大数据框架之Hadoop:MapReduce(六)Hadoop企业优化
一、MapReduce 跑的慢的原因
MapReduce程序效率的瓶颈在于两点:
1、计算机性能
CPU、内存、磁盘、网络
2、IO操作优化
- 数据倾斜
- Map和Reduce数设置不合理
- Map运行时间太长,导致Reduce等待过久
- 小文件过多
- 大量的不可分块的超大文件
- Spill次数过多
- Merge次数过多等
二、MapReduce优化方法
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
1、数据输入
1)合并小文件:在执行MR任务前将小文件进行合并,大量的小文件会产生大量的Map任务,增大Map任务装载次数,而任务的装载比较耗时,从而导致MR运行较慢。
2)采用CombineTextOutputFormat来作为输入,解决输入端大量小文件场景。
2、Map阶段
1)减少溢写(spill)次数:通过调整io.sort.mb及sort.spill.percent参数值,增大触发spill的内存上限,减少spill次数,从而减少磁盘IO。
2)减少合并(Merge)次数:通过调整io.sort.factor参数,增大Merge的文件数目,减少Merge的次数,从而缩短MR处理时间。
3)在Map之后,不影响业务的前提下,先进行Combine处理,减少IO。
3、Reduce阶段
1)合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致Map、Reduce任务间竞争资源,造成处理超时等错误。
2)设置Map、Reduce共存:调整slowstart.completedmaps参数,是Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
3)规避使用Reduce:因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
4、IO传输
1)采用数据压缩的方式,减少网络IO的时间。安装Snappy和Lzo压缩编码器。
2)使用SequenceFile二进制文件。
5、数据倾斜问题
1)数据倾斜现象
数据频率倾斜—某一个区域的数据量要远远大于其他区域。
数据大小倾斜—部分记录的大小远远大于平均值。
2)减少数据倾斜的方法
方法1:抽样和范围分区
可以通过对原始数据进行抽样得到结果集来预设分区边界值。
方法2:自定义分区
给予输出键的背景知识进行自定义分区。例如,如果Map输出键的单词来源于一本书。且其中某几个专业词汇较多。那么就可以自定义分区将这些专业词汇发送给固定的一部分Reduce实例。而将其他的都发送给剩余的Reduce实例。
方法3:Combine
使用Combine可以大量地减少数据倾斜。在可能的情况下,Combine的目的就是聚合并精简数据。
方法4:采用Map join,尽量避免Reduce join
6、常用的调优参数
1、资源相关参数
(1)以下参数是在用户自己的MR应用程序中配置就可以生效(mapred-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.map.memory.mb | 一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.reduce.memory.mb | 一个ReduceTask可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.map.cpu.vcores | 每个MapTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.cpu.vcores | 每个ReduceTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.shuffle.parallelcopies | 每个Reduce去Map中取数据的并行数。默认值是5 |
| mapreduce.reduce.shuffle.merge.percent | Buffer中的数据达到多少比例开始写入磁盘。默认值0.66 |
| mapreduce.reduce.shuffle.input.buffer.percent | Buffer大小占Reduce可用内存的比例。默认值0.7 |
| mapreduce.reduce.input.buffer.percent | 指定多少比例的内存用来存放Buffer中的数据,默认值是0.0 |
(2)应该在YARN启动之前就配置在服务器的配置文件中才能生效(yarn-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 给应用程序Container分配的最小内存,默认值:1024 |
| yarn.scheduler.maximum-allocation-mb | 给应用程序Container分配的最大内存,默认值:8192 |
| yarn.scheduler.minimum-allocation-vcores | 每个Container申请的最小CPU核数,默认值:1 |
| yarn.scheduler.maximum-allocation-vcores | 每个Container申请的最大CPU核数,默认值:32 |
| yarn.nodemanager.resource.memory-mb | 给Containers分配的最大物理内存,默认值:8192 |
(3)Shuffle性能优化的关键参数,应在YARN启动之前就配置好(mapred-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.task.io.sort.mb | Shuffle的环形缓冲区大小,默认100m |
| mapreduce.map.sort.spill.percent | 环形缓冲区溢出的阈值,默认80% |
2、容错相关参数(MapReduce性能优化)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.map.maxattempts | 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.reduce.maxattempts | 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.task.timeout | Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个Task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远Block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。 |
三、HDFS小文件优化方法
1、HDFS小文件弊端
HDFS上每个文件都要在NameNode上建立一个索引,这个索引的大小约为150byte,这样当小文件比较多的时候,就会产生很多的索引文件,一方面会大量占用NameNode的内存空间,另一方面就是索引文件过大使得索引速度变慢。
2、HDFS小文件解决方案
小文件的优化无非以下几种方式:
(1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
(2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
(3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。
1、Hadoop Archive
是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样就减少了NameNode的内存使用。
2、Sequence File
Sequence File由一系列的二进制key/value组成,如果key为文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
3、CombineFileInputFormat
CombineFileInputFormat是一种新的InputFormat,用于将多个文件合并成一个单独的Split,另外,它会考虑数据的存储位置。
4、开启JVM重用
对于大量小文件job,可以开启JVM重用会减少45%的运行时间。
JVM重用原理:一个Map运行在一个JVM上,开启重用的话,该Map在JVM上运行完毕后,JVM继续运行其他Map。
具体设置:mapreduce.job.jvm.numtasks值在10-20之间。
相关文章:
Hadoop企业优化)
大数据框架之Hadoop:MapReduce(六)Hadoop企业优化
一、MapReduce 跑的慢的原因 MapReduce程序效率的瓶颈在于两点: 1、计算机性能 CPU、内存、磁盘、网络 2、IO操作优化 数据倾斜Map和Reduce数设置不合理Map运行时间太长,导致Reduce等待过久小文件过多大量的不可分块的超大文件Spill次数过多Merge次…...

