Flink构造宽表实时入库案例介绍
1. 安装包准备
| Flink 1.15.4 安装包 |
| Flink cdc的mysql连接器 |
| Flink sql的sdb连接器 |
| MySQL驱动 |
| SDB驱动 |
| Flink jdbc的mysql连接器 |
2. 入库流程图
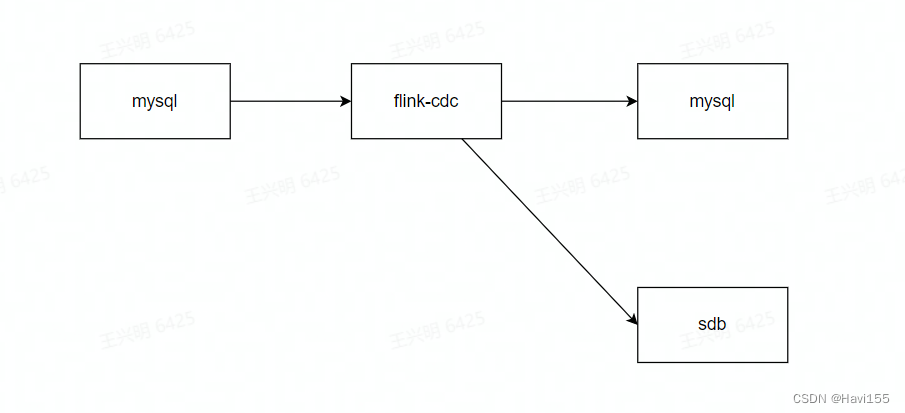
3. Flink安装部署
- 上传Flink压缩包到服务器,并解压
| tar -zxvf flink-1.14.5-bin-scala_2.11.tgz -C /opt/ |
- 复制依赖至Flink中
| cp sdb-flink-connector-3.4.8-jar-with-dependencies.jar /opt/flink-1.14.5/lib |
- 修改flink-conf.yaml文件
| vi conf/flink-conf.yaml |
- 修改master文件
| vi conf/masters |
- 修改worker文件
| vi conf/workers |
- 拷贝到集群其他机器
| scp -r /opt/flink-1.14.5 sdbadmin@upgrade2:/opt/ |
- 启动flink集群
| [sdbadmin@upgrade1 flink-1.14.5]$ ./bin/start-cluster.sh |
- 启动flink-SQL
| [sdbadmin@upgrade1 flink-1.14.5]$ ./bin/sql-client.sh |
4. 实时入库
编写造数程序进行造数
4.1 环境准备
4.1.1 开启mysql的binlog
- 创建binlog文件夹
| [sdbadmin@upgrade1 mysql]$ mkdir /opt/sequoiasql/mysql/database/3306/binlog |
- 开启binlog
| vim /opt/sequoiasql/mysql/database/3306/auto.cnf |
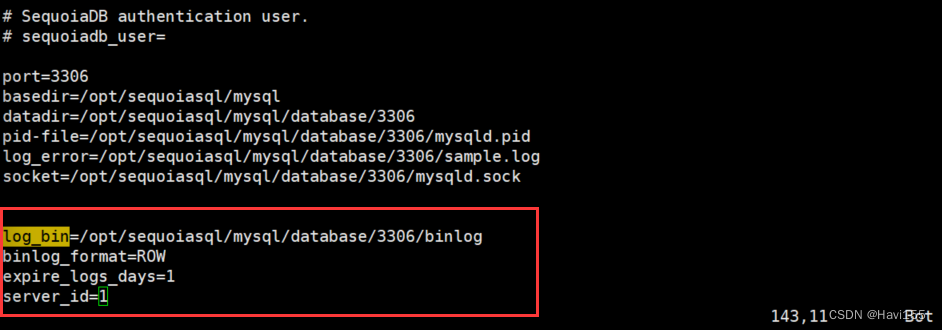
配置完成之后,重启mysql
| [sdbadmin@upgrade1 mysql]$ ./bin/sdb_mysql_ctl stop myinst |
4.1.2 创建mysql表
创建库
| create database sbtest; |
创建表
| CREATE TABLE sbtest1 ( |
| CREATE TABLE sbtest2 ( |
| CREATE TABLE sbtest3 ( |
创建flink入库表
| CREATE TABLE sbtest4 ( |
4.1.3 创建flink映射表
需要用到flink-sql-connector-mysql-cdc-2.2.1.jar
| CREATE TABLE sbtest1_mysql ( |
| CREATE TABLE sbtest2_mysql ( |
| CREATE TABLE sbtest3_mysql ( |
创建flink --> mysql入库映射表
需要用到flink-connector-jdbc_2.11-1.14.6.jar
| CREATE TABLE sbtest4_mysql ( |
创建flink --> mysql入库映射表
需要用到sdb-flink-connector-3.4.8-jar-with-dependencies.jar
| CREATE TABLE sbtest_sdb ( |
4.2 MySQL实时入库
4.2.1 Flink left join
| select sdb1.id, sdb1.uuid, sdb1.name1, sdb2.name2, sdb3.name3, sdb1.age, sdb1.time1 |
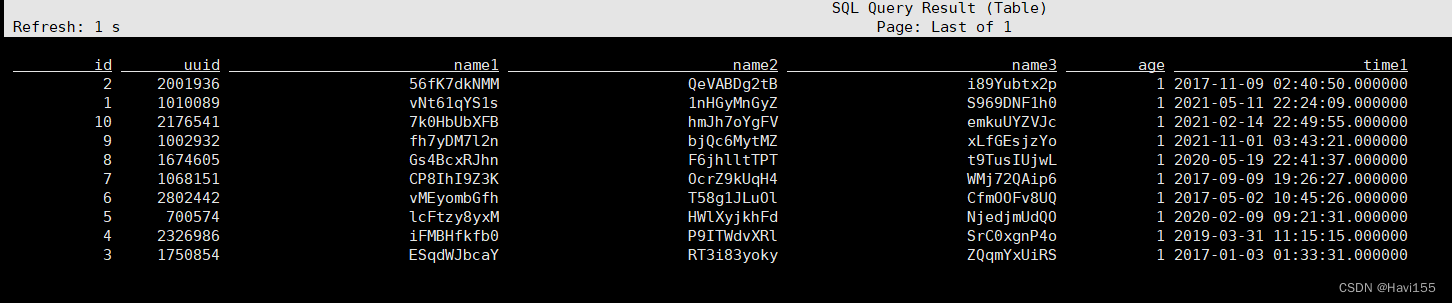
4.2.2 mysql实时入库
| insert into sbtest4_mysql select sdb1.id, sdb1.uuid, sdb1.name1, sdb2.name2, sdb3.name3, sdb1.age, sdb1.time1 |
查看Flink任务
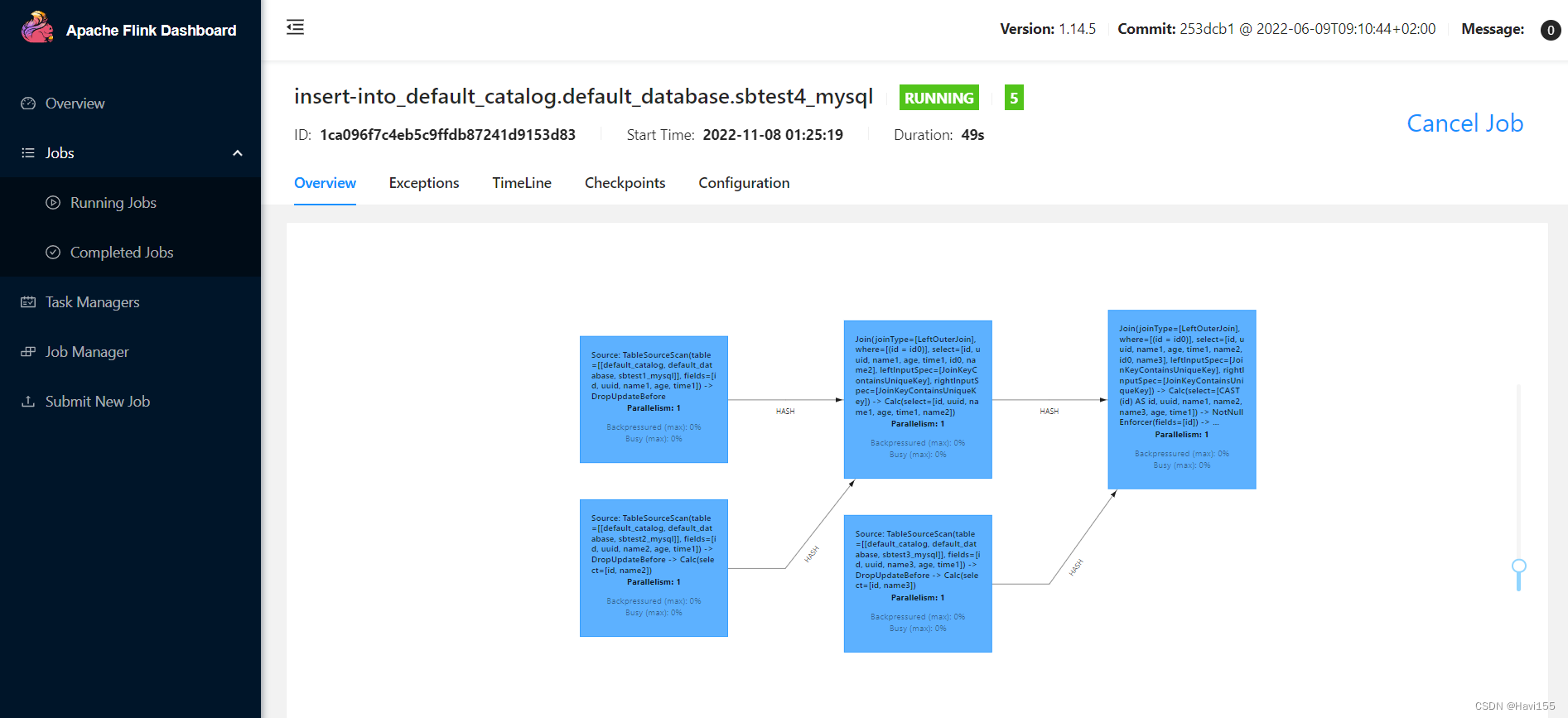
查看可以成功入库

