JPA的复杂查询包括一对多多对一和多对多的查询
1. 多表关联查询和排序
假设我们有两个实体类:Customer和Order,它们之间是一对多的关系,即一个客户可以有多个订单。我们想要查询某个客户的所有订单,并按订单金额进行降序排序。
@Entity
@Table(name = "customers")
public class Customer {@Idprivate Long id;private String name;@OneToMany(mappedBy = "customer", cascade = CascadeType.ALL)private List<Order> orders;// getter和setter方法省略
}@Entity
@Table(name = "orders")
public class Order {@Idprivate Long id;private BigDecimal amount;@ManyToOne@JoinColumn(name = "customer_id")private Customer customer;// getter和setter方法省略
}
通过使用@OneToMany和@ManyToOne注解,我们在Customer实体类和Order实体类之间建立了一对多的关系,并指定了关联的外键列。
现在,我们可以执行多表关联查询,并按订单金额进行降序排序。
@Repository
public class OrderRepository {@PersistenceContextprivate EntityManager entityManager;public List<Order> getOrdersByCustomer(Long customerId) {String queryString = "SELECT o FROM Order o WHERE o.customer.id = :customerId ORDER BY o.amount DESC";TypedQuery<Order> query = entityManager.createQuery(queryString, Order.class);query.setParameter("customerId", customerId);return query.getResultList();}
}
在上述代码中,OrderRepository类的getOrdersByCustomer方法执行了一个多表关联查询,并按订单金额进行降序排序。我们使用了JPQL语句来查询Order实体类,同时通过条件表达式o.customer.id = :customerId筛选出特定客户的订单。ORDER BY子句用于指定排序的字段和排序方式。
最后,我们通过调用getResultList方法执行查询,并返回满足条件的订单列表。
2. 复杂查询和关联操作
假设我们有三个实体类:Student、Course和Enrollment,它们之间是多对多的关系,即一个学生可以选择多门课程,一门课程也可以有多个学生选择。我们想要查询选择了某门课程的所有学生,并且能够添加新的学生和课程。
@Entity
@Table(name = "students")
public class Student {@Idprivate Long id;private String name;@ManyToMany@JoinTable(name = "enrollments",joinColumns = @JoinColumn(name = "student_id"),inverseJoinColumns = @JoinColumn(name = "course_id"))private List<Course> courses;// getter和setter方法省略
}@Entity
@Table(name = "courses")
public class Course {@Idprivate Long id;private String name;@ManyToMany(mappedBy = "courses")private List<Student> students;// getter和setter方法省略
}
通过使用@ManyToMany和@JoinTable注解,我们在Student实体类和Course实体类之间建立了多对多的关系。JoinTable注解用于指定关联表的名称和关联的外键列。
现在,我们可以执行复杂查询,获取选择了某门课程的所有学生,并且能够添加新的学生和课程。
@Repository
public class StudentRepository {@PersistenceContextprivate EntityManager entityManager;public List<Student> getStudentsByCourse(Long courseId) {String queryString = "SELECT s FROM Student s JOIN s.courses c WHERE c.id = :courseId";TypedQuery<Student> query = entityManager.createQuery(queryString, Student.class);query.setParameter("courseId", courseId);return query.getResultList();}public void addStudentToCourse(Student student, Long courseId) {Course course = entityManager.find(Course.class, courseId);student.getCourses().add(course);entityManager.persist(student);}
}
在上述代码中,StudentRepository类的getStudentsByCourse方法执行了一个复杂查询,获取选择了某门课程的所有学生。我们使用了JPQL语句来查询Student实体类,并通过JOIN语句关联了Course实体类。条件表达式c.id = :courseId用于筛选出选择了特定课程的学生。
另外,StudentRepository类的addStudentToCourse方法用于向特定课程中添加新的学生。我们首先通过entityManager.find方法获取到对应的课程实体对象,然后将学生添加到该课程的学生列表中,并通过entityManager.persist方法将更改持久化到数据库中。
当涉及到JPA复杂查询和多表关系操作时,下面是更多案例,展示了不同的情况和用法:
1. 多对多关联查询和条件过滤
假设我们有两个实体类:Product和Category,它们之间是多对多的关系,即一个产品可以属于多个分类,一个分类也可以包含多个产品。我们想要查询属于某个特定分类且价格低于某个阈值的所有产品。
@Entity
@Table(name = "products")
public class Product {@Idprivate Long id;private String name;private BigDecimal price;@ManyToMany@JoinTable(name = "product_category",joinColumns = @JoinColumn(name = "product_id"),inverseJoinColumns = @JoinColumn(name = "category_id"))private List<Category> categories;// getter和setter方法省略
}@Entity
@Table(name = "categories")
public class Category {@Idprivate Long id;private String name;@ManyToMany(mappedBy = "categories")private List<Product> products;// getter和setter方法省略
}
通过使用@ManyToMany和@JoinTable注解,我们在Product实体类和Category实体类之间建立了多对多的关系。JoinTable注解用于指定关联表的名称和关联的外键列。
现在,我们可以执行多对多关联查询,并通过价格条件进行过滤。
@Repository
public class ProductRepository {@PersistenceContextprivate EntityManager entityManager;public List<Product> getProductsByCategoryAndPrice(Long categoryId, BigDecimal maxPrice) {String queryString = "SELECT p FROM Product p JOIN p.categories c WHERE c.id = :categoryId AND p.price < :maxPrice";TypedQuery<Product> query = entityManager.createQuery(queryString, Product.class);query.setParameter("categoryId", categoryId);query.setParameter("maxPrice", maxPrice);return query.getResultList();}
}
在上述代码中,ProductRepository类的getProductsByCategoryAndPrice方法执行了一个多对多关联查询,并通过价格条件进行过滤。我们使用了JPQL语句来查询Product实体类,并通过JOIN语句关联了Category实体类。条件表达式c.id = :categoryId用于筛选出特定分类的产品,p.price < :maxPrice用于筛选出价格低于指定阈值的产品。
最后,我们通过调用getResultList方法执行查询,并返回满足条件的产品列表。
2. 自定义查询结果和投影
在某些情况下,我们可能只需要获取实体类的部分属性,而不是整个实体类的对象。这时可以使用投影(Projection)来自定义查询结果。
假设我们有一个Customer实体类,包含id、name和email等属性。我们想要查询所有客户的名称和邮箱信息。
@Entity
@Table(name = "customers")
public class Customer {@Idprivate Long id;private String name;private String email;// getter和setter方法省略
}
现在,我们可以执行自定义查询,并只选择名称和邮箱两个属性。
@Repository
public class CustomerRepository {@PersistenceContextprivate EntityManager entityManager;public List<Object[]> getCustomerNameAndEmail() {String queryString = "SELECT c.name, c.email FROM Customer c";TypedQuery<Object[]> query = entityManager.createQuery(queryString, Object[].class);return query.getResultList();}
}
在上述代码中,CustomerRepository类的getCustomerNameAndEmail方法执行了一个自定义查询,并只选择了客户的名称和邮箱属性。我们使用了JPQL语句来查询Customer实体类,并在SELECT子句中指定了要选择的属性。由于返回的结果是一组对象数组,我们将查询结果的类型指定为Object[].class。
最后,我们通过调用getResultList方法执行查询,并返回包含名称和邮箱信息的对象数组列表。
注解写SQL
此外,JPA还提供了一些注解,如@Query、@Param和@Modifying,可以更灵活地执行复杂查询操作。下面是几个示例,展示了如何使用这些注解进行复杂查询。
1. 使用@Query注解执行自定义查询
假设我们有一个名为User的实体类,其中包含id、name和email等属性。我们想要根据用户名进行模糊匹配查询符合条件的用户列表。
@Entity
@Table(name = "users")
public class User {@Idprivate Long id;private String name;private String email;// getter和setter方法省略
}
我们可以在UserRepository接口中使用@Query注解来定义自定义查询。
@Repository
public interface UserRepository extends JpaRepository<User, Long> {@Query("SELECT u FROM User u WHERE u.name LIKE %:keyword%")List<User> findByKeyword(@Param("keyword") String keyword);
}
在上述代码中,我们在UserRepository接口中定义了一个带有@Query注解的方法findByKeyword,该方法执行了一个自定义查询。我们使用JPQL语句在User实体类中进行模糊匹配查询,条件是用户名(name属性)包含给定关键字(keyword参数)。
2. 使用@Query和@Modifying注解执行更新操作
除了查询操作,@Query注解还可以用于执行更新操作,如更新、删除等。我们可以结合使用@Query和@Modifying注解来执行这样的操作。
假设我们要删除某个邮箱地址为给定值的用户。
@Repository
public interface UserRepository extends JpaRepository<User, Long> {@Modifying@Query("DELETE FROM User u WHERE u.email = :email")void deleteByEmail(@Param("email") String email);
}
在上述代码中,我们在UserRepository接口中定义了一个带有@Query和@Modifying注解的方法deleteByEmail,该方法执行了一个自定义的删除操作。我们使用JPQL语句在User实体类中删除邮箱地址为给定值(email参数)的用户。
需要注意的是,在执行更新操作时,需要添加@Modifying注解以通知JPA这是一个修改操作,并且不返回结果。
3. 使用命名参数和位置参数
在使用@Query注解时,我们可以使用命名参数或位置参数来传递参数值。
@Repository
public interface UserRepository extends JpaRepository<User, Long> {@Query("SELECT u FROM User u WHERE u.name = :name AND u.email = ?1")List<User> findByNameAndEmail(String name, String email);
}
在上述代码中,我们在@Query注解中使用了命名参数:name和位置参数?1。命名参数使用冒号(:)后跟参数名称的方式,而位置参数使用问号(?)后跟参数的索引编号的方式。在方法的参数列表中,按照在查询语句中出现的顺序,依次传入参数值。
使用@Query等注解进行多表数据的查询和操作时,你可以编写自定义的JPQL语句,来表达复杂的关联关系和条件。以下是几个示例,展示了如何使用@Query等注解进行多表查询和操作。
1. 多表关联查询
假设我们有两个实体类:Order和Customer,它们之间是一对多的关系,即一个客户可以有多个订单。我们想要查询某个客户的所有订单。
@Entity
@Table(name = "orders")
public class Order {@Idprivate Long id;private BigDecimal totalAmount;@ManyToOne@JoinColumn(name = "customer_id")private Customer customer;// getter和setter方法省略
}@Entity
@Table(name = "customers")
public class Customer {@Idprivate Long id;private String name;private String email;// getter和setter方法省略
}
我们可以在OrderRepository接口中使用@Query注解来定义自定义查询。
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {@Query("SELECT o FROM Order o JOIN o.customer c WHERE c.id = :customerId")List<Order> findByCustomerId(@Param("customerId") Long customerId);
}
在上述代码中,我们在OrderRepository接口中定义了一个带有@Query注解的方法findByCustomerId,该方法执行了一个自定义查询。我们使用JPQL语句进行多表关联查询,通过JOIN关键字将Order实体类和Customer实体类关联起来,并使用WHERE子句筛选出特定客户的订单。
2. 多表关联更新操作
除了查询,@Query注解还可以用于执行更新操作。假设我们要将某个客户的所有订单的金额增加10%。
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {@Modifying@Query("UPDATE Order o SET o.totalAmount = o.totalAmount * 1.1 WHERE o.customer.id = :customerId")void increaseAmountByCustomer(@Param("customerId") Long customerId);
}
在上述代码中,我们在OrderRepository接口中定义了一个带有@Query和@Modifying注解的方法increaseAmountByCustomer,该方法执行了一个自定义的更新操作。我们使用JPQL语句将特定客户的订单金额增加10%。通过SET子句更新totalAmount属性,并通过WHERE子句筛选出特定客户的订单。
需要注意的是,在执行更新操作时,需要添加@Modifying注解以通知JPA这是一个修改操作,并且不返回结果。
对于上述的Order实体类,如果想要执行CRUD操作(创建、读取、更新、删除),可以使用JPA提供的CrudRepository接口或者JpaRepository接口来定义相关方法。这些接口提供了一组常用的方法,例如save、findById、findAll、delete等,可以方便地对实体类进行操作。
下面展示了如何使用JpaRepository对Order实体类进行CRUD操作:
简单的CRUD操作
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {// 继承JpaRepository,无需额外定义方法
}
在上述代码中,OrderRepository接口继承了JpaRepository<Order, Long>,其中Order是实体类的类型,Long是实体类的主键类型。通过继承JpaRepository,我们无需额外定义方法,即可直接使用继承的方法来执行CRUD操作。
使用示例:
@Service
public class OrderService {private final OrderRepository orderRepository;public OrderService(OrderRepository orderRepository) {this.orderRepository = orderRepository;}public Order createOrder(Order order) {return orderRepository.save(order);}public Order getOrderById(Long orderId) {return orderRepository.findById(orderId).orElse(null);}public List<Order> getAllOrders() {return orderRepository.findAll();}public Order updateOrder(Order order) {return orderRepository.save(order);}public void deleteOrder(Long orderId) {orderRepository.deleteById(orderId);}
}
在上述代码中,我们创建了一个OrderService服务类,通过构造函数注入OrderRepository对象。在OrderService中,我们使用OrderRepository的方法来执行CRUD操作。例如,createOrder方法使用save方法创建一个新的订单,getOrderById方法使用findById方法根据订单ID获取订单,getAllOrders方法使用findAll方法获取所有订单,updateOrder方法使用save方法更新订单,deleteOrder方法使用deleteById方法删除订单。
通过上述示例,你可以使用JpaRepository提供的方法对Order实体类进行CRUD操作。当然,你也可以根据具体需求自定义查询方法,使用@Query注解等方式执行更复杂的查询和操作。
自定义类封装两个实体类的对象数据
如果我们需要查询两个表并且使用一个新的自定义类来接收查询结果,那么可以使用构造函数表达式或投影查询的方式来实现。
以下是两种方法的示例:
方法一:使用构造函数表达式
假设你有两个实体类 EntityA 和 EntityB,并且你想要使用一个新的自定义类 CustomResult 来接收查询结果。
首先,创建一个包含所需属性的 CustomResult 类:
public class CustomResult {private String propertyA;private String propertyB;public CustomResult(String propertyA, String propertyB) {this.propertyA = propertyA;this.propertyB = propertyB;}// getter 和 setter 方法...
}
然后,在你的 JPA 存储库(Repository)中使用构造函数表达式进行查询:
@Repository
public interface MyRepository extends JpaRepository<EntityA, Long> {@Query("SELECT new com.example.CustomResult(a.propertyA, b.propertyB) FROM EntityA a LEFT JOIN a.entityB b")List<CustomResult> findByCustomQuery();
}
在上面的示例中,我们使用构造函数表达式 new com.example.CustomResult(a.propertyA, b.propertyB) 来创建 CustomResult 对象,并将查询结果映射到自定义类中。我们使用了左连接 LEFT JOIN 将两个表进行连接。
当你调用 findByCustomQuery() 方法时,JPA 将执行查询并将结果封装到 CustomResult 对象中。
方法二:使用投影查询
另一种方法是使用投影查询,它允许你选择需要的属性,并将它们映射到一个接口或类的字段中。
首先,创建一个包含所需属性的接口 CustomResult:
public interface CustomResult {String getPropertyA();String getPropertyB();
}
然后,在你的 JPA 存储库(Repository)中使用投影查询:
@Repository
public interface MyRepository extends JpaRepository<EntityA, Long> {@Query("SELECT a.propertyA AS propertyA, b.propertyB AS propertyB FROM EntityA a LEFT JOIN a.entityB b")List<CustomResult> findByCustomQuery();
}
在上面的示例中,我们使用投影查询将两个表的属性映射到接口 CustomResult 中的字段。我们使用了左连接 LEFT JOIN 将两个表进行连接。
当我们调用 findByCustomQuery() 方法时,JPA 将执行查询并将结果封装到 CustomResult 接口的实现类中。
这两种方法都可以用于查询两个表并使用一个新的自定义类来接收查询结果。可以根据实际需求选择其中一种方法来实现。
更接近底层的一种写法
在JPA中,你可以使用createNativeQuery()方法执行原生SQL查询,并使用getResultList()方法将查询结果以List<Object[]>的形式返回。每个Object[]表示一行记录,其中每个元素对应于一个查询结果列的值。
以下是一个示例,展示如何使用JPA执行原生SQL查询并使用Map接收查询结果:
@Repository
public class MyRepository {@PersistenceContextprivate EntityManager entityManager;public List<Object[]> executeNativeQuery(String sql) {Query query = entityManager.createNativeQuery(sql);List<Object[]> resultList = query.getResultList();// List<Map<String, Object>> resultMapList = new ArrayList<>();
// for (Object[] result : resultList) {
// System.out.println(Arrays.toString(result));
// Map<String, Object> resultMap = new HashMap<>();
// for (int i = 0; i < result.length; i++) {
// String columnName = ""+i;
// resultMap.put(columnName, result[i]);
// }
// resultMapList.add(resultMap);
// }//[1, 123456, aaaaaa]//[2, 123456, kingdol] 拿到的结果是只有值,name要自己封装return resultList;}public int executeNativeUpdate(String sql) {Query query = entityManager.createNativeQuery(sql);return query.executeUpdate();}
}
在上面的示例中,我们使用EntityManager的createNativeQuery()方法创建一个原生SQL查询对象。然后,我们使用getResultList()方法执行查询并将结果以List<Object[]>的形式返回。
接下来,我们遍历结果列表,将每行记录转换为一个Map<String, Object>对象。对于每行记录,我们遍历查询结果的每个元素,并使用Query对象的getResultList()方法获取对应的列名。然后,我们将列名作为键,查询结果值作为值,将它们存储到Map中。最后,我们将每个Map对象添加到一个List<Map<String, Object>>中,并将其作为查询结果返回。
相关文章:

JPA的复杂查询包括一对多多对一和多对多的查询
1. 多表关联查询和排序 假设我们有两个实体类:Customer和Order,它们之间是一对多的关系,即一个客户可以有多个订单。我们想要查询某个客户的所有订单,并按订单金额进行降序排序。 Entity Table(name "customers") pu…...
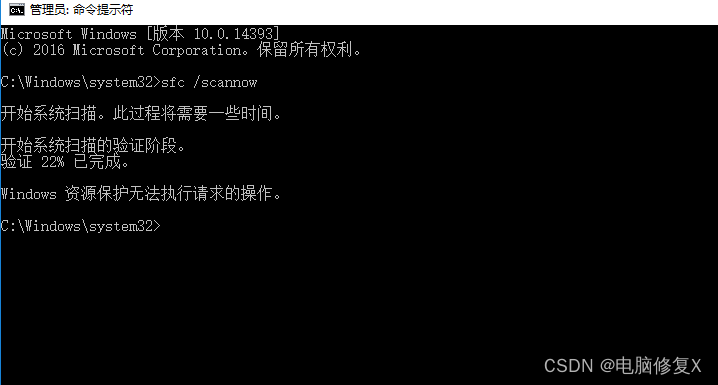
电脑文件mfc100u.dll丢失的解决方法分析,怎么修复mfc100u.dll靠谱
mfc100u.dll丢失了要怎么办?其实很多人都遇到过这样的电脑故障吧,说这个mfc100u.dll文件已经不见了,然后一些程序打不开了,那么这种情况我们要怎么解决呢?今天我们就来给大家详细的说说mfc100u.dll丢失的解决方法。 一…...
从DETR到Mask2former(2): 损失函数loss function
DETR的损失函数包括几个部分,如果只看论文或者代码,比较难理解,最好是可以打断点调试,对照着论文看。但是现在DETR模型都已经被集成进各种框架中,很难进入内部打断掉调试。与此同时,数据的label的前处理也比…...
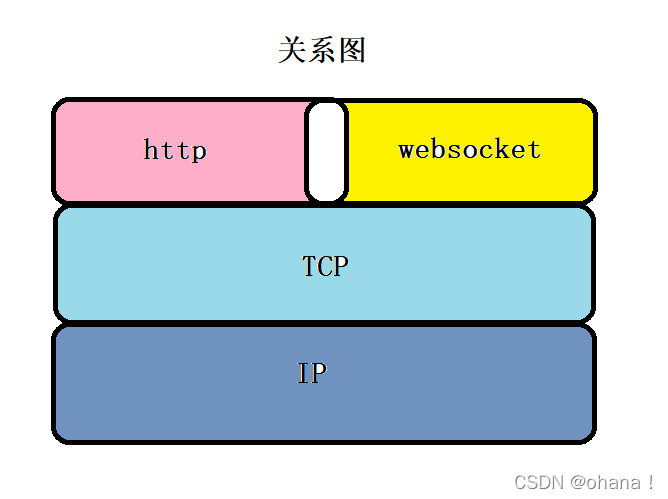
Java21 + SpringBoot3集成WebSocket
文章目录 前言相关技术简介什么是WebSocketWebSocket的原理WebSocket与HTTP协议的关系WebSocket优点WebSocket应用场景 实现方式1. 添加maven依赖2. 添加WebSocket配置类,定义ServerEndpointExporter Bean3. 定义WebSocket Endpoint4. 前端创建WebSocket对象 总结 前…...

