【MySQL】mysql集群
文章目录
- 一、mysql日志
- 错误日志
- 查询日志
- 二进制日志
- 慢查询日志
- redo log和undo log
- 二、mysql集群
- 主从复制
- 原理介绍
- 配置命令
- 读写分离
- 原理介绍
- 配置命令
- 三、mysql分库分表
- 垂直拆分
- 水平拆分
一、mysql日志
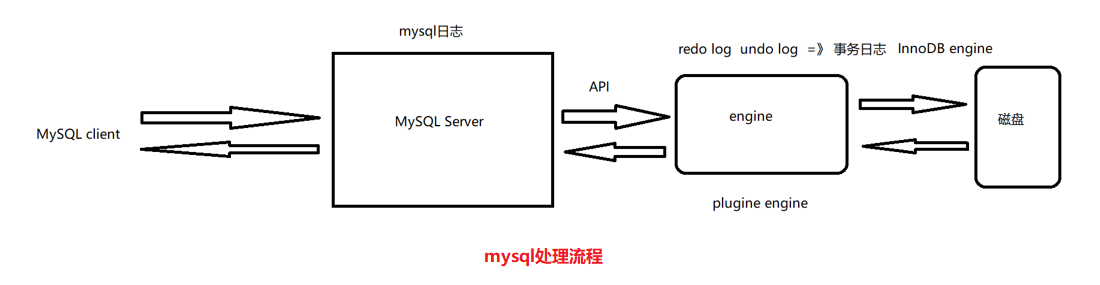
MySQL日志 是记录 MySQL 数据库系统运行过程中不同事件和操作的信息的文件。这些日志对于故障排除、性能调优、备份恢复以及复制等方面都非常重要。
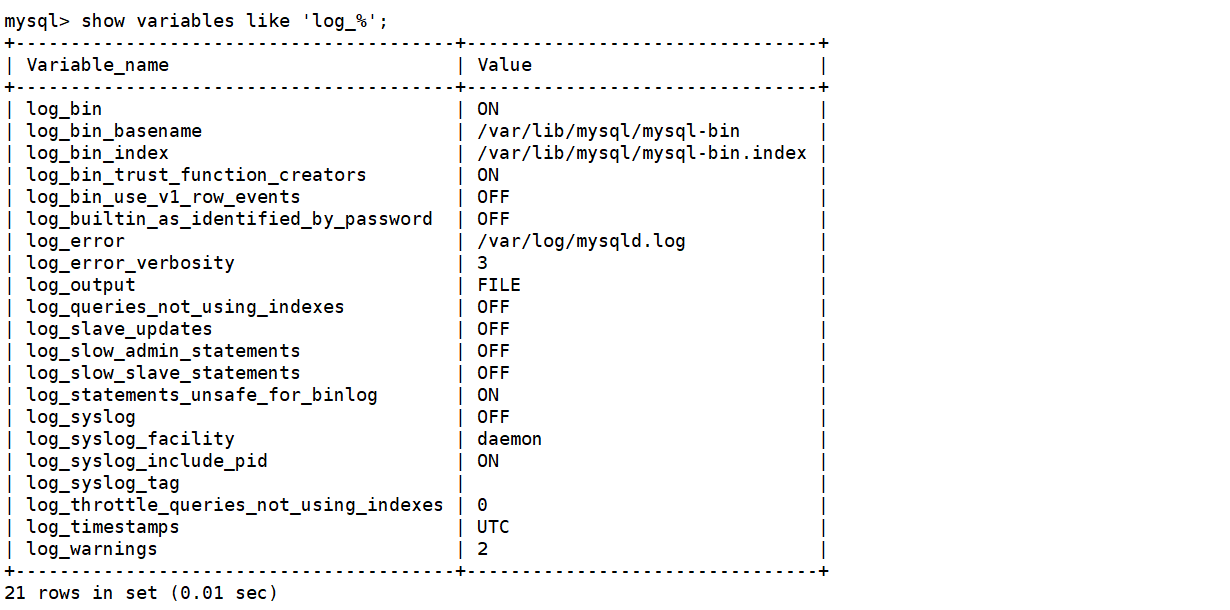
查看mysql中与日志相关的系统变量的配置信息:
show variables like 'log_%';
错误日志
错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,可以首先查看此日志。

mysqld 使用错误日志名 host_name.err(host_name 为主机名) 并默认在参数 DATADIR(数据目录)指定的目录中写入日志文件。
查询日志
查询日志
查询日志记录了客户端的所有语句。由于上线项目sql特别多,开启查询日志IO太多导致MySQL效率低,只有在调试时才开启,比如通过查看sql发现热点数据进行缓存。
mysql> show global variables like "%genera%";

二进制日志
二进制日志
二进制日志(BINLOG) 记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言) 语句,但是不包括数据查询语句。语句以“事件”的形式保存,它描述了数据的更改过程。 此日志对于灾难时的数据恢复起着极其重要的作用。

二进制日志的两个重要的应用场景:主从复制、数据恢复。
查看二进制日志:
show binary logs;

慢查询日志
慢查询日志
MySQL可以设置慢查询日志,当SQL执行的时间超过我们设定的时间,那么这些SQL就会被记录在慢查询日志当中,然后我们通过查看日志,用explain分析这些SQL的执行计划,来判定为什么效率低下,是没有使用到索引?还是索引本身创建的有问题?或者是索引使用到了,但是由于表的数据量太大,花费的时间就是很长,那么此时我们可以把表分成n个小表,比如订单表按年份分成多个小表等。

对于日志的配置,我们可以直接在 /etc/my.cnf 下配置即可。

redo log和undo log
redo log和undo log
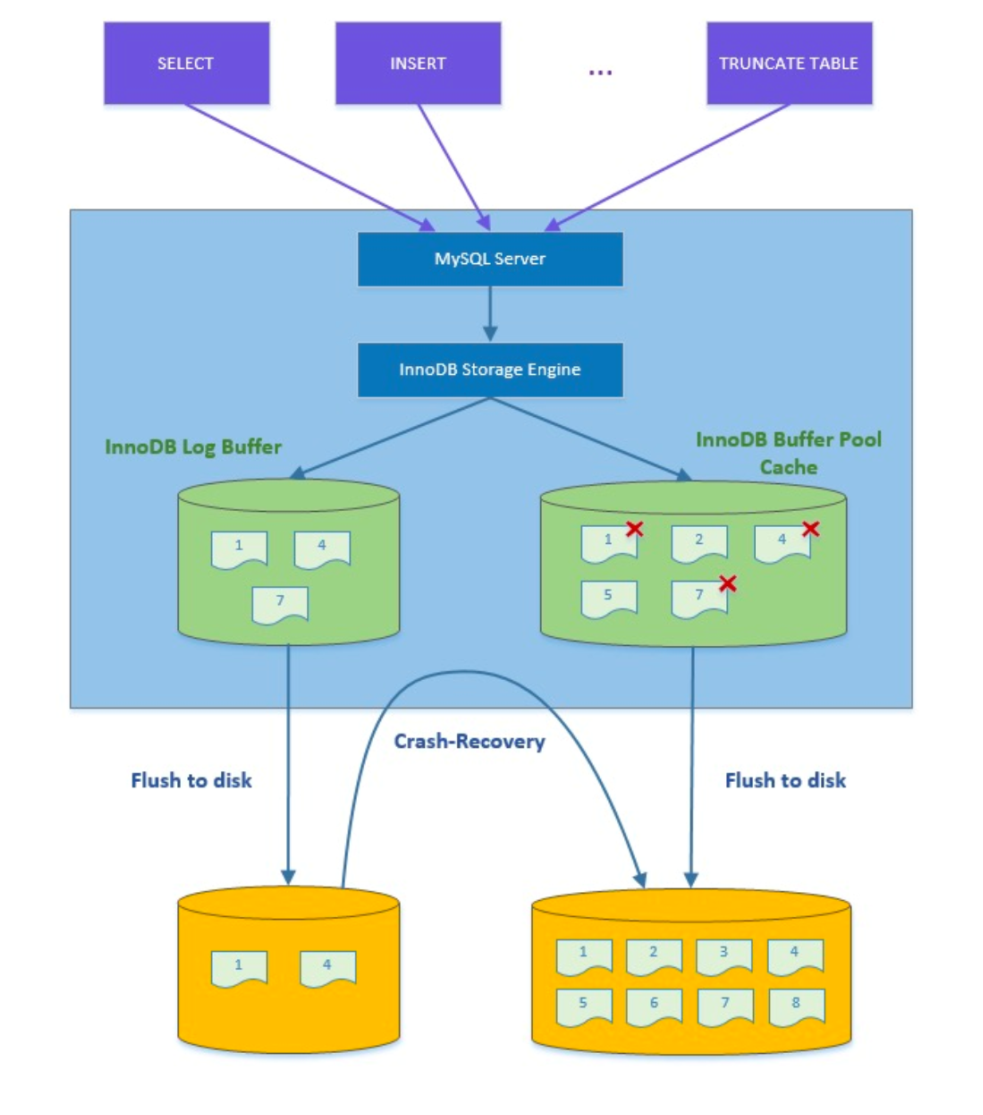
💕 redo log
redo log:重做日志,用于记录事务操作的变化,确保事务的持久性。
redo log 是在事务开始后就开始记录,不管事务是否提交都会记录下来,在异常发生时(如数据持久化过程中掉电),InnoDB会使用redo log恢复到掉电前的时刻, 保证数据的完整性。
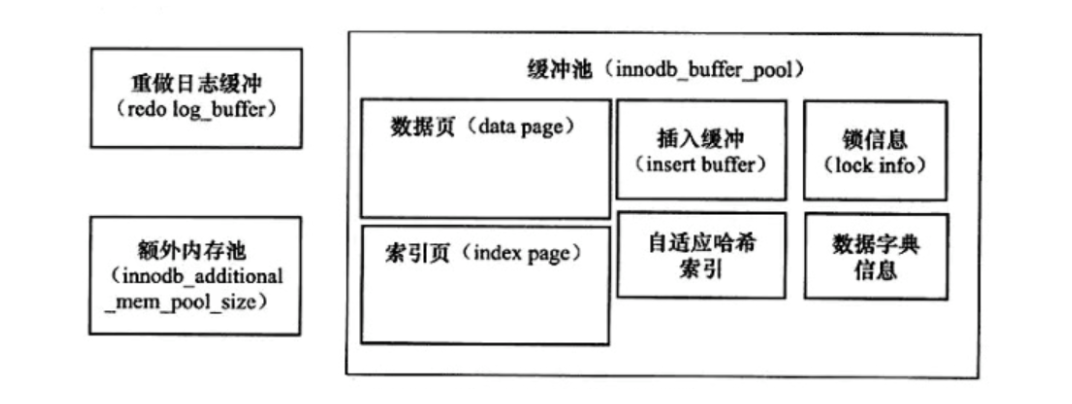
innodb_log_buffer_size 默认是16M,就是redo log缓冲区的大小,它随着事务开始,就开始写redolog,如果事务比较大,为了避免事务执行过程中花费过多磁盘IO,可以设置比较大的redo log缓存,节省磁盘IO。
InnoDB修改操作数据,不是直接修改磁盘上的数据,实际只是修改Buffer Pool中的数据。InnoDB总是先把Buffer Pool中的数据改变记录到redo log中,用来进行崩溃后的数据恢复。 优先记录redo log,然后再慢慢的将Buffer Pool中的脏数据刷新到磁盘上。
innodb_log_group_home_dir指定的目录下的两个文件:ib_logfile0和ib_logfile1,该文件被称作重做日志。
buffer pool 缓存池的作用:加速读和加速写,直接操作data page,写redo log修改就算完成,有专门的线程去做把bufferpool中的dirty page写入磁盘。
undo log
回滚日志,保存了事务发生之前的数据的一个版本,用于事务执行时的回滚操作,同时也是实现多版本并发控制(MVCC)下读操作的关键技术。详情见【MySQL】事务管理
二、mysql集群
在实际生产环境中,如果对mysql数据库的读和写都在一台数据库服务器中操作,无论是在安全性、高可用性,还是高并发等各个方面都是不能满足实际需求的,一般要通过 主从复制 的方式来同步数据,再通过 读写分离 来提升数据库的并发负载能力。
- 数据备份 - 热备份&容灾&高可用
- 读写分离,支持更大的并发
主从复制
原理介绍
主库提供对外的增删改查服务写入二进制日志(Binary log),从库通过特定的线程,将Binary log 日志中的内容同步到从库中。
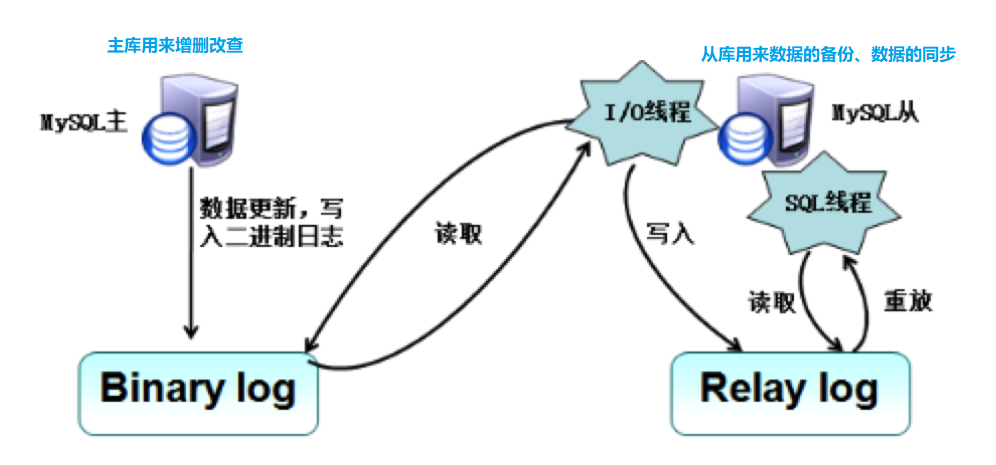
主从复制的流程: 两个日志(binlog二进制日志&relay log日志)和三个线程(master[主库]的一个线程和slave[从库]的二个线程)
- 主库的更新操作写入binlog二进制日志中。
- master服务器创建一个binlog转储线程,将二进制日志内容发送到从服务器。
- slave机器执行START SLAVE命令会在从服务器创建一个IO线程,接收master的binary log复制到其中继日志 Relay log。
首先slave开始一个工作线程(I/O线程),I/O线程在master上打开一个普通的连接,然后开始binlog dump process,binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件,I/O线程将这些事件写入中继日志。 - sql slave thread(sql从线程)处理该过程的最后一步,sql线程从中继日志中读取事件,并重放其中的事件而更新slave机器的数据,使其与master的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于os缓存中,所以中继日志的开销很小。
配置命令
配置命令
这里我们以Linux下的mysql作为主库,Windows下的mysql作为从库来进行演示。
master(centos7) :192.168.29.128
slave(win10):192.168.3.7
保证master和salve之间网络互通。并且保证3306端口是开放的。
master配置
- 开启二进制日志,然后重启mysqld服务

