机器学习算法实战案例:时间序列数据最全的预处理方法总结
文章目录
- 1 缺失值处理
- 1.1 统计缺失值
- 1.2 删除缺失值
- 1.3 指定值填充
- 1.4 均值/中位数/众数填充
- 1.5 前后项填充
- 2 异常值处理
- 2.1 3σ原则分析
- 2.2 箱型图分析
- 3 重复值处理
- 3.1 重复值计数
- 3.2 drop_duplicates重复值处理
- 3 数据归一化/标准化
- 3.1 0-1标准化
- 3.2 Z-score标准化
- 技术交流
1 缺失值处理
数据缺失主要包括记录缺失和字段信息缺失等情况,其对数据分析会有较大影响,导致结果不确定性更加显著,缺失值的处理:
- 删除记录
- 数据插补
- 不处理
首先导入相应的库文件,处理缺失值的库主要是pandas。
import matplotlib.pyplot as plt
首先参加示例数据用于分析:
df = pd.DataFrame({'time':['2023-12-11 00:00','2023-12-11 01:00','2023-12-11 02:00','2023-12-11 03:00','2023-12-11 04:00','2023-12-11 05:00','2023-12-11 06:00','2023-12-11 07:00','2023-12-11 08:00','2023-12-11 09:00','2023-12-11 010:00'],'feature1':[12,33,45,23,np.nan,np.nan,66,54,np.nan,99,190],'feature2':[np.nan,3.3,4.5,np.nan,5.2,np.nan,6.6,5.4,np.nan,9.9,1.0]})

1.1 统计缺失值
(1) df.info()和df.describe()函数
可以通过df.info()函数大概查看缺失值情况,df.info()可以查看列的数据类型,数据数量信息,df.describe()函数用于查看数据的统计信息。
- info: info方法返回DataFrame中的行数,列数,DataFrame中每一列的名称以及该列的非空值的数目以及每一列的数据类型。
- describe: describe方法返回有关DataFrame中数字数据的一些有用统计信息,例如均值,标准偏差,最大值和最小值以及一些百分位数。
df.info()

(2) isnull,notnull判断是否是缺失值
- isnull:缺失值为True,非缺失值为False
- notnull:缺失值为False,非缺失值为True
df[df['feature2'].notnull()]df["column_name"].isnull().sum(axis=0)
1.2 删除缺失值
当数据存在缺失值,可以通过不同的方式删除缺失值
df.dropna()#只要某个数据行中有缺失值,则此操作就会将该行删除df.dropna(subset=['column_1', 'column_2'])#如果column_1和column_2两列数据中存在缺失值,则将缺失值所在的行删除,而不需要考虑其他列是否为缺失值df.dropna(axis=1,how="all")df.dropna(axis=0,subset=["Name","Age"])#将会删除"Name"和“Age"中有缺失值的行
1.3 指定值填充
缺失值插补有多种方法,可以通过df.fillna()函数实现:
- 均值/中位数/众数插补
- 临近值插补
- 插值法
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None,
- value 参数表示要填充的值
- method 参数表示填充的方法
- axis 参数表示要填充的轴(0 表示行,1 表示列)
- inplace 参数表示是否在原数据框上进行修改
- limit 参数表示最多填充多少个空值
- downcast 参数表示在填充完成后对数据进行类型转换。
指定值填充可以通过df.fillna和df.replace实现
df1.fillna(0,inplace = True)
# df.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad', axis=None)df2['feature1'].replace(np.nan,'0',inplace = True)
1.4 均值/中位数/众数填充
均值/中位数/众数可以通过 mean()、median()、mode()实现
df4['feature1'].fillna(df4['feature1'].mean(),inplace = True)df4['feature1'].fillna(df4['feature1'].median(),inplace = True)df4['feature1'].fillna(df4['feature1'].mode(),inplace = True)
1.5 前后项填充
前后项填充用前面和后面的值进行填充,一般两个一起用,避免最前面和最后面一行的值填充不到。
# pad / ffill → 用之前的数据填充 # backfill / bfill → 用之后的数据填充 df4['feature2'].fillna(method = 'pad',inplace = True)

