2.右值引用和移动语义
文章目录
- 右值引用和移动语义
- &&的特性
- 右值引用优化性能,避免深拷贝
- 移动(move )语义
- forward 完美转发
- emplace_back 减少内存拷贝和移动
- unordered container 无序容器
- map和unordered_map的差别
- 内部实现机理不同
- 优缺点以及适用处
- 小结
- 优缺点以及适用处
- 小结
代码地址:https://github.com/Phoenix8215/CplusplusMagicalCrafts
右值引用和移动语义
作用:C++11中引用了右值引用和移动语义,可以避免无谓的复制,提高了程序性能。
左值是表达式结束后仍然存在的持久对象,右值是指表达式结束时就不存在的临时对象。
-
区分左值和右值的便捷方法是看能不能对表达式取地址,如果能则为左值,否则为右值;
-
将亡值是C++11新增的、与右值引用相关的表达式,比如:将要被移动的对象、T&&函数返回的 值、std::move返回值和转换成T&&的类型的转换函数返回值。
C++11中的所有的值必将属于左值、将亡值、纯右值三者之一,将亡值和纯右值都属于右值。 区分表达式的左右值属性:如果可对表达式用&符取址,则为左值,否则为右值。
左值 lvalue 是有标识符、可以取地址的表达式,最常见的情况有:
- 变量、函数或数据成员的名字
- 返回左值引用的表达式,如 ++x、x = 1、cout << ’ ’
- 字符串字面量如 “hello world”
纯右值 prvalue 是没有标识符、不可以取地址的表达式,一般也称之为“临时对象”。最常见的情况有:
- 返回非引用类型的表达式,如 x++、x + 1、make_shared(42)
- 除字符串字面量之外的字面量,如 42、true
&&的特性
右值引用就是对一个右值进行引用的类型。因为右值没有名字,所以我们只能通过引用的方式找到它。 无论声明左值引用还是右值引用都必须立即进行初始化,因为引用类型本身并不拥有所把绑定对象的内 存,只是该对象的一个别名。
通过右值引用的声明,该右值又“重获新生”,其生命周期其生命周期与右值引用类型变量的生命周期一 样,只要该变量还活着,该右值临时量将会一直存活下去。
&& 的总结如下:
- 左值和右值是独立于它们的类型的,右值引用类型可能是左值也可能是右值。
- auto&& 或函数参数类型自动推导的 T&& 是一个未定的引用类型,被称为 universal references, 它可能是左值引用也可能是右值引用类型,取决于初始化的值类型。
- 所有的右值引用叠加到右值引用上仍然是一个右值引用,其他引用折叠都为左值引 用。当 T&& 为 模板参数时,输入左值,它会变成左值引用,而输入右值时则变为具名的右 值引用。
- 编译器会将已命名的右值引用视为左值,而将未命名的右值引用视为右值。
右值引用优化性能,避免深拷贝
对于含有堆内存的类,我们需要提供深拷贝的拷贝构造函数,如果使用默认构造函数,会导致堆内存的 重复删除,比如下面的代码:
//2-1-memory
#include <iostream>
using namespace std;
class A
{public:A() :m_ptr(new int(0)) {cout << "constructor A" << endl;}~A(){cout << "destructor A, m_ptr:" << m_ptr << endl;delete m_ptr;m_ptr = nullptr;}private:int* m_ptr;
};
// 为了避免返回值优化,此函数故意这样写
A Get(bool flag)
{A a;A b;cout << "ready return" << endl;if (flag)return a;elsereturn b;
}
int main()
{{A a = Get(false); // 运行报错}cout << "main finish" << endl;return 0;
}
/*
constructor A
constructor A
ready return
destructor A, m_ptr:0xf87af8
destructor A, m_ptr:0xf87ae8
destructor A, m_ptr:0xf87af8
main finish
*/
在上面的代码中,默认构造函数是浅拷贝,main函数的 a 和Get函数的 b 会指向同一个指针 m_ptr,在 析构的时候会导致重复删除该指针。正确的做法是提供深拷贝的拷贝构造函数,比如下面的代码(关闭 返回值优化的情况下):
//2-1-memory2
#include <iostream>
using namespace std;
class A
{public:A() :m_ptr(new int(0)) {cout << "constructor A" << endl;}A(const A& a) :m_ptr(new int(*a.m_ptr)) {cout << "copy constructor A" << endl;}~A(){cout << "destructor A, m_ptr:" << m_ptr << endl;delete m_ptr;m_ptr = nullptr;}private:int* m_ptr;
};
// 为了避免返回值优化,此函数故意这样写
A Get(bool flag)
{A a;A b;cout << "ready return" << endl;if (flag)return a;elsereturn b;
}
int main()
{{A a = Get(false); // 正确运行}cout << "main finish" << endl;return 0;
}
/*
constructor A
constructor A
ready return
copy constructor A
destructor A, m_ptr:0xea7af8
destructor A, m_ptr:0xea7ae8
destructor A, m_ptr:0xea7b08
main finish
*/
这样就可以保证拷贝构造时的安全性,但有时这种拷贝构造却是不必要的,比如上面代码中的拷贝构造 就是不必要的。上面代码中的 Get 函数会返回临时变量,然后通过这个临时变量拷贝构造了一个新的对 象 b,临时变量在拷贝构造完成之后就销毁了,如果堆内存很大,那么,这个拷贝构造的代价会很大, 带来了额外的性能损耗。有没有办法避免临时对象的拷贝构造呢?答案是肯定的。看下面的代码:
//2-1-memory3
#include <iostream>
using namespace std;
class A
{public:A() :m_ptr(new int(0)) {cout << "constructor A" << endl;}A(const A& a) :m_ptr(new int(*a.m_ptr)) {cout << "copy constructor A" << endl;}A(A&& a) :m_ptr(a.m_ptr) {a.m_ptr = nullptr;cout << "move constructor A" << endl;}~A(){cout << "destructor A, m_ptr:" << m_ptr << endl;if(m_ptr)delete m_ptr;}private:int* m_ptr;
};
// 为了避免返回值优化,此函数故意这样写
A Get(bool flag)
{A a;A b;cout << "ready return" << endl;if (flag)return a;elsereturn b;
}
int main()
{{A a = Get(false); // 正确运行}cout << "main finish" << endl;return 0;
}/*
constructor A
constructor A
ready return
move constructor A
destructor A, m_ptr:0
destructor A, m_ptr:0xfa7ae8
destructor A, m_ptr:0xfa7af8
main finish
*/
上面的代码中没有了拷贝构造,取而代之的是移动构造( Move Construct)。从移动构造函数的实现 中可以看到,它的参数是一个右值引用类型的参数 A&&,这里没有深拷贝,只有浅拷贝,这样就避免了 对临时对象的深拷贝,提高了性能。这里的 A&& 用来根据参数是左值还是右值来建立分支,如果是临时 值,则会选择移动构造函数。移动构造函数只是将临时对象的资源做了浅拷贝,不需要对其进行深拷 贝,从而避免了额外的拷贝,提高性能。这也就是所谓的移动语义( move 语义),右值引用的一个重 要目的是用来支持移动语义的。
移动语义可以将资源(堆、系统对象等)通过浅拷贝方式从一个对象转移到另一个对象,这样能够减少 不必要的临时对象的创建、拷贝以及销毁,可以大幅度提高 C++ 应用程序的性能,消除临时对象的维护 (创建和销毁)对性能的影响。
以一个简单的 string 类为示例,实现拷贝构造函数和拷贝赋值操作符。
//2-1-mystring
#include <iostream>
#include <vector>
#include <cstdio>
#include <cstdlib>
#include <string.h>
using namespace std;
