Mysql——索引相关的数据结构
索引
引入
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
简介
目前大部分数据库系统及文件系统都采用B-Tree(B树)或其变种B+Tree(B+树)作为索引结构。B+Tree是数据库系统实现索引的首选数据结构。在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
索引数据结构
了解索引就需要从索引常见的数据结构开始了解学习,这是几种常见的的索引数据结构
二叉树
二叉树是每个节点最多只有两个分支(即不存在分支度大于2的节点)的树结构。通常被称之为“左子树”和“右子树”
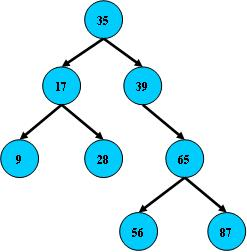
二叉树示例图
左子树<父节点<=右子树
二叉树的第i层至多有有2^(i-1)个节点,
深度为K的二叉树至多总共有个2^k-1节点(定义根节点所在深度 k0=0),而总计拥有节点数符合的,称为“满二叉树”;
二叉树通常作为数据结构应用,典型用法是对节点定义一个标记函数,将一些值与每个节点相关系。这样标记的二叉树就可以实现二叉搜索树和二叉堆,并应用于高效率的搜索和排序。
同时学习数据结构,这里还推荐Data Structure Visualizations进行学习,可以非常直观的看到数据结构允许的过程,一步一步的怎么走的都可以很清晰看得到。
找到其中的Binary Search Trees二叉树
可以看到二叉树不适合用作当作索引的,数据量庞大的话,或者按顺序插入 ,二叉树的层数会很大,查找效率固然也很慢了
红黑树(Red-Black Trees)
是一种自平衡二叉查找树,典型用途是实现关联数组。
红黑树的结构复杂,但它的操作有着良好的最坏情况运行时间,并且在实践中高效:它可以在O(log n)时间内完成查找,插入和删除,这里的n是树中元素的数目。
红黑树遵行以下原则:
节点是红色或黑色。
根是黑色。
所有叶子都是黑色(叶子是NIL节点)。
每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
下面是一个具体的红黑树的图例:
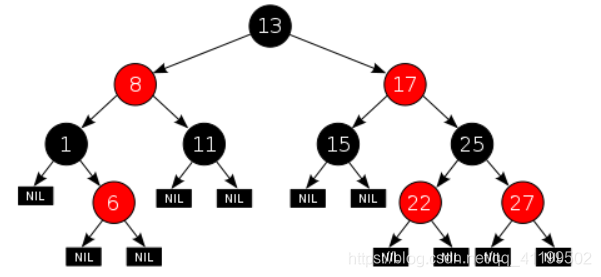 这些约束确保了红黑树的关键特性:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
这些约束确保了红黑树的关键特性:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
要知道为什么这些性质确保了这个结果,注意到性质4导致了路径不能有两个毗连的红色节点就足够了。最短的可能路径都是黑色节点,最长的可能路径有交替的红色和黑色节点。因为根据性质5所有最长的路径都有相同数目的黑色节点,这就表明了没有路径能多于任何其他路径的两倍长。
同样红黑树也不适用于MySQL的索引,数据量庞大之后,数层也会变大。
推荐阅读:
小灰红黑树
其他数据结构
由于无法装入内存,则必然依赖磁盘(或SSD)存储。而内存的读写速度是磁盘的成千上万倍(与具体实现有关),因此,核心问题是“如何减少磁盘读写次数”。
首先不考虑页表机制,假设每次读、写都直接穿透到磁盘,那么:
- 线性结构:读/写平均O(n)次
- 二叉搜索树(BST):读/写平均O(log2(n))次;如果树不平衡,则最差读/写O(n)次
- 自平衡二叉搜索树(AVL):在BST的基础上加入了自平衡算法,读/写最大O(log2(n))次
- 红黑树(RBT):另一种自平衡的查找树,读/写最大O(log2(n))次
