 定义 Embeddingsembeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 向量数据库持久化路径persist_directory = 'data_base/vector_db/chroma'# 加载数据库vectordb = Chroma(persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上embedding_function=embeddings)# 加载自定义 LLMllm = InternLM_LLM(model_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b")# 定义一个 Prompt Templatetemplate = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。{context}问题: {question}有用的回答:"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)# 运行 chainqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})return qa_chainclass Model_center():"""存储检索问答链的对象 """def __init__(self):# 构造函数,加载检索问答链self.chain = load_chain()def qa_chain_self_answer(self, question: str, chat_history: list = []):"""调用问答链进行回答"""if question == None or len(question) < 1:return "", chat_historytry:chat_history.append((question, self.chain({"query": question})["result"]))# 将问答结果直接附加到问答历史中,Gradio 会将其展示出来return "", chat_historyexcept Exception as e:return e, chat_historyimport gradio as gr# 实例化核心功能对象
model_center = Model_center()
# 创建一个 Web 界面
block = gr.Blocks()
with block as demo:with gr.Row(equal_height=True): with gr.Column(scale=15):# 展示的页面标题gr.Markdown("""<h1><center>InternLM</center></h1><center>书生浦语</center>""")with gr.Row():with gr.Column(scale=4):# 创建一个聊天机器人对象chatbot = gr.Chatbot(height=450, show_copy_button=True)# 创建一个文本框组件,用于输入 prompt。msg = gr.Textbox(label="Prompt/问题")with gr.Row():# 创建提交按钮。db_wo_his_btn = gr.Button("Chat")with gr.Row():# 创建一个清除按钮,用于清除聊天机器人组件的内容。clear = gr.ClearButton(components=[chatbot], value="Clear console")# 设置按钮的点击事件。当点击时,调用上面定义的 qa_chain_self_answer 函数,并传入用户的消息和聊天历史记录,然后更新文本框和聊天机器人组件。db_wo_his_btn.click(model_center.qa_chain_self_answer, inputs=[msg, chatbot], outputs=[msg, chatbot])gr.Markdown("""提醒:<br>1. 初始化数据库时间可能较长,请耐心等待。2. 使用中如果出现异常,将会在文本输入框进行展示,请不要惊慌。 <br>""")
gr.close_all()
# 直接启动
demo.launch()
运行效果:

相关文章:
大模型学习与实践笔记(五)
一、环境配置 1. huggingface 镜像下载 sentence-transformers 开源词向量模型 import os# 设置环境变量 os.environ[HF_ENDPOINT] https://hf-mirror.com# 下载模型 os.system(huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-…...

100个GEO基因表达芯片或转录组数据处理之GSE126848(003)
写在前边 虽然现在是高通量测序的时代,但是GEO、ArrayExpress等数据库储存并公开大量的基因表达芯片数据,还是会有大量的需求去处理芯片数据,并且建模或验证自己所研究基因的表达情况,芯片数据的处理也可能是大部分刚学生信的道友…...

