TensorRT(C++)基础代码解析
TensorRT(C++)基础代码解析
文章目录
- TensorRT(C++)基础代码解析
- 前言
- 一、TensorRT工作流程
- 二、C++ API
- 2.1 构建阶段
- 2.1.1 创建builder
- 2.1.2 创建网络定义
- 2.1.3 定义网络结构
- 2.1.4 定义网络输入输出
- 2.1.5 配置参数
- 2.1.6 生成Engine
- 2.1.7 保存为模型文件
- 2.1.8 释放资源
- 2.2 运行期
- 2.2.1 创建一个runtime对象
- 2.2.2 反序列化生成engine
- 2.2.3 创建一个执行上下文ExecutionContext
- 2.2.4 为推理填充输入
- 2.2.4 调用enqueueV2来执行推理
- 2.2.5 释放资源
- 总结
前言
一、TensorRT工作流程

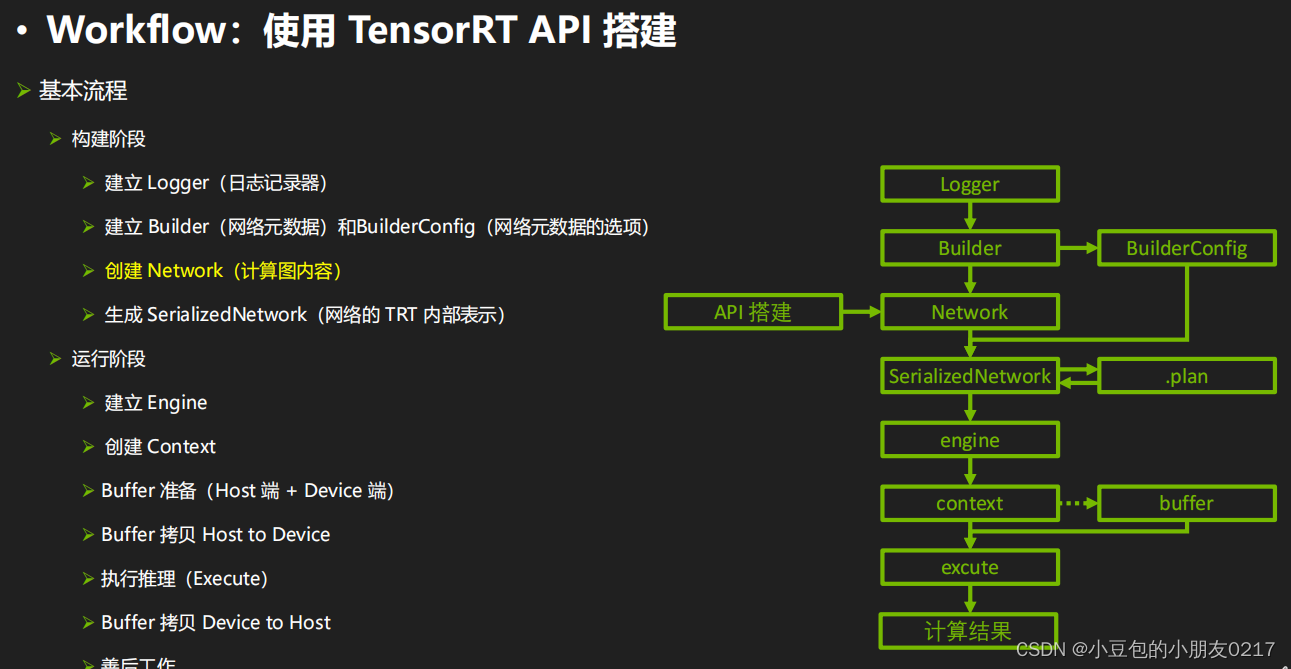
二、C++ API
2.1 构建阶段
TensorRT build engine的过程
- 创建builder
- 创建网络定义:builder —> network
- 配置参数:builder —> config
- 生成engine:builder —> engine (network, config)
- 序列化保存:engine —> serialize
- 释放资源:delete
2.1.1 创建builder
nvinfer1 是 NVIDIA TensorRT 的 C++ 接口命名空间。构建阶段的最高级别接口是 Builder。Builder负责优化一个模型,并产生Engine。通过如下接口创建一个Builder。
nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(logger);
2.1.2 创建网络定义
NetworkDefinition接口被用来定义模型。接口createNetworkV2接受配置参数,参数用按位标记的方式传入。比如上面激活explicitBatch,是通过1U << static_cast<uint32_t (nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH); 将explicitBatch对应的配置位设置为1实现的。在新版本中,请使用createNetworkV2而非其他任何创建NetworkDefinition 的接口。
auto explicitBatch = 1U << static_cast<uint32_t
(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);// 调用createNetworkV2创建网络定义,参数是显性batch
nvinfer1::INetworkDefinition *network = builder->createNetworkV2(explicitBatch);
2.1.3 定义网络结构
将模型转移到TensorRT的最常见的方式是以ONNX格式从框架中导出(将在后续课程进行介绍),并使用TensorRT的ONNX解析器来填充网络定义。同时,也可以使用TensorRT的Layer和Tensor等接口一步一步地进行定义。通过接口来定义网络的代码示例如下:
添加输入层
const int input_size = 3;
nvinfer1::ITensor *input = network->addInput("data", nvinfer1::DataType::kFLOAT,nvinfer1::Dims4{1, input_size, 1, 1})
添加全连接层
nvinfer1::IFullyConnectedLayer* fc1 = network->addFullyConnected(*input, output_size, fc1w, fc1b);
添加激活层
nvinfer1::IActivationLayer* relu1 = network->addActivation(*fc1->getOutput(0), nvinfer1::ActivationType::kRELU);
2.1.4 定义网络输入输出
定义哪些张量是网络的输入和输出。没有被标记为输出的张量被认为是瞬时值,可以被构建者优化掉。输入和输出张量必须被命名,以便在运行时,TensorRT知道如何将输入和输出缓冲区绑定到模型上。
// 设置输出名字
sigmoid->getOutput(0)->setName("output");
// 标记输出,没有标记会被当成顺时针优化掉
network->markOutput(*sigmoid->getOutput(0));
2.1.5 配置参数
添加相关Builder 的配置。createBuilderConfig接口被用来指定TensorRT应该如何优化模型
nvinfer1::IBuilderConfig *config = builder->createBuilderConfig();// 设置最大工作空间大小,单位是字节
config->setMaxWorkspaceSize(1 << 28); // 256MiB
2.1.6 生成Engine
nvinfer1::ICudaEngine *engine = builder->buildEngineWithConfig(*network, *config);
2.1.7 保存为模型文件
nvinfer1::IHostMemory *serialized_engine = engine->serialize();// 存入文件
std::ofstream outfile("model/mlp.engine", std::ios::binary);
assert(outfile.is_open() && "Failed to open file for writing");
outfile.write((char *)serialized_engine->data(), serialized_engine->size());
2.1.8 释放资源
outfile.close();
delete serialized_engine;
delete engine;
delete config;
delete network;
完整代码
/*
TensorRT build engine的过程
7. 创建builder
8. 创建网络定义:builder ---> network
9. 配置参数:builder ---> config
10. 生成engine:builder ---> engine (network, config)
11. 序列化保存:engine ---> serialize
12. 释放资源:delete
*/#include <iostream>
#include <fstream>
#include <cassert>
#include <vector>#include <NvInfer.h>// logger用来管控打印日志级别