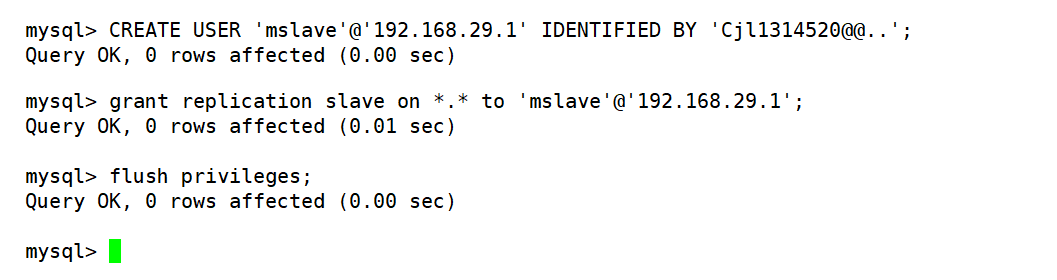
- 创建一个用于主从库通信用的账号
mysql> CREATE USER 'mslave'@'192.168.29.1' IDENTIFIED BY 'Cjl1314520@@..';
mysql> GRANT REPLICATION SLAVE ON *.* to 'mslave'@'192.168.29.1';
mysql> FLUSH PRIVILEGES;
- 获取binlog的日志文件名和position
mysql> show master status;

slave配置
-
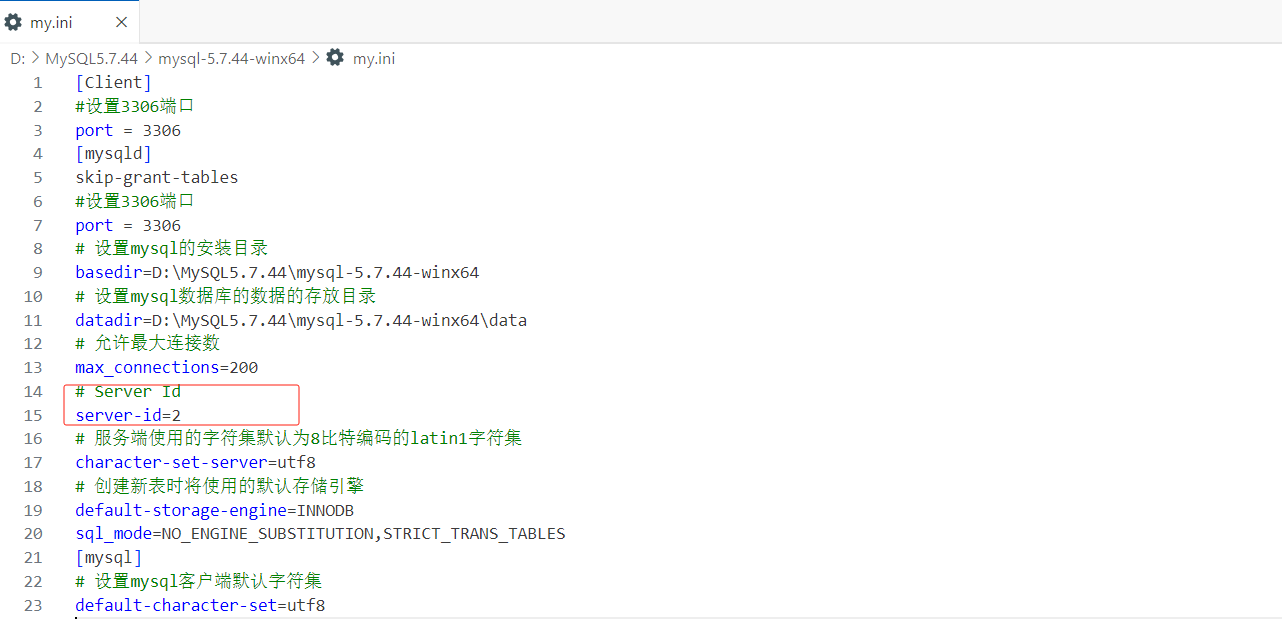
配置全局唯一的server-id(涉及修改配置文件,需要重启mysql57服务)
-
使用master创建的账户读取binlog同步数据(stop slave;start slave)

mysql> CHANGE MASTER TO MASTER_HOST='192.168.29.128',
MASTER_PORT=3306,
MASTER_USER='mslave',
MASTER_PASSWORD='Cjl1314520@@..',
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS=765;


