亿万级海量数据去重软方法
文章目录
- 原理
- 案例一
- 需求:
- 方法
- 案例二
- 需求:
- 方法:
- 参考
原理
在大数据分布式计算框架生态下,提升计算效率的方法是尽可能的把计算分布式话、并行化,避免单节点计算过载,把计算分摊到各个节点。这样解释小白能够听懂:比如你有5个桶,怎样轻松地把A池子的水倒入B池子里?
- 最大并行化,5个桶同时利用,避免count distinct只用一个桶的方法
- 重复利用化,一次提不动那么多水,不要打肿脸充胖子,一不小心oom,为什么不分几次呢
- 数据均衡化,5个桶的水不要一个多一个少的,第一个提水的次数变多,第二个某些桶扛不住,俗称数据倾斜
案例一
需求:
计算day_num维度下的uv,自己脑补出海量数据,这里为方便说明,只列举了day_num,一个维度用桶来描绘计算模型,假设数据都是按字典顺序分桶
> select * from event;
+----------------+------------+
| event.day_num | event.uid |
+----------------+------------+
| day1 | a |
| day1 | a |
| day1 | a |
| day1 | a |
| day1 | bb |
| day1 | bb |
| day1 | bbb |
| day1 | ccc |
| day1 | ccc |
| day1 | dddd |
| day1 | eeee |
| day1 | eeeee |
| day1 | eeeee |
| day1 | eeeee |
+----------------+------------+
方法
- 原始方法:count(distinct)
select count(distinct(uid))as uv from event group by day_num;

可以看到所有数据装到一个桶里面,桶已经快装不下了,明显最差
- 优化一
select size(collect_set(uid)) as uv
from (select day_num,uid from event group by day_num,uid) tmp
group by day_num;

