自学大数据第三天~终于轮到hadoop了
前面那几天是在找大数据的门,其实也是在搞一些linux的基本命令,现在终于轮到hadoop了

Hadoop
hadoop的安装方式
单机模式:
就如字面意思,在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统~就如我们一开始入门的时候都是从本地开始的;
伪分布式模式
存储采用分布式文件系统,但是HDFS的名称节点和数据节点都在同一台机器上;
简单来说就像我们学习微服务的时候,只有一台机器,只能采用不同的端口号来实现微服务的开发,
分布式模式
存储采用分布式文件系统,HDFS的名称节点和数据节点位于不同的机器上~这才符合分布式的要求;
安装hadoop
下载hadoop
此时是以root用户登陆的系统
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
解压缩文件
tar -zxf hadoop-3.3.4.tar.gz
加压完毕之后将文件的权限授予hadoop用户,以免后续出现什么问题;
授权解压的文件给hadoop用户
[root@node1 local]# sudo chown -R hadoop ./hadoop-3.3.4
#切换用户
[root@node1 local]# su hadoop
[hadoop@node1 local]$
查看hadoop是否可以正常运行
cd hadoop-3.3.4
./bin/hadoop version
结果如下~

hadoop的单机配置
hadoop下载下来之后默认是非分布式模式,无需其他配置即可运行;
非分布式即java的单进程模式,这个我们就很擅长了,拿来直接运行即可;
