sqlachemy orm create or delete table
sqlacehmy one to one ------detial to descript
关于uselist的使用。如果你使用orm直接创建表关系,实际上在数据库中是可以创建成多对多的关系,如果加上uselist=False 你会发现你的orm只能查询出来一个,如果不要这个参数orm查询的就是多个,一对多的关系。数据库级别如果也要限制可以自行建立唯一键进行约束。
总结就是:sqlacehmy One to One 是orm级别限制
sqlacehmy 简单创建实例展示:
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime Base = declarative_base()engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8', echo=True) class Worker(Base): # 表名 __tablename__ = 'worker' id = Column(Integer, primary_key=True) name = Column(String(50), unique=True) age = Column(Integer) birth = Column(DateTime) part_name = Column(String(50)) # 创建数据表Base.metadata.create_all(engine)该方法引入declarative_base模块,生成其对象Base,再创建一个类Worker。一般情况下,数据表名和类名是一致的。tablename用于定义数据表的名称,可以忽略,忽略时默认定义类名为数据表名。然后创建字段id、name、age、birth、part_name,最后使用Base.metadata.create_all(engine)在数据库中创建对应的数据表
数据表的删除
删除数据表的时候,一定要先删除设有外键的数据表,也就是先删除part,然后才能删除worker,两者之间涉及外键,这是在数据库中删除数据表的规则。对于两种不同方式创建的数据表,删除语句也不一样。
Base.metadata.drop_all(engine)
part.drop(bind=engine)
part.drop(bind=engine) Base.metadata.drop_all(engine)
sqlachemy +orm + create table代码
from sqlalchemy import Column, String, create_engine, Integer, Text
from sqlalchemy.orm import sessionmaker,declarative_base
import time# 创建对象的基类:
Base = declarative_base()# 定义User对象:
class User(Base):# 表的名字:__tablename__ = 'wokers'# 表的结构:id = Column(Integer, autoincrement=True, primary_key=True, unique=True, nullable=False)name = Column(String(50), nullable=False)sex = Column(String(4), nullable=False)nation = Column(String(20), nullable=False)birth = Column(String(8), nullable=False)id_address = Column(Text, nullable=False)id_number = Column(String(18), nullable=False)creater = Column(String(32))create_time = Column(String(20), nullable=False)updater = Column(String(32))update_time = Column(String(20), nullable=False, default=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),onupdate=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))comment = Column(String(200))# 初始化数据库连接:
engine = create_engine('postgresql://postgres:name@pwd:port/dbname') # 用户名:密码@localhost:端口/数据库名Base.metadata.create_all(bind=engine)可级联删除的写法实例
class Parent(Base):__tablename__ = "parent"id = Column(Integer, primary_key=True)class Child(Base):__tablename__ = "child"id = Column(Integer, primary_key=True)parentid = Column(Integer, ForeignKey(Parent.id, ondelete='cascade'))parent = relationship(Parent, backref="children")sqlachemy 比较好用的orm介绍链接:https://www.cnblogs.com/DragonFire/p/10166527.html
sqlachemy的级联删除:
https://www.cnblogs.com/ShanCe/p/15381412.html
除了以上例子还列举一下创建多对多关系实例