// TRTLogger继承自nvinfer1::ILogger
class TRTLogger : public nvinfer1::ILogger
{void log(Severity severity, const char *msg) noexcept override{// 屏蔽INFO级别的日志if (severity != Severity::kINFO)std::cout << msg << std::endl;}
} gLogger;// 保存权重
void saveWeights(const std::string &filename, const float *data, int size)
{std::ofstream outfile(filename, std::ios::binary);assert(outfile.is_open() && "save weights failed"); // assert断言,如果条件不满足,就会报错outfile.write((char *)(&size), sizeof(int)); // 保存权重的大小outfile.write((char *)(data), size * sizeof(float)); // 保存权重的数据outfile.close();
}
// 读取权重
std::vector<float> loadWeights(const std::string &filename)
{std::ifstream infile(filename, std::ios::binary);assert(infile.is_open() && "load weights failed");int size;infile.read((char *)(&size), sizeof(int)); // 读取权重的大小std::vector<float> data(size); // 创建一个vector,大小为sizeinfile.read((char *)(data.data()), size * sizeof(float)); // 读取权重的数据infile.close();return data;
}int main()
{// ======= 1. 创建builder =======TRTLogger logger;nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(logger);// ======= 2. 创建网络定义:builder ---> network =======// 显性batch// 1 << 0 = 1,二进制移位,左移0位,相当于1(y左移x位,相当于y乘以2的x次方)auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);// 调用createNetworkV2创建网络定义,参数是显性batchnvinfer1::INetworkDefinition *network = builder->createNetworkV2(explicitBatch);// 定义网络结构// mlp多层感知机:input(1,3,1,1) --> fc1 --> sigmoid --> output (2)// 创建一个input tensor ,参数分别是:name, data type, dimsconst int input_size = 3;nvinfer1::ITensor *input = network->addInput("data", nvinfer1::DataType::kFLOAT, nvinfer1::Dims4{1, input_size, 1, 1});// 创建全连接层fc1// weight and biasconst float *fc1_weight_data = new float[input_size * 2]{0.1, 0.2, 0.3, 0.4, 0.5, 0.6};const float *fc1_bias_data = new float[2]{0.1, 0.5};// 将权重保存到文件中,演示从别的来源加载权重saveWeights("model/fc1.wts", fc1_weight_data, 6);saveWeights("model/fc1.bias", fc1_bias_data, 2);// 读取权重auto fc1_weight_vec = loadWeights("model/fc1.wts");auto fc1_bias_vec = loadWeights("model/fc1.bias");// 转为nvinfer1::Weights类型,参数分别是:data type, data, sizenvinfer1::Weights fc1_weight{nvinfer1::DataType::kFLOAT, fc1_weight_vec.data(), fc1_weight_vec.size()};nvinfer1::Weights fc1_bias{nvinfer1::DataType::kFLOAT, fc1_bias_vec.data(), fc1_bias_vec.size()};const int output_size = 2;// 调用addFullyConnected创建全连接层,参数分别是:input tensor, output size, weight, biasnvinfer1::IFullyConnectedLayer *fc1 = network->addFullyConnected(*input, output_size, fc1_weight, fc1_bias);// 添加sigmoid激活层,参数分别是:input tensor, activation type(激活函数类型)nvinfer1::IActivationLayer *sigmoid = network->addActivation(*fc1->getOutput(0), nvinfer1::ActivationType::kSIGMOID);// 设置输出名字sigmoid->getOutput(0)->setName("output");// 标记输出,没有标记会被当成顺时针优化掉network->markOutput(*sigmoid->getOutput(0));// 设定最大batch sizebuilder->setMaxBatchSize(1);// ====== 3. 配置参数:builder ---> config ======// 添加配置参数,告诉TensorRT应该如何优化网络nvinfer1::IBuilderConfig *config = builder->createBuilderConfig();// 设置最大工作空间大小,单位是字节config->setMaxWorkspaceSize(1 << 28); // 256MiB// ====== 4. 