2 异常值处理
异常值是指样本中的个别值,其数值明显偏离其余的观测值,异常值也称离群点,异常值的分析也称为离群点的分析
- 异常值分析 → 3σ原则 / 箱型图分析
- 异常值处理方法 → 删除 / 修正填补
首先创建一组数据用于分析:
data = pd.Series(np.random.randn(10000)*100)
2.1 3σ原则分析
首先计算均值和标准差,然后绘制密度曲线,发现数据服从正态分布。
mean = data.mean() # 计算均值std = data.std() # 计算标准差print('均值为:%.3f,标准差为:%.3f' % (mean, std))stats.kstest(data, 'norm', (mean, std))fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 6))data.plot(kind='kde', grid=True, style='-k', title='密度曲线', ax=ax1)
然后根据计算的均值和标准差通过3σ原则可视化异常值。
error = data[np.abs(data - mean) > 3 * std]data_c = data[np.abs(data - mean) <= 3 * std]print('异常值共%i条' % len(error))# 筛选出异常值error、剔除异常值之后的数据data_cax2.scatter(data_c.index, data_c, color='b', marker='.', alpha=0.3, label='正常值')ax2.scatter(error.index, error, color='r', marker='.', alpha=0.5, label='异常值')ax2.set_xlim([-10, 10010])

2.2 箱型图分析
与上面3σ原则分析类似,知识检测的标准笔筒,箱型图分析采用四分位数进行统计。首先计算基本的统计量,然后绘值箱型图。
data = pd.Series(np.random.randn(10000) * 100)fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 6))print('分位差为:%.3f,下限为:%.3f,上限为:%.3f' % (iqr, mi, ma))color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray')data.plot.box(vert=False, grid=True, color=color, ax=ax1, label='样本数据')
然后根据计算的统计量通过四分位数可视化异常值。
# 筛选出异常值error、剔除异常值之后的数据data_cerror = data[(data < mi) | (data > ma)]data_c = data[(data >= mi) & (data <= ma)]print('异常值共%i条' % len(error))ax2.scatter(data_c.index, data_c, color='b', marker='.', alpha=0.3, label='正常值')ax2.scatter(error.index, error, color='r', marker='.', alpha=0.5, label='异常值')ax2.set_xlim([-10, 10010])

3 重复值处理
3.1 重复值计数
同样创建一组数据用于分析,数据的1和2行是重复数据:
df = pd.DataFrame({'time':['2023-12-11 00:00','2023-12-11 00:00','2023-12-11 01:00','2023-12-11 02:00','2023-12-11 03:00','2023-12-11 04:00','2023-12-11 05:00','2023-12-11 06:00','2023-12-11 07:00','2023-12-11 08:00','2023-12-11 09:00','2023-12-11 010:00'],'feature1':[12,12,33,45,23,np.nan,np.nan,66,54,np.nan,99,190],'feature2':[5.8,5.8,3.3,4.5,np.nan,5.2,np.nan,6.6,5.4,np.nan,9.9,1.0]})

可以通过下面的的语句查看重复值,可以看到有1个重复项:
df.duplicated().value_counts()

3.2 drop_duplicates重复值处理
用df.drop_duplicates的方法对某几列下面的重复行删除。
df.drop_duplicates(subset=None, keep='first', inplace=False)
-
subset:是用来指定特定的列,默认为所有列
-
keep:
当keep='first'时,就是保留第一次出现的重复行,其余删除 当keep='last'时,就是保留最后一次出现的重复行,其余删除 当keep=False时,就是删除所有重复行 -
inplace是指是否直接在原数据上进行修改,默认为否
df.drop_duplicates(keep='first',inplace=True)

3 数据归一化/标准化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上
- 0-1标准化
- Z-score标准化
3.1 0-1标准化
将数据的最大最小值记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理,计算公式
- x = (x - Min) / (Max - Min)
同样创建一组数据用于分析:
df = pd.DataFrame({"feature1": np.random.rand(10) * 20, 'feature2': np.random.rand(10) * 100})

使用公式进行标准化:
def data_norm(df, *cols):max_val = df_n[col].max()min_val = df_n[col].min()df_n[col] = (df_n[col] - max_val) / (max_val - min_val)df_n = data_norm(df, 'feature1', 'feature2')