BST、AVL、RBT很好的将读写次数从O(n)优化到O(log2(n));其中,AVL和RBT都比BST多了自平衡的功能,将读写次数降到最大O(log2(n))。
假设使用自增主键,则主键本身是有序的,树结构的读写次数能够优化到树高,树高越低读写次数越少;自平衡保证了树结构的稳定。如果想进一步优化,可以引入B树和B+树。
B树(B-Trees)
又称:多路平衡查找树。大多数存储引擎都支持B树索引。b树通常意味着所有的值都是按顺序存储的,并且每一个叶子节点到根的距离相同。B树索引能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取数据。下图就是一颗简单的B树。
在B树中,内部(非叶子)节点可以拥有可变数量的子节点(数量范围预先定义好)。当数据被插入或从一个节点中移除,它的子节点数量发生变化。为了维持在预先设定的数量范围内,内部节点可能会被合并或者分离。
如下图所示:
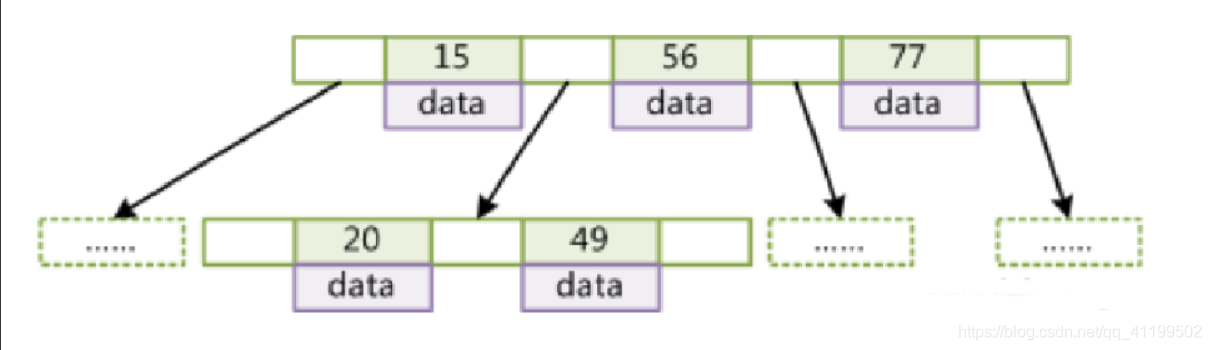
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
- 无论中间节点还是叶子节点都带有卫星数据data(索引元素所指向的数据记录
只演示了插入的过程,其中可以通过delete、find执行删除和查找操作。直观的感受到B树的执行过程。
每个节点存储了多个Key和子树,子树与Key按顺序排列。
同二叉搜索树类似,每个节点存储了多个key和子树,子树与key按顺序排列。页表的目录是扩展外存+加速磁盘读写,一个页(Page)通常4K(等于磁盘数据块block的大小,见inode与block的分析),操作系统每次以页为单位将内容从磁盘加载到内存(以摊分寻道成本),修改页后,再择期将该页写回磁盘。考虑到页表的良好性质,可以使每个节点的大小约等于一个页(使m非常大),这每次加载的一个页就能完整覆盖一个节点,以便选择下一层子树;对子树同理。对于页表来说,AVL(或RBT)相当于1个key+2个子树的B树,由于逻辑上相邻的节点,物理上通常不相邻,因此,读入一个4k页,页面内绝大部分空间都将是无效数据。
假设key、子树节点指针均占用4B,则B树节点最大m * (4 + 4) = 8m B;页面大小4KB。则m = 4 * 1024 / 8m = 512,一个512叉的B树,1000w的数据,深度最大 log(512/2)(10^7) = 3.02 ~= 4。对比二叉树如AVL的深度为log(2)(10^7) = 23.25 ~= 24,相差了5倍以上。震惊!B树索引深度竟然如此!
那为什么B数这么厉害了,还有B+树的出现呢,必然是解决B树存在的问题
1、为定位行数
2、无法处理范围查询
问题1:为定位行数
数据表的记录有多个字段,仅仅定位到主键是不够的,还需要定位到数据行。有3个方案解决:
直接将key对应的数据行(可能对应多行)存储子节点中。
数据行单独存储;节点中增加一个字段,定位key对应数据行的位置。
修改key与子树的判断逻辑,使子树大于等于上一key小于下一key,最终所有访问都将落于叶子节点;叶子节点中直接存储数据行或数据行的位置。
方案1直接pass,存储数据行将减少页面中的子树个数,m减小树高增大。
方案2的节点中增加了一个字段,假设是4B的指针,则新的m = 4 * 1024 / 12m = 341.33 ~= 341,深度最大 log(341/2)(10^7) = 3.14 ~= 4。
方案3的节点m与深度不变,但时间复杂度变为稳定的O(logm(n))。
方案3可以考虑。
问题2:无法处理范围查询
实际业务中,范围查询的频率非常高,B树只能定位到一个索引位置(可能对应多行),很难处理范围查询。改动较小的是2个方案:
不改动;查询的时候先查到左界,再查到右界,然后DFS(或BFS)遍历左界、右界之间的节点。
