机器学习库(Numpy, Scikit-learn)
Numpy
创建数组
import numpy as npa = np.array([1,2,3])
b = np.array([(1.5,2,3), (4,5,6)], dtype = float)
c = np.array([[(1.5,2,3), (4,5,6)], [(3,2,1), (4,5,6)]],dtype = float)
创建占位符
z1=np.zeros((3,4))
z2=np.ones((2,3,4),dtype=np.int16)
z3=d= np.arange(10,25,5)
z4=np.linspace(0,2,9)
z5=e=np.full((2,2),7)
z6=f=np.eye(2)
z7=np.random.random((2,2))
z8=np.empty((3,2))
输入输出
1.保存到磁盘和从磁盘导入
2.保存到文件和从文件导入
np.save('my_array',a)
np.savez('array.npz',a,b)
np.load('my_array.npy')
查看数组信息
a.shape
len(a)
b.ndim
z1.size
b.dtype
b.dtype.name
b.astype(int)
数据类型
np.int64
np.float32
np.complex
np.bool
np.object
np.string_
np.unicode_
帮助
np.info(np.ndarray.dtype)
数组运算:1.运算 2.比较 3.聚合
g=a-b
np.subtract(a,b)
b+a
np.add(b,a)
a/b
np.divide(a,b)
a*b
np.multiply(a,b)print(np.exp(b))
print(np.sqrt(b))
print(np.sin(a))
print(np.cos(b))
print(np.log(a))
print(e.dot(f))
print(a)
print(b)
print(a.sum())
print(a.min())
print(b.max(axis=0))
print(b.cumsum(axis=1))
print(a.mean())
#print(b.median())
拷贝数组
print(a)
h = a.view()
print(h)
c =np.copy(a)
print(c)
a[1]=3
print(c)
h = a.copy()
print(h)
a[0] =2
print(h)
print(a)
数组切片,布尔索引,高级索引
print(a[0:2])
print(b[0:2,1])
print(b[:1])
print(c[1,...])
print(a[::-1])
print(a[a<2]) #选取所有a<2的元素
b[[1,0,1,0],[0,1,2,0]] #选取(1,0),(0,1),(1,2) 和(0,0)
数组操作 1.转置 2.增加删除元素 3.切分数组 4.改变数组形状 5.合并数组
i=np.transpose(b)
print(h.resize(2,6))
print(np.append(h,g))
print(np.insert(a,1,5))
print(np.delete(a,[1]))
print(np.hsplit(a,3))
print(np.vsplit(c,2))
b.ravel() #数组扁平化
g.reshape(3,-2) #
np.concatnate((a,d),axis=0)
np.vstack((a,b))
np.r_[e,f]
np.hstack((e,f))
np.column_stack((a,d))
np.c_[a,d]
Scikit-learn
基本的scikit-learn操作代码
from sklearn import neighbors, datasets, preprocessing
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = datasets.load_iris()
X, y = iris.data[:, :2], iris.target
X_train, X_test, y_train, y_test = train_test_split (X, y, random_state=33)
scaler = preprocessing.StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
knn = neighbors.KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracy_score(y_test, y_pred)
Normalization这个名词在很多地方都会出现,但是对于数据却有两种截然不同且容易混淆的处理过程。对于某个多特征的机器学习数据集来说,第一种Normalization是对于将数据进行预处理时进行的操作,是对于数据集的各个特征分别进行处理,主要包括min-max normalization、Z-score normalization、 log函数转换和atan函数转换等。第二种Normalization对于每个样本缩放到单位范数(每个样本的范数为1),主要有L1-normalization(L1范数)、L2-normalization(L2范数)等,可以用于SVM等应用
第一种 Normalization
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的标准化处理,即将数据统一映射到[0,1]区间上。标准化在0-1之间是统计的概率分布,标准化在某个区间上是统计的坐标分布。目前数据标准化方法有多种。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
标准化(normalization)的目的:
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。也就说标准化(normalization)的目的是:
把特征的各个维度标准化到特定的区间
把有量纲表达式变为无量纲表达式
归一化后有两个好处:
- 加快基于梯度下降法或随机梯度下降法模型的收敛速度
- 提升模型的精度
数据预处理:标准化 x=x−u/δx={x-u}/\deltax=x−u/δ
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X_train)
standardized_X = scaler.transform(X_train)
standardized_X_test = scaler.transform(X_test)
from sklearn.preprocessing import Normalizer
scaler = Normalizer().fit(X_train)
normalized_X = scaler.transform(X_train)
normalized_X_test = scaler.transform(X_test)
二值化
from sklearn.preprocessing import Binarizer
X = [[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]]
binarizer = preprocessing.Binarizer().fit(X) # fit does nothing
binarizer.transform(X)
模型初始化
from sklearn.linear_model import LinearRegression