4.3 SDB实时入库
4.3.1 Flink left join
| select sdb1.id, sdb1.uuid, sdb1.name1, sdb2.name2, sdb3.name3, sdb1.age, sdb1.time1 |

4.3.2 sdb实时入库
| insert into sbtest_sdb select sdb1.id, sdb1.uuid, sdb1.name1, sdb2.name2, sdb3.name3, sdb1.age, sdb1.time1 |
查看Flink任务
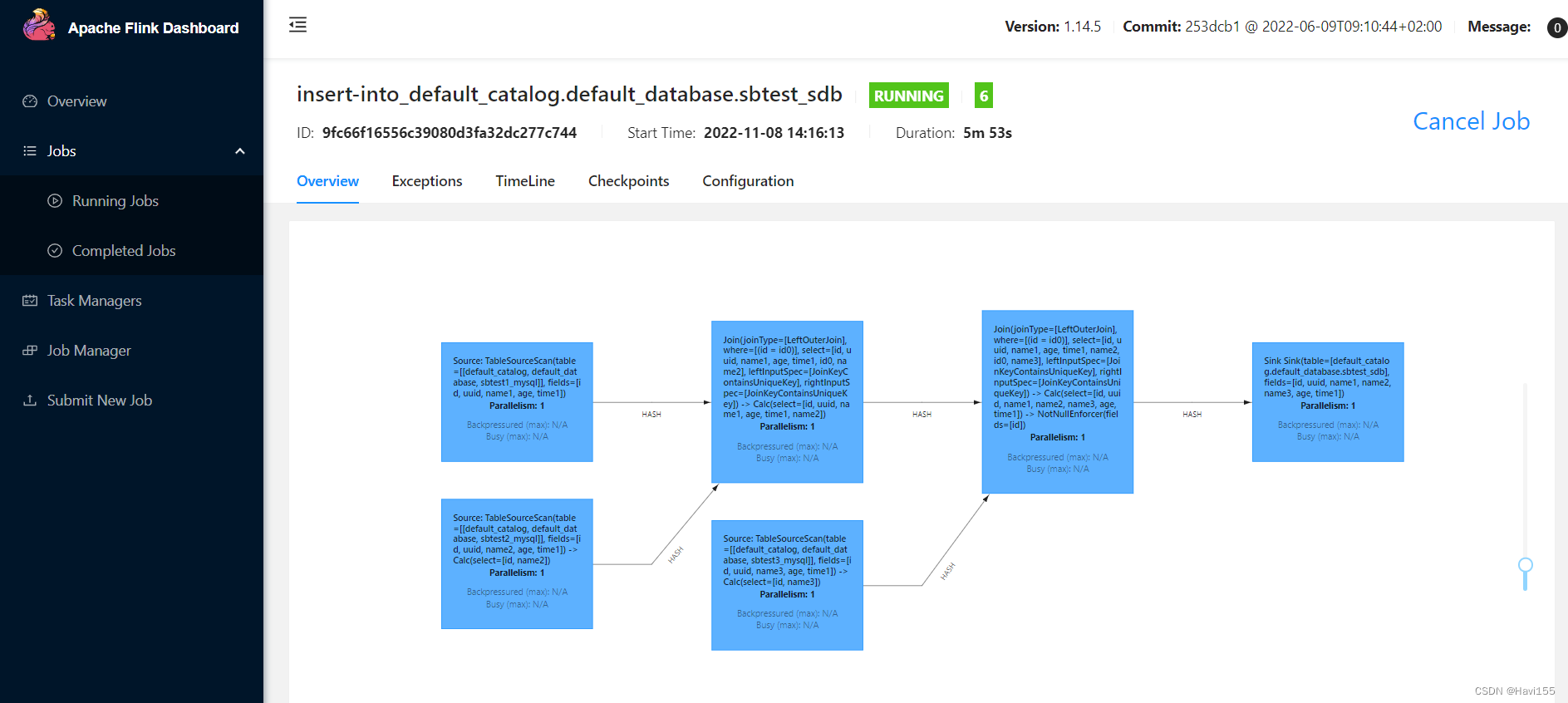
显示已经成功入库

