PiflowX如何快速开发flink程序
PiflowX如何快速开发flink程序
参考资料
Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码-腾讯云开发者社区-腾讯云 (tencent.com)
Flink SQL 背景
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是我们熟知的 Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。
Flink SQL 是面向用户的 API 层,在我们传统的流式计算领域,比如 Storm、Spark Streaming 都会提供一些 Function 或者 Datastream API,用户通过 Java 或 Scala 写业务逻辑,这种方式虽然灵活,但有一些不足,比如具备一定门槛且调优较难,随着版本的不断更新,API 也出现了很多不兼容的地方。

在这个背景下,毫无疑问,SQL 就成了我们最佳选择,之所以选择将 SQL 作为核心 API,是因为其具有几个非常重要的特点:
- SQL 属于设定式语言,用户只要表达清楚需求即可,不需要了解具体做法;
- SQL 可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划;
- SQL 易于理解,不同行业和领域的人都懂,学习成本较低;
- SQL 非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少;
- 流与批的统一,Flink 底层 Runtime 本身就是一个流与批统一的引擎,而 SQL 可以做到 API 层的流与批统一。
Flink SQL 常规实战应用
案例来自(Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码-腾讯云开发者社区-腾讯云 (tencent.com))!详细流程有兴趣可以参考原文示例。(如有侵犯,请请联系!)。
在此,简单总结一下flink sql的开发流程:
1.首先需要创建maven工程,确认需要的各种依赖,运气好的话,还需要花费大量的精力和时间去排查依赖冲突的问题(oh God bless me!);
2.开始balabala编写模板代码,如:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tableEnv = BatchTableEnvironment.getTableEnvironment(env);
3.数据准备和预处理;
DataSet<String> input = env.readTextFile("score.csv");DataSet<PlayerData> topInput = input.map(new MapFunction<String, PlayerData>() {@Overridepublic PlayerData map(String s) throws Exception {String[] split = s.split(",");return new PlayerData(String.valueOf(split[0]),String.valueOf(split[1]),String.valueOf(split[2]),Integer.valueOf(split[3]),Double.valueOf(split[4]),Double.valueOf(split[5]),Double.valueOf(split[6]),Double.valueOf(split[7]),Double.valueOf(split[8]));}});
其中的PlayerData类为自定义类:
public static class PlayerData {/*** 赛季,球员,出场,首发,时间,助攻,抢断,盖帽,得分*/public String season;public String player;public String play_num;public Integer first_court;public Double time;public Double assists;public Double steals;public Double blocks;public Double scores;public PlayerData() {super();}public PlayerData(String season,String player,String play_num,Integer first_court,Double time,Double assists,Double steals,Double blocks,Double scores) {this.season = season;this.player = player;this.play_num = play_num;this.first_court = first_court;this.time = time;this.assists = assists;this.steals = steals;this.blocks = blocks;this.scores = scores;}}
4.终于到了真正的业务处理了,有了flink sql的强大和方便,倒是省了不少代码;
Table queryResult = tableEnv.sqlQuery("
select player, count(season) as num FROM score GROUP BY player ORDER BY num desc LIMIT 3
");
5.ok,到此,数据处理和计算逻辑完毕,处理结果写入到sink,可以完结散花咯,哈哈;
DataSet<Result> result = tableEnv.toDataSet(queryResult, Result.class);
result.print();
6.哦!好像还需要调试运行,好吧,再辛苦一会,便可大功告成!


7.完美,上线。。。。。。

(以上,纯属娱乐,如有不当,敬请谅解!)
可见,在平日开发一个flink任务虽已尽可能简单,但开发周期也得1-2个工作日,甚至更长,有没有简单粗暴的,让我分分钟领盒饭,不,让我分分钟高效完成任务的!


当然有啦!!!接下来让我隆重的介绍一下今天的主角—PilfowX—大数据流水线系统。有兴趣可以查看之前的文章(StreamPark + PiflowX 打造新一代大数据计算处理平台-CSDN博客)。

PiflowX是基于Piflow和StreamPark二开实现的,在其基础上,实现了图像化拖拉拽的方式开发spark或flink作业,这里我将介绍flink任务的开发流程,以及如何零代码实现flink sql的开发。
PiflowX的flink组件算子基本都是基于flink table和sql实现的,我们只需在UI界面填写组件相关参数,之后的工作交给底层框架即可。
我们回顾一下flink sql语法定义。
Flink SQL 的语法和算子
Flink SQL 核心算子的语义设计参考了 1992、2011 等 ANSI-SQL 标准,Flink 使用 Apache Calcite 解析 SQL ,Calcite 支持标准的 ANSI SQL。
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name({ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n][ <watermark_definition> ][ <table_constraint> ][ , ...n])[COMMENT table_comment][PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]WITH (key1=val1, key2=val2, ...)[ LIKE source_table [( <like_options> )] | AS select_query ]<physical_column_definition>:column_name column_type [ <column_constraint> ] [COMMENT column_comment]<column_constraint>:[CONSTRAINT constraint_name] PRIMARY KEY NOT ENFORCED<table_constraint>:[CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED<metadata_column_definition>:column_name column_type METADATA [ FROM metadata_key ] [ VIRTUAL ]<computed_column_definition>:column_name AS computed_column_expression [COMMENT column_comment]<watermark_definition>:WATERMARK FOR rowtime_column_name AS watermark_strategy_expression<source_table>:[catalog_name.][db_name.]table_name<like_options>:
{{ INCLUDING | EXCLUDING } { ALL | CONSTRAINTS | PARTITIONS }| { INCLUDING | EXCLUDING | OVERWRITING } { GENERATED | OPTIONS | WATERMARKS }
}[, ...]
PiflowX组件flink table实现
在了解了flink sql的定义后,一切便简单多了,那么,我们只需要根据业务需要,设计出一个表单输入,填写我们的业务参数,然后,由框架自动生成sql不就可以了么。
以下介绍如何配置一个mysqlcdc组件:
1.首先从组件列表中拖入一个MysqlCdc组件到画布中,点击节点,右侧会显示出节点参数表单区域和参数说明和示例。参数解释可以查看之前的文章(PiflowX-MysqlCdc组件-CSDN博客)。