创建engine:builder ---> network ---> config ======nvinfer1::ICudaEngine *engine = builder->buildEngineWithConfig(*network, *config);if (!engine){std::cerr << "Failed to create engine!" << std::endl;return -1;}// ====== 5. 序列化engine ======nvinfer1::IHostMemory *serialized_engine = engine->serialize();// 存入文件std::ofstream outfile("model/mlp.engine", std::ios::binary);assert(outfile.is_open() && "Failed to open file for writing");outfile.write((char *)serialized_engine->data(), serialized_engine->size());// ====== 6. 释放资源 ======// 理论上,这些资源都会在程序结束时自动释放,但是为了演示,这里手动释放部分outfile.close();delete serialized_engine;delete engine;delete config;delete network;delete builder;std::cout << "engine文件生成成功!" << std::endl;return 0;
}
2.2 运行期
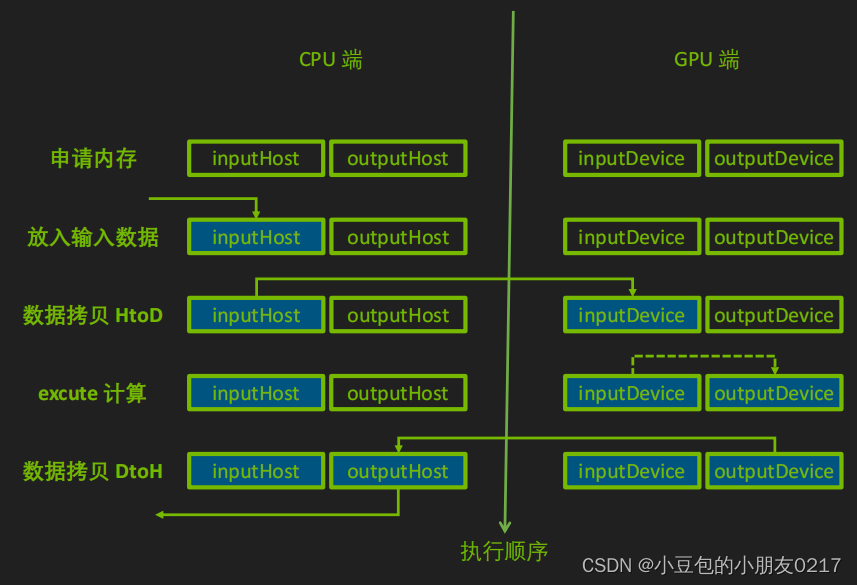
TensorRT runtime 推理过程
- 创建一个runtime对象
- 反序列化生成engine:runtime —> engine
- 创建一个执行上下文ExecutionContext:engine —> context
- 填充数据
- 执行推理:context —> enqueueV2
- 释放资源:delete
2.2.1 创建一个runtime对象
TensorRT运行时的最高层级接口是Runtime
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(logger);
2.2.2 反序列化生成engine
通过读取模型文件并反序列化,我们可以利用runtime生成Engine。
nvinfer1::ICudaEngine *engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size(), nullptr);
2.2.3 创建一个执行上下文ExecutionContext
从Engine创建的ExecutionContext接口是调用推理的主要接口。ExecutionContext包含与特定调用相关的所有状态,因此可以有多个与单个引擎相关的上下文,且并行运行它们。
nvinfer1::IExecutionContext *context = engine->createExecutionContext();
2.2.4 为推理填充输入
首先创建CUDA Stream用于推理的执行。
cudaStream_t stream = nullptr;
cudaStreamCreate(&stream);
同时在CPU和GPU上分配输入输出内存,并将输入数据从CPU拷贝到GPU上。
// 输入数据
float* h_in_data = new float[3]{1.4, 3.2, 1.1};
int in_data_size = sizeof(float) * 3;
float* d_in_data = nullptr;
// 输出数据
float* h_out_data = new float[2]{0.0, 0.0};
int out_data_size = sizeof(float) * 2;
float* d_out_data = nullptr;
// 申请GPU上的内存
cudaMalloc(&d_in_data, in_data_size);
cudaMalloc(&d_out_data, out_data_size);
// 拷贝数据
cudaMemcpyAsync(d_in_data, h_in_data, in_data_size, cudaMemcpyHostToDevice, stream);
// enqueueV2中是把输入输出的内存地址放到bindings这个数组中,需要写代码时确定这些输入输出的顺序(这样容易出错,而且不好定位bug,所以新的接口取消了这样的方式,不过目前很多官方 sample 也在用v2)
float* bindings[] = {d_in_data, d_out_data};
2.2.4 调用enqueueV2来执行推理
bool success = context -> enqueueV2((void **) bindings, stream, nullptr);
// 数据从device --> host
cudaMemcpyAsync(host_output_data, device_output_data, output_data_size, cudaMemcpyDeviceToHost, stream);
// 等待流执行完毕
cudaStreamSynchronize(stream);
// 输出结果
std::cout << "输出结果: " << host_output_data[0] << " " << host_output_data[1] << std::endl;
2.2.5 释放资源
cudaStreamDestroy(stream);
cudaFree(device_input_data_address);
cudaFree(device_output_data_address);
delete[] host_input_data;
delete[] host_output_data;delete context;
delete engine;
delete runtime;
完整代码
/*
使用.cu是希望使用CUDA的编译器NVCC,会自动连接cuda库TensorRT runtime 推理过程1. 创建一个runtime对象
2. 反序列化生成engine:runtime ---> engine
3. 创建一个执行上下文ExecutionContext:engine ---> context4. 填充数据5. 执行推理:context ---> enqueueV26. 释放资源:delete*/
#include <iostream>
#include <vector>
#include <fstream>
#include <cassert>#include "cuda_runtime.h"
#include "NvInfer.h"// logger用来管控打印日志级别
