tensorflow07——使用tf.keras搭建神经网络(Sequential顺序神经网络)——六步法——鸢尾花数据集分类
使用tf.keras搭建顺序神经网络
六步法——鸢尾花数据集分类
01 导入相关包
02 导入数据集,打乱顺序
03 建立Sequential模型
04 编译——确定优化器,损失函数,评测指标(用哪一种准确率)
05 训练模型——把各项参入填入模型
06 总结——打印网络结构
# 01
import tensorflow as tf
from sklearn import datasets
import numpy as np# 02
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
# 测试集可以在此处按照上述方法划分
# 本案例把测试集放到训练过程fit中,按照比例直接从训练集中划分(validation_split)# 乱序步骤
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)# 03
model = tf.keras.models.Sequential([# 定义全连接层tf.keras.layers.Dense(3,activation='softmax',kernel_regularizer=tf.keras.regularizers.l2())
])# 04
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])# 05
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2,validation_freq=20)# 06
model.summary()
输出结果
Train on 120 samples, validate on 30 samples
Epoch 1/500
120/120 [==============================] - 0s 3ms/sample - loss: 2.2022 - sparse_categorical_accuracy: 0.3833
Epoch 2/500
120/120 [==============================] - 0s 36us/sample - loss: 1.0013 - sparse_categorical_accuracy: 0.6083
Epoch 3/500
120/120 [==============================] - 0s 36us/sample - loss: 0.8497 - sparse_categorical_accuracy: 0.6333
。
。
此处省略500回合
。
。
。> Epoch 496/500 120/120 [==============================] - 0s
> 21us/sample - loss: 0.3384 - sparse_categorical_accuracy: 0.9583 Epoch
> 497/500 120/120 [==============================] - 0s 22us/sample -
> loss: 0.3442 - sparse_categorical_accuracy: 0.9750 Epoch 498/500
> 120/120 [==============================] - 0s 22us/sample - loss:
> 0.3394 - sparse_categorical_accuracy: 0.9583 Epoch 499/500 120/120 [==============================] - 0s 21us/sample - loss: 0.3394 -
> sparse_categorical_accuracy: 0.9333 Epoch 500/500 120/120
> [==============================] - 0s 168us/sample - loss: 0.4425 -
> sparse_categorical_accuracy: 0.8583 - val_loss: 0.3130 -
> val_sparse_categorical_accuracy: 0.9667 Model: "sequential"
> _________________________________________________________________ Layer (type) Output Shape Param #
> ================================================================= dense (Dense) multiple 15
> ================================================================= Total params: 15 Trainable params: 15 Non-trainable params: 0
> ________________________________________________________________
由于sequential是顺序模型,不方便在中间加入其他步骤
可以采取类封装的形式,新建一个类,将整个神经网络模型封装装起来
里面设置两个函数方法_ _ init _ _和call
_ _ init _ _用于定义网络结构块
call用于实现前向传播
import tensorflow as tf
from tensorflow.keras.layers import Dense #新增
from tensorflow.keras import Model #新增
from sklearn import datasets
import numpy as npx_train = datasets.load_iris().data
y_train = datasets.load_iris().targetnp.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)#类名 IrisModel
class IrisModel(Model):def __init__(self):super(IrisModel, self).__init__()#定义——网络结构块self.d1 = Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())def call(self, x):#调用——网络结构快,实现前向传播y = self.d1(x)return ymodel = IrisModel()model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary()
相关文章:
——六步法——鸢尾花数据集分类)
tensorflow07——使用tf.keras搭建神经网络(Sequential顺序神经网络)——六步法——鸢尾花数据集分类
使用tf.keras搭建顺序神经网络 六步法——鸢尾花数据集分类 01 导入相关包 02 导入数据集,打乱顺序 03 建立Sequential模型 04 编译——确定优化器,损失函数,评测指标(用哪一种准确率) 05 训练模型——把各项参入填入…...

关于Java连接Hive,Spark等服务的Kerberos工具类封装
关于Java连接Hive,Spark等服务的Kerberos工具类封装 idea连接服务器的hive等相关服务的kerberos认证注意事项 idea 本地配置,连接服务器;进行kerberos认证,连接hive、HDFS、Spark等服务注意事项: 本地idea连接Hadoo…...

