S1-08 流和消息缓冲区
流缓冲区
流缓冲区一般用在不同设备或者不同进程间的通讯,为了提高数据处理效率和性能,设置的一定大小的缓冲区,流缓冲区可以用来存储程序中需要处理的数据、对象、报文等信息,使程序对可以对这些信息进行预处理、排序、过滤、拆分等操作,从而提供程序的效率和处理速度。
流缓冲区主要应用于数据输入输出(I/O)操作中,例如读取和写入文件、网络通信等场景。在数据读取方面,缓冲区可以让程序一次读取较大量的数据,而不是多次读取小量数据,在提高读取效率的同时减少了系统调用的次数和内存访问的延迟。在数据写入方面,通过缓冲区将一部分或全部数据暂存于缓冲中,当缓冲区满或达到一定容量时再一次性写入磁盘或网络,从而减少了磁盘或网络的访问次数,提高了写入效率。
除了提高数据处理速度和性能外,流缓冲区还可以用于降低程序对内存的使用。对于大型数据集或需要大量计算的场景,使用流缓冲区可以有效地减少内存分配和释放的开销,提高程序的稳定性和运行效率。
总的来说,流缓冲区是程序中重要的优化手段之一,它可以提高程序执行效率和性能,降低内存使用,同时也是许多应用和系统的核心部分。
环形缓冲区
其实在FreeRTOS中,流缓冲区是使用环形缓冲区(Ring buffer,或者叫圆形队列,Circular queue)来实现的。
具体来说,环形缓冲区由两个指针来控制读写操作:头指针和尾指针。头指针指向缓冲区中当前的读取位置,尾指针则指向缓冲区中当前的写入位置。当读取一个数据时,头指针将向前移动一步;当写入一个数据时,尾指针将向前移动一步。当头指针和尾指针重叠时,则说明缓冲区已经满了;当头指针和尾指针完全相同时,则说明缓冲区为空。
通过使用环形缓冲区,FreeRTOS 可以高效地处理流数据,并确保数据的读取和写入操作不会越界或冲突。此外,环形缓冲区还可以避免在缓冲区操作过程中出现复制或移动操作,从而提高数据传输的速度和性能。
总的来说,FreeRTOS 中的流缓冲区使用环形缓冲区实现,既可以提高数据传输效率,又可以确保数据的安全性和稳定性。

