SqueezeNet:通过紧凑架构彻底改变深度学习
一、介绍
在深度学习领域,对效率和性能的追求往往会带来创新的架构。SqueezeNet 是神经网络设计的一项突破,体现了这种追求。本文深入研究了 SqueezeNet 的复杂性,探讨其独特的架构、设计背后的基本原理、应用及其对深度学习领域的影响。

在创新经济中,效率是成功的货币。SqueezeNet 证明了这一点,证明在深度学习领域,少确实可以多。
二、SqueezeNet架构
2.1 综述
SqueezeNet 是一种卷积神经网络 (CNN),可以用更少的参数实现 AlexNet 级别的精度。其架构设计巧妙,可在保持高精度的同时减小模型尺寸。SqueezeNet 的核心是“fire 模块”,这是一个紧凑的构建块,包含两层:挤压层和扩展层。挤压层利用 1x1 卷积滤波器来压缩输入数据,从而降低维度。随后,扩展层混合使用 1x1 和 3x3 滤波器来增加通道深度,捕获更广泛的特征。
SqueezeNet 是一种深度神经网络架构,旨在以更少的参数提供 AlexNet 级别的精度。它通过使用更小的卷积滤波器和称为“火模块”的策略来实现这一点。这些模块是“挤压”层和“扩展”层的组合,“挤压”层使用 1x1 滤波器来压缩输入通道,“扩展”层使用 1x1 和 3x3 滤波器的混合来增加通道深度。SqueezeNet 的主要优点是模型尺寸小和计算速度快,这使得它非常适合部署在计算资源有限的环境中,例如移动设备或嵌入式系统。此外,它的体积小,更容易通过网络传输,并且需要更少的存储内存。
2.2 设计原理
SqueezeNet 设计背后的主要动机是在不影响性能的情况下创建轻量级模型。AlexNet 等传统 CNN 虽然有效,但参数较多,导致计算成本和存储要求较高。SqueezeNet 通过采用更小的滤波器和更少的参数来解决这些挑战,从而减少计算量。这使得它特别适合部署在资源受限的环境中,例如移动设备或嵌入式系统。
2.3 SqueezeNet的应用
SqueezeNet 的紧凑尺寸和效率为各种应用开辟了新途径。在内存和处理能力有限的移动应用中,SqueezeNet 可实现高级图像识别和实时分析。在机器人技术中,它有助于高效的实时决策。此外,其较小的模型尺寸在基于网络的应用中具有优势,允许在带宽受限的网络上更快地传输神经网络模型。
2.4 对深度学习的影响
SqueezeNet 通过证明较小的网络可以与较大的网络一样有效,对深度学习领域产生了重大影响。它挑战了传统观念,即更大、更深的网络总是会产生更好的结果。这种范式转变引发了对高效神经网络设计的进一步研究,从而导致了 MobileNet 和 ShuffleNet 等其他紧凑架构的发展。
三、代码
创建 SqueezeNet 的完整 Python 实现以及合成数据集和绘图涉及几个步骤。我们将首先使用 TensorFlow 或 PyTorch 等深度学习库实现 SqueezeNet 架构。然后,我们将创建一个合成数据集,在此数据集上训练模型,最后绘制训练结果。
以下是如何使用 PyTorch 执行此操作的高级概述:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt# Define the Fire Module
class FireModule(nn.Module):def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand3x3_channels):super(FireModule, self).__init__()self.squeeze = nn.Conv2d(in_channels, squeeze_channels, kernel_size=1)self.expand1x1 = nn.Conv2d(squeeze_channels, expand1x1_channels, kernel_size=1)self.expand3x3 = nn.Conv2d(squeeze_channels, expand3x3_channels, kernel_size=3, padding=1)def forward(self, x):x = F.relu(self.squeeze(x))return torch.cat([F.relu(self.expand1x1(x)),F.relu(self.expand3x3(x))], 1)class SqueezeNet(nn.Module):def __init__(self, num_classes=1000):super(SqueezeNet, self).__init__()self.num_classes = num_classes# Initial convolution layerself.features = nn.Sequential(nn.Conv2d(3, 96, kernel_size=7, stride=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),)# Fire modulesself.features.add_module("fire2", FireModule(96, 16, 64, 64))self.features.add_module("fire3", FireModule(128, 16, 64, 64))self.features.add_module("fire4", FireModule(128, 32, 128, 128))self.features.add_module("maxpool4", nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True))self.features.add_module("fire5", FireModule(256, 32, 128, 128))# Additional Fire modules as needed# ...# Adjust the final Fire module to output 512 channelsself.features.add_module("final_fire", FireModule(256, 64, 256, 256))# Final convolution layerself.final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)# Dropout and classifierself.classifier = nn.Sequential(nn.Dropout(p=0.5),self.final_conv,nn.ReLU(inplace=True),nn.AdaptiveAvgPool2d((1, 1)))def forward(self, x):x = self.features(x)x = self.classifier(x)return x.view(x.size(0), self.num_classes)# Initialize the model