首先来看官网给的例子(别的例子咱也不会,入门一下,日后在搞复杂的)
- 请听第一题
我们将input文件夹下所有的文件作为输入,筛选出符合正则表达式dfs[a-z.]+的单词并统计出现次数
mkdir ./input #创建一个文件夹#拷贝hadoop配置文件到 刚刚创建的input文件夹下cp ./etc/hadoop/*.xml ./input
#执行hadoop命令~./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'查看output文件夹下的内容
cat ./output/*
我们来看一下我们复制时都复制了些什么
[hadoop@node1 hadoop-3.3.4]$ ls ./input/
capacity-scheduler.xml hadoop-policy.xml hdfs-site.xml kms-acls.xml mapred-site.xml
core-site.xml hdfs-rbf-site.xml httpfs-site.xml kms-site.xml yarn-site.xml
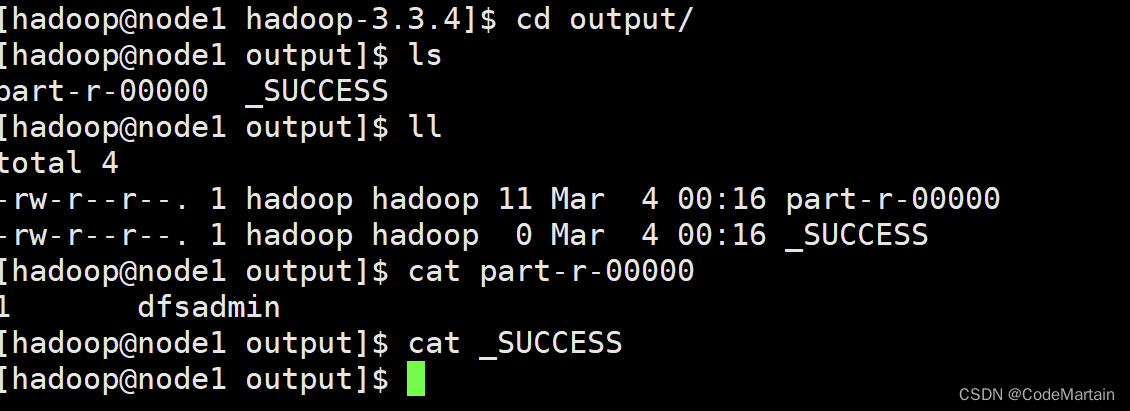
[hadoop@node1 hadoop-3.3.4]$ 再来看看 输出的文件中都有什么
[hadoop@node1 hadoop-3.3.4]$ cd output/
[hadoop@node1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@node1 output]$
这是什么?
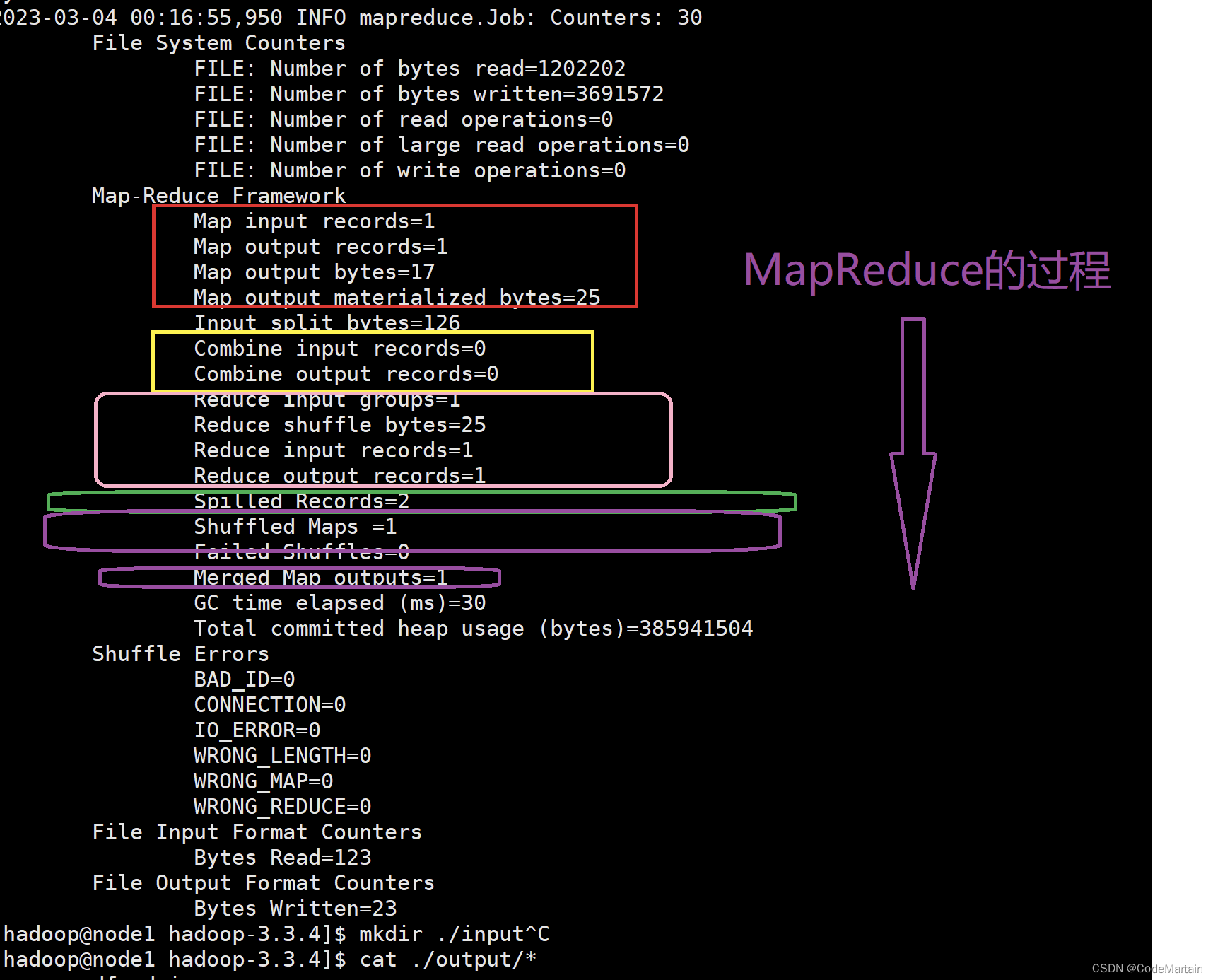