class UserModel(BaseModel):__tablename__ = "system_user"__table_args__ = ({'comment': '用户表'})username = Column(String(150), nullable=False, comment="用户名")password = Column(String(128), nullable=False, comment="密码")name = Column(String(40), nullable=False, comment="姓名")mobile = Column(String(20), nullable=True, comment="手机号")email = Column(String(255), nullable=True, comment="邮箱")gender = Column(Integer, default=1, nullable=False, comment="性别")avatar = Column(String(255), nullable=True, comment="头像")available = Column(Boolean, default=True, nullable=False, comment="是否可用")is_superuser = Column(Boolean, default=False, nullable=False, comment="是否超管")last_login = Column(DateTime, nullable=True, comment="最近登录时间")dept_id = Column(BIGINT,ForeignKey('system_dept.id', ondelete="CASCADE", onupdate="RESTRICT"),nullable=True, index=True, comment="DeptID")dept_part = relationship('DeptModel',back_populates='user_part')roles = relationship("RoleModel", back_populates='users', secondary=UserRolesModel.__tablename__, lazy="joined")positions = relationship("PositionModel", back_populates='users_obj', secondary=UserPositionModel.__tablename__, lazy="joined")class PositionModel(BaseModel):__tablename__ = "system_position_management"__table_args__ = ({'comment': '岗位表'})postion_number = Column(String(50), nullable=False, comment="岗位编号")postion_name = Column(String(50), nullable=False, comment="岗位名称")remark = Column(String(100), nullable=True, default="", comment="备注")positon_status = Column(Integer, nullable=False, default=0, comment="岗位状态")create_user = Column(Integer, nullable=True, comment="创建人")update_user = Column(Integer, nullable=True, comment="修改人")users_obj = relationship("UserModel", back_populates='positions', secondary=UserPositionModel.__tablename__, lazy="joined")class UserPositionModel(BaseModel):__tablename__ = "system_user_position"__table_args__ = ({'comment': '用户岗位关联表'})user_id = Column(BIGINT,ForeignKey("system_user.id", ondelete="CASCADE", onupdate="RESTRICT"),primary_key=True, comment="用户ID")position_id = Column(BIGINT,ForeignKey("system_position_management.id", ondelete="CASCADE", onupdate="RESTRICT"),primary_key=True, comment="岗位ID")
以上实例是多对多关系,主要是由PositionModel进行量表之间的多对多关系的关联
多对多关系查询
Session=sessionmaker(bind=engine)
sessions=Session()
Userobj=sessions.query(UserModel).filter(UserModel.id == 1).first()
# Positionobj=sessions.query(PositionModel).filter(PositionModel.id == 14).first()
# Userobj.positions.append(Positionobj)
for item in Userobj.positions:print(item.postion_name)
sessions.commit()
sessions.close()2个对象之间是通过relationship 关联参数进行 append 来创建关系
还可以通过remove来删除之间的关系
相关文章:

sqlachemy orm create or delete table
sqlacehmy one to one ------detial to descript 关于uselist的使用。如果你使用orm直接创建表关系,实际上在数据库中是可以创建成多对多的关系,如果加上uselistFalse 你会发现你的orm只能查询出来一个,如果不要这个参数orm查询的就是多个,一对多的…...
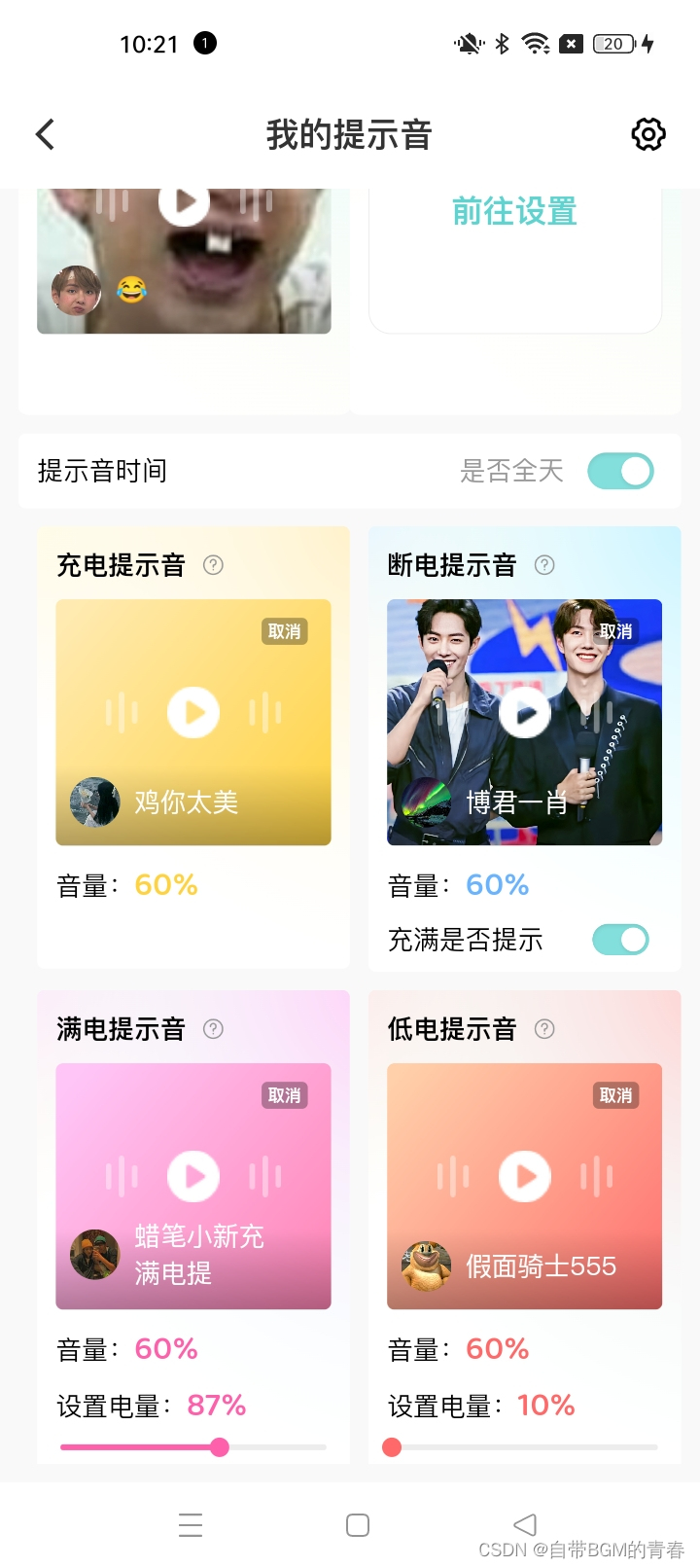
科普小米手机、华为手机、红米手机、oppo手机、vivo手机、荣耀手机、一加手机、realme手机如何设置充电提示音
用空空鱼就可以设置,上面还有很多提示音素材还可以设置满电和低电提醒...
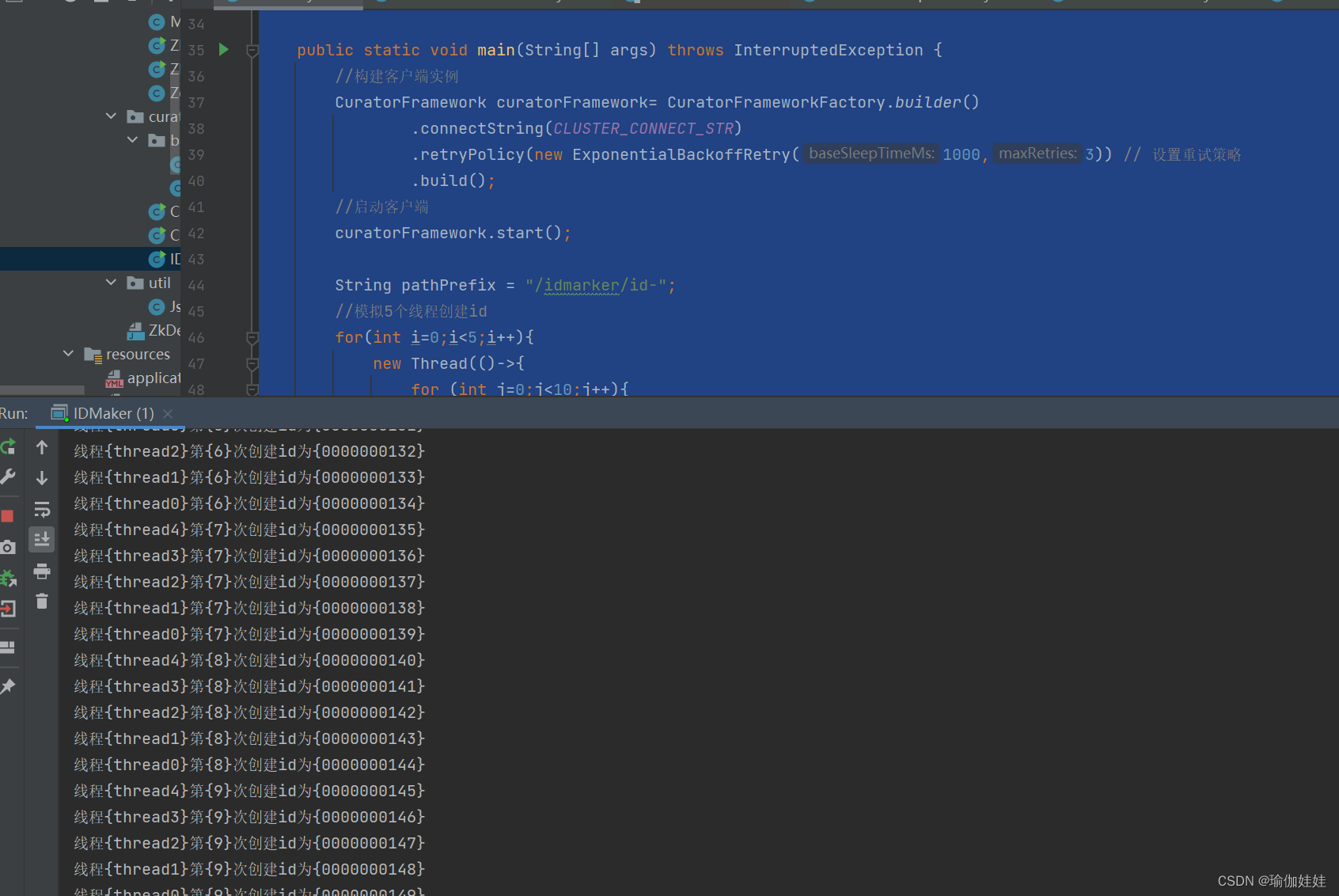