- START SLAVE
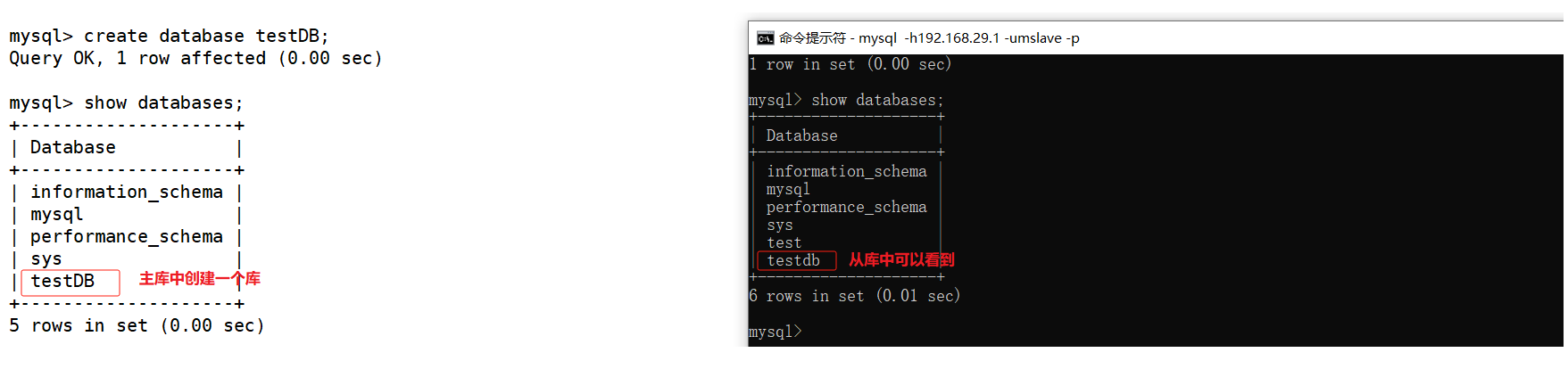
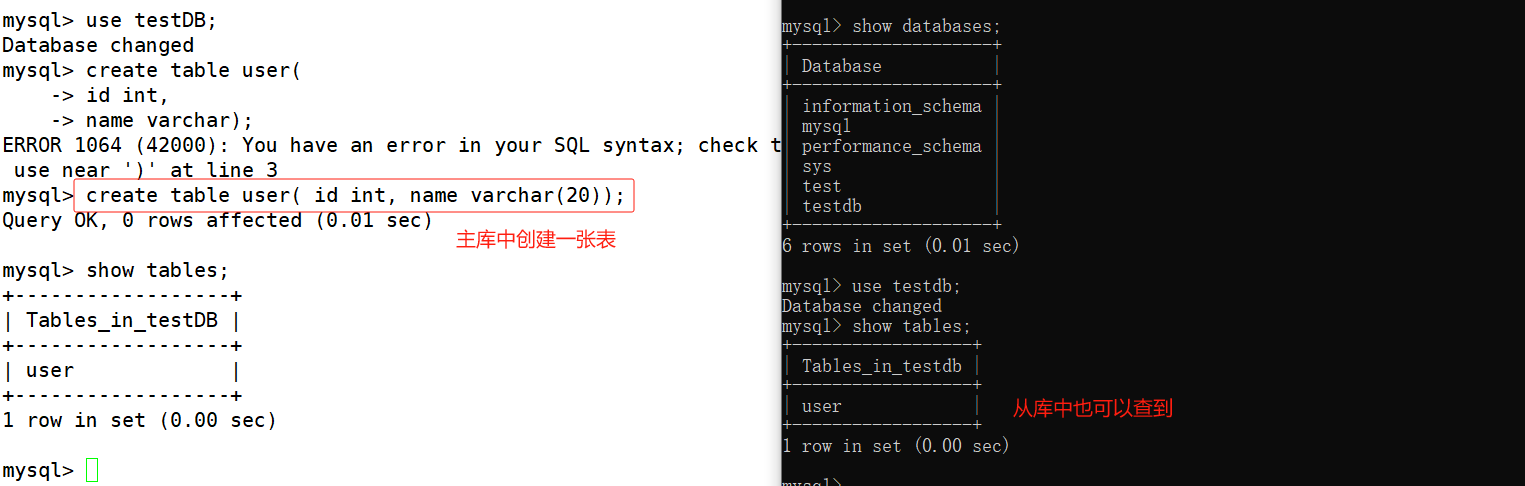
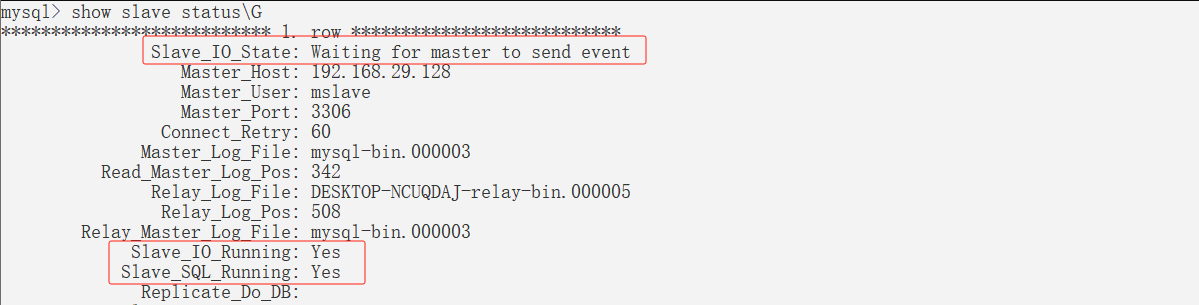
通过show slave status命令查看主从复制状态。show processlist查看master和salve相关线程的运行状态。
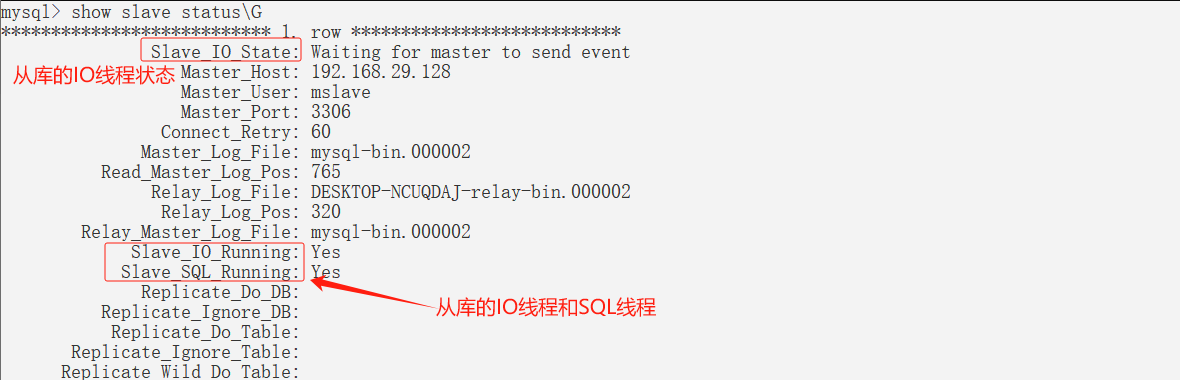
下面我们来看一下现象:
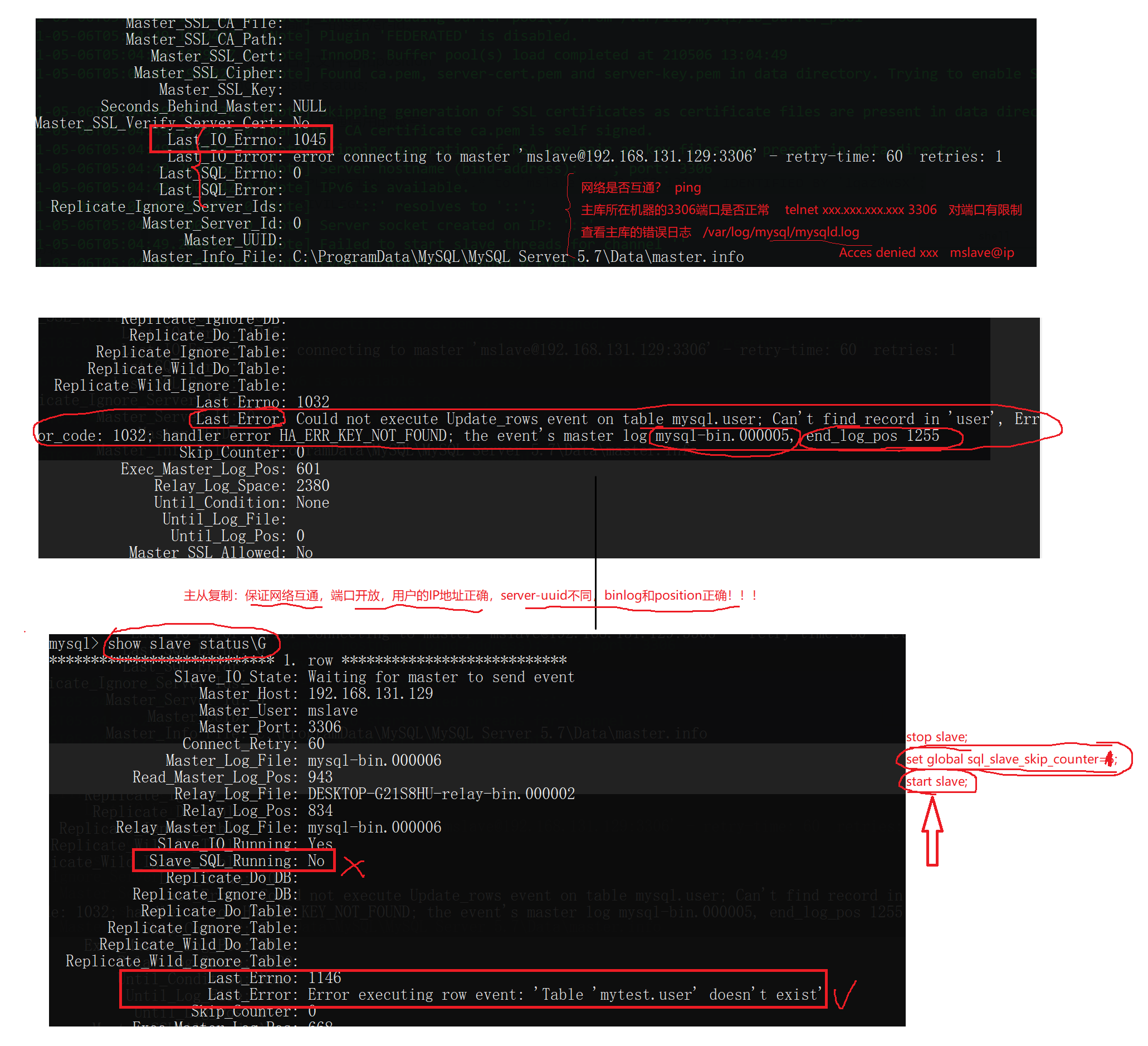
下面我们来看一下在搭建主从复制环境中可能会遇到的一些常见问题以及解决方案:
读写分离
原理介绍
MySQL读写分离 是一种常见的数据库架构设计模式,主要是为了提高系统的性能和可用性。它通过将读操作和写操作分离到不同的MySQL实例上来实现。
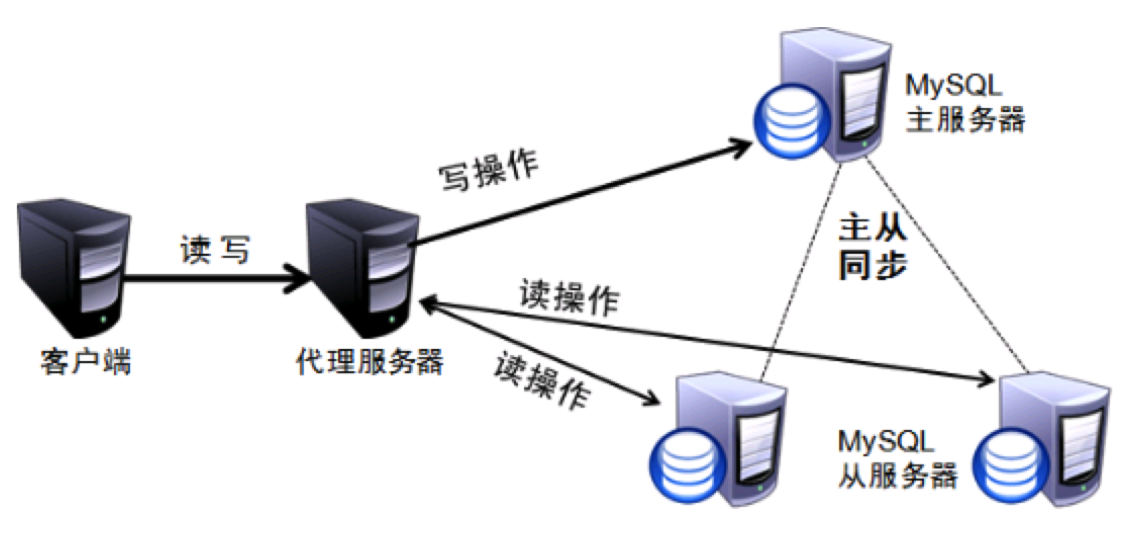
在实际的生产环境中,如果对数据库的读和写都在同一个数据库服务器中操作,无论是安全性,高可用还是并发等各个方面都不能完全满足实际需求的,因此一般来说都是通过主从复制的方式来同步数据,再通过读写分离来提供数据的高并发负载能力这样的方案来进行部署。
简单来说,读写分离就是只在主服务器上写,只在从服务器上读,基本的原理是让主数据库处理事务性查询,而从数据库处理select查询,数据库复制被用来把事务性查询导致的改变更新同步到集群中的从数据库。
目前较为常见的MySQL读写分离方式有:
- 程序代码内部实现
- 引入中间代理层
- MySQL_proxy
- Mycat
实际的开发过程中我们不能将代码和主从环境强行绑定,因为和环境强相关了,我们写代码得时候必须得知道哪个机器是负责写操作的主库,哪个机器是负责读操作的从库,由代码来选择。而这时如果有某个机器挂掉了,代码也不会知道,还是按照原来的方式转发请求,通信就会出现问题,所以把读写分离用代码实现肯定不合适。所以在实际的解决方案中,读写分离需要依赖数据库的中间件。
客户端实际上区分不出来连的是MyCat还是MySQL,因为通信都是遵守的是MySQL通信协议,之前怎么和MySQL通信,现在就怎么和MyCat通信,所以不用进行区分。
在MyCat上配置读写分离,我们在客户端上的代码不用做任何变更,代码上不需要区分哪个请求是读,哪个请求是写,代码直接访问的是MyCat,由MyCat解析请求,根据SQL的读写性质转发到负责相应操作的服务器,实现读写分离。
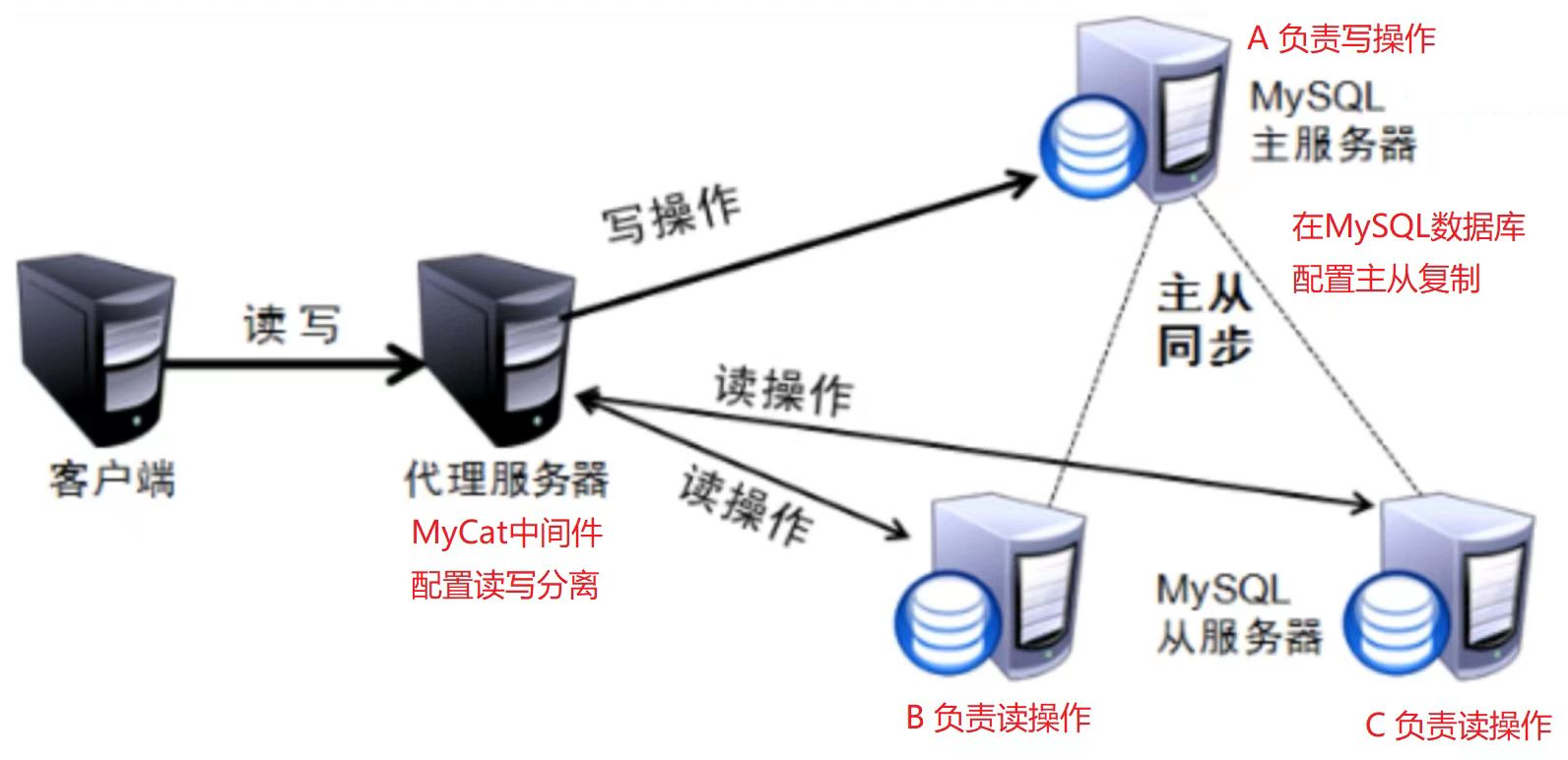
在Mycat上需要配置主服务器和从服务器的信息,有3种情况:一主一从、一主多从、多主多从。
一主一从:
多主多从
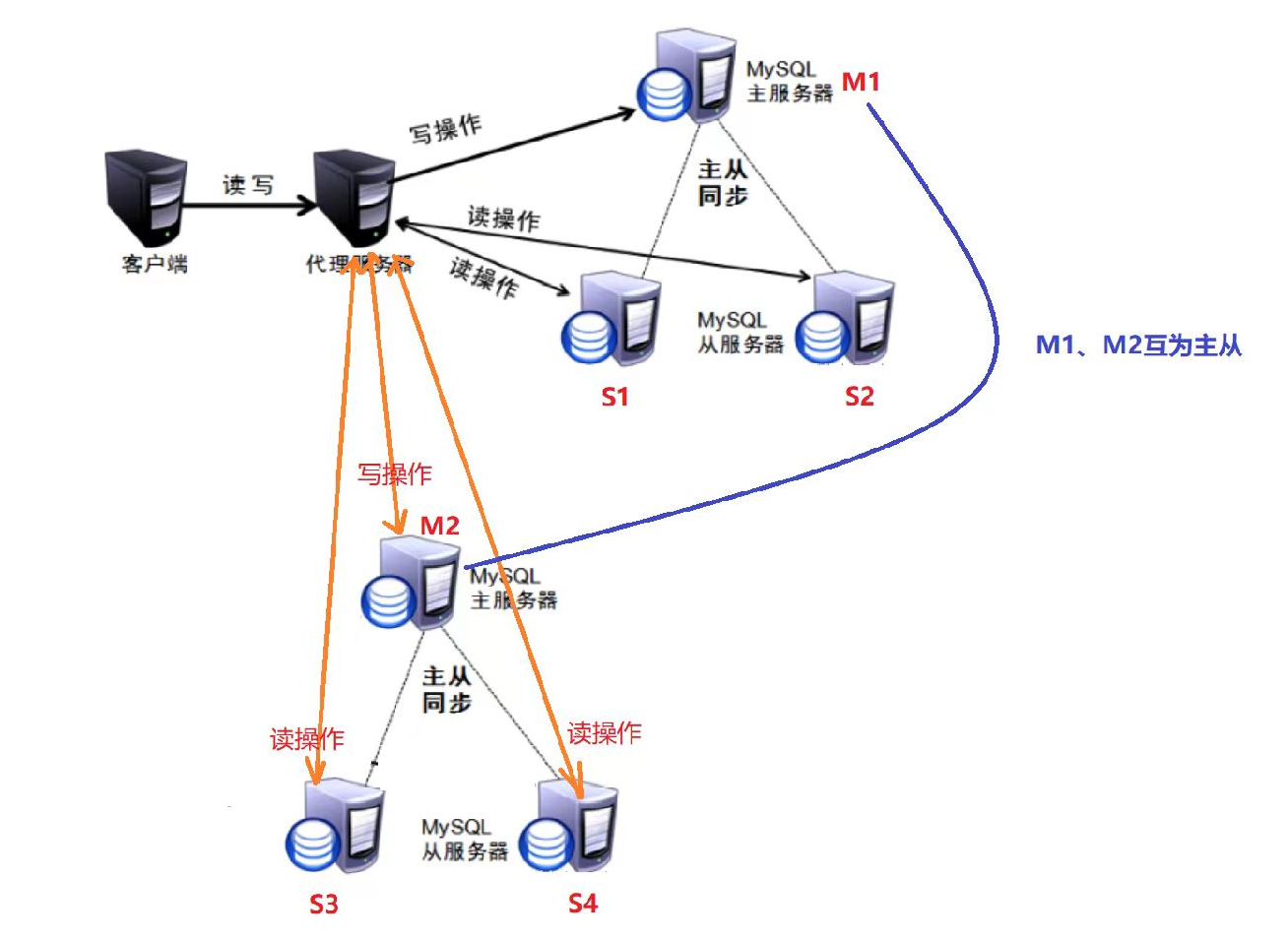
可以看到图中,MyCat服务器挂了两套环境,如果其中1套的主库宕机了(它对应的从库也就不能用了),此时MyCat会自动切到另一套环境,因为M1和M2之间也是配置成互为主从的,所以M2可以同步M1的数据,提供与M1环境完全相同的服务,所以它的 高可用容灾 能力是非常不错的。
MyCat服务端口和管理端口
- MySQL的服务端口是3306,MyCat服务端口是
8066(这个端口也是可以改的),也就是MySQL Client连接的是8066端口,登录8066端口看到的界面就和登录MySQL Server的3306端口一样。 - MyCat还有一个管理端口
9066,登录这个管理端口可以查看MyCat正在工作的所有状态以及和后端服务器的连接,以及连接数据源的状态等。
配置命令
环境准备
-
master(centos7、NAT模式、固定IP) :192.168.29.128
-
slave(win10、路由器局域网、DHCP协议):192.168.3.7
-
JDK1.7版本以上(java -version检查jdk环境)
-
MySQL的root账户有远程访问权限
💕 查看主从复制状态
💕 查看JDK版本
MyCat的运行需要java环境,需要JDK1.7版本以上,执行 java -version 检查JDK环境。