在“问题1-方案3”的基础上,由于所有数据行都存储在叶子节点,B树的叶子节点本身也是有序的,可以增加一个指针,指向当前叶子节点按主键顺序的下一叶子节点;查询时先查到左界,再查到右界,然后从左界到有界线性遍历。
乍一看感觉方案1比方案2好——时间复杂度和常数项都一样,方案1还不需要改动。但是别忘了局部性原理,不管节点中存储的是数据行还是数据行位置,方案2的好处在于,依然可以利用页表和缓存预读下一节点的信息。而方案1则面临节点逻辑相邻、物理分离的缺点。
推荐阅读
小灰B+树
B+树
主要变动如上所述:
修改key与子树的组织逻辑,将索引访问都落到叶子节点
按顺序将叶子节点串起来(方便范围查询)
回顾上一个B树,一个m阶的B树具有如下几个特征:
1.根结点至少有两个子女。
2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
一个m阶的B+树具有如下几个特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
B+树特性总结
B+树是B树的升级版,其有如下特性
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
叶子节点包含所有索引字段
叶子节点用指针连接,提高区间访问的性能
只有叶子节点带有卫星数据data(索引元素所指向的数据记录)
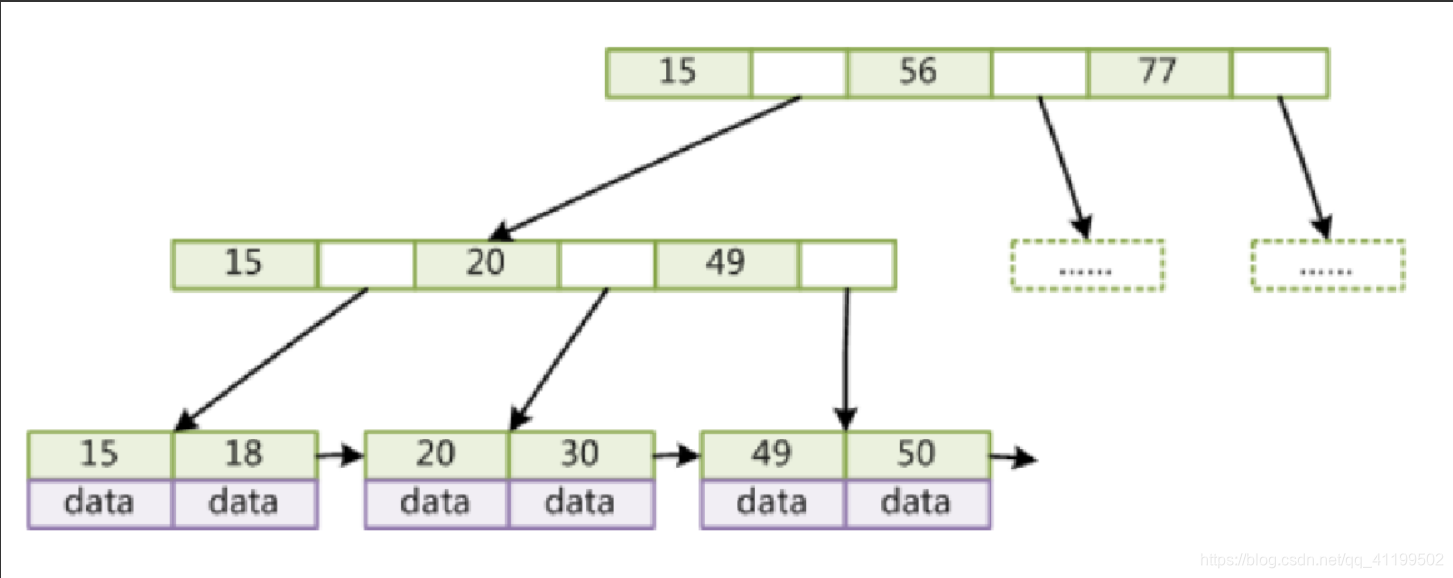 在动图中可以看出,B+树的每一个叶子节点都有一个指针指向下一个节点,把所有的叶子节点串在一起。索引数据都存储在叶子节点中。
在动图中可以看出,B+树的每一个叶子节点都有一个指针指向下一个节点,把所有的叶子节点串在一起。索引数据都存储在叶子节点中。
B+树相比于B树,有什么优势呢:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
总结,B+树相比B树的优势有三:1.IO次数更少;2.查询性能稳定;3.范围查询简便。
推荐阅读:
程序员小灰-B+树
Hash索引
hash索引基于hash表实现,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中。只有精准匹配索引所有列的查询才有效。索引的检索可以一次定位,不像B-Tree索引需要从根节点出发到目标节点。虽然Hash索引很快,远高于B-tree索引,但是也有其弊端。
Hash索引仅仅能满足'=','IN','<=>'查询,也就是等值查询,不能使用范围查询。很受限由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
由于Hash索引是通过hash表实现,其本身是没有排序的。由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
Hash索引不能利用部分索引键查询对于组合索引,Hash索引在计算hash值的时候是组合索引键合并后再一起计算hash值,而不是单独计算hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
Hash 索引在任何时候都不能避免表扫描前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
MyISAM索引实现MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址
相关文章:
Mysql——索引相关的数据结构
索引 引入 我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为…...