大数据框架之Hadoop:MapReduce(五)Yarn资源调度器
Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。 简言之,Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源&…...
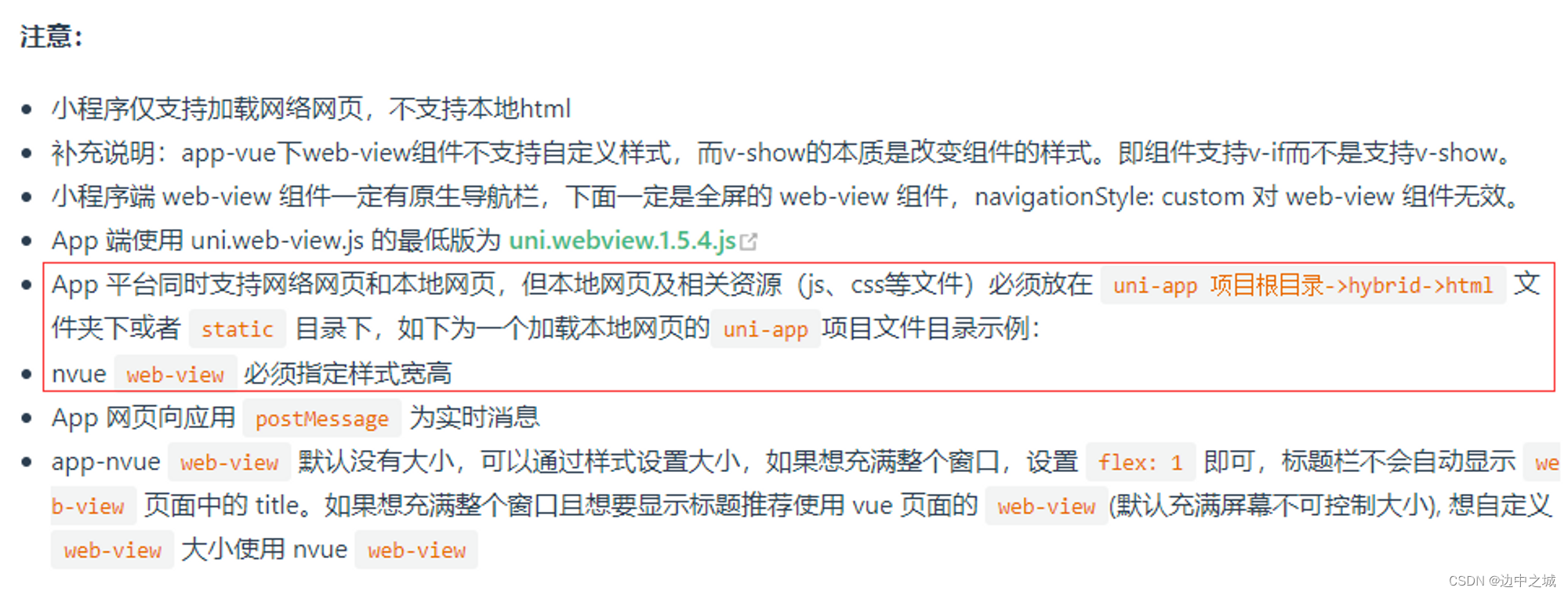
uniapp实现地图点聚合功能
前言 在工作中接到的一个任务,在app端实现如下功能: 地图点聚合地图页面支持tab切换(设备、劳务、人员)支持人员搜索显示分布 但是uniapp原有的map标签不支持点聚合功能(最新的版本支持了点聚合功能)&am…...
)
经典分类模型回顾2—GoogleNet实现图像分类(matlab版)
GoogleNet是深度学习领域的一种经典的卷积神经网络,其在ImageNet图像分类任务上的表现十分优秀。下面是使用Matlab实现GoogleNet的图像分类示例。 1. 数据准备 在开始之前,需要准备一些图像数据用来训练和测试模型,可以从ImageNet等数据集中…...