class MyString {private:char* m_data;size_t m_len;void copy_data(const char *s) {m_data = new char[m_len+1];memcpy(m_data, s, m_len);m_data[m_len] = '\0';}public:MyString() {m_data = NULL;m_len = 0;}MyString(const char* p) {m_len = strlen (p);copy_data(p);}MyString(const MyString& str) {m_len = str.m_len;copy_data(str.m_data);std::cout << "Copy Constructor is called! source: " << str.m_data <<std::endl;}MyString& operator=(const MyString& str) {if (this != &str) {m_len = str.m_len;copy_data(str.m_data);}std::cout << "Copy Assignment is called! source: " << str.m_data <<std::endl;return *this;}virtual ~MyString() {if (m_data) free(m_data);}
};
void test() {MyString a;a = MyString("Hello");std::vector<MyString> vec;vec.push_back(MyString("World"));
}
int main()
{test();return 0;
}
实现了调用拷贝构造函数的操作和拷贝赋值操作符的操作。MyString(“Hello”) 和 MyString(“World”) 都 是临时对象,也就是右值。虽然它们是临时的,但程序仍然调用了拷贝构造和拷贝赋值,造成了没有意 义的资源申请和释放的操作。如果能够直接使用临时对象已经申请的资源,既能节省资源,有能节省资 源申请和释放的时间。这正是定义转移语义的目的。
用c++11的右值引用来定义这两个函数
// 用c++11的右值引用来定义这两个函数
MyString(MyString&& str) {std::cout << "Move Constructor is called! source: " << str.m_data <<std::endl;m_len = str.m_len;m_data = str.m_data; //避免了不必要的拷贝str.m_len = 0;str.m_data = NULL;
}
MyString& operator=(MyString&& str) {std::cout << "Move Assignment is called! source: " << str.m_data <<std::endl;if (this != &str) {m_len = str.m_len;m_data = str.m_data; //避免了不必要的拷贝str.m_len = 0;str.m_data = NULL;}return *this;
}
有了右值引用和转移语义,我们在设计和实现类时,对于需要动态申请大量资源的类,应该设计右值引 用的拷贝构造函数和赋值函数,以提高应用程序的效率。
移动(move )语义
我们知道移动语义是通过右值引用来匹配临时值的,那么,普通的左值是否也能借组移动语义来优化性 能呢?C++11为了解决这个问题,提供了std::move()方法来将左值转换为右值,从而方便应用移动语 义。move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转义,没有内存拷贝。
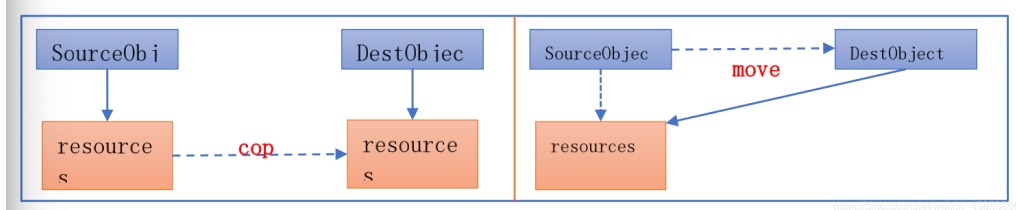
//2-2-move1
#include <iostream>
#include <vector>
#include <cstdio>
#include <cstdlib>
#include <string.h>
using namespace std;
class MyString {private:char* m_data;size_t m_len;void copy_data(const char *s) {m_data = new char[m_len+1];memcpy(m_data, s, m_len);m_data[m_len] = '\0';}public:MyString() {m_data = NULL;m_len = 0;}MyString(const char* p) {m_len = strlen (p);copy_data(p);}MyString(const MyString& str) {m_len = str.m_len;copy_data(str.m_data);std::cout << "Copy Constructor is called! source: " << str.m_data <<std::endl;}MyString& operator=(const MyString& str) {if (this != &str) {m_len = str.m_len;copy_data(str.m_data);}std::cout << "Copy Assignment is called! source: " << str.m_data <<std::endl;return *this;}// 用c++11的右值引用来定义这两个函数MyString(MyString&& str) {std::cout << "Move Constructor is called! source: " << str.m_data <<std::endl;m_len = str.m_len;m_data = str.m_data; //避免了不必要的拷贝str.m_len = 0;str.m_data = NULL;}MyString& operator=(MyString&& str) {std::cout << "Move Assignment is called! source: " << str.m_data <<std::endl;if (this != &str) {m_len = str.m_len;m_data = str.m_data; //避免了不必要的拷贝str.m_len = 0;str.m_data = NULL;}return *this;}virtual ~MyString() {if (m_data) free(m_data);}
};
int main()
{MyString a;a = MyString("Hello"); // moveMyString b = a; // copyMyString c = std::move(a); // move, 将左值转为右值return 0;
}forward 完美转发
forward 完美转发实现了参数在传递过程中保持其值属性的功能,即若是左值,则传递之后仍然是左 值,若是右值,则传递之后仍然是右值。
现存在一个函数
Template<class T>
void func(T &&val);
根据前面所描述的,这种引用类型既可以对左值引用,亦可以对右值引用。 但要注意,引用以后,这个val值它本质上是一个左值! 看下面例子
int &&a = 10;
int &&b = a; //错误
注意这里,a是一个右值引用,但其本身a也有内存名字,所以a本身是一个左值,再用右值引用引用a这 是不对的。
因此我们有了std::forward()完美转发,这种T &&val中的val是左值,但如果我们用std::forward (val), 就会按照参数原来的类型转发;
int &&a = 10;
int &&b = std::forward<int>(a);
这样是正确的! 通过范例巩固下知识:
//2-4-forward
#include <iostream>
using namespace std;
template <class T>void Print(T &t)
{cout << "L" << t << endl;
}
template <class T>void Print(T &&t)
{cout << "R" << t << endl;
}
template <class T>void func(T &&t)
{Print(t);Print(std::move(t));Print(std::forward<T>(t));
}
int main()
{cout << "-- func(1)" << endl;func(1);int x = 10;int y = 20;cout << "-- func(x)" << endl;func(x); // x本身是左值cout << "-- func(std::forward<int>(y))" << endl;func(std::forward<int>(y)); //return 0;
}
/*
-- func(1)
L1
R1
R1
-- func(x)
L10
R10
L10 按照原来的属性转发
-- func(std::forward(y))
L20
R20
R20
*/
解释: func(1) :由于1是右值,所以未定的引用类型T&&v被一个右值初始化后变成了一个右值引用,但是在 func()函数体内部,调用PrintT(v) 时,v又变成了一个左值(因为在std::forward里它已经变成了一个具 名的变量,所以它是一个左值),因此,示例测试结果第一个PrintT被调用,打印出“L1" 调用PrintT(std::forward(v))时,由于std::forward会按参数原来的类型转发,因此,它还是一个右值 (这里已经发生了类型推导,所以这里的T&&不是一个未定的引用类型,会调用void PrintT(T&&t)函 数打印 “R1”.调用PrintT(std::move(v))是将v变成一个右值(v本身也是右值),因此,它将输出”R1" func(x)未定的引用类型T&&v被一个左值初始化后变成了一个左值引用,因此,在调用 PrintT(std::forward(v))时它会被转发到void PrintT(T&t).
forward将左值转换为右值:
MyString str1 = "hello";