无代码DIY图像检索
软件环境准备 可参见《HuggingFists-低代码玩转LLM RAG-准备篇》中的HuggingFists安装及Milvus安装。 流程环境准备 图片准备 进入HuggingFists内置的文件系统,数据源->文件系统->sengee_fs_settings_201创建Image文件夹将事先准备的多张相同或不同种类的图…...
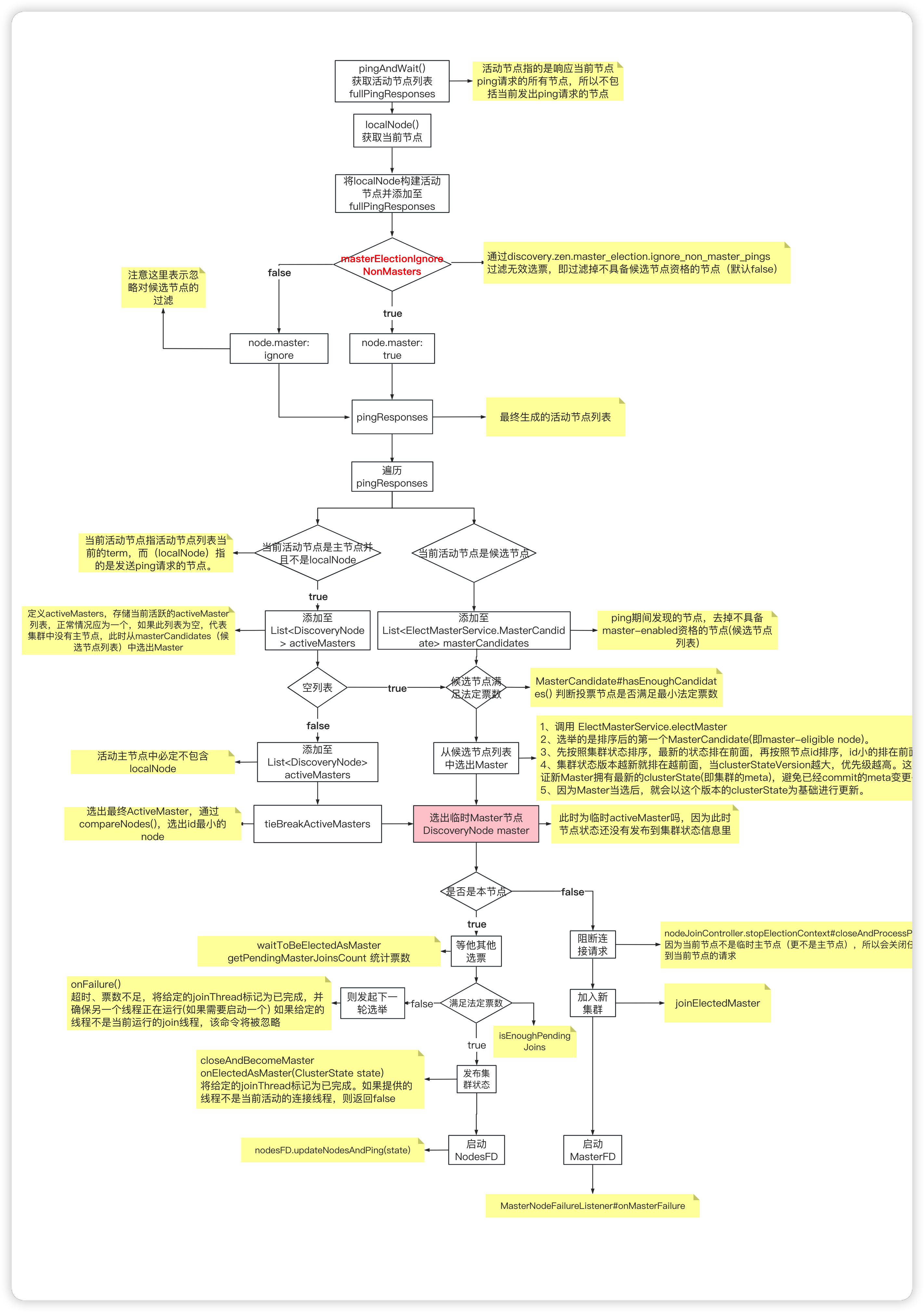
Elasticsearch--Master选举
角色 主节点(active master):一般指的是活跃的主节点,避免负载任务,主节点主要用来管理集群,专用master节点仍将充当协调节点 候选节点(master-eligible nodes):默认具备…...