1. Presto基础
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。文章目录 一、presto基础操作二、时间函数0、当前日期/当前时间1、转时间戳1)字符串转时间戳 (推荐)2)按照format指定的格式,将字符串str…...
ChatGPT可以帮你做什么?
学习 利用ChatGPT学习有很多,比如:语言学习、编程学习、论文学习拆解、推荐学习资源等,使用方法大同小异,这里以语言学习为例。 在开始前先给GPT充分的信息:(举例) 【角色】充当一名有丰富经验…...
20240111在ubuntu20.04.6下解压缩RAR格式的压缩包
20240111在ubuntu20.04.6下解压缩RAR格式的压缩包 2024/1/11 18:25 百度搜搜:ubuntu rar文件怎么解压 rootrootrootroot-X99-Turbo:~/temp$ ll total 2916 drwx------ 3 rootroot rootroot 4096 1月 11 18:28 ./ drwxr-xr-x 25 rootroot rootroot 4096 1月…...
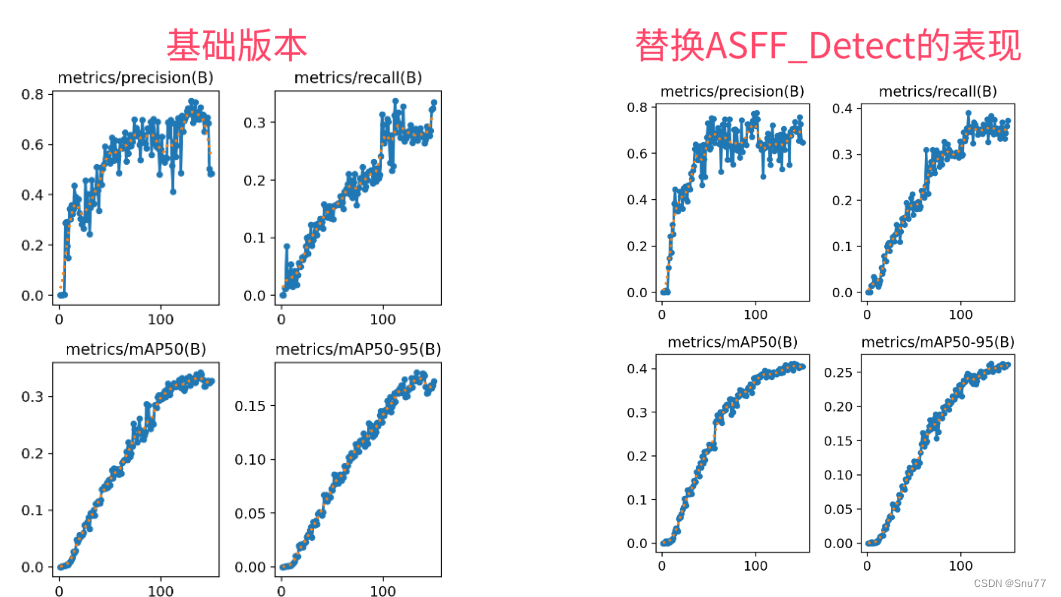
YOLOv5改进 | 检测头篇 | ASFFHead自适应空间特征融合检测头(全网首发)
一、本文介绍 本文给大家带来的改进机制是利用ASFF改进YOLOv5的检测头形成新的检测头Detect_ASFF,其主要创新是引入了一种自适应的空间特征融合方式,有效地过滤掉冲突信息,从而增强了尺度不变性。经过我的实验验证,修改后的检测头在所有的检测目标上均有大幅度的涨点效果,…...
)
第十三章 接口测试(笔记)
一、接口测试分类 内部接口:测试被测系统各个子模块之间的接口,或者被测系统提供给内部系统使用的接口 外部接口: 1.被测系统调用外部的接口 2.系统对外提供的接口 接口测试重点:检查接口参数传递的正确性,接口功能的正确性,输出结果的正确性,以及对各种异常情况的容错…...
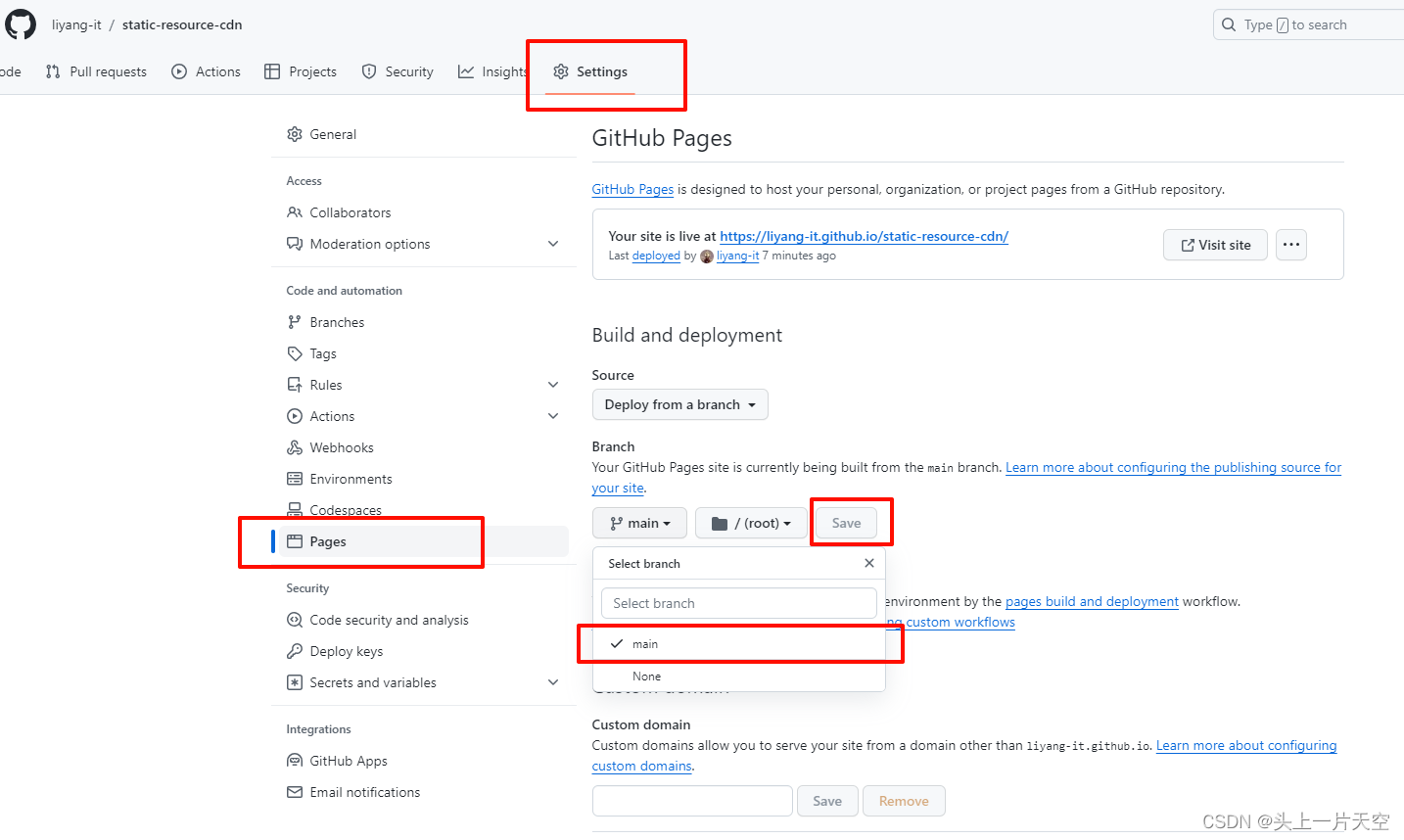
Github搭建图床 github搭建静态资源库 免费CDN加速 github搭建图床使用 jsdelivr CDN免费加速访问
Github搭建图床 github搭建静态资源库 免费CDN加速 github搭建图床使用 jsdelivr CDN免费加速访问 前言1、创建仓库2、开启 gh-pages页面功能3、访问测试 前言 写博客文章时,图片的上传和存放是一个问题,使用小众第三方图床,怕不稳定和倒闭&…...