2.填写相关参数,其实就是在定义flink table中的with属性。
在属性输入框中,点击预览可以实时查看生成的flink sql。
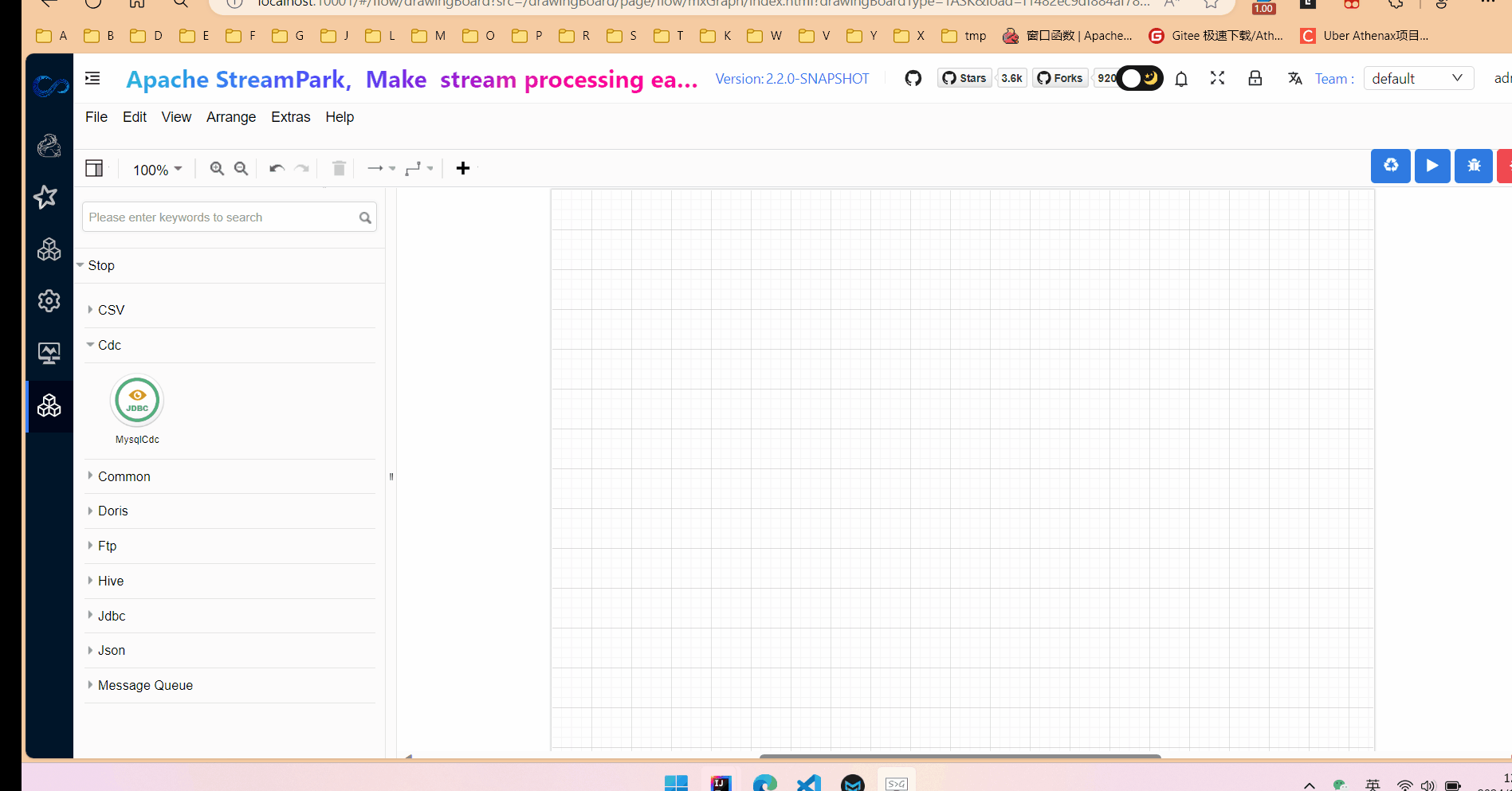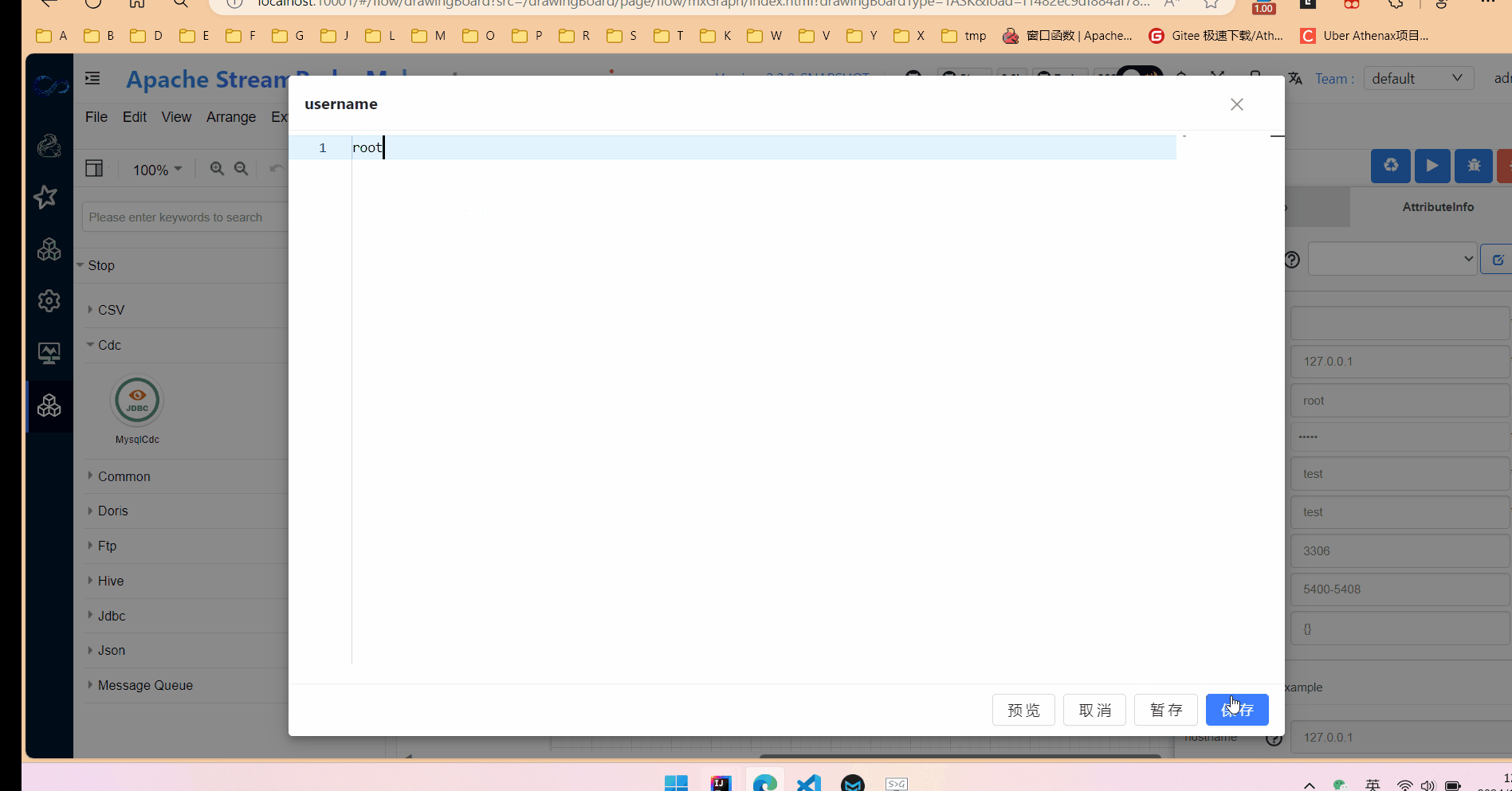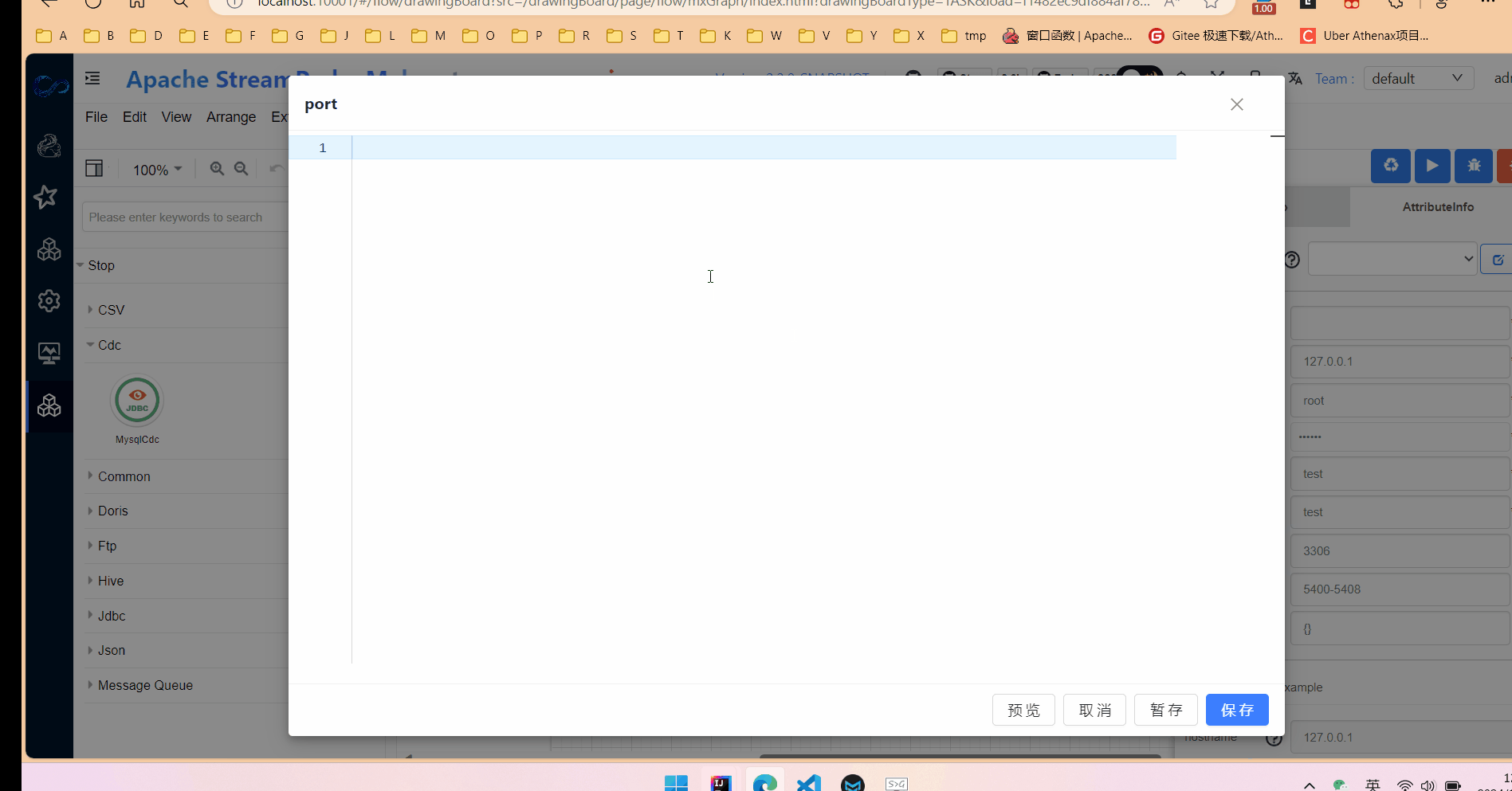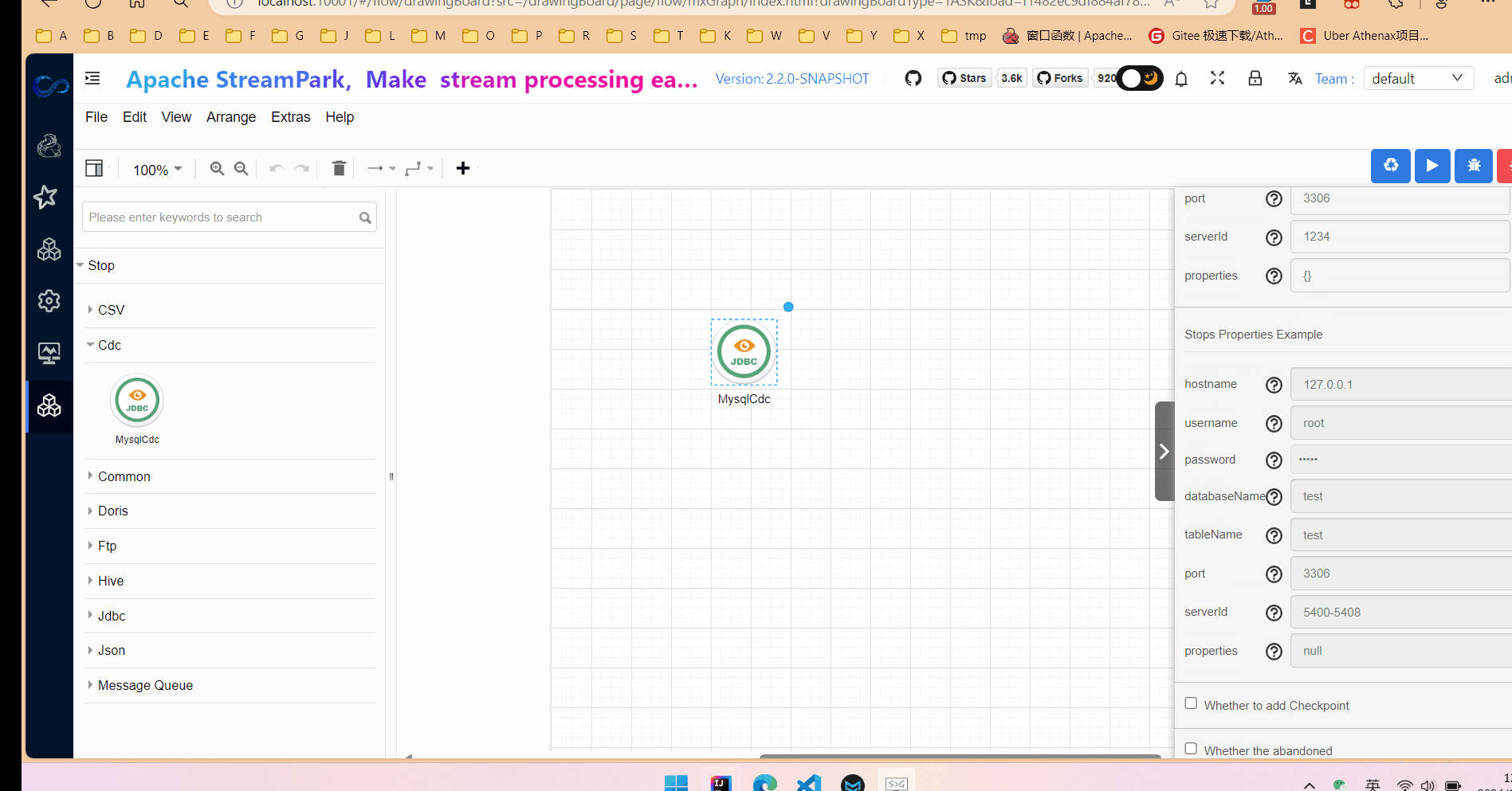