Spring File Storage的详细文档
快速入门配置pom.xml引入依赖<dependencies><!-- spring-file-storage 必须要引入 --><dependency><groupId>cn.xuyanwu</groupId><artifactId>spring-file-storage</artifactId><version>0.7.0</version></dependen…...

Java软件开发好学吗?学完好找工作吗?
互联网高速发展的当下,Java语言无处不在:手机APP、Java游戏、电脑应用,都有它的身影。作为最热门的开发语言之一,Java在编程圈的地位不可撼动。可是,听名字就很专业的样子。Java语言到底好学吗?刚入坑编程圈…...

【独家C】华为OD机试提供C语言题解 - 优秀学员统计
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明优秀…...

数据仓库、数据中台、数据湖都是什么?
相信很多人都在最近的招聘市场上看到过招聘要求里提到了数据仓库、数据中台,甚至还有数据湖,这些层出不穷的概念让人困扰。今天我就来跟大家讲一讲数据仓库、数据中台以及数据湖的概念及区别。 数据库 在了解数据仓库、数据中台以及数据湖之前ÿ…...

0099 MySQL02
1.简单查询 查询一个字段 select 字段名 from 表名; 查询多个字段,使用“,”隔开 select 字段名,字段名 from 表名; 查询所有字段 1.把每个字段都写上 select 字段名,字段名,字段名.. from 表名; 2.使用*(效率低,可读性差) select *…...

应急响应-ubuntu系统cpu飙高
这里写目录标题一、排查过程二、处置过程三、溯源总结一、排查过程 1、查看CPU使用情况 top -c2、查看异常进程的具体参数 ps -aux3、通过微步查询域名信息 4、查看异常进程的监听端口 netstat -anlpt5、查找服务器内的异常文件 ls cat run.sh cat mservice.sh6、查看脚本…...
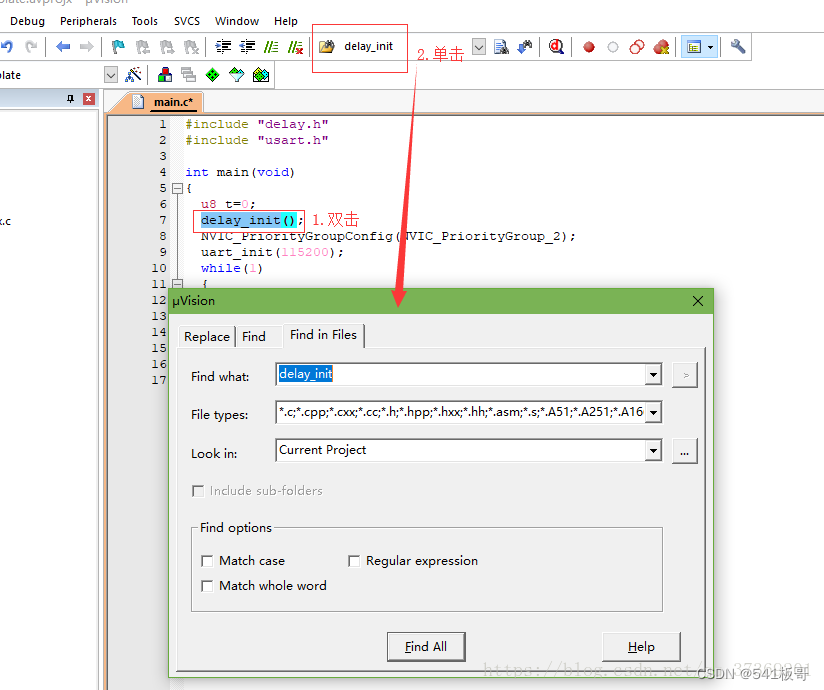
MDK软件使用技巧
本文主要汇总MDK软件使用技巧 一、字体大小及颜色修改 第一步点击工具栏的这个小扳手图标 进去后显示如下,先设置 Encoding 为:Chinese GB2312(Simplified),然后设置 Tab size 为:4 以更好的支持简体中文,否则&…...