微服务实战系列之Filter
前言 Filter,又名过滤器,当然不是我们日常中见到的,诸如此类构件: 而应该是微服务中常使用的,诸如此类(图片来自官网,点击可查看原图): 一般用于字符编码转换…...

使用GPT大模型调用工具链
本文特指openai使用sdk的方式调用工具链。 安装openai pip install openai export OPENAI_API_KEY"YOUR OPENAI KEY" 定义工具函数 from openai import OpenAI import jsonclient OpenAI() #工具函数 def get_current_weather(location, unit"fahrenheit&q…...

C语言实现bmp图像底层数据写入与创建
要用C语言实现bmp图像底层数据写入进而创建一张bmp图像,需要对bmp图像文件格式非常了解,如果不太熟悉bmp图像文件格式请先移步bmp图像文件格式超详解 创建bmp图像文件的方式有很多,比如用halcon,用qt,这些都是把已经画…...

基于BP神经网络的定位算法,基于BP神经网络定位预测
目录 摘要 BP神经网络参数设置及各种函数选择 参数设置 训练函数 传递函数 学习函数 性能函数 显示函数 前向网络创建函数 BP神经网络训练窗口详解 训练窗口例样 训练窗口四部详解 基于BP神经网络的定位算法,基于BP神经网络定位预测 代码下载:基于BP神经网络的定位算法,基于…...

Java Http各个请求类型详细介绍
1. 前言 在Spring Boot框架中,HTTP请求类型是构建Web应用程序的重要组成部分。常见的请求类型包括GET、POST、PUT和DELETE,每种类型都有其特定的用途和特点。本文将详细比较这四种请求类型,帮助您在开发过程中做出明智的选择。 2. GET请求…...

python函数装饰器参数统计调用时间和次数
1 python函数装饰器参数统计调用时间和次数 python在函数装饰器外层定义一个函数生成封闭作用域来保存装饰器入参,供装饰器使用。 1.1 装饰器统计调用时间和次数 描述 通过类的可调用实例装饰器来统计函数每次调用时间和总调用时间,以及调用次数。 …...