MyString str2(str1);
MyString str3 = Fun();
MyString str4 = move(str2);
MyString str5(forward<MyString>(str3));
综合示例
#include "stdio.h"
#include <iostream>
#include<vector>
using namespace std;
class A
{public:A() :m_ptr(NULL), m_nSize(0){}A(int *ptr, int nSize){m_nSize = nSize;m_ptr = new int[nSize];if (m_ptr){memcpy(m_ptr, ptr, sizeof(sizeof(int) * nSize));}}A(const A& other) // 拷贝构造函数实现深拷贝{m_nSize = other.m_nSize;if (other.m_ptr){delete[] m_ptr;m_ptr = new int[m_nSize];memcpy(m_ptr, other.m_ptr, sizeof(sizeof(int)* m_nSize));}else{m_ptr = NULL;}cout << "A(const int &i)" << endl;}// 右值应用构造函数A(A &&other){m_ptr = NULL;m_nSize = other.m_nSize;if (other.m_ptr){m_ptr = move(other.m_ptr); // 移动语义other.m_ptr = NULL;}}~A(){if (m_ptr){delete[] m_ptr;m_ptr = NULL;}}void deleteptr(){if (m_ptr){delete[] m_ptr;m_ptr = NULL;}}int *m_ptr;int m_nSize;
};
void main()
{int arr[] = { 1, 2, 3 };A a(arr, sizeof(arr)/sizeof(arr[0]));cout << "m_ptr in a Addr: 0x" << a.m_ptr << endl;A b(a);cout << "m_ptr in b Addr: 0x" << b.m_ptr << endl;b.deleteptr();A c(std::forward<A>(a)); // 完美转换cout << "m_ptr in c Addr: 0x" << c.m_ptr << endl;c.deleteptr();vector<int> vect{ 1, 2, 3, 4, 5 };cout << "before move vect size: " << vect.size() << endl;vector<int> vect1 = move(vect);cout << "after move vect size: " << vect.size() << endl;cout << "new vect1 size: " << vect1.size() << endl;
}emplace_back 减少内存拷贝和移动
对于STL容器,C++11后引入了emplace_back接口。 emplace_back是就地构造,不用构造后再次复制到容器中。因此效率更高。 考虑这样的语句:
vector<string> testVec;
testVec.push_back(string(16, 'a'));
上述语句足够简单易懂,将一个string对象添加到testVec中。底层实现:
- 首先,string(16, ‘a’)会创建一个string类型的临时对象,这涉及到一次string构造过程。
- 其次,vector内会创建一个新的string对象,这是第二次构造。
- 最后在push_back结束时,最开始的临时对象会被析构。加在一起,这两行代码会涉及到两次 string构造和一次析构。
c++11可以用emplace_back代替push_back,emplace_back可以直接在vector中构建一个对象,而非 创建一个临时对象,再放进vector,再销毁。emplace_back可以省略一次构建和一次析构,从而达到优 化的目的.
//time_interval.h
#ifndef TIME_INTERVAL_H
#define TIME_INTERVAL_H
#include <iostream>
#include <memory>
#include <string>
#ifdef GCC
#include <sys/time.h>
#else
#include <ctime>
#endif // GCC
class TimeInterval
{public:TimeInterval(const std::string& d) : detail(d){init();}TimeInterval(){init();}~TimeInterval(){#ifdef GCCgettimeofday(&end, NULL);std::cout << detail<< 1000 * (end.tv_sec - start.tv_sec) + (end.tv_usec -start.tv_usec) / 1000<< " ms" << endl;#elseend = clock();std::cout << detail<< (double)(end - start) << " ms" << std::endl;#endif // GCC}protected:void init() {#ifdef GCCgettimeofday(&start, NULL);#elsestart = clock();#endif // GCC}private:std::string detail;#ifdef GCCtimeval start, end;#elseclock_t start, end;#endif // GCC
};
#define TIME_INTERVAL_SCOPE(d) std::shared_ptr<TimeInterval>
time_interval_scope_begin = std::make_shared<TimeInterval>(d)#endif // TIME_INTERVAL_H
//2-5-emplace_back
#include <vector>
#include <string>
#include "time_interval.h"
int main() {std::vector<std::string> v;int count = 10000000;v.reserve(count); //预分配十万大小,排除掉分配内存的时间{TIME_INTERVAL_SCOPE("push_back string:");for (int i = 0; i < count; i++){std::string temp("ceshi");v.push_back(temp);// push_back(const string&),参数是左值引用}}v.clear();{TIME_INTERVAL_SCOPE("push_back move(string):");for (int i = 0; i < count; i++){std::string temp("ceshi");v.push_back(std::move(temp));// push_back(string &&), 参数是右值引用}}v.clear();{TIME_INTERVAL_SCOPE("push_back(string):");for (int i = 0; i < count; i++){v.push_back(std::string("ceshi"));// push_back(string &&), 参数是右值引用}}v.clear();{TIME_INTERVAL_SCOPE("push_back(c string):");for (int i = 0; i < count; i++){v.push_back("ceshi");// push_back(string &&), 参数是右值引用}}v.clear();{TIME_INTERVAL_SCOPE("emplace_back(c string):");for (int i = 0; i < count; i++){v.emplace_back("ceshi");// 只有一次构造函数,不调用拷贝构造函数,速度最快}}
}
/*
push_back string:335 ms
push_back move(string):307 ms
push_back(string):285 ms
push_back(c string):295 ms
emplace_back(c string):234 ms
*/
第1中方法耗时最长,原因显而易见,将调用左值引用的push_back,且将会调用一次string的拷贝构造 函数,比较耗时,这里的string还算很短的,如果很长的话,差异会更大
第2、3、4中方法耗时基本一样,参数为右值,将调用右值引用的push_back,故调用string的移动构造 函数,移动构造函数耗时比拷贝构造函数少,因为不需要重新分配内存空间。
第5中方法耗时最少,因为emplace_back只调用构造函数,没有移动构造函数,也没有拷贝构造函数。 为了证实上述论断,我们自定义一个类,并在普通构造函数、拷贝构造函数、移动构造函数中打印相应 描述:
#include <vector>
#include <string>
#include "time_interval.h"
using namespace std;
