大数据 - Doris系列《三》- 数据表设计之表的基本概念
目录
🐶3.1 字段类型
🐶3.2 表的基本概念
3.2.1 Row & Column
3.2.2 分区与分桶
🥙3.2.2.1 Partition
1. Range 分区
2. List 分区
进阶:复合分区与单分区的选择
3.2.3 PROPERTIES
🥙3.2.3.1 分片副本数
🥙3.2.3.2 存储介质 和 热数据冷却时间
3.2.4小练习:建表指定分区和分桶数
🐶3.1 字段类型
| TINYINT | 1 字节 | 范围:-2^7 + 1 ~ 2^7 - 1 |
| SMALLINT | 2 字节 | 范围:-2^15 + 1 ~ 2^15 - 1 |
| INT | 4 字节 | 范围:-2^31 + 1 ~ 2^31 - 1 |
| BIGINT | 8 字节 | 范围:-2^63 + 1 ~ 2^63 - 1 |
| LARGEINT | 16 字节 | 范围:-2^127 + 1 ~ 2^127 - 1 |
| FLOAT | 4 字节 | 支持科学计数法 |
| DOUBLE | 12 字节 | 支持科学计数法 |
| DECIMAL[(precision, scale)] | 16 字节 | 保证精度的小数类型。默认是DECIMAL(10, 0) ,precision: 1 ~ 27 ,scale: 0 ~ 9,其中整数部分为 1 ~ 18,不支持科学计数法 |
| DATE | 3 字节 | 范围:0000-01-01 ~ 9999-12-31 |
| DATETIME | 8 字节 | 范围:0000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| CHAR[(length)] | 定长字符串。长度范围:1 ~ 255。默认为 1 | |
| VARCHAR[(length)] | 变长字符串。长度范围:1 ~ 65533 | |
| BOOLEAN | 与 TINYINT 一样,0 代表 false,1 代表 true | |
| HLL | 1~16385 个字节 | hll 列类型,不需要指定长度和默认值,长度根据数据的聚合程度系统内控制,并且 HLL 列只能通过 配套的hll_union_agg、Hll_cardinality、hll_hash 进行查询或使用 |
| BITMAP | bitmap 列类型,不需要指定长度和默认值。表示整型的集合,元素最大支持到 2^64 - 1 | |
| STRING | 变长字符串,0.15 版本支持,最大支持 2147483643 字节(2GB-4),长度还受 be 配置`string_type_soft_limit`, 实际能存储的最大长度取两者最小值。 只能用在 value 列,不能用在 key列和分区、分桶列 |
🐶3.2 表的基本概念
3.2.1 Row & Column
doris中的列分为两类:key列和value列key列在doris中有两种作用:聚合表模型中,key是聚合和排序的依据其他表模型中,key是排序依据
3.2.2 分区与分桶
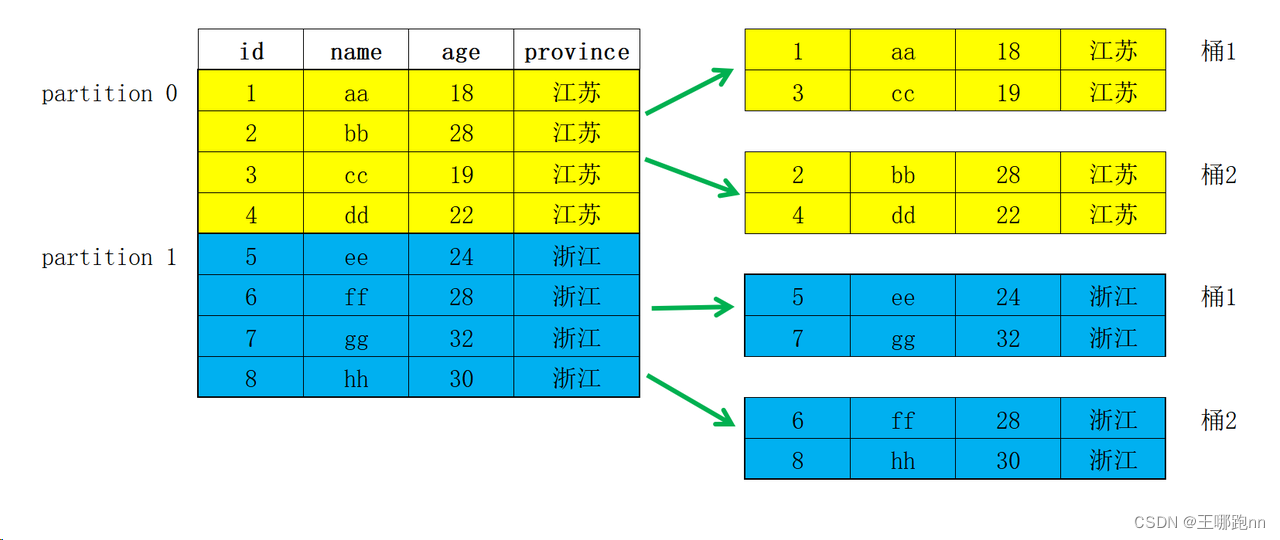
- partition(分区):是在 逻辑上 将一张表按行(横向)划分
分区的逻辑存储在元数据里面的
- tablet(又叫bucket,分桶):在 物理上 对一个分区再按行(横向)划分
分区的基础上进一步划分
🥙3.2.2.1 Partition
- Partition 列可以指定一列或多列,在聚合模型中,分区列必须为 KEY 列。
- 不论分区列是什么类型,在写分区值时,都需要加双引号。
- 分区数量理论上没有上限。
- 当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的 Partition。该 Partition 对用户不可见,并且不可删改。
- 创建分区时 不可添加范围重叠的分区。
1. Range 分区
-- Range Partition
drop table if exists test.expamle_range_tb;
CREATE TABLE IF NOT EXISTS test.expamle_range_tb
(`user_id` LARGEINT NOT NULL COMMENT "用户id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别"
)
ENGINE=OLAP
DUPLICATE KEY(`user_id`, `date`) -- 表模型
-- 分区的语法
PARTITION BY RANGE(`date`) -- 指定分区类型和分区列
(-- 指定分区名称,分区的上界 前闭后开PARTITION `p201701` VALUES LESS THAN ("2017-02-01"), PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 2;注意点
1. 分区名称要么用``号围起来,要么就单加一个名称--id为int类型
PARTITION BY RANGE(`id`) -- 指定分区类型和分区列
(-- 指定分区名称,分区的上界 前闭后开PARTITION `p100` VALUES LESS THAN (100), //范围: [int的最小值,100)PARTITION `p200` VALUES LESS THAN (200), //范围: [100,200)PARTITION `p300` VALUES LESS THAN (300) //范围: [200,300)
)insert into table values(300) 丢掉
ok, 0行收到影响insert into table values(200) -->p300
ok.1行收到影响但在公司中往往需要同时插入多行数据,可能就会漏掉一条而不自知