💕 查看root远程连接权限

💕 安装MyCat
用rz命令将MyCat安装包传输到Linux上。
解压mycat安装包

这里为了使用方便我们直接在 /usr/bin 下建立软链接,连接用户目录下的mycat和我们解压路径下的mycat。
ln -s /MySQL/MyCat/mycat/bin/mycat /usr/bin/mycat
配置文件
server.xml
server.xml 配置登录mycat账号信息。

不需要和MySQL的账号密码一样,因为我们的MySQL Client直接访问的是MyCat,再由MyCat登录MySQL Server。TESTDB是逻辑库,是一个不存在的库,最终这个库映射到后端的MySQL上,实际上它会真实地映射到MySQL库表当中,所以我们把它叫做逻辑库。这个逻辑库看起来好像在MyCat一台机器上,实际上经过分库分表操作可能分配在不同的机器上,我们只需要操作这个逻辑库就可以,其他的不用关心。多个逻辑库的话,用逗号分隔开。
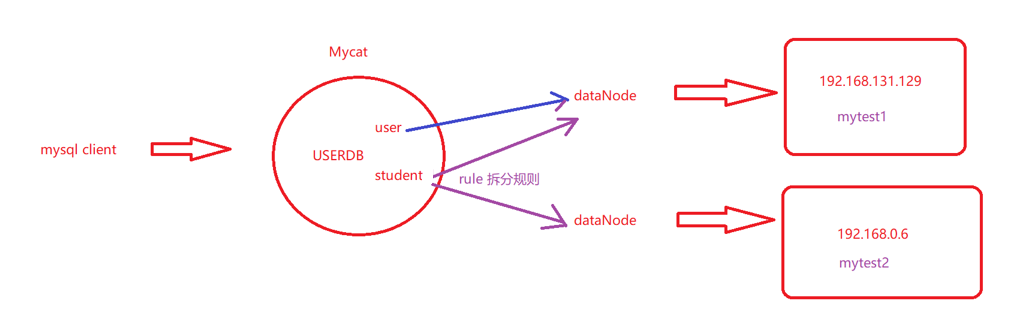
schema.xml
schema.xml配置逻辑库与数据源、读写分离,分库分表等。
- 逻辑库和逻辑表:MySQL Client都是操作的MyCat上的逻辑库(schema)和逻辑表
- 数据节点:这个库或者表的内容放在哪个节点(dataNode)上,这个节点对应具体的物理机器(dataHost)
- 以下三个地方需要相同(其中逻辑库、数据节点以及数据库主机名称都可以随便取)