鲸鱼优化算法WOA改进预告
鲸鱼优化算法(Whale Optimization Algorithm,WOA)是一种基于自然界中鲸鱼群体行为的启发式优化算法。这个算法模拟了鲸鱼的觅食行为和社会行为,通过模拟这些行为来解决优化问题。 以下是鲸鱼优化算法的一些关键特点和步骤&#x…...
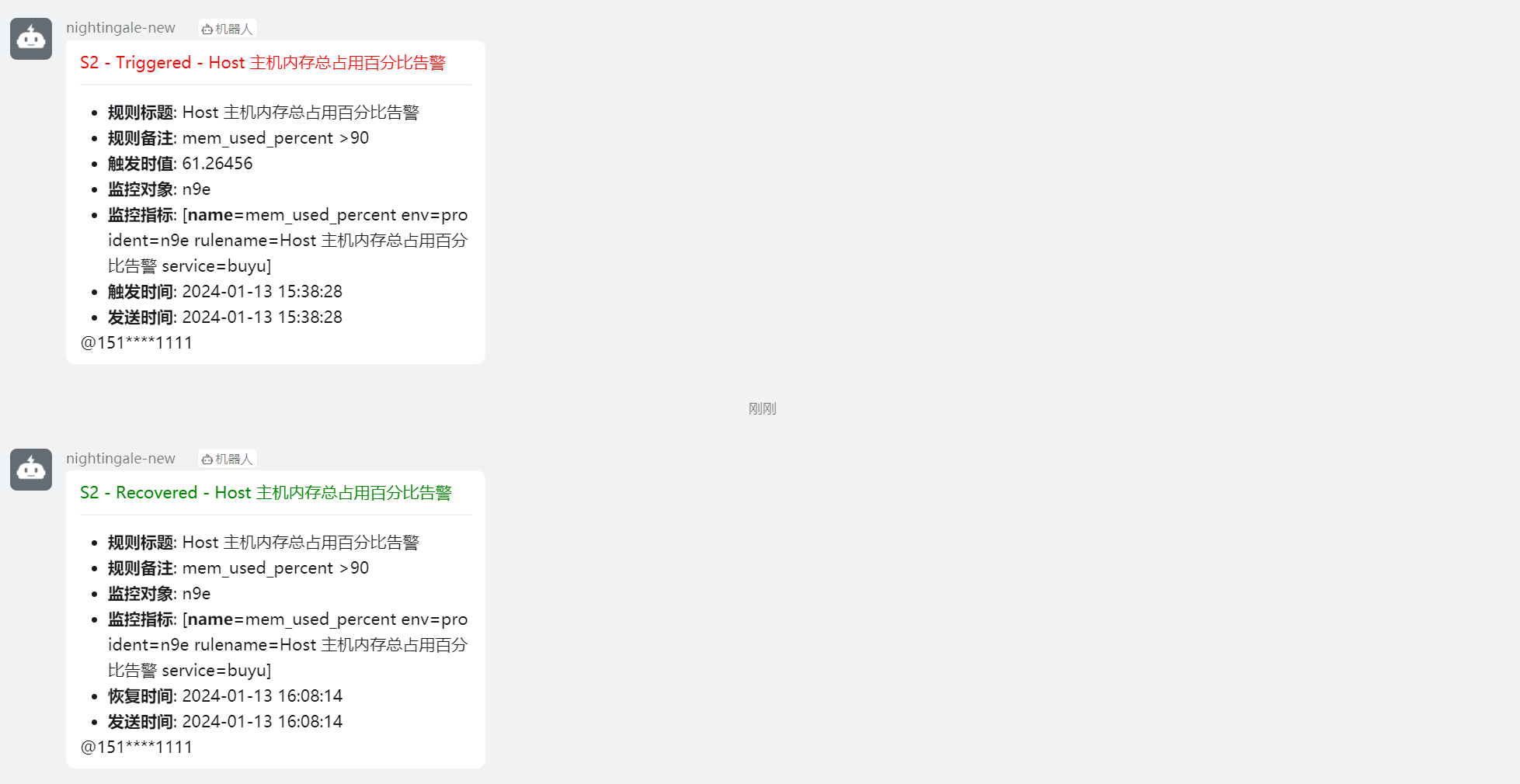
Nightingale 夜莺监控系统 - 告警篇(3)
Author:rab 官方文档:https://flashcat.cloud/docs/content/flashcat-monitor/nightingale-v6/usage/alert/alert-rule/ 目录 前言一、配置1.1 创建钉钉机器人1.2 n9e 创建通知用户1.3 n9e 创建团队(组)1.4 将通知用户添加团队1.…...