机器学习之集成学习AdaBoost
概念 AdaBoost(Adaptive Boosting)是一种迭代的集成学习算法,其主要目标是通过组合多个弱学习器来创建一个强大的模型。以下是AdaBoost算法的主要步骤: 初始化样本权重: 为每个训练样本分配相等的权重,通常设为 w i = 1 N w_i = \frac{1}{N} w...
行云部署成长之路 -- 慢 SQL 优化之旅 | 京东云技术团队
当项目的SQL查询慢得像蜗牛爬行时,用户的耐心也在一点点被消耗,作为研发,我们可不想看到这样的事。这篇文章将结合行云部署项目的实践经验,带你走进SQL优化的奇妙世界,一起探索如何让那些龟速的查询飞起来!…...
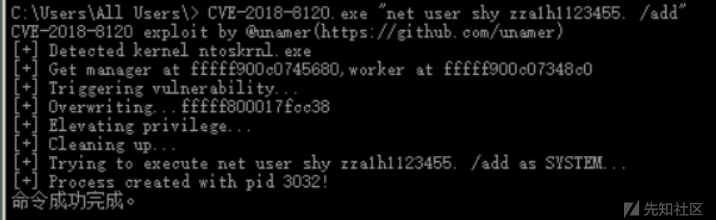
Windows权限提升
0x01 简介 提权可分为纵向提权与横向提权: 纵向提权:低权限角色获得高权限角色的权限; 横向提权:获取同级别角色的权限。 Windows常用的提权方法有:系统内核溢出漏洞提权、数据库提权、错误的系统配置提权、组策略首…...
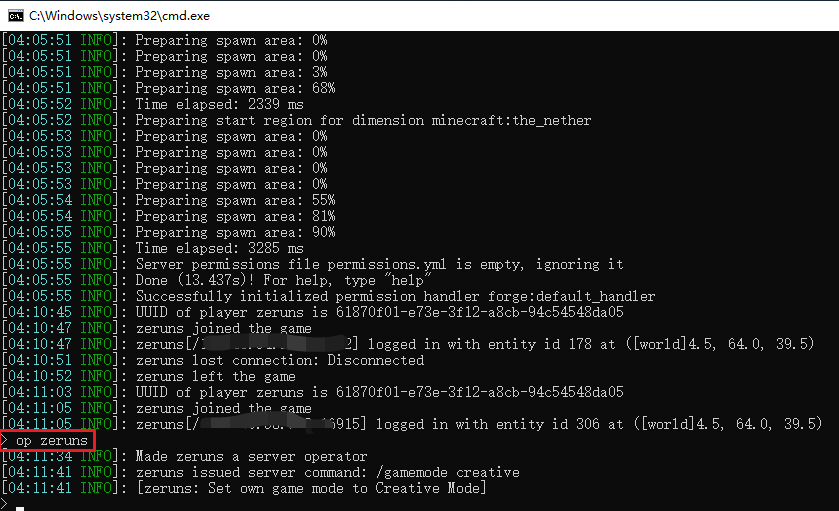
win系统搭建Minecraft世界服务器,MC开服教程,小白开服教程
Windows系统搭建我的世界世界服务器,Minecraft开服教程,小白开服教程,MC 1.19.4版本服务器搭建教程。 此教程使用 Mohist 1.19.4 服务端,此服务端支持Forge模组和Bukkit/Spigot/Paper插件,如果需要开其他服务端也可参…...

word2vec中的CBOW和Skip-gram
word2cev简单介绍 Word2Vec是一种用于学习词嵌入(word embeddings)的技术,旨在将单词映射到具有语义关联的连续向量空间。Word2Vec由Google的研究员Tomas Mikolov等人于2013年提出,它通过无监督学习从大规模文本语料库中学习词汇…...

在ios上z-index不起作用问题的总结
最近在维护一个H5老项目时,遇到一个问题,就是在ios上z-index不起作用,在安卓上样式都是好的。 项目的架构组成是vue2.x vux vuex vue-router等 用的UI组件库是vux 在页面中有一个功能点,就是点选择公司列表的时候,会…...

力扣labuladong一刷day59天动态规划
力扣labuladong一刷day59天动态规划 文章目录 力扣labuladong一刷day59天动态规划一、509. 斐波那契数二、322. 零钱兑换 一、509. 斐波那契数 题目链接:https://leetcode.cn/problems/fibonacci-number/description/ 思路:这是非常典型的一道题&#x…...

pyenv环境找不到sqlite:No module named _sqlite3
前言 一般遇到这个问题都在python版本管理或者虚拟环境切换中遇到,主要有两个办法解决,如下: 解决方法1 如果使用的pyenv管理python环境时遇到没有_sqlite3 库,可以将当前pyenv的python环境卸载 pyenv uninstall xxx然后在系统…...