生成的flink sql 语句仅供参考,最终执行的语句会在引擎执行侧生成。
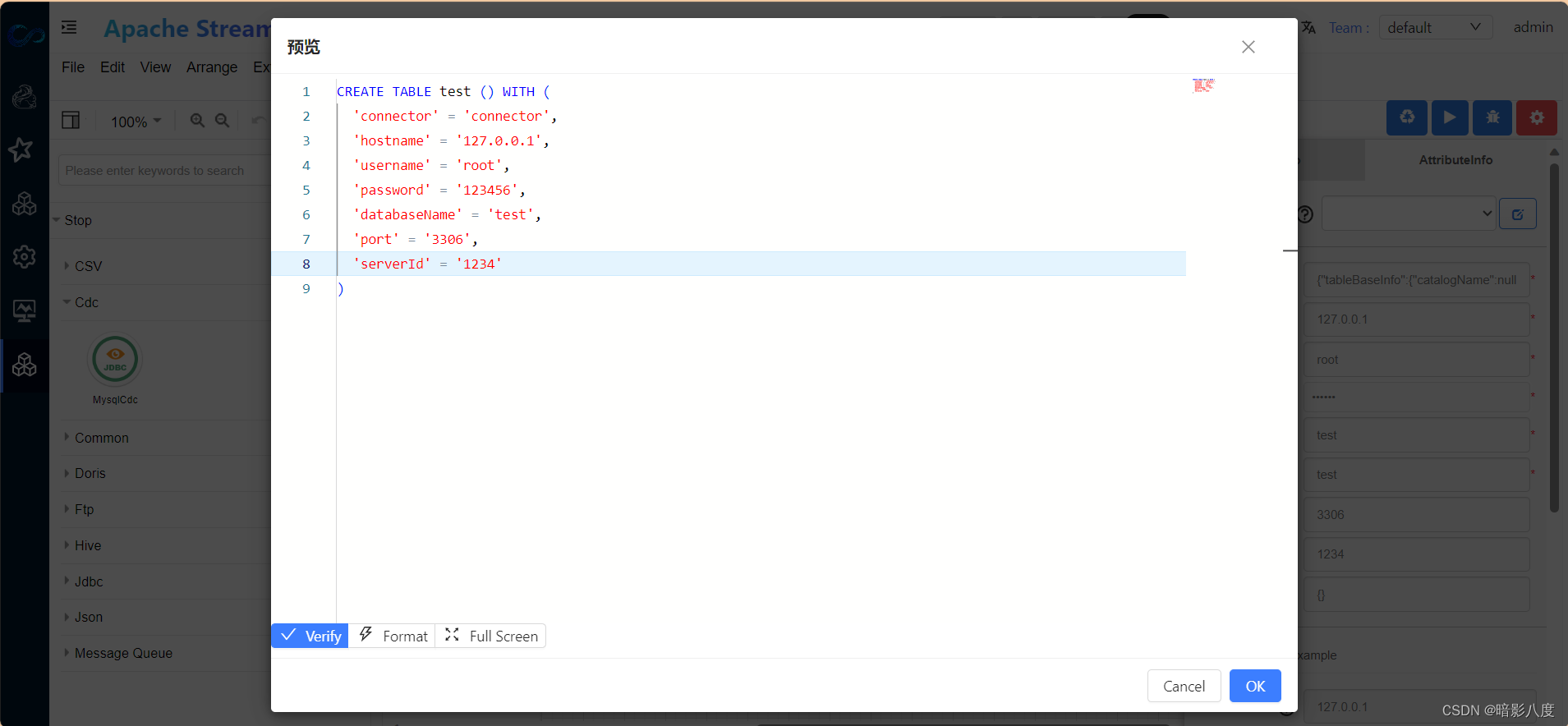
3.接下来我们可以根据需要来定义flink table结构,此步骤和其他步骤没有先后顺序。点击表单属性tableDefinition,在此表单中我们可以输入flink table中的结构属性定义。
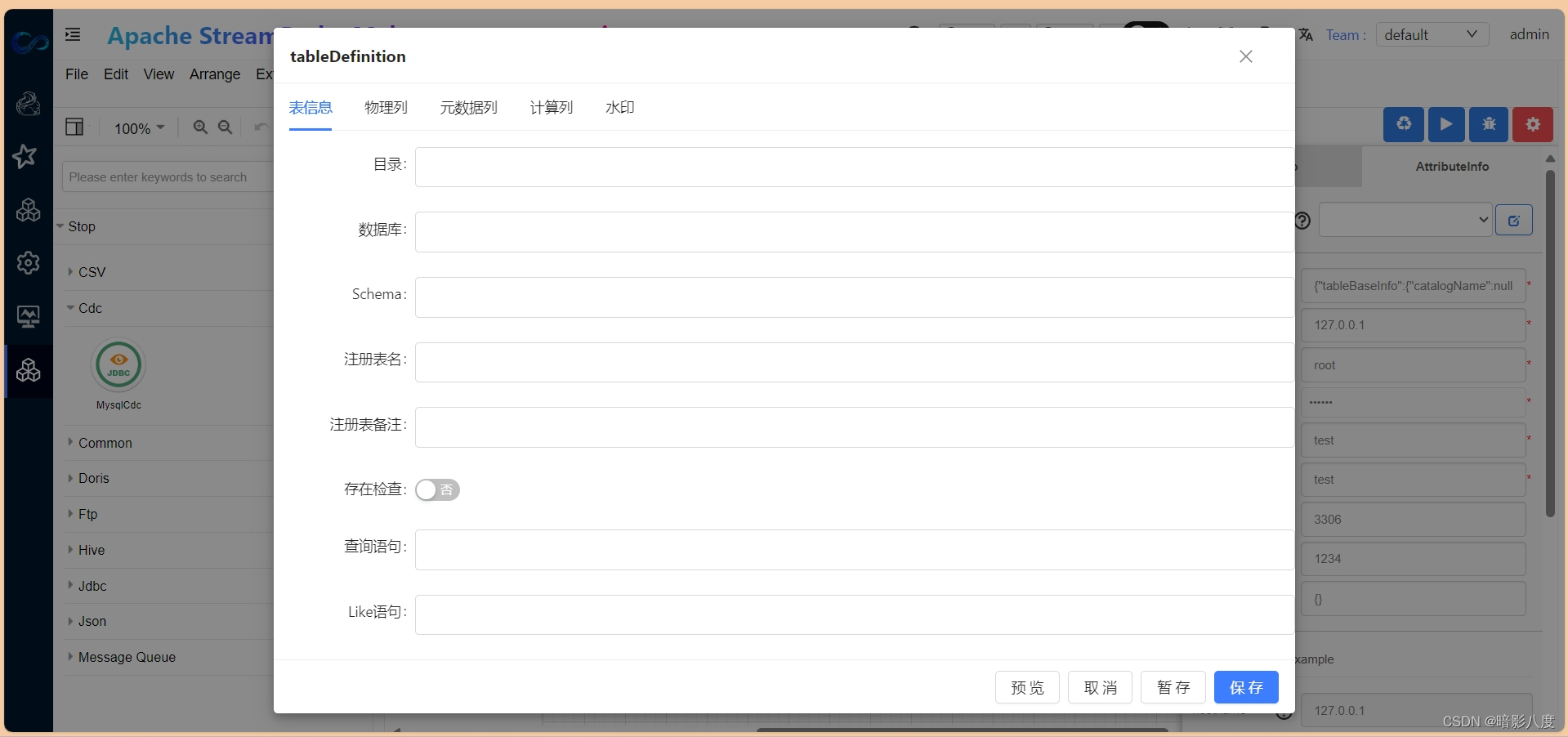
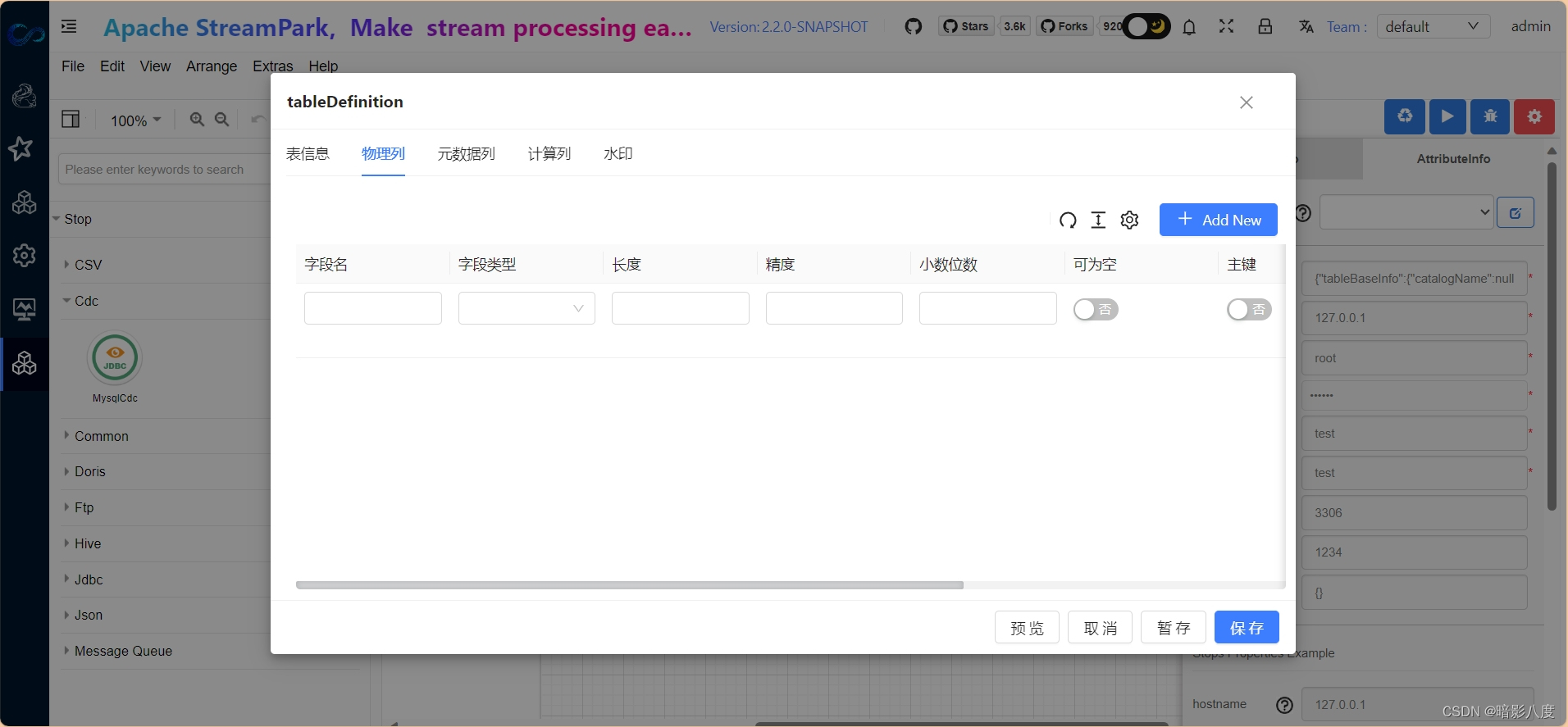
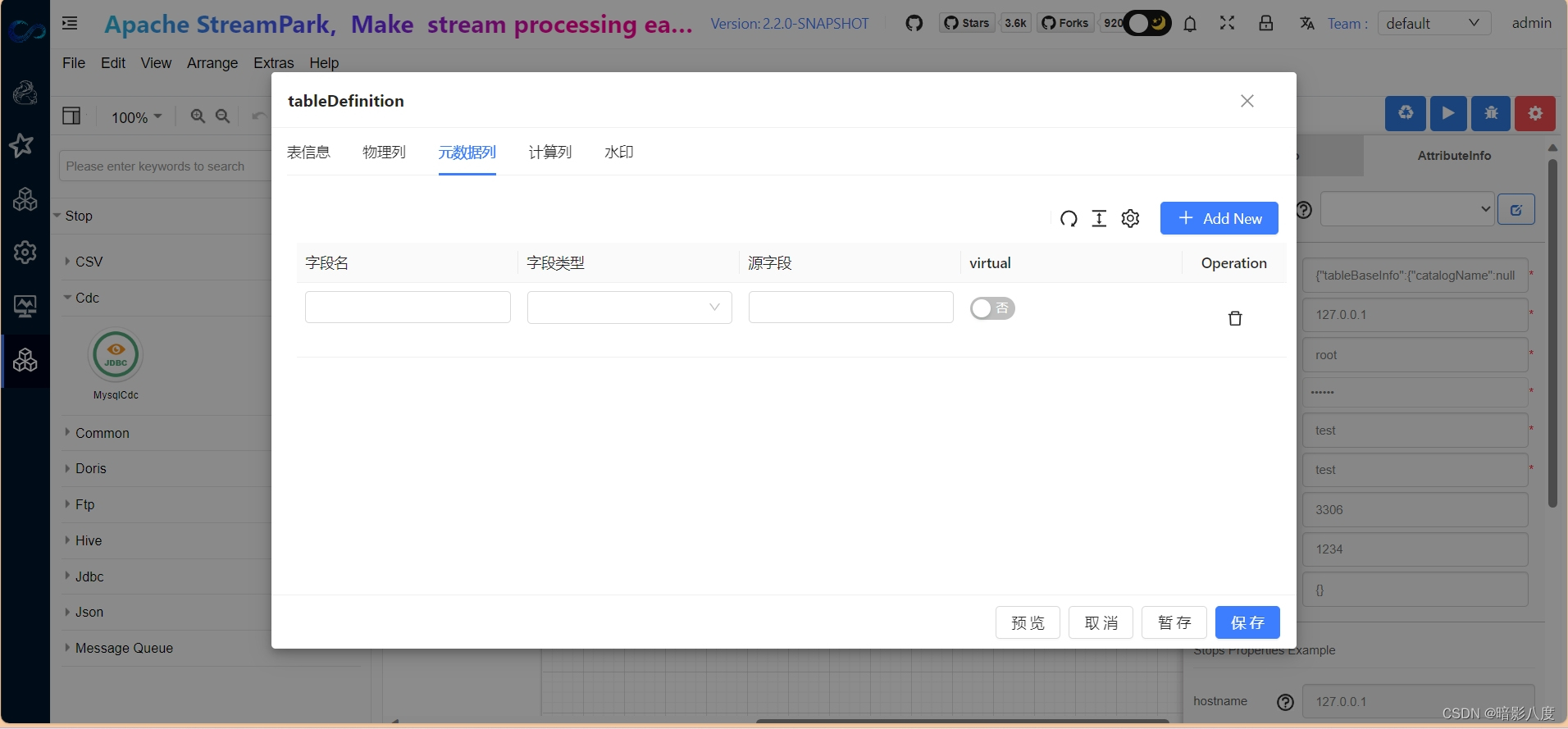