- 分区列通常为时间列,以方便的管理新旧数据。
- Partition 支持通过 VALUES LESS THAN (...) 仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。同时,也支持通过 VALUES [...) 指定上下界,生成一个左闭右开的区间。
- 通过 VALUES [...) 同时指定上下界比较容易理解。这里举例说明,当使用 VALUES LESS THAN (...) 语句进行分区的增删操作时,分区范围的变化情况:
-- 查看表中分区得情况
SHOW PARTITIONS FROM test.expamle_range_tbl \G;mysql> SHOW PARTITIONS FROM test.expamle_range_tbl \G;
*************************** 1. row ***************************PartitionId: 12020PartitionName: p201701VisibleVersion: 1VisibleVersionTime: 2022-08-30 21:57:36State: NORMALPartitionKey: dateRange: [types: [DATE]; keys: [0000-01-01]; ..types: [DATE]; keys: [2017-02-01]; )DistributionKey: user_idBuckets: 1ReplicationNum: 3StorageMedium: HDDCooldownTime: 9999-12-31 23:59:59
LastConsistencyCheckTime: NULLDataSize: 0.000 IsInMemory: falseReplicaAllocation: tag.location.default: 3
*************************** 2. row ***************************PartitionId: 12021PartitionName: p201702VisibleVersion: 1VisibleVersionTime: 2022-08-30 21:57:36State: NORMALPartitionKey: dateRange: [types: [DATE]; keys: [2017-02-01]; ..types: [DATE]; keys: [2017-03-01]; )DistributionKey: user_idBuckets: 1ReplicationNum: 3StorageMedium: HDDCooldownTime: 9999-12-31 23:59:59
LastConsistencyCheckTime: NULLDataSize: 0.000 IsInMemory: falseReplicaAllocation: tag.location.default: 3
*************************** 3. row ***************************PartitionId: 12022PartitionName: p201703VisibleVersion: 1VisibleVersionTime: 2022-08-30 21:57:35State: NORMALPartitionKey: dateRange: [types: [DATE]; keys: [2017-03-01]; ..types: [DATE]; keys: [2017-04-01]; )DistributionKey: user_idBuckets: 1ReplicationNum: 3StorageMedium: HDDCooldownTime: 9999-12-31 23:59:59
LastConsistencyCheckTime: NULLDataSize: 0.000 IsInMemory: falseReplicaAllocation: tag.location.default: 3
3 rows in set (0.00 sec)p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)ALTER TABLE test.expamle_range_tbl ADD PARTITION p201705 VALUES LESS THAN ("2017-06-01");
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
p201705: [2017-04-01, 2017-06-01)ALTER TABLE test.expamle_range_tbl DROP PARTITION p201703;
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)p201701: [MIN_VALUE, 2017-02-01)
p201705: [2017-04-01, 2017-06-01)空洞范围变为:[2017-02-01, 2017-04-01)现在增加一个分区 p201702new VALUES LESS THAN ("2017-03-01"),分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)可以看到空洞范围缩小为:[2017-03-01, 2017-04-01)PARTITION BY RANGE(`date`, `id`) 前闭后开
(PARTITION `p201701_1000` VALUES LESS THAN ("2017-02-01", "1000"),PARTITION `p201702_2000` VALUES LESS THAN ("2017-03-01", "2000"),PARTITION `p201703_all` VALUES LESS THAN ("2017-04-01")-- 默认采用id类型的最小值
)在以上示例中,我们指定 date(DATE 类型) 和 id(INT 类型) 作为分区列。以上示例最终得到的分区如下:
* p201701_1000: [(MIN_VALUE, MIN_VALUE), ("2017-02-01", "1000") )
* p201702_2000: [("2017-02-01", "1000"), ("2017-03-01", "2000") )
* p201703_all: [("2017-03-01", "2000"), ("2017-04-01", MIN_VALUE)) 注意,最后一个分区用户缺失,只指定了 date 列的分区值,所以 id 列的分区值会默认填充 MIN_VALUE。当用户插入数据时,分区列值会按照顺序依次比较,最终得到对应的分区。举例如下:

2. List 分区
- 分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
- Partition 支持通过 VALUES IN (...) 来指定每个分区包含的枚举值。
- 下面通过示例说明,进行分区的增删操作时,分区的变化。
-- List PartitionCREATE TABLE IF NOT EXISTS test.expamle_list_tbl
(`user_id` LARGEINT NOT NULL COMMENT "用户id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",`city` VARCHAR(20) NOT NULL COMMENT "用户所在城市",`age` SMALLINT NOT NULL COMMENT "用户年龄",`sex` TINYINT NOT NULL COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),PARTITION `p_jp` VALUES IN ("Tokyo")
)
-- 指定分桶的语法
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES
("replication_num" = "3"
);p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
p_uk: ("London")当我们删除分区 p_jp,分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_uk: ("London")PARTITION BY LIST(`id`, `city`)
(PARTITION `p1_city` VALUES IN (("1", "Beijing"), ("2", "Shanghai")),PARTITION `p2_city` VALUES IN (("2", "Beijing"), ("1", "Shanghai")),PARTITION `p3_city` VALUES IN (("3", "Beijing"), ("4", "Shanghai"))
)在以上示例中,我们指定 id(INT 类型) 和 city(VARCHAR 类型) 作为分区列。以上示例最终得到的分区如下:
* p1_city: [("1", "Beijing"), ("1", "Shanghai")]
* p2_city: [("2", "Beijing"), ("2", "Shanghai")]
* p3_city: [("3", "Beijing"), ("3", "Shanghai")]当用户插入数据时,分区列值会按照顺序依次比较,最终得到对应的分区。举例如下:
* 数据 ---> 分区
* 1, Beijing ---> p1_city
* 1, Shanghai ---> p1_city
* 2, Shanghai ---> p2_city
* 3, Beijing ---> p3_city
* 1, Tianjin ---> 无法导入
* 4, Beijing ---> 无法导入- 如果使用了 Partition,则 DISTRIBUTED ... 语句描述的是数据在 各个分区内的划分规则。如果不使用 Partition,则描述的是对整个表的数据的划分规则。
- 分桶列可以是多列,但必须为 Key 列。分桶列可以和 Partition 列相同或不同。
- 分桶列的选择,是在 查询吞吐 和 查询并发 之间的一种权衡:多个分桶列, 适合高吞吐低并发的场景单个分桶列,使用高并发点查询场景。
- 如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样 查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合高吞吐低并发的查询场景。
- 如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有 较大的概率分别触发不同的分桶扫描,各个查询之间的IO影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
-
- 分桶的数量理论上没有上限
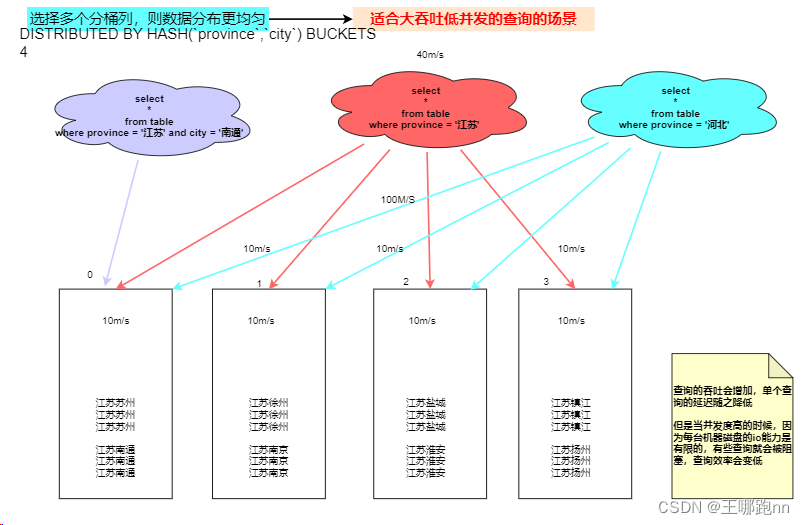
