深度学习笔记(七)——基于Iris/MNIST数据集构建基础的分类网络算法实战
文中程序以Tensorflow-2.6.0为例
部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。
截图和程序部分引用自北京大学机器学习公开课
认识网络的构建结构
在神经网络的构建过程中,都避不开以下几个步骤:
- 导入网络和依赖模块
- 原始数据处理和清洗
- 加载训练和测试数据
- 构建网络结构,确定网络优化方法
- 将数据送入网络进行训练,同时判断预测效果
- 保存模型
- 部署算法,使用新的数据进行预测推理
使用Keras快速构建网络的必要API
在tensorflow2版本中将很多基础函数进行了二次封装,进一步急速了算法初期的构建实现。通过keras提供的很多高级API可以在较短的代码体量上实现网络功能。同时通过搭配tf中的基础功能函数可以实现各种不同类型的卷积和组合操作。正是这中高级API和底层元素及的操作大幅度的提升了tensorflow的自由程度和易用性。
常用网络
全连接层
tf.keras.layers.Dense(units=3, activation=tf.keras.activations.softmax, kernel_regularizer=tf.keras.regularizers.L2())
units:维数(神经元个数)
activation:激活函数,可选:relu softmax sigmoid tanh,这里记不住的话可以用tf.keras.activations.逐个查看
kernel_regularizer:正则化函数,同样的可以使用tf.keras.regularizers.逐个查看
全连接层是标准的神经元组成,更多被用在网络的后端或解码端(Decoder)用来输出预测数据。
拉伸层(维度展平)
tf.keras.layers.Flatten()
这个函数默认不需要输入参数,直接使用,它会将多维的数据按照每一行依次排开首尾连接变成一个一维的张量。通常在数据输入到全连接层之前使用。
卷积层
tf.keras.layers.Conv2D(filters=3, kernel_size=3, strides=1, padding='valid')
filters:卷积核个数
kernel_size:卷积核尺寸
strides:卷积核步长,卷积核是在原始数据上滑动遍历完成数据计算。
padding:可填 ‘valid’ ‘same’,是否使用全零填充,影响最后卷积结果的大小。
卷积一般被用来提取数据的数据特征。卷积最关键的就是卷积核个数和卷积核尺寸。假设输入一个1nn大小的张量,经过x个卷积核+步长为2+尺寸可以整除n的卷积层之后会输出一个x*(n/2)*(n/2)大小的张量。可以理解为卷积步长和卷积核大小影响输出张量的长宽,卷积核的大小影响输出张量的深度。
构建网络
使用Sequential构建简单网络,或者构建网络模块。列表中顺序包含网络的各个层。
tf.keras.models.Sequential([ ])
使用独立的class构建,这里定义一个类继承自 tensorflow.keras.Model 后面基本是标准结构>初始化相关参数>定义网络层>重写call函数定义前向传播层的连接顺序。后续随着使用的深入可以进一步的添加更多函数来实现不同类型的网络。
class mynnModel(Model): # 继承from tensorflow.keras import Model 作为父类def __init__(self):super(IrisModel, self).__init__() # 初始化父类的参数self.d1 = layers.Dense(units=3, activation=tf.keras.activations.softmax, kernel_regularizer=tf.keras.regularizers.L2())def call(self, input): # 重写前向传播函数y = self.d1(input)return ymodel = IrisModel()
训练及其参数设置
设置训练参数
tensorflow.keras.Model.compile(optimizer=参数更新优化器,loss=损失函数metrics=准确率计算方式,即输出数据类型和标签数据类型如何对应)
具体参数可以看下面的内容:
optimizer:参数优化器 SGD: tf.keras.optimizers.SGD(learning_rate=0.1,momentum=动量参数) learning_rate学习率,momentum动量参数AdaGrad: tf.keras.optimizers.Adagrad(learning_rate=学习率)Adam: tf.keras.optimizers.Adam(learning_rate=学习率 , beta_1=0.9, beta_2=0.999)
loss:损失函数MSE: tf.keras.losses.MeanSquaredError()交叉熵损失: tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False) from_logits=true时输出值经过一次softmax概率归一化
metrics:准确率计算方式,就是输出数据类型和标签数据类型如何对应数值型(两个都是序列值): 'accuracy'都是独热码: 'categorical_accuracy'标签是数值,输出是独热码: 'sparse_categorical_accuracy'
训练
tensorflow.keras.Model.model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