使用库函数实现0-1标准化:
from sklearn.preprocessing import MinMaxScalerX_scaled = scaler.fit_transform(df['feature1'].values.reshape(-1, 1))
3.2 Z-score标准化
Z分数(z-score),是一个分数与平均数的差再除以标准差的过程 → z=(x-μ)/σ,其中x为某一具体分数,μ为平均数,σ为标准差,Z值的量代表着原始分数和母体平均值之间的距离,是以标准差为单位计算。在原始分数低于平均值时Z则为负数,反之则为正数。
同样创建一组数据用于分析:
df = pd.DataFrame({"feature1":np.random.rand(10) * 100,'feature2':np.random.rand(10) * 100})
使用公式进行标准化,归一化后可以检测数据的均值和标准差:
def data_Znorm(df, *cols):u = df_n[col].mean()std = df_n[col].std()df_n[col] = (df_n[col] - u) / std# 使用功能函数实现Z-score标准化并替换原始数据df = data_Znorm(df, 'feature1', 'feature2')
使用库函数实现z-score标准化:
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()X_scaled = scaler.fit_transform(df['feature1'].values.reshape(-1, 1))
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
本文相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
方式②、添加微信号:dkl88194,备注:来自CSDN + 技术交流
我们打造了《机器学习算法实战案例宝典》,特点:从0到1轻松学习,方法论及原理、代码、案例应有尽有,所有案例都按照这样的节奏进行的整理。

相关文章:
机器学习算法实战案例:时间序列数据最全的预处理方法总结
文章目录 1 缺失值处理1.1 统计缺失值1.2 删除缺失值1.3 指定值填充1.4 均值/中位数/众数填充1.5 前后项填充 2 异常值处理2.1 3σ原则分析2.2 箱型图分析 3 重复值处理3.1 重复值计数3.2 drop_duplicates重复值处理 3 数据归一化/标准化3.1 0-1标准化3.2 Z-score标准化 技术交…...
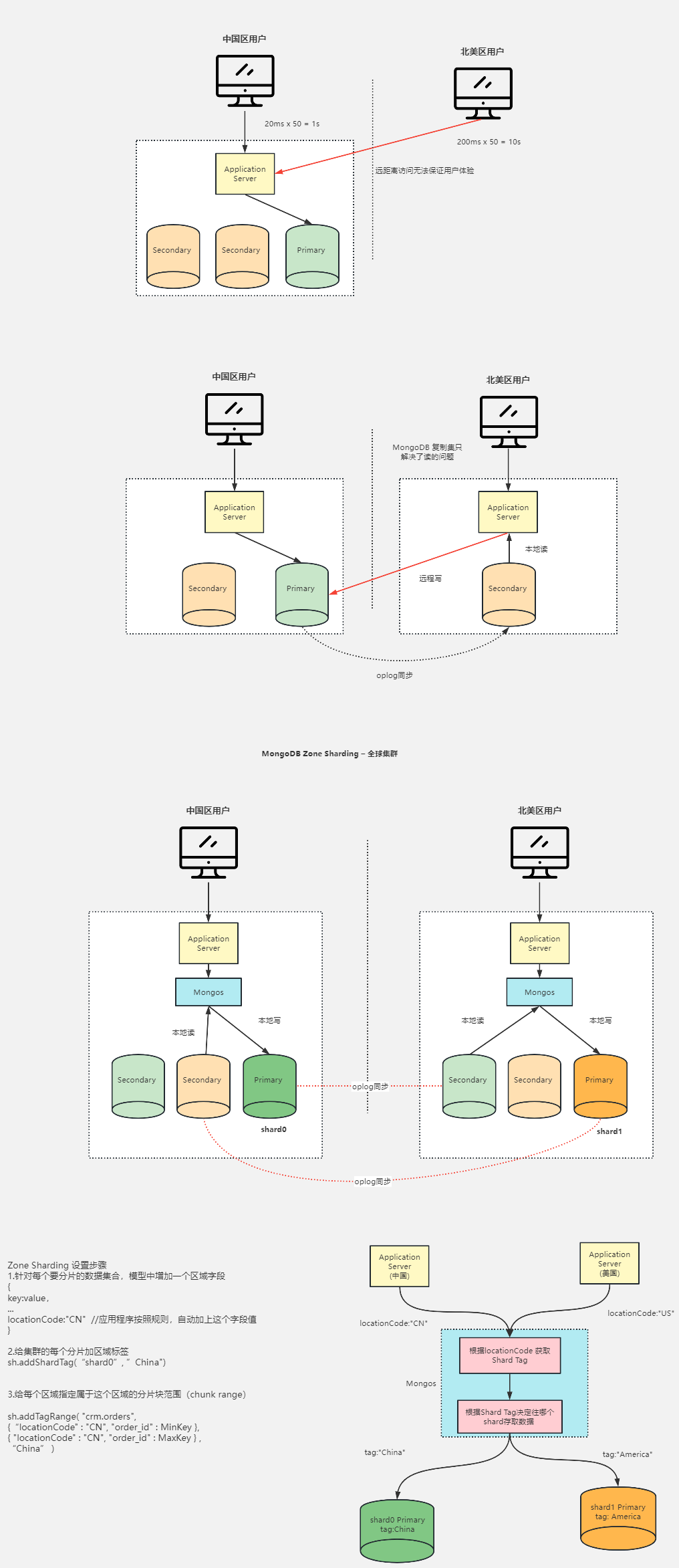
MongoDB高级集群架构设计
两地三中心集群架构设计 容灾级别 RPO & RTO RPO(Recovery Point Objective):即数据恢复点目标,主要指的是业务系统所能容忍的数据丢失量。RTO(Recovery Time Objective):即恢复时间目标&…...