// TRTLogger继承自nvinfer1::ILogger
class TRTLogger : public nvinfer1::ILogger
{void log(Severity severity, const char *msg) noexcept override{// 屏蔽INFO级别的日志if (severity != Severity::kINFO)std::cout << msg << std::endl;}
} gLogger;// 加载模型
std::vector<unsigned char> loadEngineModel(const std::string &fileName)
{std::ifstream file(fileName, std::ios::binary); // 以二进制方式读取assert(file.is_open() && "load engine model failed!"); // 断言file.seekg(0, std::ios::end); // 定位到文件末尾size_t size = file.tellg(); // 获取文件大小std::vector<unsigned char> data(size); // 创建一个vector,大小为sizefile.seekg(0, std::ios::beg); // 定位到文件开头file.read((char *)data.data(), size); // 读取文件内容到data中file.close();return data;
}int main()
{// ==================== 1. 创建一个runtime对象 ====================TRTLogger logger;nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(logger);// ==================== 2. 反序列化生成engine ====================// 读取文件auto engineModel = loadEngineModel("./model/mlp.engine");// 调用runtime的反序列化方法,生成engine,参数分别是:模型数据地址,模型大小,pluginFactorynvinfer1::ICudaEngine *engine = runtime->deserializeCudaEngine(engineModel.data(), engineModel.size(), nullptr);if (!engine){std::cout << "deserialize engine failed!" << std::endl;return -1;}// ==================== 3. 创建一个执行上下文 ====================nvinfer1::IExecutionContext *context = engine->createExecutionContext();// ==================== 4. 填充数据 ====================// 设置stream 流cudaStream_t stream = nullptr;cudaStreamCreate(&stream);// 数据流转:host --> device ---> inference ---> host// 输入数据float *host_input_data = new float[3]{2, 4, 8}; // host 输入数据int input_data_size = 3 * sizeof(float); // 输入数据大小float *device_input_data = nullptr; // device 输入数据// 输出数据float *host_output_data = new float[2]{0, 0}; // host 输出数据int output_data_size = 2 * sizeof(float); // 输出数据大小float *device_output_data = nullptr; // device 输出数据// 申请device内存cudaMalloc((void **)&device_input_data, input_data_size);cudaMalloc((void **)&device_output_data, output_data_size);// host --> device// 参数分别是:目标地址,源地址,数据大小,拷贝方向cudaMemcpyAsync(device_input_data, host_input_data, input_data_size, cudaMemcpyHostToDevice, stream);// bindings告诉Context输入输出数据的位置float *bindings[] = {device_input_data, device_output_data};// ==================== 5. 执行推理 ====================bool success = context -> enqueueV2((void **) bindings, stream, nullptr);// 数据从device --> hostcudaMemcpyAsync(host_output_data, device_output_data, output_data_size, cudaMemcpyDeviceToHost, stream);// 等待流执行完毕cudaStreamSynchronize(stream);// 输出结果std::cout << "输出结果: " << host_output_data[0] << " " << host_output_data[1] << std::endl;// ==================== 6. 释放资源 ====================cudaStreamDestroy(stream);cudaFree(device_input_data); cudaFree(device_output_data);delete host_input_data;delete host_output_data;delete context;delete engine;delete runtime;return 0;
}
总结
TensorRT(C++)基础代码解析
相关文章:
TensorRT(C++)基础代码解析
TensorRT(C)基础代码解析 文章目录 TensorRT(C)基础代码解析前言一、TensorRT工作流程二、C API2.1 构建阶段2.1.1 创建builder2.1.2 创建网络定义2.1.3 定义网络结构2.1.4 定义网络输入输出2.1.5 配置参数2.1.6 生成Engine2.1.7 保存为模型文件2.1.8 释放资源 2.2 运行期2.2.1…...