举例来说:我们拿 省份和城市作为分桶列1) 当查询where province ='江苏‘ and city="南通“时,此时只需要根据江苏和南通的hashcode找到对应的分桶编号。 (查询很快)2)当查询where province ='江苏‘时,此时需要全表扫描。 (查询会慢一些,但当你一个人查询时,所有机器都为你服务,读写数据的 吞吐量 会增加,因此适合于高吞吐低并发的场景)
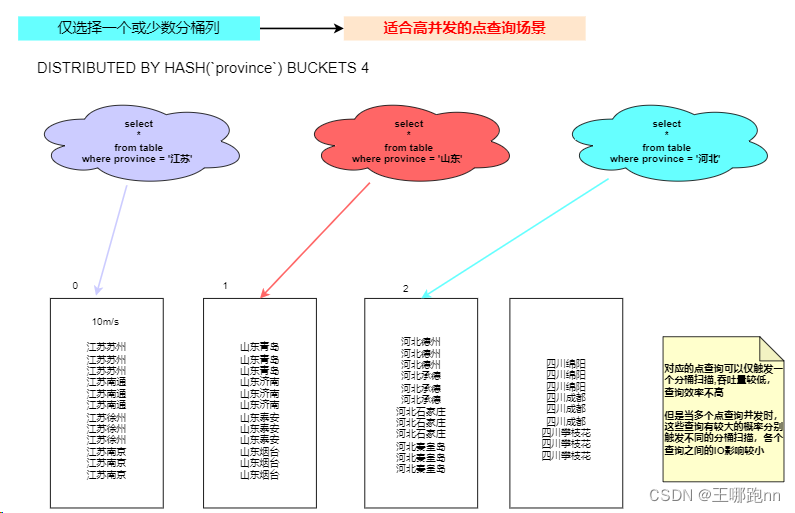
- 一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
- 分桶字段尽量选择基数大的字段。如只选择性别作为分桶列,只会落入两个桶中。
- 一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
- 单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。分桶应该控制桶内数据量 , 不易过大或者过小
- 当 Tablet 的数据量原则和数量原则冲突时,建议 优先考虑数据量原则 。
- 在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。
- 一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
小例子:假设在有10台BE,每台BE一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑4-8个分片。 5个5GB:8-16个分片。50GB:32个分片。500GB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。5TB:建议分区,每个分区大小在 500GB 左右,每个分区16-32个分片。
进阶:复合分区与单分区的选择
复合分区
3.2.3 PROPERTIES
PROPERTIES("参数名" = "参数值"
)🥙3.2.3.1 分片副本数
- replication_num
🥙3.2.3.2 存储介质 和 热数据冷却时间
- storage_medium
- storage_cooldown_time datetime
"storage_medium" = "SSD"
"storage_cooldown_time" = "2023-04-20 00:00:00" 要在当前时间之后,并且是一个datetime类型 默认初始存储介质可通过 fe 的配置文件 fe.conf 中指定 default_storage_medium=xxx,如果没有指定,则默认为 HDD。如果指定为 SSD,则数据 初始 存放在 SSD 上。没设storage_cooldown_time,则默认 30 天后,数据会从 SSD 自动 迁移到 HDD上。如果指定了 storage_cooldown_time,则在到达 storage_cooldown_time 时间后,数据才会迁移。
3.2.4小练习:建表指定分区和分桶数
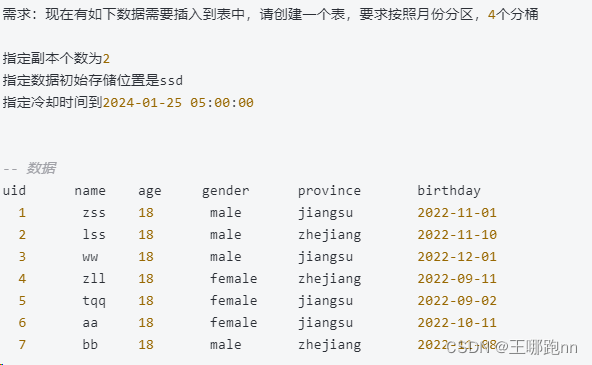
create table student(uid int,name varchar(10),birthday date,age int,province varchar(10)
)engine =olap
duplicate key(uid,name,birthday)
partition by range(birthday)(partition `p202209` values less than ("2022-10-01"),partition `p202210` values less than ("2022-11-01"),partition `p202211` values less than ("2022-12-01"),partition `p202212` values less than ("2023-01-01")
)
distributed by hash(uid) buckets 4
properties("replication_num"="2","storage_medium"="SSD","storage_cooldown_time"="2024-01-25 05:00:00"
);相关文章:

大数据 - Doris系列《三》- 数据表设计之表的基本概念
目录 🐶3.1 字段类型 🐶3.2 表的基本概念 3.2.1 Row & Column 3.2.2 分区与分桶 🥙3.2.2.1 Partition 1. Range 分区 2. List 分区 进阶:复合分区与单分区的选择 3.2.3 PROPERTIES 🥙3.2.3.1 分片副本数 …...

数据库mysql no.3
1.排序查询 order by 排序列表 【asc/desc】 排序列表:可以是单个字段、多个字段、表达式、函数、别名。 asc 升序 desc 降序 如果没有写那就是默认升序 2.常见函数 select 函数名(); 定义:函…...
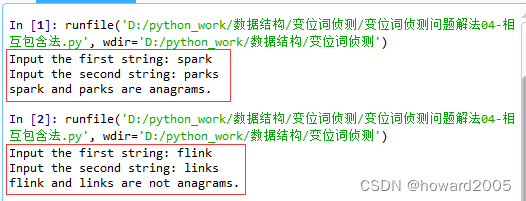
数据结构实战:变位词侦测
文章目录 一、实战概述二、实战步骤(一)逐个比较法1、编写源程序2、代码解释说明(1)函数逻辑解释(2)主程序部分 3、运行程序,查看结果4、计算时间复杂度 (二)排序比较法1…...
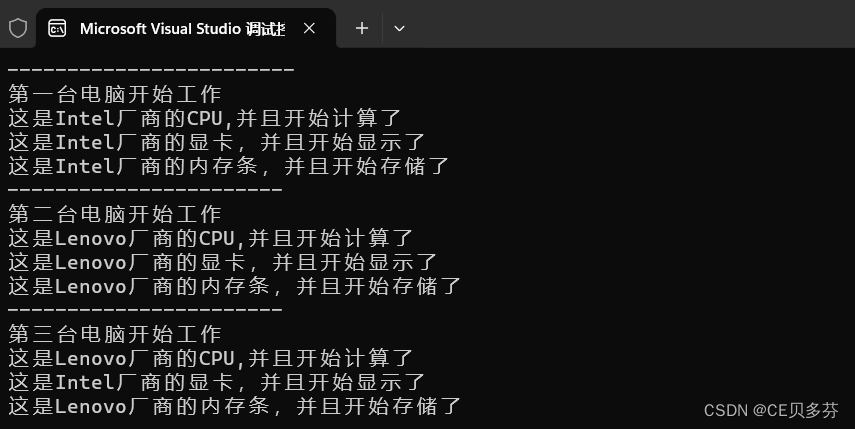
C++核心编程之类和对象---C++面向对象的三大特性--多态
目录 一、多态 1. 多态的概念 2.多态的分类: 1. 静态多态: 2. 动态多态: 3.静态多态和动态多态的区别: 4.动态多态需要满足的条件: 4.1重写的概念: 4.2动态多态的调用: 二、多态 三、多…...
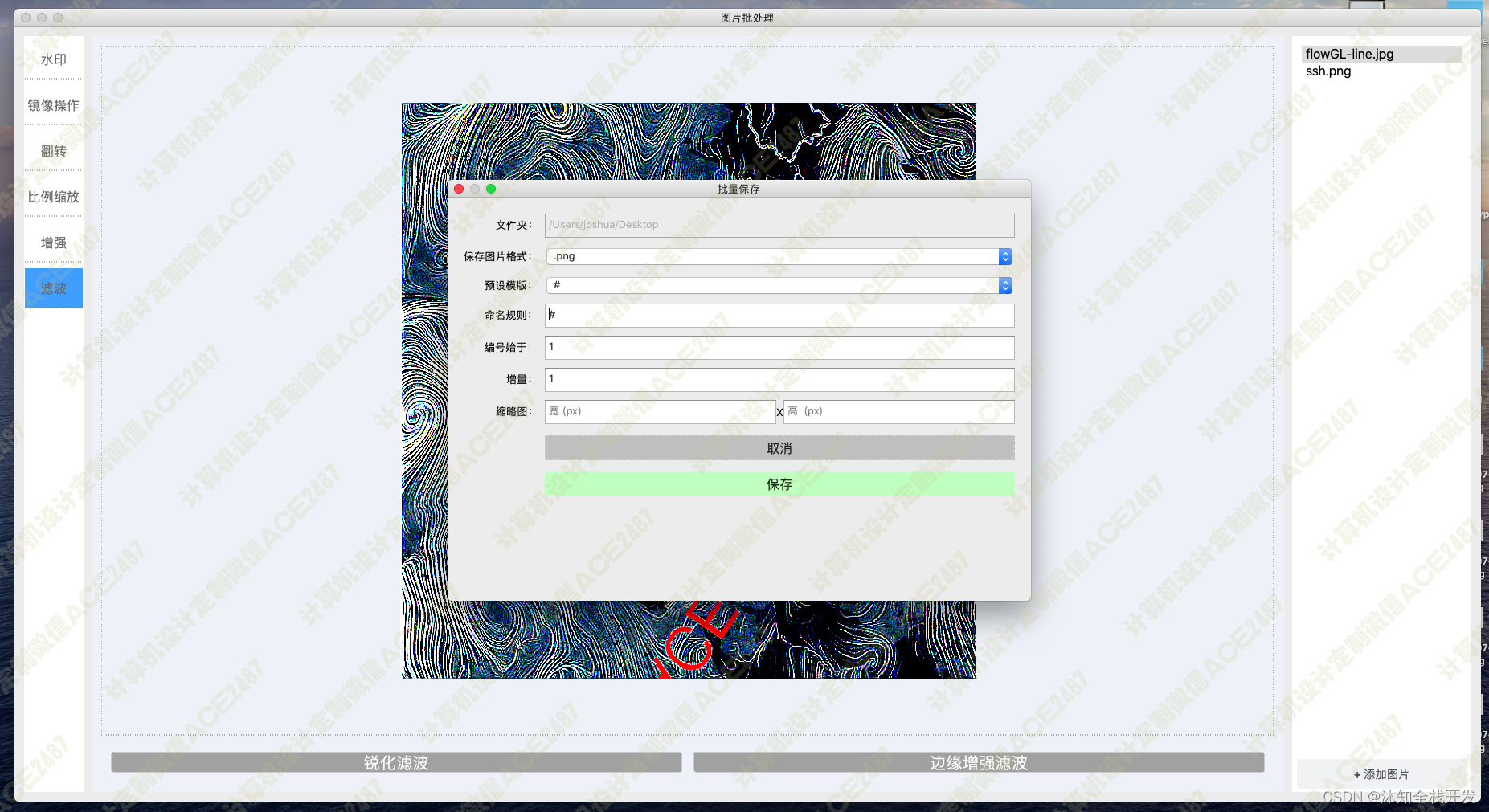
基于PyQT的图片批处理系统
项目背景: 随着数字摄影技术的普及,人们拍摄和处理大量图片的需求也越来越高。为了提高效率,开发一个基于 PyQt 的图片批处理系统是很有意义的。该系统可以提供一系列图像增强、滤波、水印、翻转、放大缩小、旋转等功能,使用户能够…...

vscode文件配置
lanuch.json {"version": "0.2.0","configurations": [{"name": "(gdb) 启动","type": "cppdbg","request": "launch",// "program": "输入程序名称,例…...

C++学习笔记——SLT六大组件及头文件
目录 一、C中STL(Standard Template Library) 二、 Gun源代码开发精神 三、 实现版本 四、GNU C库的头文件分布 bits目录 ext目录 backward目录 iostream目录 stdexcept目录 string目录 上一篇文章: C标准模板库(STL&am…...