squeezenet = SqueezeNet()# Synthetic Dataset
class SyntheticDataset(Dataset):def __init__(self, num_samples, num_classes):self.num_samples = num_samplesself.num_classes = num_classesdef __len__(self):return self.num_samplesdef __getitem__(self, idx):image = torch.randn(3, 224, 224) # Simulating a 3-channel imagelabel = torch.randint(0, self.num_classes, (1,))return image, label# Create the synthetic dataset
synthetic_dataset = SyntheticDataset(num_samples=1000, num_classes=10)
dataloader = DataLoader(synthetic_dataset, batch_size=32, shuffle=True)# Training
optimizer = optim.Adam(squeezenet.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()losses = []
accuracies = []num_epochs = 5 # Example number of epochs
for epoch in range(num_epochs):running_loss = 0.0correct = 0total = 0for images, labels in dataloader:optimizer.zero_grad()outputs = squeezenet(images)loss = criterion(outputs, labels.squeeze())loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels.squeeze()).sum().item()epoch_loss = running_loss / len(dataloader)epoch_accuracy = 100 * correct / totallosses.append(epoch_loss)accuracies.append(epoch_accuracy)print(f'Epoch {epoch+1}, Loss: {epoch_loss}, Accuracy: {epoch_accuracy}%')# Plotting
plt.plot(losses)
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()plt.plot(accuracies)
plt.title('Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
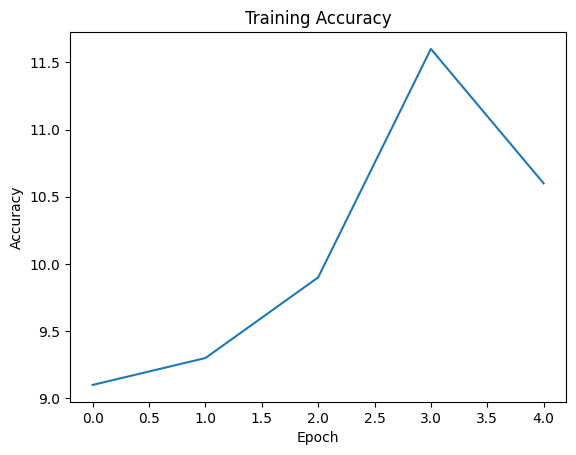
plt.show()Epoch 1, Loss: 4.31704169511795, Accuracy: 9.1%
Epoch 2, Loss: 2.3903158977627754, Accuracy: 9.3%
Epoch 3, Loss: 2.391318053007126, Accuracy: 9.9%
Epoch 4, Loss: 2.366191916167736, Accuracy: 11.6%
Epoch 5, Loss: 2.4050718769431114, Accuracy: 10.6%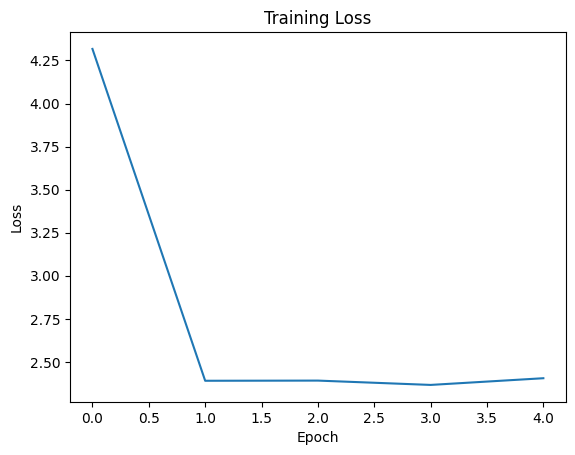
请记住,这是一个高级大纲。每个步骤都需要根据您的具体要求和 PyTorch 文档进行详细实施。此外,对合成数据集的训练不会产生有意义的见解,但对于测试实现很有用。对于实际训练,请考虑使用 CIFAR-10 或 ImageNet 等标准数据集。
四、结论
SqueezeNet 代表了神经网络发展的一个里程碑。其创新设计成功地平衡了尺寸和性能之间的权衡,使其成为高效深度学习的开创性模型。随着技术不断向更紧凑、更高效的解决方案发展,SqueezeNet 的影响力可能会增长,继续塑造神经网络设计和应用的未来。
相关文章:
SqueezeNet:通过紧凑架构彻底改变深度学习
一、介绍 在深度学习领域,对效率和性能的追求往往会带来创新的架构。SqueezeNet 是神经网络设计的一项突破,体现了这种追求。本文深入研究了 SqueezeNet 的复杂性,探讨其独特的架构、设计背后的基本原理、应用及其对深度学习领域的影响。 在创…...
用法)
Python:正则表达式之re.group()用法
Python正则表达式之re.group()用法学习笔记 正则表达式是在处理字符串时非常有用的工具,而re.group()是在匹配到的文本中提取特定分组内容的方法之一。 1. re.group()的基本用法 在正则表达式中,通过圆括号可以创建一个或多个分组。re.group()用于获取…...
Shiro框架:Shiro登录认证流程源码解析
目录 1.用户登录认证流程 1.1 生成认证Token 1.2 用户登录认证 1.2.1 SecurityManager login流程解析 1.2.1.1 authenticate方法进行登录认证 1.2.1.1.1 单Realm认证 1.2.1.2 认证通过后创建登录用户对象 1.2.1.2.1 复制SubjectContext 1.2.1.2.2 对subjectContext设…...
WEB前端人机交互导论实验-实训2格式化文本、段落与列表
1.项目1 文本与段落标记的应用: A.题目要求: B.思路: (1)首先,HTML文档的基本结构是通过<html>...</html>标签包围的,包含了头部信息和页面主体内容。 (2)在头部信息…...