class Foo {public:Foo(std::string str) : name(str) {std::cout << "constructor" << std::endl;}Foo(const Foo& f) : name(f.name) {std::cout << "copy constructor" << std::endl;}Foo(Foo&& f) : name(std::move(f.name)){std::cout << "move constructor" << std::endl;}private:std::string name;
};
int main() {std::vector<Foo> v;int count = 10000000;v.reserve(count); //预分配十万大小,排除掉分配内存的时间{TIME_INTERVAL_SCOPE("push_back T:");Foo temp("test");v.push_back(temp);// push_back(const T&),参数是左值引用//打印结果://constructor//copy constructor}cout << " ---------------------\n" << endl;v.clear();{TIME_INTERVAL_SCOPE("push_back move(T):");Foo temp("test");v.push_back(std::move(temp));// push_back(T &&), 参数是右值引用//打印结果://constructor//move constructor}cout << " ---------------------\n" << endl;v.clear();{TIME_INTERVAL_SCOPE("push_back(T&&):");v.push_back(Foo("test"));// push_back(T &&), 参数是右值引用//打印结果://constructor//move constructor}cout << " ---------------------\n" << endl;v.clear();{std::string temp = "test";TIME_INTERVAL_SCOPE("push_back(string):");v.push_back(temp);// push_back(T &&), 参数是右值引用//打印结果://constructor//move constructor}cout << " ---------------------\n" << endl;v.clear();{std::string temp = "test";TIME_INTERVAL_SCOPE("emplace_back(string):");v.emplace_back(temp);// 只有一次构造函数,不调用拷贝构造函数,速度最快//打印结果://constructor}
}
/*
constructor
copy constructor
push_back T:2 ms
constructor
move constructor
push_back move(T):0 ms
constructor
move constructor
push_back(T&&):0 ms
constructor
move constructor
push_back(string):0 ms
constructor
emplace_back(string):0 ms
*/
unordered container 无序容器
C++11 增加了无序容器 unordered_map/unordered_multimap 和 unordered_set/unordered_multiset,由于这些容器中的元素是不排序的,因此,比有序容器 map/multimap 和 set/multiset 效率更高。 map 和 set 内部是红黑树,在插入元素时会自动排序,而 无序容器内部是散列表( Hash Table),通过哈希( Hash),而不是排序来快速操作元素,使得效率 更高。由于无序容器内部是散列表,因此无序容器的 key 需要提供 hash_value 函数,其他用法和 map/set 的用法是一样的。不过对于自定义的 key,需要提供 Hash 函数和比较函数。
map和unordered_map的差别
需要引入的头文件不同
-
map: #include < map > -
unordered_map: #include < unordered_map >
内部实现机理不同
- map: map内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而AVL是严格平衡二叉搜 索树),红黑树具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点 都代表着map的一个元素。因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对 红黑树进行的操作。map中的元素是按照二叉搜索树(又名二叉查找树、二叉排序树,特点就是左 子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值)存储 的,使用中序遍历可将键值按照从小到大遍历出来。
- unordered_map: unordered_map内部实现了一个哈希表(也叫散列表,通过把关键码值映射到 Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应 用)。因此,其元素的排列顺序是无序的。
优缺点以及适用处
map:
- 优点: 有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作 红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非 常的高
- 缺点:
空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额 外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
- 适用处: 对于那些有顺序要求的问题,用map会更高效一些
unordered_map:
- 优点: 因为内部实现了哈希表,因此其查找速度非常的快
- 缺点: 哈希表的建立比较耗费时间
- 适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用 unordered_map
总结
- 内存占有率的问题就转化成红黑树 VS hash表 , 还是unorder_map占用的内存要高。
- 但是unordered_map执行效率要比map高很多
- 对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相 同,因为遍历是按照哈希表从前往后依次遍历的
小结
C++11 在性能上做了很大的改进,最大程度减少了内存移动和复制,通过右值引用、 forward、 emplace 和一些无序容器我们可以大幅度改进程序性能。
- 右值引用仅仅是通过改变资源的所有者来避免内存的拷贝,能大幅度提高性能。
- forward 能根据参数的实际类型转发给正确的函数。
- emplace 系列函数通过直接构造对象的方式避免了内存的拷贝和移动。
),其在海量数据处理中有着广泛应 用)。因此,其元素的排列顺序是无序的。
优缺点以及适用处
map:
- 优点: 有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作 红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非 常的高
- 缺点:
空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额 外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
- 适用处: 对于那些有顺序要求的问题,用map会更高效一些
unordered_map:
- 优点: 因为内部实现了哈希表,因此其查找速度非常的快
- 缺点: 哈希表的建立比较耗费时间
- 适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用 unordered_map
总结
- 内存占有率的问题就转化成红黑树 VS hash表 , 还是unorder_map占用的内存要高。
- 但是unordered_map执行效率要比map高很多
- 对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相 同,因为遍历是按照哈希表从前往后依次遍历的
小结
C++11 在性能上做了很大的改进,最大程度减少了内存移动和复制,通过右值引用、 forward、 emplace 和一些无序容器我们可以大幅度改进程序性能。
- 右值引用仅仅是通过改变资源的所有者来避免内存的拷贝,能大幅度提高性能。
- forward 能根据参数的实际类型转发给正确的函数。
- emplace 系列函数通过直接构造对象的方式避免了内存的拷贝和移动。
- 无序容器在插入元素时不排序,提高了插入效率,不过对于自定义 key 时需要提供 hash 函数和比 较函数
相关文章:
2.右值引用和移动语义
文章目录 右值引用和移动语义&&的特性右值引用优化性能,避免深拷贝移动(move )语义forward 完美转发emplace_back 减少内存拷贝和移动unordered container 无序容器map和unordered_map的差别内部实现机理不同优缺点以及适用处 小结优缺点以及适用处 小结 代…...
深入浅出线程原理
Linux 中的线程本质 线程接口由 Native POSIX Thread Library 提供,即:NPTL 库函数 线程被称为轻量级进程 (Light Weight Process) 每一个线程在内核中都对应一个调度实体,拥有独立的结构体 (task_struct) 内核设计:一个进程对…...

