mysql原理--undo日志1
1.事务回滚的需求
我们说过 事务 需要保证 原子性 ,也就是事务中的操作要么全部完成,要么什么也不做。但是偏偏有时候事务执行到一半会出现一些情况,比如:
(1). 事务执行过程中可能遇到各种错误,比如服务器本身的错误,操作系统错误,甚至是突然断电导致的错误。
(2). 程序员可以在事务执行过程中手动输入 ROLLBACK 语句结束当前的事务的执行。
这两种情况都会导致事务执行到一半就结束,但是事务执行过程中可能已经修改了很多东西,为了保证事务的原子性,我们需要把东西改回原先的样子,这个过程就称之为 回滚 (英文名: rollback ),这样就可以造成一个假象:这个事务看起来什么都没做,所以符合 原子性 要求。
小时候我非常痴迷于象棋,总是想找厉害的大人下棋,赢棋是不可能赢棋的,这辈子都不可能赢棋的,又不想认输,只能偷偷的悔棋才能勉强玩的下去。 悔棋 就是一种非常典型的 回滚 操作,比如棋子往前走两步, 悔棋 对应的操作就是向后走两步;比如棋子往左走一步, 悔棋 对应的操作就是向右走一步。数据库中的回滚跟 悔棋 差不多,你插入了一条记录, 回滚 操作对应的就是把这条记录删除掉;你更新了一条记录, 回滚 操作对应的就是把该记录更新为旧值;你删除了一条记录, 回滚 操作对应的自然就是把该记录再插进去。
从上边的描述中我们已经能隐约感觉到,每当我们要对一条记录做改动时(这里的 改动 可以指 INSERT 、DELETE 、 UPDATE ),都需要留一手 —— 把回滚时所需的东西都给记下来。比方说:
(1). 你插入一条记录时,至少要把这条记录的主键值记下来,之后回滚的时候只需要把这个主键值对应的记录删掉就好了。
(2). 你删除了一条记录,至少要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的记录插入到表中就好了。
(3). 你修改了一条记录,至少要把修改这条记录前的旧值都记录下来,这样之后回滚时再把这条记录更新为旧值就好了。
设计数据库的大叔把这些为了回滚而记录的这些东东称之为撤销日志,英文名为 undo log ,我们也可以土洋结合,称之为 undo日志 。这里需要注意的一点是,由于查询操作( SELECT )并不会修改任何用户记录,所以在查询操作执行时,并不需要记录相应的 undo日志 。在真实的 InnoDB 中, undo日志 其实并不像我们上边所说的那么简单,不同类型的操作产生的 undo日志 的格式也是不同的,不过先暂时把这些容易让人脑子糊的具体细节放一放,我们先回过头来看看 事务id 是个神马玩意儿。
2.事务id
2.1.给事务分配id的时机
我们前边在唠叨 事务简介 时说过,一个事务可以是一个只读事务,或者是一个读写事务:
(1). 我们可以通过 START TRANSACTION READ ONLY 语句开启一个只读事务。在只读事务中不可以对普通的表(其他事务也能访问到的表)进行增、删、改操作,但可以对临时表做增、删、改操作。
(2). 我们可以通过 START TRANSACTION READ WRITE 语句开启一个读写事务,或者使用 BEGIN 、 START TRANSACTION 语句开启的事务默认也算是读写事务。在读写事务中可以对表执行增删改查操作。
如果某个事务执行过程中对某个表执行了增、删、改操作,那么 InnoDB 存储引擎就会给它分配一个独一无二的事务id ,分配方式如下:
(1). 对于只读事务来说,只有在它第一次对某个用户创建的临时表执行增、删、改操作时才会为这个事务分配一个 事务id ,否则的话是不分配 事务id 的。
我们前边说过对某个查询语句执行EXPLAIN分析它的查询计划时,有时候在Extra列会看到Using temporary的提示,这个表明在执行该查询语句时会用到内部临时表。这个所谓的内部临时表和我们手动用CREATE TEMPORARY TABLE创建的用户临时表并不一样,在事务回滚时并不需要把执行SELECT语句过程中用到的内部临时表也回滚,在执行SELECT语句用到内部临时表时并不会为它分配事务 id。
(2). 对于读写事务来说,只有在它第一次对某个表(包括用户创建的临时表)执行增、删、改操作时才会为这个事务分配一个 事务id ,否则的话也是不分配 事务id 的。
有的时候虽然我们开启了一个读写事务,但是在这个事务中全是查询语句,并没有执行增、删、改的语句,那也就意味着这个事务并不会被分配一个 事务id 。
说了半天, 事务id 有啥子用?这个先保密哈,后边会一步步的详细唠叨。现在只要知道只有在事务对表中的记录做改动时才会为这个事务分配一个唯一的 事务id 。
2.2.事务id是怎么生成的
这个 事务id 本质上就是一个数字,它的分配策略和我们前边提到的对隐藏列 row_id (当用户没有为表创建主键和 UNIQUE 键时 InnoDB 自动创建的列)的分配策略大抵相同,具体策略如下:
(1). 服务器会在内存中维护一个全局变量,每当需要为某个事务分配一个 事务id 时,就会把该变量的值当作 事务id 分配给该事务,并且把该变量自增1。每当这个变量的值为 256 的倍数时,就会将该变量的值刷新到系统表空间的页号为 5 的页面中一个称之为 Max Trx ID 的属性处,这个属性占用 8 个字节的存储空间。
(2). 当系统下一次重新启动时,会将上边提到的 Max Trx ID 属性加载到内存中,将该值加上256之后赋值给我们前边提到的全局变量(因为在上次关机时该全局变量的值可能大于 Max Trx ID 属性值)。
这样就可以保证整个系统中分配的 事务id 值是一个递增的数字。先被分配 id 的事务得到的是较小的 事务id ,后被分配 id 的事务得到的是较大的 事务id 。
2.3.trx_id隐藏列
我们前边唠叨 InnoDB 记录行格式的时候重点强调过:聚簇索引的记录除了会保存完整的用户数据以外,而且还会自动添加名为trx_id、roll_pointer的隐藏列,如果用户没有在表中定义主键以及UNIQUE键,还会自动添加一个名为row_id的隐藏列。所以一条记录在页面中的真实结构看起来就是这样的:
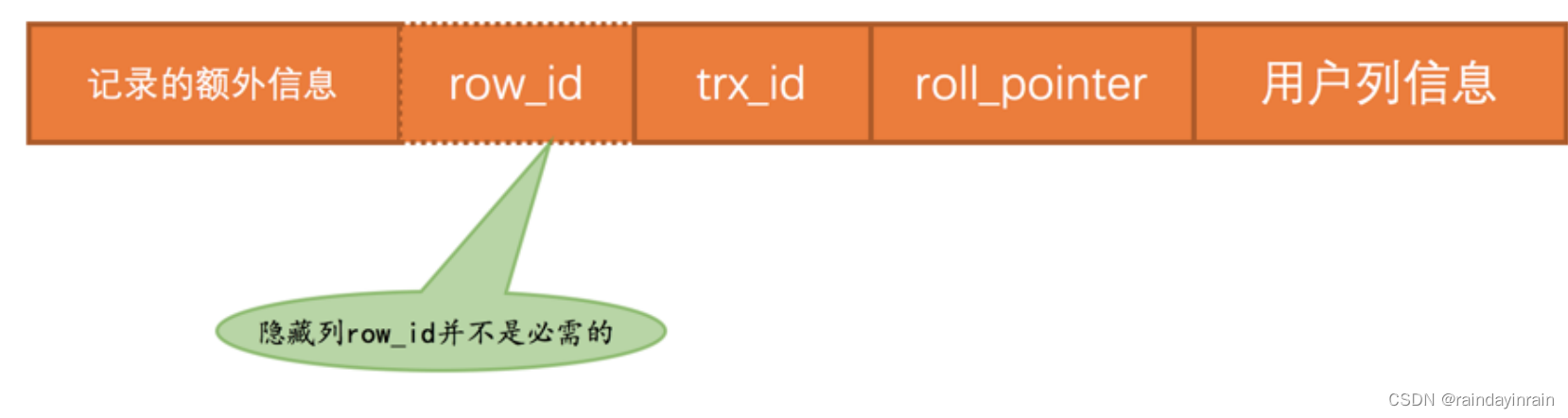
其中的 trx_id 列其实还蛮好理解的,就是某个对这个聚簇索引记录做改动的语句所在的事务对应的 事务id 而已(此处的改动可以是 INSERT 、 DELETE 、 UPDATE 操作)。至于 roll_pointer 隐藏列我们后边分析~
3.undo日志的格式
为了实现事务的 原子性 , InnoDB 存储引擎在实际进行增、删、改一条记录时,都需要先把对应的 undo日志 记下来。一般每对一条记录做一次改动,就对应着一条 undo日志 ,但在某些更新记录的操作中,也可能会对应着2条 undo日志 ,这个我们后边会仔细唠叨。一个事务在执行过程中可能新增、删除、更新若干条记录,也就是说需要记录很多条对应的 undo日志 ,这些 undo日志 会被从 0 开始编号,也就是说根据生成的顺序分别被称为 第0号undo日志 、 第1号undo日志 、…、 第n号undo日志 等,这个编号也被称之为 undo no 。
这些 undo日志 是被记录到类型为 FIL_PAGE_UNDO_LOG (对应的十六进制是 0x0002 ,忘记了页面类型是个啥的同学需要回过头再看看前边的章节)的页面中。这些页面可以从系统表空间中分配,也可以从一种专门存放 undo 日志 的表空间,也就是所谓的 undo tablespace 中分配。不过关于如何分配存储 undo日志 的页面这个事情我们稍后再说,现在先来看看不同操作都会产生什么样子的 undo日志 吧~ 为了故事的顺利发展,我们先来创建一个名为 undo_demo 的表:
CREATE TABLE undo_demo (id INT NOT NULL,key1 VARCHAR(100),col VARCHAR(100),PRIMARY KEY (id),KEY idx_key1 (key1)
)Engine=InnoDB CHARSET=utf8;
这个表中有3个列,其中 id 列是主键,我们为 key1 列建立了一个二级索引, col 列是一个普通的列。我们前边介绍 InnoDB 的数据字典时说过,每个表都会被分配一个唯一的 table id ,我们可以通过系统数据库 information_schema 中的 innodb_sys_tables 表来查看某个表对应的 table id 是什么,现在我们查看一下 undo_demo 对应的 table id 是多少:

从查询结果可以看出, undo_demo 表对应的 table id 为 1078,先把这个值记住,我们后边有用。
3.1.INSERT操作对应的undo日志
我们前边说过,当我们向表中插入一条记录时会有 乐观插入 和 悲观插入 的区分,但是不管怎么插入,最终导致的结果就是这条记录被放到了一个数据页中。如果希望回滚这个插入操作,那么把这条记录删除就好了,也就是说在写对应的 undo 日志时,主要是把这条记录的主键信息记上。所以设计 InnoDB 的大叔设计了一个类型为 TRX_UNDO_INSERT_REC 的 undo日志 ,它的完整结构如下图所示:
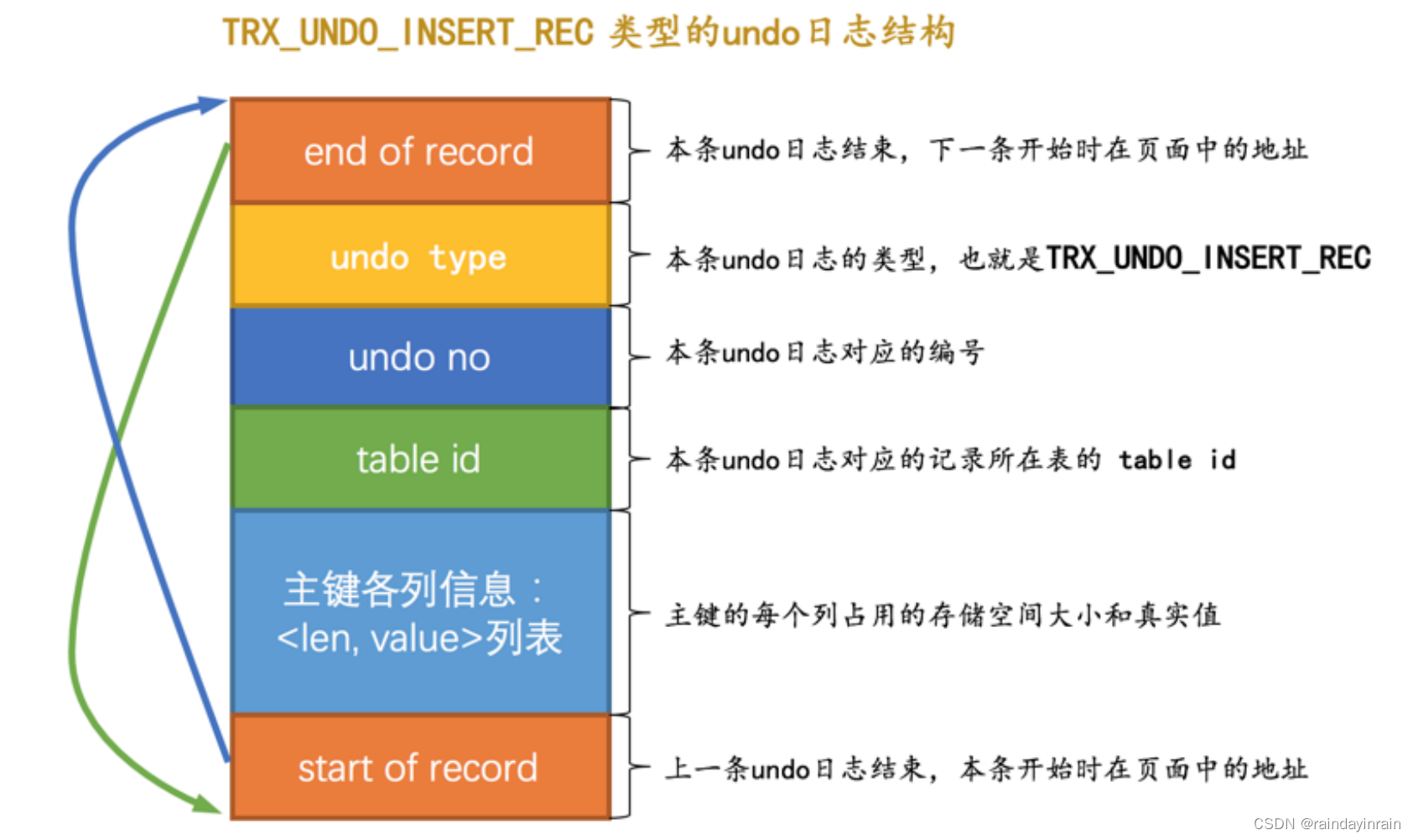
根据示意图我们强调几点:
(1). undo no 在一个事务中是从 0 开始递增的,也就是说只要事务没提交,每生成一条 undo日志 ,那么该条日志的 undo no 就增1。
(2). 如果记录中的主键只包含一个列,那么在类型为 TRX_UNDO_INSERT_REC 的 undo日志 中只需要把该列占用的存储空间大小和真实值记录下来,如果记录中的主键包含多个列,那么每个列占用的存储空间大小和对应的真实值都需要记录下来(图中的 len 就代表列占用的存储空间大小, value 就代表列的真实值)。
