设计一个简单的规则引擎
- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:源码溯源,一探究竟
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
- 设计一个简单的规则引擎
- 问题描述
- 需求设计
- 数据库设计
- rule_tree
- rule_tree_node
- rule_tree_node_line
- rule_tree data
- rule_tree_node data
- rule_tree_node_line data
- 结构设计
- 核心代码
- 规则管理器
- 推理引擎
- 最终展示
- 测试结果
设计一个简单的规则引擎
问题描述
何为规则引擎?按照gpt的给的定义来解释下:
规则引擎是一种计算机软件或系统,用于管理和执行特定规则集合。它基于预定义的规则和逻辑,对输入数据进行处理、评估和决策。规则引擎通常由两个主要组成部分组成:规则管理器和推理引擎。
那么假如说我们需要设计一个简单的规则引擎,那么结合上述需要考虑什么呢?
比如说我们已知一个人的性别和年龄,根据这两个进行规则的判断,然后分流到不同的分支,怎么实现呢?
最简单的方式莫过于几个if,else就能结果,但是假如说后面加入了更多的规则,岂不是我们还要重新进去写代码改这个规则?
所以需要设计一个动态的规则引擎,这样当有新的规则来的时候,我们不需要很大的变动,就可以完成规则的加入。
需求设计

本质上就是要完成这样的一个规则引擎,首先通过性别进行规则判断,然后是通过年龄进行规则判断,这样一个简单的规则殷勤的雏形就设计好了。
数据库设计
一个好的规则引擎还可以用于将来的扩展,所以理论上一些值应该保存在数据库中,将来再由一套管理系统进行动态扩展即可。
那么数据库的设计是什么呢?
从上图也可以看到,这个结构是不是很像一颗二叉树,实际上的设计也是基于此,库表中其实就是将一颗二叉树抽象进去啦,那么这里就需要包括:树根、树茎、子叶、果实。在具体的逻辑实现中则需要通过子叶判断走哪个树茎以及最终筛选出一个果实来。
rule_tree
CREATE TABLE `rule_tree` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',`tree_name` varchar(64) DEFAULT NULL COMMENT '规则树NAME',`tree_desc` varchar(128) DEFAULT NULL COMMENT '规则树描述',`tree_root_node_id` bigint(20) DEFAULT NULL COMMENT '规则树根ID',`create_time` datetime DEFAULT NULL COMMENT '创建时间',`update_time` datetime DEFAULT NULL COMMENT '更新时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10002 DEFAULT CHARSET=utf8;
rule_tree_node
CREATE TABLE `rule_tree_node` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',`tree_id` int(2) DEFAULT NULL COMMENT '规则树ID',`node_type` int(2) DEFAULT NULL COMMENT '节点类型;1子叶、2果实',`node_value` varchar(32) DEFAULT NULL COMMENT '节点值[nodeType=2];果实值',`rule_key` varchar(16) DEFAULT NULL COMMENT '规则Key',`rule_desc` varchar(32) DEFAULT NULL COMMENT '规则描述',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=123 DEFAULT CHARSET=utf8;
rule_tree_node_line
CREATE TABLE `rule_tree_node_line` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',`tree_id` bigint(20) DEFAULT NULL COMMENT '规则树ID',`node_id_from` bigint(20) DEFAULT NULL COMMENT '节点From',`node_id_to` bigint(20) DEFAULT NULL COMMENT '节点To',`rule_limit_type` int(2) DEFAULT NULL COMMENT '限定类型;1:=;2:>;3:<;4:>=;5<=;6:enum[枚举范围];7:果实',`rule_limit_value` varchar(32) DEFAULT NULL COMMENT '限定值',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
以上就是表的结构,那么将上图中的结构抽象进数据库中数据应该写呢?
rule_tree data