启动服务
-
启动mycat

-
查看服务是否正常

这里我们需要注意的是,如果配置上有问题,启动服务是看不出来的,应该查看 mycat/logs/warpper.log,记录了mycat启动过程中的错误。
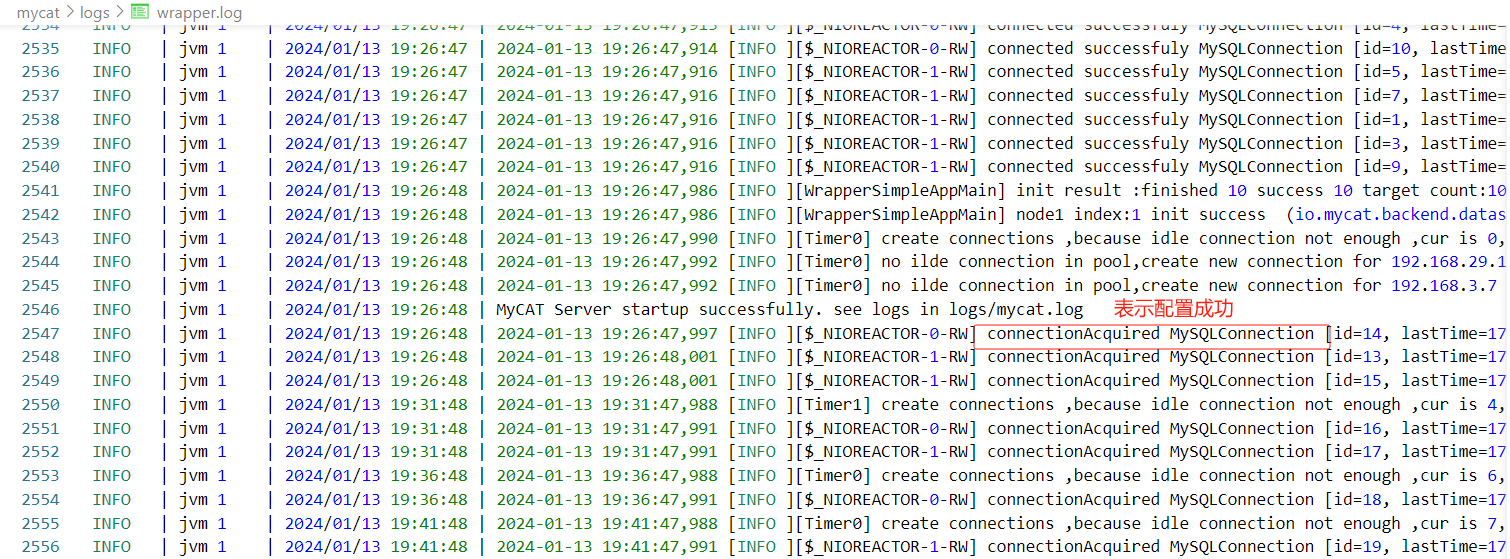
mycat 9066端口和8066端口
- 9066管理端口
show @@help 可以显示mycat的管理端支持的命令
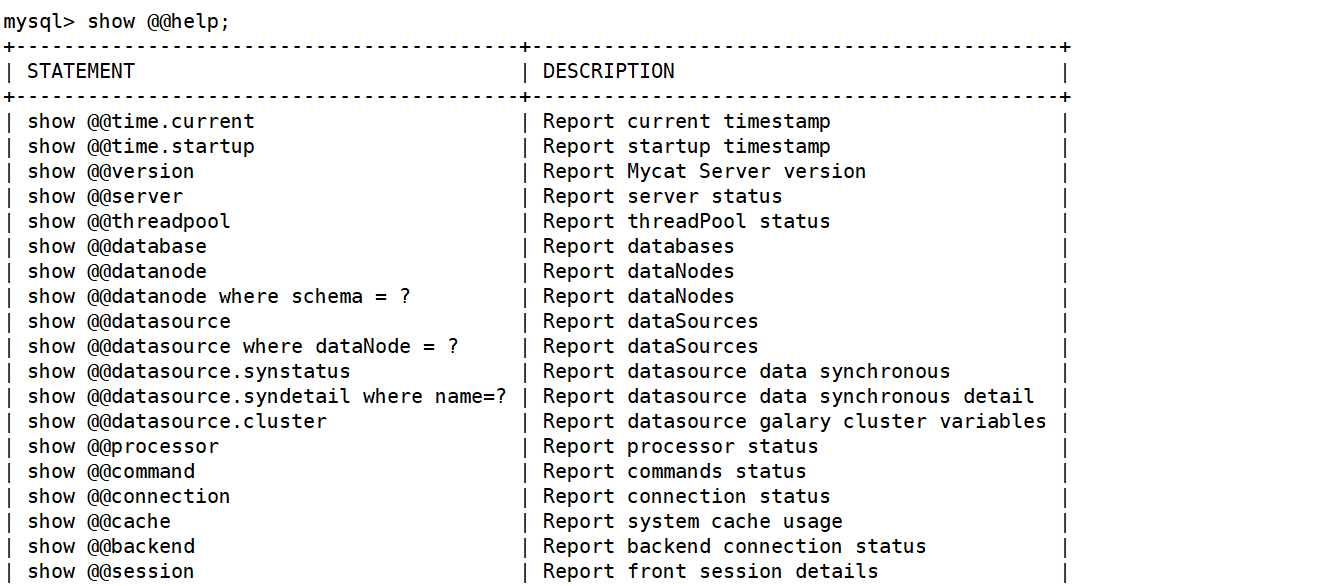
show @@database查看逻辑表

show @@datanode;查看逻辑节点和真实库之间的映射关系

show @@datasource;查看数据源

- 8066数据端口
OpenCloundDB表示我们看到的是一个云状数据库,云后面是如何提供的库表的服务能力,我们是不知道的。mycat就是云DB,把后端所有的细节给客户端隐藏了,客户端只需要去处理代理服务器上的DB就可以了。可以看作一个反向代理服务。
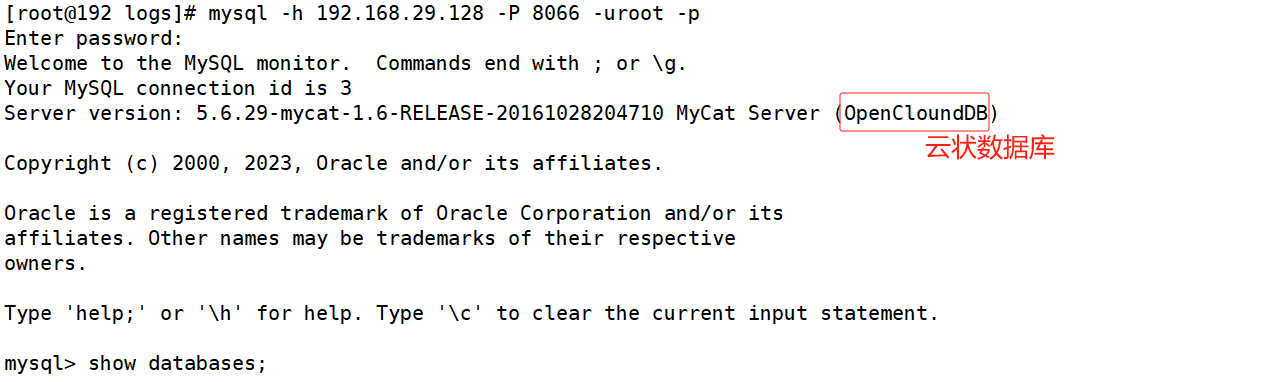
查看数据库

这个逻辑库TESTDB对应的就是真实库testDB。

验证读写分离
💕 验证读操作在slave
- 将Windows上和Linux上的查询日志都打开。
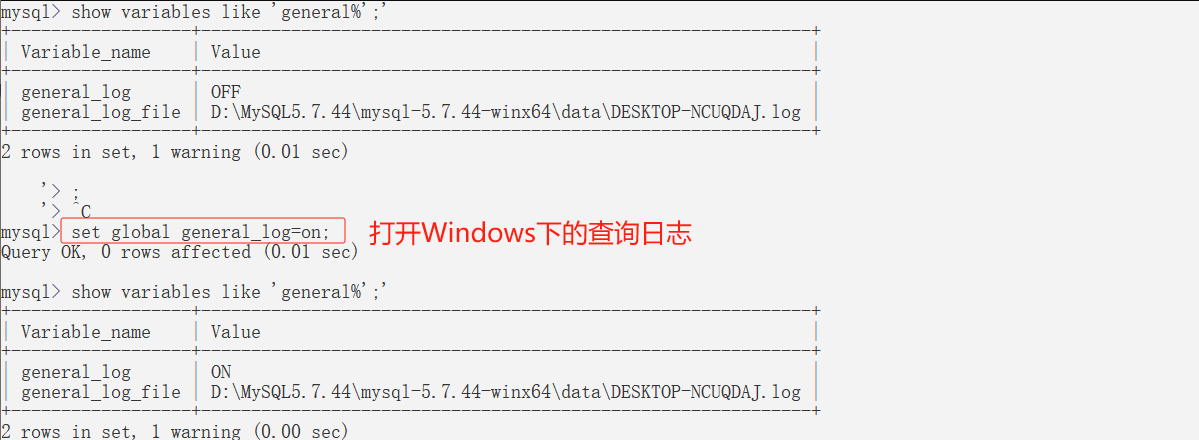