Java经典面试题——谈谈 final、finally、finalize 有什么不同?
典型回答 final 可以用来修饰类、方法、变量,分别有不同的意义,final 修饰的 class 代表不可以继承扩展, final 的变量是不可以修改的,而 final 的方法也是不可以重写的(override)。 finally 则是 Java 保…...

C#的Version类型值与SQL Server中二进制binary类型转换
使用C#语言编写的应用程序可以通过.NET Framework框架提供的Version类来控制每次发布的版本号,以便更好控制每次版本更新迭代。 版本号由两到四个组件组成:主要、次要、内部版本和修订。 版本号的格式如下所示, 可选组件显示在方括号 ([ 和…...
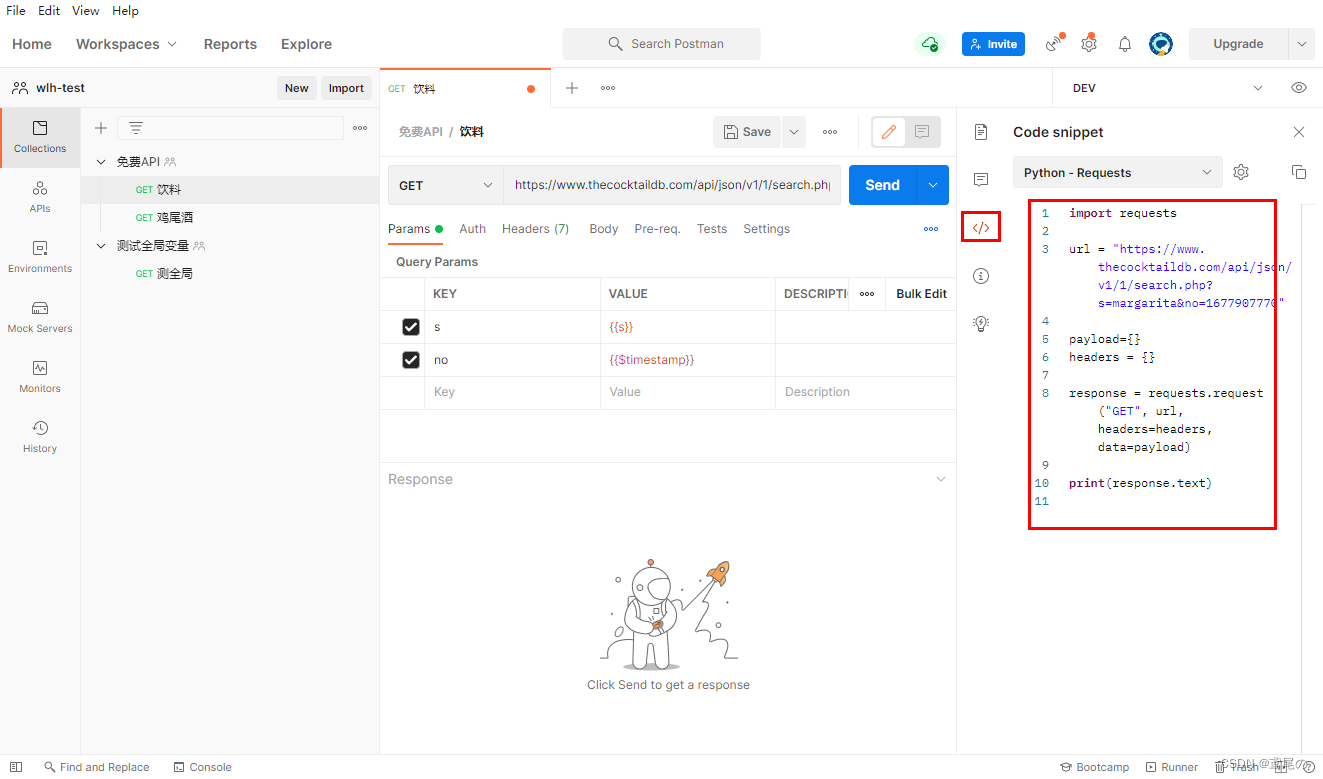
软测入门(五)接口测试Postman
Postman 一款Http接口收工测试工具。如果做自动化测试会使用jemter做。 安装 去官网下载即可。 https://www.postman.com/downloads/?utm_sourcepostman-home 功能介绍 页面上的单词基本上都能了解,不多介绍。 转代码&注释 可将接口的访问转为其他语言的…...
UWB通道选择、信号阻挡和反射对UWB定位范围和定位精度的影响
(一)介绍检查NLOS操作时需要考虑三个方面:(1)由于整体信号衰减,通信范围减小。(2)由于直接路径信号的衰减,导致直接路径检测范围的减小。(3)由于阻…...

