NLP论文阅读记录 - 2022 | WOS 数据驱动的英文文本摘要抽取模型的构建与应用
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.相关工作
- 三.本文方法
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 4.6 细粒度分析
- 五 总结
前言

Construction and Application of a Data-Driven Abstract Extraction Model for English Text(2204)
0、论文摘要
本文以单个英文文本为研究对象,采用数据驱动的方法研究文本摘要的自动提取方法。 +is论文以单个文本为研究对象,建立文章句子之间的连接关系,提出一种基于图模型和主题模型的文本摘要自动提取方法。 +e方法结合文本图模型、复杂网络理论和LDA主题模型构建句子综合评分函数来计算文本单句权重,并将文本阈值内的句子按降序输出作为文本摘要。 +e算法提高了文本摘要的可读性,同时为文本摘要提供了足够的信息。
在本文中,我们提出了一种基于神经主题模型的基于 BERT 的主题感知文本摘要模型。 +e方法利用神经主题模型编码的潜在主题嵌入表示与BERT的嵌入表示相匹配来指导主题生成,以满足文本语义表示的要求,并在端到端中联合探索主题推理和摘要生成。通过变压器架构以最终方式捕获语义特征,同时通过自我关注机制对远程依赖关系进行建模。
在本文中,我们提出了基于提取和生成算法的预训练模型的改进,使它们增强了全局信息记忆。结合两种算法的优点,提出了一种新的联合模型,使得能够生成与原始主题更加一致的摘要,并且对于均匀分布的文章信息具有降低的重复率。对多个数据集进行了对比实验,构建了小型均匀分布的私有数据集。在多次对比实验中,评价指标提高了高达2.5个百分点,证明了该方法的有效性,并构建了自动摘要生成原型系统来验证结果。
一、Introduction
1.1目标问题
+文本的价值不在于静态数据,而在于文本理解和传递所产生的数据和信息的价值。近年来,对大量文本的自动化处理而不是手动注释的需求不断增长,这迫使需要对机器进行训练来学习人类如何处理文本和理解通信[1]。自然语言处理的存在是为了让机器能够更好地模仿人类对自然语言的处理,能够像人脑一样智能地执行自动语音对话、自动文本编写和其他大数据任务等任务。在这个劳动力成本极其昂贵的大数据时代,自然语言处理技术可以从文本中获取大量信息和价值,成为未来人类与机器无障碍沟通的重要技术之一[2]。 TFIDF改善了词频统计方法的不足。除了考虑词频之外,它还计算词的逆文档频率。 +e的基本思想是,如果一个词出现在语料库中的大部分文章中,即使该词的词频很高,但它的TFIDF值也不一定很高。
尽管人工智能近年来在各个领域取得了快速发展,计算机比人类任何时代都更接近人脑,但计算机不是人脑,无法理解含义并准确生成认知。像人类一样阅读一些相关文本,但他们只能通过统计、机器学习、简单推理机和基本记忆机制来处理文档[3]。 +他们只能提取或简单地“思考处理”文档,通过统计、机器学习、简单的推理机以及基本的记忆机制来组成文章的最终摘要。本文的+e模型对于长文本的上下文语义获取更加准确,并且提高了长距离的依赖能力。当输入文本较短时,发现纯Transformer模型和PGEN模型的评价指标结果相似,说明简单的Transformer模型处理短文本的能力很强,生成能力可以媲美LSTM 网络增加了注意力机制。然而,我们期望文本摘要是对文本的“深刻理解”,而计算机并不能“理解”文档的真正含义。目前大多数关于自动文本摘要的研究倾向于从原始文本中提取表达文本核心含义的句子,使其包含尽可能多的文本信息[4]。然而,无论从文档中提取哪些句子,都无法完全表达文本的主要含义。近年来,随着神经网络序列模型和分布式表示学习在自然语言处理任务中的技术突破和创新,文本摘要及其应用越来越受到研究人员的关注。
1.2相关的尝试
1.3本文贡献
在社交网络时代,信息检索和自然语言处理中数据挖掘的快速发展使得自动文本摘要任务成为必要,如何有效地处理和利用文本资源已成为研究热点[5]。 +e 文本摘要任务旨在将文本转换为包含关键信息的摘要。当今的自动文本摘要方法主要分为提取模型和生成模型。尽管这些模型具有强大的编码能力,但它们仍然无法解决长文本依赖性和语义不准确的问题。因此,本文进行了深入研究,以进一步解决生成的摘要与源文本事实不匹配的主要问题[6]。