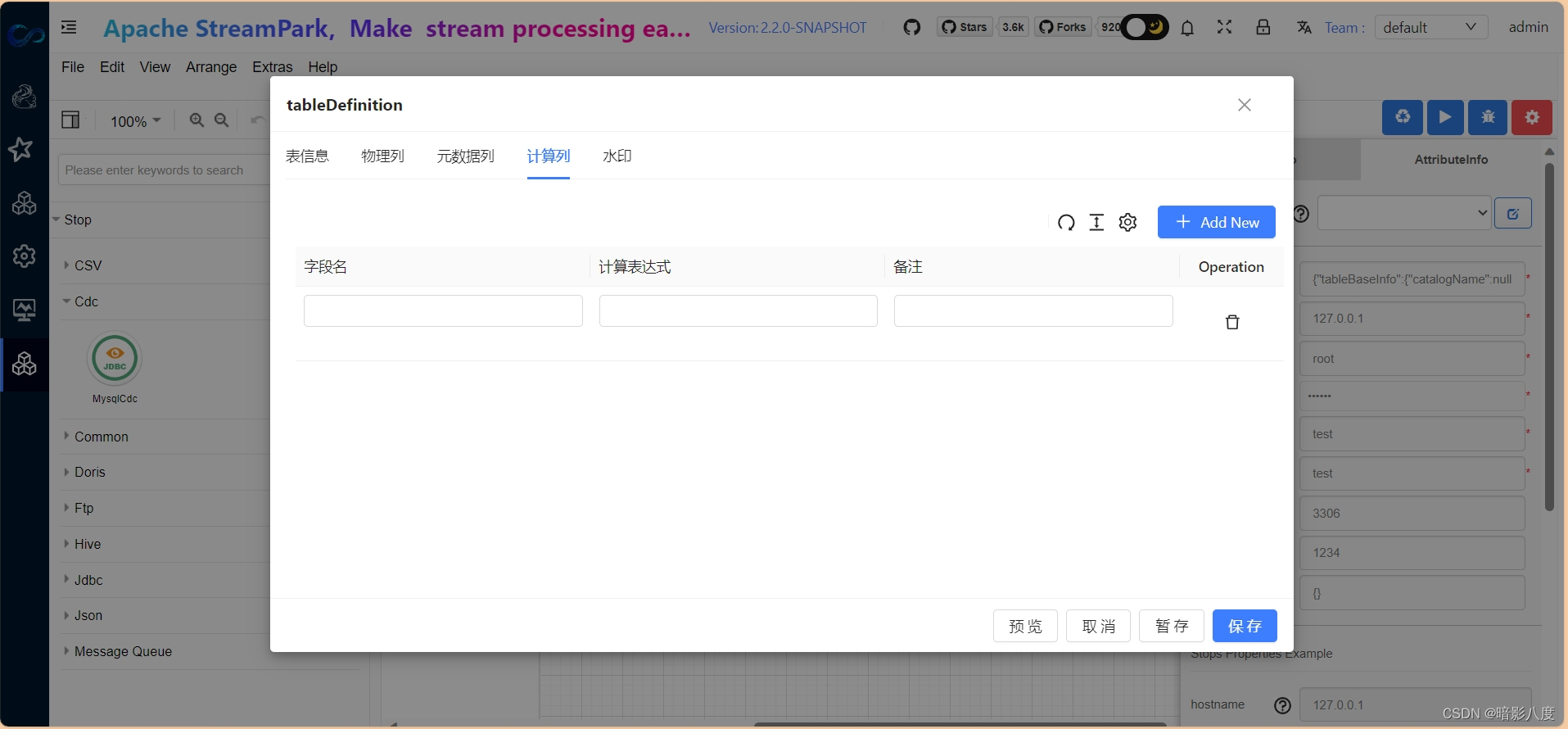
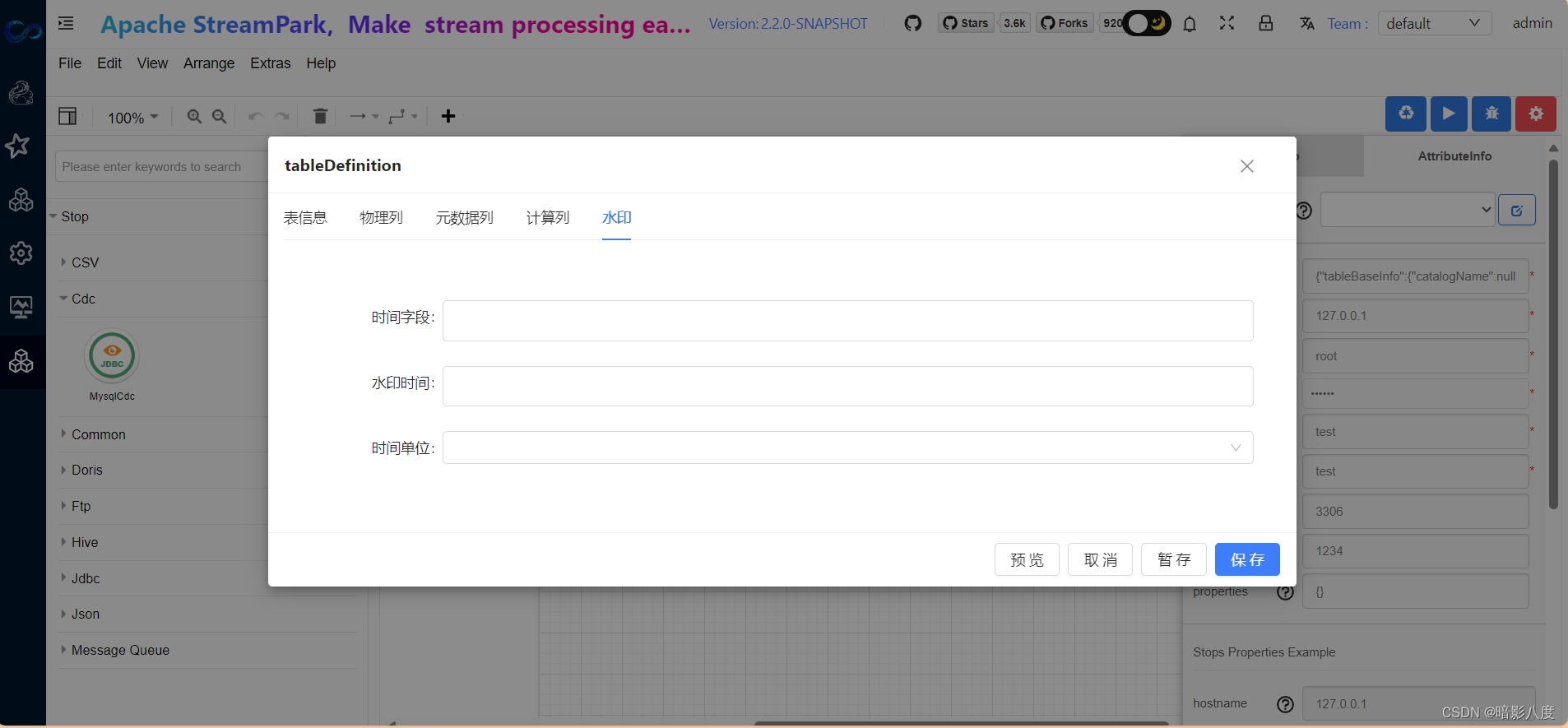
可以看到,我们可以在此定义flink table中的表基本信息,物理列,元数据列,计算列,水印等,具体说明在此就不赘述了,以后会有具体文章来说明。看看最终的效果:
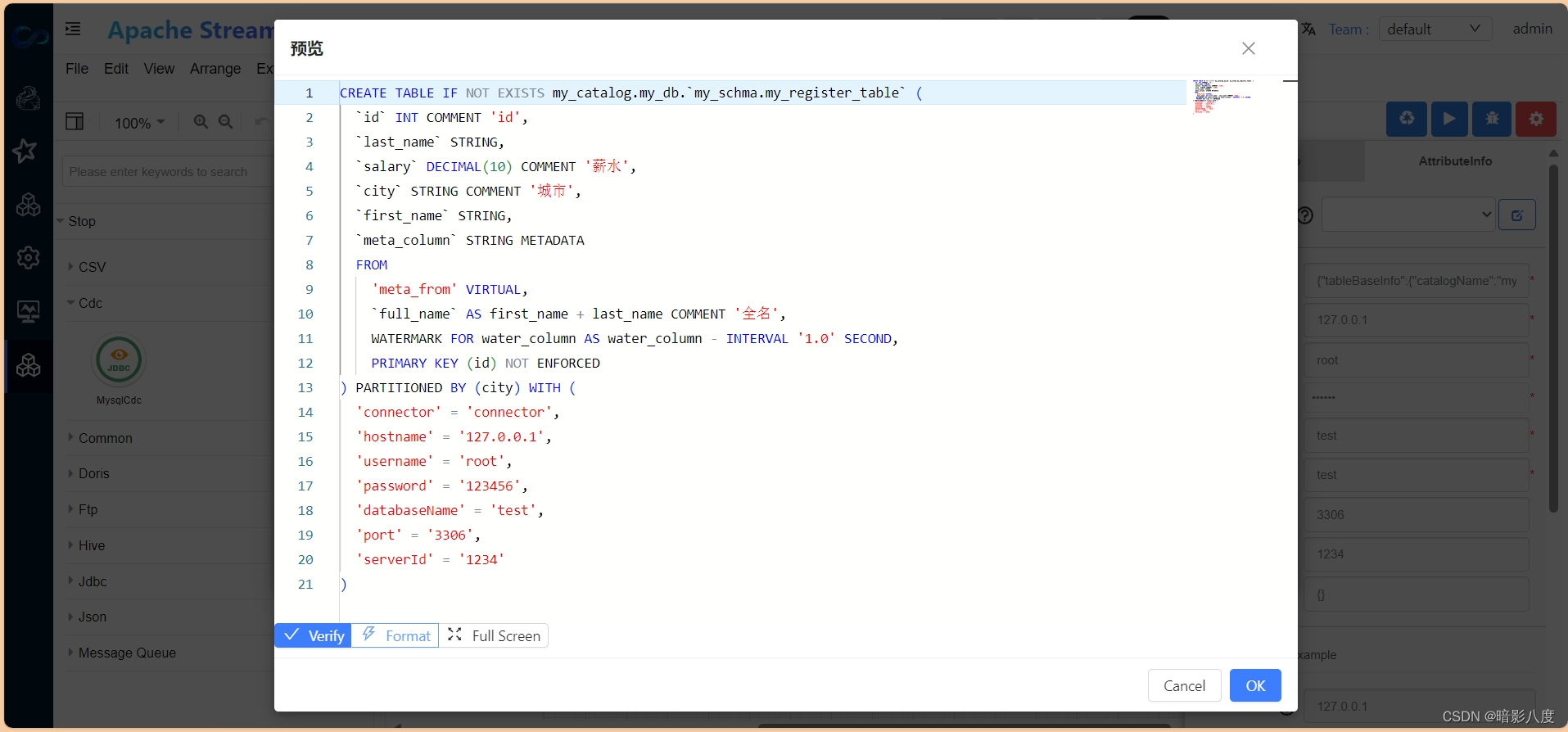
至此,我们通过简单的表单填写,便可开发一个flink任务,最后,点击运行,系统便可自动提交到flink环境,并可实时查看运行日志,是不是很方便快捷!
当然,目前系统处于初期研发阶段,还有很多不完善的地方,敬请谅解。最后,我们来看一个简单的实例,如果通过PiflowX开发一个mysql cdc实时同步和flink读取doris的任务。
PiflowX-Droris读写组件
PiflowX-MysqlCdc组件
相关文章:
PiflowX如何快速开发flink程序
PiflowX如何快速开发flink程序 参考资料 Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码-腾讯云开发者社区-腾讯云 (tencent.com) Flink SQL 背景 Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标…...