- 验证读写操作
操作8066端口逻辑库下面的user表
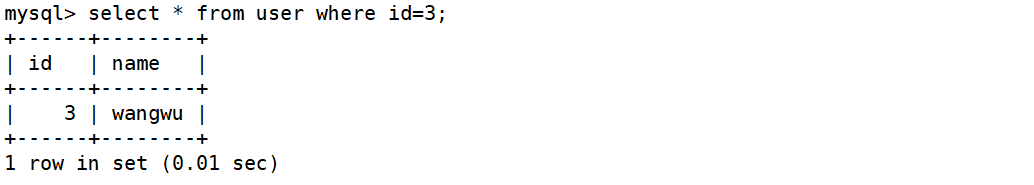
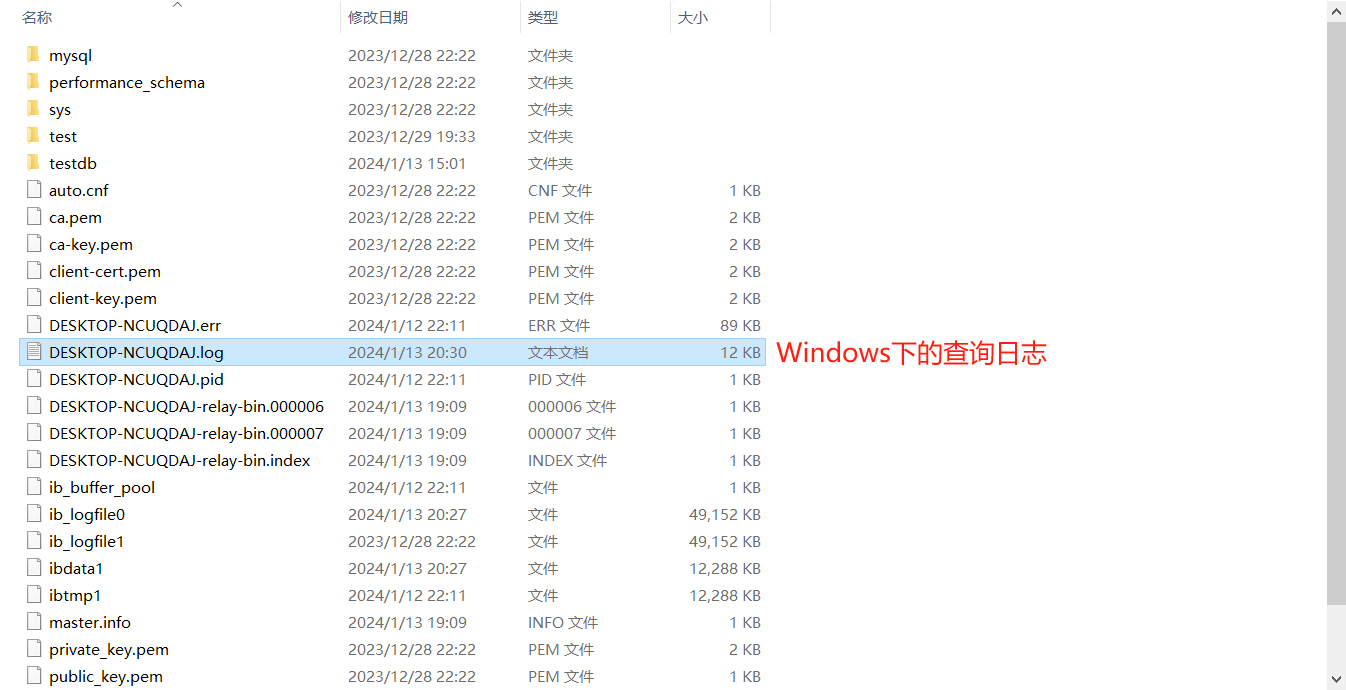
在Linux下的master服务器查看general_log,并没有看见查询日志。
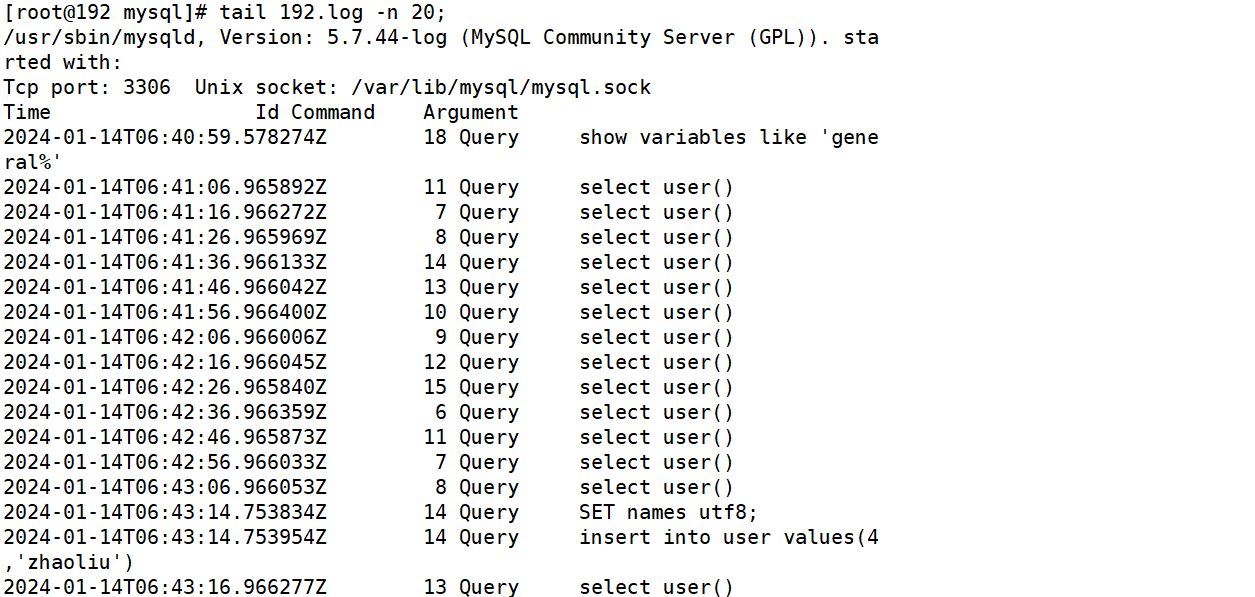
在Windows下的slave服务器种查看 general_log,看到了mycat发送的查询user表的SQL。
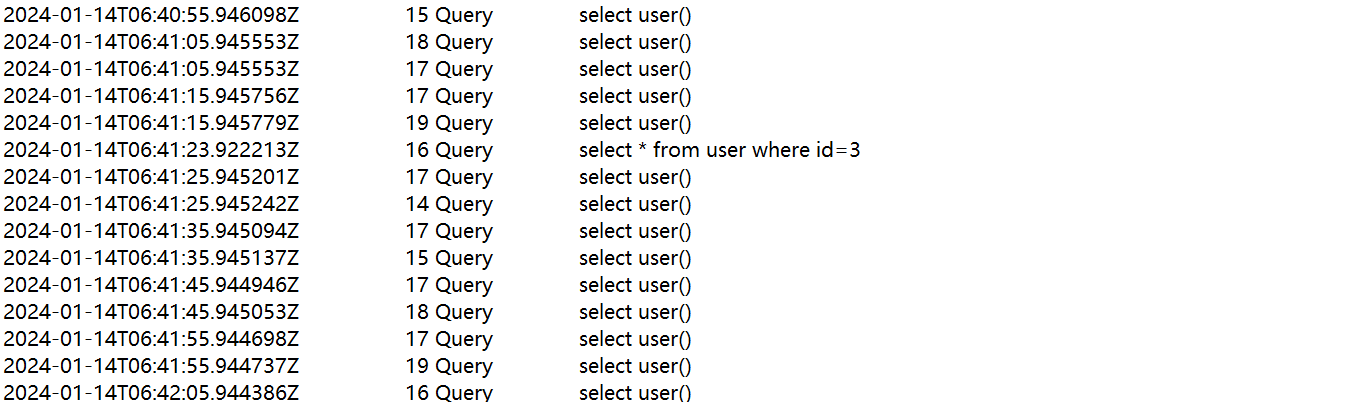
💕 验证写操作在slave
登录mycat8066数据端口,给user表insert一条数据。
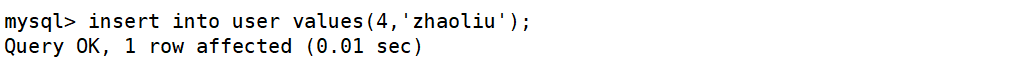
在Windows下的slave服务器中查看general_log,没有发现insert数据的SQL。
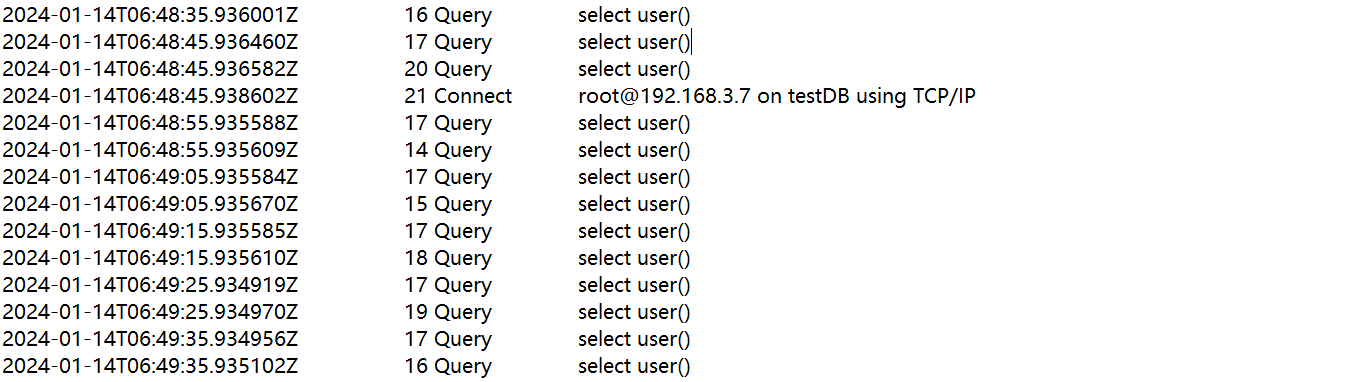
在Linux下的master服务器查看general_log,看到了insert数据的SQL。
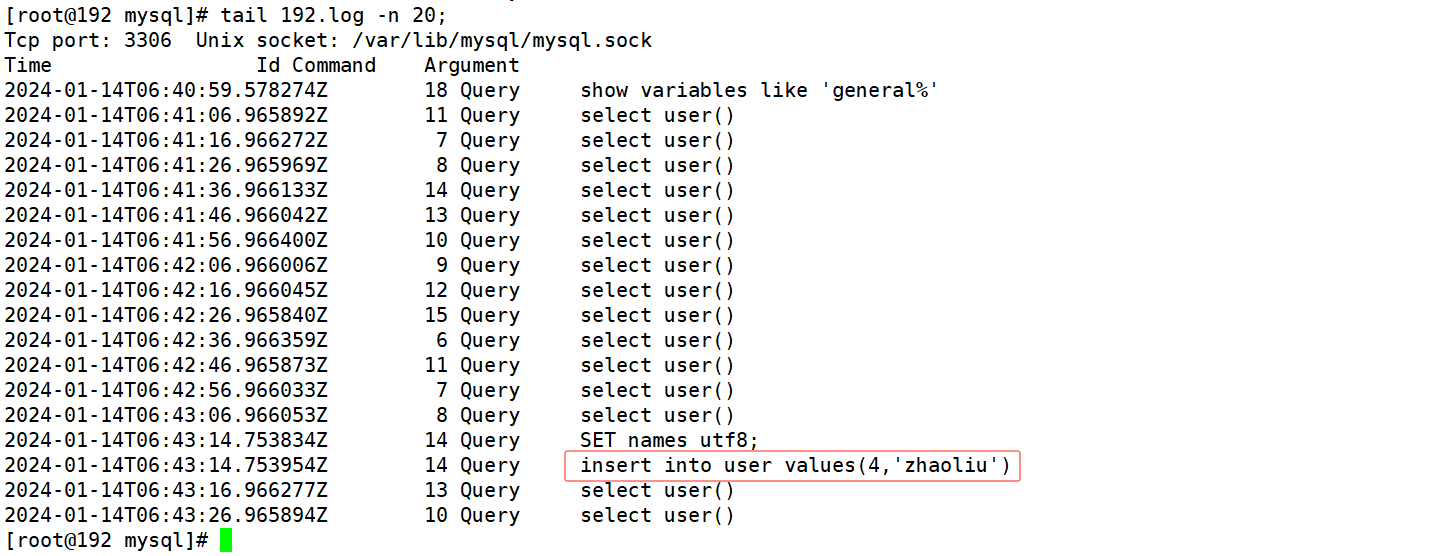
这样我们就验证了我们读写分离是没有问题的,所有的写操作都是在master上进行的,读操作都是在slave上进行的,这就是读写分离,比起单个主机既做写也做读操作肯定能提升它的性能。
验证容灾功能
我们在 mycat/conf/schema.xml 中配置的是多主多从,因此M1挂了,读写操作都会全部转发到M2上,在我们当前的环境中,如果Linux上的MySQL Server 挂了,所有的读写操作都会转发给Windows上的MySQL Server。
关闭Linux上的mysqld服务,相当于关闭了master。