Airtest-Selenium实操小课②:刷B站视频
1. 前言 上一课我们讲到用Airtest-Selenium爬取网站上我们需要的信息数据,还没看的同学可以戳这里看看~ 那么今天的推文,我们就来说说看,怎么实现看b站、刷b站的日常操作,包括点击暂停,发弹幕,点赞&#…...
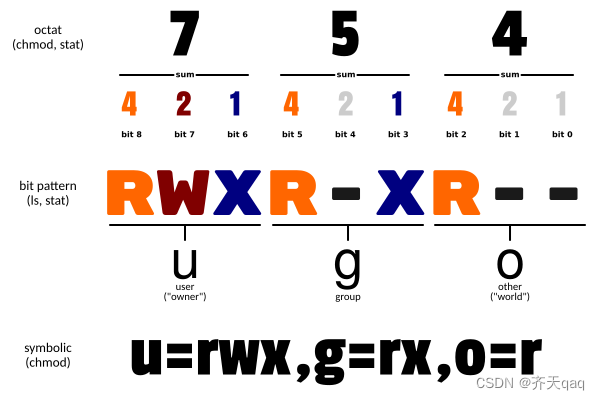
Linux chmod命令详解
Linux chmod(英文全拼:change mode)命令是控制用户对文件的权限的命令 Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)…...