Python:list列表与tuple元组的区别
在Python中,List(列表) 和Tuple(元组) 都是用于存储一组有序元素的数据结构,但它们有一些关键的区别,包括可变性、性能、语法等方面。 1. List(列表) 用法:…...
如何基于 Gin 封装出属于自己 Web 框架?
思路 在基于 Gin 封装出属于自己的 Web 框架前,你需要先了解 Gin 的基本用法和设计理念。 然后,你可以通过以下步骤来封装自己的 Web 框架: 封装路由:Gin 的路由是通过 HTTP 方法和 URL 路径进行匹配的,你可以根据自己…...
VUE element-ui实现表格动态展示、动态删减列、动态排序、动态搜索条件配置、表单组件化。
1、实现效果 1.1、文件目录 1.2、说明 1、本组件支持列表的表头自定义配置,checkbox实现 2、本组件支持列表列排序,vuedraggable是拖拽插件,上图中字段管理里的拖拽效果 ,需要的话请自行npm install 3、本组件支持查询条件动态…...

压测工具ab
Apache Benchmark(简称ab) 是Apache安装包中自带的压力测试工具 ,简单易用, Apache的ab命令模拟多线程并发请求,测试服务器负载压力,也可以适用于其他服务:nginx、lighthttp、tomcat、IIS等其它Web服务器的压力 采用平台…...

P4学习(一) 环境搭建
系列文章目录 第一章 P4学习入门之虚拟机环境搭建 文章目录 系列文章目录前言一、P4是什么?二、搭建步骤1.下载虚拟机镜像2.虚拟机管理软件载入镜像2.1 找到你镜像的所在位置2.2 打开VMware Workstation2.3 载入镜像 3.检验环境是否配置成功 P4 的真机环境搭建 前言…...
openssl3.2 - 官方demo学习 - server-arg.c
文章目录 openssl3.2 - 官方demo学习 - server-arg.c概述笔记备注END openssl3.2 - 官方demo学习 - server-arg.c 概述 TLS服务器, 等客户端来连接; 如果客户端断开了, 通过释放bio来释放客户端socket, 然后继续通过bio读来aceept. 笔记 对于开源工程, 不可能有作者那么熟悉…...