这里我们登录mycat 8806端口,对user表分别进行读写操作。

查看我们多主多从中备用系统的general_log,即Windows下的MySQL Server 的 general_log。

这里可以看到,由于master挂了,读写操作都被转发到了备用的Windows 上的 MySQL Server,证明容灾没有问题。
三、mysql分库分表
刚开始多数项目用单机数据库就够了,随着服务器流量越来越大,面对的请求也越来越多,我们做了数据库读写分离, 使用多个从库副本(Slave)负责读,使用主库(Master)负责写,master和slave通过主从复制实现数据同步更新,保持数据一致。slave 从库可以水平扩展,所以更多的读请求不成问题。
但是当用户量级上升,写请求越来越多,怎么保证数据库的负载足够?增加一个Master是不能解决问题的, 因为数据要保存一致性,写操作需要2个master之间同步,相当于是重复了,而且架构设计更加复杂。这时需要用到 分库分表(sharding),对写操作进行切分。
库表问题
单库太大: 单库处理能力有限、所在服务器上的磁盘空间不足、遇到IO瓶颈,需要把单库切分成更多更小的库
单表太大:CURD效率都很低、数据量太大导致索引膨胀、查询超时,需要把单表切分成多个数据集更小的表
拆分策略
单个库太大,先考虑是表多还是数据多。
- 如果因为表多而造成数据过多,则使用垂直拆分,即根据业务拆分成不同的库
- 如果因为单张表的数据量太大,则使用水平拆分,即把表的数据按照某种规则拆分成多张表
分库分表的原则应该是先考虑垂直拆分,再考虑水平拆分。
垂直拆分
垂直分表
也就是“大表拆小表”,基于列字段进行。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。一般是针对几百列的这种大表,也避免查询时,数据量太大造成的“跨页”问题。
垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分。
比如用户User一个库,商品Product一个库,订单Order一个库, 切分后,要放在多个服务器上,而不
是一个服务器上。想象一下,一个购物网站对外提供服务,会有用户,商品,订单等的CRUD。没拆分之前, 全部都是落到单一的库上的,这会让数据库的单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。 所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的“治理”,“降级”机制类似,也能对不同业务的数据分别的进行管理,
维护,监控,扩展等。 数据库往往最容易成为应用系统的瓶颈,而数据库本身属于“有状态”的,相对于Web和应用服务器来讲,是比较难实现“横向扩展”的。 数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。
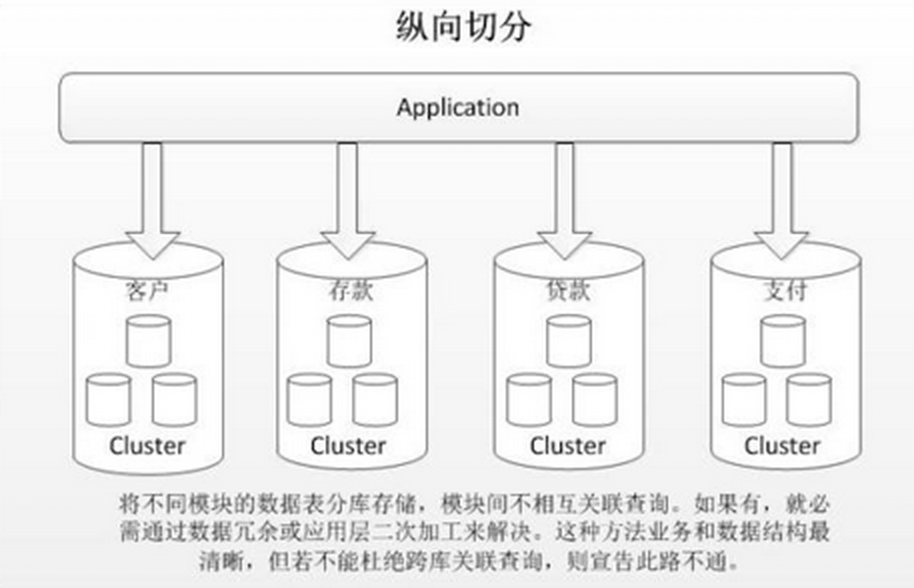
水平拆分
水平分表
针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈,不建议采用。
水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
下面我们以水平拆分的方式来模拟一下:
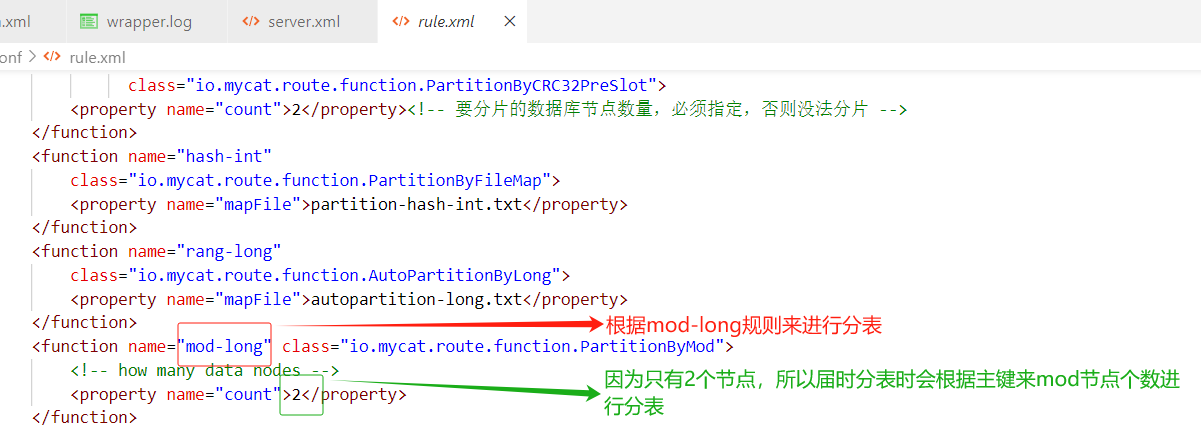
💕 修改配置文件

💕 创建数据库和表
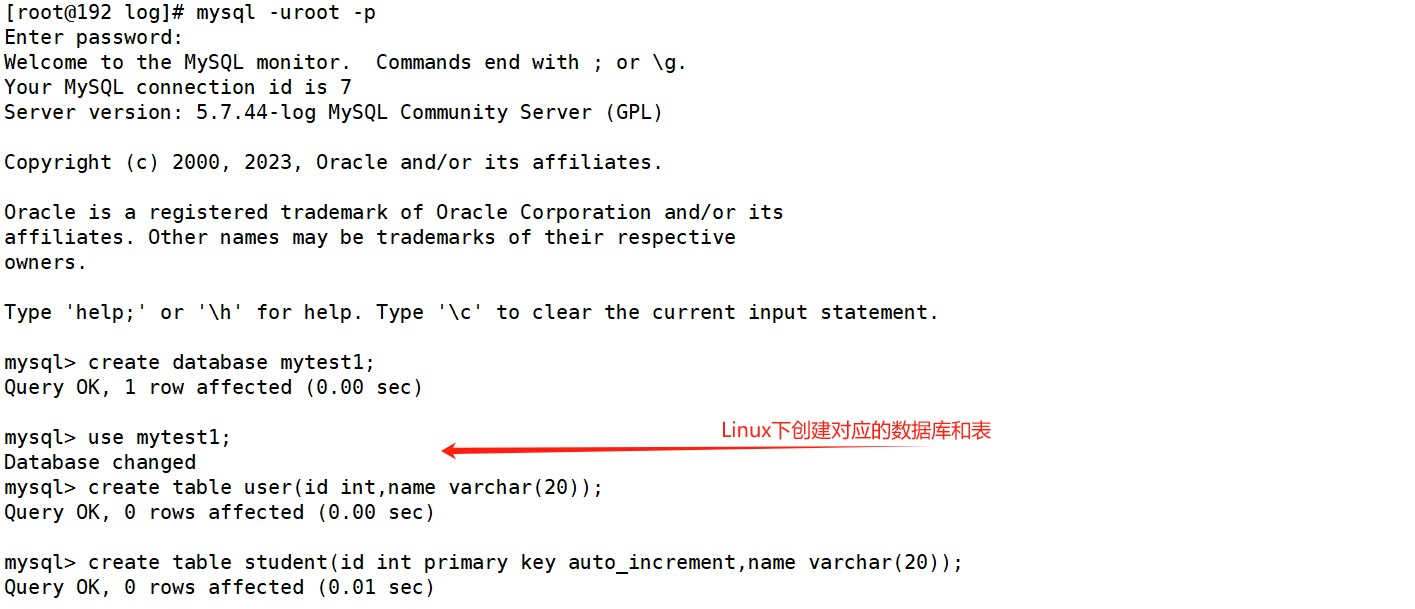
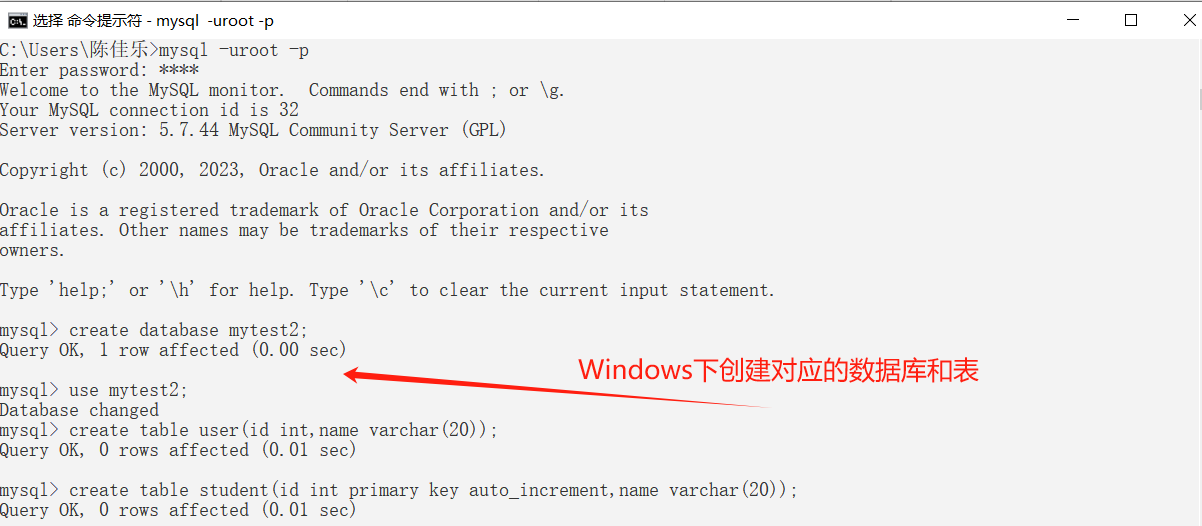
💕 登录mycat服务器
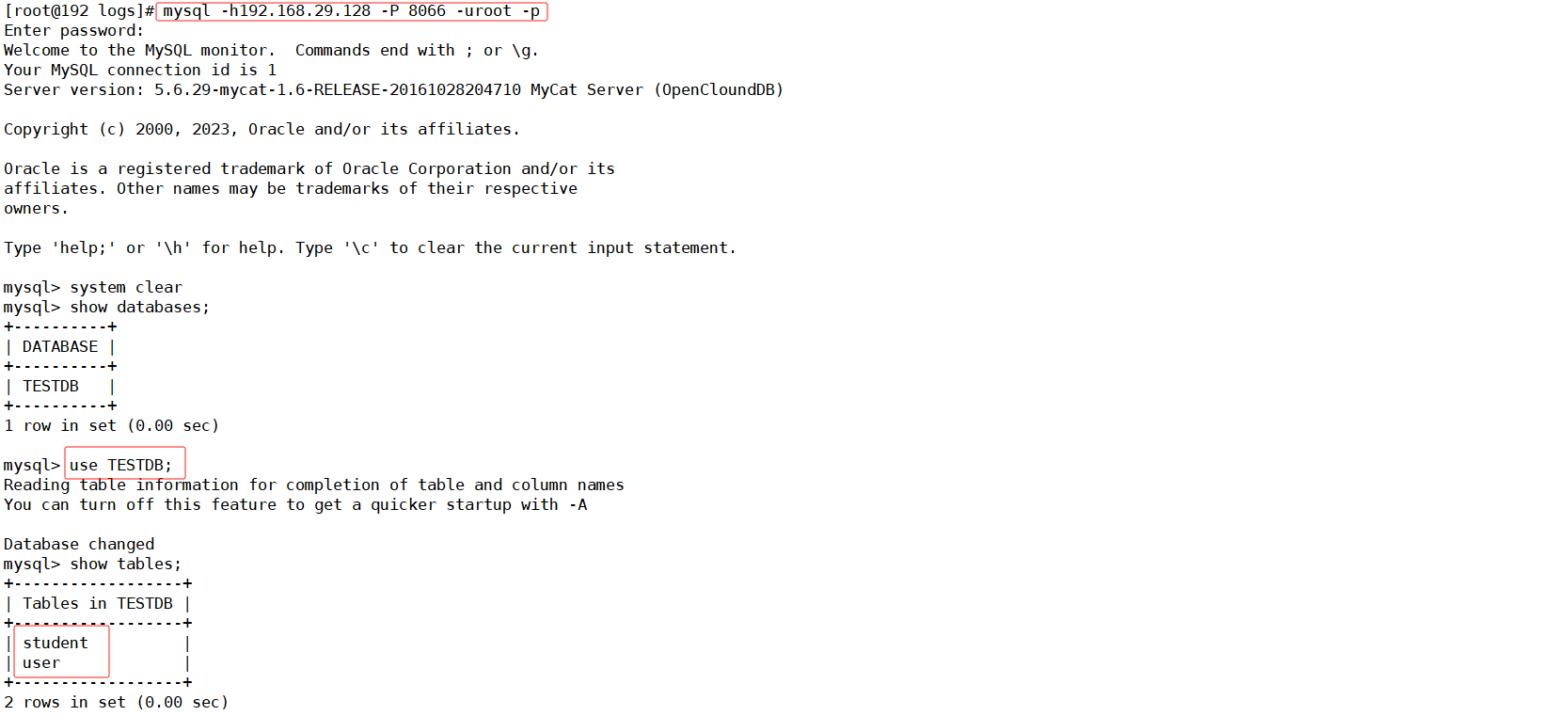
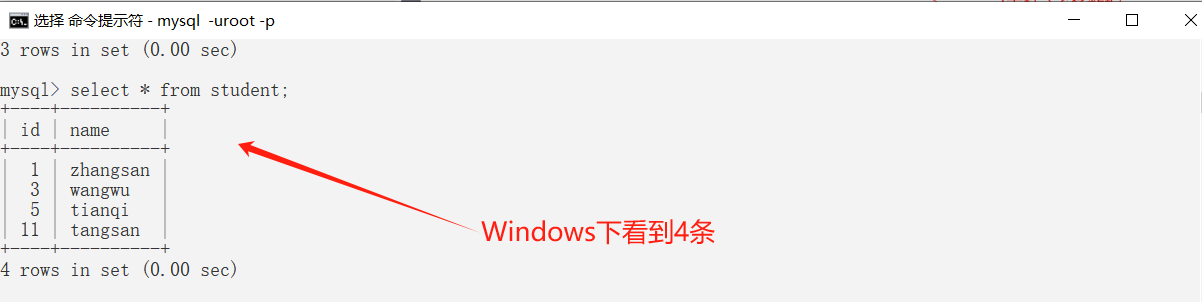
💕 分库分表演示