Mysql运算符
文章目录 比较运算符< > !IS NULL \ IS NOT NULL \ ISNULLLEAST() \ GREATEST() 查询数据大小(字典序)BETWEEN...AND...IN (SET) \ NOT IN (SET)LIKE 模糊查询REGEXP \ RLIKE 逻辑运算符逻辑运算符: OR (||)、A…...
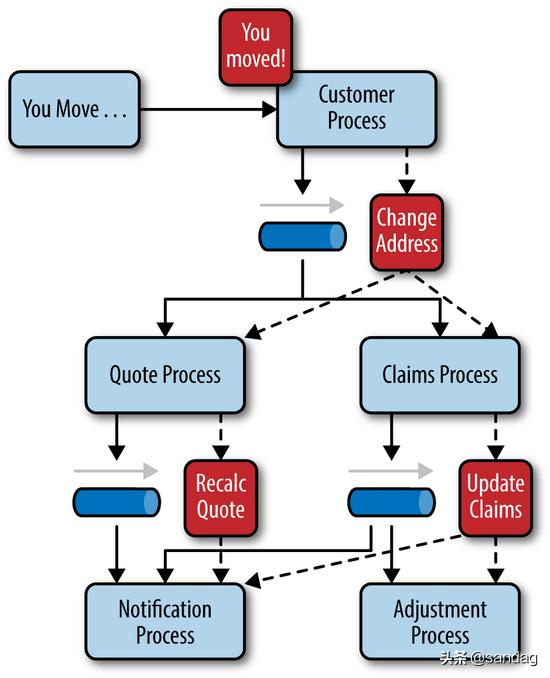
软件架构之事件驱动架构
一、定义 事件驱动的架构是围绕事件的发布、捕获、处理和存储(或持久化)而构建的集成模型。 某个应用或服务执行一项操作或经历另一个应用或服务可能想知道的更改时,就会发布一个事件(也就是对该操作或更改的记录)&am…...