如何查询MySQL中的树型表
在 MySQL 中查询树型表(即具有层级结构的表)可以使用递归查询或者使用嵌套集模型。下面分别介绍这两种方法: 递归查询:递归查询是通过自连接来实现的,可以使用 WITH RECURSIVE 关键字进行递归查询。假设有一个 catego…...

Programming Abstractions in C阅读笔记:p246-p247
《Programming Abstractions in C》学习第68天,p246-p247总结,总计2页。 一、技术总结 本章通过“the game of nim(尼姆游戏)”,这类以现实生活中事物作为例子进行讲解的情况,往往对学习者要求比较高,需要学习者具备…...
智能寻迹避障清障机器人设计(电路图附件+代码)
附 录 智能小车原理图 智能小车拓展板原理图 智能小车拓展板PCB 智能小车底板PCB Arduino UNO原理图 Arduino UNO PCB 程序部分 void Robot_Traction() //机器人循迹子程序{//有信号为LOW 没有信号为HIGHSR digitalRead(SensorRight);//有信号表明在白…...
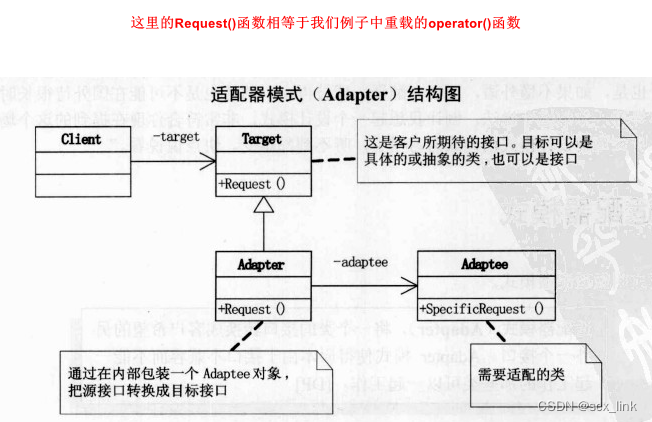
设计模式-- 3.适配器模式
适配器模式 将一个类的接口转换成客户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 角色和职责 请求者(client):客户端角色,需要使用适配器的对象,不需要关心适配器内部的实现,…...
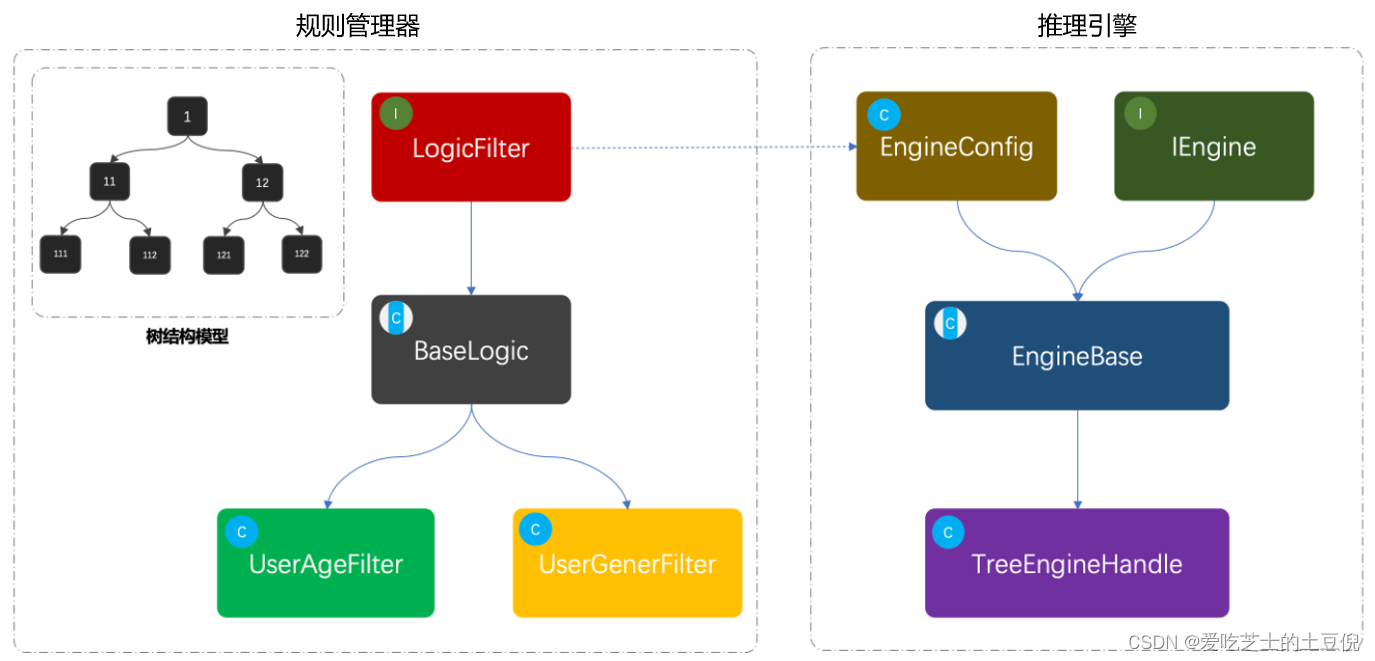
设计一个简单的规则引擎
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术🔥如果感觉博主的文章还不错的…...