Windows RPC运行时漏洞事后总结
2022年4月前后,Windows RPC运行时被曝出存在远程代码执行漏洞,当时曾引起很多人广泛关注。微软很快做出反应,发布补丁程序进行修补。这次事件中,Windows远程过程调用(RPC)运行时共出现三个关键漏洞…...

运算电路(1)——加法器
一、引言 微处理器是由一片或少数几片大规模集成电路组成的中央处理器。这些电路执行控制部件和算术逻辑部件的功能。微处理器能完成取指令、执行指令,以及与外界存储器和逻辑部件交换信息等操作,是微型计算机的运算控制部分。它可与存储器和外围电路芯片…...
)
ESP32-WIFI(Arduino)
ESP32-WIFI Wi-Fi是一种基于IEEE 802.11标准的无线局域网技术,是Wi-Fi联盟制造商的商标作为产品的品牌认证。它可以让电脑、手机、平板电脑等设备通过无线信号连接到互联网 。 在无线网络中,AP(Access Point)和 STA(St…...

【网络虚拟化】网络设备常见冗余方式——堆叠、M-Lag、DRNI
网络设备常见冗余设计——堆叠、M-Lag、DRNI 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 网络设备常见冗余设计——堆叠、M-Lag、DRNI 网络设备常见冗余设计——堆叠、M-Lag、DRNI前言一、网络设备虚拟化二、堆叠技术1.技术原理2.…...

arm的侏罗纪二 cache学习
个人觉得inner shareable和outer shareable;POU和POC 是难点,慢慢学习吧。 inner shareable是cluster内 outer shareable是cluster之间 参考文献: 深入学习Cache系列 1: 带着几个疑问,从Cache的应用场景学起 https://www.eet-c…...
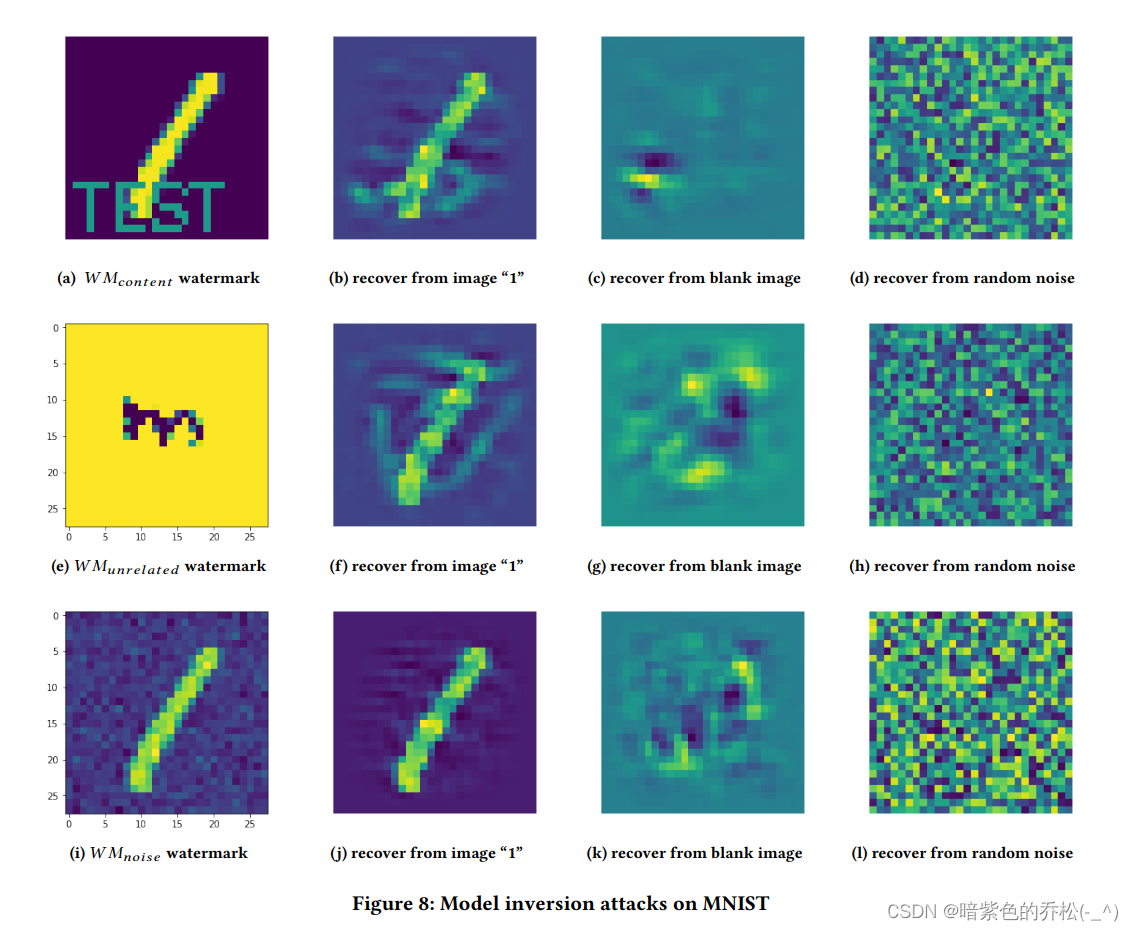
Protecting Intellectual Property of Deep NeuralNetworks with Watermarking
保护深度神经网络的知识产权与数字水印技术 ABSTRACT 深度学习是当今人工智能服务的关键组成部分,在视觉分析、语音识别、自然语言处理等多个任务方面表现出色,为人类提供了接近人类水平的能力。构建一个生产级别的深度学习模型是一项非常复杂的任务&a…...
c++学习笔记-STL案例-机房预约系统1-准备工作
前言 准备工作包括:需求分析、项目创建、主菜单实现、退出功能实现 目录 1 机房预约系统需求 1.1 简单介绍 1.2 身份介绍 1.3 机房介绍 1.4 申请介绍 1.5 系统具体要求 1.6 预约系统-主界面思维导图 2 创建项目 2.1 创建项目 2.2 添加文件 编辑 3 创建…...