zookeeper应用场景之分布式的ID生成器
1. 分布式ID生成器的使用场景 在分布式系统中,分布式ID生成器的使用场景非常之多: 大量的数据记录,需要分布式ID。大量的系统消息,需要分布式ID。大量的请求日志,如restful的操作记录,需要唯一标识&#x…...
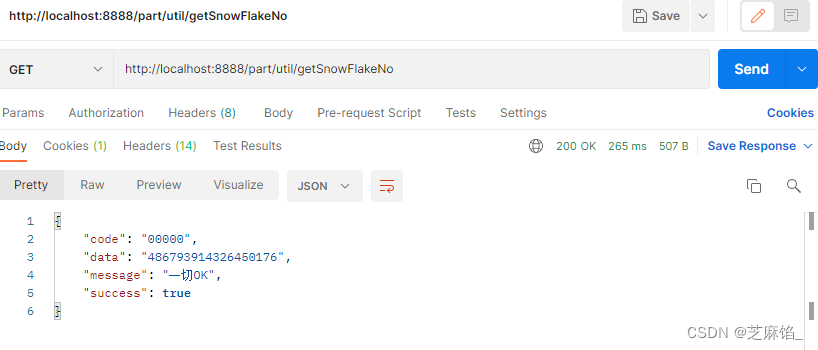
Java--Spring项目生成雪花算法数字(Twitter SnowFlake)
文章目录 前言步骤查看结果 前言 分布式系统常需要全局唯一的数字作为id,且该id要求有序,twitter的SnowFlake解决了这种需求,生成了符合条件的这种数字,本文将提供一个接口获取雪花算法数字。以下为代码。 步骤 SnowFlakeUtils …...