【LeetCode2696】删除子串后的字符串最小长度
1、题目描述 【题目链接】 标签:栈 、字符串、模拟 难度:简单 给你一个仅由 大写 英文字符组成的字符串 s 。 你可以对此字符串执行一些操作,在每一步操作中,你可以从 s 中删除 任一个 “AB” 或 “CD” 子字符串。 通过执行操作…...
VMware安装CentOS7虚拟机
VMware 安装 获取 VMware 安装包 下载地址:链接:https://pan.baidu.com/s/1ELR5NZa7rO6YVplZ1IUigw?pwdplz3 提取码:plz3 包括:当然,也可以自己去别的地方下载,WMware 版本都差不多,现在用的比…...
Linux第22步_安装CH340驱动和串口终端软件MobaXterm
开发板输出信息通常是采用串口,而计算机通常是USB接口,为了让他们之间能够交换数据,我们通常采用USB转串口的转换器来实现。目前市场上的串口转换器大多是采用CH340芯片来实现的,因此我们需要在计算中安装一个CH340驱动程序&#…...
Elasticsearch 地理空间搜索 - 远超 OpenSearch
作者:来自 Elastic Nathan_Reese 2021 年,OpenSearch 和 OpenSearch Dashboards 开始作为 Elasticsearch 和 Kibana 的分支。 尽管 OpenSearch 和 OpenSearch Dashboards 具有相似的血统,但它们不提供相同的功能。 在分叉时,只能克…...