linux基本功之列之wget命令实战
文章目录前言一. wget命令介绍二. 语法格式及常用选项三. 参考案例3.1 下载单个文件3.2 使用wget -o 下载文件并改名3.3 -c 参数,下载断开链接时,可以恢复下载3.4 wget后台下载3.5 使用wget下载整个网站四. 补充与汇总常见用法总结前言 大家好ÿ…...

学习ROS时针对gazebo相关的问题(重装与卸载是永远的神)
ResourceNotFound:gazebo_ros 错误解决 参考:https://blog.csdn.net/weixin_42591529/article/details/123869969 当将机器人加载到gazebo时,运行launch文件出现如下错误 这是由于缺少gazebo包所导致的。 解决办法:...

几个C语言容易忽略的问题
1 取模符号自增问题 我们不妨尝试写这样的程序 #include<stdio.h> int main(){int n,t5;printf("%d\n",7%(-3));//1printf("%d\n",(-7)%3);//-1while(--t)printf("%d\n",t);t5;while(t--)printf("%d\n",t);return 0; } 运行…...
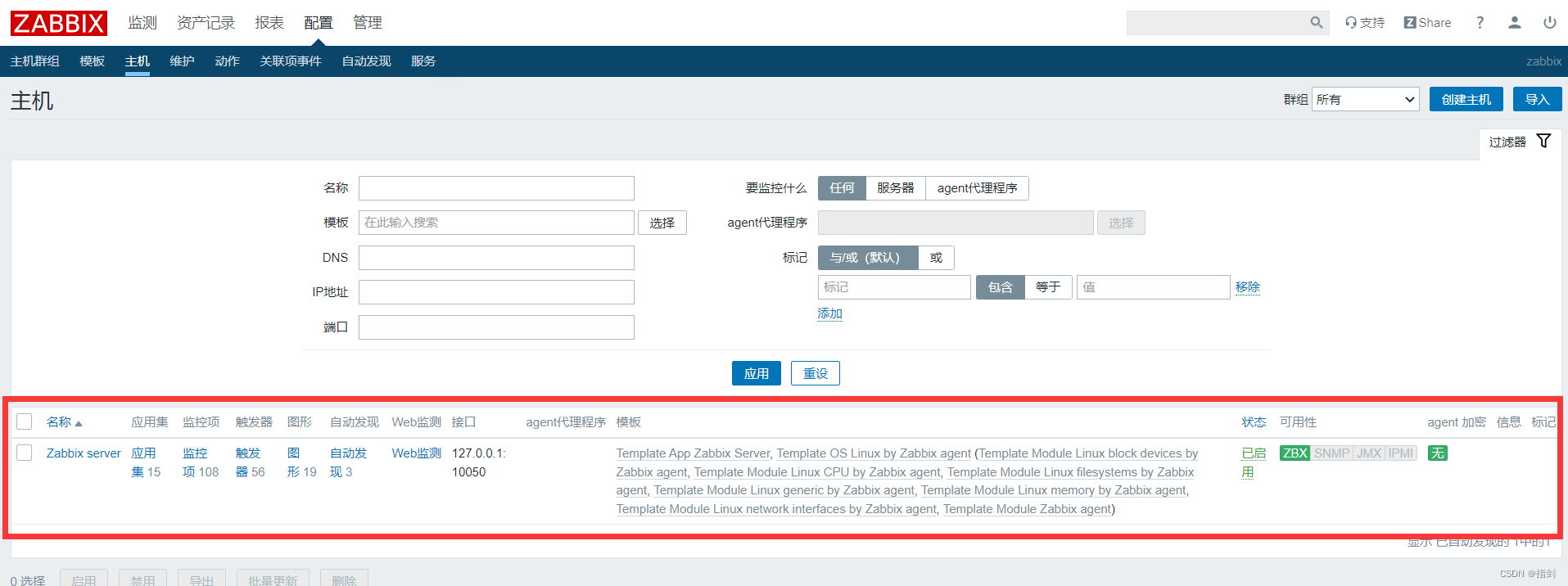
CentOS 7.9安装Zabbix 4.4《保姆级教程》
CentOS 7.9安装Zabbix 4.4一、配置一览二、环境准备设置Selinux和firewalld设置软件源1.配置ustc CentOS-Base源2.安装zabbix 4.4官方源3.安装并更换epel源4.清除并生成缓存三、安装并配置Zabbix Server安装zabbix组件安装php安装mariadb并创建数据库修改zabbix_server.conf设置…...