rule_tree_node data

rule_tree_node_line data

以上就是全部的数据库设计啦,其实就是将二叉树的结构抽象进数据库中,然后为每个分支都加上逻辑判断即可,如rule_tree_node_line data 所示。
结构设计
聊完数据库设计,再回到问题描述里说的:
规则引擎是一种计算机软件或系统,用于管理和执行特定规则集合。它基于预定义的规则和逻辑,对输入数据进行处理、评估和决策。规则引擎通常由两个主要组成部分组成:规则管理器和推理引擎。
总结起来就是一句话,规则引擎分为 规则管理器 + 推理引擎。
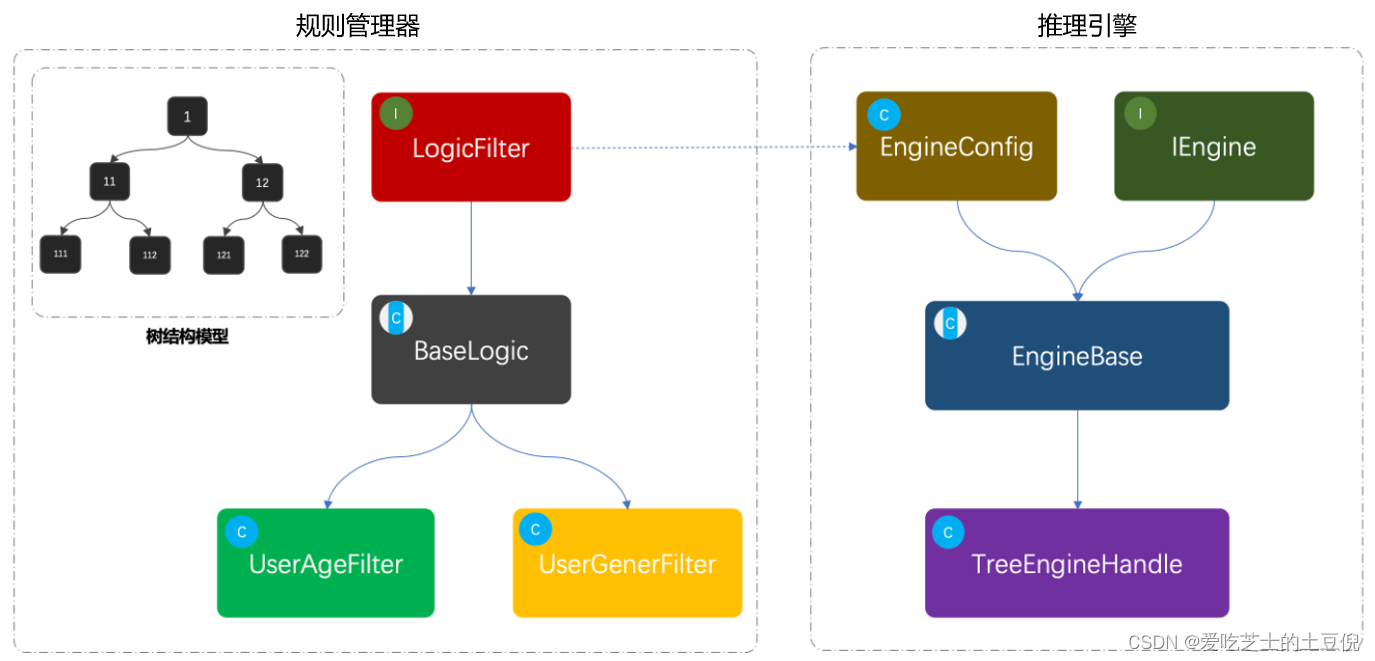
核心代码
规则管理器
// 规则过滤器接口
public interface LogicFilter {/*** 逻辑决策器* @param matterValue 决策值* @param treeNodeLineInfoList 决策节点* @return 下一个节点Id*/Long filter(String matterValue, List<TreeNodeLineVO> treeNodeLineInfoList);/*** 获取决策值** @param decisionMatter 决策物料* @return 决策值*/String matterValue(DecisionMatterReq decisionMatter);}
filter的核心就是根据当前的决策值返回下一个节点的ID
public abstract class BaseLogic implements LogicFilter {@Overridepublic Long filter(String matterValue, List<TreeNodeLineVO> treeNodeLineInfoList) {for (TreeNodeLineVO nodeLine : treeNodeLineInfoList) {if (decisionLogic(matterValue, nodeLine)) {return nodeLine.getNodeIdTo();}}return Constants.Global.TREE_NULL_NODE;}/*** 获取规则比对值* @param decisionMatter 决策物料* @return 比对值*/@Overridepublic abstract String matterValue(DecisionMatterReq decisionMatter);private boolean decisionLogic(String matterValue, TreeNodeLineVO nodeLine) {switch (nodeLine.getRuleLimitType()) {case Constants.RuleLimitType.EQUAL:return matterValue.equals(nodeLine.getRuleLimitValue());case Constants.RuleLimitType.GT:return Double.parseDouble(matterValue) > Double.parseDouble(nodeLine.getRuleLimitValue());case Constants.RuleLimitType.LT:return Double.parseDouble(matterValue) < Double.parseDouble(nodeLine.getRuleLimitValue());case Constants.RuleLimitType.GE:return Double.parseDouble(matterValue) >= Double.parseDouble(nodeLine.getRuleLimitValue());case Constants.RuleLimitType.LE:return Double.parseDouble(matterValue) <= Double.parseDouble(nodeLine.getRuleLimitValue());default:return false;}}}
以及两个对应的规则
@Component
public class UserAgeFilter extends BaseLogic {@Overridepublic String matterValue(DecisionMatterReq decisionMatter) {return decisionMatter.getValMap().get("age").toString();}}@Component
public class UserGenderFilter extends BaseLogic {@Overridepublic String matterValue(DecisionMatterReq decisionMatter) {return decisionMatter.getValMap().get("gender").toString();}}
推理引擎
// 规则过滤器引擎
public interface EngineFilter {/*** 规则过滤器接口** @param matter 规则决策物料* @return 规则决策结果*/EngineResult process(final DecisionMatterReq matter);}// 规则配置
public class EngineConfig {protected static Map<String, LogicFilter> logicFilterMap = new ConcurrentHashMap<>();@Resourceprivate UserAgeFilter userAgeFilter;@Resourceprivate UserGenderFilter userGenderFilter;@PostConstructpublic void init() {logicFilterMap.put("userAge", userAgeFilter);logicFilterMap.put("userGender", userGenderFilter);}}
