word2vec中的CBOW和Skip-gram
word2cev简单介绍
Word2Vec是一种用于学习词嵌入(word embeddings)的技术,旨在将单词映射到具有语义关联的连续向量空间。Word2Vec由Google的研究员Tomas Mikolov等人于2013年提出,它通过无监督学习从大规模文本语料库中学习词汇的分布式表示。目前Word2Vec有两种主要模型:Skip-gram和Continuous Bag of Words (CBOW)。前面已经讨论过它们的基本思想,简要总结如下:
1.Skip-gram: 从一个词预测其周围的上下文词,引入了独立假设,认为上下文的每个词都可以独立预测。
2.CBOW: 从上下文的词预测中心词,通过对上下文词的平均进行预测。
无论是Skip-gram还是CBOW,它们都使用神经网络进行训练,其中词向量是模型学习的参数。这些词向量在向量空间中被设计成使得语义相似的词在空间中距离较近。Word2Vec的训练通常涉及大量的文本数据,以便能够学到通用的词汇表示。Word2Vec模型在自然语言处理领域的应用广泛,包括词义相似度计算、文档相似度、命名实体识别等任务。得到的词嵌入可以被用作其他自然语言处理任务的输入特征,或者通过进一步微调可以适应特定任务的语境。
一.CBOW
CBOW(Continuous Bag of Words)是一种用于自然语言处理中的词嵌入模型,它的思想是从周围的上下文词语预测中心词。具体来说,CBOW的目标是根据上下文中的词语来预测当前位置的目标词语。
1.1CBOW的训练步骤
CBOW的训练过程包括以下步骤:
构建词嵌入表: 首先,为语料库中的每个词语构建一个词向量(词嵌入)。这些词向量可以随机初始化,然后在训练过程中不断调整。上下文窗口: 对于每个训练样本,模型会选择一个中心词,然后从该中心词的上下文中选择周围的2n个词语作为输入。这个上下文窗口的大小由超参数n决定。预测中心词: 使用选定的上下文词向量的平均值或拼接它们,作为输入,通过一个神经网络预测中心词。这个神经网络通常包含一个或多个隐藏层。损失函数: 使用损失函数(通常是交叉熵损失函数)来度量预测的中心词和实际中心词之间的差异。反向传播: 通过反向传播算法来调整词向量,使得损失函数最小化。这会更新词嵌入表中的每个词的向量表示。
1.2训练优化的策略
CBOW(Continuous Bag of Words)模型训练词向量时使用的优化策略通常是随机梯度下降(SGD)或其变体。以下是CBOW训练词向量时的一般优化策略:
梯度下降算法: CBOW通常使用随机梯度下降(SGD)或其变体来最小化损失函数。
SGD每次从训练数据中随机选择一个小批量样本,计算损失,并更新模型参数以减小损失。
这个过程不断迭代,直到达到预定的迭代次数或损失满足某个条件。学习率调度: 为了稳定和加速训练过程,可以使用学习率调度策略。
学习率是梯度下降中用于控制参数更新幅度的超参数。
学习率调度允许在训练过程中逐渐降低学习率,以便在接近最优解时更加细致地调整模型参数。负采样: 在CBOW的训练中,通常需要对负样本进行采样,以便更有效地训练模型。
负采样是指在计算损失时,不是对所有可能的词汇进行预测,而是从负样本中随机选择一小部分来计算损失。
这样可以减少计算复杂度,加速训练。批量训练: 与在线学习相对,批量训练使用整个训练数据集的子集进行参数更新。
批量训练可以带来更加稳定的收敛和更高的训练效率。参数初始化: 初始化词向量和神经网络参数对于训练的成功非常重要。
通常,可以使用小量的随机数来初始化参数,以确保在训练过程中网络能够学到有用的表示。层次化softmax: 在CBOW模型中,层次化softmax是一种用于优化训练过程的策略,特别是在大规模词汇量的情况下。
层次化softmax通过构建一个二叉树结构,将词汇表中的词语划分为不同的类别,从而降低了计算复杂度。
这种策略可以有效地加速训练过程,尤其在训练大规模语料库时表现得更为明显。
层次化softmax的主要思想是将词汇表中的词语组织成一棵二叉树,其中每个叶子节点表示一个词语。