网络传入参数含义如下:
输入的数据依次为:输入训练特征数据,标签数据,单次输入数据量,迭代次数
validation_split=从训练集划分多少比例数据用来测试 / validation_data=(测试特征数据,测试标签数据) 这两个参数智能二选一
validation_freq=多少次epoch测试一次
输出网络信息
tensorflow.keras.Model.model.summary()
上面这个函数可以在训练结束或者训练开始之前输出一次网络的结构信息用于确认。
实际应用展示
环境
软件环境的配置可以查看环境配置流程说明
cuda = 11.8 # CUDA也可以使用11.2版本
python=3.7
numpy==1.19.5
matplotlib== 3.5.3
notebook==6.4.12
scikit-learn==1.2.0
tensorflow==2.6.0
keras==2.6.0
使用iris数据集构建基础的分类网络
import tensorflow as tf
from sklearn import datasets
import numpy as npx_train = datasets.load_iris().data
y_train = datasets.load_iris().targetnp.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)model = tf.keras.models.Sequential([ tf.keras.layers.Dense(3, activation='softmax',kernel_regularizer=tf.keras.regularizers.l2())])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1),loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary( )
通过上面这样几行简单的代码,我们实现了对iris数据的分类训练。在上面的代码中使用了Sequential函数来构建网络。
使用MNIST数据集设计分类网络
在开始下面的代码之前,要先下载对应的数据 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 复制这段网址在浏览器打开会直接下载数据,然后将下载好的mnist.npz复制到一个新的路径下,然后在tf.keras.datasets.mnist.load_data(path=‘you file path ’)代码中的这行里修改为你的路径,注意要使用绝对路径。
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras import layers
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data(path='E:\Tensorflow\data\mnist.npz') # 注意替换自己的使用绝对路径
x_train, x_test = x_train/255.0, x_test/255.0 # 图像数据归一化
print('训练集样本的大小:', x_train.shape)
print('训练集标签的大小:', y_train.shape)
print('测试集样本的大小:', x_test.shape)
print('测试集标签的大小:', y_test.shape)
#可视化样本,下面是输出了训练集中前20个样本
fig, ax = plt.subplots(nrows=4,ncols=5,sharex='all',sharey='all')
ax = ax.flatten()
for i in range(20):img = x_train[i].reshape(28, 28)ax[i].imshow(img,cmap='Greys')
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
# 定义网络结构
class mnisModel(Model):def __init__(self, *args, **kwargs):super(mnisModel, self).__init__(*args, **kwargs)self.flatten1=layers.Flatten()self.d1=layers.Dense(128, activation=tf.keras.activations.relu)self.d2=layers.Dense(10, activation=tf.keras.activations.softmax)def call(self, input):x = self.flatten1(input)x = self.d1(x)x = self.d2(x)return(x)
model = mnisModel()
#设置训练参数
model.compile(optimizer='adam', # 'adam' tf.keras.optimizers.Adam(learning_rate=0.4 , beta_1=0.9, beta_2=0.999)loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])
# 训练
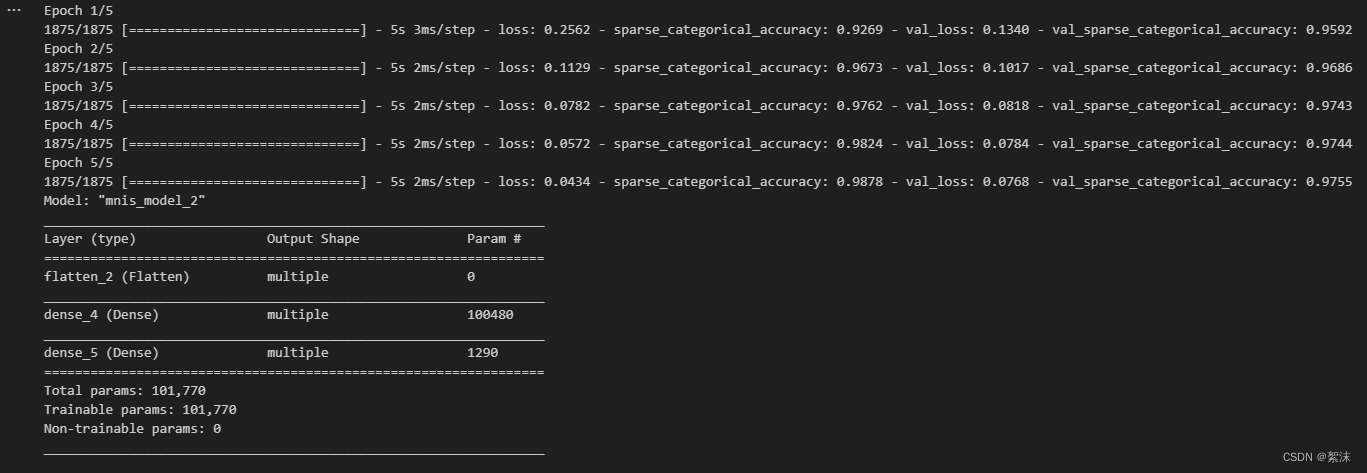
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data = (x_test, y_test), validation_freq=1)
model.summary()
运行后会先显示数据集中的前二十个数字