3 333333
全部 答对 答错 单选题 1. 一个项目来取代目前公司的文件存储系统已经获批。外部供应商提供硬件,内部团队开发软件。这个团队是自组织的,由一般的专家组成。团队建议迭代地与供应商合作,但供应商表示拒绝。因此,只有软件将被迭代…...
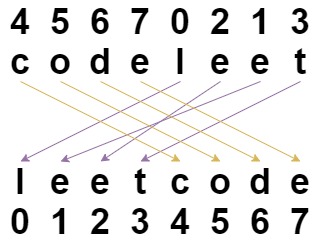
1528. 重新排列字符串
1528. 重新排列字符串https://leetcode.cn/problems/shuffle-string/ 难度简单52收藏分享切换为英文接收动态反馈 给你一个字符串 s 和一个 长度相同 的整数数组 indices 。 请你重新排列字符串 s ,其中第 i 个字符需要移动到 indices[i] 指示的位置。 返回重新…...
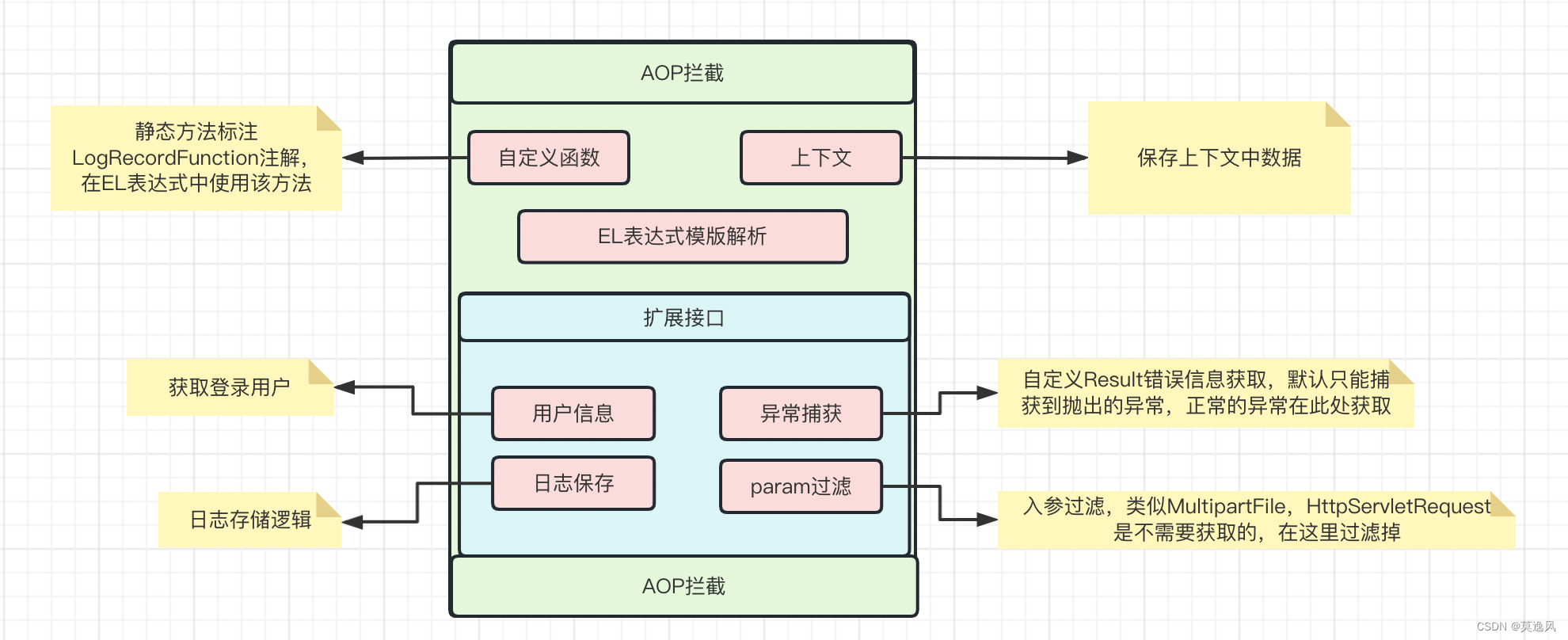
【8】【用户操作日志】操作日志SpringBootStarter
操作日志 此版本操作日志主要就是通过AOP拦截器实现的,整体主要分为AOP拦截器、自定义函数、日志上下文、扩展接口;组件提供了6个扩展点,自定义函数、日志上下文、用户信息获取,日志保存,自定义异常获取,入…...
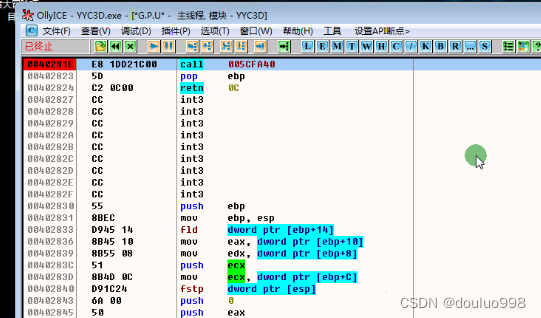
【游戏逆向】寻路函数隐藏检测点分析
案例: 某游戏出现调用寻路函数失败异常崩溃。 基本情况分析: 在刚登陆游戏的时候直接调用寻路函数崩溃。 手动寻路以后再调用寻路不崩溃。(排除了函数编写错误的可能) 猜测可能检测方法: 有某一个标志位(全局类型)在游戏刚登陆的时候没…...