流缓冲区和消息队列的不同点
在之前学到的消息队列中,队列有个长度,表示队列中可以存储多少个信息,每个信息又有一个固定的长度。
这种设计在寸土寸金的单片机中是非常浪费的,而且这种设计对非格式化数据的存储非常不友好。
比如我们从网络下载音乐,然后在本地解码播放,这个过程中,每次下载多少个字节的数据是不可预知的,网络快的时候每次下载的数据量会多一些,可能一次1k字节,当网络状态不好的时候每次下载会少一些,比如10字节,那对于每次如此悬殊的数据量,再用消息队列的话就非常浪费,不管我们给队列分配10字节的大小,还是1k字节的大小,似乎都无法满足我们的需求。
所以缓冲区的概念就诞生了:
比如我们要用水烧饭,人少的时候每次我们只用半桶水,人多的时候一次可能要用3~5桶水,如果每次烧饭的时候都去河边打水就显得很麻烦,而且每次多打的水就会浪费掉。
于是我们做了一个可以装10桶的大水缸作为缓冲区,等没事的时候我们就去河边挑水倒到水缸中,每次做饭的时候就从水缸中取得一定量的水使用,这样就解决了打水不即时和浪费的问题。
在程序中,我们在内存中定义一块区域当这个水缸(缓冲区),下载器从网上下载MP3数据后有顺序的将数据放入到这块区域中,当数据被存满的时候就暂停不再下载;而MP3播放器每次取一定量的数据进行解码播放,取出后对应的空间被空出来,让下载器继续下载。
代码共享位置:https://wokwi.com/projects/362958849739503617
#include <freertos/stream_buffer.h>
/********************************* 一些公共函数,不用管 ***********************************/
#define BUZZER_PIN 4 // 蜂鸣器的引脚
#define BUZZER_CHANNEL 0 // PWM通道
/*** @brief 音频解码算法* 对输入的字符串进行音频解码,并通过PWM控制蜂鸣器播放* @param[in] music 音频字符串,格式为 音符,八度,间隔时间;下一个音符,* @怕扰民[in] size 长度*/
static void decode(char *notes, size_t size) {ledcAttachPin(BUZZER_PIN, BUZZER_CHANNEL); // 初始化PWM,指定使用引脚和PWM通道size_t len = size/3;for(int i=0; i<len; i++){int note = notes[i*3];int octave = notes[i*3+1];int rest = notes[i*3+2]*5;ledcWriteNote(BUZZER_CHANNEL, (note_t)note, octave);vTaskDelay(rest);}ledcDetachPin(BUZZER_PIN);
}
/*** @brief 随机生成音符* param[out] notes 音符序列* @return 返回字符串长度*/
static size_t randomMusic(char **notes) {uint8_t len = random(1, 21); // 生成1~20 组音符,每组有3位char *p =(char *)pvPortMalloc(sizeof(char)*len*3); // 动态分配内存// 随机生成数据,第一个字节数据是0~12,第二个是5~9,第三个是20~200的5倍for(int i=0; i<len; i++){p[i*3] = random(0,13);p[i*3+1] = random(5,10);p[i*3+2] = random(20,200);}*notes = p;return len*3;
}
/*** @brief 测试用打印音乐* @param[in] notes 音乐数据序列* @param[in] size 音乐长度,3个一组打印**/
static void printMusic(char *notes, size_t size){// taskENTER_CRITICAL();printf("[");for(int i=0; i<size; i++){if(i % 3 ==0){printf(" ");}printf("%d,", notes[i]);}printf("]\n");// taskEXIT_CRITICAL();
}
/********************************* 留缓冲区例程 ***********************************/
#define BUFFER_SIZE 600 // 留缓冲区大小
#define TRIGGER_LEVEL 3 // 最小读出单位
#define READ_SIZE 90 // 最大读出宽度
StreamBufferHandle_t xStreamMusic = NULL; // 声明一个流缓冲区指针
uint16_t read_counter=0, write_counter=0; // 读出和写入次数计数器,纯计数没卵用
// 模拟下载线程
void download_task(void* param_t){printf("[DOWN] 下载器启动...\n");char *music= NULL; // 下载待写入的数据size_t music_size; // 随机生成的音乐大小size_t size; // 存放实际写入数据的大小while(1){// 模拟从网上下载随机长度的音乐music_size = randomMusic(&music);printf("[DOWN] 随机生成音乐长度: %d \n", music_size);// printMusic(music, music_size);// 并写入到流缓冲区中,并返回实际写入的数据长度size = xStreamBufferSend(xStreamMusic, // 缓冲区句柄(void *)music, // 要写入的数据music_size, // 写入的数据大小portMAX_DELAY); // 当缓冲区满后的等待时间vPortFree(music);if(size != music_size){// 如果实际写入的大小与音乐本身大小不一致,说明缓冲区写入满了,无法再继续写入printf("[DOWN] 音乐写入失败,缓冲区已满!%d - %d\n",size, music_size);}else{printf("[DOWN] 第 %d 次写入,大小 %d\n", ++write_counter, size);}vTaskDelay(pdMS_TO_TICKS(random(100,500)));}
}
// 模拟播放线程
void paly_task(void* param_t){printf("[PLAY] 播放器启动...\n");size_t size; // 存放实际读出数据的大小char music[READ_SIZE]; // 读出数据的存放位置while(1){printf("[PLAY] 准备读取音乐\n");size = xStreamBufferReceive(xStreamMusic, // 流缓冲区指针(void *)music, // 读出数据的存放变量指针READ_SIZE, // 预读出大小portMAX_DELAY); // 等待时间if(size>0){// 解码播放音乐printf("[PLAY] 第 %d 次读出,大小 %d\n", ++read_counter, size);// printMusic(music, size);decode(music, size);printf("[PLAY] 第 %d 段播放完毕!\n",read_counter);}}
}
// 数据监控线程
void monitor_task(void* param_t){while(1){if (xStreamBufferIsFull(xStreamMusic) == pdTRUE){printf("[MONI] 缓冲区已满!\n");}else{printf("[MONI] 已用 : %d , 剩余 : %d\n", xStreamBufferBytesAvailable(xStreamMusic),xStreamBufferSpacesAvailable(xStreamMusic));}vTaskDelay(1000);}
}
void setup() {Serial.begin(115200);Serial.println("Hello, ESP32-S3!");pinMode(BUZZER_PIN, OUTPUT);ledcSetup(0, 5000, 16); // 初始化PWMxStreamMusic = xStreamBufferCreate(BUFFER_SIZE, TRIGGER_LEVEL);if ( xStreamMusic == NULL ){printf("流缓冲区初始化失败,请检查内存是否够用!\n");}// // 创建线程xTaskCreate(download_task, "Downloader", 10240, NULL, 1, NULL);xTaskCreate(monitor_task, "Monitor", 10240, NULL, 1, NULL);xTaskCreate(paly_task, "Player", 10240, NULL, 1, NULL);