lr = LinearRegression(normalize=True)
from sklearn.svm import SVC
svc = SVC(kernel='linear')
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier(n_neighbors=5)
模型训练
lr.fit(X, y)
knn.fit(X_train, y_train)
svc.fit(X_train, y_train)
k_means.fit(X_train)
#pca_model = pca.fit_transform(X_train)
预测
y_pred = svc.predict(np.random.radom((2,5)))
y_pred = lr.predict(X_test)
y_pred = knn.predict_proba(X_test)
数据预处理
#Standardization
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X_train)
standardized_X = scaler.transform(X_train)
standardized_X_test = scaler.transform(X_test)#Normalization
from sklearn.preprocessing import Normalizer
scaler = Normalizer().fit(X_train)
normalized_X = scaler.transform(X_train)
normalized_X_test = scaler.transform(X_test)#Binarization
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.0).fit(X)
binary_X = binarizer.transform(X)#Encoding Categorical Features
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values=0, strategy='mean', axis=0)
imp.fit_transform(X_train)#Imputing Missing Values
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values=0, strategy='mean', axis=0)
imp.fit_transform(X_train)#Generating Polynomial Features
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(5)
poly.fit_transform(X)
评价模型:分类算法的指标
#Accuracy Score
knn.score(X_test, y_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)#Classification Report
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))#Confusion Matrix
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_pred))
评价模型:回归算法的指标
#Mean Absolute Error
from sklearn.metrics import mean_absolute_error
y_true = [3, -0.5, 2]
mean_absolute_error(y_true, y_pred)
#Mean Squared Error
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_pred)
#R² Score
from sklearn.metrics import r2_score
r2_score(y_true, y_pred)
评价模型:聚类算法的指标
#Adjusted Rand Index
from sklearn.metrics import adjusted_rand_score
adjusted_rand_score(y_true, y_pred)
#Homogeneity
from sklearn.metrics import homogeneity_score
homogeneity_score(y_true, y_pred)
#V-measure
from sklearn.metrics import v_measure_score
metrics.v_measure_score(y_true, y_pred)
评价模型:交叉验证
#Cross-Validation
from sklearn.model_selection import cross_val_score
print(cross_val_score(knn, X_train, y_train, cv=4))
print(cross_val_score(lr, X, y, cv=2))
训练模型
#监督学习
lr.fit(X, y)
knn.fit(X_train, y_train)
svc.fit(X_train, y_train)
#无监督学习
k_means.fit(X_train)
pca_model = pca.fit_transform(X_train)
训练和测试
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y)
模型调优
#Grid Search
from sklearn.model_selection import GridSearchCV
params = {"n_neighbors": np.arange(1,3),"metric": ["euclidean","cityblock"]}
grid = GridSearchCV(estimator=knn,param_grid=params)
grid.fit(X_train, y_train)
print(grid.best_score_)
print(grid.best_estimator_.n_neighbors)#Randomized Parameter Optimization
from sklearn.model_selection import RandomizedSearchCV
params = {"n_neighbors": range(1,5),"weights": ["uniform", "distance"]}
rsearch = RandomizedSearchCV(estimator=knn,param_distributions=params,cv=4,n_iter=8,random_state=5)
rsearch.fit(X_train, y_train)
print(rsearch.best_score_)
相关文章:
)
机器学习库(Numpy, Scikit-learn)
Numpy 创建数组 import numpy as npa np.array([1,2,3]) b np.array([(1.5,2,3), (4,5,6)], dtype float) c np.array([[(1.5,2,3), (4,5,6)], [(3,2,1), (4,5,6)]],dtype float)创建占位符 z1np.zeros((3,4)) z2np.ones((2,3,4),dtypenp.int16) z3d np.arange(10,25,5)…...