USB micro输入口中三个问题详解——差分信号、自恢复保险丝SMD1210P050TF、电容滤波
前言:本文对USB micro输入口中遇见的三个问题进行详解:差分信号、自恢复保险丝SMD1210P050TF、电容滤波 目录: 差分信号 自恢复保险丝SMD1210P050TF 电容滤波 如下图,USB为U-F-M5DD-Y-1型号(9个引脚,除…...
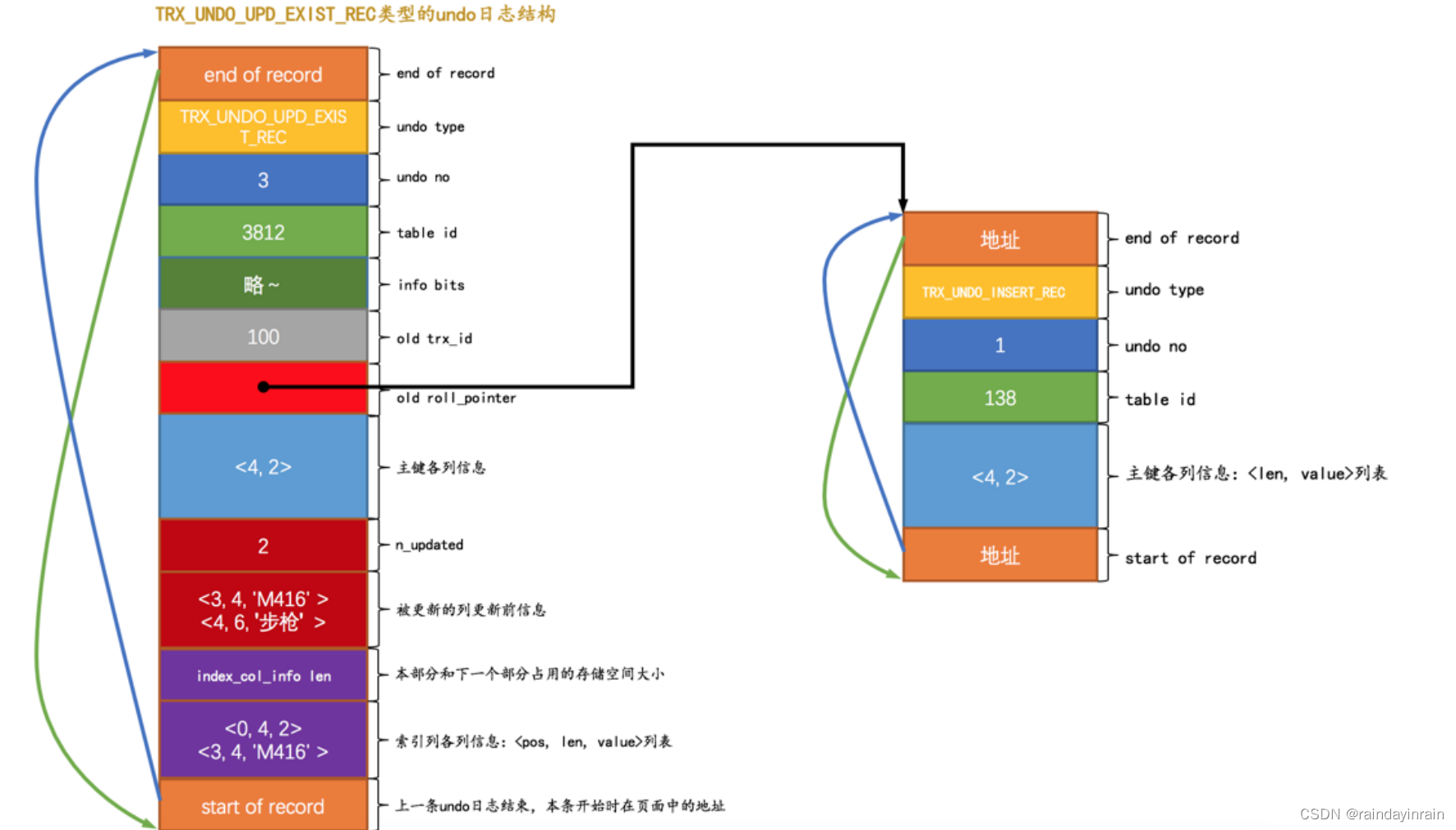
mysql原理--undo日志1
1.事务回滚的需求 我们说过 事务 需要保证 原子性 ,也就是事务中的操作要么全部完成,要么什么也不做。但是偏偏有时候事务执行到一半会出现一些情况,比如: (1). 事务执行过程中可能遇到各种错误,比如服务器本身的错误&…...
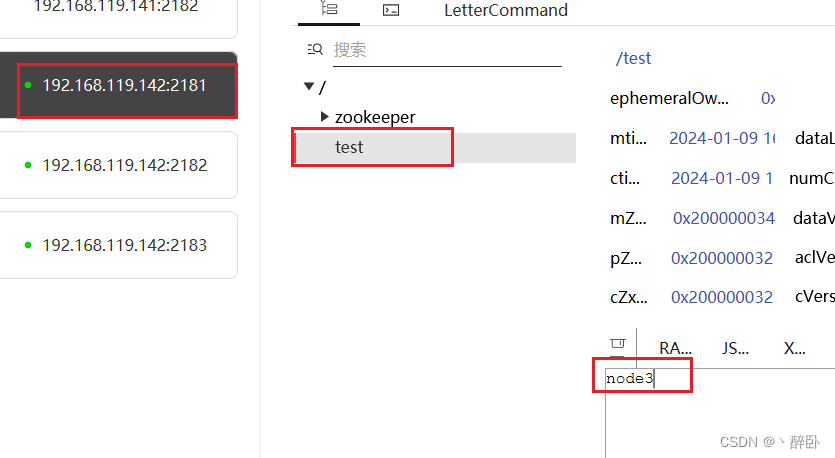
Zookeeper系列(一)集群搭建(非容器)
系列文章 Zookeeper系列(一)集群搭建(非容器) 目录 前言 下载 搭建 Data目录 Conf目录 集群复制和修改 启动 配置示例 测试 总结 前言 Zookeeper是一个开源的分布式协调服务,其设计目标是将那些复杂的且容易出错的分…...