关闭数字展示窗口后开始训练,并看到训练的过程
相关文章:
深度学习笔记(七)——基于Iris/MNIST数据集构建基础的分类网络算法实战
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 认识网络的构建结构 在神经网络的构建过程中,都避不开以下几个步骤: 导入网络和依…...

Windows启动MongoDB服务报错(错误 1053:服务没有及时响应启动或控制请求)
问题描述:修改MongoDB服务bin目录下的mongod.cfg,然后在任务管理器找到MongoDB服务-->右键-->点击【开始】,启动失败无提示: 右键点击任务管理器的MongoDB服务-->点击【打开服务】,跳转到服务页面-->找到M…...
定制CPUSET解决方案-system修改及编译部分调整)
Android Framework 常见解决方案(25-2)定制CPUSET解决方案-system修改及编译部分调整
1 原理说明 这个方案有如下基本需求: 构建自定义CPUSET,/dev/cpuset中包含一个全新的cpuset分组。且可以通过set_cpuset_policy和set_sched_policy接口可以设置自定义CPUSET。开机启动后可以通过zygote判定来对特定的应用进程设置CPUSET,并…...
OpenAI推出GPT商店和ChatGPT Team服务
🦉 AI新闻 🚀 OpenAI推出GPT商店和ChatGPT Team服务 摘要:OpenAI正式推出了其GPT商店和ChatGPT Team服务。用户已经创建了超过300万个ChatGPT自定义版本,并分享给其他人使用。GPT商店集结了用户为各种任务创建的定制化ChatGPT&a…...
3D建模素材分层渲染怎么操作?
在3D建模素材分层渲染过程中,需要将场景中的元素分到不同的层里,然后分别进行渲染。以下是一个简单的方法: 1、打开要渲染的3D建模素材。 2、在场景中选择要分层的元素,然后在软件的图层面板中新建图层,将元素拖拽到新…...
的实现)
SAICP(模拟退火迭代最近点)的实现
SAICP(模拟退火迭代最近点)的实现 注: 本系列所有文章在github开源, 也是我个人的学习笔记, 欢迎大家去star以及fork, 感谢! 仓库地址: pointcloud-processing-visualization 总结一下上周的学习情况 ICP会存在局部最小值的问题, 这个问题可能即使是没有实际遇到过, 也或多…...
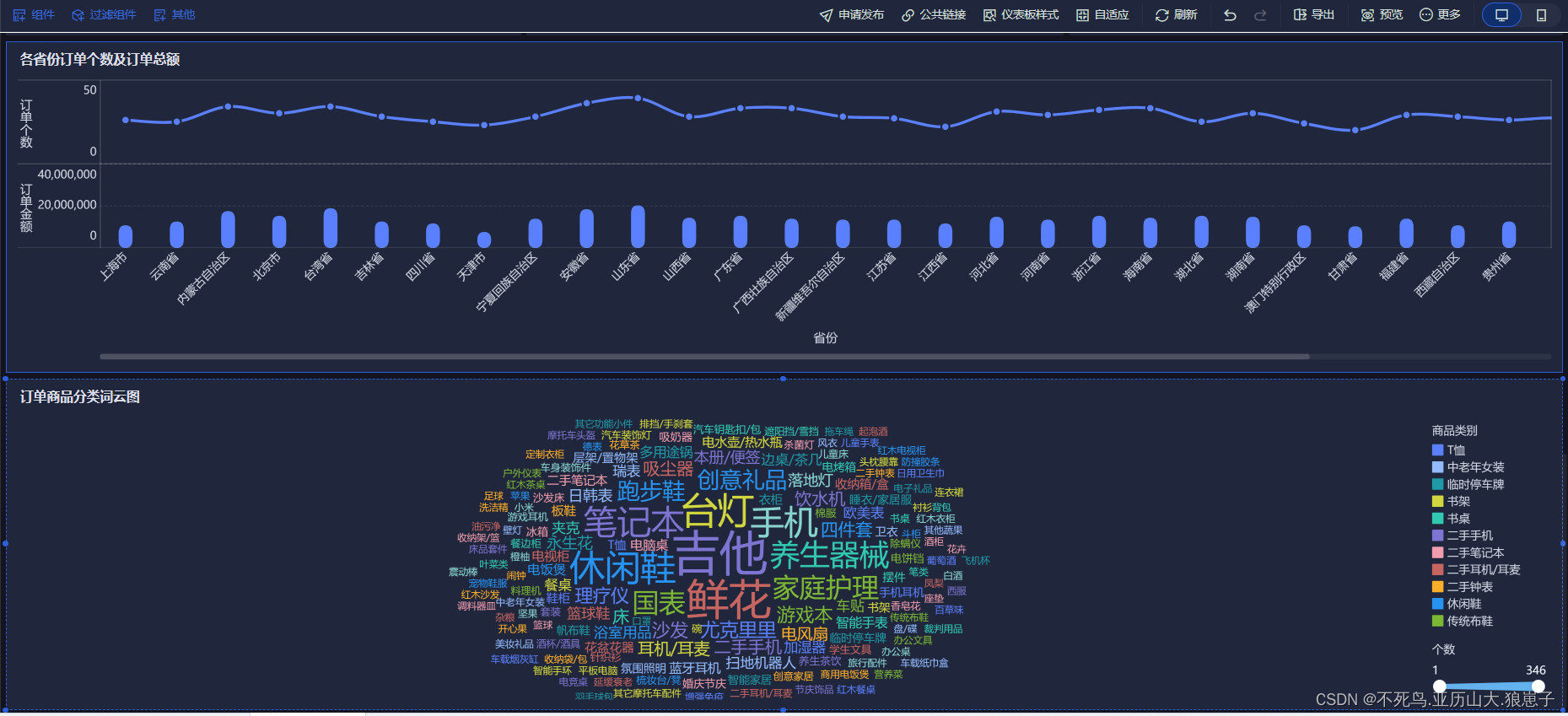
FineBI实战项目一(23):订单商品分类词云图分析开发
点击新建组件,创建订单商品分类词云图组件。 选择词云,拖拽catName到颜色和文本,拖拽cat到大小。 将组件拖拽到仪表板。 结果如下:...