Linux操作系统学习(进程替换)
文章目录进程替换进程替换是什么?替换的方法进程替换简易shell模拟进程替换 进程替换是什么? 如下图所示: 进程替换就是,把进程B的代码和数据,替换正在执行的进程A的代码和数据在内存中的位置(若代码…...

【C++从入门到放弃】类和对象(中)———类的六大默认成员函数
🧑💻作者: 情话0.0 📝专栏:《C从入门到放弃》 👦个人简介:一名双非编程菜鸟,在这里分享自己的编程学习笔记,欢迎大家的指正与点赞,谢谢! 类和对…...

白盒测试重点复习内容
白盒测试白盒测试之逻辑覆盖法逻辑覆盖用例设计方法1.语句覆盖2.判定覆盖(分支覆盖)3.条件覆盖4.判定条件覆盖5.条件组合覆盖6.路径覆盖白盒测试之基本路径测试法基本路径测试方法的步骤1.根据程序流程图画控制流图2.计算圈复杂度3.导出测试用例4.准备测试用例5.例题白盒测试总…...

【13】linux命令每日分享——groupadd建立组
大家好,这里是sdust-vrlab,Linux是一种免费使用和自由传播的类UNIX操作系统,Linux的基本思想有两点:一切都是文件;每个文件都有确定的用途;linux涉及到IT行业的方方面面,在我们日常的学习中&…...
《第一行代码》 第十章:服务
一,在子线程中更新UI 1,新建项目,修改布局代码 <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"&g…...
简单介绍编程进制
十进制 十进制的位权为 10,比如十进制的 123,123 1 * 10 ^ 2 2 * 10 ^ 1 3 * 10 ^ 0。 二进制 二进制的位权为 2,比如十进制的 4,二进制为 100,4 1 * 2 ^ 2 0 * 2 ^ 1 0 *2 ^ 0。 Java7 之前,不支…...

windows忘记开机密码怎么办
windows忘记开机密码怎么办 清除windows登录密码 清除windows登录密码简单方法 开机到欢迎界面时,按CtrlAltDelete两次,跳出帐号窗口,输入用户名:administrator,回车, 或者启动时按F8 选“带命令行的安全…...

SpringCloud:Eureka
目录 一、eureka的作用 二、搭建Eureka服务端 三、添加客户端 四、服务发现 提供者与消费者 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务) 服务消费者:一次业务中,调用其它微服务的服…...

如何获取或设置CANoe以太网网卡信息(SET篇)
CAPL提供了一系列函数用来操作CANoe网卡。但是,但是,首先需要明确一点,不管是获取网卡信息,还是设置网卡信息,只能访问CAPL程序所在的节点下的网卡,而不是节点所在的以太网通道下的所有网卡 关于第一张图中,Class节点下,有三个网卡:Ethernet1、VLAN 1.100、VLAN 1.200…...

【软件测试面试题】项目经验?资深测试 (分析+回答) 我不信你还拿不到offer......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 在面试过程中&#…...

tensorflow lite简介-移动设备端机器学习
TensorFlow Lite 是一组工具,可帮助开发者在移动设备、嵌入式设备和 loT 设备上运行模型,以便实现设备端机器学习。 支持多平台 支持多种平台,涵盖 Android 和 iOS 设备、嵌入式 Linux 和微控制器。 原理/流程 工作原理或者使用流程就是上面…...

Node.js常用知识
1、什么是 Node.js 【】Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。浏览器是 js 的前端运行环境,node.js 是 js 的后端运行环境。他们都有 V8 引擎,有各自的内置 API 2、fs 文件系统模块 【】fs 模块是 Node.js 官方提供的、用来操作文件…...
踩坑:maven打包失败的解决方式总结
Maven打包失败原因总结如下: 失败原因1:无法使用spring-boot-maven-plugin插件 使用spring-boot-maven-plugin插件可以创建一个可执行的JAR应用程序,前提是应用程序的parent为spring-boot-starter-parent。 需要添加parent的包spring-boot…...
【C++】位图
文章目录位图概念位图操作位图代码位图应用位图概念 boss直接登场: 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中❓ 40亿个整数,大概就是16GB。40亿个字节大概就是4GB。 1Byt…...

蓝桥杯-考勤刷卡
蓝桥杯-考勤刷卡1、问题描述2、解题思路3、代码实现1、问题描述 小蓝负责一个公司的考勤系统, 他每天都需要根据员工刷卡的情况来确定 每个员工是否到岗。 当员工刷卡时, 会在后台留下一条记录, 包括刷卡的时间和员工编号, 只 要在一天中员工刷过一次卡, 就认为他到岗了。 现在…...

如何利用站内推广和站外推广提高转化率?
在如今的网络时代,拥有一个好的网站是非常重要的。但是,光有一个好的网站是不够的,为了达到我们的目标,需要不断地提高网站的转化率。而在实现这个目标的过程中,站内推广和站外推广是两个非常关键的因素。 站内推广是…...
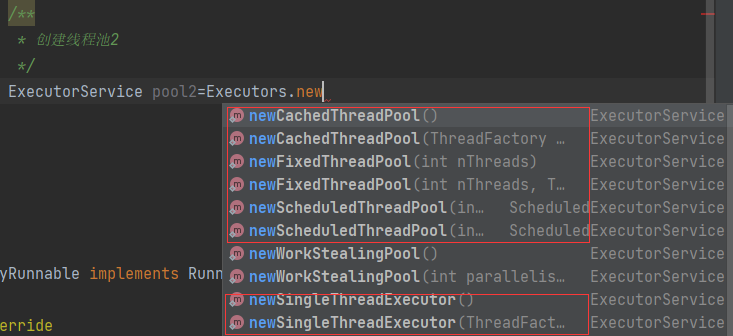
Java多线程(三)——线程池及定时器
线程池就是一个可以复用线程的技术。前面三种多线程方法就是在用户发起一个线程请求就创建一个新线程来处理,下次新任务来了又要创建新线程,而创建新线程的开销是很大的,这样会严重影响系统的性能。线程池就相当于预先创建好几个线程…...