}
void loop() {delay(10);
}
例程代码中一共三个线程,download_task 用于模拟数据下载,paly_task 模拟播放器让蜂鸣器发声,monitor_task 则用于数据监控。
代码中 decode 和 randomMusic 两个方法我们完全不用关心他是如何实现的,与本例程无关。
在 setup 函数中,首先通过 xStreamBufferCreate 方式创建了一个指定大小的数据缓冲区,该函数包含有两个参数,第一个表示该缓冲区的实际大小,单位是字节,第二个表示最小的读出大小,也就是说缓冲区中必须包含 TRIGGER_LEVEL 个字节后才允许读取,另外该函数还有个变形 xStreamBufferCreateWithCallback ,改变形中包含四个参数,前两个和 xStreamBufferCreate 参数一直,后两个参数分别需要传入两个函数指针,表示数据发送完和数据接收完的回调(具体请文档)。
当缓冲区创建成功后会返回这个缓冲区的句柄,如果返回NULL则表示创建失败,这时候需要检查内存是否够用。
download_task 任务模拟了从网上下载数据,首先使用 randomMusic 函数随机创建了一些音符播放数据,然后通过xStreamBufferSend 函数将数据发送到缓冲区中,该函数原型如下:
size_t xStreamBufferSend( StreamBufferHandle_t xStreamBuffer,const void *pvTxData,size_t xDataLengthBytes,TickType_t xTicksToWait );
xStreamBuffer:缓冲区句柄;
pvTxData:一个指向缓冲区的指针, 该缓冲区用于保存要复制到流缓冲区的字节
xDataLengthBytes:本次要发送的数据大小,单位为字节
xTicksToWait:超时等待时间,当流缓冲区的空间太小, 无法 容纳 另一个 xDataLengthBytes 的字节时,任务应保持在阻塞状态,以等待流缓冲区中出现足够空间的最长时间。
该函数会返回一个size_t的数据,表示实际发送到数据缓冲区中的数据量,如果发现返回值和xDataLengthBytes不一致时,则有可能是pvTxData 指向数据所产生的问题,因为如果缓冲区剩余空间不足的时候,Send函数会等待;还有一种可能就是数据发送等待超时引起。
有兴趣的同学可以修改https://wokwi.com/projects/362983694485624833
在该函数调用时,如果 pvTxData 所指向的数据长度大于 xDataLengthBytes ,则只会发送 xDataLengthBytes 个字节的数据,之后的数据降不发送。
在编写此例程的时候最初用的是String类型数据,后来测试发现问题频出,还没来得及解决,所以就改成了char型数据收发。
但随之产生一系列修改,比如在动态分配空间时,C语言中使用malloc分配,使用free释放,但是在FreeRTOS中存在内存管理单元,所以需要特有的函数 pvPortMalloc 来分配内存空间,使用 vPortFree 释放存储空间,如果仍然使用malloc和freee进行操作,一定几率上会出现问题(取决于内存管理单元的配置项)。
在 paly_task 中模拟了从数据缓冲区中读取数据并播放的流程,我们预设每次最多读取 READ_SIZE 个字节的数据,所以首先晟敏一个 READ_SIZE 大小的char数组作为通用接收器,通过 xStreamBufferReceive 函数等待接收数据,该函数原型如下:
size_t xStreamBufferReceive( StreamBufferHandle_t xStreamBuffer,void *pvRxData,size_t xBufferLengthBytes,TickType_t xTicksToWait );
xStreamBuffer:缓冲区句柄;
pvTxData:指向缓冲区的指针,接收的字节将被复制到该缓冲区
xDataLengthBytes:这会设置一次调用中 接收的最大字节数。 xStreamBufferReceive 将返回尽可能多的字节数, 直到达到由 xBufferLengthBytes 设置的最大字节数为止。
xTicksToWait:超时等待时间,当流缓冲区的空间太小, 无法 容纳 另一个 xDataLengthBytes 的字节时,任务应保持在阻塞状态,以等待流缓冲区中出现足够空间的最长时间。
该函数返回 size_t表示实际读出数据大小,改大小有可能小于 xDataLengthBytes。
该函数如果在读取的时候,缓冲区内不足 TRIGGER_LEVEL 个数据(创建缓冲区时候设置的数据),则会等待,一旦大于或等于该数值是,数据被读出。
在缓冲区内数据足够的情况下,如果 pvRxData 长度大于 xBufferLengthBytes ,则只会读出 xBufferLengthBytes 个字节的数据,但如果 pvRxData 长度小于 xBufferLengthBytes 时,读出有可能会因为数据溢出而报错,所以在定义 pvRxData 大小是,一定要考虑大于等于 xBufferLengthBytes。
当缓冲区内数据长度小于 xBufferLengthBytes 时,只会读取剩余所有的数据,此时返回值比 xBufferLengthBytes 小。
为了确保数据正常,在读取前还可以调用 xMessageBufferNextLengthBytes 函数来查看缓冲区内下次可以读出多少个字节的数据。
monitor_task 是一个数据监控程序,每间隔一段时间就输出缓冲区的已用空间大小和可用空间大小,分别使用 xStreamBufferBytesAvailable 和 xStreamBufferSpacesAvailable 获取,或使用 xStreamBufferIsFull 查看缓冲区是否已经满了,但这个函数需要注意,当使用Send函数向缓冲区发送数据时,发送数据的大小大于缓冲区剩余空间大小时,Send会等待并不会发送,但其实此时缓冲区中扔剩余空间,调用 xStreamBufferIsFull 返回也是false。
流缓冲区一般用在一对一的数据传输中,很少使用多对一、一对多和多对多,因为数据并非格式化的,有前后顺序,多对一容易造成写入数据混乱,一对多容易造成读取数据混乱。
关于流缓冲区的所有API,可以参考:https://www.freertos.org/zh-cn-cmn-s/RTOS-stream-buffer-API.html
消息缓冲区
在 FreeRTOS 中,消息缓冲区(Message buffer)是一种用于任务间通信的机制。它可以让任务之间传递各种类型的数据,例如整数、浮点数、字符、结构体等等。消息缓冲区是由一块预定义大小的内存缓冲区和一些管理该缓冲区的数据结构组成。
在流缓冲区中,每次放入消息的大小和读出的大小是可以不一致的,因为要存储和传递的内容是非结构化的数据,更像是水流,所以在存入和读取的时候只需要关注顺序,不需要关注大小。
在大多时候的数据通讯中,我们都采用非固定长度的结构化数据进行传说,也就是报文,或者数据包的模式,在这种数据传说中,每次存入的数据大小是不同的 ,但读取是会根据存入的大小进行读取。
所以消息缓冲区在流缓冲区的基础上,每次发送数据的时候在之前加入了4个字节的内容,表示要传输数据的大小,之后才是真正的消息。每次读取的时候总是先读取这四个字节,当缓冲区中在这4个字节之后存在一个与四字节表达长度一致的消息时,才会可以读取。
数据包
在互联网数据传输中,我们一般收发指令都采用标准格式的数据包,即数据传输协议,每个软件都有自己的数据传输协议,以本例程用到的数据规范,定义协议如下:
- 协议包含包头和包体两部分
- 包头的长度固定8字节,包体长度做大255个字节
- 包头前三个字节表示一个正确包的开始,依次是 0x55 0xAA 0x89
- 包头第四个字节表示数据包的类型
- 包头第五个字节为包体的大小
- 根据ESP32数据规范,数据包要求4字节对齐,不足部分在最后使用char数组补齐
在数据传输过程中,我们每一帧的数据都是以8字节的包头开始,后面跟一组不定长的数据,数据长度存放在包头第四个字节中。
场景