二.相关工作
+“数据驱动”一词最早来自计算机科学领域;当我们构建往往无法用准确真实(一般真实原理简单准确)方法解决的数学模型时,我们也会根据之前的历史数据,通过大量的数据细化,构建近似模型来逼近真实情况[7] ,由数据驱动控制模型得出。赫尔登斯等人。提出了模型驱动的数据再工程、用于创建元模型的模型转换 MDE 工具以及模型转换语言。 Bernhard Hohmann 提出了一种基于 GML 的建模语言来生成参数驱动的提取模型 [8]。在国外,数据驱动的方法已逐渐从通常用于计算机的数据转换和重新设计转向参数化设计和模型构建驱动。东北大学的徐和党在《数据驱动建模方法的仿真研究》中总结了联合供热站TE数据驱动建立的基于BP神经网络的模型[9]。徐等人。杜克大学的研究人员分析了 Revit Structure 和 Robot Structural Analysis 之间的双向联系,并将分析结果与 PKPM 的计算结果进行了比较 [10]。
自动文本摘要任务作为自然语言处理任务的重要分支受到越来越多的关注。从内容上来说,自动摘要分为单文档摘要和多文档摘要。从方法上来说,它分为抽取式总结和生成式总结[11]。主题建模是文本挖掘的强大工具之一,可以通过文本的先验知识挖掘数据之间、数据与文本之间的潜在联系。主题建模在处理离散数据的源文本时可以发挥最大的优势。 +这些模型使用吉布采样、非负矩阵分解、变分推理和其他机器学习算法从特征文本空间推断隐藏的主题信息,特别是对于高维和稀疏特征文本[12]。 +e概率主题模型诞生了,它从海量文本中提取出能够表达文本主题的主题词及其概率组合,并大量剖析文档语义,从而对文本进行更深层次的分类或聚类。早期的概率主题模型以PLSA和广泛使用的LDA模型为代表,吸引了越来越多的研究人员对主题模型从模型假设、参数推断、主题数量到监督等各个方面进行改进和应用。纳迪姆等人。使用LDA模型来标记源文本的主题,并使用形式概念分析来构建结构等等。拉金德拉等人。提出了一种启发式方法,通过潜在的狄利克雷分配技术来确保生成的文本包含语料库原始文档的必要组成信息,以匹配源文本的最佳主题数量[13]。此外,一些研究将基于Pinball分配模型(PAM)的两级主题模型与文本排名算法相结合来完成主题文本摘要。然而,这些传统的基于词共现的长文本主题建模算法有很大的局限性,文本中信息和词汇量有限的问题没有得到很好的解决[14]。
三.本文方法
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
4.6 细粒度分析
五 总结
本文基于数据驱动不确定性分析理论,提出一种数据驱动建模方法,通过对模型组件进行参数化设计,然后对其进行数据驱动分析,最后以Revit为载体进行参数化二次开发。组件来实现数据驱动建模。为了获得更高、更适合摘要的词向量表示,本文提出了一种结合词汇性的细粒度词向量表示方法,因为表示学习是进行自然语言处理的基础任务,也是后续进行自然语言研究的基石。相关任务。本文通过结合词汇和位置信息,构建了一种新的、细粒度的用于文本摘要的词向量表示,并结合<word,lexical>词向量的二维表表示来减少词向量查找表的大小,提高查询效率效率高,实验表明该方法具有更好的文本语义表示能力。由于现有方法大多关注摘要所包含的文本信息量而忽略摘要本身的连贯性,因此本文结合文本图模型、复杂网络理论和LDA主题模型构建句子综合评分函数来计算对文本单句进行加权,将文本阈值内的句子按降序输出作为文本摘要。 +e算法提高了摘要的可读性,同时在摘要中提供了足够的信息。在下一步的研究中,将加强对文本的语义分析,进一步完善文摘的语义信息;此外,还可以扩展自建语料库,探索本文方法对其他类型中文文本摘要的准确性和可读性的提高。
相关文章:
NLP论文阅读记录 - 2022 | WOS 数据驱动的英文文本摘要抽取模型的构建与应用
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结 前言 Construction and Application of a Data-Driven Abstract Extractio…...