C++中JSON与string格式互转
1、JSON-》string 操作步骤: 1、在C中新建一个json对象并赋值,然后将其转给char *data。 2、在使用 #include <json.h> 头文件时,通常是使用第三方库 jsoncpp。由于它不是标准库的一部分,所以需要从官网http://jsoncpp.sou…...

2023一带一路暨金砖国家技能发展与技术创新大赛 【企业信息系统安全赛项】国内赛竞赛样题
2023一带一路暨金砖国家技能发展与技术创新大赛 【企业信息系统安全赛项】国内赛竞赛样题 2023一带一路暨金砖国家技能发展与技术创新大赛 【企业信息系统安全赛项】国内赛竞赛样题第一阶段: CTF 夺旗项目1. CTF 夺旗任务一 命令注入任务二 SQL 注入 项目2. 序列化漏…...

【BBuf的CUDA笔记】十二,LayerNorm/RMSNorm的重计算实现
带注释版本的实现被写到了这里:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/apex 由于有很多个人理解,读者可配合当前文章谨慎理解。 0x0. 背景 我也是偶然在知乎的一个问题下看到这个问题,大概就是说在使用apex的…...
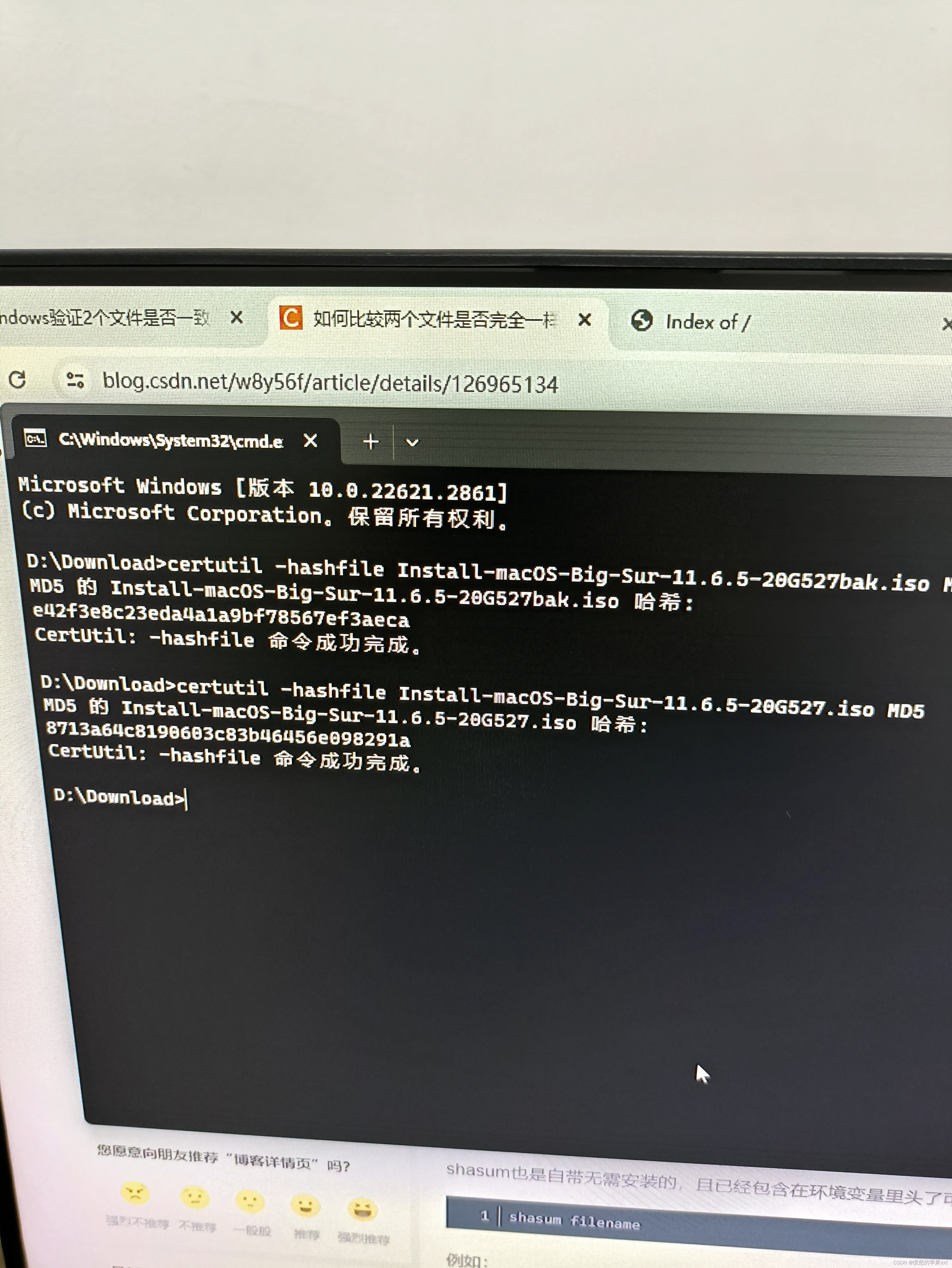
安装Mac提示安装无法继续,因为安装器已损坏
目录 事件起因报错原因 事件起因 有两台电脑,由于电脑1下载镜像文件很快,于是我先用电脑1下载这个大文件,然后安装openresty,电脑2用http链接下载这个大文件。电脑2安装中途就报安装无法继续,因为安装器已损坏。 报错原因 不知…...