路由器与交换机的区别(基础知识)
文章目录交换机路由器路由器和交换机的区别(1)工作层次不同(2)数据转发所依据的对象不同(3)传统的交换机只能分割冲突域,不能分割广播域;而路由器可以分割广播域(4&#…...

Python基础学习9——函数
基本概念 函数是一种能够完成某项任务的封装工具。在数学中,函数是自变量到因变量的一种映射,通过某种方式能够使自变量的值变成因变量的值。其实本质上也是实现了某种值的转换的任务。 函数的定义 在python中,函数是利用def来进行定义&am…...
项目中的MD5、盐值加密
首先介绍一下MD5,而项目中用的是MD5和盐值来确保密码的安全性; 1. md5简介 md5的全称是md5信息摘要算法(英文:MD5 Message-Digest Algorithm ),一种被广泛使用的密码散列函数,可以产生一个128位…...
电商项目后端框架SpringBoot、MybatisPlus
后端框架基础 1.代码自动生成工具 mybatis-plus (1)首先需要添加依赖文件 <dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.2</version></dependency><de…...

2023年03月IDE流行度最新排名
点击查看最新IDE流行度最新排名(每月更新) 2023年03月IDE流行度最新排名 顶级IDE排名是通过分析在谷歌上搜索IDE下载页面的频率而创建的 一个IDE被搜索的次数越多,这个IDE就被认为越受欢迎。原始数据来自谷歌Trends 如果您相信集体智慧&am…...
)
华为校招机试 - 数组取最小值(Java JS Python)
目录 题目描述 输入描述 输出描述 用例 题目解析 JavaScript算法源码 Java算法源码...

20 客户端服务订阅的事件机制剖析
Nacos客户端服务订阅的事件机制剖析 我们已经分析了Nacos客户端订阅的核心流程:Nacos客户端通过一个定时任务,每6秒从注册中心获取实例列表,当发现实例发生变化时,发布变更事件,订阅者进行业务处理,然后更…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...

基于Arduino与433MHz射频的智能灯光定时系统设计与实现
1. 项目概述:告别机械定时器,打造智能灯光管家家里前后院的照明,还有出门度假时屋内的几盏灯,过去一直靠四个老旧的机械定时器来管理。说实话,这玩意儿用起来真是费劲。它的核心问题在于“死板”——你设定好晚上7点开…...

从无线破解到PDF解密:盘点那些容易被忽略的‘非主流’密码审计场景与工具
密码安全审计的隐秘战场:从无线网络到加密文档的实战指南 当大多数人谈论密码安全时,脑海中浮现的往往是服务器登录、数据库访问这些企业级场景。然而在数字生活的每个角落,从家庭Wi-Fi到工作文档,密码保护的脆弱性同样可能成为安…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...

Windows HEIC缩略图解决方案:让iPhone照片在资源管理器中重获新生
Windows HEIC缩略图解决方案:让iPhone照片在资源管理器中重获新生 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 想…...

Safe Exam Browser 虚拟化检测绕过技术深度实践
Safe Exam Browser 虚拟化检测绕过技术深度实践 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在现代教育技术领域,Safe Exam Browser&…...