虹科新闻丨LIBERO医药冷链PDF温度计完成2024年航空安全鉴定,可安全空运!
来源:虹科环境监测技术 虹科新闻丨LIBERO医药冷链PDF温度计完成2024年航空安全鉴定,可安全空运! 原文链接:https://mp.weixin.qq.com/s/XHT4kU27opeKJneYO0WqrA 欢迎关注虹科,为您提供最新资讯! 虹科LIBE…...

智能搬运机器人作为一种新型的物流技术
随着物流行业的快速发展,货物转运的效率和准确性成为了企业竞争的关键因素之一。智能搬运机器人作为一种新型的物流技术,已经在许多企业中得到了广泛应用。本文将介绍富唯智能智能搬运机器人在物流行业的应用和优势。 在实际应用中,智能搬运机…...

UI自动化测试工具对企业具有重要意义
随着软件行业的不断发展,企业对高质量、高效率的软件交付有着越来越高的要求。在这个背景下,UI自动化测试工具成为了企业不可或缺的一部分。以下是UI自动化测试工具对企业的重要作用: 1. 提高软件质量 UI自动化测试工具能够模拟用户的操作&am…...

Linux--进程状态与优先级
概念 进程指的是程序在执行过程中的活动。进程是操作系统进行资源分配和调度的基本单位。 进程可以看作是程序的一次执行实体,它包含了程序代码、数据以及相关的执行上下文信息。操作系统通过创建、调度和管理多个进程来实现对计算机系统资源的有效利用。 每个进程…...
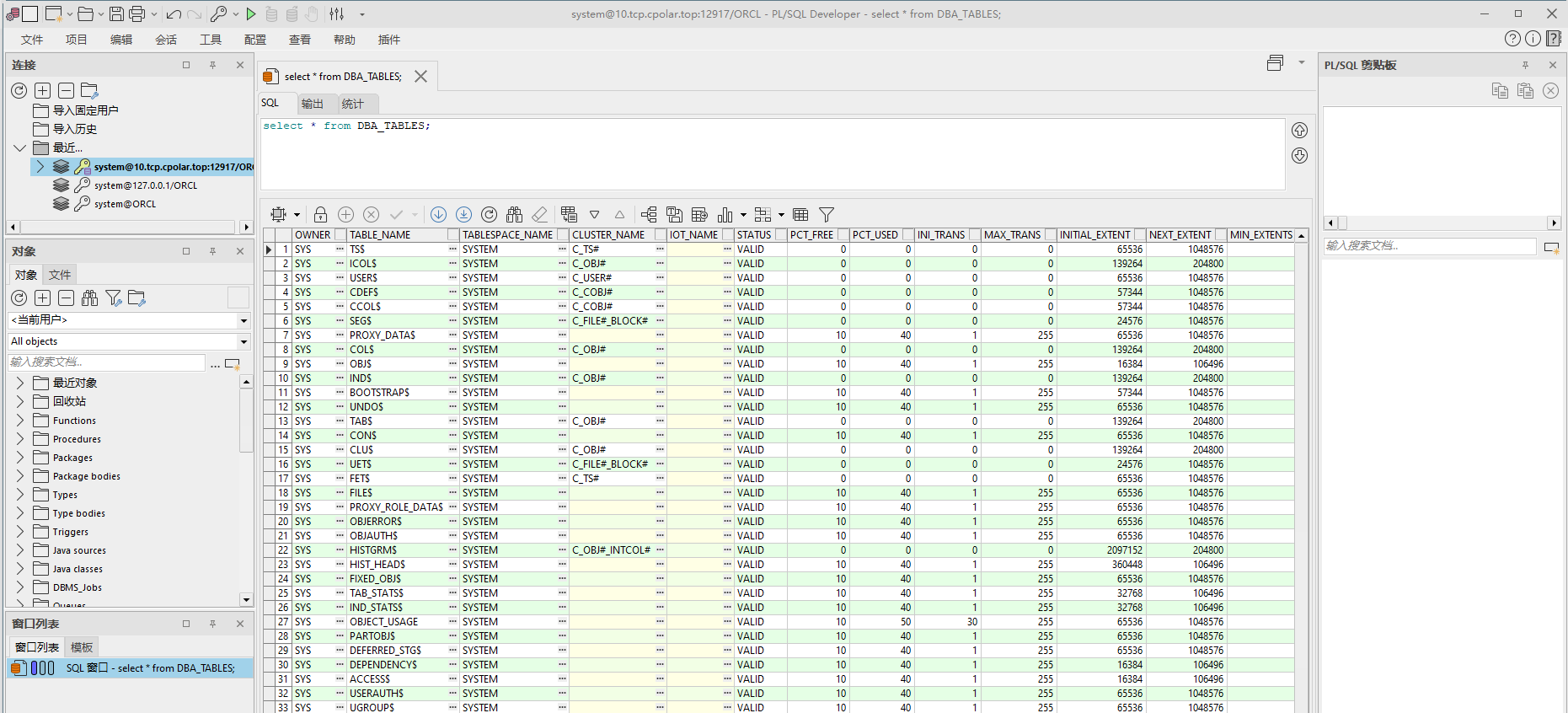
如何实现无公网ip固定TCP端口地址远程连接Oracle数据库
文章目录 前言1. 数据库搭建2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射 3. 公网远程访问4. 配置固定TCP端口地址4.1 保留一个固定的公网TCP端口地址4.2 配置固定公网TCP端口地址4.3 测试使用固定TCP端口地址远程Oracle 前言 Oracle,是甲骨文公司的一款关系…...
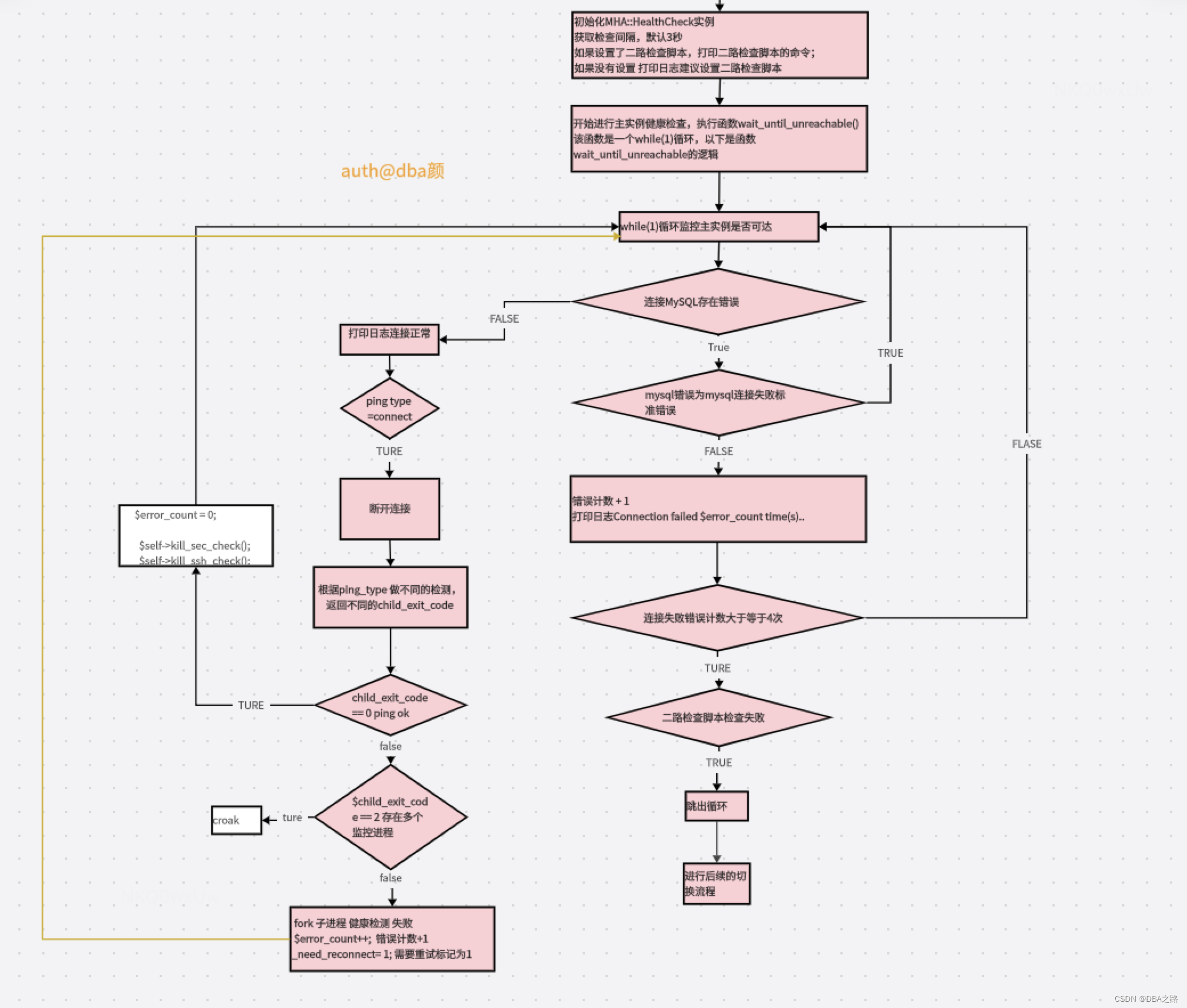
Orchestrator源码解读2-故障失败发现
目录 前言 核心流程函数调用路径 GetReplicationAnalysis 故障类型和对应的处理函数 编辑 拓扑结构警告类型 核心流程总结 与MHA相比 前言 Orchestrator另外一个重要的功能是监控集群,发现故障。根据从复制拓扑本身获得的信息,它可以识别各种故…...