当我们向某个表中插入一条记录时,实际上需要向聚簇索引和所有的二级索引都插入一条记录。不过记录undo日志时,我们只需要考虑向聚簇索引插入记录时的情况就好了,因为其实聚簇索引记录和二级索引记录是一一对应的,我们在回滚插入操作时,只需要知道这条记录的主键信息,然后根据主键信息做对应的删除操作,做删除操作时就会顺带着把所有二级索引中相应的记录也删除掉。后边说到的DELETE操作和UPDATE操作对应的undo日志也都是针对聚簇索引记录而言的,我们之后就不强调了。
现在我们向 undo_demo 中插入两条记录:
BEGIN; # 显式开启一个事务,假设该事务的id为100
# 插入两条记录
INSERT INTO undo_demo(id, key1, col) VALUES (1, 'AWM', '狙击枪'), (2, 'M416', '步枪');
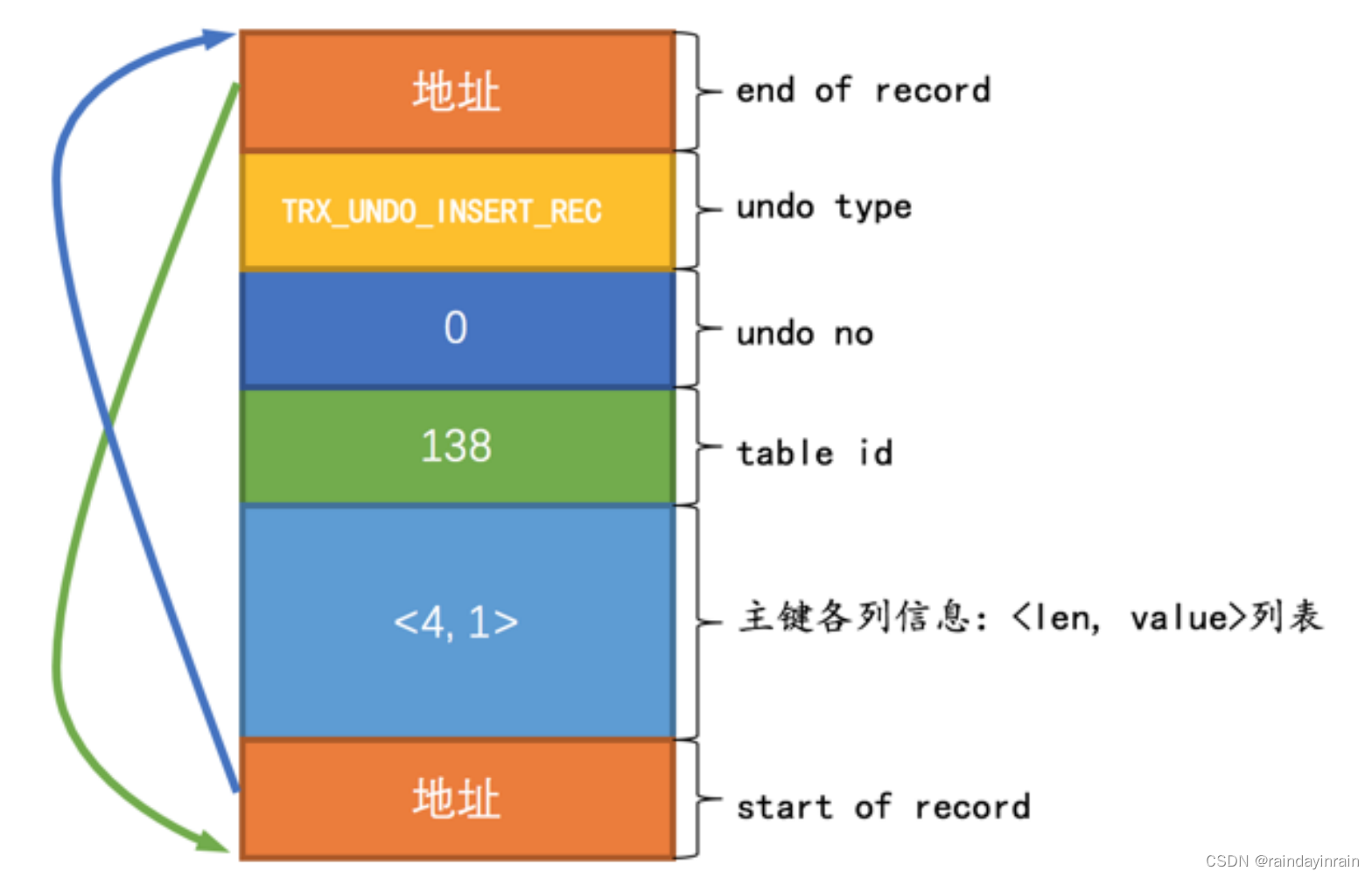
因为记录的主键只包含一个 id 列,所以我们在对应的 undo日志 中只需要将待插入记录的 id 列占用的存储空间长度( id 列的类型为 INT , INT 类型占用的存储空间长度为 4 个字节)和真实值记录下来。本例中会产生两条类型为TRX_UNDO_INSERT_REC 的 undo日志 :
(1). 第一条 undo日志 的 undo no 为 0 ,记录主键占用的存储空间长度为 4 ,真实值为 1 。画一个示意图就是这样:
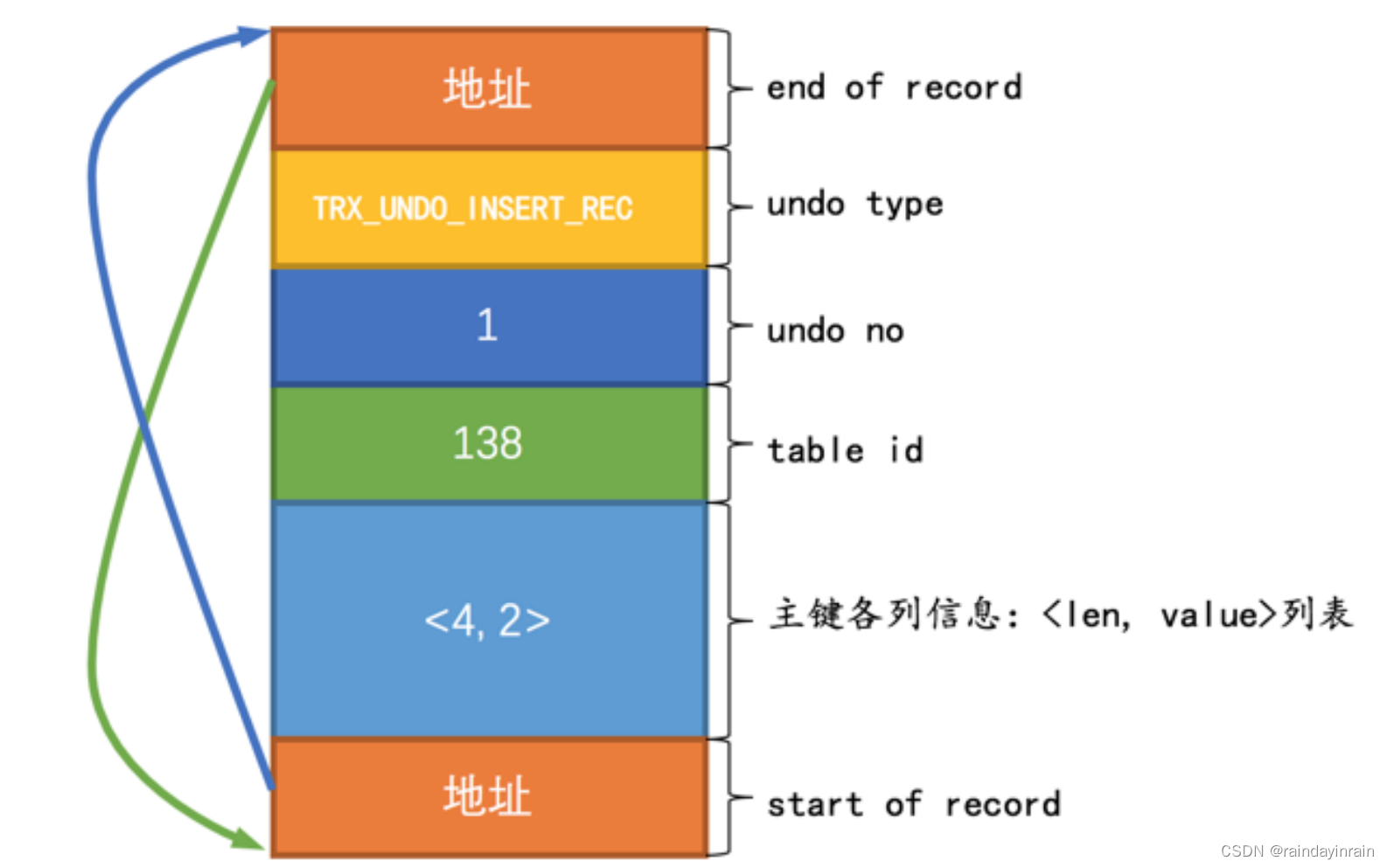
(2). 第二条 undo日志 的 undo no 为 1 ,记录主键占用的存储空间长度为 4 ,真实值为 2 。画一个示意图就是这样(与第一条 undo日志 对比, undo no 和主键各列信息有不同):
为了最大限度的节省undo日志占用的存储空间,和我们前边说过的redo日志类似,设计InnoDB的大叔会给undo日志中的某些属性进行压缩处理,具体的压缩细节我们就不唠叨了。
3.2.roll pointer隐藏列的含义
是时候揭开 roll_pointer 的真实面纱了,这个占用 7 个字节的字段其实一点都不神秘,本质上就是一个指向记录对应的 undo日志 的一个指针。比方说我们上边向 undo_demo 表里插入了2条记录,每条记录都有与其对应的一条 undo日志 。记录被存储到了类型为 FIL_PAGE_INDEX 的页面中(就是我们前边一直所说的 数据页 ),undo日志 被存放到了类型为 FIL_PAGE_UNDO_LOG 的页面中。效果如图所示:
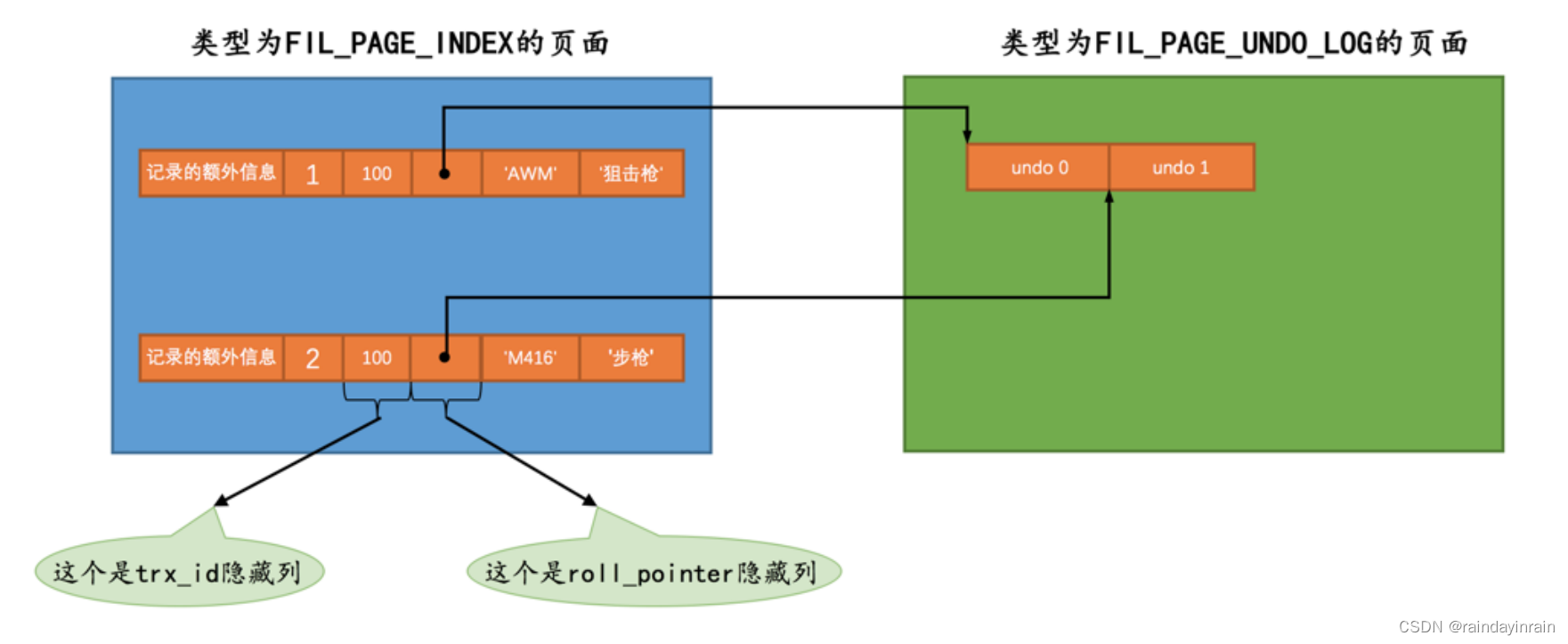
从图中也可以更直观的看出来, roll_pointer 本质就是一个指针,指向记录对应的undo日志。不过这 7 个字节的 roll_pointer 的每一个字节具体的含义我们后边唠叨完如何分配存储 undo 日志的页面之后再具体说哈~
3.2.DELETE操作对应的undo日志
我们知道插入到页面中的记录会根据记录头信息中的 next_record 属性组成一个单向链表,我们把这个链表称之为 正常记录链表 ;我们在前边唠叨数据页结构的时候说过,被删除的记录其实也会根据记录头信息中的next_record 属性组成一个链表,只不过这个链表中的记录占用的存储空间可以被重新利用,所以也称这个链表为 垃圾链表 。 Page Header 部分有一个称之为 PAGE_FREE 的属性,它指向由被删除记录组成的垃圾链表中的头节点。为了故事的顺利发展,我们先画一个图,假设此刻某个页面中的记录分布情况是这样的(这个不是 undo_demo 表中的记录,只是我们随便举的一个例子):
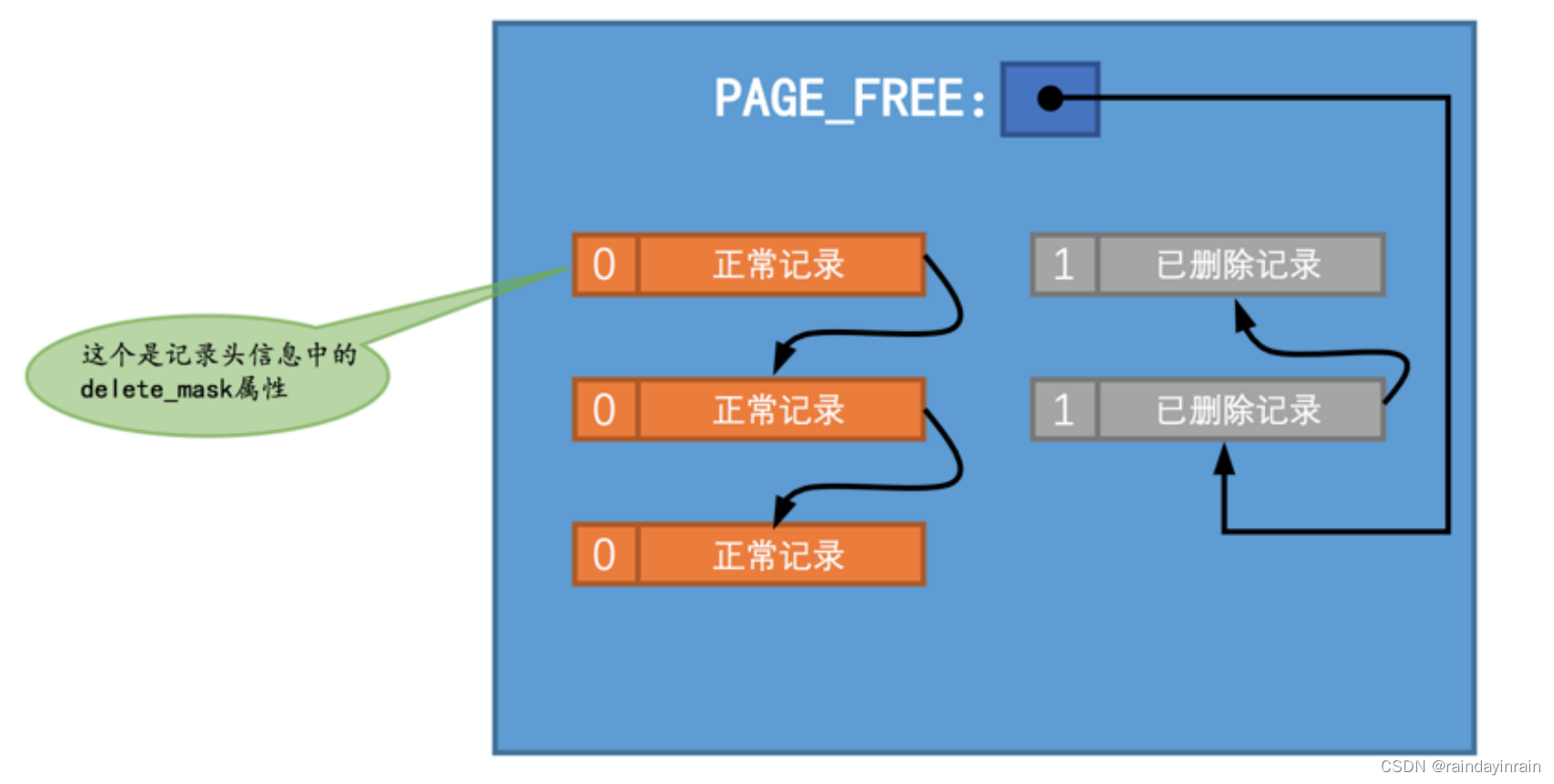
为了突出主题,在这个简化版的示意图中,我们只把记录的 delete_mask 标志位展示了出来。从图中可以看出, 正常记录链表 中包含了3条正常记录, 垃圾链表 里包含了2条已删除记录,在 垃圾链表 中的这些记录占用的存储空间可以被重新利用。页面的 Page Header 部分的 PAGE_FREE 属性的值代表指向 垃圾链表 头节点的指针。假设现在我们准备使用 DELETE 语句把 正常记录链表 中的最后一条记录给删除掉,其实这个删除的过程需要经历两个阶段:
(1). 仅仅将记录的 delete_mask 标识位设置为 1 ,其他的不做修改(其实会修改记录的 trx_id 、roll_pointer 这些隐藏列的值)。设计 InnoDB 的大叔把这个阶段称之为 delete mark 。
把这个过程画下来就是这样:
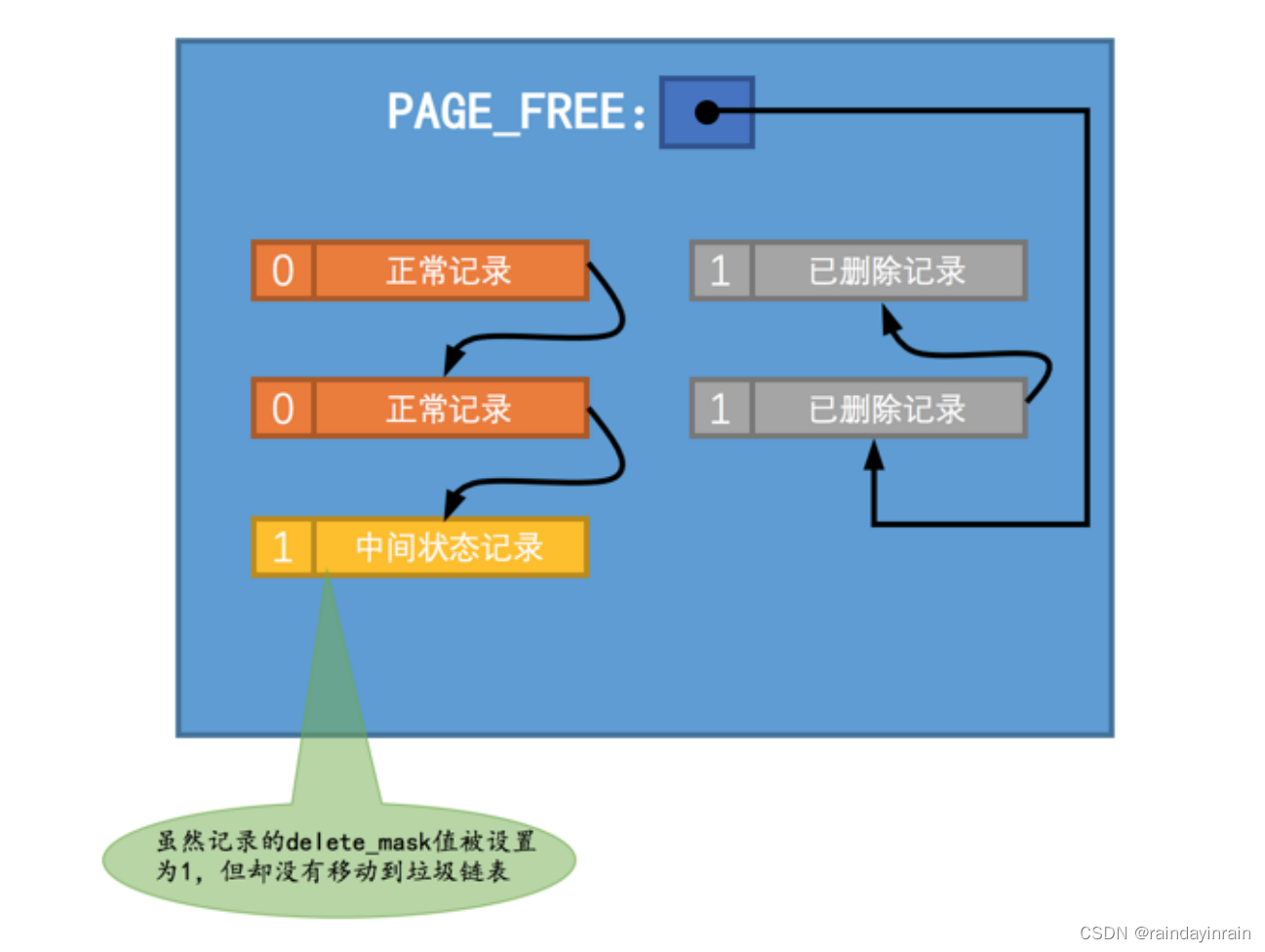
可以看到, 正常记录链表 中的最后一条记录的 delete_mask 值被设置为 1 ,但是并没有被加入到 垃圾链表 。也就是此时记录处于一个 中间状态 ,跟猪八戒照镜子——里外不是人似的。在删除语句所在的事务提交之前,被删除的记录一直都处于这种所谓的 中间状态 。