Spring之AOP源码(二)
书接上文 文章目录 一、简介1. 前文回顾2. 知识点补充 二、ProxyFactory源码分析1. ProxyFactory2. JdkDynamicAopProxy3. ObjenesisCglibAopProxy 三、 Spring AOP源码分析 一、简介 1. 前文回顾 前面我们已经介绍了AOP的基本使用方法以及基本原理,但是还没有涉…...
)
VS code console.log快捷键设置 :console.log(‘n>>>‘,n)
vscode设置log快捷显示: 一、打开 VS Code,并进入菜单栏选择 “文件”(File)-> “首选项”(Preferences)-> “用户代码片段”(User Snippets)。 二、在弹出的下拉菜单中选择 …...
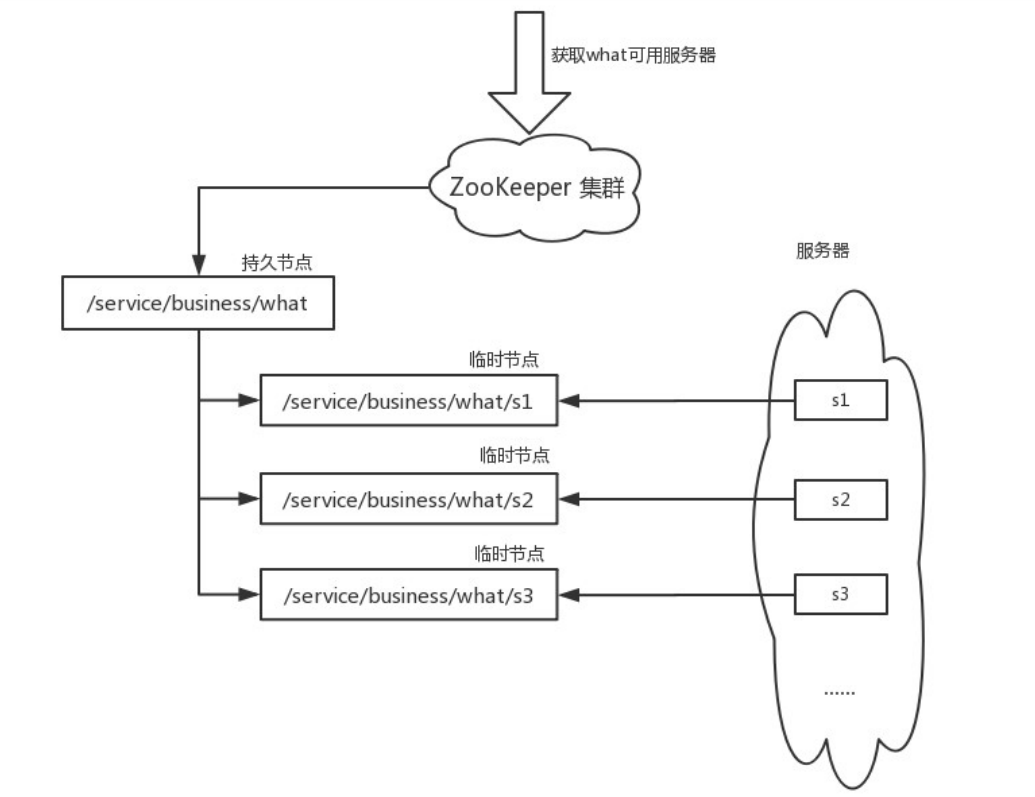
ZooKeeper 简介
1、概念介绍 ZooKeeper 是一个开放源码的分布式应用程序协调服务,为分布式应用提供一致性服务的软件,由雅虎创建,是 Google Chubby 的开源实现,是 Apache 的子项目,之前是 Hadoop 项目的一部分,使用 Java …...
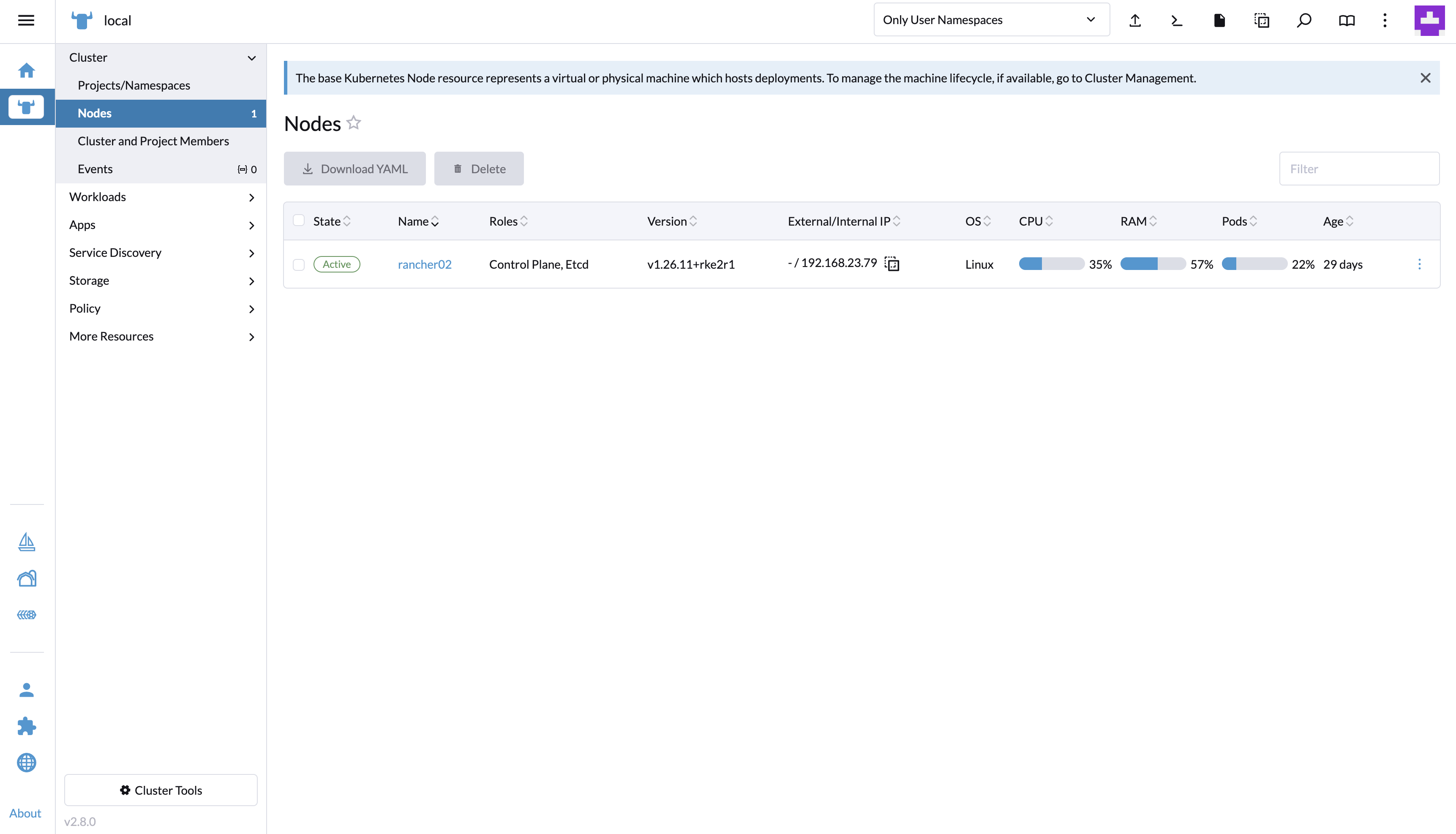
rke2 Online Deploy Rancher v2.8.0 latest (helm 在线部署 rancher v2.8.0)
文章目录 1. 简介2. 预备条件3. 安装 helm4. 安装 cert-manager4.1 yaml 安装4.2 helm 安装 5. 安装 rancher6. 验证7. 界面预览 1. 简介 Rancher 是一个 Kubernetes 管理工具,让你能在任何地方和任何提供商上部署和运行集群。 Rancher 可以创建来自 Kubernetes 托…...