public abstract class EngineBase extends EngineConfig implements EngineFilter {private Logger logger = LoggerFactory.getLogger(EngineBase.class);@Overridepublic EngineResult process(DecisionMatterReq matter) {throw new RuntimeException("未实现规则引擎服务");}protected TreeNodeVO engineDecisionMaker(TreeRuleRich treeRuleRich, DecisionMatterReq matter) {TreeRootVO treeRoot = treeRuleRich.getTreeRoot();Map<Long, TreeNodeVO> treeNodeMap = treeRuleRich.getTreeNodeMap();// 规则树根IDLong rootNodeId = treeRoot.getTreeRootNodeId();TreeNodeVO treeNodeInfo = treeNodeMap.get(rootNodeId);// 节点类型[NodeType];1子叶、2果实while (Constants.NodeType.STEM.equals(treeNodeInfo.getNodeType())) {String ruleKey = treeNodeInfo.getRuleKey();LogicFilter logicFilter = logicFilterMap.get(ruleKey);String matterValue = logicFilter.matterValue(matter);Long nextNode = logicFilter.filter(matterValue, treeNodeInfo.getTreeNodeLineInfoList());treeNodeInfo = treeNodeMap.get(nextNode);logger.info("决策树引擎=>{} userId:{} treeId:{} treeNode:{} ruleKey:{} matterValue:{}",treeRoot.getTreeName(), matter.getUserId(), matter.getTreeId(), treeNodeInfo.getTreeNodeId(),ruleKey, matterValue);}return treeNodeInfo;}}
上述这段代码也是真正的推理引擎的代码,来解读一下,首先获取到这课规则树,然后遍历这颗规则树,遍历的时候根据对应节点的规则key,从规则管理器中找到对应的规则,然后执行规则,获取到下一个即将要执行的规则,然后在while循环中遍历,并且将每一次找到的规则打印即可。
@Service("ruleEngineHandle")
public class RuleEngineHandle extends EngineBase {@Resourceprivate IRuleRepository ruleRepository;@Overridepublic EngineResult process(DecisionMatterReq matter) {// 决策规则树TreeRuleRich treeRuleRich = ruleRepository.queryTreeRuleRich(matter.getTreeId());if (null == treeRuleRich) {throw new RuntimeException("Tree Rule is null!");}// 决策节点TreeNodeVO treeNodeInfo = engineDecisionMaker(treeRuleRich, matter);// 决策结果return new EngineResult(matter.getUserId(), treeNodeInfo.getTreeId(), treeNodeInfo.getTreeNodeId(), treeNodeInfo.getNodeValue());}}
最终展示
@RunWith(SpringRunner.class)
@SpringBootTest
public class RuleTest {private Logger logger = LoggerFactory.getLogger(ActivityTest.class);@Resourceprivate EngineFilter engineFilter;@Testpublic void test_process() {DecisionMatterReq req = new DecisionMatterReq();req.setTreeId(2110081902L);req.setUserId("nhs");req.setValMap(new HashMap<String, Object>() {{put("gender", "man");put("age", "25");}});EngineResult res = engineFilter.process(req);logger.info("请求参数:{}", JSON.toJSONString(req));logger.info("测试结果:{}", JSON.toJSONString(res));}}
测试结果
09:30:58.874 INFO 53959 --- [ main] c.i.l.d.rule.service.engine.EngineBase : 决策树引擎=>抽奖活动规则树 userId:fustack treeId:2110081902 treeNode:11 ruleKey:userGender matterValue:man
09:30:58.874 INFO 53959 --- [ main] c.i.l.d.rule.service.engine.EngineBase : 决策树引擎=>抽奖活动规则树 userId:fustack treeId:2110081902 treeNode:112 ruleKey:userAge matterValue:25
09:30:59.349 INFO 53959 --- [ main] c.i.lottery.test.domain.ActivityTest : 请求参数:{"treeId":2110081902,"userId":"fustack","valMap":{"gender":"man","age":"25"}}
09:30:59.355 INFO 53959 --- [ main] c.i.lottery.test.domain.ActivityTest : 测试结果:{"nodeId":112,"nodeValue":"100002","success":true,"treeId":2110081902,"userId":"nhs"}
相关文章:
设计一个简单的规则引擎
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术🔥如果感觉博主的文章还不错的…...