充分利用了桶,最大的实现了并行化,执行虽然分为了两部,但是大大减轻了第一步的负担,面向海量数据的场景去重方面拥有绝对的优势,假如第二步的结果集还是太大了呢?一样会oom扛不住
- 优化二(推荐👍)
简单说就是转化计算,在一个jvm里面,硬去重的方法都逃不开把所有字符或字符的映射放一个对象里面,通过一定的逻辑获取去重集合,对于分布式海量数据的场景下,这种硬去重的计算仍然会花大量的时间在上图的最后单点去重的步骤,我们可以把去重的逻辑按照一定的规则分桶计算完成,每个桶之间分的数据都不重复,所有桶计算完桶内数据去重的集合大小,最后一步再相加。
创建临时表,其中length(uid) as len_uid是映射字段,uid的长度create table event_tmp as select *,length(uid) as len_uid from event;
select sum(uv_tmp) as uv
from(select day_num,size(collect_set(uid)) as uv_tmp from event_tmp group by len_uid,day_num) tmp group by day_num
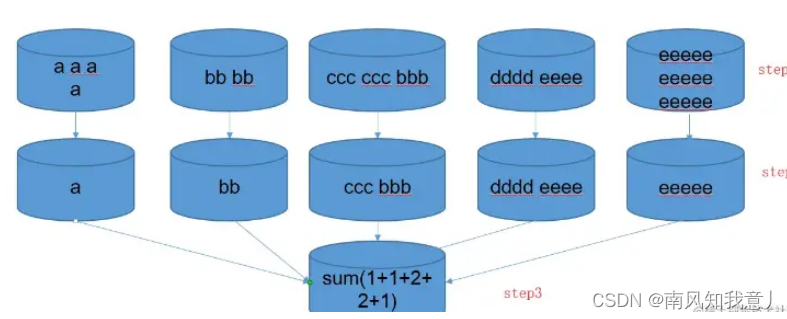
这里使用uid长度映射字段,实际开发中,你也可以选择首字母、末字母或者其它能想到的属性作为映射字段,分桶分步预聚合的方法,巧妙的把一个集合去重问题最终转化为相加问题,避开了单个jvm去重承受的压力,在海量数据的场景下,这个方法最为使用,推荐用在生产上。
案例二
需求:
商品 product 每日总销售记录量级亿 级别起,去重 product 量大概 万 级别。每个商品有一个 state 标识其状态,该状态共3个值,分别为 “0”, “1”,“2”。
统计:
(1) 三个 state 下 product 的总量 pv
(2) 对应 state 下 product 去重后的量 uv
第二个统计每个 state 下有亿级别的 value ,去重时有严重的数据倾斜且数据去重规模很大,亿级别去重至万亿级别
方法:
- GroupBy + RandomIndex + ToSet
val re = sc.textFile(input).map(line => {val info = line.split("\t")val state = info(0)val productId = info(1)// 全局计数countMap(state).add(1L)// 构建 state + randomIndex + product 的 PairRDD(state + "_" + random.nextInt(100) , productId)}).groupBy(_._1).map(info => {val state = info._1.split("_")(0)// 分治val productSet = info._2.map(kv => {val productId = kv._2productId}).toArray.toSet(state, productSet)}).groupBy(_._1).map(info => {val state = info._1val tmpSet = mutable.HashSet[String]()// 合并info._2.foreach(kv => {tmpSet ++= kv._2})state + ":" + tmpSet.size}).collect()
因为 state 只有 0,1,2 三种可能,所以最后全部压力分摊在 3 个节点上,构造 PairRDD 时可以给 state 加上随机索引,从而将任务分散,获得多个小的 Set 再合并成大 Set 。相当于分治,该方法会将原始数据分为 3 x 100 份,缩减了每个 key 要处理的 productId 的量,最后再去除随机索引再 groupBy 一次,汇总得到结果,执行时间 5 min,优化效果显著。
- Distinct + GroupBy (推荐👍 )
上一步方案通过 randomIndex 将数据量分治,减少的百分比和 random 的数值成正比,但是在数据量很大的情况下,分治的每个 key 对应的 value 量还是很大,所以简单的去重执行 5min +,这次将 groupBy 改为 distinct,先去重得到 万 级别数据量,再 GroupBy,此时的数据量本机也可轻松完成
def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getSimpleName)val sc: SparkContext = SparkContext.getOrCreate(conf)val rdd1: RDD[String] = sc.parallelize(List("1,spark","0,flink","1,kafka","1,spark","0,hadoop",), 4)val myAccumulator = new MyAccumulatorsc.register(myAccumulator, "myAcc")val rdd2 = rdd1.map(str => {val info: Array[String] = str.split(",")val state: String = info(0)val productId: String = info(1)//累加器 求pvmyAccumulator.add(state)state + "_" + productId}).distinct().map(info => {val str: Array[String] = info.split("_")val state: String = str(0)val productId: String = str(1)(state, productId)}).groupBy(_._1) //(1,CompactBuffer((1,kafka), (1,spark))).map(f => {val state: String = f._1val num: Int = f._2.map(_._2).toSet.size(state, num)})rdd2.foreach(println(_))//输出累加器值(注意在action后)val sentMap: mutable.HashMap[String, Long] = myAccumulator.valueprintln(sentMap.toString())}
}//自定义累加器
class MyAccumulator extends AccumulatorV2[String, mutable.HashMap[String, Long]] {private val hashMap = new mutable.HashMap[String, Long]()override def isZero: Boolean = hashMap.isEmptyoverride def copy(): AccumulatorV2[String, mutable.HashMap[String, Long]] = new MyAccumulatoroverride def reset(): Unit = hashMap.clear()override def add(v: String): Unit = {val l: Long = hashMap.getOrElse(v, 0L)hashMap.update(v, l + 1)}override def merge(other: AccumulatorV2[String, mutable.HashMap[String, Long]]): Unit = {val hashMap1: mutable.HashMap[String, Long] = this.hashMapval hashMap2: mutable.HashMap[String, Long] = other.valuehashMap2.foreach {case (k, v) => {val l: Long = hashMap1.getOrElse(k, 0L)hashMap1.update(k, l + v)}}}override def value: mutable.HashMap[String, Long] = this.hashMap
}
输出:(1,2)(0,2)Map(1 -> 3, 0 -> 2)
- distinct源码
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {def removeDuplicatesInPartition(partition: Iterator[T]) .......partitioner match {case Some(_) if numPartitions == partitions.length =>mapPartitions(removeDuplicatesInPartition, preservesPartitioning = true)case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)}}
partitioner源码是这样声明的:val partitioner: Option[Partitioner] = None
case Some(_) //这句是匹配partitioner不为None
所以最终执行的代码是:
case _ => map(x => (x, null)).reduceByKey((x, ) => x, numPartitions).map(._1)
case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
主要是用到了 reduceByKey ,这个算子会在MapSide进行预聚合的操作。将聚合后的结果传递到reduce端。
参考
https://www.jianshu.com/p/1cdc943bb649
https://blog.csdn.net/BIT_666/article/details/121672715
reduceByKey详见
累加器详见
相关文章:
亿万级海量数据去重软方法
文章目录原理案例一需求:方法案例二需求:方法:参考原理 在大数据分布式计算框架生态下,提升计算效率的方法是尽可能的把计算分布式话、并行化,避免单节点计算过载,把计算分摊到各个节点。这样解释小白能够…...