openssl3.2 - 官方demo学习 - saccept.c
文章目录 openssl3.2 - 官方demo学习 - saccept.cEND openssl3.2 - 官方demo学习 - saccept.c 建立TLSServer(使用了证书, 和证书中的私钥), 接收客户端的连接, 并将客户端发来的信息打印到屏幕 笔记 /*! \file saccept.c */ /*! \brief 建立TLSServer(使用了证书, 和证书中…...
JavaScript基础(26)_dom增删改练习
<!DOCTYPE html> <html lang"zh"><head><meta charset"UTF-8"><title>DOM增删改练习</title><link rel"stylesheet" href"../browser_default_style/reset.css"><style>table {borde…...

mac上部署单体hbase
1. 简介 HBase 是一个开源的、分布式的、版本化的典型非关系型数据库。它是 Google BigTable 的开源实现,并且是 Apache 基金会的 Hadoop 项目的一部分1。HBase 在 Hadoop Distributed File System (HDFS) 上运行,作为一个列式存储非关系数据库管理系统…...

【RV1126 学习】SDK/ U-Boot/kernel/rootfs 编译学习
文章目录 RV1126芯片介绍rv1126 模块代码目录相关说明 SDK 包下的脚本使用build.sh 脚本使用envsetup.sh 脚本使用mkfirmware.sh 脚本使用rkflash.sh 脚本使用 U-Boot 编译和配置uboot 的配置修改编译操作 kernel 的修改编译rootfs 编译和配置buildroot 配置busybox 配置 RV112…...