 我们再来看执行成功后的提示~
我们再来看执行成功后的提示~
 回头再来看hadoop执行的命令
回头再来看hadoop执行的命令
#头部命令
./bin/hadoop jar
有些类似于java执行jar 的那个逻辑
java jar
看看hadoop文件中都写了什么…
乌压压一大片(暂且搁置一边)
 源码自取
源码自取
然后就是参数部分
./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
找到它~可以看到是一些打包好的jar包,就是提前写好的代码去执行一些运算,以后我们也可以写代码打包后交给hadoop运行
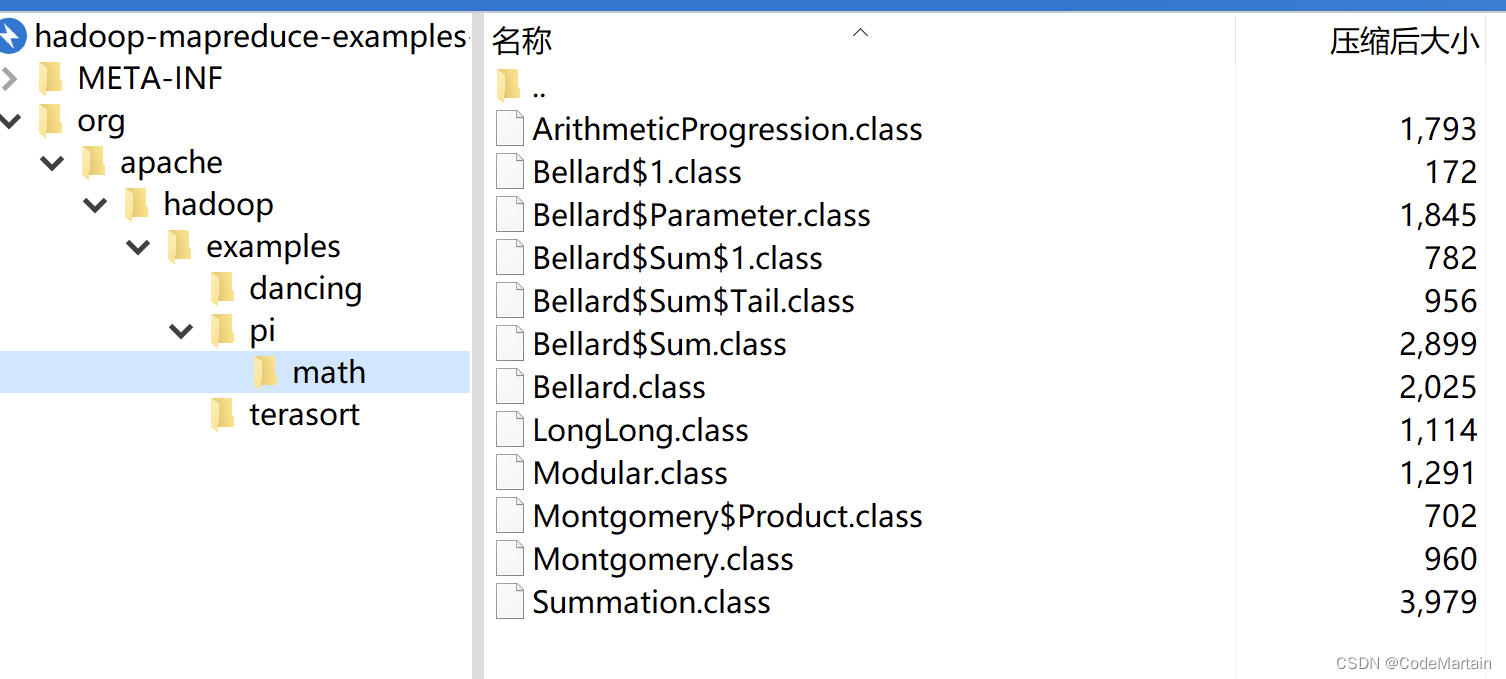
**注意,**Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
hadoop伪分布式配置
hadoop可以在单节点上以伪分布式的方式运行,这个由hadoop进程分离的java进程来运行,节点既可以作为namenode也可以作为datanode,同时读取hdfs中的文件.
伪分布式需要一些配置,其配置文件在etc/hadoop/ 中,需要修改两个配置文件
- core-site.xml
找到该文件并修改他
vi /usr/local/hadoop-3.3.4/etc/hadoop/core-site.xml
文件中添加如下内容
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop3.3.4/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>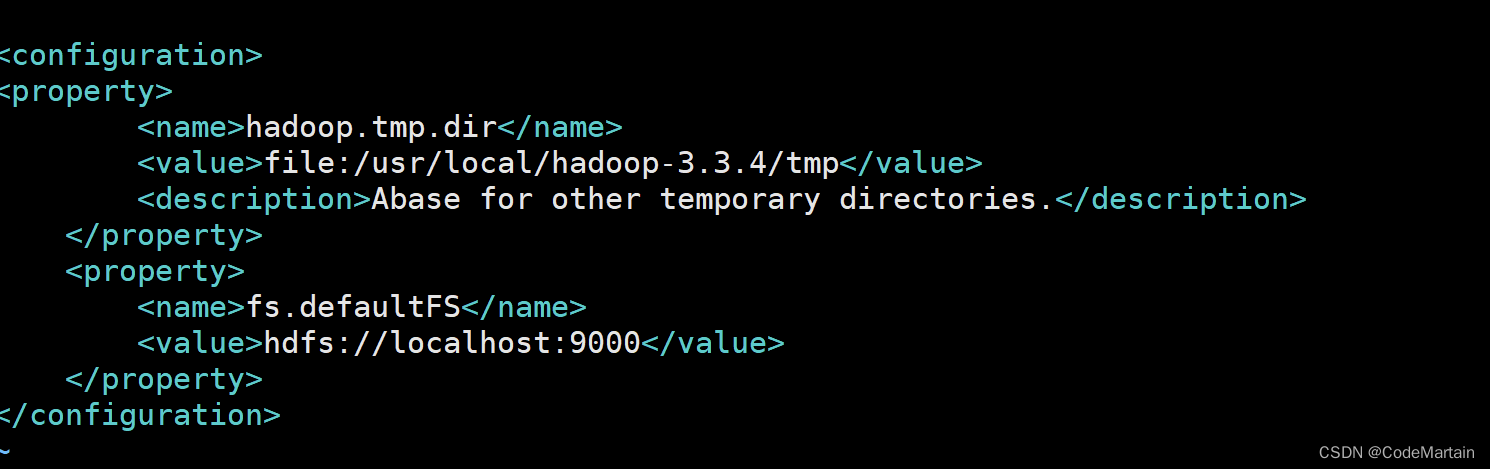