相关文章:
Flink构造宽表实时入库案例介绍
1. 安装包准备 Flink 1.15.4 安装包 Flink cdc的mysql连接器 Flink sql的sdb连接器 MySQL驱动 SDB驱动 Flink jdbc的mysql连接器 2. 入库流程图 3. Flink安装部署 上传Flink压缩包到服务器,并解压 tar -zxvf flink-1.14.5-bin-scala_2.11.tgz -C /opt/ 复…...

【Kubernetes】K8s 查看 Pod 的状态
K8s 查看 Pod 的状态 [rootk8s-master1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-3 1/1 Running 2 (34m ago) 14hNAME:Pod 的名称。READY:代表 Pod 里面有几个容器,前面是启动的,后面…...
Linux系统操作命令
Linux管理 在线查询Linux命令: https://www.runoob.com/linux/linux-install.htmlhttps://www.linuxcool.com/https://man.linuxde.net/ 1.Linux系统目录结构 Linux系统的目录结构是一个树状结构,每一个文件或目录都从根目录开始,并且根目…...
大模型学习与实践笔记(五)
一、环境配置 1. huggingface 镜像下载 sentence-transformers 开源词向量模型 import os# 设置环境变量 os.environ[HF_ENDPOINT] https://hf-mirror.com# 下载模型 os.system(huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-…...

100个GEO基因表达芯片或转录组数据处理之GSE126848(003)
写在前边 虽然现在是高通量测序的时代,但是GEO、ArrayExpress等数据库储存并公开大量的基因表达芯片数据,还是会有大量的需求去处理芯片数据,并且建模或验证自己所研究基因的表达情况,芯片数据的处理也可能是大部分刚学生信的道友…...