在智慧农业中经常会用到温度、湿度、光照、二氧化的浓度等等数据,以此需求为例,本次例程我们将完成一个集合温度、湿度、光照三项数据采集的设备,其中温湿度采集设备位DHT22,可同时采集温度和湿度两路数据,LDR采集光照度。当传感器采集设备后,通过数据包的方式发送到处理器中,假设传感器和处理器都是网络中的两台设备(本次例程中使用两个任务模拟网络上的两台设备),两个传感器采集数据后封装标准的数据包,并发送到消息缓冲区中,DHT22传感器采集的是温度和湿度两种数据,都是float类型的(每个占4字节),而LDR采集器最后传说的是一个float数据,所以两个数据包的长度是不想同的。在读取阶段,消息缓冲区会自动识别包长度进行读取。
本例程传输的数据结构只有两个,比较简单,理论上可以不加包头,直接用长度确定数据类型,但为了对数据报文结构明确演示,我们将采用完整的方式编程。
注意:在数据包的定义中,尽可能的根据需要传输的协议简化包结构,尽可能的少传输数据,这样才能提升效率。
代码共享位置:https://wokwi.com/projects/363029703756578817
#include <freertos/message_buffer.h>
#include "DHTesp.h"
#define DHT_PIN 15
#define LDR_PIN 5
#define BUFFER_SIZE 512 // 缓冲区大小
#define PH {0X55, 0XAA, 0X89} // 包头固定字符串
const char HEAD[3]=PH;
typedef struct{ // 数据包结构体char head[3]; // 数据表其实标志(包头,包花)uint8_t data_type; // 数据包类型uint8_t data_length; // 数据包包体长度char reserve[3]; // 无实际用途,用于数据对齐
}Package_Head;
typedef struct{ // DHP22 数据结构体Package_Head head; // 包头float temperature; // 温度float humidity; // 湿度
}DHT22_Package;
typedef struct{ // LDR 数据结构体Package_Head head; // 包头float lux; // 光照度
}LDR_Package;
MessageBufferHandle_t xMessageBuffer = NULL; // 消息缓冲区句柄
// 温湿度传感器数据获取线程
void dht22_task(void* param_t){DHTesp dhtSensor;dhtSensor.setup(DHT_PIN, DHTesp::DHT22);size_t psize = sizeof(DHT22_Package); // 数据包大小Package_Head head = {PH, 1, psize- sizeof(Package_Head)};DHT22_Package pck = {head, 0, 0};size_t size;while(1){TempAndHumidity data = dhtSensor.getTempAndHumidity();// 灌装数据pck.temperature = data.temperature;pck.humidity = data.humidity;size = xMessageBufferSend(xMessageBuffer, // 消息缓冲句柄(void*)&pck, // 传输的消息体首地址指针psize, // 本次传输的数据大小portMAX_DELAY); // 传输等待超时时间if(size != psize){printf("[DHTP] 数据发送失败,可能造成数据不完整的混乱\n");}else{// printf("[DHTP] 数据发送成功,大小 : %d\n",size);}vTaskDelay(random(1000,3000));}
}
// 光照度传感器数据获取线程
void ldr_task(void* param_t){const float GAMMA = 0.7;const float RL10 = 50;size_t psize = sizeof(LDR_Package); // 数据包大小Package_Head head = {PH, 2, psize- sizeof(Package_Head)};LDR_Package pck = {head, 0};size_t size;while(1){int analogValue = analogRead(LDR_PIN); // 读取引脚的模拟量// 一下是一顿猛如虎的操作,具体做了些什么请参照LDR的文档,8191是精度,表示13位精度float voltage = analogValue / 8191. * 5;float resistance = 2000 * voltage / (1 - voltage / 5);float lux = pow(RL10 * 1e3 * pow(10, GAMMA) / resistance, (1 / GAMMA));pck.lux = lux;size = xMessageBufferSend(xMessageBuffer, // 消息缓冲句柄(void*)&pck, // 传输的消息体首地址指针psize, // 本次传输的数据大小portMAX_DELAY); // 传输等待超时时间if(size != psize){printf("[LDRP] 数据发送失败,可能造成数据不完整的混乱\n");}else{// printf("[DHTP] 数据发送成功,大小 : %d\n",size);}vTaskDelay(random(1000,3000));}
}
// 消息处理器
void processor(char *data, size_t size){/* 正确的消息处理方式如下:* 1. 首先判断包头是否正确,如果不正确则直接扔掉数据包* 2. 判断长度是否正确,如果不正确则扔掉数据包* 3. 取出数据*/if(data[0] == HEAD[0] && data[1] == HEAD[1] && data[2] == HEAD[2]){Package_Head *head= (Package_Head *)data;if(head->data_length == size-sizeof(Package_Head)){// printf("[PROC] 数据包到达,类型 :%02X , 长度 : %d\n", data[3], head->data_length);switch(data[3]){case 0x01: // DHT22类型数据{DHT22_Package *pak = (DHT22_Package *)data;printf("[PROC] DHT22数据到达,Temperature : %.2f°C , Humidity : %.2f%%\n",pak->temperature, pak->humidity);break;}case 0x02: // LDR类型数据{LDR_Package *pak = (LDR_Package *)data;printf("[PROC] LDR数据到达,光照 : %.2f\n",pak->lux);break;}default:{printf("[PROC] 未知数据包 : %02X\n",data[3]);}}}else{printf("[PROC] 数据长度检测失败 : %d\n", data[4]);}}else{printf("[PROC] 包头检测失败 : %02X , %02X , %02X\n", data[0], data[1], data[2]);}
}
/*** @brief 数据处理器线程* 该函数优先级建议比数据存入线程高,保证数据先处理(视具体情况而定)* 当发现缓冲区中有数据时,先处理缓冲区数据,确保所有数据处理完成之后再进行下一次等待**/
void processor_task(void* param_t){size_t msize; // 消息的长度size_t size; // 接收的长度while(1){msize = xMessageBufferNextLengthBytes(xMessageBuffer); // 获得下一条消息的长度while(msize>0){char *data = (char *)pvPortMalloc(msize); // 开辟空间准备接收消息size = xMessageBufferReceive(xMessageBuffer, // 消息缓冲区句柄(void *)data, // 接收数据的首地址msize, // 最大接收数据长度portMAX_DELAY); // 等待时间if(size == msize){// 正确收到了消息processor(data, size);}else{printf("[PROC] 消息接收错误,应接收 : %d , 实际接收 : %d\n", msize, size);}vPortFree(data); // 释放空间msize = xMessageBufferNextLengthBytes(xMessageBuffer); // 获得下一条消息的长度}vTaskDelay(1000);}