openssl3.2 - 官方demo学习 - digest - EVP_MD_stdin.c
文章目录 openssl3.2 - 官方demo学习 - digest - EVP_MD_stdin.c概述笔记END openssl3.2 - 官方demo学习 - digest - EVP_MD_stdin.c 概述 使用 SHA3-512 对stdin输入做摘要, 并输出摘要值. 笔记 /*! \file EVP_MD_stdin.c \note openssl3.2 - 官方demo学习 - digest - EVP…...

浅谈 Raft 分布式一致性协议|图解 Raft
前言 大家好,这里是白泽。本文是一年多前参加字节训练营针对 Raft 自我整理的笔记。 本篇文章将模拟一个KV数据读写服务,从提供单一节点读写服务,到结合分布式一致性协议(Raft)后,逐步扩展为一个分布式的…...

4_【Linux版】重装数据库问题处理记录
1、卸载已安装的oracle数据库。 2、知识点补充: 3、调整/dev/shm/的大小 【linux下修改/dev/shm tmpfs文件系统大小 - saratearing - 博客园 (cnblogs.com)】 mount -o remount,size100g /dev/shm 4、重装oracle后没有orainstRoot.sh 【重装oracle后没有orains…...
隧道应用2-netsh端口转发监听Meterpreter
流程介绍: 跳板机 A 和目标靶机 B 是可以互相访问到的,在服务器 A 上可以通过配置 netsh 端口映射访问 B 服务器。如果要拿 B 服务器的权限通常是生成正向后门,使用 kali 的 msf 正向连接B服务器,进而得到 Meterpreter,…...