为啥会有这种奇怪的中间状态呢?其实主要是为了实现一个称之为MVCC的功能,哈哈,稍后再介绍。
(2). 当该删除语句所在的事务提交之后,会有专门的线程后来真正的把记录删除掉。所谓真正的删除就是把该记录从 正常记录链表 中移除,并且加入到 垃圾链表 中,然后还要调整一些页面的其他信息,比如页面中的用户记录数量 PAGE_N_RECS 、上次插入记录的位置 PAGE_LAST_INSERT 、垃圾链表头节点的指针PAGE_FREE 、页面中可重用的字节数量 PAGE_GARBAGE 、还有页目录的一些信息等等。设计 InnoDB 的大叔把这个阶段称之为 purge 。
把 阶段二 执行完了,这条记录就算是真正的被删除掉了。这条已删除记录占用的存储空间也可以被重新利用了。画下来就是这样:

对照着图我们还要注意一点,将被删除记录加入到 垃圾链表 时,实际上加入到链表的头节点处,会跟着修改 PAGE_FREE 属性的值。
页面的Page Header部分有一个PAGE_GARBAGE属性,该属性记录着当前页面中可重用存储空间占用的总字节数。每当有已删除记录被加入到垃圾链表后,都会把这个PAGE_GARBAGE属性的值加上该已删除记录占用的存储空间大小。PAGE_FREE指向垃圾链表的头节点,之后每当新插入记录时,首先判断PAGE_FREE指向的头节点代表的已删除记录占用的存储空间是否足够容纳这条新插入的记录,如果不可以容纳,就直接向页面中申请新的空间来存储这条记录(是的,你没看错,并不会尝试遍历整个垃圾链表,找到一个可以容纳新记录的点)。如果可以容纳,那么直接重用这条已删除记录的存储空间,并且把PAGE_FREE指向垃圾链表中的下一条已删除记录。但是这里有一个问题,如果新插入的那条记录占用的存储空间大小小于垃圾链表的头节点占用的存储空间大小,那就意味头节点对应的记录占用的存储空间里有一部分空间用不到,这部分空间就被称之为碎片空间。那这些碎片空间岂不是永远都用不到了么?其实也不是,这些碎片空间占用的存储空间大小会被统计到PAGE_GARBAGE属性中,这些碎片空间在整个页面快使用完前并不会被重新利用,不过当页面快满时,如果再插入一条记录,此时页面中并不能分配一条完整记录的空间,这时候会首先看一看PAGE_GARBAGE的空间和剩余可利用的空间加起来是不是可以容纳下这条记录,如果可以的话,InnoDB会尝试重新组织页内的记录,重新组织的过程就是先开辟一个临时页面,把页面内的记录依次插入一遍,因为依次插入时并不会产生碎片,之后再把临时页面的内容复制到本页面,这样就可以把那些碎片空间都解放出来(很显然重新组织页面内的记录比较耗费性能)。
从上边的描述中我们也可以看出来,在删除语句所在的事务提交之前,只会经历 阶段一 ,也就是 delete mark 阶段(提交之后我们就不用回滚了,所以只需考虑对删除操作的 阶段一 做的影响进行回滚)。设计 InnoDB 的大叔为此设计了一种称之为 TRX_UNDO_DEL_MARK_REC 类型的 undo日志 ,它的完整结构如下图所示:
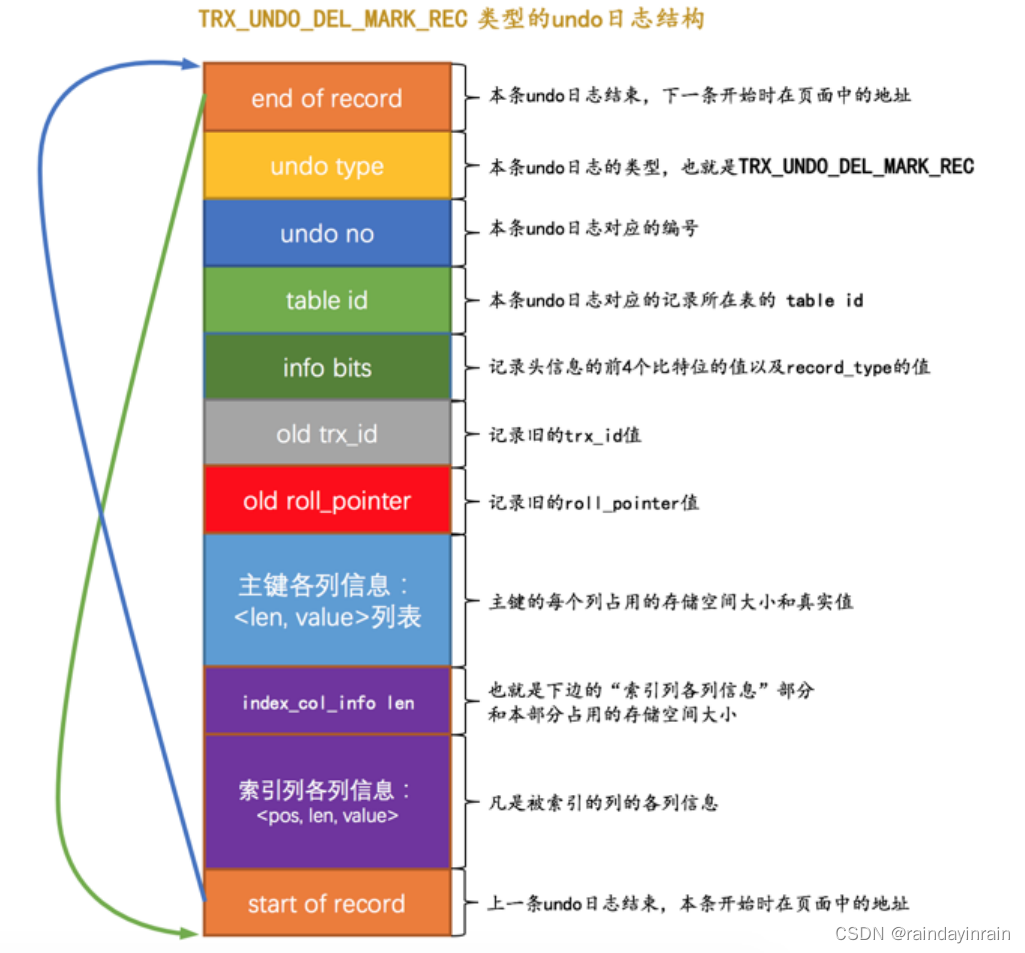
特别注意一下这几点:
(1). 在对一条记录进行 delete mark 操作前,需要把该记录的旧的 trx_id 和 roll_pointer 隐藏列的值都给记到对应的 undo日志 中来,就是我们图中显示的 old trx_id 和 old roll_pointer 属性。这样有一个好处,那就是可以通过 undo日志 的 old roll_pointer 找到记录在修改之前对应的 undo 日志。比方说在一个事务中,我们先插入了一条记录,然后又执行对该记录的删除操作,这个过程的示意图就是这样:

从图中可以看出来,执行完 delete mark 操作后,它对应的 undo 日志和 INSERT 操作对应的 undo 日志就串成了一个链表。这个很有意思啊,这个链表就称之为 版本链 ,现在貌似看不出这个 版本链 有啥用,等我们再往后看看,讲完 UPDATE 操作对应的 undo 日志后,这个所谓的 版本链 就慢慢的展现出它的牛逼之处了。
(2). 与类型为 TRX_UNDO_INSERT_REC 的 undo日志 不同,类型为 TRX_UNDO_DEL_MARK_REC 的 undo 日志还多了一个 索引列各列信息 的内容,也就是说如果某个列被包含在某个索引中,那么它的相关信息就应该被记录到这个 索引列各列信息 部分,所谓的相关信息包括该列在记录中的位置(用 pos 表示),该列占用的存储空间大小(用 len 表示),该列实际值(用 value 表示)。所以 索引列各列信息 存储的内容实质上就是<pos, len, value> 的一个列表。这部分信息主要是用在事务提交后,对该 中间状态记录 做真正删除的阶段二,也就是 purge 阶段中使用的,具体如何使用现在我们可以忽略~