紫光展锐M6780丨画质增强——更炫的视觉体验
智能显示被认为是推动数字化转型和创新的重要技术之一。研究机构数据显示,预计到2035年底,全球智能显示市场规模将达到1368.6亿美元,2023-2035年符合年增长率为36.4%。 随着消费者对高品质视觉体验的需求不断增加,智能手机、平板…...

控制el-table的列显示隐藏
控制el-table的列显示隐藏,一般的话可以通过循环来实现,但是假如业务及页面比较复杂的话,list数组循环并不好用。 在我们的页面中el-table-column是固定的,因为现在是对现有的进行维护和迭代更新。 对需要控制列显示隐藏的页面进…...

2024上海国际冶金及材料分析测试仪器设备展览会
2024上海国际冶金及材料分析测试仪器设备展览会 时间:2024年12月18~20日 地点:上海新国际博览中心 ◆ 》》》组织机构: 主办单位:全联冶金商会、中国宝武钢铁集团有限公司、上海市金属学会 支持单位ÿ…...

商业定位,1元平价商业咨询:豪威尔咨询!平价咨询。
在做生意之前,就需要对企业整体进行一完整的商业定位,才能让商业定位带动企业进行飞速发展。 所以,包含商业定位的有效工作内容就显得极为重要,今天,小编特地为大家整理出了商业定位所需要的筹备的工作,如下…...
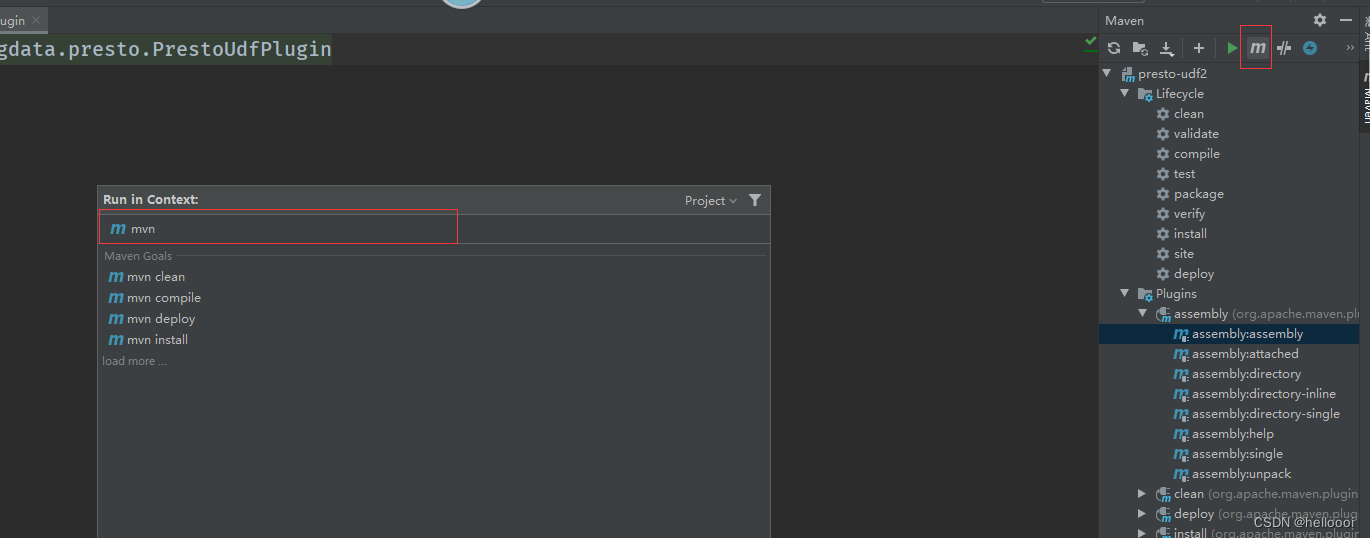
2. Presto应用
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。文章目录 1、Presto安装使用2、事件分析3、漏斗分析4、漏斗分析UDAF开发开发UDF插件开发UDAF插件 5、漏斗测试 1、Presto安装使用 参考官方文档:https://prestodb.io/docs/current/ P…...