脚本编程游戏引擎会遇到哪些问题
在游戏开发中,脚本编程已经成为了一种非常常见的方式,用来实现游戏逻辑和功能。但是脚本编程游戏引擎也可能会面临一些挑战和问题。下面简单的探讨一下都会遇到哪些问题,并且该如果做。 性能问题 脚本语言通常需要运行时解释执行࿰…...
什么软件可以做报表?
数据报表,是商业领域中不可或缺的一部分,它通过表格、图表等形式,将复杂的数据进行整理、分析并呈现出来,帮助用户更好地理解数据的趋势和关系。数据报表不仅展示了业务现状和趋势,还支持多种数据分析和挖掘功能&#…...

数据结构学习 jz39 数组中出现次数超过一半的数字
关键词:排序 摩尔投票法 摩尔投票法没学过所以没有想到,其他的都自己想。 题目:库存管理 II 方法一: 思路: 排序然后取中间值。因为超过一半所以必定在中间值是我们要的结果。 复杂度计算: 时间复杂度…...

基于Linux的Flappy bird游戏开发
项目介绍 主要是使用C语言实现,开启C项目之旅。 复习巩固C语言、培养做项目的思维。 功能: 按下空格键小鸟上升,不按下落; 显示小鸟需要穿过的管道; 小鸟自动向右飞行;(管道自动左移和创建&a…...

排序算法6---快速排序(非递归)(C)
回顾递归的快速排序,都是先找到key中间值,然后递归左区间,右区间。 那么是否可以实现非递归的快排呢?答案是对的,这里需要借助数据结构的栈。将右区间左区间压栈(后进先出),然后取出…...

【Verilog】期末复习——设计带异步清零且高电平有效的4位循环移位寄存器
系列文章 数值(整数,实数,字符串)与数据类型(wire、reg、mem、parameter) 运算符 数据流建模 行为级建模 结构化建模 组合电路的设计和时序电路的设计 有限状态机的定义和分类 期末复习——数字逻辑电路分…...