【高等数学之泰勒公式】
一、从零开始 1.1、泰勒中值定理1 什么是泰勒公式?我们先看看权威解读: 那么我们从古至今到底是如何创造出泰勒公式的呢? 由上图可知,任一无穷小数均可以表示成用一系列数字的求和而得出的结果,我们称之为“无穷算法”。 那么同理我们想对任一曲线来…...
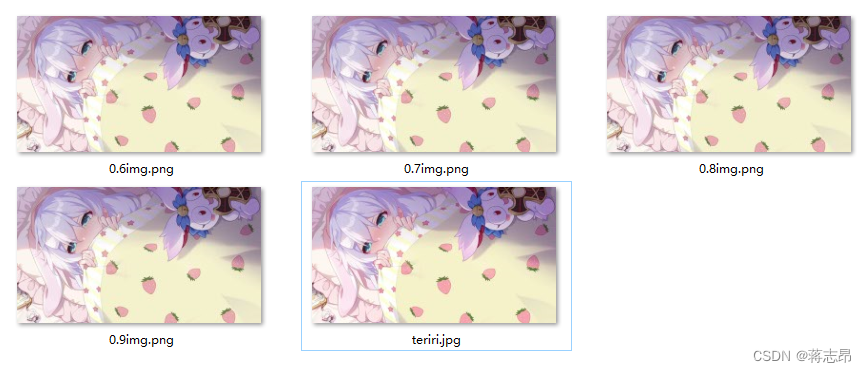
奇异值分解在图形压缩中的应用
奇异值分解在图形压缩中的应用 在研究奇异值分解的工程应用之前,我们得明白什么是奇异值?什么是奇异向量? 奇异值与奇异向量 概念:奇异值描述了矩阵在一组特定向量上的行为,奇异向量描述了其最大的作用方向。 奇异值…...