1. Presto基础
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。文章目录 一、presto基础操作二、时间函数0、当前日期/当前时间1、转时间戳1)字符串转时间戳 (推荐)2)按照format指定的格式,将字符串str…...
ChatGPT可以帮你做什么?
学习 利用ChatGPT学习有很多,比如:语言学习、编程学习、论文学习拆解、推荐学习资源等,使用方法大同小异,这里以语言学习为例。 在开始前先给GPT充分的信息:(举例) 【角色】充当一名有丰富经验…...
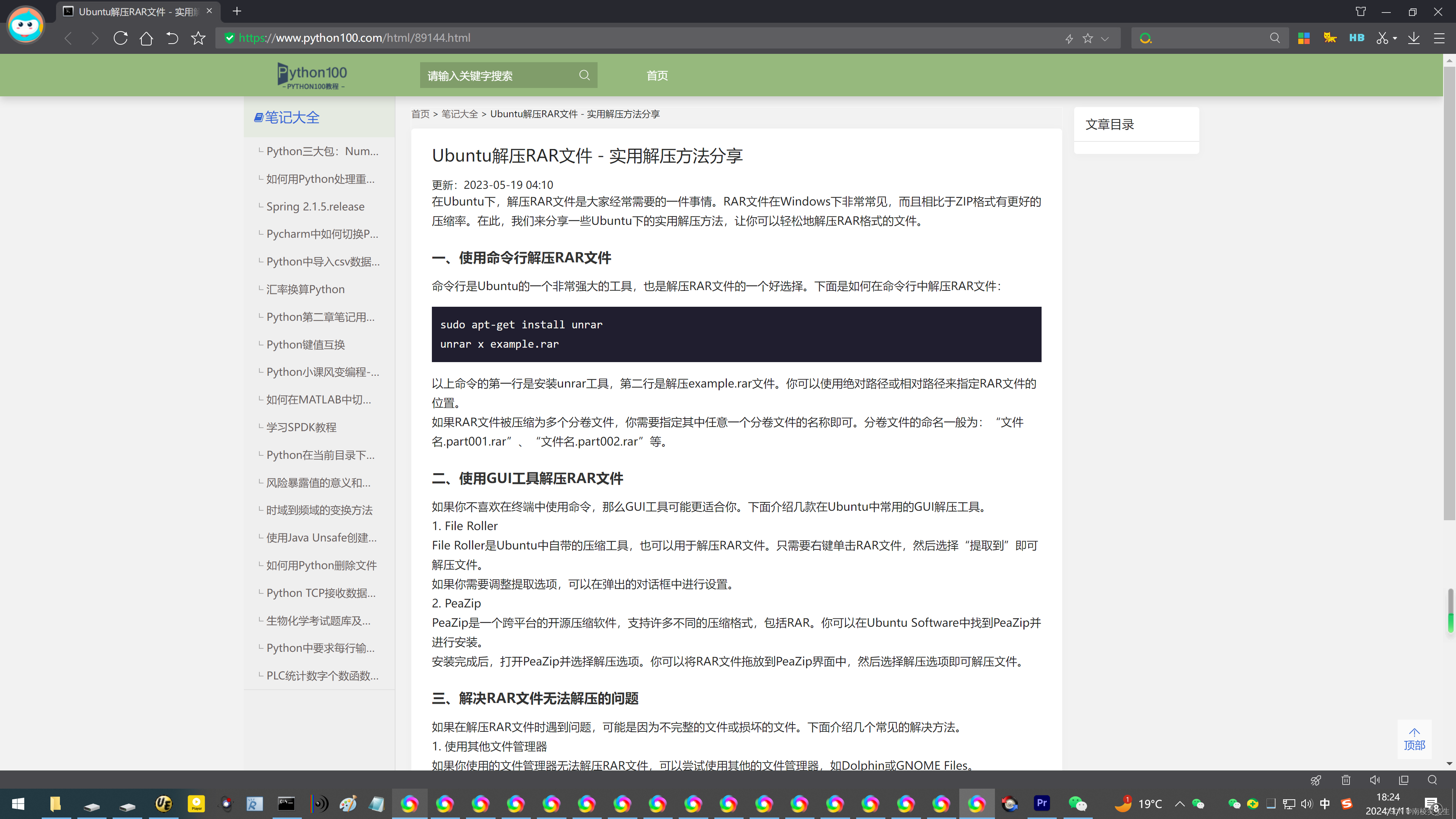
20240111在ubuntu20.04.6下解压缩RAR格式的压缩包
20240111在ubuntu20.04.6下解压缩RAR格式的压缩包 2024/1/11 18:25 百度搜搜:ubuntu rar文件怎么解压 rootrootrootroot-X99-Turbo:~/temp$ ll total 2916 drwx------ 3 rootroot rootroot 4096 1月 11 18:28 ./ drwxr-xr-x 25 rootroot rootroot 4096 1月…...
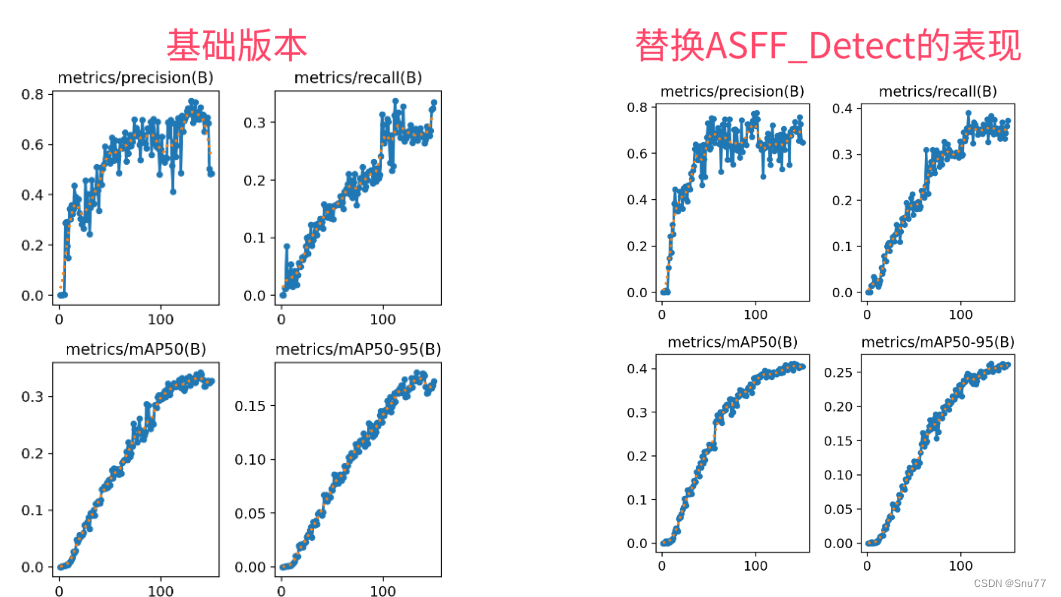