Golang 使用 AST 获取方法和参数名以及应用举例
背景 在做一些自动生成的代码工作时,有时需要知道方法以及对应的参数名 如果仅是方法,利用反射机制就可以解决 而参数名,程序编译后,已经丢失 可以通过 AST 事先获取方法的参数名 有了方法、参数名,加上反射&…...
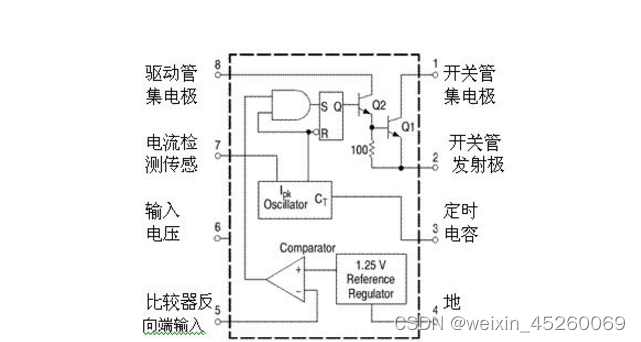
DC-DC变换集成电路芯片B34063——工作电压范围宽,静态电流小
B34063为一单片DC-DC变换集成电路,内含温度补偿的参考电压源(1.25V)、比较器、能有效限制电流及控制工作周期的振荡器,驱动器及大电流输出开关管等,外配少量元件,就能组成升压、降压及电压反转型DC-DC变换器。 主要特点: ● 工作…...
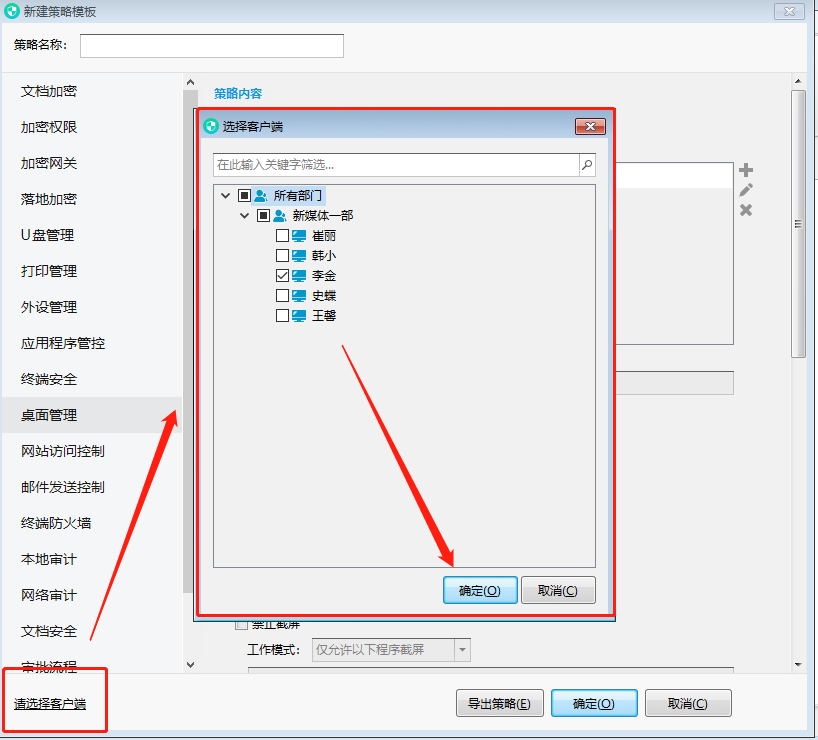
强力推荐:本地文件加密软件—超详细加密步骤来了!
在数字化时代,数据安全问题日益受到人们的关注。 为了保护个人和企业的重要信息不被泄露,越来越多的人开始使用文件加密软件。 尤其是常常会有数据泄露风险的企业更是需要一款非常给力的加密工具来保护企业数据安全。 一、选择合适的加密软件 在选择加…...