}
void setup() {Serial.begin(115200);Serial.println("Hello, ESP32-S3!");xMessageBuffer = xMessageBufferCreate(BUFFER_SIZE); // 初始化消息缓冲区if (xMessageBuffer == NULL){printf("创建缓冲区失败,内存不足!\n");}else{// 创建线程xTaskCreate(dht22_task, "DHT22", 1024 * 4, NULL, 1, NULL);xTaskCreate(ldr_task, "LDR", 1024 * 4, NULL, 1, NULL);xTaskCreate(processor_task, "PROC", 1024 * 4, NULL, 1, NULL);}
}
void loop() {delay(10);
}
在 setup 函数中,首先通过 xMessageBufferCreate 对消息缓冲区进行格式化,这个函数中只需要传入一个函数,即缓冲区的大小,单位是字节(这里的字节数包含了消息自身和4个字节的数据长度)。
dht22_task 用于操作DHT22硬件设备,首先在程序的开头对设备进行初始化,并对DHT22的数据包结构进行了格式化,包含包头和包体两部分,包头8字节,前三个字节是包花,用于识别一个标准完整的数据包,第四个字节是数据类型,DHT22数据类型是0x01,第五个字节是包体长度,因为DHT33返回2个float型数据,理论上长度应该是8字节。
这里需要注意,在 Package_Head 中最后预留了三个字节的数据,及时这里不写,系统仍然会对 Package_Head 进行4字节对齐(包头原本是5字节,4字节对齐后是8字节),如果不写着三个字节的预留,sizeof(Package_Head)时候得到的结果是5,而sizeof(DHT22_Package)的时候得到的确实16,会让初学者造成困扰,而且在跨系统数据传递的时候也容易造成困扰和数据错乱,所以遵循ESP32的规矩,加入3个字节保留位。
数据构造完毕后,通过 xMessageBufferSend 函数发出,这个函数的原型如下:
size_t xMessageBufferSend( MessageBufferHandle_t xMessageBuffer,const void *pvTxData,size_t xDataLengthBytes,TickType_t xTicksToWait );
xMessageBuffer:消息缓冲区句柄
pvTxData:要发送数据的首地址指针
xDataLengthBytes:发送数据的最大长度
xTicksToWait:等待时间
返回实际发送的数据大小,与流缓冲区发送数据时相同,xDataLengthBytes 一定要比实际pvTxData的数据长度小或者相等,否则会造成不可预估的数据溢出错误。
返回值是实际发送到缓冲区的数据,如果发现xDataLengthBytes与返回值不一致的情况,有可能是数据错误(非常严重,必定会导致系统崩溃),或者是因为超时没有发送成功(此时返回值应该为0)。
ldr_task 和 dht22_tas 做所的事基本无异,只是发送的数据长度不同,LDR_Package 的数据长度是12,正好也是四字节对齐的。
这里需要注意,在 LDR_Package 和 DHT22_Package 中,head 成员变量已经做了4字节对齐,所以这里不会出现数据错乱,但如果结构体本身没有进行四字节对齐,那在其他结构体或作为其他结构成员使用的时候,系统会自动进行四字节对齐,与其让系统自己补充,不如我们自己先补充上,这是一个好习惯,省得以后读代码的时候搞得自己很费解。
单片机编程中类似的坑还有很多,猜的次数多了也就踏平了
在 processor_task 任务中,有两层循环,这也是物联网消息处理中比较合理的结构,当缓冲区中没有数据的时候,让出 CPU ,所以在外层循环中有 delay 函数,但如果缓冲区中存在消息,则应该先处理缓冲区的消息在考虑让出 CPU,以确保消息处理的及时性(如果还有其他重要任务在同意核心中运行,三种建议,一种是提升该任务的优先级,在就是在内循环中 delay 1ms 短暂让出 CPU,或在内循环中通过 taskYIELD 函数手动强制调度)。
另外,在大多数程序中,消息处理的优先级要比数据接收的优先级要高,所以可以考虑提升数据处理任务的优先级。
但在一些程序中(比如蓝牙和WiFi等流数据的接收),应该考虑先接收数据,所以数据接收任务的优先级要比事件处理的优先级要高。
我们应该因程序设定优先级,不能生搬硬套死记硬背。
首先在外层循环调用 xMessageBufferNextLengthBytes 获取下一条消息的长度,如果缓冲区中有消息,长度必定是大于8的(因为包头的长度为8,而我们的数据中没有只含包头的数据包),这是将进入内层循环,调用 xMessageBufferReceive 获取消息具体内容,该函数原型如下:
size_t xMessageBufferReceive( MessageBufferHandle_t xMessageBuffer,void *pvRxData,size_t xBufferLengthBytes,TickType_t xTicksToWait );
xMessageBuffer:消息缓冲区句柄
pvRxData:指向缓冲区的指针,收到的信息 将被复制到该缓冲区
xBufferLengthBytes:接收消息的最大长度,可以大于消息本身,这样仍然会返回下一条完整的消息,该函数的返回值是消息本身的实际长度,但如果 xBufferLengthBytes 小于本条消息的长度,则消息不回被读出,仍然会保留在缓冲区中,该函数返回值为0。
xTicksToWait:如果缓冲区中没有消息,则会等待至超时。
该函数返回值为本条消息的实际长度,和 xBufferLengthBytes 可能不一致。
如果消息长度是合法的,任务将消息扔给 processor 进行处理。
注意:在实际项目开发中,消息是从外部(WiFi、蓝牙、Zigbee、485等)到达的,我们需要完成三个线程的开发:
- 数据接收线程,该线程以流的方式接收二进制数据,并存入到流缓冲区中;
- 消息构造线程,该线程从流缓冲区中读取并验证消息的合法性,并封装成数据包发送到消息缓冲区中;
- 消息处理线程,该线程从消息缓冲区中读取消息,并分发给处理函数进行处理,但一般这个处理线程不会对消息进行同步处理,根据消息类型可分为独立线程处理,或进入指定类型的队列中进行处理。
在 数据接收线程 中,任务只需要收取来自外部的二进制数据流,并发送到缓冲区,不做多余的动作,也有些项目中将 数据接收线程 和 消息构造线程 合并的,这取决于突发数据量的大小,建议分开。
消息构造线程 需要分析的事项依次如下:
- 流缓冲区中是否有一个完成的包头(也就是我们构造流缓冲区时候的 TRIGGER_LEVEL 参数),如果不够则等待,如果够则执行步骤 2;
- 包花是否一致,如果不一致删除流缓冲区第一位(读取以为即可),重新执行步骤 1, 如果符合则执行步骤 3;
- 读取包头,并从中获取数据长度,查看缓冲区中是否仍然存在符合数据长度的数据,如果不符合则等待,如果符合则进入步骤 4;
- 从流缓冲区中读取剩余包体数据,并构造完整的数据包,送入 消息缓冲区中 等待消息处理线程的处理。
消息处理线程 需要做的事项如下:
- 通过传入的二进制数据构造完成的数据包;
- 根据包类型可以做以下选择:
a. 本地同步处理消息(一般针对应答消息适用,比如所有需要有 ACK 回应的消息,或是要求重新发送的消息,都再次进行处理);
b. 放入指定类型消息的消息队列中,等待其他任务处理(一般针对普适性消息,比如显示数据、保存数据等);
c. 启用高优先级新线程对此消息进行及时处理(一般针对突发命令,比如紧急停止);
d. 丢弃,对于不认识的数据包,直接丢弃。
而在例程中,我们已经把2和3合并成了一个线程,消息处理函数 processor 对消息合法性进行判断,并且在本线程中同步处理了所有的消息。(例程仅做演示,正式项目开发中尽可能分开)
消息缓冲区适合用在多对一的消息传递中,多个发送者,一个接收者;对于多对多的方式可以使用,但一般接受者都为负载线程,执行相同或相似的任务。
关于消息缓冲区的所有API,可以参考:https://wokwi.com/projects/363029703756578817
相关文章:
S1-08 流和消息缓冲区
流缓冲区 流缓冲区一般用在不同设备或者不同进程间的通讯,为了提高数据处理效率和性能,设置的一定大小的缓冲区,流缓冲区可以用来存储程序中需要处理的数据、对象、报文等信息,使程序对可以对这些信息进行预处理、排序、过滤、拆…...