YOLOv5改进 | 检测头篇 | ASFFHead自适应空间特征融合检测头(全网首发)
一、本文介绍 本文给大家带来的改进机制是利用ASFF改进YOLOv5的检测头形成新的检测头Detect_ASFF,其主要创新是引入了一种自适应的空间特征融合方式,有效地过滤掉冲突信息,从而增强了尺度不变性。经过我的实验验证,修改后的检测头在所有的检测目标上均有大幅度的涨点效果,…...
)
第十三章 接口测试(笔记)
一、接口测试分类 内部接口:测试被测系统各个子模块之间的接口,或者被测系统提供给内部系统使用的接口 外部接口: 1.被测系统调用外部的接口 2.系统对外提供的接口 接口测试重点:检查接口参数传递的正确性,接口功能的正确性,输出结果的正确性,以及对各种异常情况的容错…...
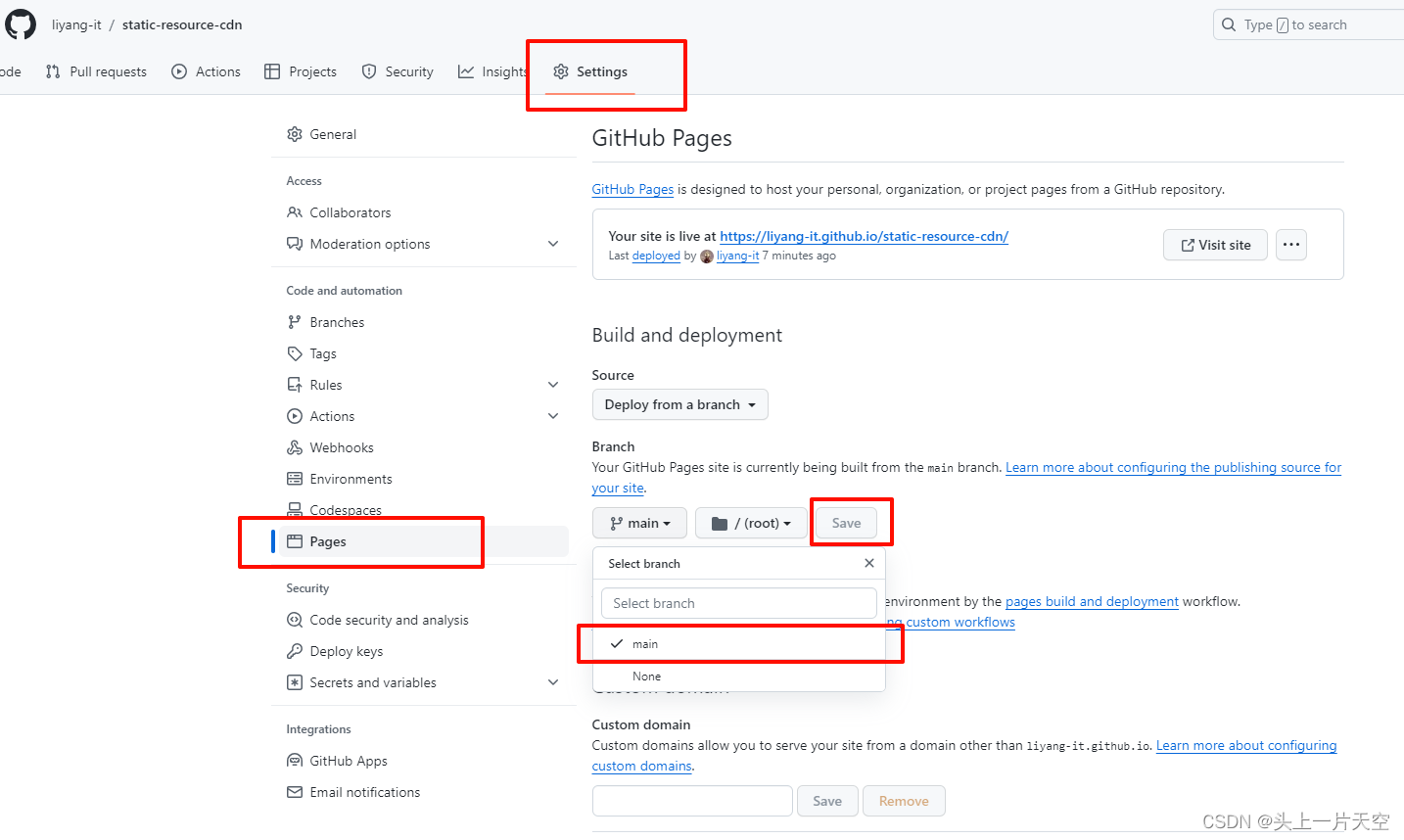
Github搭建图床 github搭建静态资源库 免费CDN加速 github搭建图床使用 jsdelivr CDN免费加速访问
Github搭建图床 github搭建静态资源库 免费CDN加速 github搭建图床使用 jsdelivr CDN免费加速访问 前言1、创建仓库2、开启 gh-pages页面功能3、访问测试 前言 写博客文章时,图片的上传和存放是一个问题,使用小众第三方图床,怕不稳定和倒闭&…...