《Spring》--使用application.yml特性提供多环境开发解决方案/开发/测试/线上--方案1
阿丹有话说: 有不少同志有疑问说我正常开发的时候,需要自己搭建项目的时候。总是出现配置文件环境切换出现问题。多环境系列会出两个文章解决给搭建重点解决一下这个问题。给与两种解决的方案。正确让大家只需要按照步骤操作就可以完成。 原理…...

统计项目5000+,出具报表5分钟......捷顺科技数据中台怎么做?
捷顺创立于1992年,以智慧车行、人行出入口软硬件产品为依托,致力于智慧停车生态建设和运营,是出入口智能管理和智慧生态环境建设的开创者和引领者。 历经近三十年的发展,已经成为国内智慧停车领域的领军企业。公司集研、产、销一…...

力扣(105. 从前序与中序遍历序列构造二叉树,106. 从中序与后序遍历序列构造二叉树)
题目1链接 题目1: 思路:使用前序确定根,使用中序分左右子树,分治法。 难点:如何控制递归确定左右子树。 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* T…...
网络安全技术新手入门:在docker上安装dvwa靶场
前言 准备工作:1.已经安装好kali linux 步骤总览:1.安装好docker 2.拖取镜像,安装dvwa 一、安装docker 输入命令:sudo su 输入命令:curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key …...
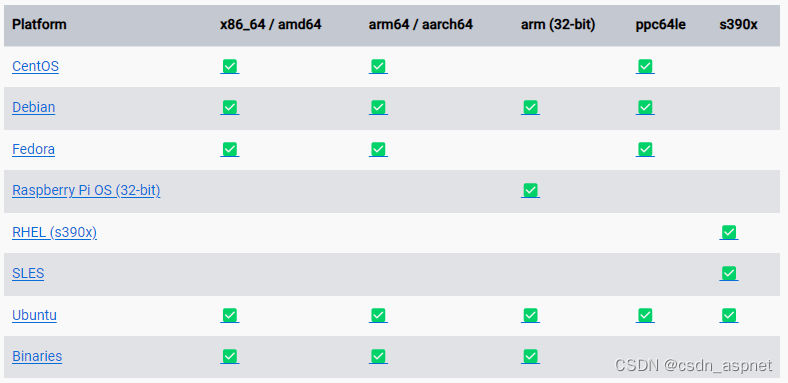
Docker 介绍 及 支持的操作系统
Docker组成: Docker主机(Host): 一个物理机或虚拟机, 用于运行Docker服务进程和容器, 也成为宿主机, node节点。 Docker服务器端(Server): Docker守护进程, 运行Docker容器。 Docker客户端(Client): 客户端使用docker命令或其他工…...

大模型实战营Day5 LMDeploy大模型量化部署实践
模型部署 定义 产品形态 计算设备 大模型特点 内存开销大 动态shape 结构简单 部署挑战 设备存储 推理速度 服务质量 部署方案:技术点 (模型并行 transformer计算和访存优化 低比特量化 Continuous Batch Page Attention)方案(…...
py连接sqlserver数据库报错问题处理。20009
报错 pymssql模块连接sqlserver出现如下错误: pymssql._pymssql.OperationalError) (20009, bDB-Lib error message 20009, severity 9:\nUnable to connect: Adaptive Server is unavailable or does not exist (passwordlocalhost)\n) 解决办法: 打…...

LTESniffer:一款功能强大的LTE上下行链路安全监控工具
关于LTESniffer LTESniffer是一款功能强大的LTE上下行链路安全监控工具,该工具是一款针对LTE的安全开源工具。 该工具首先可以解码物理下行控制信道(PDCCH)并获取所有活动用户的下行链路控制信息(DCI)和无线网络临时…...
SQL语句详解二-DDL(数据定义语言)
文章目录 操作数据库创建:Create查询:Retrieve修改:Update删除:Delete使用数据库 操作表常见的几种数据类型创建:Create复制表 查询:Retrieve修改:Update删除:Delete 操作数据库 创…...
web前端算法简介之链表
链表 链表 VS 数组链表类型链表基本操作 创建链表:插入操作:删除操作:查找操作:显示/打印链表:反转链表:合并两个有序链表:链表基本操作示例 JavaScript中,instanceof环形链表 判断…...