通过在树上进行二进制编码,可以用较少的比特数来表示较常见的词汇,从而减少了计算的复杂度。
训练时,模型通过遵循从树根到叶子节点的路径,来预测目标词语。
以下是使用层次化softmax进行CBOW训练的步骤:
构建二叉树: 将词汇表中的词语组织成一个二叉树结构。频率较高的词语通常位于树的较底层,而频率较低的词语位于较高层。路径编码: 为了在树上表示每个词语,对每个内部节点和叶子节点分配一个二进制编码。通常,可以使用哈夫曼编码等方法。训练过程: 在CBOW的训练过程中,通过预测目标词语的路径,使用层次化softmax计算损失。这样可以避免对整个词汇表进行全面的计算,提高了训练的效率。
层次化softmax的主要优势在于,它可以在保持模型性能的同时,显著减少计算开销。
然而,它的构建和实现可能相对复杂,需要一些额外的工作来准备树结构和路径编码。
CBOW的优点之一是它相对较快地训练,因为它对上下文中的词语进行平均处理,减少了模型参数的数量。然而,它可能在处理稀有词汇或短语的能力上略逊于Skip-gram模型。
二.Skip-gram
Skip-gram是一种用于自然语言处理中的词嵌入模型,与CBOW(Continuous Bag of Words)相反,它的思想是从当前词预测上下文的词语。具体来说,Skip-gram的目标是在给定中心词的情况下预测其周围的上下文词语。
Skip-gram与CBOW之间的核心差异在于其独立假设性。在Skip-gram中,每个上下文词都被认为是独立的,模型的目标是独立地预测每个上下文词,而不是像CBOW那样对上下文词的平均进行预测。这使得Skip-gram更适合处理包含复杂语法和语义关系的语料库。
2.1训练步骤
Skip-gram的训练过程包括以下步骤:
构建词嵌入表: 与CBOW类似,首先为语料库中的每个词语构建一个词向量,这些词向量可以随机初始化。上下文窗口: 对于每个训练样本,模型会选择一个中心词,并从该中心词的上下文中选择周围的词语作为目标预测。预测上下文词: 使用选定的中心词的词向量,通过一个神经网络预测上下文词。这个神经网络通常包含一个或多个隐藏层。损失函数: 使用损失函数(通常是交叉熵损失函数)来度量预测的上下文词和实际上下文词之间的差异。反向传播: 通过反向传播算法来调整词向量,使得损失函数最小化。这会更新词嵌入表中的每个词的向量表示。
Skip-gram的优势之一是它在处理罕见词汇和捕捉词汇之间的复杂关系方面表现较好。然而,由于每个上下文词都被独立预测,训练过程可能会更慢,特别是在大规模语料库中。
2.2优势
1.处理罕见词汇: Skip-gram相对于CBOW在处理罕见词汇方面表现更好。这是因为Skip-gram的目标是从一个词语预测其上下文,因此对于罕见词汇,通过训练模型学到的词向量可能更具有泛化性,能够更好地捕捉它们的语义信息。
2.捕捉复杂关系: Skip-gram的独立假设性使其更能够捕捉词汇之间的复杂关系。每个上下文词都被独立预测,这允许模型在学习过程中更灵活地调整每个词的向量表示,从而更好地捕捉词汇的细粒度语义信息。
2.3挑战
训练速度慢: 由于每个上下文词都被独立预测,Skip-gram的训练过程相对较慢,尤其是在大规模语料库中。这是因为对于每个训练样本,需要更新多个参数,导致计算复杂度较高。
存储需求高: 由于Skip-gram需要学习每个词语的词向量,对于大规模的词汇表,存储这些词向量可能需要大量的内存。这可能成为在资源受限环境中应用Skip-gram时的一个挑战。
参数数量多: Skip-gram的模型参数数量与词汇表的大小相关。当词汇表很大时,模型的参数数量也会增加,可能导致模型的训练和存储变得更为复杂。
总体而言,Skip-gram模型在某些任务和语境下表现得很好,但在实际应用中需要权衡其优势和挑战。在资源受限或对训练时间要求较高的情况下,研究人员可能会选择其他词嵌入模型或采用一些技术来加速训练过程。
word2vec中的CBOW和Skip-gram和传统语言模型的优化目标采用了相同的方式,但是最终的目标不同。语言模型的最终目标是为了通过一个参数化模型条件概率以便更好的预测下一个词,但是词向量是通过条件概率获得词向量矩阵。
相关文章:

word2vec中的CBOW和Skip-gram
word2cev简单介绍 Word2Vec是一种用于学习词嵌入(word embeddings)的技术,旨在将单词映射到具有语义关联的连续向量空间。Word2Vec由Google的研究员Tomas Mikolov等人于2013年提出,它通过无监督学习从大规模文本语料库中学习词汇…...

在ios上z-index不起作用问题的总结
最近在维护一个H5老项目时,遇到一个问题,就是在ios上z-index不起作用,在安卓上样式都是好的。 项目的架构组成是vue2.x vux vuex vue-router等 用的UI组件库是vux 在页面中有一个功能点,就是点选择公司列表的时候,会…...

力扣labuladong一刷day59天动态规划
力扣labuladong一刷day59天动态规划 文章目录 力扣labuladong一刷day59天动态规划一、509. 斐波那契数二、322. 零钱兑换 一、509. 斐波那契数 题目链接:https://leetcode.cn/problems/fibonacci-number/description/ 思路:这是非常典型的一道题&#x…...

pyenv环境找不到sqlite:No module named _sqlite3
前言 一般遇到这个问题都在python版本管理或者虚拟环境切换中遇到,主要有两个办法解决,如下: 解决方法1 如果使用的pyenv管理python环境时遇到没有_sqlite3 库,可以将当前pyenv的python环境卸载 pyenv uninstall xxx然后在系统…...

Histone H3K4me2 Antibody, SNAP-Certified™ for CUTRUN
EpiCypher是一家为表观遗传学和染色质生物学研究提供高质量试剂和工具的专业制造商。EpiCypher推出的CUT&RUN级别的Histone H3K4me2 Antibody符合EpiCypher的批次特异性SNAP-CertifiedTM标准,在CUT&RUN中具有特异性和高效的靶点富集。通过SNAP-CUTANA™K-Me…...
我用 Laf 开发了一个非常好用的密码管理工具
【KeePass 密码管理】是一款简单、安全简洁的账号密码管理工具,服务端使用 Laf 云开发,支持指纹验证、FaceID,N 重安全保障,可以随时随地记录我的账号和密码。 写这个小程序之前,在国内市场找了很多密码存储类的 App …...

windows项目部署
文章目录 一、项目部署1.1 先准备好文件1.2安装jdk1.3 配置环境1.4 安装tomcat1.5 MySQL安装本机测试的话:远程连接测试 1.6 项目部署 一、项目部署 1.1 先准备好文件 1.2安装jdk 下一步 下一步 下一步 1.3 配置环境 变量名:JAVA_HOME 变量值:jdk的…...

http首部
1. htttp 报文首部 报文结构为:首部 空行(CRLF)主体 在请求中 http报文首部由请求方法,URI,http版本,首部字段等构成 在响应中:状态码,http版本,首部字段3部分构成 2…...