DOS命令
当使用DOS命令时,可以在命令提示符下输入各种命令以执行不同的任务。以下是一些常见DOS命令的详细说明: dir (Directory): 列出当前目录中的文件和子目录。 用法: dir [drive:][path][filename] [/p] [/w] cd (Change Directory): 更改当前目录。 用法: …...
函数详解和示例)
【Python】torch中的.detach()函数详解和示例
在PyTorch中,.detach()是一个用于张量的方法,主要用于创建该张量的一个“离断”版本。这个方法在很多情况下都非常有用,例如在缓存释放、模型评估和简化计算图等场景中。 .detach()方法用于从计算图中分离一个张量,这意味着它创建…...
二级域名分发系统源码 对接易支付php源码 全开源
全面开源的易支付PHP源码分享:实现二级域名分发对接 首先,在epay的config.php文件中修改您的支付域名。 随后,在二级域名分发网站上做相应修改。 伪静态 location / { try_files $uri $uri/ /index.php?$query_string; } 源码下载&#…...
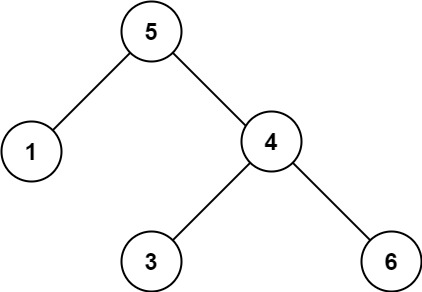
二分查找与搜索树的高频问题(算法村第九关白银挑战)
基于二分查找的拓展问题 山峰数组的封顶索引 852. 山脉数组的峰顶索引 - 力扣(LeetCode) 给你由整数组成的山脉数组 arr ,返回满足 arr[0] < arr[1] < ... arr[i - 1] < arr[i] > arr[i 1] > ... > arr[arr.length - 1…...