openssl3.2 - 官方demo学习 - digest - EVP_MD_stdin.c
文章目录 openssl3.2 - 官方demo学习 - digest - EVP_MD_stdin.c概述笔记END openssl3.2 - 官方demo学习 - digest - EVP_MD_stdin.c 概述 使用 SHA3-512 对stdin输入做摘要, 并输出摘要值. 笔记 /*! \file EVP_MD_stdin.c \note openssl3.2 - 官方demo学习 - digest - EVP…...

浅谈 Raft 分布式一致性协议|图解 Raft
前言 大家好,这里是白泽。本文是一年多前参加字节训练营针对 Raft 自我整理的笔记。 本篇文章将模拟一个KV数据读写服务,从提供单一节点读写服务,到结合分布式一致性协议(Raft)后,逐步扩展为一个分布式的…...

4_【Linux版】重装数据库问题处理记录
1、卸载已安装的oracle数据库。 2、知识点补充: 3、调整/dev/shm/的大小 【linux下修改/dev/shm tmpfs文件系统大小 - saratearing - 博客园 (cnblogs.com)】 mount -o remount,size100g /dev/shm 4、重装oracle后没有orainstRoot.sh 【重装oracle后没有orains…...
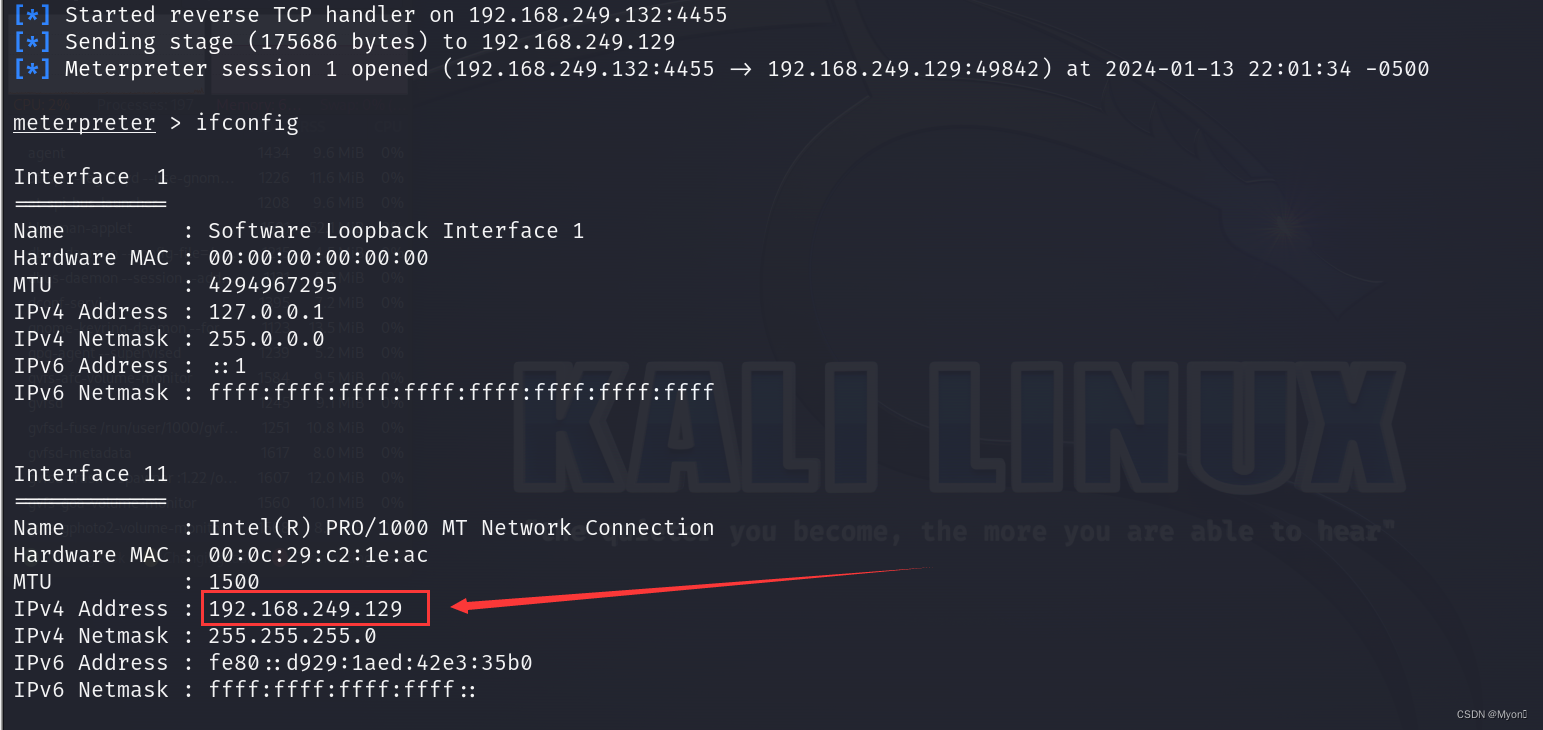
隧道应用2-netsh端口转发监听Meterpreter
流程介绍: 跳板机 A 和目标靶机 B 是可以互相访问到的,在服务器 A 上可以通过配置 netsh 端口映射访问 B 服务器。如果要拿 B 服务器的权限通常是生成正向后门,使用 kali 的 msf 正向连接B服务器,进而得到 Meterpreter,…...