Histone H3K4me2 Antibody, SNAP-Certified™ for CUTRUN
EpiCypher是一家为表观遗传学和染色质生物学研究提供高质量试剂和工具的专业制造商。EpiCypher推出的CUT&RUN级别的Histone H3K4me2 Antibody符合EpiCypher的批次特异性SNAP-CertifiedTM标准,在CUT&RUN中具有特异性和高效的靶点富集。通过SNAP-CUTANA™K-Me…...
我用 Laf 开发了一个非常好用的密码管理工具
【KeePass 密码管理】是一款简单、安全简洁的账号密码管理工具,服务端使用 Laf 云开发,支持指纹验证、FaceID,N 重安全保障,可以随时随地记录我的账号和密码。 写这个小程序之前,在国内市场找了很多密码存储类的 App …...

windows项目部署
文章目录 一、项目部署1.1 先准备好文件1.2安装jdk1.3 配置环境1.4 安装tomcat1.5 MySQL安装本机测试的话:远程连接测试 1.6 项目部署 一、项目部署 1.1 先准备好文件 1.2安装jdk 下一步 下一步 下一步 1.3 配置环境 变量名:JAVA_HOME 变量值:jdk的…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...

移动端AI助手开发实战:混合架构、模型部署与性能优化
1. 项目概述:一个移动端AI助手的诞生 最近在移动端AI应用开发圈子里,一个名为 copaw-mobile 的项目开始引起不少同行的注意。这个由 xmingai 团队开源的项目,定位非常清晰——它要做的,就是将一个功能强大的AI助手,…...

Arm CoreLink PCK-600电源管理架构与寄存器编程详解
1. Arm CoreLink PCK-600电源控制架构解析在嵌入式系统设计中,电源管理单元(PMU)是实现高效能耗控制的核心组件。Arm CoreLink PCK-600作为业界领先的电源控制解决方案,其架构设计体现了现代SoC电源管理的先进理念。PCK-600系列采…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...

基于IMAP的邮件自动化处理工具mymailclaw配置与实战指南
1. 项目概述:一个轻量级的邮件抓取与处理工具最近在折腾一个需要自动化处理邮件通知的小项目,发现市面上的方案要么太重,要么不够灵活。直到我遇到了psandis/mymailclaw这个项目,它就像一把小巧而锋利的瑞士军刀,专门用…...

基于树莓派与QT Py的本地化物联网红外遥控器DIY指南
1. 项目概述与核心价值想没想过,把家里那堆遥控器——电视的、机顶盒的、空调的、音响的——统统集成到一个你手机能打开的网页里?而且这个控制中心完全在你家局域网里运行,不依赖任何云服务,不用担心厂商倒闭后设备变砖。今天分享…...

韩国市场合规语音交付迫在眉睫!ElevenLabs韩文生成必须配置的4项GDPR+KCC隐私开关
更多请点击: https://intelliparadigm.com 第一章:韩国市场语音AI合规落地的紧迫性与战略意义 韩国《个人信息保护法》(PIPA)于2023年修订后,明确将语音生物特征数据列为“敏感信息”,要求语音AI系统在采集…...

RTX 5090功耗600W:高功耗显卡的系统级挑战与实战装机指南
1. 项目概述:从一则功耗新闻到显卡生态的深度解构最近,一则关于英伟达下一代旗舰显卡RTX 5090功耗可能高达600W的消息,在硬件圈和AI计算领域激起了不小的波澜。对于普通玩家而言,这或许只是一个“电老虎”又升级了的谈资ÿ…...

保姆级教程:用STM8S207R6和FD6288T自制BLDC驱动板,从原理图到代码框架搭建
从零构建BLDC驱动板:STM8S207R6与FD6288T实战指南 在创客和嵌入式开发领域,无刷直流电机(BLDC)控制一直是兼具挑战性和实用性的热门方向。与有刷电机相比,BLDC电机具有高效率、长寿命和低噪音等优势,但驱动电路和控制系统也更为复…...

基于CircuitPython的Fruit Jam OS:在RP2350上构建复古微型计算机系统
1. 项目概述:当复古计算精神遇见现代微控制器如果你和我一样,对早期个人计算机那种开机即用、一切尽在掌控的纯粹体验抱有怀念,同时又痴迷于现代开源硬件带来的无限可能,那么Fruit Jam OS绝对是一个会让你眼前一亮的项目。它不是一…...