C++ 后端面试 - 题目汇总
文章目录 🍺 非技术问题🍻 基本问题🥂 请自我介绍?🥂 你有什么问题需要问我的? 🍻 加班薪资🥂 你对加班有什么看法?🥂 你的薪资期望是多少?【待回…...

zds1104示波器使用指南
1、设置语言 2、功能检测验证示波器是否正常工作 3、示波器面板按钮详解 3.1、软键 3.2、运行控制与操作区 3.3、水平控制区 3.4、垂直控制区 3.5、多功能控制区 3.6、断电启动恢复,auto setup,default setup,恢复出厂设置详细解释 3.7、触…...
uni-app修改头像和个人信息
效果图 代码(总) <script setup lang"ts"> import { reqMember, reqMemberProfile } from /services/member/member import type { MemberResult, Gender } from /services/member/type import { onLoad } from dcloudio/uni-app impor…...
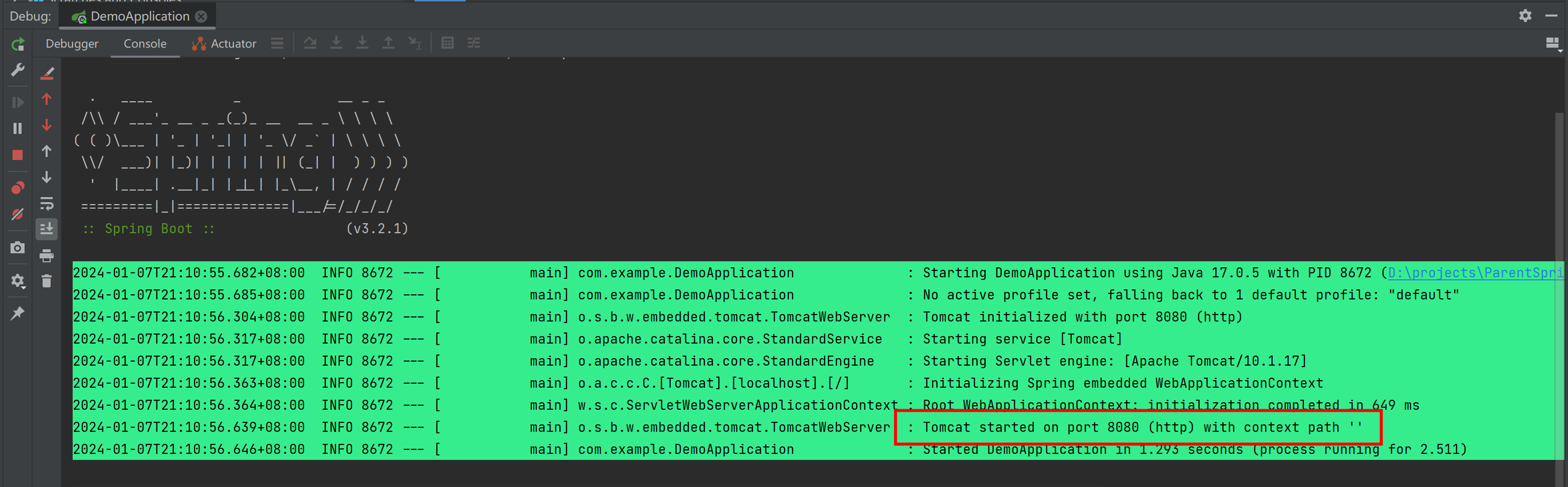
IDEA 中搭建 Spring Boot Maven 多模块项目 (父SpringBoot+子Maven)
第1步:新建一个SpringBoot 项目 作为 父工程 [Ref] 新建一个SpringBoot项目 删除无用的 .mvn 目录、 src 目录、 mvnw 及 mvnw.cmd 文件,最终只留 .gitignore 和 pom.xml 第2步:创建 子maven模块 第3步:整理 父 pom 文件 ① …...
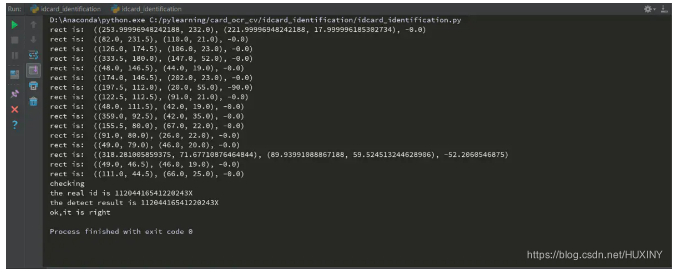
竞赛保研 基于计算机视觉的身份证识别系统
0 前言 🔥 优质竞赛项目系列,今天要分享的是 基于机器视觉的身份证识别系统 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-sen…...
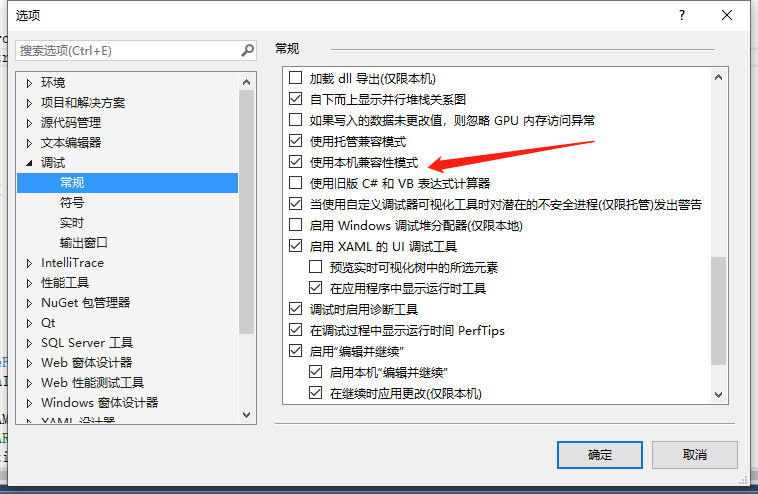
在visual studio中调试时无法查看std::wstring
1.问题 在调试的时候发现std::wstring类型的变量查看不了,会显示(error)|0,百思不得其解。 2.解决方法 参考的:vs2015调试时无法显示QString变量的值,只显示地址_vs调试qstring的时候如何查看字符串-CSDN博客 在工具/选项/调试…...