Java重修第五天—面向对象3
通过学习本篇文章可以掌握如下知识 1、多态; 2、抽象类; 3、接口。 之前已经学过了继承,static等基础知识,这篇文章我们就开始深入了解面向对象多态、抽象类和接口的学习。 多态 多态是在继承/实现情况下的一种现象…...
)
【征稿进行时|见刊、检索快速稳定】2024年经济发展与旅游管理国际学术会议(ICEDTM 2024)
【征稿进行时|见刊、检索快速稳定】2024年经济发展与旅游管理国际学术会议(ICEDTM 2024) 2024 International Conference Economic Development and Tourism Management(ICEDTM 2024) 一、【会议简介】 ICEDTM 2024将围绕"旅游管理”“经济发展”的最新研究领域ÿ…...

瑞_Java开发手册_(四)安全规约
🙊前言:本文章为瑞_系列专栏之《Java开发手册》的安全规约篇。由于博主是从阿里的《Java开发手册》学习到Java的编程规约,所以本系列专栏主要以这本书进行讲解和拓展,有需要的小伙伴可以点击链接下载。本文仅供大家交流、学习及研…...

Docker 安全必知:最佳实践、漏洞管理与监控策略
容器安全是实施和管理像 Docker 这样的容器技术的关键方面。它包括一组实践、工具和技术,旨在保护容器化应用程序及其运行的基础架构。在本节中,我们将讨论一些关键的容器安全考虑因素、最佳实践和建议。 容器隔离 隔离对于确保容器化环境的强大性和安全…...