REST2SQL是什么?它有什么功能和特性?它值不值得我们去学习?我们该如何去学习呢?
REST2SQL是一种将RESTful API转换为SQL查询的工具或技术。它可以将RESTful API中的请求转换为对数据库的SQL查询,以便从数据库中检索、更新或删除数据。 REST2SQL的工作原理是通过分析RESTful API的请求参数和路径,将其转换为相应的SQL查询语句。这样可…...

Android 实现获取集合中出现重复数据的值和数量
方法一:使用HashMap和HashSet 创建一个HashMap,用于存储集合中的元素及其出现次数。 Map<String, Integer> map new HashMap<>();遍历集合,将每个元素作为键,将其出现次数作为值添加到HashMap中。 for (String it…...

【QT学习十一】QThread
一、引言 在现代软件开发中,多线程编程变得越来越重要,尤其是对于需要处理并发任务的应用程序。Qt C 框架提供了强大的多线程支持,使得开发者能够轻松地创建和管理多线程应用。 在 Qt 中,多线程的实现主要基于 QThread 类。QThrea…...

Mybatis 39_使用MBG生成代码
此2个插件均未晚装成功!!!! 安装 MyBatipse插件 MyBatipse插件 - 开发MyBatis应用的Eclipse插件- 自动完成- 有效性验证- Mapper视图使用MBG MyBatis Generator (MBG):根据底层数据表来自动生成Mapper组件只要两步即可: (1) 提供一个简单的配置文件,告诉MBG连接数据…...
)
Hudi metadata table(元数据表)
什么是metadata表 Metadata表即Hudi元数据表,是一种特殊的Hudi表,对用户隐藏。该表用于存放普通Hudi表的元数据信息。Metadata表包含在普通Hudi表内部,与Hudi表是一一对应关系。 元数据表的作用 ApacheHudi元数据表可以显著提高查询的读/写性能。元数据表的主要目的是消…...

提高iOS App开发效率的方法
引言 随着智能手机的普及,iOS App开发成为越来越受欢迎的技术领域之一。许多人选择开发iOS应用程序来满足市场需求,但是iOS App开发需要掌握一些关键技术和工具,以提高开发效率和质量。本文将介绍一些关键点,可以帮助你进行高效的…...