在qml中,ListModel可以与WorkerScript一起使用,从多个线程访问列表模型
在QML中,您可以使用ListModel和WorkerScript一起实现多线程访问列表模型。以下是一个简单的例子,演示了如何在QML中使用这两个元素: import QtQuick 2.15 import QtQuick.Controls 2.15ApplicationWindow {visible: truewidth: 400height: 3…...

rocketmq实现延迟消息
SpringBoot整合RocketMQ发送延时消息 springboot rocketmq 延迟消息 Windows下RocketMQ安装及可视化界面搭建 Java 客户端 RocketMQ延迟消息 项目背景 项目中有延时消息的需求,综合考量RocketMQ比较适合。 RocketMQ支持多维度的延迟级别 支持多种消息类型 基…...

vue倒计时60秒改变按钮状态效果demo(整理)
你可以使用Vue的计时器和绑定状态的方法来实现这个功能。 首先,在data中添加一个计时器countdown,初始值为0。 data() {return {countdown: 0} }<template><div><button click"startCountdown" :disabled"countdown > …...
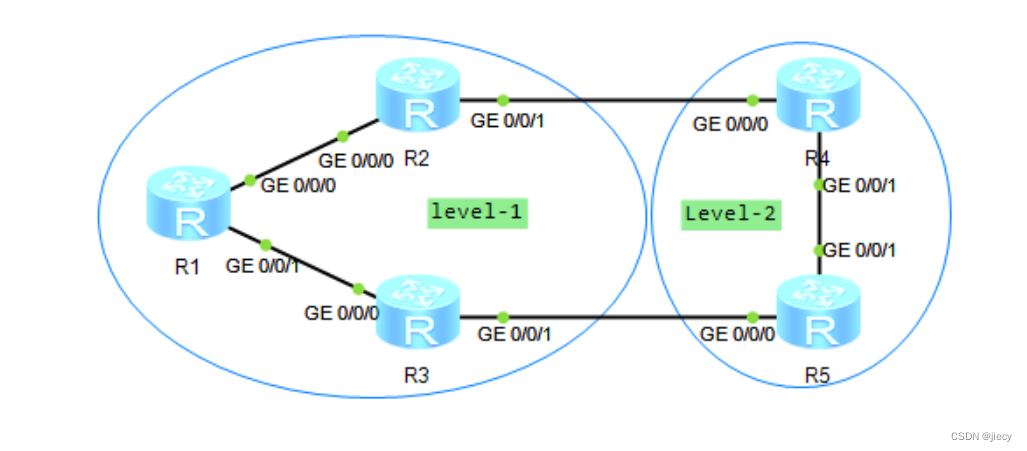
多区域isis配置实验
一、预习: IS-IS:Intermediate System to Intermediate System,中间系统到中间系统,是ISO为它的CLNP(ConnectionLess Network Protocol)设计的一种动态路由协议,后来为了提供对IP路由的支持&…...
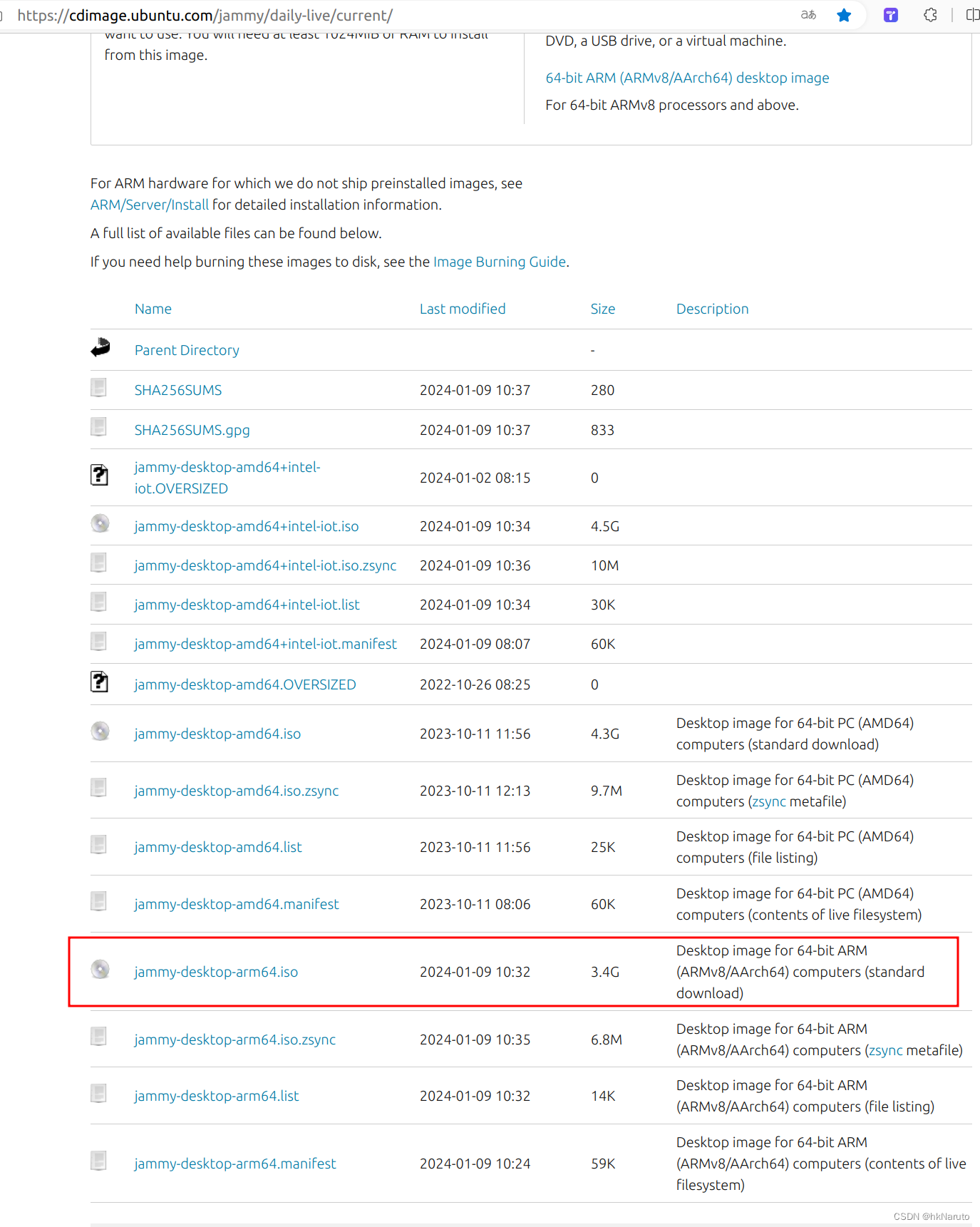
Ubuntu 22.04.3 LTS arm64 aarch64 ISO jammy-desktop-arm64.iso 下载
Ubuntu 22.04.3 LTS (Jammy Jellyfish) Daily Build 参考 Are there official Ubuntu ARM / aarch64 desktop images? - Ask Ubuntu...

软件测试面试必备知识
随着软件测试领域对于技术要求越来越清晰,到现在测试人员在市场上的岗位需求也变得越来越复杂。极大部分的企业都开始对自动化测试岗位有了更多的需要。自然而然,面试就相对于非常重要了。 网络上有着各式各样的测试框架的存在,我也不知道我…...
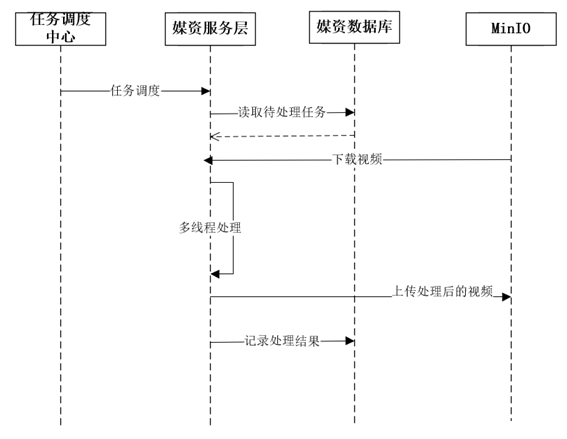
4.4 媒资管理模块 - 分布式任务处理介绍、视频处理技术方案
媒资管理模块 - 视频处理 文章目录 媒资管理模块 - 视频处理一、视频转码1.1 视频转码介绍1.2 FFmpeg 基本使用1.2.1 下载安装配置1.2.2 转码测试 1.3 工具类1.3.1 VideoUtil1.3.2 Mp4VideoUtil1.3.3 测试工具类 二、分布式任务处理2.1 分布式任务调度2.2 XXL-JOB 配置执行器 中…...
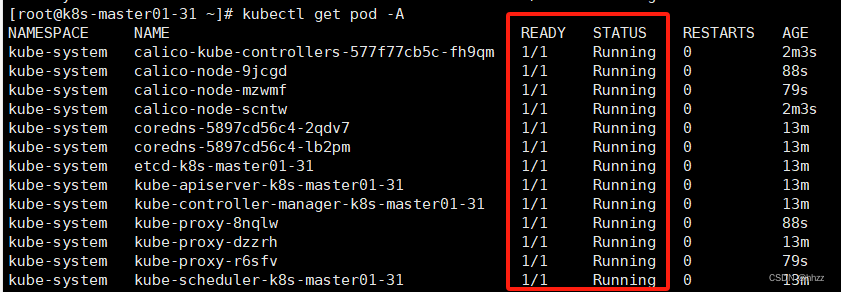
K8S集群重新初始化--详细过程
K8S集群重新初始化 0、当前环境1、master节点1.1、在master节点执行下面reset命令:1.2、手动清除配置信息,这一步很关键:1.3、重新引导集群1.4、创建配置目录,并复制权限配置文件到用户目录下:1.5 查看集群状态1.6 安装…...