【Flutter】多线程
Flutter 作为一个跨平台的UI库,前面的Flutter 架构有涉及到,Flutter 架构中的运行的多个线程。那么最为一个Flutter开发者,我们如何创建线程呢 多线程 上述我们提及到了,架构层涉及的多线程问题。比如说 主线程, 平台线程&#x…...
STM32-实时时钟RTC-1
...
node(express.js创建项目)+连接mysql数据库
1.node npm的安装 2.express的安装 全局安装:npm install express -gnpm install -g express-generator// ps: 4.0版本把generator分离出来了,需要单独安装3.创建express项目 express 项目名称 cd 项目名称 npm install npm start4.项目中安装数据库 npm install…...

【FLV】记录 H.264的解析
参考 FLV 文件格式分析 知乎大神的FLV文件格式分析。 FLV 首先下发9个字节的FLV 头 -2024-01-08 11:38:29.698 INFO [32196] [evplayer_client_main@153] player clinet run … 2024-01-08 11:38:29.702 INFO [2276] [evplayer_client_main::<lambda_1>::operator ()@14…...
nodejs+vue+ElementUi音乐分享社交网站77l8j
本文介绍的系统主要分为两个部分:一是前台界面:用户通过注册登录可以实现音乐播放、新闻浏览、留言评论等功能;另一个是后台界面:音乐网站管理员对用户信息进行管理,上传更新音乐资源,发布最新音乐资讯等功…...

进销存+小程序商城:实现批发零售企业的互联网转型与管理升级
在当今互联网高速发展的时代,越来越多的批发零售企业开始开始考虑转型。在这个行业中,企业要想取得更好的发展,就要积极地拥抱互联网。专属的订货商城小程序是企业转型的第一步。通过将进销存与订货商城一体化,企业可以更好地满足…...

Tomcat解压打包文件和并部署
一、文件压缩和上传解压 1.本地打包好dist.tar.gz文件 2.通过xftp拖拽上传到知道文件夹下,或者通过命令: cp dist.tar.gz /path/to/destination/folder注:将dist.tar.gz复制到 /path/to/destination/folder文件夹下,该文件夹只是举个例子怎么复制和解压! 3.进入/path/…...

JDK17
JDK 17是Java开发工具包(Java Development Kit)的一个版本。JDK是用于开发和运行Java应用程序的软件包,它包含了编译器、调试器、运行时环境和其他一些实用工具。JDK 17是Java的最新版本,它提供了许多新的功能、增强和改进。 使用…...

使用Docker运行SRS Stack
SRS Stack | SRS (ossrs.net) Docker 推荐使用Docker运行SRS Stack: docker run --restart always -d -it --name srs-stack -v $HOME/data:/data \-p 2022:2022 -p 2443:2443 -p 1935:1935 -p 8000:8000/udp -p 10080:10080/udp \registry.cn-hangzhou.aliyun…...
git安装教程 Windows 附安装包链接
Git是一款分布式源代码管理工具(版本控制工具) 。 git的作用 当你需要做一个大工程的时候,文件的管理无疑是非常庞大的工作,因为你需要不断的修改更新文件内容,同时可能还要保留旧版本保证可以复原,这样就需要备份多个版本的文件…...
TensorRT(C++)基础代码解析
TensorRT(C)基础代码解析 文章目录 TensorRT(C)基础代码解析前言一、TensorRT工作流程二、C API2.1 构建阶段2.1.1 创建builder2.1.2 创建网络定义2.1.3 定义网络结构2.1.4 定义网络输入输出2.1.5 配置参数2.1.6 生成Engine2.1.7 保存为模型文件2.1.8 释放资源 2.2 运行期2.2.1…...

如何查询MySQL中的树型表
在 MySQL 中查询树型表(即具有层级结构的表)可以使用递归查询或者使用嵌套集模型。下面分别介绍这两种方法: 递归查询:递归查询是通过自连接来实现的,可以使用 WITH RECURSIVE 关键字进行递归查询。假设有一个 catego…...