记录--手摸手带你撸一个拖拽效果
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 最近看见一个拖拽效果的视频(抖音:艾恩小灰灰),看好多人评论说跟着敲也没效果,还有就是作者也不回复大家提出的一些疑问,本着知其然必要知其所以然…...
python高德地图+58租房网站平台源码
wx供重浩:创享日记 对话框发送:python地图 免费获取完整源码源文件说明文档配置教程等 在PyCharm中运行《高德地图58租房》即可进入如图1所示的高德地图网页。 具体的操作步骤如下: (1)打开地图网页后,在编…...
ubuntu 将jupyter-lab保存为桌面快捷方式和favourites
ubuntu: 将jupyter-lab保存为桌面快捷方式和favourites desktop shortcut 建立一个新的desktop文件 cd ~/Desktop touch Jupyter-lab.desktop将文件修改成如下: [Desktop Entry] Version1.0 NameJupyterlab CommentBack up your data with one click Exec/home/cjb/…...
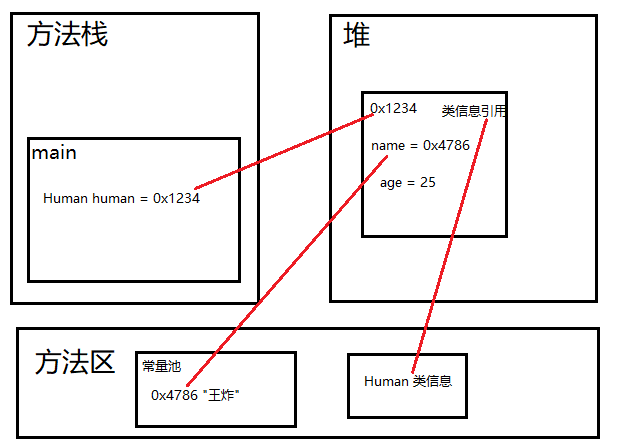
Java 类和对象简介
类是对象的抽象,是一组具有相同特性(属性,事物的状态信息)和行为(事物能做什么)的事物的集合,可以看做一类事物的模板。 对象是类的实例化,是具体的事物。 比如:人类和…...

时间复杂度的计算
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【数据结构初阶(C实现)】 文章目录123456789时间复杂度(就是一个函数)的计算,…...
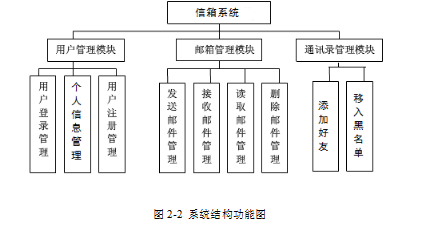
站内信箱系统的设计与实现
技术:Java、JSP等摘要:在经济全球化和信息技术成为发展迅速的今时今日,人们通过电子邮件收发进行信息传递已经成为主流。随着互联网和网络办公的发展,电子邮件正在被广泛应用在人们的日常生活中。跟据调查研究统计,在全…...

systemV共享内存
systemV共享内存 共享内存区是最快的IPC形式。共享内存的大小一般是4KB的整数倍,因为系统分配共享内存是以4KB为单位的(Page)!4KB也是划分内存块的基本单位。 之前学的管道,是通过文件系统来实现让不同的进程看到同一…...