大体是配置了一个临时存储文件夹的地址和一个访问的网址
- hdfs-site.xml
找到配置文件并修改他
vi /usr/local/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
添加如下内容
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property>
</configuration>
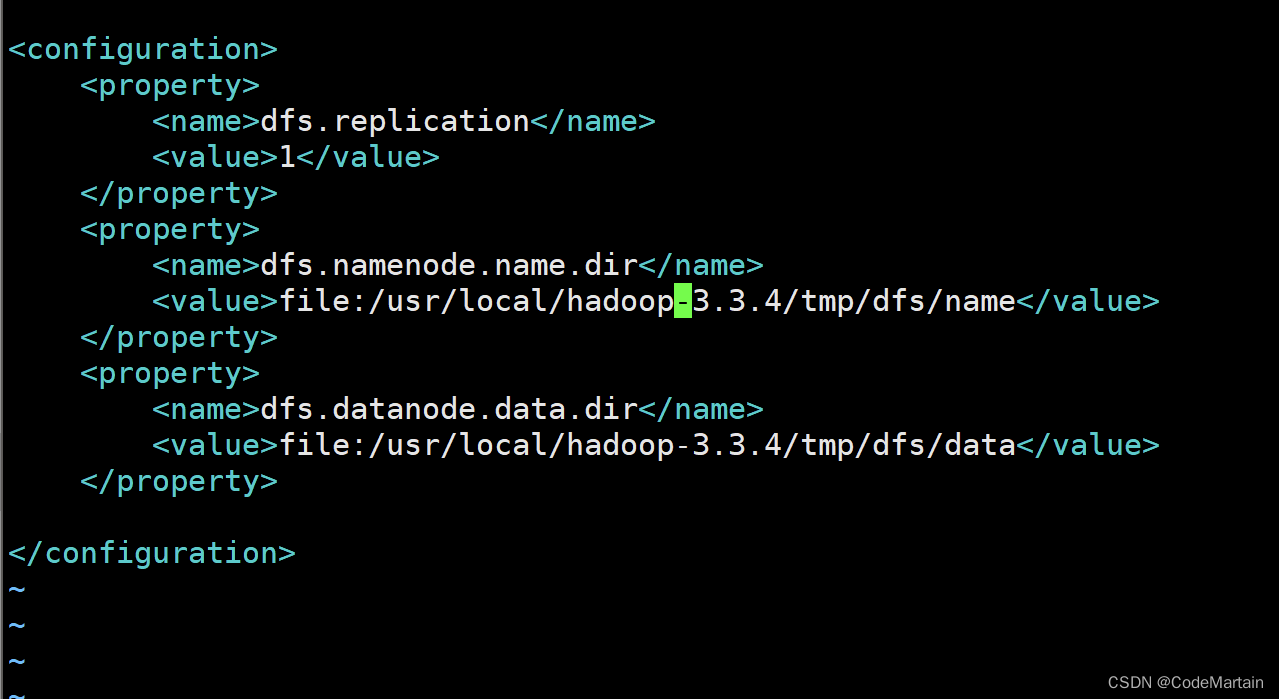
大体就是配置了namenode节点和datanode节点
hadoop的配置文件说明
hadoop的运行方式是由配置文件决定的(hadoop在运行时会读取配置文件)
由于一开始并没有配置任何内容,所以是单机模式;
按照hadoop的与运行方式来说,伪分布式子需要配置fs.defaultFS 和 dfs.replication 就可以了,但是若没有配置hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop, 而这个目录会在机器重启时可能会被删掉,导致必须重新执行format才行;
我们也指定了namenode节点跟datanode节点
配置完成后
初始化namenode
cd /usr/local/hadoop./bin/hdfs namenode -format
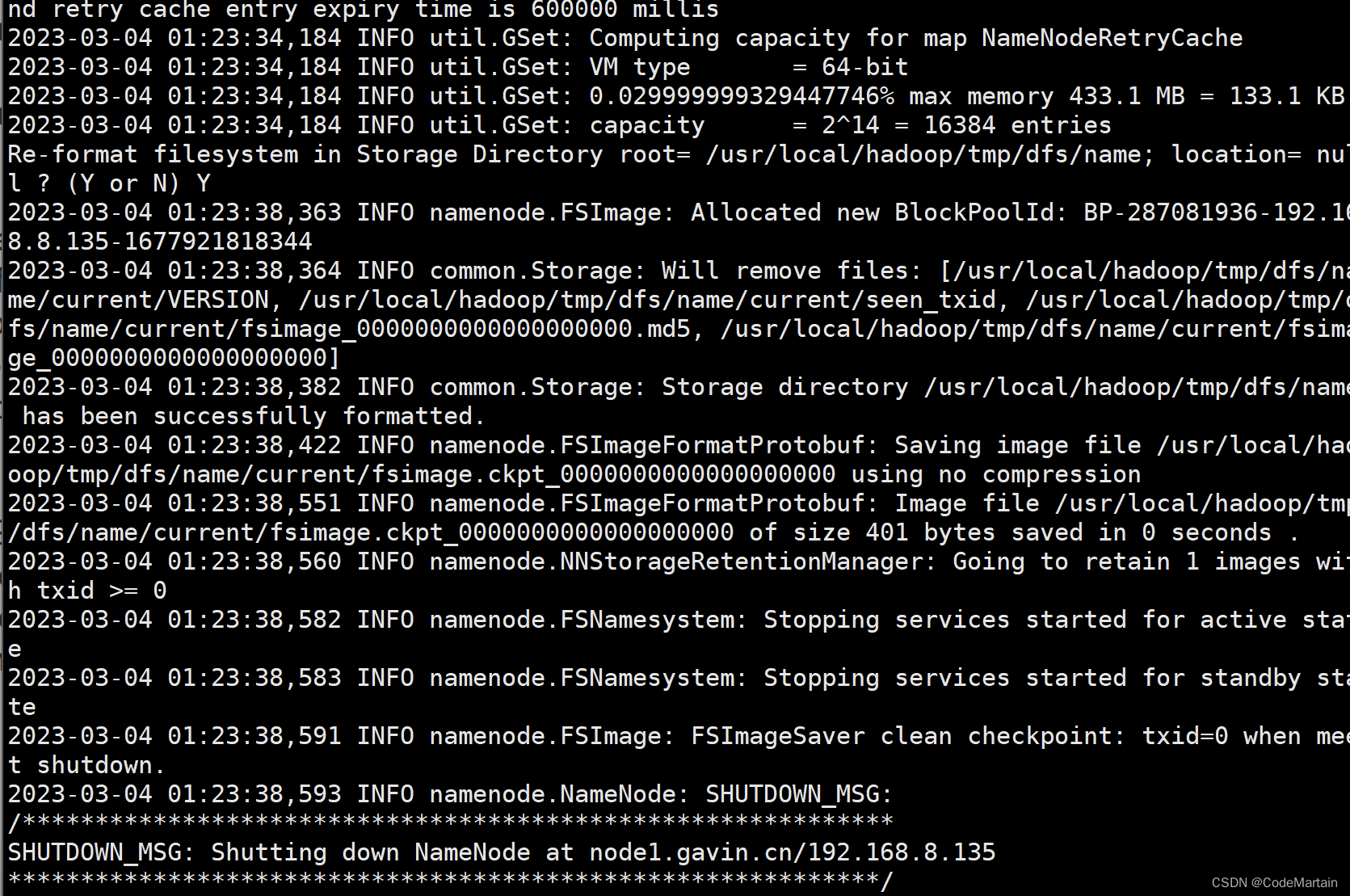 看到success就表示执行成功了;
看到success就表示执行成功了;
啥?没看到?这就尴尬了,截个图给你看看