Programming Abstractions in C阅读笔记:p246-p247
《Programming Abstractions in C》学习第68天,p246-p247总结,总计2页。 一、技术总结 本章通过“the game of nim(尼姆游戏)”,这类以现实生活中事物作为例子进行讲解的情况,往往对学习者要求比较高,需要学习者具备…...
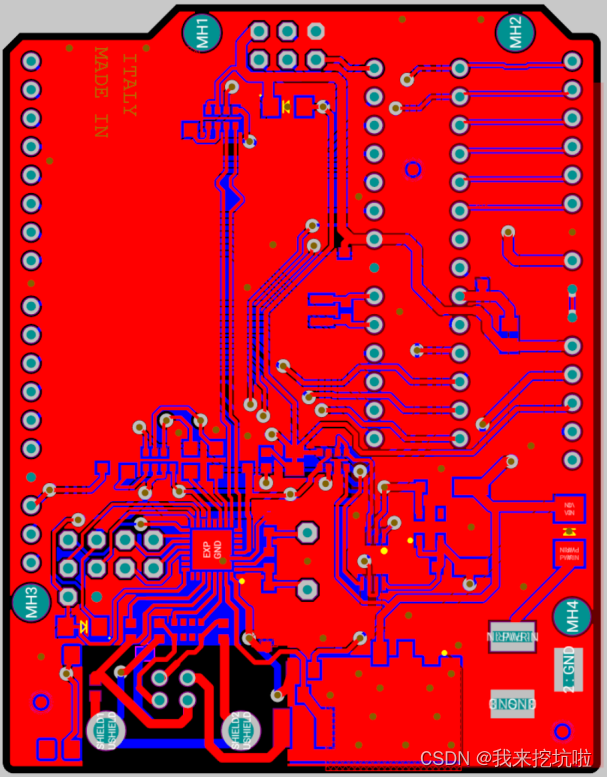
智能寻迹避障清障机器人设计(电路图附件+代码)
附 录 智能小车原理图 智能小车拓展板原理图 智能小车拓展板PCB 智能小车底板PCB Arduino UNO原理图 Arduino UNO PCB 程序部分 void Robot_Traction() //机器人循迹子程序{//有信号为LOW 没有信号为HIGHSR digitalRead(SensorRight);//有信号表明在白…...
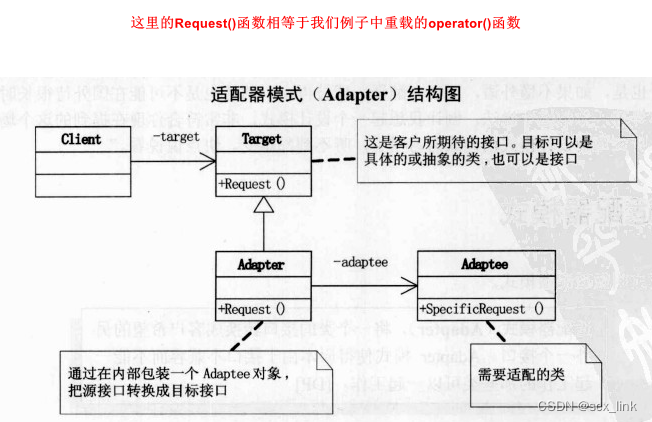
设计模式-- 3.适配器模式
适配器模式 将一个类的接口转换成客户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 角色和职责 请求者(client):客户端角色,需要使用适配器的对象,不需要关心适配器内部的实现,…...

LabVIEW触发采集实战:从原理到多通道同步实现
1. 项目概述:为什么我们需要触发采集?在数据采集领域,尤其是自动化测试、设备监控和信号分析等场景,我们常常会遇到一个核心痛点:如何精准地捕捉到我们真正关心的那一段信号?想象一下,你正在监测…...

Keil MDK Debug 命令行常用命令
适用:Keil MDK-ARM (uVision5),进入 Debug 模式后,下方的 Command 窗口或 View → Command Window 打开。一、断点管理 (BKPT / BS / BL) 硬件断点 (Breakpoint Set) BS <func> ; 在函数入口设断点 BS <func&…...

RISC-V处理器架构演进:从单周期到流水线的性能跃迁之路
1. 从单周期到流水线:RISC-V架构的性能进化史 第一次接触处理器设计时,我盯着单周期架构的电路图看了整整三天。最让我困惑的是:为什么简单的加法指令要和复杂的访存指令共用相同的时钟周期?这个问题背后,藏着处理器架…...

Windows 系统安装阶段快速创建本地账户操作说明
Windows 系统安装阶段快速创建本地账户操作说明 一、功能概述 本操作适用于 Windows 10/11 系统初始化联网配置(OOBE)界面,可直接绕过微软账户强制登录流程,一键启动本地账户创建向导,自定义设置系统用户名,…...

使用 Taotoken 后 API 调用延迟与稳定性体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后 API 调用延迟与稳定性体验分享 作为一名日常需要频繁调用大模型 API 的开发者,服务的稳定性和响应速…...

Haystack框架实战:从零构建企业级智能问答系统
1. 项目概述:一个为构建智能搜索与问答系统而生的框架如果你正在为海量文档构建一个能“理解”问题并“找到”答案的智能系统,比如一个公司内部的知识库助手,或者一个能检索技术文档并给出精准回复的客服机器人,那么你很可能已经听…...

TaotokenAPI密钥管理与访问控制功能的实际使用体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API 密钥管理与访问控制功能的实际使用体验 在团队协作开发中,如何安全、高效地管理大模型 API 的访问权限&a…...

英雄联盟智能助手:从青铜到王者的全方位游戏体验升级指南
英雄联盟智能助手:从青铜到王者的全方位游戏体验升级指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 想要在英雄联盟中获得竞争…...
)
告别卡顿!在Ubuntu 22.04 LTS上丝滑安装Burp Suite 2024.1(附国内源加速配置)
在Ubuntu 22.04 LTS上极速安装Burp Suite 2024.1的终极指南 每次启动Burp Suite都要等上几分钟?运行过程中频繁卡顿甚至崩溃?如果你正在使用Ubuntu 22.04 LTS或更新的版本,很可能是因为还在沿用那些针对Ubuntu 18.04的过时教程。本文将带你彻…...

MQTT QoS压力测试:RyanMqtt消息可靠性深度剖析与实战避坑
1. 项目概述:为什么我们要死磕MQTT的QoS?最近在折腾一个物联网项目,后台服务用的是RyanMqtt。项目上线前,团队里有个兄弟随口问了句:“咱们这消息到底靠不靠谱?别设备上报的数据丢了,或者指令发…...