C++函数对象
任何定义了函数调用操作符的对象都是函数对象。C 支持创建、操作新的函数对象,同时也提供了许多内置的函数对象。 函数包装器 std::function 提供存储任意类型函数对象的支持。 function (C11) 包装具有指定函数调用签名的任意类型的可调用对象 (类模板) bad_funct…...

插件化简单介绍
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。 未经允许不得转载 目录 一、导读二、概览三、常见的插件化方案…...
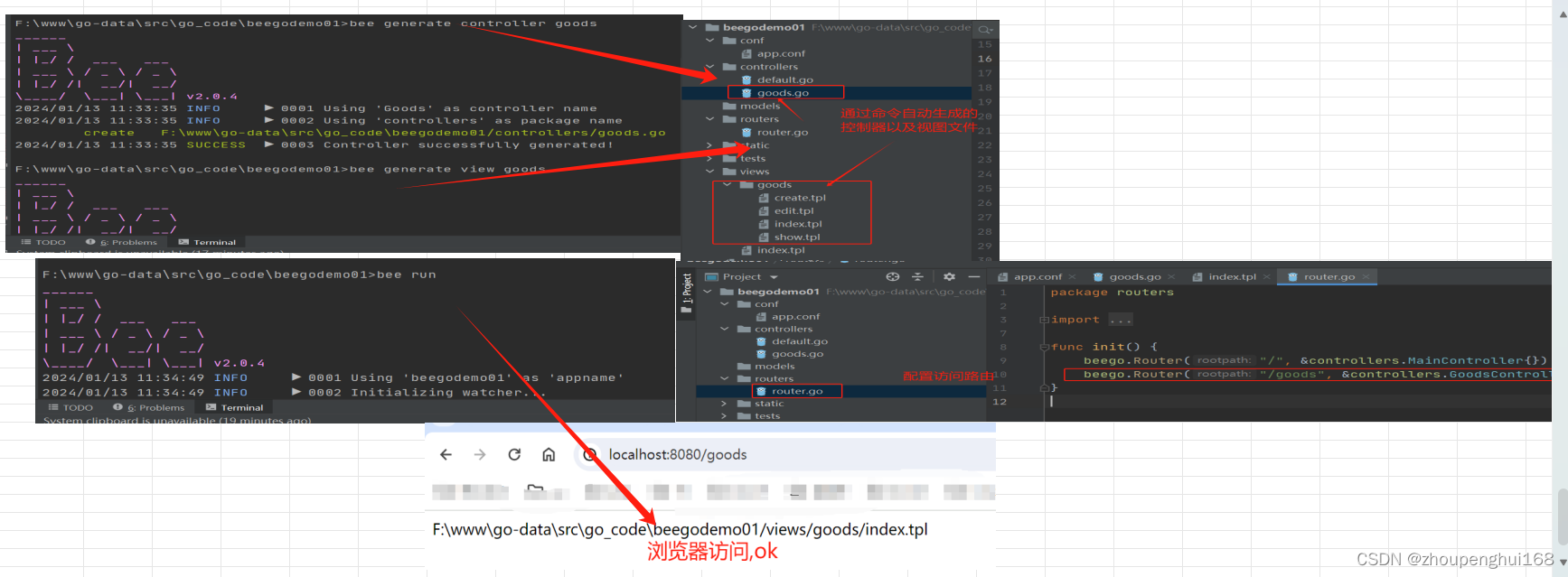
[Beego]1.Beego简介以及beego环境搭建,bee脚手架的使用,创建,运行项目
一.Beego介绍 Beego是一个开源的基于Golang的MVC框架,主要用于Golang Web开发,Beego可以用来快速开发API、Web、后端服务等各种应用。 Golang 的Web开发框架有很多,从 github star 数量来看Gin>Beego>lris>Echo>Revel>Buffalo 目前国内用的比较多的就…...
)
Tomcat 静态资源访问与项目根路径设置(AI问答)
一个静态文件,放在Tomcat中,希望能够通过网络访问,应该放在哪里? 在Apache Tomcat中,如果想要部署静态文件(例如HTML、CSS、JavaScript、图片等)并能通过网络访问,通常需要将这些文…...

