imgaug库指南(28):从入门到精通的【图像增强】之旅(万字长文)
引言
在深度学习和计算机视觉的世界里,数据是模型训练的基石,其质量与数量直接影响着模型的性能。然而,获取大量高质量的标注数据往往需要耗费大量的时间和资源。正因如此,数据增强技术应运而生,成为了解决这一问题的关键所在。而imgaug,作为一个功能强大的图像增强库,为我们提供了简便且高效的方法来扩充数据集。本系列博客将带您深入了解如何运用imgaug进行图像增强,助您在深度学习的道路上更进一步。我们将从基础概念讲起,逐步引导您掌握各种变换方法,以及如何根据实际需求定制变换序列。让我们一起深入了解这个强大的工具,探索更多可能性,共同推动深度学习的发展。
前期回顾
| 链接 | 主要内容 |
|---|---|
| imgaug库指南(11):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— 加性高斯噪声(AdditiveGaussianNoise方法) |
| imgaug库指南(12):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— 加性拉普拉斯噪声(AdditiveLaplaceNoise方法) |
| imgaug库指南(13):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— 加性泊松噪声(AdditivePoissonNoise方法) |
| imgaug库指南(14):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— 乘法运算(Multiply方法) |
| imgaug库指南(15):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— 乘法运算(MultiplyElementwise方法) |
| imgaug库指南(16):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— Cutout方法 |
| imgaug库指南(17):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— Dropout方法 |
| imgaug库指南(18):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— CoarseDropout方法 |
| imgaug库指南(19):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— Dropout2D方法 |
| imgaug库指南(20):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— TotalDropout方法 |
| imgaug库指南(21):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— ReplaceElementwise方法 |
| imgaug库指南(22):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— ImpulseNoise方法 |
| imgaug库指南(23):从入门到精通的【图像增强】之旅 | 详细介绍了imgaug库的数据增强方法 —— SaltAndPepper方法 |
| imgaug库指南(24):从入门到精通的【图像增强】之旅(干货!万字长文!) | 详细介绍了imgaug库的数据增强方法 —— CoarseSaltAndPepper方法 |
在本博客中,我们将向您详细介绍imgaug库的数据增强方法 —— CoarsePepper方法。
CoarsePepper方法
功能介绍
iaa.CoarsePepper是imgaug库中另一个用于添加黑椒噪声的方法。与iaa.Pepper相比,iaa.CoarsePepper添加的噪声颗粒更大,通常用于模拟较为粗糙的噪声模式。以下是三个具体的使用场景举例:
- 图像分割和目标检测任务:在这些任务中,
iaa.CoarsePepper可以帮助模拟图像中的粗糙噪声模式,从而使得模型在训练过程中更加鲁棒。通过将这种噪声模式添加到训练数据中,模型将学会在面对类似噪声的输入时更好地处理和识别目标。 - 图像修复和增强任务:在图像修复和增强的应用中,
iaa.CoarsePepper可以用来模拟图像中可能存在的较大噪声区域。通过将这种噪声模式添加到图像中,然后使用适当的算法进行修复或增强,可以训练出更强大的图像处理系统。 - 深度学习模型的预处理阶段:在使用深度学习模型进行图像处理之前,通常需要进行数据预处理。
iaa.CoarsePepper可以用于这一阶段,以增加训练数据的多样性,并帮助模型更好地泛化到实际应用中可能遇到的噪声模式。通过在训练过程中引入这种噪声模式,模型将学会更好地处理实际应用中的噪声问题。
语法
import imgaug.augmenters as iaa
aug = iaa.CoarsePepper(p=(0.02, 0.1), size_px=None, size_percent=None, per_channel=False, min_size=3, seed=None, name=None, random_state='deprecated', deterministic='deprecated')
以下是对iaa.CoarsePepper方法中各个参数的详细介绍:
-
p:
- 类型:可以是浮点数|浮点数元组|浮点数列表。
- 描述:将像素替换为黑椒噪声的概率。
- 若
p为浮点数,则表示将像素替换为黑椒噪声的概率; - 若
p为元组(a, b),则将像素替换为黑椒噪声的概率为从区间[a, b]中采样的随机数; - 若
p为列表,则将像素替换为黑椒噪声的概率为从列表中随机采样的浮点数;
- 若
-
size_px:- 类型:可以是整数|整数元组|整数列表。
- 描述:定义每个噪声方块的大小。
- 若
size_px为整数,例如size_px为3,且RGB图像的宽和高都为300。则每个噪声方块大小为(H/size_px,W/size_px), 即(100, 100) ==> 将RGB图像分成9宫格, 每个宫格形状(100, 100), 根据参数p的大小确定有多少个宫格会被替换为黑椒噪声方块; - 若
size_px为元组(a, b),则每个噪声方块大小为(H/size,W/size),size为从区间[a, b]中采样的随机数; - 若
size_px为列表,则每个噪声方块大小为(H/size,W/size),size为从列表中随机采样的数;
- 若
- 注意:若
size_px为None,则size_percent参数必须设置。
-
size_percent:- 类型:可以是浮点数|浮点数元组|浮点数列表。
- 描述:定义每个噪声方块的大小。
- 若
size_percent为浮点数0.02,则每个噪声方块大小为(1/size_percent,1/size_percent), 即(50, 50); - 若