Python爬虫快速入门
Python 爬虫Sutdy 1.基本类库 request(请求) 引入 from urllib import request定义url路径 url"http://www.baidu.com"进行请求,返回一个响应对象response responserequest.urlopen(url)读取响应体read()以字节形式打印网页源码 response.read()转码 编码 文本–by…...
部署MinIO
一、安装部署MINIO 1.1 下载 wget https://dl.min.io/server/minio/release/linux-arm64/minio chmod x minio mv minio /usr/local/bin/ # 控制台启动可参考如下命令, 守护进程启动请看下一个代码块 # ./minio server /data /data --console-address ":9001"1.2 配…...
RK3566环境搭建
环境:vmware16,ubuntu 18.04 安装依赖库: sudo apt-get install repo git ssh make gcc libssl-dev liblz4-tool expect g patchelf chrpath gawk texinfo chrpath diffstat binfmt-support qemu-user-static live-build bison flex fakero…...
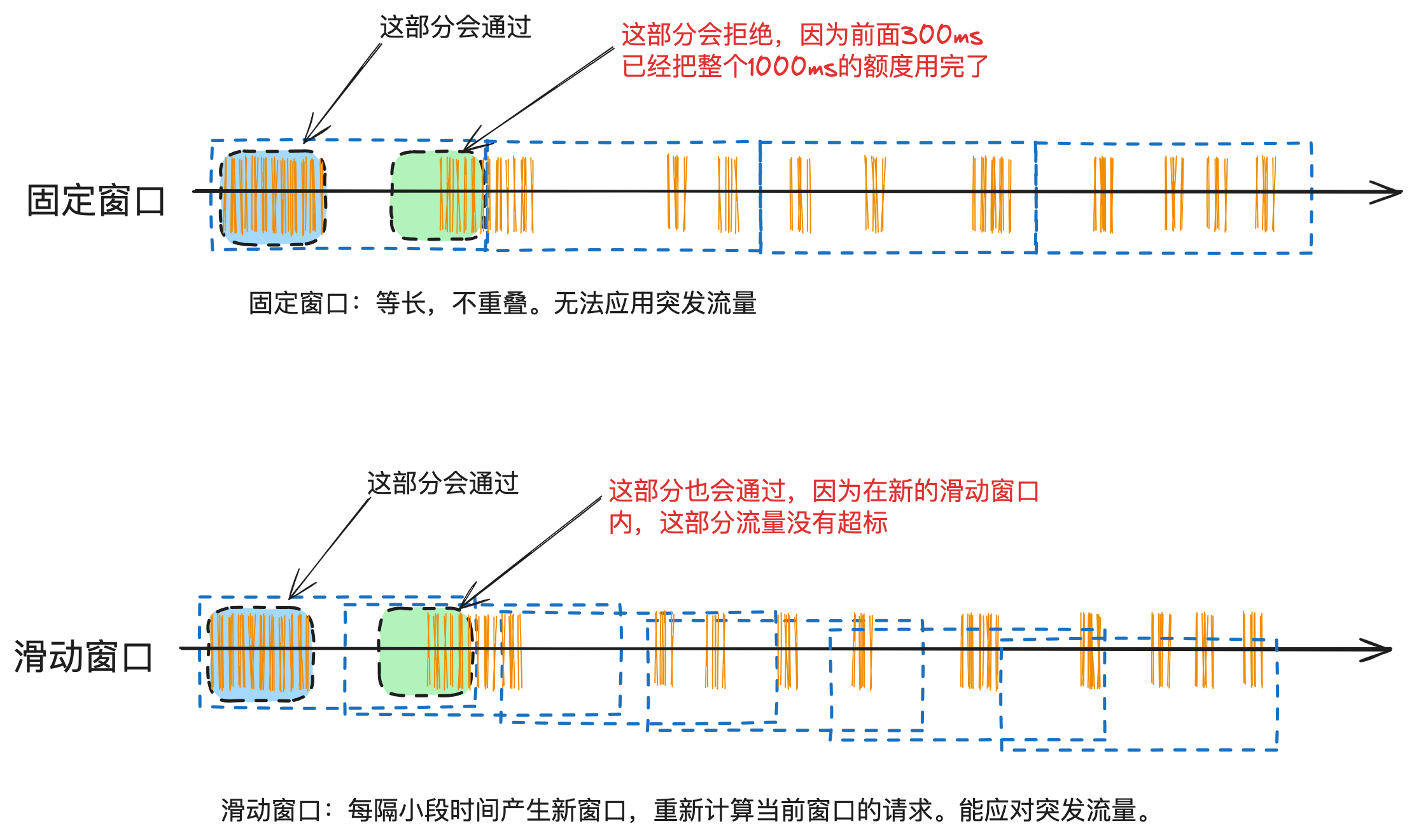
精确掌控并发:滑动时间窗口算法在分布式环境下并发流量控制的设计与实现
这是《百图解码支付系统设计与实现》专栏系列文章中的第(15)篇,也是流量控制系列的第(2)篇。点击上方关注,深入了解支付系统的方方面面。 上一篇介绍了固定时间窗口算法在支付渠道限流的应用以及使用redis…...