Airtest-Selenium实操小课②:刷B站视频
1. 前言 上一课我们讲到用Airtest-Selenium爬取网站上我们需要的信息数据,还没看的同学可以戳这里看看~ 那么今天的推文,我们就来说说看,怎么实现看b站、刷b站的日常操作,包括点击暂停,发弹幕,点赞&#…...
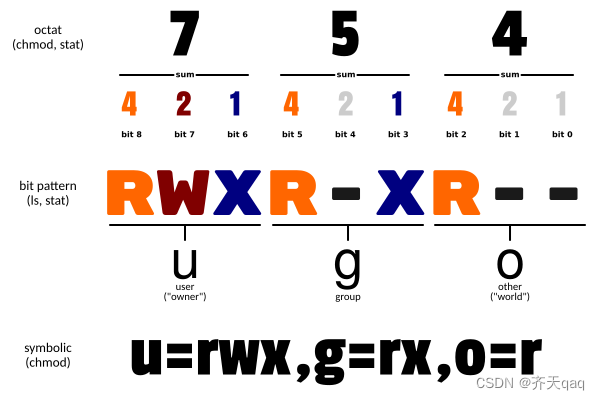
Linux chmod命令详解
Linux chmod(英文全拼:change mode)命令是控制用户对文件的权限的命令 Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)…...