该介绍的我们介绍完了,现在继续在上边那个事务id为 100 的事务中删除一条记录,比如我们把 id 为1的那条记录删除掉:
BEGIN; # 显式开启一个事务,假设该事务的id为100
# 插入两条记录
INSERT INTO undo_demo(id, key1, col) VALUES (1, 'AWM', '狙击枪'), (2, 'M416', '步枪');
# 删除一条记录
DELETE FROM undo_demo WHERE id = 1;
这个 delete mark 操作对应的 undo日志 的结构就是这样:
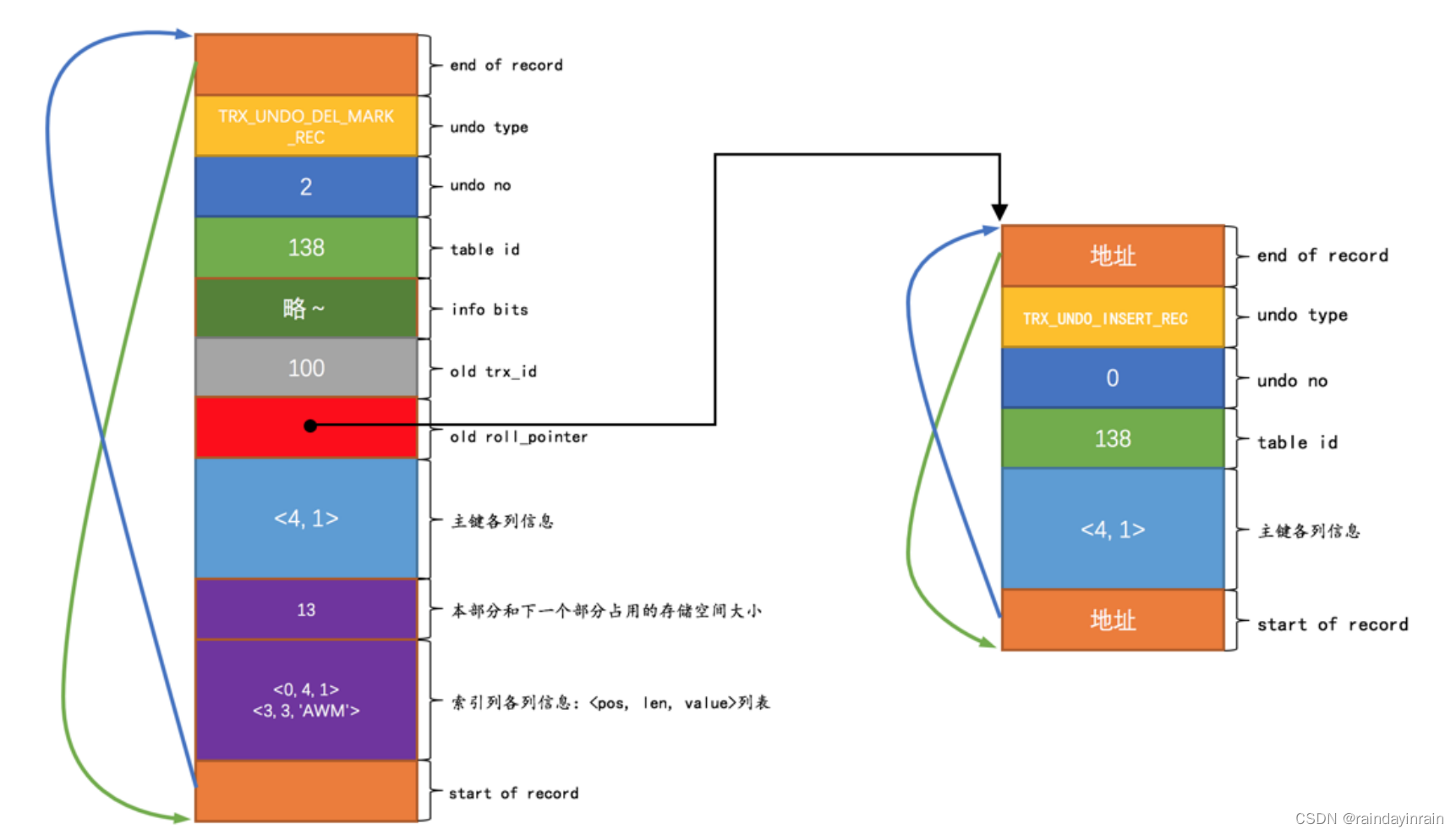
对照着这个图,我们得注意下边几点:
(1). 因为这条 undo 日志是 id 为 100 的事务中产生的第3条 undo 日志,所以它对应的 undo no 就是 2 。
(2). 在对记录做 delete mark 操作时,记录的 trx_id 隐藏列的值是 100 (也就是说对该记录最近的一次修改就发生在本事务中),所以把 100 填入 old trx_id 属性中。然后把记录的 roll_pointer 隐藏列的值取出来,填入 old roll_pointer 属性中,这样就可以通过 old roll_pointer 属性值找到最近一次对该记录做改动时产生的 undo日志 。
(3). 由于 undo_demo 表中有2个索引:一个是聚簇索引,一个是二级索引 idx_key1 。只要是包含在索引中的列,那么这个列在记录中的位置( pos ),占用存储空间大小( len )和实际值( value )就需要存储到 undo日志 中。
a. 对于主键来说,只包含一个 id 列,存储到 undo日志 中的相关信息分别是:
pos : id 列是主键,也就是在记录的第一个列,它对应的 pos 值为 0 。 pos 占用1个字节来存储。
len : id 列的类型为 INT ,占用4个字节,所以 len 的值为 4 。 len 占用1个字节来存储。
value :在被删除的记录中 id 列的值为 1 ,也就是 value 的值为 1 。 value 占用4个字节来存储。
画一个图演示一下就是这样:
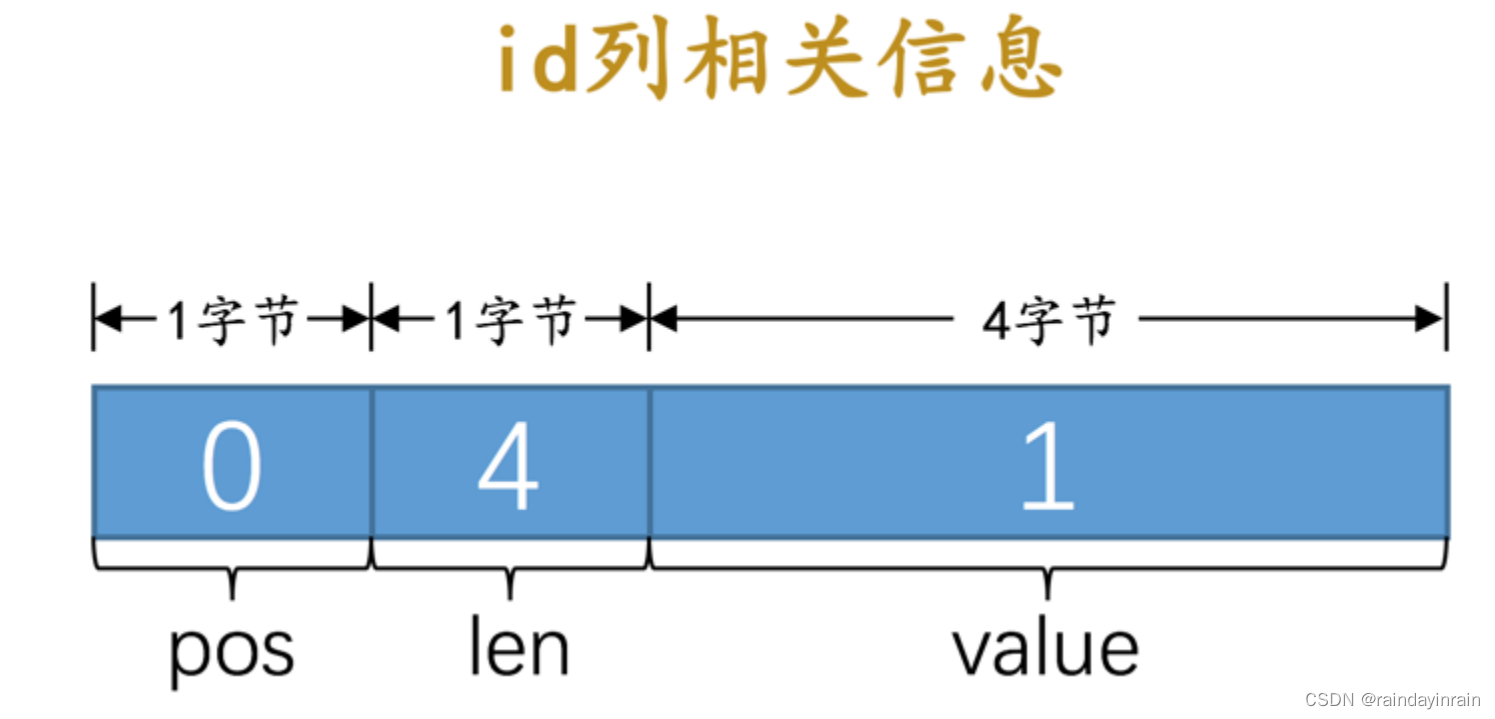
所以对于 id 列来说,最终存储的结果就是 <0, 4, 1> ,存储这些信息占用的存储空间大小为 1 + 1 + 4 = 6 个字节。
b. 对于 idx_key1 来说,只包含一个 key1 列,存储到 undo日志 中的相关信息分别是:
pos : key1 列是排在 id 列、 trx_id 列、 roll_pointer 列之后的,它对应的 pos 值为 3 。
pos 占用1个字节来存储。
len : key1 列的类型为 VARCHAR(100) ,使用 utf8 字符集,被删除的记录实际存储的内容是 AWM ,所以一共占用3个字节,也就是所以 len 的值为 3 。 len 占用1个字节来存储。
value :在被删除的记录中 key1 列的值为 AWM ,也就是 value 的值为 AWM 。 value 占用3个字节来存储。
画一个图演示一下就是这样:
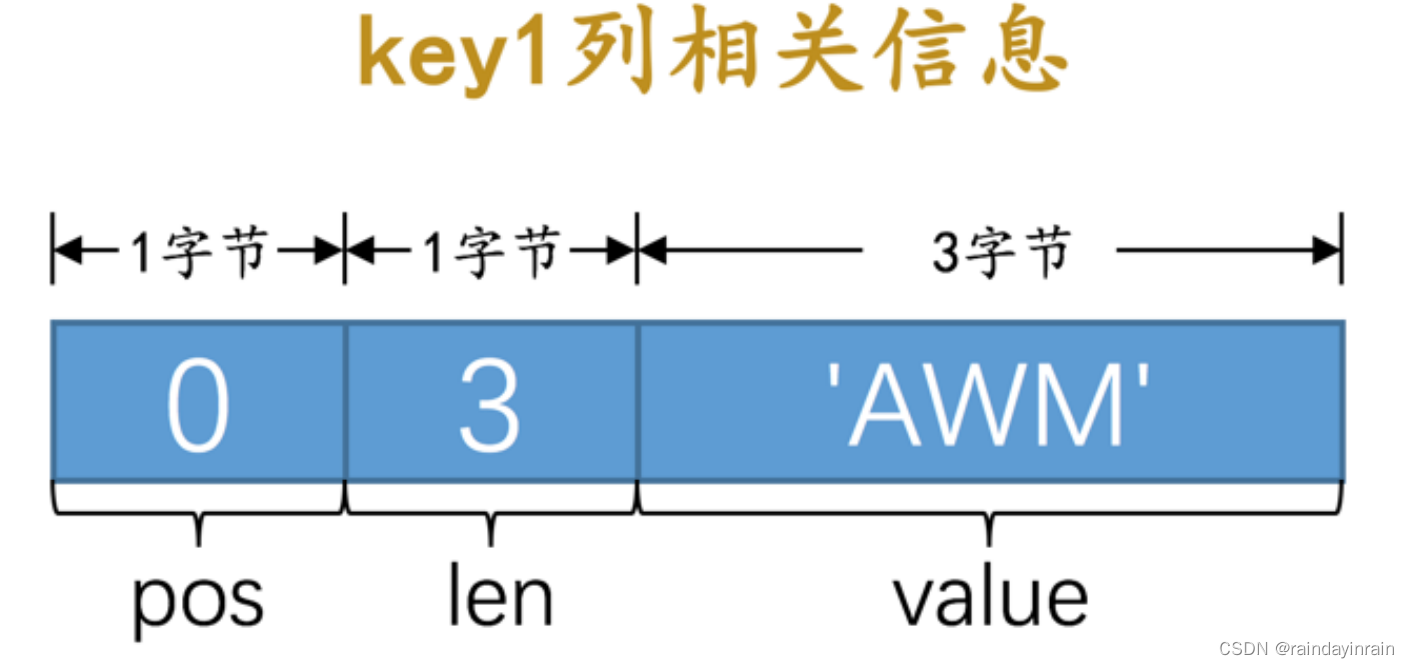
所以对于 key1 列来说,最终存储的结果就是 <3, 3, 'AWM'> ,存储这些信息占用的存储空间大小为 1 + 1 + 3 = 5 个字节。
从上边的叙述中可以看到, <0, 4, 1> 和 <3, 3, 'AWM'> 共占用 11 个字节。然后 index_col_info len 本身占用 2 个字节,所以加起来一共占用 13 个字节,把数字 13 就填到了 index_col_info len 的属性中。
3.3.UPDATE操作对应的undo日志
在执行 UPDATE 语句时, InnoDB 对更新主键和不更新主键这两种情况有截然不同的处理方案。
3.3.1.不更新主键的情况
在不更新主键的情况下,又可以细分为被更新的列占用的存储空间不发生变化和发生变化的情况。
(1). 就地更新(in-place update)
更新记录时,对于被更新的每个列来说,如果更新后的列和更新前的列占用的存储空间都一样大,那么就可以进行 就地更新 ,也就是直接在原记录的基础上修改对应列的值。再次强调一边,是每个列在更新前后占用的存储空间一样大,有任何一个被更新的列更新前比更新后占用的存储空间大,或者更新前比更新后占用的存储空间小都不能进行 就地更新 。比方说现在 undo_demo 表里还有一条 id 值为 2 的记录,它的各个列占用的大小如图所示(因为采用 utf8 字符集,所以 ‘步枪’ 这两个字符占用6个字节):
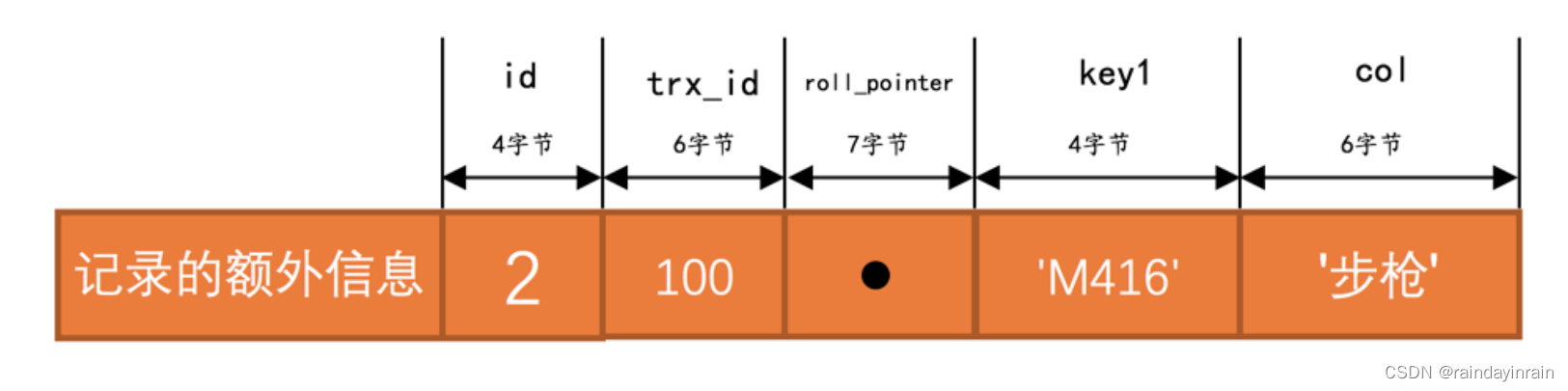
假如我们有这样的 UPDATE 语句:
UPDATE undo_demo SET key1 = 'P92', col = '手枪' WHERE id = 2;
在这个 UPDATE 语句中, col 列从 步枪 被更新为 手枪 ,前后都占用6个字节,也就是占用的存储空间大小未改变; key1 列从 M416 被更新为 P92 ,也就是从 4 个字节被更新为 3 个字节,这就不满足 就地更新 需要的条件了,所以不能进行 就地更新 。但是如果 UPDATE 语句长这样:
UPDATE undo_demo SET key1 = 'M249', col = '机枪' WHERE id = 2;
由于各个被更新的列在更新前后占用的存储空间是一样大的,所以这样的语句可以执行 就地更新 。
(2). 先删除掉旧记录,再插入新记录
在不更新主键的情况下,如果有任何一个被更新的列更新前和更新后占用的存储空间大小不一致,那么就需要先把这条旧的记录从聚簇索引页面中删除掉,然后再根据更新后列的值创建一条新的记录插入到页面中。请注意一下,我们这里所说的 删除 并不是 delete mark 操作,而是真正的删除掉,也就是把这条记录从 正常记录链表 中移除并加入到 垃圾链表 中,并且修改页面中相应的统计信息(比如 PAGE_FREE 、PAGE_GARBAGE 等这些信息)。不过这里做真正删除操作的线程并不是在唠叨 DELETE 语句中做 purge 操作时使用的另外专门的线程,而是由用户线程同步执行真正的删除操作,真正删除之后紧接着就要根据各个列更新后的值创建的新记录插入。
这里如果新创建的记录占用的存储空间大小不超过旧记录占用的空间,那么可以直接重用被加入到 垃圾链表 中的旧记录所占用的存储空间,否则的话需要在页面中新申请一段空间以供新记录使用,如果本页面内已经没有可用的空间的话,那就需要进行页面分裂操作,然后再插入新记录。
针对 UPDATE 不更新主键的情况(包括上边所说的就地更新和先删除旧记录再插入新记录),设计 InnoDB 的大叔们设计了一种类型为 TRX_UNDO_UPD_EXIST_REC 的 undo日志 ,它的完整结构如下:
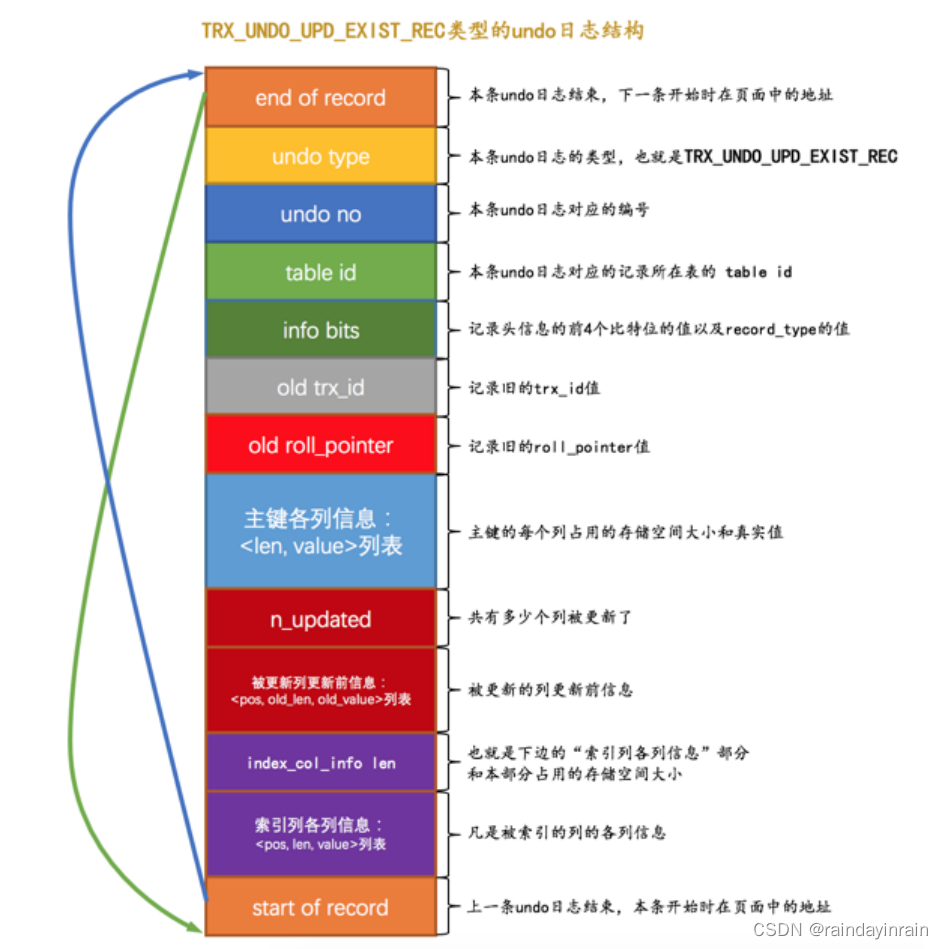
其实大部分属性和我们介绍过的 TRX_UNDO_DEL_MARK_REC 类型的 undo日志 是类似的,不过还是要注意这么几点:
(1). n_updated 属性表示本条 UPDATE 语句执行后将有几个列被更新,后边跟着的 <pos, old_len, old_value> 分别表示被更新列在记录中的位置、更新前该列占用的存储空间大小、更新前该列的真实值。
(2). 如果在 UPDATE 语句中更新的列包含索引列,那么也会添加 索引列各列信息 这个部分,否则的话是不会添加这个部分的。
现在继续在上边那个事务id为100的事务中更新一条记录,比如我们把id为2的那条记录更新一下:
BEGIN; # 显式开启一个事务,假设该事务的id为100
# 插入两条记录
INSERT INTO undo_demo(id, key1, col) VALUES (1, 'AWM', '狙击枪'), (2, 'M416', '步枪');
# 删除一条记录
DELETE FROM undo_demo WHERE id = 1;
# 更新一条记录
UPDATE undo_demo SET key1 = 'M249', col = '机枪' WHERE id = 2;
这个 UPDATE 语句更新的列大小都没有改动,所以可以采用 就地更新 的方式来执行,在真正改动页面记录时,会先记录一条类型为 TRX_UNDO_UPD_EXIST_REC 的 undo日志 ,长这样:
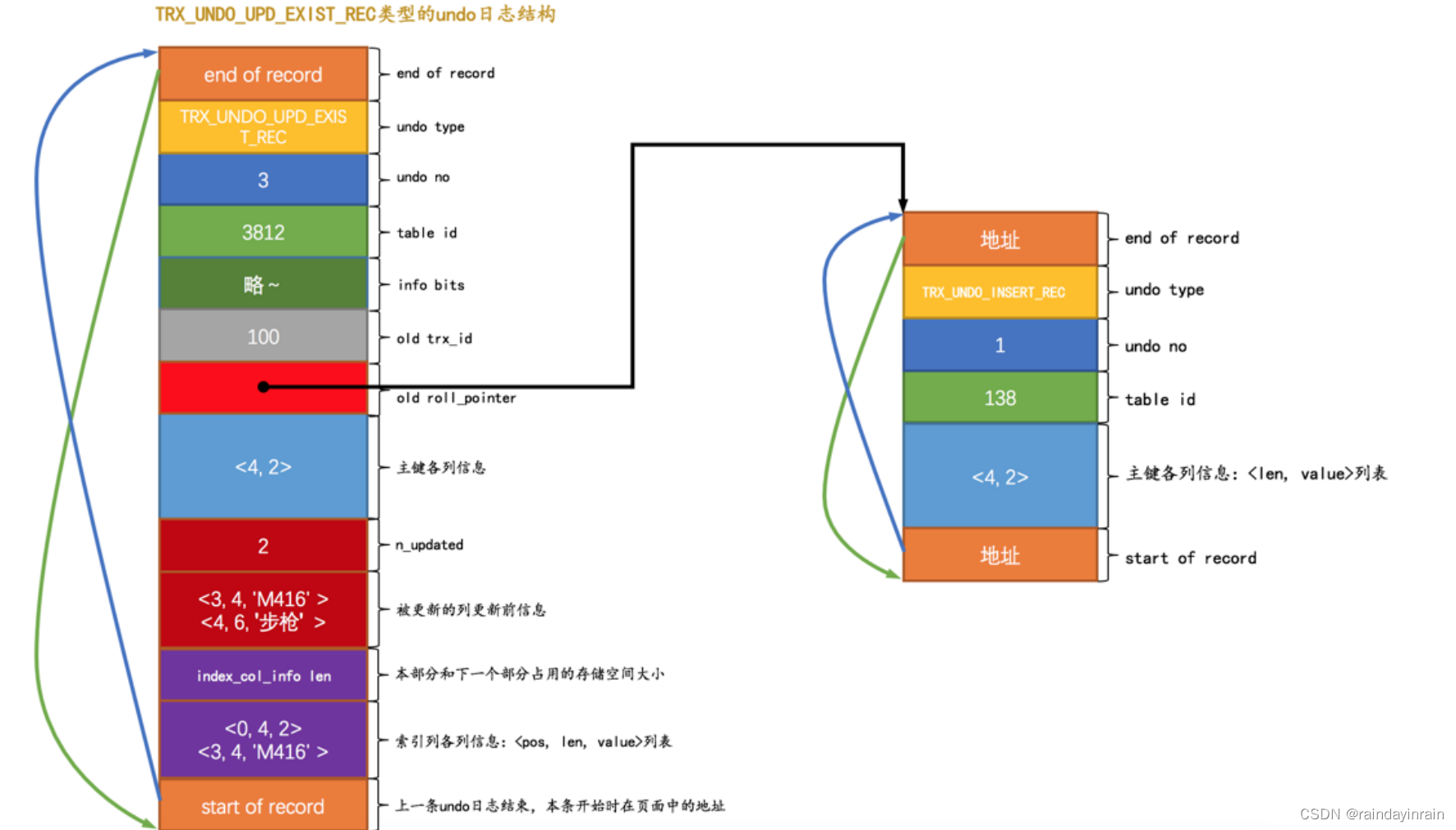
对照着这个图我们注意一下这几个地方:
(1). 因为这条 undo日志 是 id 为 100 的事务中产生的第4条 undo日志 ,所以它对应的 undo no 就是3。
(2). 这条日志的 roll_pointer 指向 undo no 为 1 的那条日志,也就是插入主键值为 2 的记录时产生的那条 undo日志 ,也就是最近一次对该记录做改动时产生的 undo日志 。
(3). 由于本条 UPDATE 语句中更新了索引列 key1 的值,所以需要记录一下 索引列各列信息 部分,也就是把主键和 key1 列更新前的信息填入。
3.3.2.更新主键的情况
在聚簇索引中,记录是按照主键值的大小连成了一个单向链表的,如果我们更新了某条记录的主键值,意味着这条记录在聚簇索引中的位置将会发生改变,比如你将记录的主键值从1更新为10000,如果还有非常多的记录的主键值分布在 1 ~ 10000 之间的话,那么这两条记录在聚簇索引中就有可能离得非常远,甚至中间隔了好多个页面。针对 UPDATE 语句中更新了记录主键值的这种情况, InnoDB 在聚簇索引中分了两步处理:
(1). 将旧记录进行 delete mark 操作