AnnData:单细胞和空间组学分析的数据基石
AnnData:单细胞和空间组学分析的数据基石 今天我们来系统学习一下单细胞分析的标准数据类型——AnnData! AnnData就是有注释的数据,全称是Annotated Data。 AnnData是为了矩阵类型数据设计的,也就是长得和表格一样的数据。比如…...

C语言中的 `string.h` 头文件包含的函数
C语言中的 string.h 头文件包含了许多与字符串或数字相关的函数。这些函数可以用于字符串的复制、连接、搜索、比较等操作。 常用字符串函数 函数名功能strlen()返回字符串的长度strcpy()将一个字符串复制到另一个字符串中strncpy()将最多 n 个字符从一个字符串复制到另一个字…...

kotlin的抽象类和抽象方法
在 Kotlin 中,抽象类和抽象方法是面向对象编程中的概念,用于实现抽象和多态性。抽象类无法实例化,这意味着我们无法创建抽象类的对象。与其他类不同,抽象类总是打开的,因此我们不需要使用open关键字。 抽象类ÿ…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...

终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题
终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否还在为Windows…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...
)
【独家首发】Sora 2 AVI支持并非“开箱即用”:3层封装校验机制详解(RIFF→AVI→OpenCV Mat内存映射链路图解)
更多请点击: https://codechina.net 第一章:Sora 2 AVI支持并非“开箱即用”:核心矛盾与技术定位 Sora 2 的官方文档与发布说明中明确将 AVI 视为“实验性容器支持”,而非默认启用的输入格式。其底层解码栈基于 FFmpeg 5.1 构建&…...

四大桌面云品牌评测:从安全、体验到性价比
桌面云不再是大型企业的专属,它已成为各行各业实现数据安全、混合办公和IT降本增效的“标准配置”。经过对市场主流方案的全面评估,我们认为,深信服(Sangfor)aDesk桌面云因其在安全内生化、传输协议自研化、运维管理智…...