2024.1.8 Day04_SparkCore_homeWork
目录 1. 简述Spark持久化中缓存和checkpoint检查点的区别 2 . 如何使用缓存和检查点? 3 . 代码题 浏览器Nginx案例 先进行数据清洗,做后续需求用 1、需求一:点击最多的前10个网站域名 2、需求二:用户最喜欢点击的页面排序TOP10 3、需求三&#x…...
09.简单工厂模式与工厂方法模式
道生一,一生二,二生三,三生万物。——《道德经》 最近小米新车亮相的消息可以说引起了不小的轰动,我们在感慨SU7充满土豪气息的保时捷设计的同时,也深深的被本土品牌的野心和干劲所鼓舞。 今天我们就接着这个背景&…...
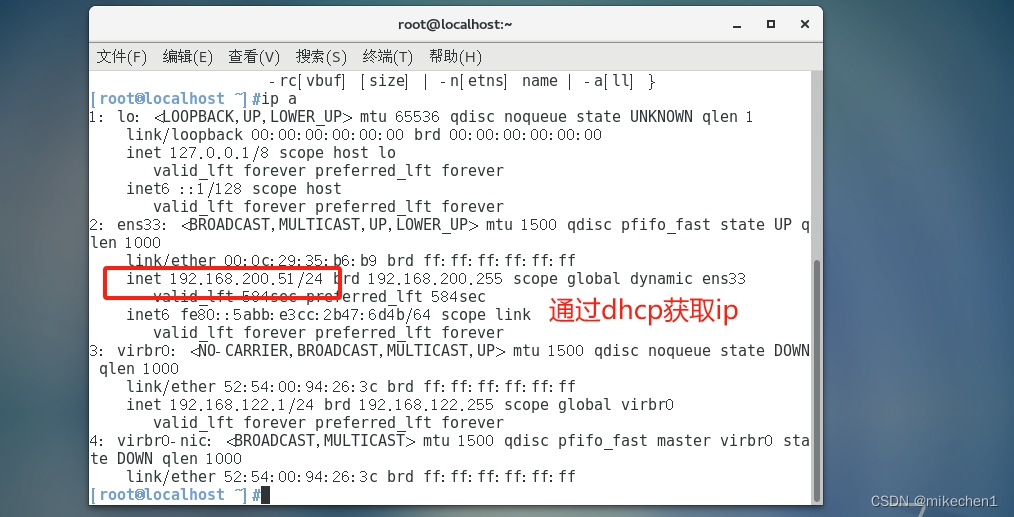
DHCP,怎么在Linux和Windows中获得ip
一、DHCP 1.1 什么是dhcp DHCP动态主机配置协议,通常被应用在大型的局域网络环境中,主要作用是集中地管理、分配IP地址,使网络环境中的主机动态的获得IP地址、DNS服务器地址等信息,并能够提升地址的使用率。 DHCP作为用应用层协…...
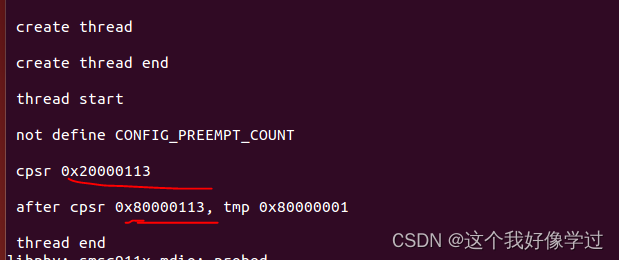
读写锁(arm)
参考文章读写锁 - ARM汇编同步机制实例(四)_汇编 prefetchw-CSDN博客 读写锁允许多个执行流并发访问临界区。但是写访问是独占的。适用于读多写少的场景 另外好像有些还区分了读优先和写优先 读写锁定义 typedef struct {arch_rwlock_t raw_lock; #if…...

【第33例】IPD体系进阶:市场细分
目录 内容简介 市场细分原因 市场细分主要活动 市场细分流程 作者简介 内容简介 这节内容主要来谈谈 IPD 市场管理篇的市场细分步骤。 其中,市场管理(Market Management)是一套系统的方法。 用于对广泛的机会进行选择性收缩,...