size_percent为元组(a, b),则每个噪声方块大小为(1/size,1/size),size为从区间[a, b]中采样的随机数; - 若
size_percent为列表,则每个噪声方块大小为(1/size,1/size),size为从列表中随机采样的数;
- 若
- 注意:若
size_percent为None,则size_px参数必须设置。
-
per_channel:
- 类型:布尔值(
True或False)|浮点数。 - 描述:
- 若
per_channel为True,则RGB图像的每个像素位置所对应的三个通道像素值可能不会同时替换为黑椒噪声方块 ==> RGB图像会出现彩色失真; - 若
per_channel为False,则RGB图像的每个像素位置所对应的三个通道像素值会同时替换为黑椒噪声方块; - 若
per_channel为区间[0,1]的浮点数,假设per_channel=0.6,那么对于60%的图像,per_channel为True;对于剩余的40%的图像,per_channel为False;
- 若
- 类型:布尔值(
-
min_size:
- 类型:整数
- 描述:考虑到错误地设置
size_percent或size_px参数会导致整个图像都被替换成黑椒噪声,因此通过设置min_size来确保最大的噪声方块不至于太大。
-
seed:
- 类型:整数|
None。 - 描述:用于设置随机数生成器的种子。如果提供了种子,则结果将是可重复的。默认值为
None,表示随机数生成器将使用随机种子。
- 类型:整数|
-
name:
- 类型:字符串或
None。 - 描述:用于标识增强器的名称。如果提供了名称,则可以在日志和可视化中识别该增强器。默认值为
None,表示增强器将没有名称。
- 类型:字符串或
示例代码
- 使用不同的p
import cv2
import imgaug.augmenters as iaa
import matplotlib.pyplot as plt# 读取图像
img_path = r"D:\python_project\lena.png"
img = cv2.imread(img_path)
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 创建数据增强器
aug1 = iaa.CoarsePepper(p=0.2, size_px=3, size_percent=None, per_channel=False, min_size=3, seed=0)
aug2 = iaa.CoarsePepper(p=0.5, size_px=3, size_percent=None, per_channel=False, min_size=3, seed=0)
aug3 = iaa.CoarsePepper(p=0.8, size_px=3, size_percent=None, per_channel=False, min_size=3, seed=0)# 对图像进行数据增强
Augmented_image1 = aug1(image=image)
Augmented_image2 = aug2(image=image)
Augmented_image3 = aug3(image=image)# 展示原始图像和数据增强后的图像
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
axes[0][0].imshow(image)
axes[0][0].set_title("Original Image")
axes[0][1].imshow(Augmented_image1)
axes[0][1].set_title("Augmented Image1")
axes[1][0].imshow(Augmented_image2)
axes[1][0].set_title("Augmented Image2")
axes[1][1].imshow(Augmented_image3)
axes[1][1].set_title("Augmented Image3")
plt.show()
运行结果如下:

可以从图1看到:
- 当p参数设置的越接近1.0时,图像增强后的新图像将会出现更多的黑椒噪声方块。
- 由于
size_px为3,且RGB图像的宽和高都接近300,因此每个黑椒噪声方块的尺寸都接近(100, 100) ==> 先把RGB图像分为9宫格,即9个相同大小的区域,再根据参数p确定将多少个区域替换为黑椒噪声方块。
- 使用不同的size_px
import cv2
import imgaug.augmenters as iaa
import matplotlib.pyplot as plt# 读取图像
img_path = r"D:\python_project\lena.png"
img = cv2.imread(img_path)
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 创建数据增强器
aug1 = iaa.CoarsePepper(p=0.5, size_px=3, size_percent=None, per_channel=False, min_size=3, seed=0)
aug2 = iaa.CoarsePepper(p=0.5, size_px=6, size_percent=None, per_channel=False, min_size=3, seed=0)
aug3 = iaa.CoarsePepper(p=0.5, size_px=10, size_percent=None, per_channel=False, min_size=3, seed=0)# 对图像进行数据增强
Augmented_image1 = aug1(image=image)
Augmented_image2 = aug2(image=image)
Augmented_image3 = aug3(image=image)# 展示原始图像和数据增强后的图像
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
axes[0][0].imshow(image)
axes[0][0].set_title("Original Image")
axes[0][1].imshow(Augmented_image1)
axes[0][1].set_title("Augmented Image1")
axes[1][0].imshow(Augmented_image2)
axes[1][0].set_title("Augmented Image2")
axes[1][1].imshow(Augmented_image3)
axes[1][1].set_title("Augmented Image3")
plt.show()
运行结果如下:

可以从图2看到:
- 当size_px参数设置的越大时,增强后的新图像的每个黑椒噪声方块的尺寸会越小。
- 当