MPU机制与实现详解
目录 MPU机制与实现详解 Partition元素-MPU Partition实现元素OSApplication Partition元素-RTE MPU机制与实现详解 1、freedom from interference 此概念来自ISO26262-1:多个元素之间没有可能导致违反安全目标的级联故障,称之为免于干涉。 在左侧的…...
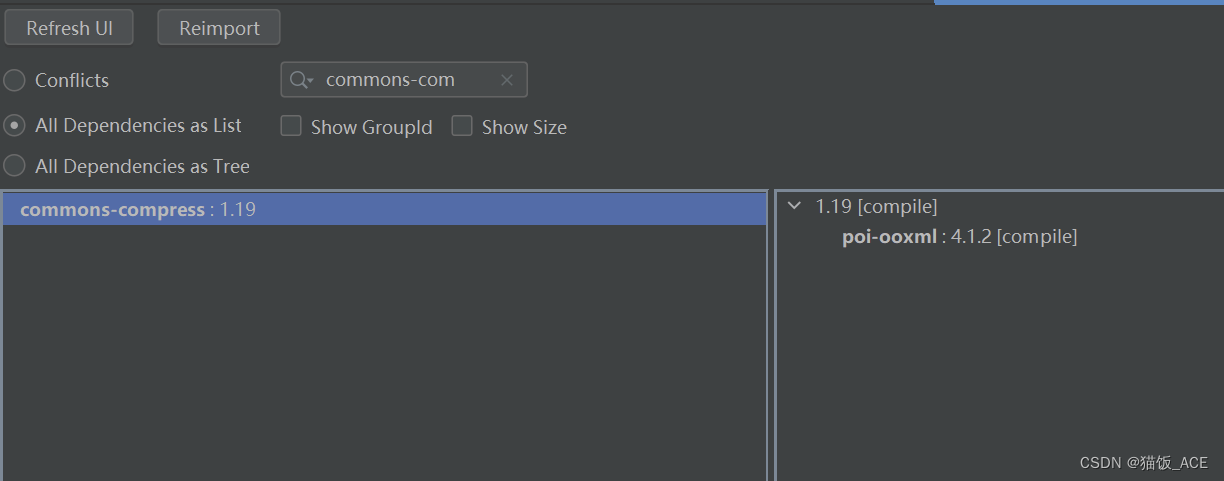
pom文件冲突引起的Excel无法下载
问题一:之前生产环境上可以进行下载Excel的功能突然不能用了 报错提示信息: NoClassDefFoundError: Could not initialize class org.apache.poi.xssf.usermodel.XSSFWorkbook, 在最开始初始化的时候找不到对应的类,虽然我的Libr…...

【HarmonyOS4.0】第十篇-ArkUI布局容器组件(二)
三、层叠布局容器(Stack) 堆叠容器组件 Stack的布局方式是把子组件按照设置的对齐方式顺序依次堆叠,后一个子组件覆盖在前一个子组件上边。 注意:Stack 组件层叠式布局,尺寸较小的布局会有被遮挡的风险, …...

PLECS如何下载第三方库并导入MOSFET 的xml文件,xml库路径添加方法及相关问题
1. 首先xml库的下载,PLECS提供了一个跳转的链接。 https://www.plexim.com/download/thermal_models 2. 下载一个库(以最后一个Wolfspeed为例,属于CREE的SiC MOSFET) 下载这个就行,都包含了。不信自己可以试试再下载…...
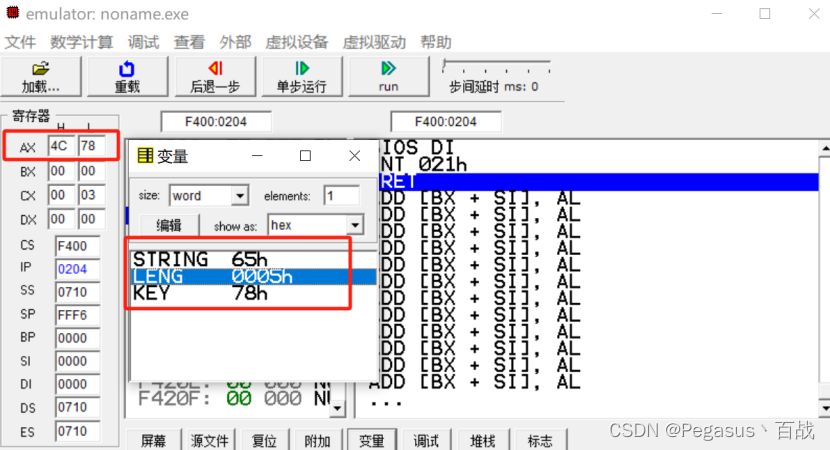
使用emu8086实现——子程序的设计
一、实验目的 学习子程序的结构、特点,以及子程序的设计和调试方法 二、实验内容 1、从字符串中删除一个字符,并存储到寄存器AX中。 代码及注释: data segmentstring db exas ;字符串内容leng dw $-string ; 字符串长度key db x …...
)
快速排序、归并排序、希尔排序(2023-12-25)
参考文章 十大经典排序算法总结整理_十大排序算法-CSDN博客 推荐文章 算法:归并排序和快排的区别_归并排序和快速排序的区别-CSDN博客 package com.tarena.test.B20; import java.util.Arrays; import java.util.StringJoiner; public class B25 { static i…...