银行网络安全实战对抗体系建设实践
文章目录 前言一、传统攻防演练面临的瓶颈与挑战(一)银行成熟的网络安全防护体系1、缺少金融特色的演练场景设计2、资产测绘手段与防护体系不适配3、效果评价体系缺少演练过程维度相关指标 二、实战对抗体系建设的创新实践(一)建立…...

SwiftUI之深入解析Alignment Guides的超实用实战教程
一、Alignment Guide 简介 Alignment guides 是一个强大的布局工具,但通常未被充分利用。在很多情况下,它们可以帮助我们避免更复杂的选项,比如锚点偏好。如下所示,对对齐的更改也可以自动(并且容易地)动画…...

java获取视频文件的编解码器
java获取视频文件的编解码器 引入jar包: <dependency><groupId>org.bytedeco</groupId><artifactId>javacv-platform</artifactId><version>1.5.9</version></dependency>测试类 package com.jd.brand.approve.…...
)
动态规划Day06(完全背包)
完全背包 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。 完全背包和01背包问题唯一不同…...
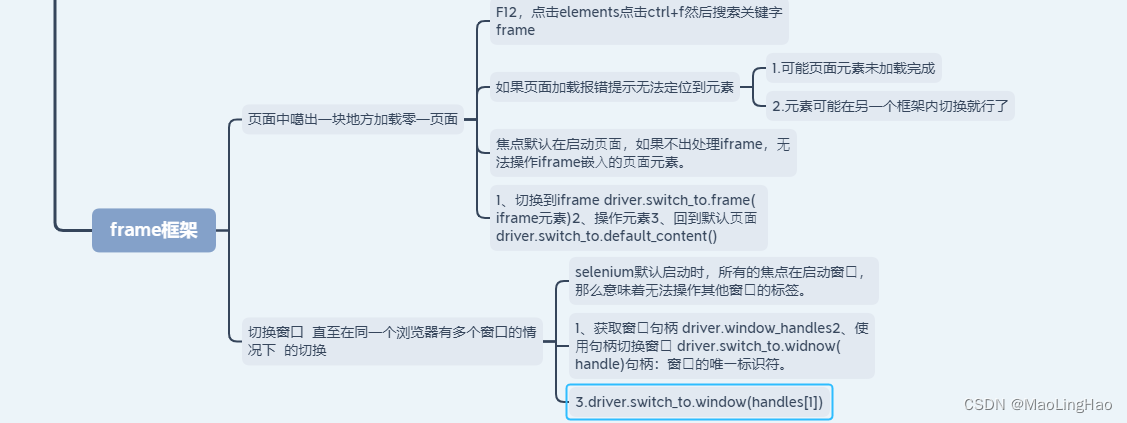
selenium之框架之窗口
...
)
华为OD机试 - 最小矩阵宽度(Java JS Python C)
题目描述 给定一个矩阵,包含 N * M 个整数,和一个包含 K 个整数的数组。 现在要求在这个矩阵中找一个宽度最小的子矩阵,要求子矩阵包含数组中所有的整数。 输入描述 第一行输入两个正整数 N,M,表示矩阵大小。 接下来 N 行 M 列表示矩阵内容。 下一行包含一个正整数 K…...

嵌入式linux_C应用学习之API函数
1.文件IO 1.1 open打开文件 #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> int open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode);pathname:字符串类型,用于标…...
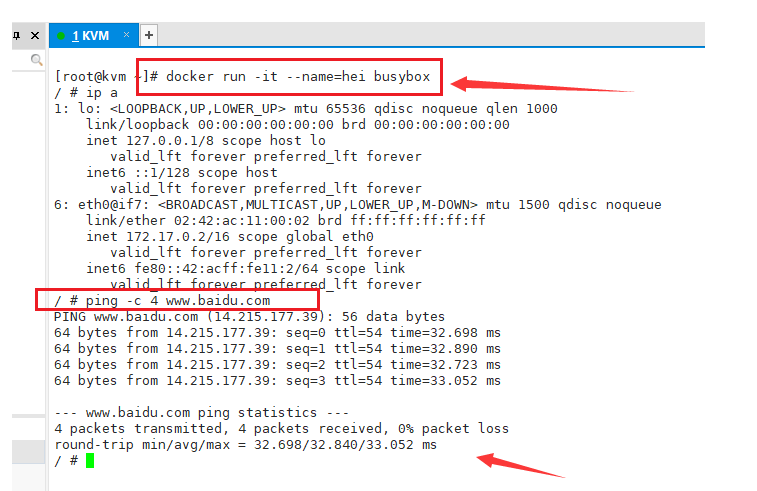
【ubuntu】docker中如何ping其他ip或外网
docker中如何ping其他ip或外网 示例图: 运行下面命令: docker run -it --namehei busybox看情况需要加权限 sudo,即: sudo docker run -it --namehei busyboxping 外网 ping -c 4 www.baidu.comping 内网 ping -c 4 192.168.…...
AITranslate:本地化AI翻译工作流框架,构建可编程翻译管道
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫AITranslate。这名字一看就知道,它想用AI来干翻译的活儿。但说实话,现在市面上翻译工具多如牛毛,从老牌的谷歌翻译、DeepL,到各种大厂出的AI翻译插件,…...