Python基础之if逻辑判断
在学习if语句之前,我们先学习一种数据类型,布尔类型(bool),在if语句中,我们需要通过判断条件是否为真或者假,才进入下面的语句块执行。 一、布尔类型(bool) 布尔类型&a…...
实现pdf文件预览
前言 工作上接到的一个任务,实现pdf的在线预览,其实uniapp中已经有对应的api:uni.openDocument(OBJECT)(新开页面打开文档,支持格式:doc, xls, ppt, pdf, docx, xlsx, pptx。)**实现了相关功能…...

【java】alibaba Fastjson --全解史上最快的JSON解析库
文章目录前序Fastjson 简介Fastjson 的优点速度快使用广泛测试完备使用简单功能完备下载和使用将 Java 对象转换为 JSON 格式JSONField创建 JSON 对象JSON 字符串转换为 Java 对象使用 ContextValueFilter 配置 JSON 转换使用 NameFilter 和 SerializeConfigFastjson 处理日期F…...
(十道编程题))
绝对零基础的C语言科班作业(期末模拟考试)(十道编程题)
编程题(共10题; 共100.0分)(给猛男妙妙屋更一篇模拟考试)模拟1(输出m到n的素数)从键盘输入两个整数[m,n], 输出m和n之间的所有素数。 输入样例:3,20输出样例:…...

按位与为零的三元组[掩码+异或的作用]
掩码异或的作用前言一、按位与为零的三元组二、统计分组1、map统计分组2、异或掩码总结参考资料前言 当a b 0时,我们能够很清楚的知道b是个什么值,b 0 - a -a,如果当a & b 0时,我们能够很清楚的知道b是什么值吗…...

C++基础篇(一)-- 简单入门
C 语言是在优化 C 语言的基础上为支持面向对象的程序设计而研制的一个通用目的的程序设计语言。在后来的持续研究中,C 增加了许多新概念,例如虚函数、重载、继承、标准模板库、异常处理、命名空间等。 C 语言的特点主要表现在两个方面:全面兼…...
前端整理 —— javascript 2
1. generator(生成器) 详细介绍 generator 介绍 generator 是 ES6 提供的一种异步编程解决方案,在语法上,可以把它理解为一个状态机,内部封装了多种状态。执行generator,会生成返回一个遍历器对象。返回的…...
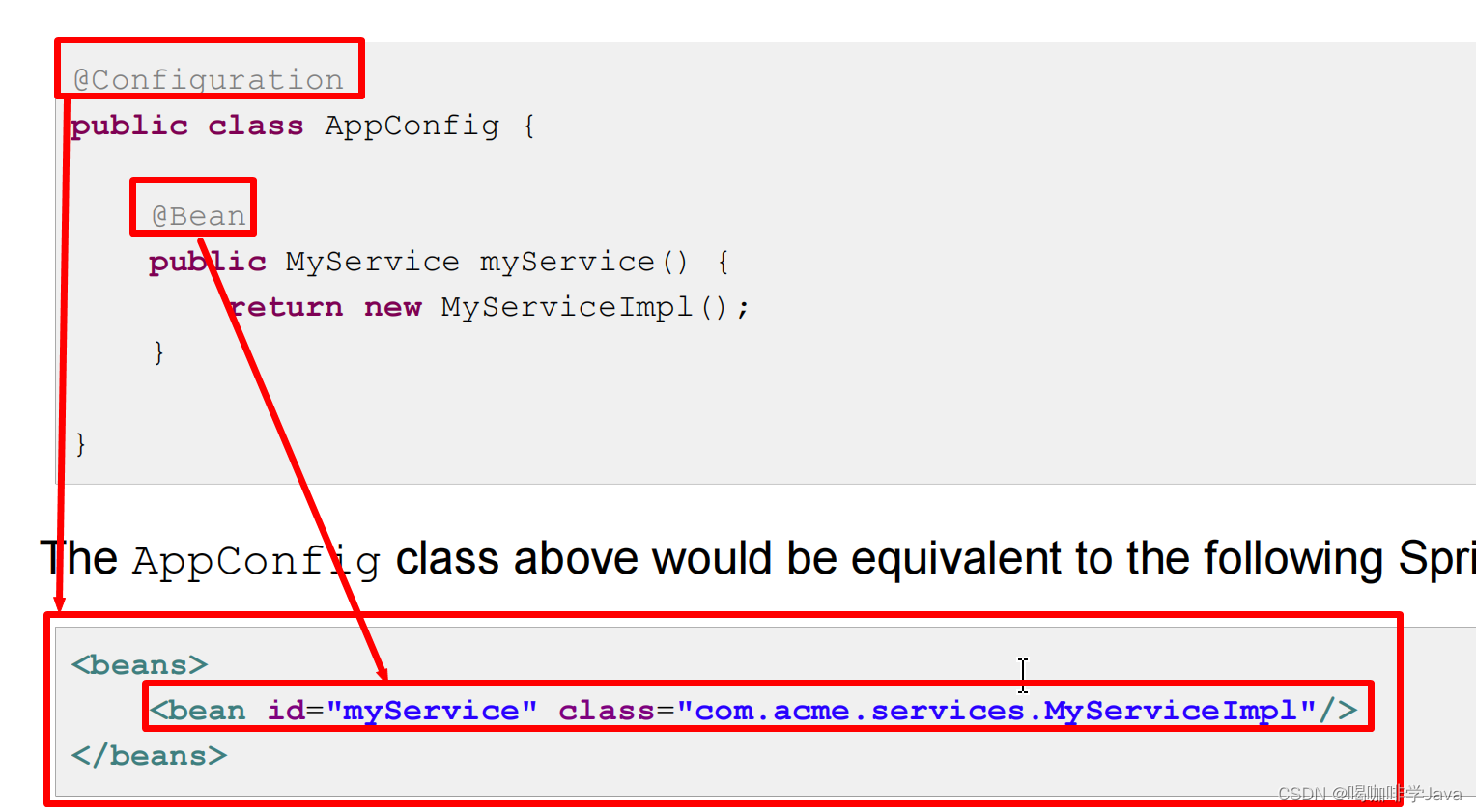
Spring-注解注入
一、回顾XML注解 bean 配置 创建 bean public class Student { } 配置 xml bean <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema/beans"xmlns:xsi"http://www.w3.org/2001/XMLSche…...
)
华为校招机试 - 攻城战(Java JS Python)
目录 题目描述 输入描述 输出描述 用例 题目解析 JavaScript算法源码 Java算法源码...