Qt SDL2播放Wav音频
这里介绍两种方法来实现Qt播放Wav音频数据。 方法一:使用QAudioOutput pro文件中加入multimedia模块。 #include <QApplication> #include <QFile> #include <QAudioFormat> #include <QAudioOutput>int main(int argc, char *argv[]) {…...

从RNN的“失忆症”到LSTM的“记忆宫殿”:图解三个门控单元如何拯救梯度消失
从RNN的"失忆症"到LSTM的"记忆宫殿":图解三个门控单元如何拯救梯度消失 想象一下,你正在阅读一本精彩的小说,但每翻过一页就会忘记前一页的大部分内容——这就是标准RNN神经网络面临的困境。在自然语言处理和时间序列分析…...

ARM GICv4.1 GICD_TYPER2寄存器详解与虚拟化应用
1. GICD_TYPER2寄存器概述 GICD_TYPER2是ARM GICv4.1架构中引入的关键寄存器,属于中断控制器类型寄存器家族。作为GIC Distributor的一部分,它专门用于增强虚拟化场景下的中断管理能力。这个32位寄存器位于内存映射地址Dist_base 0x000C处,仅…...

恶意 Hugging Face 仓库 18 小时登顶热门榜,引发公共 AI 仓库安全担忧
【事件概述】一个伪装成 OpenAI 发布内容的恶意 Hugging Face 仓库,向 Windows 系统投放信息窃取恶意软件。该仓库在 18 小时内登上 Hugging Face 热门排行榜首位,被移除前下载量达 24.4 万次,引发人们对企业从公共仓库获取和验证 AI 模型的新…...

HDiffPatch嵌入式系统应用:如何在MCU和NB-IoT设备上实现OTA更新
HDiffPatch嵌入式系统应用:如何在MCU和NB-IoT设备上实现OTA更新 【免费下载链接】HDiffPatch a C\C library and command-line tools for Diff & Patch between binary files or directories(folder); cross-platform; runs fast; create small delta/different…...

告别网盘限速困扰:网盘直链下载助手全面解析与应用指南
告别网盘限速困扰:网盘直链下载助手全面解析与应用指南 【免费下载链接】baiduyun 油猴脚本 - 一个免费开源的网盘下载助手 项目地址: https://gitcode.com/gh_mirrors/ba/baiduyun 还在为网盘下载速度缓慢而烦恼吗?网盘直链下载助手作为一款免费…...

LangChain集成MCP协议:构建模块化AI应用的新范式
1. 项目概述:当LangChain遇见MCP,构建下一代AI应用的新范式如果你最近在捣鼓LangChain,想给AI应用加点“料”,比如让它能实时查询数据库、调用外部API,甚至控制智能家居,那你大概率会遇到一个核心痛点&…...

社交媒体运营实战指南:从算法逻辑到内容变现的完整技能树
1. 项目概述:社交媒体技能库的构建与价值在信息爆炸的今天,社交媒体早已不是简单的“发发状态、看看朋友”的平台。无论是个人品牌塑造、产品推广、内容创作,还是求职招聘、行业洞察,社交媒体都扮演着至关重要的角色。然而&#x…...
研究(Matlab代码实现))
【CPO三维路径规划】豪猪算法CPO多无人机协同集群避障路径规划(目标函数:最低成本:路径、高度、威胁、转角)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

超净实验室建设公司厂家:如何根据需求选择方案|中南实验室建设
在半导体制造、地质微量元素分析、生物制药等高精度领域,实验环境的洁净度直接影响数据可靠性与产品良率。超净实验室作为核心基础设施,其建设需融合空气动力学、材料科学、自动化控制等多学科技术。 一、超净实验室建设公司厂家的设计规划:…...

别再死记硬背了!用这5个真实数据处理场景,彻底搞懂Python列表、字典和集合
别再死记硬背了!用这5个真实数据处理场景,彻底搞懂Python列表、字典和集合 当你第一次学习Python时,列表、字典和集合可能只是教科书上的几个定义。但真正掌握它们的关键,在于理解如何将这些数据结构转化为解决实际问题的工具。本…...