再去文件夹下看看有没有对应的文件建立
ll ./tmp/dfs/name/current/

如果出现错误:
1.JAVA_HOME 错误,那就去配置一下 hadoop-env.sh文件 ,重新配置一下JAVA_HOME
2.文件夹创建失败,可能是当前用户没有权限,给当前用户授权
sudo chown -R hadoop /usr/local/hadoop-3.3.4
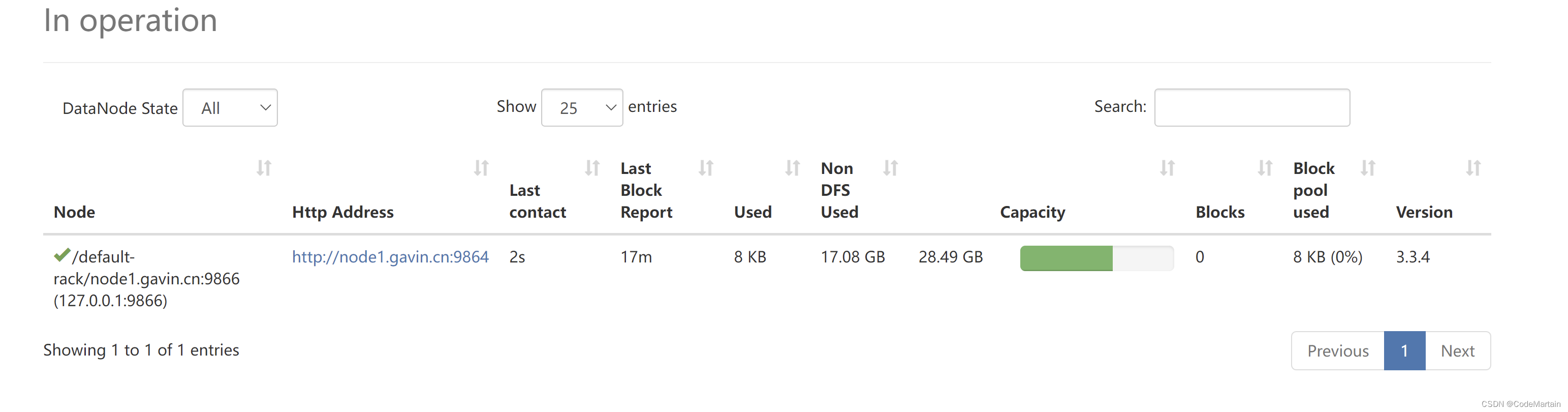
开启namenode和datanode节点
./sbin/start-dfs.sh 开启之后访问一下配置文件中的那个网址:
开启之后访问一下配置文件中的那个网址:
注:这里用虚拟机的ip地址;
 datanode节点的信息
datanode节点的信息
启动hadoop时遇到的一些问题集锦:
专门从网上找的,虽然现在还没有遇到,说不定以后会遇到,这样也能快速知道如何解决;
速度自取
接下来就是回顾时刻,这几天我们通过学习 了解到hadoop 的一些知识
首先是:
1,hadoop的环境-配置jdk
2,hadoop各个节点之间的交流通过ssh加密 --配置ssh
3,hadoop的运行三种方式:
- 单体模式
- 伪分布式
- 分布式
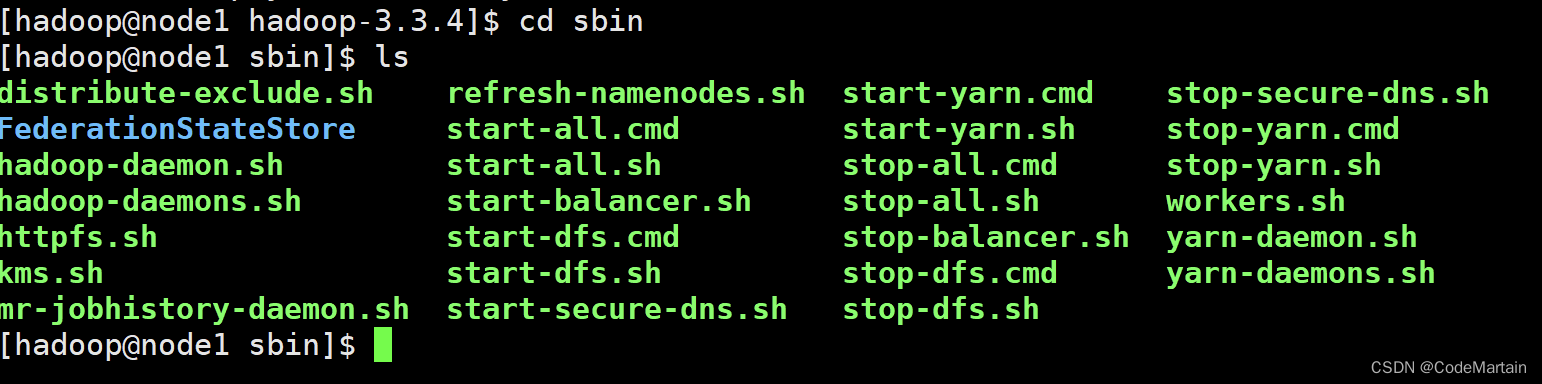
4,hadoop的运行命令
首先在hadoop文件下的bin目录有很多可以运行的命令文件
目前接触到了
启动hadoop ~ ~
./bin/hadoop jar 写好的打包程序 其他的运行配置
5,配置伪分布式的关键配置文件:
core-site.xml ~配置了临时文件夹
hdfs-site.xml ~配置了namenode节点和datanode节点以及一个访问html的地址
6,配置结束后 格式化namenode
./bin/hdfs namenode -format
7,启动namenode以及datanode守护进程
./sbin/start-dfs.sh
 未完待续~ 另一台机器操作一遍在熟悉一下啊!
未完待续~ 另一台机器操作一遍在熟悉一下啊!
相关文章:
自学大数据第三天~终于轮到hadoop了
前面那几天是在找大数据的门,其实也是在搞一些linux的基本命令,现在终于轮到hadoop了 Hadoop hadoop的安装方式 单机模式: 就如字面意思,在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统~就如我们一开始入门的时候都是从本地开始的; 伪分布式模式 存储采用…...