Docker入门
Docker一、何为DockerDocker是一个开源的应用容器引擎,基于GO语言并遵循从Apache2.0协议开源。Docker可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后在发布到任何流行的Linux机器上,也可以实现虚拟化。容器是完全使…...

时间序列分析 | CNN-LSTM卷积长短期记忆神经网络时间序列预测(Matlab完整程序)
时间序列分析 | CNN-LSTM卷积长短期记忆神经网络时间序列预测(Matlab完整程序) 目录 时间序列分析 | CNN-LSTM卷积长短期记忆神经网络时间序列预测(Matlab完整程序)预测结果模型输出基本介绍完整程序参考资料预测结果 模型输出 layers = 具有以下层的 151 Layer 数组:...
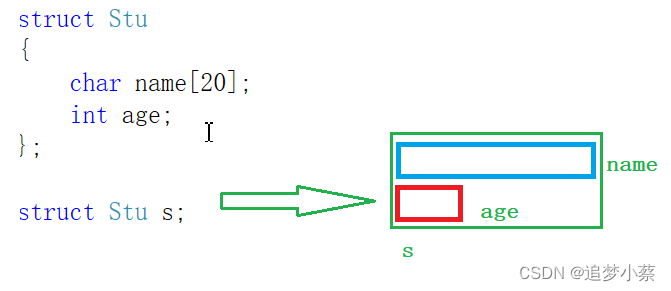
【蒸滴C】C语言结构体入门?看这一篇就够了
目录 一、结构体的定义 二、结构的声明 例子 三、 结构成员的类型 结构体变量的定义和初始化 1.声明类型的同时定义变量p1 2.直接定义结构体变量p2 3.初始化:定义变量的同时赋初值。 4.结构体变量的定义放在结构体的声明之后 5.结构体嵌套初始化 6.结构体…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...

当B站字幕不再只是弹幕:你的个人学习宝库解锁指南
当B站字幕不再只是弹幕:你的个人学习宝库解锁指南 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还记得那个深夜吗?你正在B站追着某个技术…...

免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南
免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...