求幸存数之和 - 华为OD统一考试
OD统一考试(C卷) 分值: 100分 题解: Java / Python / C++ 题目描述 给一个正整数列nums,一个跳数jump,及幸存数量left。运算过程为:从索引为0的位置开始向后跳,中间跳过 J 个数字,命中索引为 J+1 的数字,该数被敲出,并从该点起跳,以此类推,直到幸存left个数为止。…...
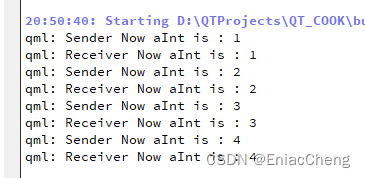
【QML COOK】- 008-自定义属性
前面介绍了用C定义QML类型,通常在使用Qt Quick开发项目时,C定义后端数据类型,前端则完全使用QML实现。而QML类型或Qt Quick中的类型时不免需要为对象增加一些属性,本篇就来介绍如何自定义属性。 1. 创建项目,并编辑Ma…...
前端页面优化做的工作
1.分析模块占用空间 new (require(webpack-bundle-analyzer).BundleAnalyzerPlugin)() 2.使用谷歌浏览器中的layers,看下有没有影响性能的模块,或者应该销毁没销毁的 3.由于我们页面中含有很大的序列帧动画,所以会导致页面性能低࿰…...
Spark六:Spark 底层执行原理SparkContext、DAG、TaskScheduler
Spark底层执行原理 学习Spark运行流程 学习链接:https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ 一、Spark运行流程 流程: SparkContext向管理器注册并向资源管理器申请运行Executor资源管理器分配Executor,然后资源管理器启动Execut…...

关于鸿蒙的笔记整理
提示:有使用过 vue 或 react 的小伙伴更容易理解 知识点强调: ArkTS所有内容都不支持深层数据更新 UI渲染 文章目录 一、关于样式1 . 默认单位 vp2 . 写公共样式 二 、 加载图片三 、 自定义构建函数 Builder四、构建函数-BuilderParam 传递UI五 、 父子…...
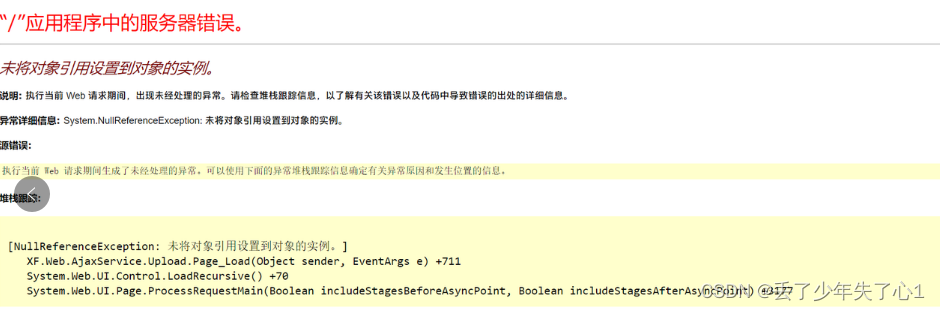
【漏洞复现】先锋WEB燃气收费系统文件上传漏洞 1day
漏洞描述 /AjaxService/Upload.aspx 存在任意文件上传漏洞 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和利益,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作…...
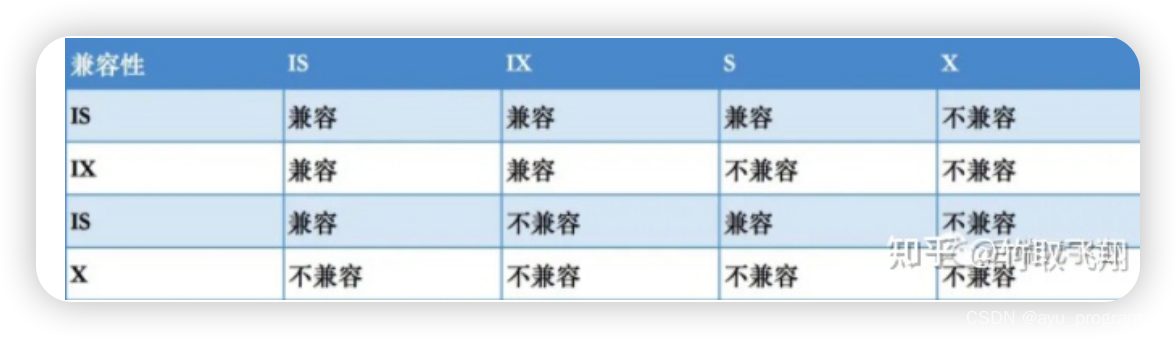
MYSQL篇--锁机制高频面试题
Mysql锁机制 1对mysql的锁有了解吗? 首先我们要知道,mysql的锁 其实是为了解决在并发事务时所导致的数据不一致问题的一种处理机制,也就是说 在事务的隔离级别实现中,就需要利用锁来解决幻读问题 然后我们可以聊到锁的分类 按锁…...
创建一个郭德纲相声GPTs
前言 在这篇文章中,我将分享如何利用ChatGPT 4.0辅助论文写作的技巧,并根据网上的资料和最新的研究补充更多好用的咒语技巧。 GPT4的官方售价是每月20美元,很多人并不是天天用GPT,只是偶尔用一下。 如果调用官方的GPT4接口&…...
靶机实战(10):OSCP备考之VulnHub Tre 1
靶机官网:Tre: 1[1] 实战思路: 一、主机发现二、端口发现(服务、组件、版本)三、漏洞发现(获取权限) 8082端口/HTTP服务 组件漏洞URL漏洞(目录、文件)80端口/HTTP服务 组件漏洞URL漏…...