Unity 入门精要00---Unity提供的基础变量和宏以及一些基础知识
头文件引入: XXPROGRAM ... #include "UnityCG.cginc"; ... ENDXX 常用的结构体(在UnityCg.cginc文件中):在顶点着色器输入和输出时十分好用 。 关于如何使用这些结构体,可在Unity安装文件目录/Editor…...
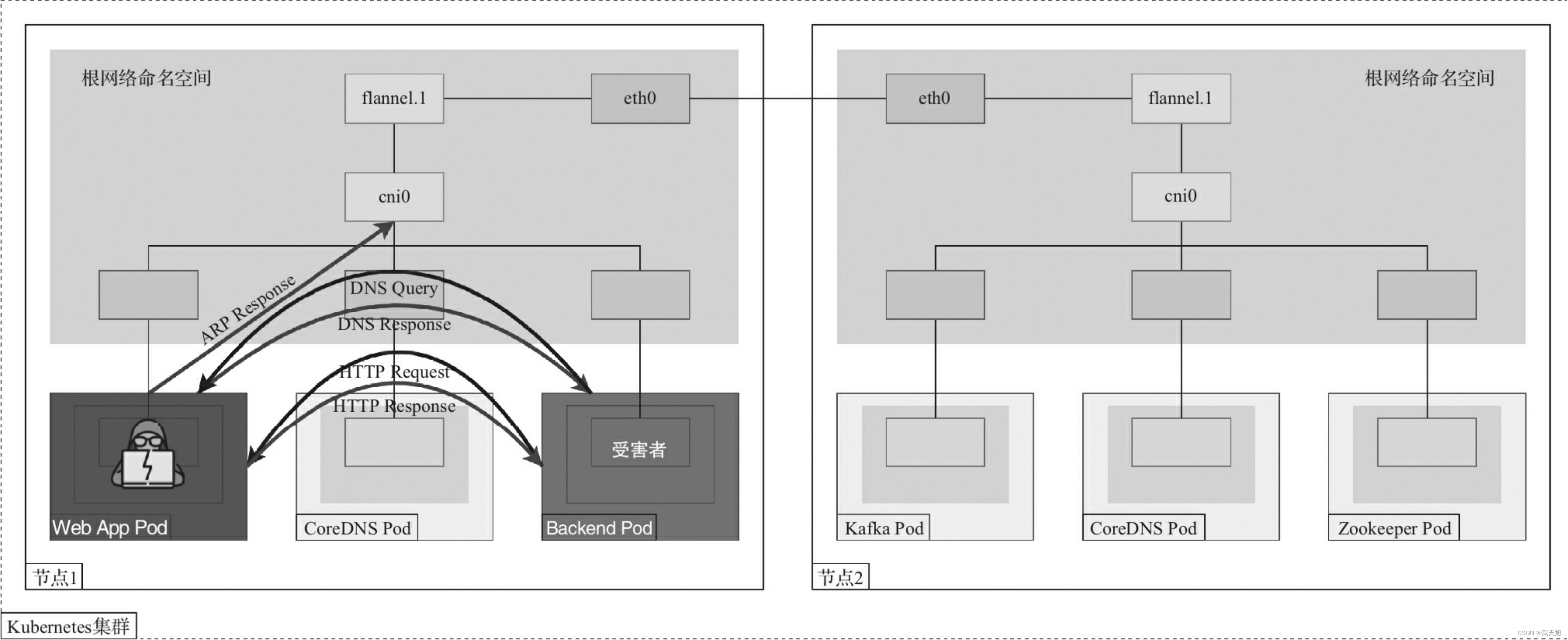
Kubernetes的网络架构及其安全风险
本博客地址:https://security.blog.csdn.net/article/details/129137821 一、常见的Kubernetes网络架构 如图所示: 说明: 1、集群由多个节点组成。 2、每个节点上运行若干个Pod。 3、每个节点上会创建一个CNI网桥(默认设备名称…...
)
Blob分析+特征+(差分)
Blob分析特征0 前言1 概念2 方法2.1 图像采集2.2 图像分割2.3 特征提取3 主要应用场景:0 前言 在缺陷检测领域,halcon通常有6种处理方法,包括Blob分析特征、Blob分析特征差分、频域空间域、光度立体法、特征训练、测量拟合,本篇博…...