IGH-1.6.2-创龙RK3506-RT-----8-----my_master.c讲解【应用层PDO读写】
本文解决三个应用层问题: 第一,如何从 TxPDO 里读取 3 个 KEY。 第二,如何向 RxPDO 写入 5 个 LED。 第三,如何新增一个 UINT8 数据 PDO。 当前工程里的过程数据指针是 domain_pd,它是应用层读写 PDO 的基础。LED 和 KEY 的字节偏移、bit 位置,都是前面注册 PDO entry …...

AI技能开发脚手架:从零构建大模型应用的标准化起点
1. 项目概述:一个为AI技能开发量身定制的脚手架如果你正在或打算开发一个基于大语言模型的AI技能(Skill),无论是想集成到ChatGPT的GPTs里,还是想构建一个独立的AI Agent,那么你大概率会遇到一个共同的起点问…...

API淘宝关键词搜索:运用场所、使用方式及获客逻辑
在电商生态中,淘宝关键词搜索API是连接第三方系统与平台商品数据的核心桥梁。其核心价值在于通过标准化接口,精准、合规地获取关键词对应的商品、店铺及市场数据,为各类业务提供坚实的数据支撑。相较于传统爬虫,API调用具备合规性…...

从数据中心视角聊token
“我爱你”被AI拆解成了3个tokens,“I love U”也同样被AI拆解成了3个tokens,AI将人类的语言拆解到可被数据分析的最小单位,叫做token,中文是词元,AI通过数据模型的分析,又将无数的token组成了答复反馈给用…...

线性调频等离子鞘套目标雷达探测平台【附代码】
✨ 长期致力于等离子鞘套、脉内多普勒频率、干扰目标抑制、FPGA研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)等离子鞘套回波建模与脉内多普勒参数提…...

别再只用BigGantt了!这个免费JIRA甘特图插件Gantt Suite,配置简单速度快
轻量高效的JIRA甘特图解决方案:Gantt Suite全面评测与迁移指南 在项目管理领域,甘特图作为可视化排期的黄金标准已有百年历史。然而当这一经典工具遇上现代敏捷开发平台JIRA时,许多团队却陷入了两难境地——要么忍受BigGantt等老牌插件的臃肿…...

复杂技术决策如何避免“竞选广告”陷阱?工程师必备的4项流程变革
1. 从一场“选举广告”引发的思考:工程师如何审视复杂系统设计午餐时看新闻,每个广告时段都被政治竞选广告塞满,内容无一例外都在攻击对手,却对自身主张闭口不谈。这场景让我这个在电子设计自动化(EDA)和半…...

离散流匹配与MaskFlow框架:视频生成技术解析
1. 离散流匹配在视频生成中的技术演进 视频生成技术近年来取得了显著进展,但长视频生成仍然面临两大核心挑战:一是如何有效建模视频中复杂的时空动态关系,二是如何在有限的计算资源下实现高效生成。传统方法通常采用固定长度的训练序列&…...
到Stream API:Java二维数组初始化的几种高效写法与性能对比)
从Arrays.fill()到Stream API:Java二维数组初始化的几种高效写法与性能对比
从Arrays.fill()到Stream API:Java二维数组初始化的几种高效写法与性能对比 在算法竞赛和数据处理应用中,二维数组的初始化往往是性能优化的第一个瓶颈。我曾在一个图像处理项目中,因为选择了不当的初始化方式,导致整体性能下降了…...