高能注意:这里是delete mark操作!这里是delete mark操作!这里是delete mark操作!也就是说在 UPDATE 语句所在的事务提交前,对旧记录只做一个 delete mark 操作,在事务提交后才由专门的线程做purge操作,把它加入到垃圾链表中。这里一定要和我们上边所说的在不更新记录主键值时,先真正删除旧记录,再插入新记录的方式区分开!
之所以只对旧记录做delete mark操作,是因为别的事务同时也可能访问这条记录,如果把它真正的删除加入到垃圾链表后,别的事务就访问不到了。这个功能就是所谓的MVCC,我们后边的章节中会详细唠叨什么是个MVCC。
(2). 根据更新后各列的值创建一条新记录,并将其插入到聚簇索引中(需重新定位插入的位置)。
由于更新后的记录主键值发生了改变,所以需要重新从聚簇索引中定位这条记录所在的位置,然后把它插进去。
针对 UPDATE 语句更新记录主键值的这种情况,在对该记录进行 delete mark 操作前,会记录一条类型为TRX_UNDO_DEL_MARK_REC 的 undo日志 ;之后插入新记录时,会记录一条类型为 TRX_UNDO_INSERT_REC 的 undo日志 ,也就是说每对一条记录的主键值做改动时,会记录2条 undo日志 。这些日志的格式我们上边都唠叨过了,就不赘述了。
其实还有一种称为TRX_UNDO_UPD_DEL_REC的undo日志的类型我们没有介绍,主要是想避免引入过多的复杂度,如果大家对这种类型的undo日志的使用感兴趣的话,可以额外查一下别的资料。
相关文章:
mysql原理--undo日志1
1.事务回滚的需求 我们说过 事务 需要保证 原子性 ,也就是事务中的操作要么全部完成,要么什么也不做。但是偏偏有时候事务执行到一半会出现一些情况,比如: (1). 事务执行过程中可能遇到各种错误,比如服务器本身的错误&…...
Zookeeper系列(一)集群搭建(非容器)
系列文章 Zookeeper系列(一)集群搭建(非容器) 目录 前言 下载 搭建 Data目录 Conf目录 集群复制和修改 启动 配置示例 测试 总结 前言 Zookeeper是一个开源的分布式协调服务,其设计目标是将那些复杂的且容易出错的分…...

【高等数学之泰勒公式】
一、从零开始 1.1、泰勒中值定理1 什么是泰勒公式?我们先看看权威解读: 那么我们从古至今到底是如何创造出泰勒公式的呢? 由上图可知,任一无穷小数均可以表示成用一系列数字的求和而得出的结果,我们称之为“无穷算法”。 那么同理我们想对任一曲线来…...
奇异值分解在图形压缩中的应用
奇异值分解在图形压缩中的应用 在研究奇异值分解的工程应用之前,我们得明白什么是奇异值?什么是奇异向量? 奇异值与奇异向量 概念:奇异值描述了矩阵在一组特定向量上的行为,奇异向量描述了其最大的作用方向。 奇异值…...

C++深入学习之STL:1、容器部分
标准模板库STL的组成 主要由六大基本组件组成:容器、迭代器、算法、适配器、函数对象(仿函数)以及空间配置器。 容器:就是用来存数据的,也称为数据结构。 本文要详述的是容器主要如下: 序列式容器:vector、list 关联…...

Javascript——vue下载blob文档流
<el-table-column label"操作" fixed"right" width"150" showOverflowTooltip><template slot-scope"scope"><el-button type"text" v-has"stbsd-gjcx-down" class"edit-button" click&…...

C# 的SequenceEqual
SequenceEqual 是 LINQ 扩展方法之一,用于比较两个序列(如数组、列表等)的元素是否相等。 该方法的详细定义如下: public static bool SequenceEqual<TSource>(this IEnumerable<TSource> first, IEnumerable<TS…...
)
第九部分 使用函数 (一)
目录 一、简介 二、函数的调用语法 一、简介 在 Makefile 中可以使用函数来处理变量,从而让我们的命令或是规则更为的灵活和具 有智能。make 所支持的函数也不算很多,不过已经足够我们的操作了。函数调用后,函数 的返回值可以当做变量来使用…...
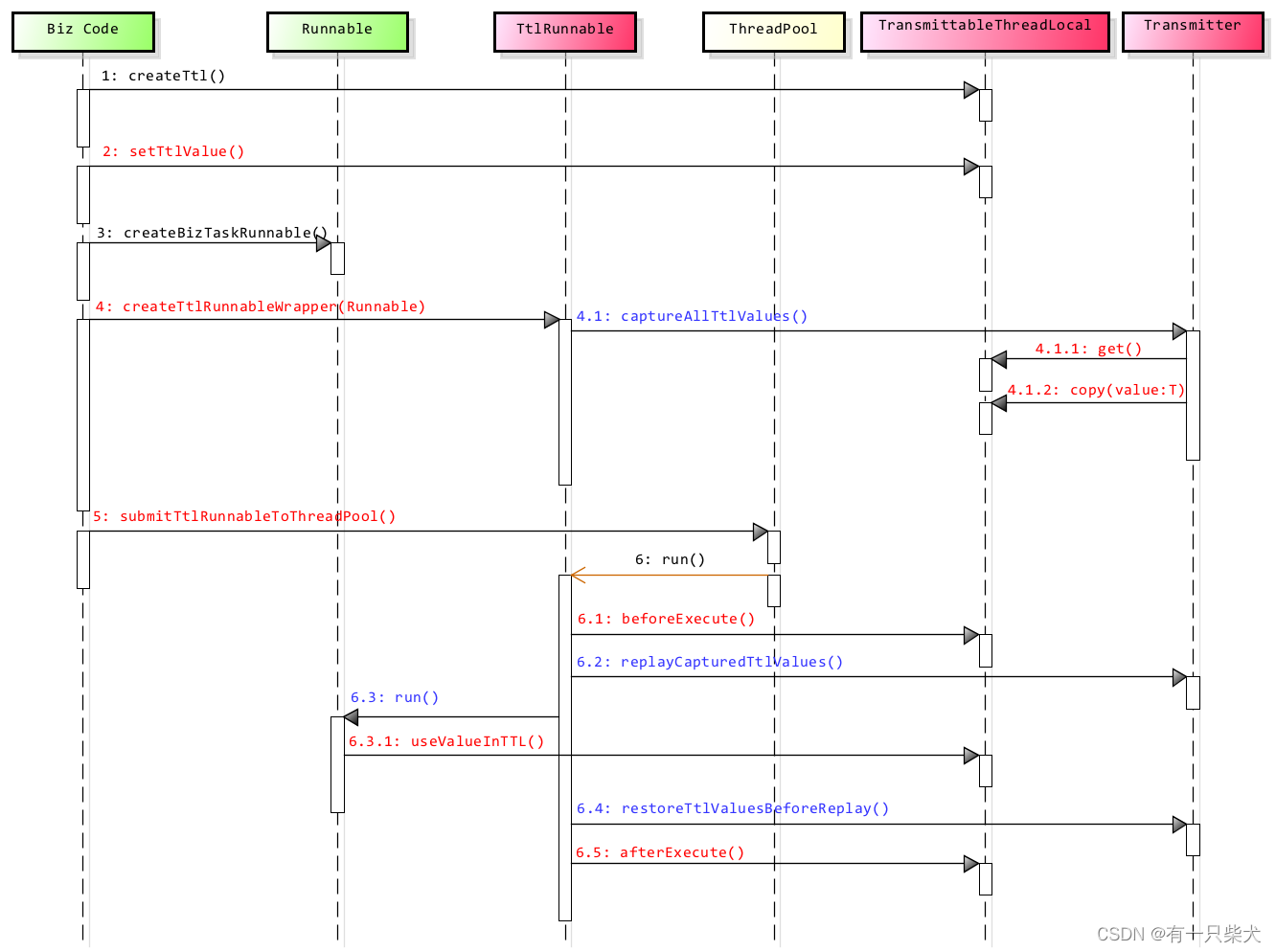
【JUC进阶】14. TransmittableThreadLocal
目录 1、前言 2、TransmittableThreadLocal 2.1、使用场景 2.2、基本使用 3、实现原理 4、小结 1、前言 书接上回《【JUC进阶】13. InheritableThreadLocal》,提到了InheritableThreadLocal虽然能进行父子线程的值传递,但是如果在线程池中&#x…...