Flink 提交模式
Flink的部署方式有很多,支持Local,Standalone,Yarn,Docker,Kubernetes模式等。而根据Flink job的提交模式,又可以分为三种模式: 模式1:Application Mode Flink提交的程序,被当做集群内部Application,不再需要Client端做繁重的准备工作。(例如执行main函数,生成JobG…...
三)
网络总结知识点(网络工程师必备)三
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放,树高千尺,落叶归根人生不易,人间真情 目录 前言 51.什么是ARP代理?...
测开:前端基础-css
一、CSS介绍和引用 1.1 css概述 层叠样式表,是一种样式表语言,用来描述HTML和XML文档的呈现。 CSS 用于简化HTML标签,把关于样式部分的内容提取出来,进行单独的控制,使结构与样式分离开发。 CSS 是以HTML为基础&…...

Java学习记录之JDBC
JDBC JDBC 是 Java Database Connectivity 的缩写,是允许Java 程序访问并操作关系型数据库数据的一套 应用程序接口。本身就是一种规范,它提供的接口有一套完整的,可移植的访问底层数据库的程序。 JDBC 的架构 JDBC API支持两层和三层处理…...

矩阵翻硬币
题目描述 小明先把硬币摆成了一个 n 行 m 列的矩阵。 随后,小明对每一个硬币分别进行一次 Q 操作。 对第 x 行第 y 列的硬币进行 Q 操作的定义:将所有第 ix 行,第 jy 列的硬币进行翻转。...
【C语言跬步】——指针数组和数组指针(指针进阶)
一.指针数组和数组指针的区别 1.指针数组是数组,是一种存放指针的数组; 例如: int* arr[10]; 2.数组指针是指针,是一种指向数组的指针,存放的是数组的地址; 例如: int arr[5]; int (p)[5]&a…...
第十四届蓝桥杯模拟赛第三期(Python)
写在前面 包含本次模拟赛的10道题题解能过样例,应该可以AC若有错误,欢迎评论区指出本次题目除了最后两题有些难度,其余题目较为简单,我只将代码和结果给出,如果不能理解欢迎私信我,我会解答滴。start 2022…...

css-盒模型
巧妙运用margin负值盒模型和怪异盒模型(border padding 包含在内)display: block 能让textarea input 水平尺寸自适应父容器? – 不能 * {box-sizing: border-box; // bs: bb }<textarea/> 是替换元素,尺寸由内部元素决定,不受display水平影响. 当然可以直接设置宽度10…...

Linux | 调试器GDB的详细教程【纯命令行调试】
文章目录一、前言二、调试版本与发布版本1、见见gdb2、程序员与测试人员3、为什么Release不能调试但DeBug可以调试❓三、使用gdb调试代码1、指令集汇总2、命令演示⌨ 行号显示⌨ 断点设置⌨ 查看断点信息⌨ 删除断点⌨ 开启 / 禁用断点⌨ 运行 / 调试⌨ 逐过程和逐语句⌨ 打印 …...

wifi芯片大市场和个人小生活
3.3 是日也,天朗气清,惠风和畅。仰观宇宙之大,俯察论文论坛,所以游目骋怀,足以极视听之娱,信可乐也。 夫人之相与,俯仰一世,或取诸怀抱,悟言一室之内;或因寄所…...
考试 上半年2023年3月13日开始,下半年2023年8月14日开始)
全国计算机技术与软件专业技术资格(水平)考试 上半年2023年3月13日开始,下半年2023年8月14日开始
根据2023年计算机技术与软件专业技术资格(水平)考试工作计划,可以得知,2023年软考报名时间——上半年2023年3月13日开始,下半年2023年8月14日开始。 点击查看:人力资源社会保障部办公厅关于2023年度专业技术人员职业资格考试工作计划及有关事项的通知 点击查看:2023年度…...
Hadoop企业优化)
大数据框架之Hadoop:MapReduce(六)Hadoop企业优化
一、MapReduce 跑的慢的原因 MapReduce程序效率的瓶颈在于两点: 1、计算机性能 CPU、内存、磁盘、网络 2、IO操作优化 数据倾斜Map和Reduce数设置不合理Map运行时间太长,导致Reduce等待过久小文件过多大量的不可分块的超大文件Spill次数过多Merge次…...