response 拦截器返回的二进制文档(同步下载excel)如何配置
response 拦截器返回的二进制文档(同步下载excel)如何配置 一、返回效果图二、response如何配置 一、返回效果图 二、response如何配置 service.interceptors.response.use(response > {// 导出excel接口if (response.config.isExport) {return resp…...
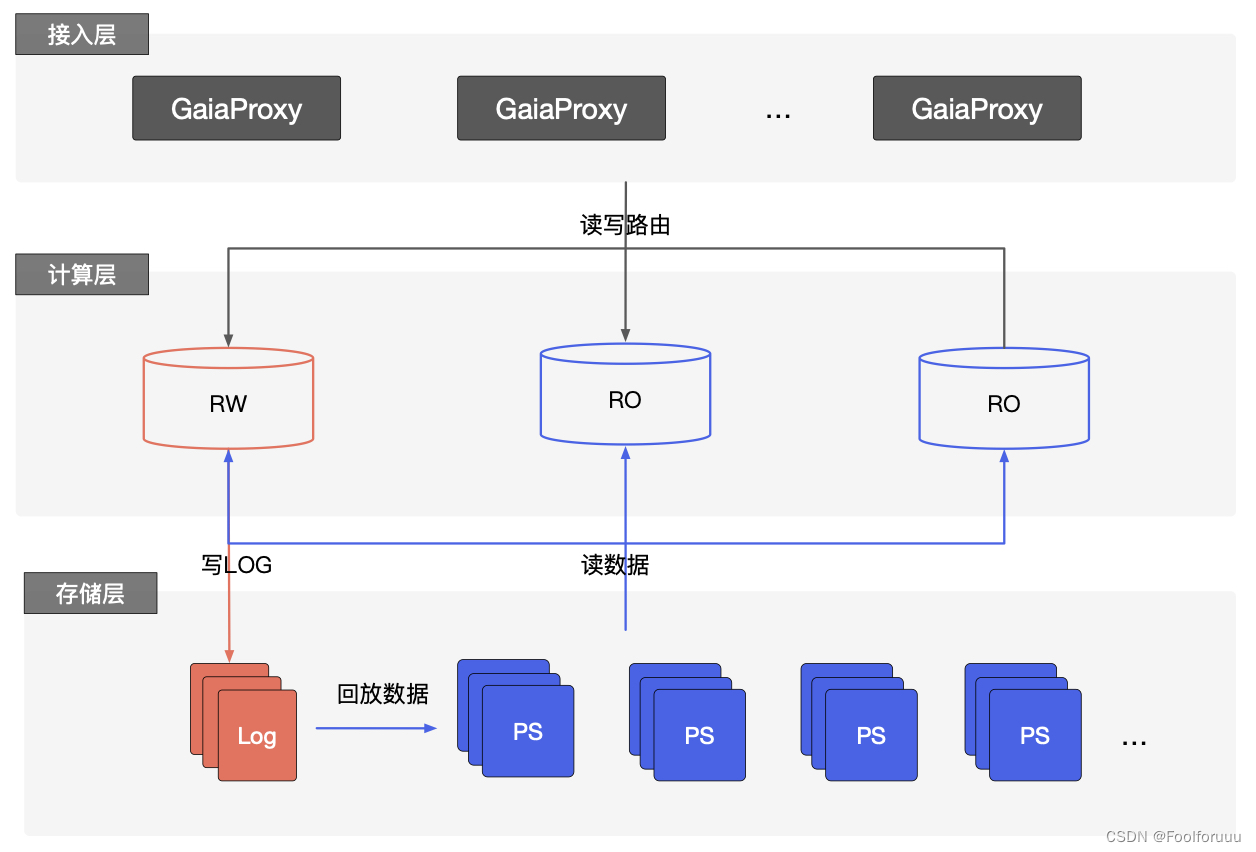
为什么要使用云原生数据库?云原生数据库具体有哪些功能?
相比于托管型关系型数据库,云原生数据库极大地提高了MySQL数据库的上限能力,是云数据库划代的产品;云原生数据库最早的产品是AWS的 Aurora。AWS Aurora提出来的 The log is the database的理念,实现存储计算分离,把大量…...

05- OpenCV:图像操作和图像混合
目录 一、图像操作 1、读写图像 2、读写像素 3、修改像素值 4、Vec3b与Vec3F 5、相关的代码演示 二、图像混合 1、理论-线性混合操作 2、相关API(addWeighted) 3、代码演示(完整的例子) 一、图像操作 1、读写图像 (1)…...