求幸存数之和 - 华为OD统一考试
OD统一考试(C卷) 分值: 100分 题解: Java / Python / C++ 题目描述 给一个正整数列nums,一个跳数jump,及幸存数量left。运算过程为:从索引为0的位置开始向后跳,中间跳过 J 个数字,命中索引为 J+1 的数字,该数被敲出,并从该点起跳,以此类推,直到幸存left个数为止。…...
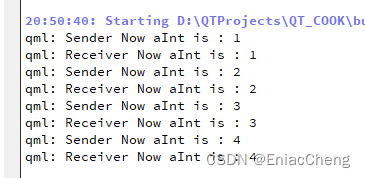
【QML COOK】- 008-自定义属性
前面介绍了用C定义QML类型,通常在使用Qt Quick开发项目时,C定义后端数据类型,前端则完全使用QML实现。而QML类型或Qt Quick中的类型时不免需要为对象增加一些属性,本篇就来介绍如何自定义属性。 1. 创建项目,并编辑Ma…...
前端页面优化做的工作
1.分析模块占用空间 new (require(webpack-bundle-analyzer).BundleAnalyzerPlugin)() 2.使用谷歌浏览器中的layers,看下有没有影响性能的模块,或者应该销毁没销毁的 3.由于我们页面中含有很大的序列帧动画,所以会导致页面性能低࿰…...
Spark六:Spark 底层执行原理SparkContext、DAG、TaskScheduler
Spark底层执行原理 学习Spark运行流程 学习链接:https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ 一、Spark运行流程 流程: SparkContext向管理器注册并向资源管理器申请运行Executor资源管理器分配Executor,然后资源管理器启动Execut…...