k8s实战从入门到上天系列第一篇:K8s微服务实战内容开篇介绍
前言 我们使用开源ruoyi微服务基本使用,基于基本的微服务实践。我们来讲解k8s的实战内容。 第一章:开源ruoyi微服务简介基本使用 第二章:k8s基本知识回顾、k3s集群搭建和基本使用 第三章:微服务镜像构建 第四章:中间件…...
统一网关 Gateway【微服务】
文章目录 1. 前言2. 搭建网关服务3. 路由断言工厂4. 路由过滤器4.1 普通过滤器4.2 全局过滤器4.3 过滤器执行顺序 5. 跨域问题处理 1. 前言 通过前面的学习我们知道,通过 Feign 就可以向指定的微服务发起 http 请求,完成远程调用。但是这里有一个问题&am…...

【征服redis1】基础数据类型详解和应用案例
博客计划 ,我们从redis开始,主要是因为这一块内容的重要性不亚于数据库,但是很多人往往对redis的问题感到陌生,所以我们先来研究一下。 本篇,我们先看一下redis的基础数据类型详解和应用案例。 1.redis概述 以mysql为…...

【WPF.NET开发】WPF中的XAML资源
本文内容 使用 XAML 中的资源静态和动态资源静态资源动态资源样式、DataTemplate 和隐式键 资源是可以在应用中的不同位置重复使用的对象。 资源的示例包括画笔和样式。 本概述介绍如何使用 Extensible Application Markup Language (XAML) 中的资源。 你还可以使用代码创建和…...
)
ChatGPT 淘金潮(全)
原文:The ChatGPT GoldRush 译者:飞龙 协议:CC BY-NC-SA 4.0 一、ChatGPT 简介 什么是 ChatGPT? ChatGPT 是由 OpenAI 基于 GPT-4 架构创建的大型语言模型。它旨在理解和回应自然语言文本输入,使得可以与机器进行对话…...
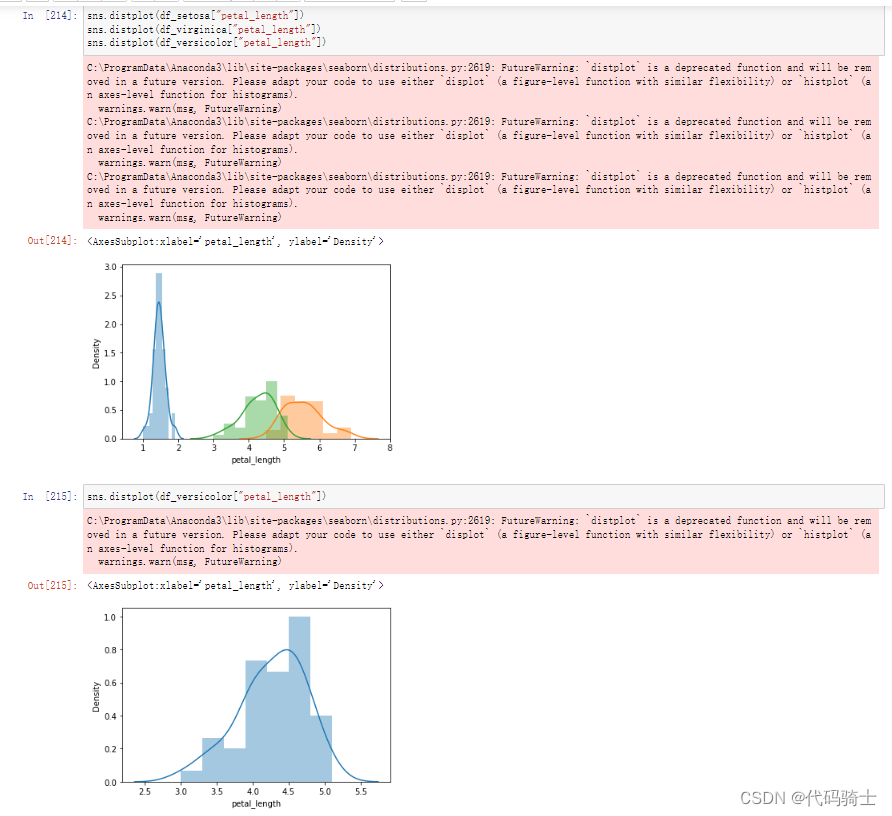
【零基础入门Python数据分析】Anaconda3 JupyterNotebookseaborn版
目录 一、安装环境 python介绍 anaconda介绍 jupyter notebook介绍 anaconda3 环境安装 解决JuPyter500:Internal Server Error问题-CSDN博客 Jupyter notebook快捷键操作大全 二、Python基础入门 数据类型与变量 数据类型 变量及赋值 布尔类型与逻辑运算…...