2023年全国职业院校技能大赛高职组应用软件系统开发正式赛题—模块三:系统部署测试
模块三:系统部署测试(3 小时) 一、模块考核点 模块时长:3 小时模块分值:20 分本模块重点考查参赛选手的系统部署、功能测试、Bug 排查修复及文档编写能力,具体包括:系统部署。将给定项目发布到…...

微信小程序上传并显示图片
实现效果: 上传前显示: 点击后可上传,上传后显示: 源代码: .wxml <view class"{{company_logo_src?blank-area:}}" style"position:absolute;top:30rpx;right:30rpx;height:100rpx;width:100rp…...
java基础知识点系列——数据输入(五)
java基础知识点系列——数据输入(五) 数据输入概述 Scanner使用步骤 (1)导包 import java.util.Scanner(2)创建对象 Scanner sc new Scanner(System.in)(3)接收数据 int i sc…...

MySQL面试题 | 07.精选MySQL面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

C语言中关于指针的理解及用法
关于指针意思的参考:https://baike.baidu.com/item/%e6%8c%87%e9%92%88/2878304 指针 指针变量 地址 野指针 野指针就是指针指向的位置是不可知的(随机的,不正确的,没有明确限制的) 以下是导致野指针的原因 1.指针…...

软件测试|深入理解Python中的re.search()和re.findall()区别
前言 在Python中,正则表达式是一种强大的工具,用于在文本中查找、匹配和处理模式。re 模块提供了许多函数来处理正则表达式,其中 re.search()和 re.findall() 是常用的两个函数,用于在字符串中查找匹配的模式。本文将深入介绍这两…...

❤ Vue3 完整项目太白搭建 Vue3+Pinia+Vant3/ElementPlus+typerscript(一)yarn 版本控制 ltb (太白)
❤ 项目搭建 一、项目信息 Vue3 完整项目搭建 Vue3PiniaVant3/ElementPlustyperscript(一)yarn 版本控制 项目地址: 二、项目搭建 (1)创建项目 yarn create vite <ProjectName> --template vueyarn install …...

linux搭建SRS服务器
linux搭建SRS服务器 文章目录 linux搭建SRS服务器SRS说明实验说明搭建步骤推流步骤查看web端服务器拉流步骤final SRS说明 SRS(simple Rtmp Server),是一个简单高效的实时视频服务器,支持RTMP/WebRTC/HLS/HTTP-FLV/SRT, 是国人自己开发的一款…...
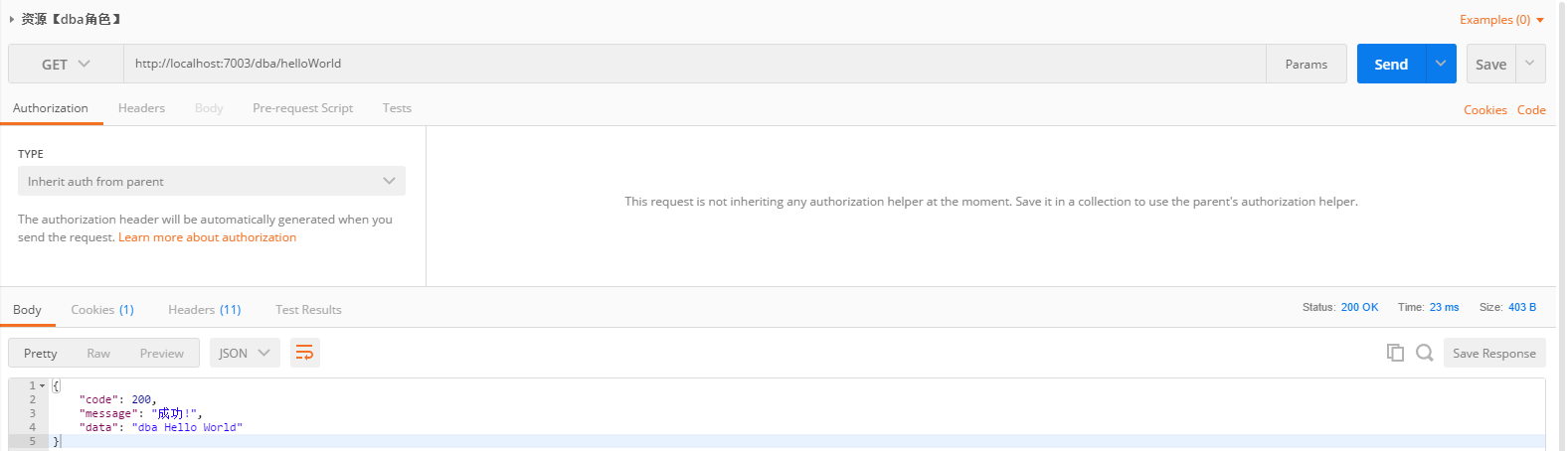
系列六、Spring Security中的认证 授权 角色继承
一、Spring Security中的认证 & 授权 & 角色继承 1.1、概述 关于Spring Security中的授权,请参考【系列一、认证 & 授权】,这里不再赘述。 1.2、资源类 /*** Author : 一叶浮萍归大海* Date: 2024/1/11 20:58* Description: 测试资源*/ Re…...

云原生周刊:OpenTofu 宣布正式发布 | 2023.1.15
开源项目推荐 kubeaudit kubeaudit 是一个开源项目,旨在帮助用户对其 Kubernetes 集群进行常见安全控制的审计。该项目提供了工具和检查规则,可以帮助用户发现潜在的安全漏洞和配置问题。 Chronos Chronos 是一款综合性开发人员工具,可监…...
【如何在 GitHub上面找项目】【转载】
很多的小伙伴,经常会有这样的困惑,我看了很多技术的学习文档、书籍、甚至视频,我想动手实践,于是我打开了GitHub,想找个开源项目,进行学习,获取项目实战经验。这个时候很多小伙伴就会面临这样的…...

线性化多噪声训练:提升混沌系统长期预测稳定性的正则化技术
1. 项目概述:当机器学习遇上混沌,如何让预测“长治久安”?在天气预报、气候模拟乃至金融市场分析中,我们常常需要面对一类“混沌系统”。这类系统的特点是,其短期行为虽然遵循确定的规律,但长期演化对初始条…...
)
别再只盯着MSE了!用Python实战对比5大回归评估指标(附避坑指南)
别再只盯着MSE了!用Python实战对比5大回归评估指标(附避坑指南)当你的回归模型在测试集上表现不佳时,第一个浮现在脑海的问题往往是:"该用哪个指标来评估才最合理?"这个问题远比想象中复杂——我…...

从事件关系网络看现有AI技术:一个统一的底层解释框架
在前几篇文章中,我提出了一个核心命题:智能的本质不是“知道什么”,而是“知道在发生什么”。 要实现这种智能,我们的AI系统必须从处理“实体”转向处理“事件”。事件不是孤立的存在者,而是在关系网络中确定自身意义的…...

效率直接起飞!2026年最值得信赖的专业AI论文软件
2026年AI论文写作工具已从“内容生成”升级为智能学术辅助系统,核心评价维度包括文献真实性、格式合规性、长文本逻辑、查重降重、AIGC合规与多语言支持。本次测评覆盖6款主流工具,测试场景涵盖中英文论文、全流程与专项功能、免费与付费版本,…...

2026年论文党必备:盘点2026年倾心之选的的降AIGC网站
轻松降低论文AI率在2026年已不再是天方夜谭。以下是2026年最炸裂、实测效果显著的降AIGC网站神器,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,帮你稳妥搞定毕业论文。 一、全流程王者:一站式搞定论文全链路 这类工具…...
专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢)
项目介绍 基于Python的大学生竞赛组队系统设计与实现(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢
基于Python的大学生竞赛组队系统设计与实现的详细项目实例 请注意此篇内容只是一个项目介绍 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解) 大学生竞赛已成为高校人才培养…...

独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目 对于独立开发者或小型工作室而言,在项目启动…...

通过curl命令直接测试Taotoken聊天补全接口的配置与调用方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的配置与调用方法 在开发或调试大模型应用时,有时你可能希望绕过高级SDK&am…...

AssetStudio深度解析:Unity资源逆向的底层原理与工程实践
1. 这不是“点开即用”的工具,而是Unity资源逆向的手术刀AssetStudio这个名字听起来像某个轻量级小工具——点开、拖入、导出,三步搞定。但实际用过Unity项目逆向的人都知道,它根本不是“一键提取”的魔法棒,而是一把需要你亲手调…...

5分钟彻底掌握Windows驱动管理:DriverStore Explorer完全指南
5分钟彻底掌握Windows驱动管理:DriverStore Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现Windows系统盘空间持续减少,却找不到原因…...