工业级安卓PDA超高频读写器手持掌上电脑,RFID电子标签读写器
掌上电脑,又称为PDA。工业级PDA的特点就是坚固,耐用,可以用在很多环境比较恶劣的地方。 随着技术的不断发展,加快了数字化发展趋势,RFID技术就是RFID射频识别及技术,作为一种新兴的非接触式的自动识别技术&…...

Prompt提示工程上手指南:基础原理及实践(一)
想象一下,你在装饰房间。你可以选择一套标准的家具,这是快捷且方便的方式,但可能无法完全符合你的个人风格或需求。另一方面,你也可以选择定制家具,选择特定的颜色、材料和设计,以确保每件家具都符合你的喜…...

Redis如何保证缓存和数据库一致性?
背景 现在我们在面向增删改查开发时,数据库数据量大时或者对响应要求较快,我们就需要用到Redis来拿取数据。 Redis:是一种高性能的内存数据库,它将数据以键值对的形式存储在内存中,具有读写速度快、支持多种数据类型…...

学完C/C++,再学Python是一种什么体验?
你好,我是安然无虞。 文章目录 变量及类型变量类型动态类型特性 注释输入输出通过控制台输出通过控制台输入 运算符算术运算符关系运算符逻辑运算符赋值运算符 条件循环语句条件语句语法格式代码案例缩进和代码块空语句pass 循环语句while循环语法格式代码案例 for…...
ssm基于Java的壁纸网站设计与实现论文
目 录 目 录 I 摘 要 III ABSTRACT IV 1 绪论 1 1.1 课题背景 1 1.2 研究现状 1 1.3 研究内容 2 2 系统开发环境 3 2.1 vue技术 3 2.2 JAVA技术 3 2.3 MYSQL数据库 3 2.4 B/S结构 4 2.5 SSM框架技术 4 3 系统分析 5 3.1 可行性分析 5 3.1.1 技术可行性 5 3.1.2 操作可行性 5 3…...

零基础也可以探索 PyTorch 中的上采样与下采样技术
目录 torch.nn子模块Vision Layers详解 nn.PixelShuffle 用法与用途 使用技巧 注意事项 参数 示例代码 nn.PixelUnshuffle 用法与用途 使用技巧 注意事项 参数 示例代码 nn.Upsample 用法与用途 使用技巧 注意事项 参数 示例代码 nn.UpsamplingNearest2d …...

代码随想录算法训练营Day23|669. 修剪二叉搜索树、108.将有序数组转换为二叉搜索树、538.把二叉搜索树转换为累加树
目录 669. 修剪二叉搜索树 前言 思路 递归法 108.将有序数组转换为二叉搜索树 前言 递归法 538.把二叉搜索树转换为累加树 前言 递归法 总结 669. 修剪二叉搜索树 题目链接 文章链接 前言 本题承接昨天二叉搜索树的插入和删除操作题目,要对整棵二叉搜索树…...

乱 弹 篇(一)
题记 对于“乱弹”这个词汇的释义,《辞海》上仅有“ 戏曲剧种,亦指声腔 ”8个字。而由于“乱弹 ”的“ 弹”谐音谈”,这就容易让人联想到“乱谈”。不过从文体上看,“乱谈”也非乱七八糟之谈,反倒是“东西南北&#x…...
)
《JVM由浅入深学习【八】 2024-01-12》JVM由简入深学习提升分(JVM的垃圾回收算法)
目录 JVM的垃圾回收算法1. 标记-清除算法(Mark-Sweep)原理步骤优点缺点 2. 复制算法(Copying)原理步骤优点缺点 3. 标记-整理算法(Mark-Compact)原理步骤优点缺点 4. 分代收集算法(Generational…...