C++面试:单例模式、工厂模式等简单的设计模式 创建型、结构型、行为型设计模式的应用技巧
理解和能够实现基本的设计模式是非常重要的。这里,我们将探讨两种常见的设计模式:单例模式和工厂模式,并提供一些面试准备的建议。 目录 单例模式 (Singleton Pattern) 工厂模式 (Factory Pattern) 面试准备 1. 理解设计模式的基本概念…...

Oracle JDK 8 中的 computeIfAbsent 方法及实践
Java 8 引入了一系列新特性,其中之一是对 Map 接口的增强,其中包括了 computeIfAbsent 方法。这个方法为处理映射提供了一种便捷而强大的方式,允许在键不存在或对应的值为 null 时,动态计算新的值并将其放入映射。在本篇博客中&am…...
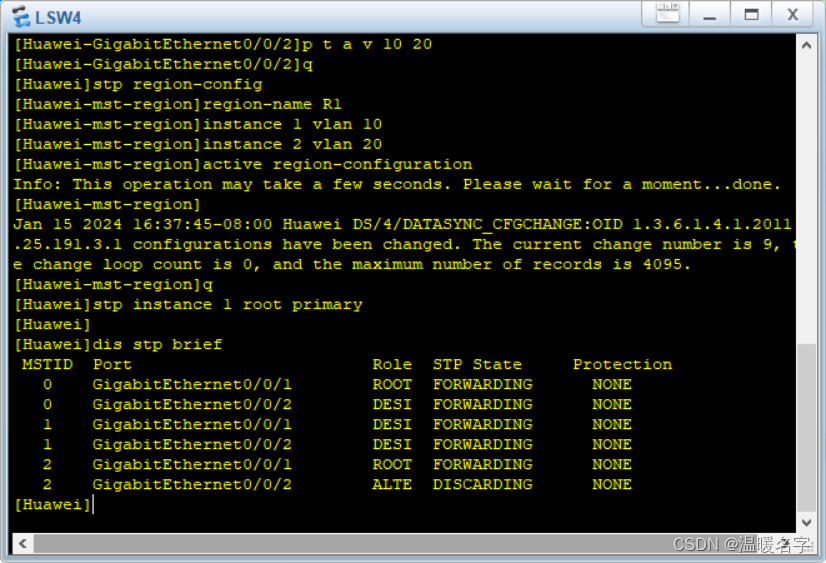
华为设备vlan下配置MSTP,STP选举
核心代码,不同实例,承载不同流量,为每个实例设置一个根网桥达到分流的效果 stp region-config //进入stp区域的设置 region-name R1 //区域命名为R1 instance 1 vlan 10 …...

Lindy流程自动化效果衰减真相:3年追踪数据显示,未做持续治理的企业6个月后效率回落至基线112%
更多请点击: https://codechina.net 第一章:Lindy流程自动化效果衰减真相:3年追踪数据显示,未做持续治理的企业6个月后效率回落至基线112% Lindy效应在流程自动化领域呈现显著反向特征:系统上线初期的效率跃升并非稳态…...

3分钟快速上手:用ComfyUI-MimicMotionWrapper实现专业级AI动作迁移
3分钟快速上手:用ComfyUI-MimicMotionWrapper实现专业级AI动作迁移 【免费下载链接】ComfyUI-MimicMotionWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-MimicMotionWrapper 你是否曾梦想过让普通人也能跳出专业舞者的优美动作?…...

如何高效处理PDF文档:Windows平台的终极解决方案
如何高效处理PDF文档:Windows平台的终极解决方案 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上的PDF处理工具而烦恼吗…...

在自动化客服系统中集成多模型API以提升回答稳定性与成本可控性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化客服系统中集成多模型API以提升回答稳定性与成本可控性 对于需要7x24小时稳定运行的智能客服系统而言,单一模型…...

递归函数详解
递归函数详解——用递归改写谭浩强《C 程序设计》经典例题 📚 基于谭浩强《C 程序设计》经典例题 💡 一套代码看懂递归的本质与应用 🎯 适合 C 语言进阶学习者 📋 目录 1. 递归函数入门基础 2. 递归的三要素 3. 经典例题递归改写 4. 递归进阶应用 [5. 递归 vs 迭代对比…...

Unity热更新原理与方案选型:从AOT限制到HybridCLR实践
1. 热更新不是“打补丁”,而是游戏生命周期的呼吸系统很多人第一次听说Unity热更新,脑子里浮现的是“改个UI文字不用重发包”“修个崩溃不用上架审核”——这没错,但太浅了。我带过三支手游团队,从2017年用AssetBundle硬啃&#x…...

RLHF实战指南:从人类反馈到对齐AI的工程化路径
1. 项目概述:当AI学会“听人话”——人类反馈如何真正撬动强化学习的天花板你有没有试过教一只特别聪明但完全不懂人情世故的助手做事?比如,你想让它帮你写一封得体又不失温度的辞职信,它却交出一份逻辑严密、用词精准、但通篇“根…...

3分钟学会洛雪音乐音源配置:免费获取全网高品质音乐的终极指南
3分钟学会洛雪音乐音源配置:免费获取全网高品质音乐的终极指南 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 还在为找不到高质量免费音乐资源而烦恼吗?lxmusic-项目为你提…...

终极实战指南:openpilot自动驾驶系统从部署到深度应用
终极实战指南:openpilot自动驾驶系统从部署到深度应用 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trendin…...

智能网络资源下载器:轻松捕获微信、抖音、小红书等平台内容
智能网络资源下载器:轻松捕获微信、抖音、小红书等平台内容 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...