《Spring》--使用application.yml特性提供多环境开发解决方案/开发/测试/线上--方案1
阿丹有话说: 有不少同志有疑问说我正常开发的时候,需要自己搭建项目的时候。总是出现配置文件环境切换出现问题。多环境系列会出两个文章解决给搭建重点解决一下这个问题。给与两种解决的方案。正确让大家只需要按照步骤操作就可以完成。 原理…...

统计项目5000+,出具报表5分钟......捷顺科技数据中台怎么做?
捷顺创立于1992年,以智慧车行、人行出入口软硬件产品为依托,致力于智慧停车生态建设和运营,是出入口智能管理和智慧生态环境建设的开创者和引领者。 历经近三十年的发展,已经成为国内智慧停车领域的领军企业。公司集研、产、销一…...

力扣(105. 从前序与中序遍历序列构造二叉树,106. 从中序与后序遍历序列构造二叉树)
题目1链接 题目1: 思路:使用前序确定根,使用中序分左右子树,分治法。 难点:如何控制递归确定左右子树。 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* T…...
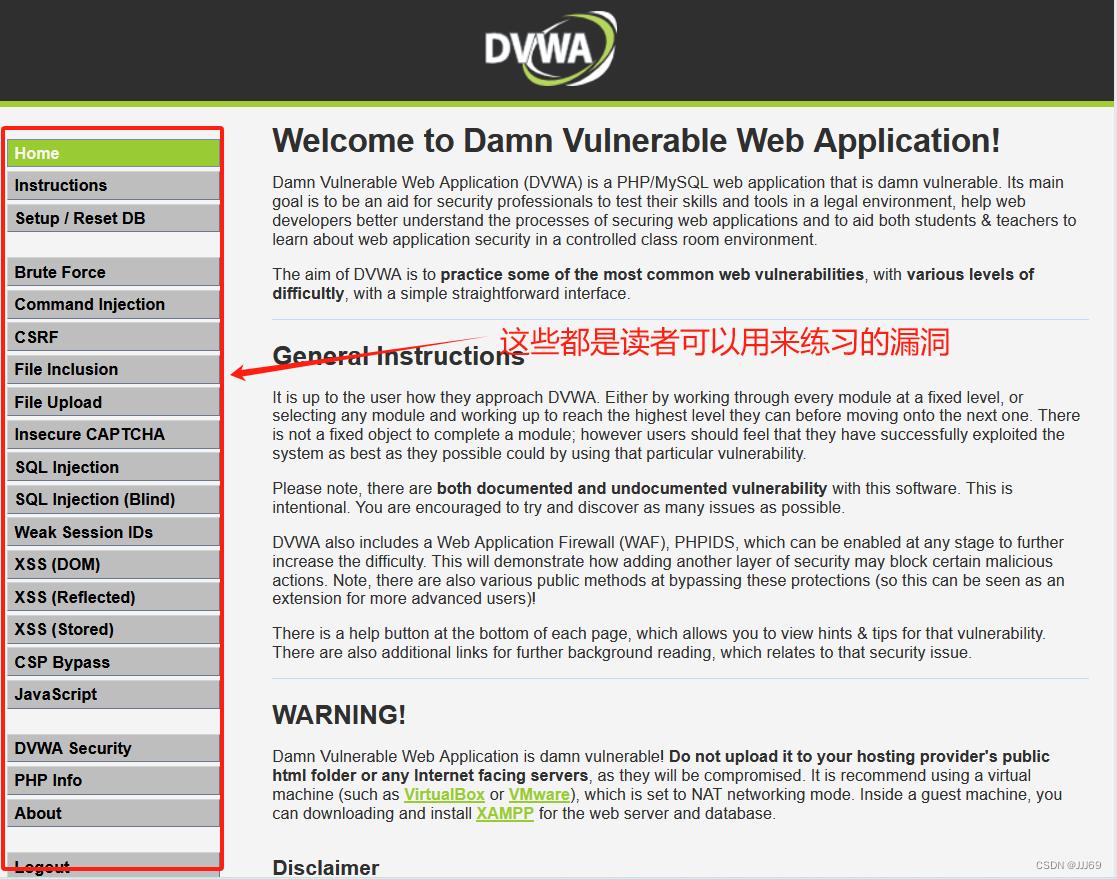
网络安全技术新手入门:在docker上安装dvwa靶场
前言 准备工作:1.已经安装好kali linux 步骤总览:1.安装好docker 2.拖取镜像,安装dvwa 一、安装docker 输入命令:sudo su 输入命令:curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key …...
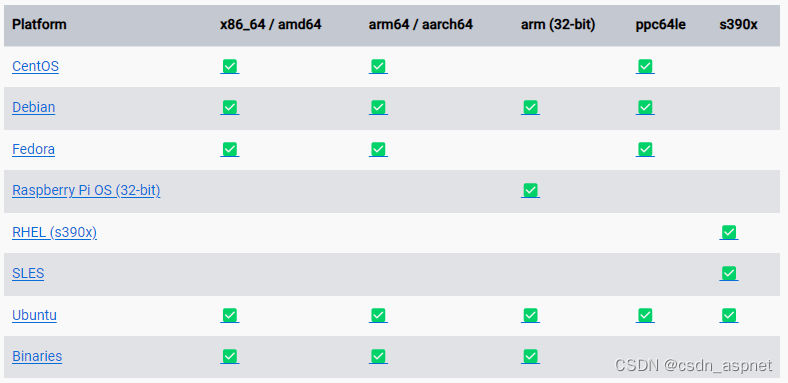
Docker 介绍 及 支持的操作系统
Docker组成: Docker主机(Host): 一个物理机或虚拟机, 用于运行Docker服务进程和容器, 也成为宿主机, node节点。 Docker服务器端(Server): Docker守护进程, 运行Docker容器。 Docker客户端(Client): 客户端使用docker命令或其他工…...