在矩阵回溯中进行累加和比较的注意点
1 总结 在回溯时,如果递归函数采用void返回,在入口处使用了sum变量,那么一般在初次调用dfs的地方,这个sum的初始值可能不是0,而是数组的对应指针的值,在比较操作的时候,需要在for循环开始之前进行…...
AI语音机器人的发展
第一代AI语音机器人具体投入研发的开始时间不太清楚,只记得2017年的下半年就已经开始接触到成型的AI语音机器人,并且正式商用。语音识别效果还不多,大多都是接入的科大讯飞或者百度的ASR。 2018年算是AI语音机器人的“青春期”吧,…...

基于React的记忆管理UI组件库:openclaw-memory-ui实战指南
1. 项目概述:一个为记忆管理而生的开源UI组件库最近在折腾一个需要处理大量结构化记忆数据的项目,比如知识库、笔记应用或者智能助手的历史对话管理。这类应用的核心痛点在于,数据本身是复杂的、多维的,但传统的列表或表格展示方式…...

MedAgentBench:大语言模型在医学诊断中的动态评估与智能体构建实践
1. 项目概述:当大语言模型成为医学诊断的“实习生”最近在医学人工智能的圈子里,一个名为MedAgentBench的项目引起了我的注意。它来自斯坦福大学机器学习组,这个名字本身就自带光环。简单来说,这不是一个直接看病的AI,…...

动态提示词工程:让AI提示词具备上下文学习能力的实践指南
1. 项目概述:当提示词遇上上下文学习最近在折腾大语言模型应用时,我反复遇到一个痛点:精心设计的提示词(Prompt)在特定任务上效果拔群,但换个场景或数据,效果就大打折扣。每次都得重新调整、测试…...

LoRA模型合并实战:多技能大模型融合指南与vLLM+Copaw工具链解析
1. 项目概述:LoRA模型合并的“瑞士军刀” 在AIGC(人工智能生成内容)领域,模型微调是让大语言模型(LLM)或扩散模型适配特定任务、风格或知识库的核心手段。而LoRA(Low-Rank Adaptation࿰…...

基于SpringBoot+Flowable的办公流程审批系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Flowable框架的办公流程审批系统以解决传统审批模式中存在的效率低下问题。当前多数组织机构在日常运营中普遍采用人工审批…...

从“客户匿名”到“可验证”:技术服务案例的工程化写法
在撰写技术服务案例时,我们经常面临一个挑战:客户要求匿名,但案例又需要让潜在客户相信效果。如何平衡?结合文澜天下科技在AI搜索优化项目中的实践,分享一种“可验证”的案例写法。一、定位具体行业和场景 不写“某教育…...

影刀RPA跨境店群运营架构:多账号环境隔离与 Python 高并发调度系统实战
关于我一个曾经死磕底层算法、痴迷于压榨软硬件性能、满脑子分布式高可用架构的资深开发者,最后跑去给跨境工作室的“Boss”写店群底层自动化调度系统这件事。 很多以前在技术圈里混的同行,或者是看着我一路从 ImageTransPro 图像处理软件 1.0 重构做到…...

从竞赛到实践:基于TDOA的声源定位系统设计与实现
1. 从竞赛到实战:TDOA声源定位系统设计全解析 第一次接触声源定位是在大三的电子设计竞赛上,当时看着题目要求"用激光笔追踪移动声源",我和队友面面相觑——这玩意儿真能实现吗?三年后,当我负责公司智能会议…...
)
告别python-pcl!用pclpy在Windows上轻松玩转PCL点云处理(Python 3.6/3.7保姆级教程)
告别python-pcl!用pclpy在Windows上轻松玩转PCL点云处理(Python 3.6/3.7保姆级教程) 在三维视觉和机器人领域,点云处理一直是核心技术难点之一。PCL(Point Cloud Library)作为开源领域的标杆工具库&#x…...
)
告别U盘!用PXE网络批量装UOS,一台电脑搞定所有(附Arm/Mips/X86全架构配置)
告别U盘!用PXE网络批量装UOS,一台电脑搞定所有(附Arm/Mips/X86全架构配置) 在国产化替代的大背景下,UOS操作系统凭借其出色的兼容性和安全性,正被越来越多的企业和机构采用。然而,当面对数十台甚…...