Docker实战09|使用AUFS包装busybox
前几篇文章中,重点讲解了如何实现构建容器,需要回顾的小伙伴可以看以下文章: 《Docker实战06|深入剖析Docker Run命令》《Docker实战07|Docker增加容器资源限制》《Docker实战08|Docker管道及环境变量识别…...
深度探秘:以一次文件打开操作为例)
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例 当我们在终端输入cat /etc/shadow时,系统背后究竟发生了什么?这个看似简单的操作,实际上触发了一系列精妙的安全检查机制。本文将带您深入Linux内…...

AI Agent变现难题与破局之道:小白程序员必备收藏,2026年蓝海掘金指南!
文章深入分析了当前AI Agent行业的冰火两重天现象,揭示了技术不成熟、伪需求泛滥、基础设施不完善等六大核心底层逻辑导致变现困难。同时,文章指出了电商全链路、企业办公自动化、本地生活商家、开发者垂直、垂类定制化等五大变现蓝海赛道,并…...

2025届毕业生推荐的六大AI学术助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于内容创作进程里,要减低AI生成文本的可检测比率,得从语义、结构以及…...
)
NotebookLM实战指南(NLP任务辅助黄金公式首次公开)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM实战指南(NLP任务辅助黄金公式首次公开) NotebookLM 是 Google 推出的基于可信来源驱动的 AI 助手,专为研究者与工程师设计,其核心能力在于“…...

CodeMaker完整指南:5分钟掌握IntelliJ IDEA智能代码生成插件
CodeMaker完整指南:5分钟掌握IntelliJ IDEA智能代码生成插件 【免费下载链接】CodeMaker A idea-plugin for Java/Scala, support custom code template. 项目地址: https://gitcode.com/gh_mirrors/co/CodeMaker 还在为Java和Scala项目中的重复编码工作而烦…...

Book118文档下载器:3步免费获取完整PDF文档的终极指南
Book118文档下载器:3步免费获取完整PDF文档的终极指南 【免费下载链接】book118-downloader 基于java的book118文档下载器 项目地址: https://gitcode.com/gh_mirrors/bo/book118-downloader 你是否曾在Book118网站上找到急需的学习资料,却发现需…...

Flutter从入门到实战-02-Flutter框架核心
Flutter 从入门到实战(二):Flutter 框架核心本文根据讲义目标是把“会搭环境、会写页面、会管理状态与路由、会做基础网络请求”串成一条完整上手路径。一、先把开发环境一次搭对 这部分讲义强调的核心思想是:环境问题越早解决&am…...

PyQt6 GUI开发实战:构建现代化桌面应用的架构设计指南
PyQt6 GUI开发实战:构建现代化桌面应用的架构设计指南 【免费下载链接】PyQt-Chinese-tutorial PyQt6中文教程 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Chinese-tutorial 在当今软件开发领域,桌面应用依然占据着重要地位,特…...

多波束声呐接收机与信号处理算法【附程序】
✨ 长期致力于多通道声呐接收机、电路设计、FPGA、数字信号处理、波束形成研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)小型化96通道接收机硬件电路…...

PaddleOCR迁移学习踩坑记:从数字识别到模型过拟合,我的2万张图白训了?
PaddleOCR迁移学习实战避坑指南:从数字识别到模型优化的深度复盘 在OCR技术应用日益广泛的今天,迁移学习成为快速实现特定场景文字识别的有效手段。然而在实际操作中,许多开发者(包括笔者本人)都曾陷入"伪迁移学…...