【Zabbix实战之运维篇】Zabbix监控Docker容器配置方法
【Zabbix实战之运维篇】Zabbix监控Docker容器配置方法 一、检查Zabbix监控平台状态1.检查Zabbix各组件容器状态2.奸诈Zabbix-server状态二、下载监控模板1.进入Zabbix官网下载页面2.查看下载模板三、创建一个测试容器1.创建一个测试容器2.检查测试容器状态3.访问测试web服务四、…...

这款 Python 工具进行数据分析及数据可视化真的很棒啊
前言 大家好,今天我们以全国各地区衣食住行消费数据为例,来分析2022年中国统计年鉴数据,统计全国各地人民的消费地图,看看: 哪个省份的人最能花钱 哪个省份的人最舍得花钱 哪个省份的人最抠门 全国各地区人民在吃、穿…...

visual Studio Code常用快捷键
1、向上/向下移动代码行 alt 下箭头/上箭头 2、向上/向下复制一行代码 shiftalt 下箭头/上箭头 3、选定多个相同的单词 ctrl d 4、全局替换 ctrl h 5、快速定位到某一行 ctrl g 6、放大缩小整个编辑器界面 ctrl / - 7、添加多个光标 Ctrl Alt 上箭头/下箭头…...
十六进制转八进制)
基础(一)十六进制转八进制
试题 基础练习 十六进制转八进制 资源限制 内存限制:512.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 问题描述 给定n个十六进制正整数,输出它们对应的八进制数。输入格式 输入的第…...
梯度提升算法决策过程的逐步可视化
梯度提升算法是最常用的集成机器学习技术之一,该模型使用弱决策树序列来构建强学习器。这也是XGBoost和LightGBM模型的理论基础,所以在这篇文章中,我们将从头开始构建一个梯度增强模型并将其可视化。 梯度提升算法介绍 梯度提升算法&#x…...

Linux系统调用之文件属性操作函数
前言 如果,想要深入的学习Linux系统调用中access,chmod,chown,truncate这些有关于文件属性的操作函数,还是需要去自己阅读Linux系统中的帮助文档。 具体输入命令: man 2 access/chmod/chown/truncate 即可…...

VMware 安装 银河麒麟高级服务器操作系统 V10 + QT 开发环境搭建
下载并安装vmware 下载银河麒麟操作烯烃服务器版v10的镜像文件从官网下载,因为是x86的电脑芯片,选择AMD64版,即vmare 安装麒麟操作系统注意事项:安装位置选择自动分区网络和主机名设置打开网络,ip4就不用再设置了创建一…...