Linux命令行安装Oracle19c教程和踩坑经验
安装 下载 从 Oracle官方下载地址 需要的版本,本次安装是在Linux上使用yum安装,因此下载的是RPM。另外,需要说明的是,Oracle加了锁的下载需要登录用户才能安装,而用户是可以免费注册的,这里不做过多说明。 …...

Linux常用命令等
目录 1.Linux常用命令 (1)系统命令 (2)文件操作命令 2.vim编辑器 3.linux系统中,软件安装 (1) rpm 安装,RedHat Package Manager (2)yum 安装 (3)源代码编译安装 1.Linux常用命令 Linux命令是非常多的,对于像嵌入式开发工程师,运维工程师需要掌握的命令是非常多的.对于…...

Fabric 结合IPFS 链码示例
购买专栏前请认真阅读:《Fabric项目学习笔记》专栏介绍 package mainimport ("bytes""encoding/json""fmt""time""github.com/hyperledger/fabric/core/chaincode/shim"sc "github.com/hyperledger/fabric/protos/pee…...

NanoSVG完整教程:从SVG文件解析到贝塞尔曲线渲染
NanoSVG完整教程:从SVG文件解析到贝塞尔曲线渲染 【免费下载链接】nanosvg Simple stupid SVG parser 项目地址: https://gitcode.com/gh_mirrors/na/nanosvg NanoSVG是一款轻量级的SVG解析库,能够将SVG文件高效转换为贝塞尔曲线数据,…...

如何利用Marketing-for-Engineers营销自动化工具:节省90%时间的终极指南
如何利用Marketing-for-Engineers营销自动化工具:节省90%时间的终极指南 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for…...

网络安全入门:2026年转行网络安全完整路径图
网络安全入门:2026 年转行网络安全完整路径图 导语:2026 年,网络安全人才缺口达 150 万,平均薪资较传统 IT 岗位高出 30%。但 70% 的转行者因路径不清晰而失败。本文详解 2026 年转行网络安全的完整路径:学习路线、证…...

Helm模板智能助手:提升Kubernetes应用部署效率的VSCode插件
1. 为什么你需要一个Helm模板智能助手如果你和我一样,每天都在和Kubernetes的Helm Charts打交道,那你一定对编写templates/目录下那些.yaml文件又爱又恨。爱的是Helm的模板引擎确实强大,能把一堆重复的YAML配置抽象成可复用的模板;…...

党建知识竞赛系统推荐:满足各级党组织需求的智能化工具
🚩 党建知识竞赛系统推荐:满足各级党组织需求的智能化工具创新党员教育形式 提升学习实效 推动智慧党建🎯 一、核心价值与功能需求在新时代加强党的建设背景下,如何创新党员教育形式、提升学习实效,是各级党组织面临…...

基于MCP的任务编排框架:让AI代理动态规划与执行复杂工作流
1. 项目概述:一个面向AI代理的任务编排与执行框架最近在折腾AI应用开发,特别是想让大语言模型(LLM)能更“自主”地完成一些复杂任务时,发现了一个绕不开的痛点:任务编排。你给模型一个目标,比如…...

别再只调API了!深入Qt QGraphicsView事件流,彻底搞懂拖拽缩放背后的‘为什么’
深入Qt QGraphicsView事件流:从拖拽缩放的底层机制到高效调试 在Qt的图形视图框架中,QGraphicsView、QGraphicsScene和QGraphicsItem构成了一个强大的交互系统。许多开发者虽然能够通过调用API实现基本功能,但当遇到事件被意外吞噬、坐标计算…...
:8大核心维度,适配信创+全行业场景)
2026设备管理系统选型标准(技术向):8大核心维度,适配信创+全行业场景
对于企业IT运维、采购人员而言,设备管理系统选型需兼顾技术适配、合规要求、落地效率与长期扩展性。本文从技术与实践角度,梳理出8大核心选型标准,重点覆盖独享云部署、Excel导入能力、自定义扩展、信创适配等关键维度,为技术选型…...

算法将驱动一切:边缘AI智能体如何重塑智能系统
仓库装卸区的安全摄像头每天采集86400秒的视频数据。长途卡车上的车队远程信息记录仪在两次加油之间积累了数GB的行车影像。外科手术机器人的立体摄像头以每秒60帧的速度生成密集点云。所有这些数据都产生于数字世界与现实世界的交界处,但几乎没有任何一条被用于智能…...