相关文章:
【MySQL】mysql集群
文章目录 一、mysql日志错误日志查询日志二进制日志慢查询日志redo log和undo log 二、mysql集群主从复制原理介绍配置命令 读写分离原理介绍配置命令 三、mysql分库分表垂直拆分水平拆分 一、mysql日志 MySQL日志 是记录 MySQL 数据库系统运行过程中不同事件和操作的信息的文件…...
zabbix监控windows主机
下载安装zabbix agent安装包 Zabbix官网下载地址: https://www.zabbix.com/cn/download_agents?version5.0LTS&release5.0.40&osWindows&os_versionAny&hardwareamd64&encryptionOpenSSL&packagingMSI&show_legacy0 这里使用zabbix agent2 安装 …...

单例模式的八种写法、单例和并发的关系
文章目录 1.单例模式的作用2.单例模式的适用场景3.饿汉式静态常量(可用)静态代码块(可用) 4.懒汉式线程不安全(不可用)同步方法(线程安全,但不推荐用)同步代码块…...

基于实时Linux+FPGA实现NI CompactRIO系统详解
利用集成的软件工具链,结合信号调理I/O模块,轻松构建和部署实时应用程序。 什么是CompactRIO? CompactRIO系统提供了高处理性能、传感器专用I/O和紧密集成的软件工具,使其成为工业物联网、监测和控制应用的理想之选。实时处理器提…...
Webhook端口中的自定义签名身份认证
概述 如果需要通过 Webhook 端口从交易伙伴处接收数据,但该交易伙伴可能对于安全性有着较高的要求,而不仅仅是用于验证入站 Webhook 要求的基本身份验证用户名/密码,或者用户可能只想在入站 Webhook 消息上增加额外的安全层。 使用 Webhook…...

用Linux的视角来理解缓冲区概念
缓冲区的认识 缓冲区(buffer)是存储数据的临时存储区域。当我们用C语言向文件中写入数据时,数据并不会直接的写到文件中,中途还经过了缓冲区,而我们需要对缓冲区的数据进行刷新,那么数据才算写到文件当中。…...
 方法用于计算)
C#中Enumerable.Range(Int32, Int32) 方法用于计算
目录 一、关于Enumerable.Range(Int32, Int32) 方法 1.定义 2.Enumerable.Range()用于数学计算的操作方法 3.实例1:显示整型数1~9的平方 4.实例2:显示整型数0~9 5.实例3:Enumerable.Range()vs for循环 &#x…...
:windows 下进程同步)
Linux和windows进程同步与线程同步那些事儿(四):windows 下进程同步
Linux和windows进程同步与线程同步那些事儿(一) Linux和windows进程同步与线程同步那些事儿(二): windows线程同步详解示例 Linux和windows进程同步与线程同步那些事儿(三): Linux线…...

1. Logback介绍
Logback介绍 Logback旨在成为流行的log4j项目的继任者。它由Ceki Glc设计,他是log4j的创始人。它基于十年在设计工业级日志系统方 面的经验。结果产品,即logback,比所有现有的日志系统更快,具有更小的占用空间,有时差距…...
SqueezeNet:通过紧凑架构彻底改变深度学习
一、介绍 在深度学习领域,对效率和性能的追求往往会带来创新的架构。SqueezeNet 是神经网络设计的一项突破,体现了这种追求。本文深入研究了 SqueezeNet 的复杂性,探讨其独特的架构、设计背后的基本原理、应用及其对深度学习领域的影响。 在创…...
用法)
Python:正则表达式之re.group()用法
Python正则表达式之re.group()用法学习笔记 正则表达式是在处理字符串时非常有用的工具,而re.group()是在匹配到的文本中提取特定分组内容的方法之一。 1. re.group()的基本用法 在正则表达式中,通过圆括号可以创建一个或多个分组。re.group()用于获取…...
Shiro框架:Shiro登录认证流程源码解析
目录 1.用户登录认证流程 1.1 生成认证Token 1.2 用户登录认证 1.2.1 SecurityManager login流程解析 1.2.1.1 authenticate方法进行登录认证 1.2.1.1.1 单Realm认证 1.2.1.2 认证通过后创建登录用户对象 1.2.1.2.1 复制SubjectContext 1.2.1.2.2 对subjectContext设…...
WEB前端人机交互导论实验-实训2格式化文本、段落与列表
1.项目1 文本与段落标记的应用: A.题目要求: B.思路: (1)首先,HTML文档的基本结构是通过<html>...</html>标签包围的,包含了头部信息和页面主体内容。 (2)在头部信息…...

Python:list列表与tuple元组的区别
在Python中,List(列表) 和Tuple(元组) 都是用于存储一组有序元素的数据结构,但它们有一些关键的区别,包括可变性、性能、语法等方面。 1. List(列表) 用法:…...
如何基于 Gin 封装出属于自己 Web 框架?
思路 在基于 Gin 封装出属于自己的 Web 框架前,你需要先了解 Gin 的基本用法和设计理念。 然后,你可以通过以下步骤来封装自己的 Web 框架: 封装路由:Gin 的路由是通过 HTTP 方法和 URL 路径进行匹配的,你可以根据自己…...
VUE element-ui实现表格动态展示、动态删减列、动态排序、动态搜索条件配置、表单组件化。
1、实现效果 1.1、文件目录 1.2、说明 1、本组件支持列表的表头自定义配置,checkbox实现 2、本组件支持列表列排序,vuedraggable是拖拽插件,上图中字段管理里的拖拽效果 ,需要的话请自行npm install 3、本组件支持查询条件动态…...

压测工具ab
Apache Benchmark(简称ab) 是Apache安装包中自带的压力测试工具 ,简单易用, Apache的ab命令模拟多线程并发请求,测试服务器负载压力,也可以适用于其他服务:nginx、lighthttp、tomcat、IIS等其它Web服务器的压力 采用平台…...

P4学习(一) 环境搭建
系列文章目录 第一章 P4学习入门之虚拟机环境搭建 文章目录 系列文章目录前言一、P4是什么?二、搭建步骤1.下载虚拟机镜像2.虚拟机管理软件载入镜像2.1 找到你镜像的所在位置2.2 打开VMware Workstation2.3 载入镜像 3.检验环境是否配置成功 P4 的真机环境搭建 前言…...
openssl3.2 - 官方demo学习 - server-arg.c
文章目录 openssl3.2 - 官方demo学习 - server-arg.c概述笔记备注END openssl3.2 - 官方demo学习 - server-arg.c 概述 TLS服务器, 等客户端来连接; 如果客户端断开了, 通过释放bio来释放客户端socket, 然后继续通过bio读来aceept. 笔记 对于开源工程, 不可能有作者那么熟悉…...

Windows RPC运行时漏洞事后总结
2022年4月前后,Windows RPC运行时被曝出存在远程代码执行漏洞,当时曾引起很多人广泛关注。微软很快做出反应,发布补丁程序进行修补。这次事件中,Windows远程过程调用(RPC)运行时共出现三个关键漏洞…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

量子机器学习多编码框架MEDQ:提升模型泛化能力与参数效率
1. 项目概述:为什么量子机器学习需要“多编码”?量子机器学习(QML)这几年火得不行,但真正上手做过的人都知道,它有个挺让人头疼的“怪病”:模型在某些数据集上表现神勇,换到另一个看…...