人脸识别(Java实现的)
虹软人脸识别: 虹软人脸识别的地址:虹软视觉开放平台—以免费人脸识别技术为核心的人脸识别算法开放平台 依赖包: 依赖包是从虹软开发平台下载的 在项目中引入这个依赖包 pom.xml <!-- 人脸识别 --><dependency><gr…...

Maven 依赖管理项目构建工具 教程
Maven依赖管理项目构建工具 此文档为 尚硅谷 B站maven视频学习文档,由官方文档搬运而来,仅用来当作学习笔记用途,侵删。 另:原maven教程短而精,值得推荐,下附教程链接。 atguigu 23年Maven教程 目录 文章目…...
供应链+低代码,实现数字化【共赢链】转型新策略
在深入探讨之前,让我们首先明确供应链的基本定义。供应链可以被理解为一个由采购、生产、物流配送等环节组成的网状系统,它始于原材料的采购,经过生产加工,最终通过分销和零售环节到达消费者手中。 而数字化供应链,则是…...

[力扣 Hot100]Day3 最长连续序列
题目描述 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 出处 思路 此题可用带排序的哈希表,先构建哈希表࿰…...

解锁端侧智能:基于BigDL-LLM与Qwen-1.8B-Chat的CPU高效推理实践
1. 为什么要在CPU上部署大模型? 最近两年大模型技术发展迅猛,但大多数应用都依赖昂贵的GPU服务器。我在实际项目中发现,很多中小企业和个人开发者其实更需要能在普通电脑上运行的轻量化方案。这就是为什么基于CPU的大模型部署方案变得越来越…...

深度集成AI的VSCode扩展:从代码生成到调试的全流程实战指南
1. 项目概述:一个为VSCode注入AI灵魂的扩展如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(VSCode)里度过的,那么你一定对提升编码效率有着近乎偏执的追求。从代码补全、语法高亮到调试、版本控制&#…...
在Windows下的详细评测与实战技巧)
Kafka运维新选择:Offset Explorer(Kafka Tool)在Windows下的详细评测与实战技巧
Kafka运维新选择:Offset Explorer在Windows下的深度评测与高阶实战 当Kafka集群规模从几个节点扩展到数十甚至上百个Broker时,命令行工具kafka-topics.sh和kafka-console-consumer.sh开始显得力不从心。这时,一个得力的可视化工具就像黑暗中的…...

ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析
ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款运行在Windows内核模式的驱…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...

Nixtla时间序列预测库实战:从统计模型到深度学习的一站式解决方案
1. 项目概述:时间序列预测的“瑞士军刀”如果你正在处理销售预测、服务器负载监控或者任何与时间相关的数据预测问题,并且厌倦了在复杂的模型库和繁琐的预处理步骤之间反复横跳,那么 Nixtla 这个开源项目很可能就是你一直在找的“瑞士军刀”。…...

82.人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案
人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案 一、问题场景:测试环境改了 Prompt,结果生产回答变了 很多大模型项目早期只有一个环境: 一套 Prompt 一个知识库 一个模型地址 一个配置表开发、测试、运营都在同一套配置…...

基于RAG与智能体技术构建专业客服AI:从知识注入到流程执行
1. 项目概述:一个面向客服场景的AI智能体指南最近在GitHub上看到一个挺有意思的项目,叫mrqhocungdungai-vn/hermes-cskh-guide。从名字就能猜个大概,这是一个关于“Hermes”的客服(CSKH)指南,而且看起来是越…...

安卓客户端架构解析:从MVVM到网络通信的完整实践
1. 项目概述:一个面向安卓设备的智能客户端最近在整理手头的开源项目时,发现了一个挺有意思的仓库,名字叫TOM88812/xiaozhi-android-client。光看这个标题,你可能会有点摸不着头脑,这“小智”到底是个啥?是…...

FinalBurn Neo:终极开源街机模拟器技术深度解析
FinalBurn Neo:终极开源街机模拟器技术深度解析 【免费下载链接】FBNeo FinalBurn Neo - We are Team FBNeo. 项目地址: https://gitcode.com/gh_mirrors/fb/FBNeo FinalBurn Neo(简称FBNeo)是一款专业级的开源街机模拟器,…...