关于鸿蒙的笔记整理
提示:有使用过 vue 或 react 的小伙伴更容易理解 知识点强调: ArkTS所有内容都不支持深层数据更新 UI渲染 文章目录 一、关于样式1 . 默认单位 vp2 . 写公共样式 二 、 加载图片三 、 自定义构建函数 Builder四、构建函数-BuilderParam 传递UI五 、 父子…...
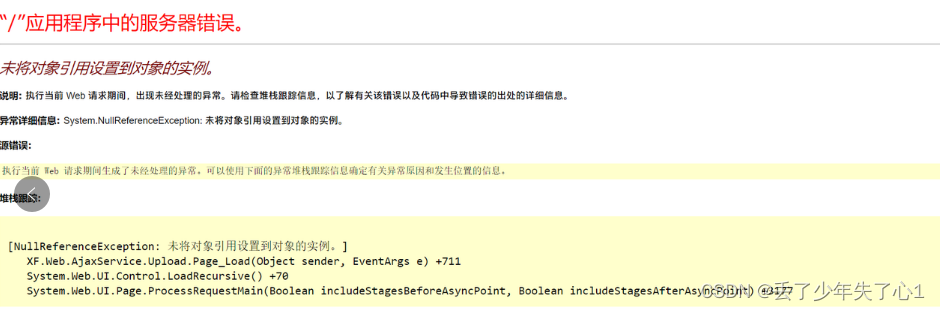
【漏洞复现】先锋WEB燃气收费系统文件上传漏洞 1day
漏洞描述 /AjaxService/Upload.aspx 存在任意文件上传漏洞 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和利益,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作…...
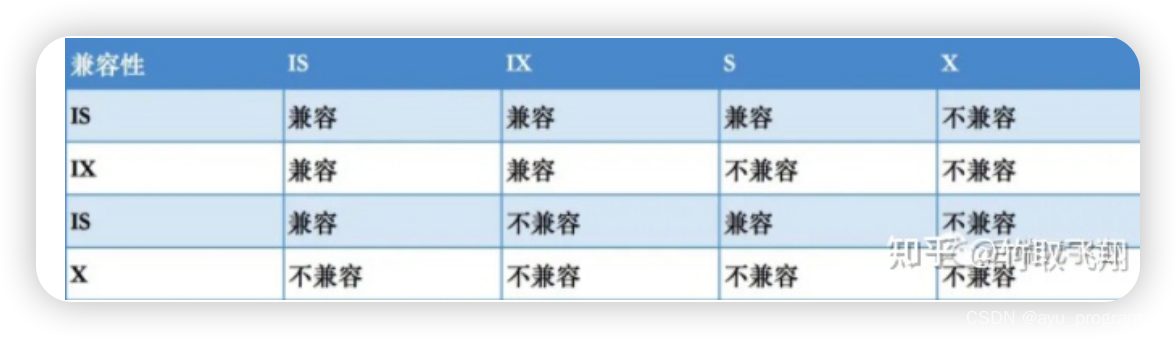
MYSQL篇--锁机制高频面试题
Mysql锁机制 1对mysql的锁有了解吗? 首先我们要知道,mysql的锁 其实是为了解决在并发事务时所导致的数据不一致问题的一种处理机制,也就是说 在事务的隔离级别实现中,就需要利用锁来解决幻读问题 然后我们可以聊到锁的分类 按锁…...

STM32CubeMX外设配置实战——以F103C8T6的CAN与DMA为例
1. STM32CubeMX与F103C8T6开发基础 STM32CubeMX是ST官方推出的图形化配置工具,它能极大简化STM32系列MCU的外设初始化流程。对于刚接触STM32开发的工程师来说,这个工具就像"乐高积木说明书"——通过可视化操作就能完成80%的底层配置工作。我最…...
:Agentic RAG——让 Agent 主导检索过程)
RAG 系列(十七):Agentic RAG——让 Agent 主导检索过程
Pipeline RAG 的沉默失败 前面十几篇一直在优化一件事:怎么让检索结果更好。更好的分块、更精准的排序、更聪明的问法、CRAG 纠偏、Graph RAG 关系遍历…… 但有一件事始终没变:无论检索结果好不好,都会被传给 LLM 生成答案。 Pipeline RAG 的流程是线性的、固定的: 问…...

NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导?
NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导? 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: ht…...

开源银行API模拟器Bankr Buddy:金融科技开发的本地化测试解决方案
1. 项目概述:一个为开发者准备的银行API模拟器如果你正在开发一个需要与银行账户数据打交道的应用,无论是个人财务管理工具、预算分析软件,还是企业级的财务聚合服务,你肯定遇到过同一个难题:如何在不触碰真实用户敏感…...

从零到一:基于GD32E230核心板的PCB设计实战与模块化解析
1. GD32E230核心板硬件设计基础 第一次拿到GD32E230这颗国产MCU时,说实话有点小激动。作为兆易创新基于Cortex-M23内核的拳头产品,它用55nm工艺把芯片面积压缩到了惊人的3x3mm,却集成了5个定时器、2个SPI、2个I2C这些实用外设。我在去年一个智…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...

Nextra:基于Next.js的现代化文档站构建利器
1. 项目概述:为什么Nextra能成为文档站构建的“瑞士军刀”?如果你最近在寻找一个构建技术文档、博客或个人知识库的工具,大概率会听到“Nextra”这个名字。它不是一个独立框架,而是一个基于Next.js的静态站点生成器,专…...

从零构建现代化工作流引擎:架构、实战与生产级部署指南
1. 项目概述:一个为专业开发者打造的现代化工作流引擎最近在GitHub上看到一个挺有意思的项目,叫rohitg00/pro-workflow。光看名字,你可能觉得这又是一个“工作流”工具,市面上这类工具已经多如牛毛了。但当我深入去研究它的源码、…...

AI智能体任务控制中心:构建可管理复杂项目的协作框架
1. 项目概述:为智能体装上“任务控制中心” 最近在折腾AI智能体(Agent)开发的朋友,可能都遇到过这样的场景:你精心设计了一个能联网搜索、处理文档、调用API的智能体,它单次任务的表现堪称完美。但当你试图…...