2023年疫情开放,国内程序员薪资涨了还是跌了?大数据告诉你答案
自从疫情开放,国内各个行业都开始有复苏的迹象,尤其是旅游行业更是空前暴涨,那么互联网行业如何? 有人说今年好找工作多了,有人说依然是内卷得一塌糊涂,那么今年开春以来,各个岗位的程序员工资…...
从基础到进阶:全面解析与实战指南)
金三银四这波我就先上车了兄弟们,大模型(LLMs)从基础到进阶:全面解析与实战指南
本文全面解析了大模型(LLMs)的基础、进阶和微调面,涵盖了主流开源模型体系、prefix LM与causal LM的区别、涌现能力的原因、大模型LLM架构、LLMs复读机问题及其缓解方法、不同模型的选择场景、专业领域模型需求、处理长文本的方法、全参数微调…...

OpCore Simplify革新:4步实现OpenCore EFI配置的极简实践
OpCore Simplify革新:4步实现OpenCore EFI配置的极简实践 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是否曾在普通PC上安装macOS时&…...
)
PyQt5实战:手把手教你打造PPT风格的颜色+线型组合下拉框(附完整源码)
PyQt5高级控件开发:打造Office风格的颜色与线型组合选择器 在桌面应用开发中,提供直观、专业的样式选择控件是提升用户体验的关键。本文将深入探讨如何利用PyQt5构建一个功能完备的Office风格组合选择器,集成颜色选择、线型设置和粗细调整等核…...

Fun-ASR参数配置攻略:热词列表、目标语言,这样设置准确率最高
Fun-ASR参数配置攻略:热词列表、目标语言,这样设置准确率最高 1. 为什么参数配置如此重要? 语音识别系统的准确率往往取决于两个关键因素:模型本身的性能和使用者的参数配置。Fun-ASR作为钉钉与通义实验室联合推出的企业级语音识别…...

COMSOL声子晶体复能带模型与PDE模块:声学黑洞复能带模型及实虚能带绘制与二维结构分析
comsol声子晶体复能带模型 PDE模块 声学黑洞 复能带模型 实能带与虚能带的绘制 参考论文 前两个是论文图,后四个是模型及结果图。 可根据模型设置,进行其他二维结构的分析复能带这玩意儿搞声子晶体的肯定不陌生,但用COMSOL PDE模块手搓模型…...
)
别再死记硬背了!用Multisim仿真带你玩转计数器与数据选择器(附FPGA引脚配置)
用Multisim仿真与FPGA实战:计数器与数据选择器的设计艺术 数字电路课程中那些抽象的概念,是否曾让你感到困惑?模5计数器、序列信号发生器这些名词听起来高深莫测,但通过Multisim仿真和FPGA实战,你会发现它们其实可以很…...

浏览器插件开发:OpenClaw+GLM-4.7-Flash增强网页交互
浏览器插件开发:OpenClawGLM-4.7-Flash增强网页交互 1. 为什么需要智能化的浏览器插件? 在日常网页浏览中,我们经常会遇到这样的场景:看到一篇长文想快速提取核心观点,或者需要将网页内容与本地文件进行联动处理。传…...

RPCS3终极指南:在电脑上完美运行PS3游戏的完整教程
RPCS3终极指南:在电脑上完美运行PS3游戏的完整教程 【免费下载链接】rpcs3 PS3 emulator/debugger 项目地址: https://gitcode.com/GitHub_Trending/rp/rpcs3 还在为无法重温经典PS3游戏而烦恼吗?RPCS3作为全球领先的免费开源PlayStation 3模拟器…...

情感漏洞经纪:倒卖AI崩溃瞬间年入百万
新兴暴利职业的崛起在人工智能技术高速发展的今天,一种名为“情感漏洞经纪”的灰色产业悄然兴起,从业者通过倒卖AI系统崩溃瞬间的数据年入百万。这些经纪人专门捕捉AI模型在情感交互中的故障时刻——如系统宕机前的“遗言”、未完成的情感回应或异常输出…...
)
避坑指南:MTK DRM屏兼容中,那些容易让你“点不亮”的硬件与配置细节(附TP复位脚案例)
MTK DRM屏兼容开发实战:从硬件引脚到驱动配置的深度避坑指南 在MTK平台的多屏兼容开发中,工程师们常常会遇到屏幕"点不亮"的棘手问题。这类问题往往源于硬件连接、引脚配置或驱动编译选项中的细微疏忽。本文将结合真实案例,深入剖…...