Python展示 RGB立方体的二维切面视图
代码实现 import numpy as np import matplotlib.pyplot as plt# 生成 24-bit 全彩 RGB 立方体 def generate_rgb_cube():# 初始化一个 256x256x256 的三维数组rgb_cube np.zeros((256, 256, 256, 3), dtypenp.uint8)# 填充立方体for r in range(256):for g in range(256):fo…...

03 顺序表
目录 线性表顺序表练习 线性表(Linear list)是n个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串。。。 线性表在逻辑上时线性结构,是连续的一条直线。但在物理结…...

2023年全球软件开发大会(QCon北京站2023)9月:核心内容与学习收获(附大会核心PPT下载)
随着科技的飞速发展,全球软件开发大会(QCon)作为行业领先的技术盛会,为世界各地的专业人士提供了交流与学习的平台。本次大会汇集了全球的软件开发者、架构师、项目经理等,共同探讨软件开发的最新趋势、技术与实践。本…...

ChatGPT 和 文心一言 的优缺点及需求和使用场景
ChatGPT和文心一言是两种不同的自然语言生成模型,它们有各自的优点和缺点。 ChatGPT(Generative Pre-trained Transformer)是由OpenAI开发的生成式AI模型,它在庞大的文本数据集上进行了预训练,并可以根据输入生成具有上…...
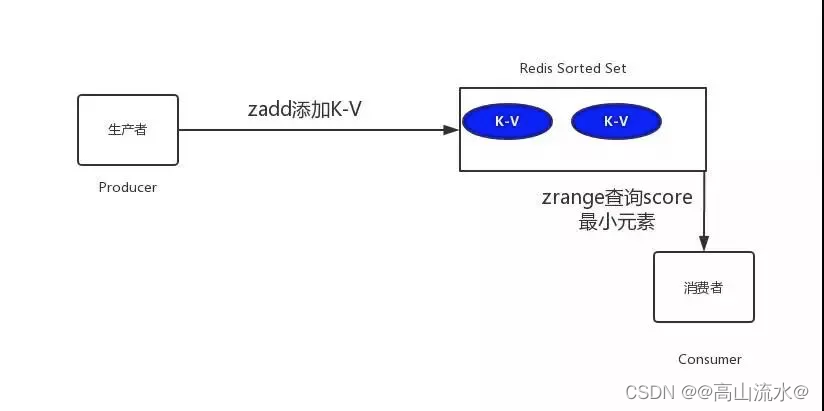
架构师之超时未支付的订单进行取消操作的几种解决方案
今天给大家上一盘硬菜,并且是支付中非常重要的一个技术解决方案,有这块业务的同学注意自己尝试一把哈! 一、需求如下: 生成订单30分钟未支付,自动取消 生成订单60秒后,给用户发短信 对上述的需求,我们给…...