基于C++的ORM框架sqlpp11入门介绍(附MySQL运行实例)
基本介绍 sqlpp11 是 C 的类型安全的 SQL 模版库。 Sqlpp11的官方下载地址是, GitHub - rbock/sqlpp11: A type safe SQL template library for C 在这里,可以找到官方的详细介绍文档, https://github.com/rbock/sqlpp11/tree/main/docs…...

对写文章的想法
一些思考 思考初心现在错觉想说的话 最后 思考 在CSDN里面写文章已经快半年了啊,虽然更得不多,但每一篇都花费很多时间,写的时候能帮自己查漏补缺,这边找找资料补充一下,都能去拓展自己的知识面,让自己的文…...
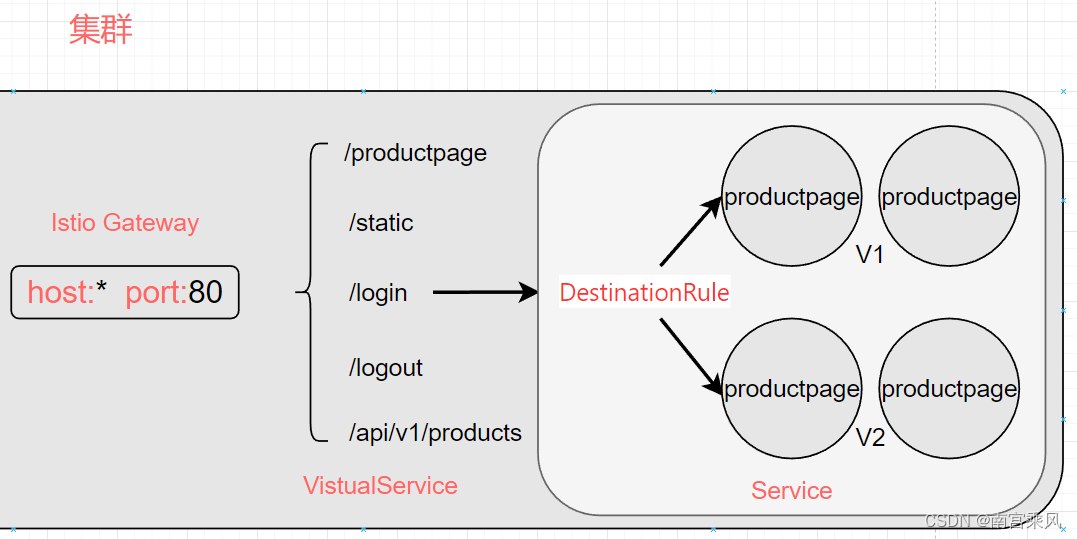
Istio安装和基础原理
1、Istio简介 Istio 是一个开源服务网格,它透明地分层到现有的分布式应用程序上。 Istio 强大的特性提供了一种统一和更有效的方式来保护、连接和监视服务。 Istio 是实现负载平衡、服务到服务身份验证和监视的路径——只需要很少或不需要更改服务代码。它强大的控…...

C++核心编程——基于多态的企业职工系统
本专栏记录C学习过程包括C基础以及数据结构和算法,其中第一部分计划时间一个月,主要跟着黑马视频教程,学习路线如下,不定时更新,欢迎关注。 当前章节处于: ---------第1阶段-C基础入门 ---------第2阶段实战…...
Nginx服务安装
Nginx(发音为[engine x])专为性能优化而开发,其最知名的优点是它的稳定性和低系统资源消 耗,以及对HTTP并发连接的高处理能力(单台物理服务器可支持30000~50000个并发请求)。正因 为如此,大量提供社交网络、…...

微信小程序canvas画布实现矩形元素自由缩放、移动功能
一、获取画布信息并绘制背景 .whml <canvas class="canvas" type="2d" id="myCanvas" bindtouchstart="get_rect_touch_position" bindtouchmove="move_or_scale" bind:tap="finish_edit_check"/> 定义c…...

一文搞懂 Python 3 中的数据类型
介绍 在 Python 中,与所有编程语言一样,数据类型用于对一种特定类型的数据进行分类。这很重要,因为您使用的特定数据类型将决定您可以为其分配哪些值以及您可以对其执行哪些操作(包括可以对其执行哪些操作)。 1. 数字…...
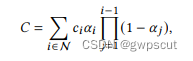
学习笔记之——3D Gaussian Splatting源码解读
之前博客对3DGS进行了学习与调研 学习笔记之——3D Gaussian Splatting及其在SLAM与自动驾驶上的应用调研-CSDN博客文章浏览阅读450次。论文主页3D Gaussian Splatting是最近NeRF方面的突破性工作,它的特点在于重建质量高的情况下还能接入传统光栅化,优…...
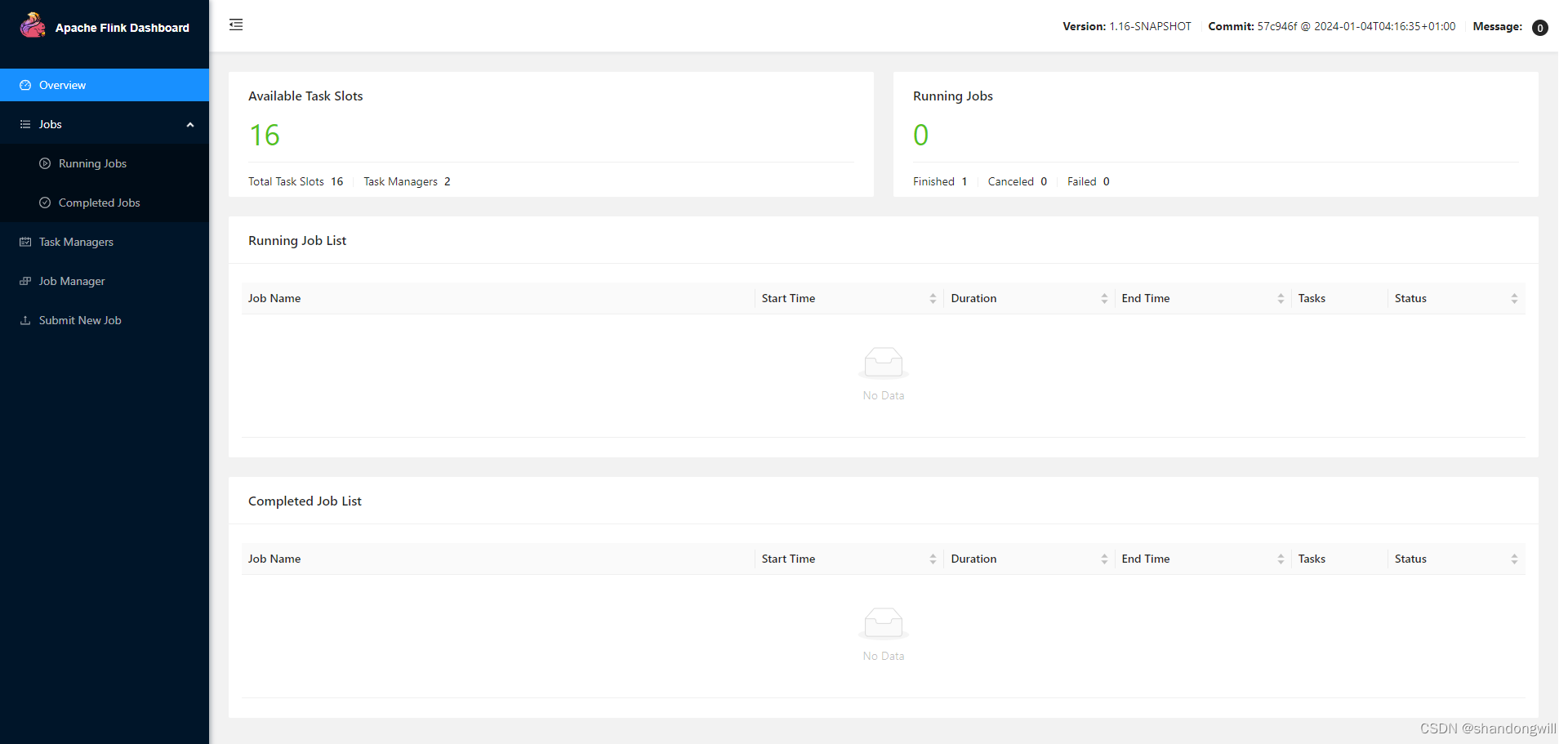
Flink standalone集群部署配置
文章目录 简介软件依赖部署方案二、安装1.下载并解压2.ssh免密登录3.修改配置文件3.启动集群4.访问 Web UI 简介 Flink独立模式(Standalone)是部署 Flink 最基本也是最简单的方式:所需要的所有 Flink 组件, 都只是操作系统上运行…...
 方法和 extend()方法的区别和用法)
Python: + 运算符、append() 方法和 extend()方法的区别和用法
在Python中,有几种常见的方式可以向列表中添加元素,其中包括使用 运算符、append() 方法和 extend() 方法。 使用 运算符: 运算符用于合并两个列表。 通过创建一个新列表,包含两个被合并的列表的元素。不会修改原始列表&…...
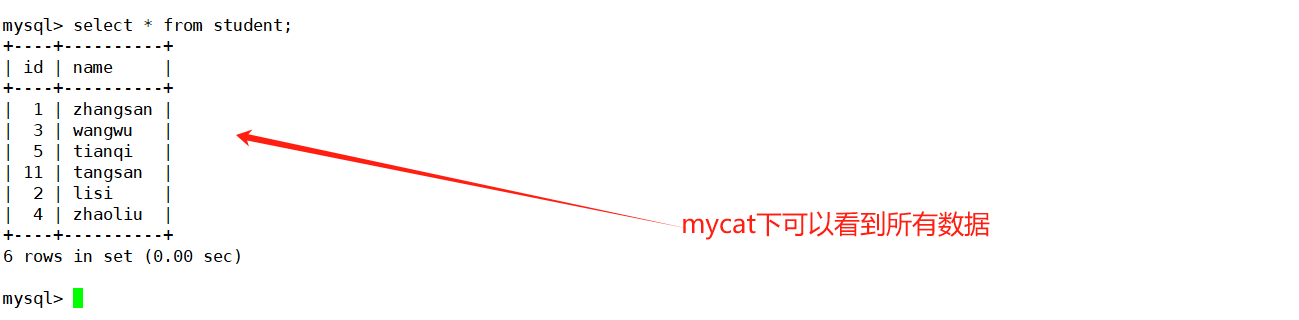
【MySQL】mysql集群
文章目录 一、mysql日志错误日志查询日志二进制日志慢查询日志redo log和undo log 二、mysql集群主从复制原理介绍配置命令 读写分离原理介绍配置命令 三、mysql分库分表垂直拆分水平拆分 一、mysql日志 MySQL日志 是记录 MySQL 数据库系统运行过程中不同事件和操作的信息的文件…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

DragonBones与Godot集成:骨骼动画的可编程化实践
1. 为什么在Godot里用DragonBones不是“锦上添花”,而是“绕不开的刚需” 去年上线一个横版动作手游Demo时,美术团队交来一套20个角色、每个角色含8套动画(待机/跑动/跳跃/攻击/受击/死亡/闪避/必杀)的Spine资源。我兴冲冲导入God…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...