大模型实战营Day5 LMDeploy大模型量化部署实践
模型部署 定义 产品形态 计算设备 大模型特点 内存开销大 动态shape 结构简单 部署挑战 设备存储 推理速度 服务质量 部署方案:技术点 (模型并行 transformer计算和访存优化 低比特量化 Continuous Batch Page Attention)方案(…...
py连接sqlserver数据库报错问题处理。20009
报错 pymssql模块连接sqlserver出现如下错误: pymssql._pymssql.OperationalError) (20009, bDB-Lib error message 20009, severity 9:\nUnable to connect: Adaptive Server is unavailable or does not exist (passwordlocalhost)\n) 解决办法: 打…...

LTESniffer:一款功能强大的LTE上下行链路安全监控工具
关于LTESniffer LTESniffer是一款功能强大的LTE上下行链路安全监控工具,该工具是一款针对LTE的安全开源工具。 该工具首先可以解码物理下行控制信道(PDCCH)并获取所有活动用户的下行链路控制信息(DCI)和无线网络临时…...
SQL语句详解二-DDL(数据定义语言)
文章目录 操作数据库创建:Create查询:Retrieve修改:Update删除:Delete使用数据库 操作表常见的几种数据类型创建:Create复制表 查询:Retrieve修改:Update删除:Delete 操作数据库 创…...
web前端算法简介之链表
链表 链表 VS 数组链表类型链表基本操作 创建链表:插入操作:删除操作:查找操作:显示/打印链表:反转链表:合并两个有序链表:链表基本操作示例 JavaScript中,instanceof环形链表 判断…...

3步搞定微信聊天记录导出:Mac用户必备的数据备份指南
3步搞定微信聊天记录导出:Mac用户必备的数据备份指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心珍贵的微信聊天记录因为手机丢失或系统升级而…...

OpenClawWatch:本地优先的AI智能体监控工具,实现成本、安全与行为全链路追踪
1. 项目概述:为什么我们需要一个“本地优先”的AI智能体监控工具?如果你正在开发或运行能够自主执行任务的AI智能体,比如自动处理邮件、调用API、操作文件,甚至进行线上交易,那么你肯定经历过这样的焦虑时刻࿱…...

跨平台的Web应用快速开发框架
跨平台的Web应用快速开发框架。该框架提供了一套标准化的项目结构规范、统一的API接口命名规则、规范化的前后端代码,支持基于同一套设计规范Python(Flask/Django)、PHP、Java(SpringBoot/SSM)等多种后端语言代码 &…...

突破性APK安装器:在Windows上高效运行Android应用的革命性方案
突破性APK安装器:在Windows上高效运行Android应用的革命性方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否渴望在Windows电脑上无缝运行Android应…...

终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽
终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 想为你的机械键盘打造一套独一无二的键帽吗?Cherr…...

Remix Icon终极指南:3200+免费矢量图标库的完整使用手册
Remix Icon终极指南:3200免费矢量图标库的完整使用手册 【免费下载链接】RemixIcon Open source neutral style icon system 项目地址: https://gitcode.com/gh_mirrors/re/RemixIcon 还在为项目寻找高质量的免费图标而烦恼吗?🤔 每天…...

在多模型间切换时Taotoken路由策略带来的稳定性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型间切换时Taotoken路由策略带来的稳定性体验 在构建基于大模型的应用时,服务的稳定性是开发者关心的核心问题之…...
)
手把手教你给天邑TY1608机顶盒刷机(S905L3B芯片,支持RTL8822CS/MT7668无线模块)
天邑TY1608机顶盒刷机全攻略:从零开始玩转S905L3B芯片 第一次拿到天邑TY1608机顶盒时,你可能被它原厂系统的各种限制所困扰——预装软件无法卸载、广告弹窗频繁出现、存储空间严重不足。这款搭载Amlogic S905L3B芯片的设备,配合RTL8822CS或MT…...

避开这些坑!在Colab上运行AlphaFold2时,参数、路径和依赖库的常见错误排查指南
避开这些坑!在Colab上运行AlphaFold2时,参数、路径和依赖库的常见错误排查指南 在Google Colab上运行AlphaFold2看似简单,但实际操作中90%的用户都会遇到各种"诡异"报错。上周一位结构生物学博士向我吐槽:"明明按照…...

AI智能体安全防护:ClawGuard主动防御系统架构与实战部署
1. 项目概述:为AI智能体构建一道主动防御的“防火墙”在AI智能体(AI Agent)技术快速普及的今天,我们正面临一个全新的安全挑战。想象一下,你精心调教的AI助手,能够自主浏览网页、调用API、执行命令…...