服务器 Linux常见指令
删除文件 删除文件 单个删除:rm -f 文件名 rm -f 2018_12_26.stderrout.log.060121612 --执行完成即将这个文件删除删除文件夹 rm -rf 路径/目录名tar命令 压缩 tar -cvf [文件名].tar [文件目录] //打包成.tar文件 tar -jcvf [文件名].tar.bz2 [文件目录]…...

C++合并K个有序链表
本篇博客介绍如何使用C合并k个有序链表,在代码中会用到std::priority_queue,首先需要介绍一下std::priority_queue的用法,介绍完std::priority_queue后将介绍如何使用std::priority_queue来辅助合并k个有序链表。 一、C priority_queue用法介…...
win10在启动游戏时报错,提示“d3dx9_25.dll文件丢失”,怎么办?d3dx9_25.dll丢失如何自动修复
一、d3dx9_25.dll文件是什么? d3dx9_25.dll是DirectX的一部分,DirectX是一种由微软开发的专门处理与多媒体、游戏程序和视频相关的应用程序接口。d3dx9_25.dll文件是DirectX9中一个重要的dll文件,主要负责处理3D图形程序,作用是帮…...

PyTorch张量操作实战:从基础运算到高效数据处理
1. PyTorch张量基础:从零开始理解多维数组 第一次接触PyTorch张量时,我完全被这个看似复杂的概念搞懵了。直到有一天,我把张量想象成俄罗斯套娃,突然就豁然开朗了。最外层的套娃是最高维度,每打开一层就降一个维度&…...
安全迁移到Nexus 3私库?)
企业级前端基建:如何将离线npm包(tgz)安全迁移到Nexus 3私库?
企业级前端基建:如何将离线npm包(tgz)安全迁移到Nexus 3私库? 当企业面临安全合规审计或网络隔离需求时,如何将分散在各处的npm离线包(tgz格式)安全、高效地迁移至Nexus私有仓库,成为…...

Python内存管理进入“自动驾驶”时代:详解memguard-core插件的AI预测式回收机制,安装仅需3行命令
第一章:Python智能体内存管理策略Python智能体(如基于LLM的Agent、ReAct架构或Tool-Calling Agent)在运行过程中常面临对象生命周期长、中间状态缓存多、工具调用频繁导致引用残留等问题。其内存管理不能仅依赖CPython默认的引用计数与循环垃…...

PCB多层板设计:偶数层优势与奇数层解决方案
PCB多层板层数设计解析:偶数层优势与奇数层解决方案1. 多层PCB基础概念与现状PCB(Printed Circuit Board)根据层数可分为单面板、双面板和多层板。现代电子产品中,多层PCB的应用越来越广泛,其层数从4层到超过100层不等…...

原神抽卡记录导出工具:一键备份分析你的抽卡历史数据
原神抽卡记录导出工具:一键备份分析你的抽卡历史数据 【免费下载链接】genshin-wish-export biuuu/genshin-wish-export - 一个使用Electron制作的原神祈愿记录导出工具,它可以通过读取游戏日志或代理模式获取访问游戏祈愿记录API所需的authKey。 项目…...

LSM303DLHC六轴IMU硬件设计与磁场校准实战指南
1. LSM303DLHC 器件概述与工程定位LSM303DLHC 是意法半导体(STMicroelectronics)推出的一款高集成度、低功耗的六轴惯性测量单元(6-DoF IMU),由独立封装的三轴加速度计(LIS3DH 兼容架构)和三轴磁…...

U盘频繁提示“驱动器存在问题”?三步教你彻底修复并避免数据丢失
1. 为什么U盘会频繁提示“驱动器存在问题”? 每次插入U盘都弹出那个烦人的提示框,就像有个唠叨的管家在耳边不停提醒"您的U盘有问题啦!"。这种情况我遇到过太多次了,特别是在使用时间较久的U盘上。其实这个提示背后隐藏…...

SAP ABAP RFC函数外部调用Debug全攻略:从SE37设置到断点跟踪
SAP ABAP RFC函数外部调用Debug全攻略:从SE37设置到断点跟踪 在跨系统集成的复杂场景中,RFC函数调试往往让开发者头疼不已。想象一下这样的场景:你开发的RFC接口在生产环境突然报错,但本地测试一切正常;或者第三方系统…...

OptiScaler终极指南:3步解锁跨平台超分辨率技术,让所有显卡享受DLSS级画质提升
OptiScaler终极指南:3步解锁跨平台超分辨率技术,让所有显卡享受DLSS级画质提升 【免费下载链接】OptiScaler DLSS replacement for AMD/Intel/Nvidia cards with multiple upscalers (XeSS/FSR2/DLSS) 项目地址: https://gitcode.com/GitHub_Trending/…...

避坑指南:TDengine开源版taosdump备份恢复,这些性能问题和‘缺口’你得知道
TDengine开源版备份恢复实战:taosdump性能瓶颈与数据缺口深度解析 1. 当开源版遇上生产环境:taosdump的真实表现 去年夏天,我们团队在新能源监控项目中首次尝试用TDengine开源版构建时序数据库集群。当系统运行三个月后,客户突然…...