C++深入学习之STL:1、容器部分
标准模板库STL的组成 主要由六大基本组件组成:容器、迭代器、算法、适配器、函数对象(仿函数)以及空间配置器。 容器:就是用来存数据的,也称为数据结构。 本文要详述的是容器主要如下: 序列式容器:vector、list 关联…...

Javascript——vue下载blob文档流
<el-table-column label"操作" fixed"right" width"150" showOverflowTooltip><template slot-scope"scope"><el-button type"text" v-has"stbsd-gjcx-down" class"edit-button" click&…...

C# 的SequenceEqual
SequenceEqual 是 LINQ 扩展方法之一,用于比较两个序列(如数组、列表等)的元素是否相等。 该方法的详细定义如下: public static bool SequenceEqual<TSource>(this IEnumerable<TSource> first, IEnumerable<TS…...
)
第九部分 使用函数 (一)
目录 一、简介 二、函数的调用语法 一、简介 在 Makefile 中可以使用函数来处理变量,从而让我们的命令或是规则更为的灵活和具 有智能。make 所支持的函数也不算很多,不过已经足够我们的操作了。函数调用后,函数 的返回值可以当做变量来使用…...
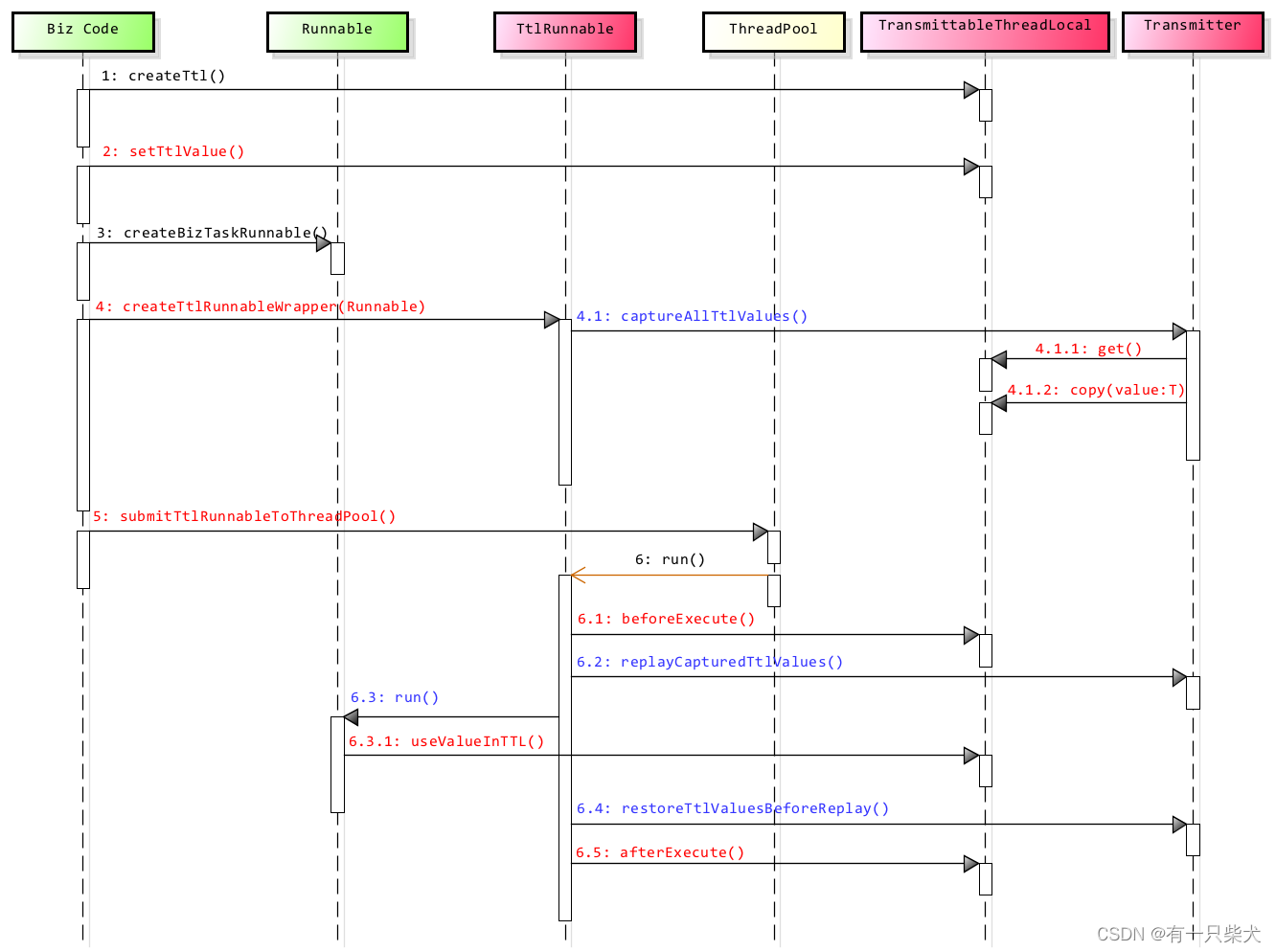
【JUC进阶】14. TransmittableThreadLocal
目录 1、前言 2、TransmittableThreadLocal 2.1、使用场景 2.2、基本使用 3、实现原理 4、小结 1、前言 书接上回《【JUC进阶】13. InheritableThreadLocal》,提到了InheritableThreadLocal虽然能进行父子线程的值传递,但是如果在线程池中&#x…...