Spring File Storage的详细文档
快速入门配置pom.xml引入依赖<dependencies><!-- spring-file-storage 必须要引入 --><dependency><groupId>cn.xuyanwu</groupId><artifactId>spring-file-storage</artifactId><version>0.7.0</version></dependen…...

Java软件开发好学吗?学完好找工作吗?
互联网高速发展的当下,Java语言无处不在:手机APP、Java游戏、电脑应用,都有它的身影。作为最热门的开发语言之一,Java在编程圈的地位不可撼动。可是,听名字就很专业的样子。Java语言到底好学吗?刚入坑编程圈…...

【独家C】华为OD机试提供C语言题解 - 优秀学员统计
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明优秀…...

数据仓库、数据中台、数据湖都是什么?
相信很多人都在最近的招聘市场上看到过招聘要求里提到了数据仓库、数据中台,甚至还有数据湖,这些层出不穷的概念让人困扰。今天我就来跟大家讲一讲数据仓库、数据中台以及数据湖的概念及区别。 数据库 在了解数据仓库、数据中台以及数据湖之前ÿ…...

G-Helper:华硕笔记本色彩配置一键恢复指南
G-Helper:华硕笔记本色彩配置一键恢复指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址: https://…...

Qwen3-VL-4B Pro科研绘图生成:根据论文描述反向生成示意图初稿
Qwen3-VL-4B Pro科研绘图生成:根据论文描述反向生成示意图初稿 1. 项目概述 科研工作者经常面临一个痛点:在论文写作过程中,明明有清晰的理论描述和实验方案,却需要花费大量时间绘制专业的示意图。现在,借助Qwen3-VL…...

云手机 流畅稳定 操作简单
云手机依托云端服务器集群,配备企业级 GPU和高性能 CPU,通过资源池化技术,将物理算力切割成多个独立安卓实例,每个云手机实例可独占或动态共享强大资源,算力远超本地旗舰手机,能轻松运行大型 3D 游戏等高性…...

快速掌握Fast-F1:Python赛车数据分析终极指南
快速掌握Fast-F1:Python赛车数据分析终极指南 【免费下载链接】Fast-F1 FastF1 is a python package for accessing and analyzing Formula 1 results, schedules, timing data and telemetry 项目地址: https://gitcode.com/GitHub_Trending/fa/Fast-F1 想要…...
)
别再乱接Type-C了!手把手教你设计一个5V/5A的稳定电源模块(附电路图)
5V/5A Type-C电源模块实战设计指南:从选型到避坑全解析 Type-C接口凭借其正反插拔的便利性,已成为现代电子设备的标配。但许多DIY爱好者在自制Type-C电源模块时,常遇到供电不稳、接口烧毁甚至设备损坏的问题。本文将带你从零设计一个稳定可靠…...

【分箱进阶篇】分箱的工程细节:从训练到部署的完整模式
基础篇参考:【分箱基础篇】pandas 分箱双子星:pd.cut 与 pd.qcut 我们在基础篇讲了 pd.cut 和 pd.qcut 各自怎么用。但在实际项目里,分箱不是调一次函数就完事的。通常来说,训练集上算出来的切分点要保存下来,测试集…...

如何10分钟快速上手:语音转换工具完全指南
如何10分钟快速上手:语音转换工具完全指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI 语音数据小于等于10分钟也可以用来训练一个优秀的变声模型! 项目地址: https://gitcode.com/GitHub_Trending/re/Retrieval-based-Voice-Conversion…...
在静电模拟中的应用)
GAMES201实战:5分钟搞懂快速多极展开(FMM)在静电模拟中的应用
GAMES201实战:5分钟搞懂快速多极展开(FMM)在静电模拟中的应用 当你在游戏引擎中设计一个带电粒子系统时,是否遇到过这样的困境:随着粒子数量增加,计算速度呈指数级下降?传统N体问题计算需要处理每个粒子间的相互作用&a…...

Clipy:macOS效率工具中的自动化剪贴板增强专家
Clipy:macOS效率工具中的自动化剪贴板增强专家 【免费下载链接】Clipy Clipboard extension app for macOS. 项目地址: https://gitcode.com/gh_mirrors/cl/Clipy 你是否曾遇到这样的窘境:刚复制的重要文本被新内容覆盖,不得不重新打开…...

Python自动化爬取企查查企业工商信息的实战技巧
1. Python爬取企查查数据的核心思路 企查查作为国内权威的企业信息查询平台,包含了大量有价值的工商注册信息。对于金融、证券行业的从业者来说,经常需要批量获取这些数据进行分析。手动一个个查询不仅效率低下,还容易出错。这时候Python自动…...