跨VM RowHammer攻击防御技术与DRAM安全研究
1. 跨VM RowHammer攻击与防御技术概述在云计算环境中,虚拟机(VM)之间的安全隔离是保障多租户数据安全的核心机制。然而,RowHammer攻击的出现对这一基础安全假设提出了严峻挑战。RowHammer是一种利用DRAM物理特性的硬件漏洞攻击方式,攻击者通过…...

安全稀疏矩阵乘法:基于二叉树递归传播的MPC算法优化详解
1. 项目概述:当稀疏矩阵乘法遇上安全多方计算 在分布式机器学习、联合数据分析以及隐私保护推荐系统的构建中,我们常常面临一个核心矛盾:数据的所有权分散在多个互不信任的参与方手中,大家希望共同训练一个模型或进行一次计算&…...

FPGA与机器学习协同加速量子点自动调谐:原理、实现与性能分析
1. 项目概述:当FPGA遇上机器学习,量子点调谐的“自动驾驶”时代在量子计算实验室里,调谐一个量子点器件进入单电子态,是每个实验物理学家都绕不开的“苦差事”。这活儿有多磨人?你得坐在仪器前,手动调节两个…...

文房四宝-徽墨
文房四宝,除了你已经熟悉的墨(以徽墨为代表),还包括笔、纸、砚。这套书写工具共同构成了中国传统文化中文房雅器的核心,每一宝都有其最具代表性的产地与传奇故事。简单来说就是:湖笔、徽墨、宣纸、端砚。&a…...
)
【AI问答/前端】前端满天过海局(一)
Axios感觉就像一堆ajax函数,再高深我就不懂了,Pinia可以当成是各组件之间的变量主动响应?这边改了,那边用到这个变量的也变了?跟vue插件传参不一样吧,感觉,vue还要写插槽传值(好像是这样,太久我忘了)。router这个路由我就蛋疼了,他上面的url是真变了呀,他是客户端…...

2025-2026年全球DHA品牌推荐:五大榜单评测婴幼儿纯净藻油口感无腥味适用场景
摘要 当家长与个体健康管理者纷纷将DHA纳入日常营养补充方案,面对市场上琳琅满目的品牌与产品,却陷入了“如何甄别纯度、规避过敏原、匹配不同年龄段需求”的现实困境:是追求高纯度藻油,还是优先考虑配方安全性?根据Gr…...

老Mac焕新秘籍:3个步骤让你的旧设备运行最新macOS系统
老Mac焕新秘籍:3个步骤让你的旧设备运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否还在为手中的老款Mac无法升级到最新系…...

从岭回归到Lasso:正则化原理、稀疏性与ADMM算法实践
1. 项目概述:从岭回归到Lasso的深度解析在机器学习和统计建模的实践中,我们常常面临一个核心矛盾:模型在训练数据上表现优异,但在未见过的数据上却一塌糊涂,这就是所谓的“过拟合”。想象一下,你为了记住一…...

全域轨迹可回溯,高效破解煤矿灾害搜救难题 ——基于视频孪生无感定位的矿山轨迹溯源搜救技术解析方案
全域轨迹可回溯,高效破解煤矿灾害搜救难题——基于视频孪生无感定位的矿山轨迹溯源搜救技术解析方案一、方案前言煤矿井下瓦斯爆炸、顶板垮塌、透水冲击等灾害发生后,巷道结构损毁、通信供电中断、有害气体弥漫,现场环境瞬息万变。传统人员监…...
)
企业ESG披露合规危机应对指南(2024欧盟CSRD强制落地倒计时)
更多请点击: https://intelliparadigm.com 第一章:CSRD法规核心要义与企业合规临界点 欧盟《企业可持续发展报告指令》(CSRD)已于2024年1月1日正式生效,取代原有的NFRD,显著扩大了适用范围与披露深度。其核…...