在windows11系统上利用docker搭建linux记录
我的windows11系统上,之前已经安装好了window版本的docker,没有安装的小伙伴需要去安装一下。 下面直接记录安装linux的步骤: 一、创建linux容器 1、拉取镜像 docker pull ubuntu 2、查看镜像 docker images 3、创建容器 docker run --…...

SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器
SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 还在为格斗游戏中同时按下W和S导致角色卡顿而烦恼吗?或者在射击游戏急停转…...

YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具
YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...
)
【限时公开】后印象派专属--ar 16:9 --style raw --stylize 800参数组合包(含塞尚构图/修拉点彩/劳特累克动态线共12套已验证prompt模板)
更多请点击: https://intelliparadigm.com 第一章:后印象派艺术精神与Midjourney风格迁移的本质逻辑 后印象派并非对印象派的简单延续,而是对主观表达、结构重构与象征张力的自觉回归——梵高旋转的星云、塞尚凝练的几何体、高更原始的色域&…...

百度网盘直链解析终极指南:如何实现高速下载的完整技术方案
百度网盘直链解析终极指南:如何实现高速下载的完整技术方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在云存储服务普及的今天,百度网盘作为国内用…...

Onekey:重构Steam Depot清单下载流程的现代化解决方案
Onekey:重构Steam Depot清单下载流程的现代化解决方案 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Onekey作为一款专为Steam Depot清单设计的自动化下载工具,通过其创…...
)
中文长文本语音崩溃?ElevenLabs API超时/截断/静音突变?20年语音架构师紧急发布的6行容错重试+分段重对齐代码(已验证10万+字符稳定输出)
更多请点击: https://intelliparadigm.com 第一章:中文长文本语音崩溃的根因诊断与现象复现 中文长文本语音合成(TTS)在处理超长段落(如 >3000 字)时频繁出现进程中断、内存溢出或静音输出,…...

构建通用Docker工具镜像:从设计到实践的全流程指南
1. 项目概述:一个“反重力”的Docker镜像?看到这个镜像名runzhliu/docker-antigravity,很多人的第一反应可能是好奇和疑惑。在Docker Hub上,以“antigravity”(反重力)命名的镜像并不常见,它不像…...

基于Claude API构建可编程AI智能体:从对话到自动化生产单元
1. 项目概述:从Claude中“招聘”一个AI伙伴最近在GitHub上看到一个挺有意思的项目,叫“hire-from-claude”。初看这个标题,你可能会有点摸不着头脑:Claude不是Anthropic公司开发的那个AI助手吗?怎么还能从它那里“招聘…...

MPLAB代码配置器实战:图形化配置PIC/AVR单片机外设,提升开发效率
1. 项目概述:为什么你需要关注MPLAB代码配置器如果你正在使用Microchip的PIC或AVR单片机,并且还在手动编写外设初始化代码、一遍遍翻阅数据手册核对寄存器位,那今天聊的这个工具,可能会让你有种“相见恨晚”的感觉。我说的就是MPL…...

AI原生代码库OpenCode:从代码生成到项目级协同的开发新范式
1. 项目概述:一个面向开发者的AI原生代码库最近在GitHub上看到一个挺有意思的项目,叫opencode-ai/opencode。光看名字,你可能会觉得这又是一个“AI写代码”的工具,或者是一个AI模型的代码仓库。但如果你点进去仔细研究一下&#x…...