RAGFlow图片回答避坑指南:为什么不用Base64和阿里云OSS?
RAGFlow图片回答架构设计:从Base64到容器化服务器的技术演进 当RAG系统需要处理包含图片的回答时,技术选型直接关系到系统的性能、安全性和可维护性。本文将深入探讨几种主流方案的优劣对比,并解析为何容器化图片服务器成为当前最优解。 1. 图…...

如何一站式管理Mac周边所有设备的电池电量:AirBattery终极指南
如何一站式管理Mac周边所有设备的电池电量:AirBattery终极指南 【免费下载链接】AirBattery Get the battery level of all your devices on your Mac and put them on the Dock / Status Bar / Widget! && 在Mac上获取你所有设备的电量信息并显示在Dock / …...

3分钟零基础入门:GPU加速MediaPipe TouchDesigner插件完整指南
3分钟零基础入门:GPU加速MediaPipe TouchDesigner插件完整指南 【免费下载链接】mediapipe-touchdesigner GPU Accelerated MediaPipe Plugin for TouchDesigner 项目地址: https://gitcode.com/gh_mirrors/me/mediapipe-touchdesigner 你是否曾想过在TouchD…...
】五、从逻辑门到LEG:指令集与条件跳转的构建)
【图灵完备(Turing Complete)】五、从逻辑门到LEG:指令集与条件跳转的构建
1. 从逻辑门到处理器:LEG架构的诞生之路 记得我第一次用面包板搭建简单逻辑电路时,连个LED灯闪烁都要折腾半天。而现在我们要做的,是把这些基础逻辑门像乐高积木一样拼接成真正的处理器核心。LEG架构的设计初衷就是要解决原始图灵机指令宽度受…...

5个实战技巧深度解析:XUnity.AutoTranslator如何革新Unity游戏多语言体验
5个实战技巧深度解析:XUnity.AutoTranslator如何革新Unity游戏多语言体验 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator作为一款创新的开源实时翻译插件,为…...

Phi-3-mini-128k-instruct与智能车仿真:生成自然语言控制逻辑与调试报告
Phi-3-mini-128k-instruct与智能车仿真:生成自然语言控制逻辑与调试报告 最近在折腾一个智能车仿真项目,发现一个挺有意思的事儿:让AI来帮忙写控制逻辑和看报告,效率提升了不少。以前我们得手动把“绕过前面那个障碍物࿰…...

Qwen3交互界面开发:利用JavaScript实现网页端字幕编辑器
Qwen3交互界面开发:利用JavaScript实现网页端字幕编辑器 1. 引言 做视频的朋友们,不知道你们有没有过这样的经历:用AI工具生成了视频字幕,时间轴对得总差那么一点,要么是话还没说完字幕就跳了,要么是沉默…...

Unity内联序列化类的秘密
一个藏在Inspector面板背后的"俄罗斯套娃" 一、开篇:一个看似简单的问题 你在Unity中写了一个脚本: public class Player : MonoBehaviour {public int health;public float speed...

Loop:让Mac窗口管理效率倍增的效率神器
Loop:让Mac窗口管理效率倍增的效率神器 【免费下载链接】Loop MacOS窗口管理 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 你是否也曾在多任务处理时,被杂乱无章的窗口搞得焦头烂额?切换应用时总要在一堆窗口中寻找目标&a…...
)
手把手教你用NEWLab搭建智能温控系统(附完整代码)
手把手教你用NEWLab搭建智能温控系统(附完整代码) 在智能家居和工业自动化领域,温度控制始终是核心需求之一。无论是保持室内舒适环境,还是确保精密设备的稳定运行,一套可靠的温控系统都不可或缺。对于物联网初学者和…...