size_px=3时,由于RGB图像的宽和高都接近300,因此每个黑椒噪声方块的尺寸都接近(100, 100) ==> 先把RGB图像分为9宫格,即9个相同大小的区域,再根据参数p确定将多少个区域替换为黑椒噪声方块。 - 当
size_px=6时,由于RGB图像的宽和高都接近300,因此每个黑椒噪声方块的尺寸都接近(50, 50) ==> 先把RGB图像分为36宫格,即36个相同大小的区域,再根据参数p确定将多少个区域替换为黑椒噪声方块。 - 当
size_px=10时,由于RGB图像的宽和高都接近300,因此每个黑椒噪声方块的尺寸都接近(30, 30) ==> 先把RGB图像分为100宫格,即100个相同大小的区域,再根据参数p确定将多少个区域替换为黑椒噪声方块。
- 当
- 使用不同的size_percent
import cv2
import imgaug.augmenters as iaa
import matplotlib.pyplot as plt# 读取图像
img_path = r"D:\python_project\lena.png"
img = cv2.imread(img_path)
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 创建数据增强器
aug1 = iaa.CoarsePepper(p=0.5, size_px=None, size_percent=0.02, per_channel=False, min_size=3, seed=0)
aug2 = iaa.CoarsePepper(p=0.5, size_px=None, size_percent=0.05, per_channel=False, min_size=3, seed=0)
aug3 = iaa.CoarsePepper(p=0.5, size_px=None, size_percent=0.1, per_channel=False, min_size=3, seed=0)# 对图像进行数据增强
Augmented_image1 = aug1(image=image)
Augmented_image2 = aug2(image=image)
Augmented_image3 = aug3(image=image)# 展示原始图像和数据增强后的图像
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
axes[0][0].imshow(image)
axes[0][0].set_title("Original Image")
axes[0][1].imshow(Augmented_image1)
axes[0][1].set_title("Augmented Image1")
axes[1][0].imshow(Augmented_image2)
axes[1][0].set_title("Augmented Image2")
axes[1][1].imshow(Augmented_image3)
axes[1][1].set_title("Augmented Image3")
plt.show()
运行结果如下:

可以从图3看到:
- 当size_percent参数设置的越大时,增强后的新图像的每个黑椒噪声方块的尺寸会越小(size_percent和噪声方块尺寸的关系见size_percent的参数描述)。
- 当
size_percent=0.02时,每个黑椒噪声方块的尺寸都接近(50, 50),根据参数p确定将多少个区域替换为黑椒噪声方块。 - 当
size_percent=0.05时,每个黑椒噪声方块的尺寸都接近(20, 20),根据参数p确定将多少个区域替换为黑椒噪声方块。 - 当
size_percent=0.1时,每个黑椒噪声方块的尺寸都接近(10, 10),根据参数p确定将多少个区域替换为黑椒噪声方块。
- 当
- per_channel设置为True
import cv2
import imgaug.augmenters as iaa
import matplotlib.pyplot as plt# 读取图像
img_path = r"D:\python_project\lena.png"
img = cv2.imread(img_path)
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 创建数据增强器
aug1 = iaa.CoarsePepper(p=0.5, size_px=None, size_percent=0.02, per_channel=True, min_size=3, seed=0)
aug2 = iaa.CoarsePepper(p=0.5, size_px=None, size_percent=0.05, per_channel=True, min_size=3, seed=0)
aug3 = iaa.CoarsePepper(p=0.5, size_px=None, size_percent=0.1, per_channel=True, min_size=3, seed=0)# 对图像进行数据增强
Augmented_image1 = aug1(image=image)
Augmented_image2 = aug2(image=image)
Augmented_image3 = aug3(image=image)# 展示原始图像和数据增强后的图像
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
axes[0][0].imshow(image)
axes[0][0].set_title("Original Image")
axes[0][1].imshow(Augmented_image1)
axes[0][1].set_title("Augmented Image1")
axes[1][0].imshow(Augmented_image2)
axes[1][0].set_title("Augmented Image2")
axes[1][1].imshow(Augmented_image3)
axes[1][1].set_title("Augmented Image3")
plt.show()
运行结果如下:

可以从图4看到:图像增强后的新图像将会出现彩色失真(不再是黑色的黑椒噪声)。
原因:当per_channel设置为True时,RGB的三个通道会独立进行处理,不一定能够同时替换为黑椒噪声块。
注意事项
- p的选择:
p参数决定了一副图像黑椒噪声的强度。较大的p值可能会导致新图像出现严重失真。需要根据具体场景选择合适的p; - size_px的选择:
size_px参数决定了黑椒噪声块的大小。错误地设置size_px值可能会导致原图完全被替换成黑椒噪声图像。需要根据具体场景选择合适的size_px; - size_percent的选择:
size_percent参数决定了黑椒噪声块的大小。错误地设置size_percent值也可能会导致原图完全被替换成黑椒噪声图像。需要根据具体场景选择合适的size_percent; - size_px和size_percent:若
size_percent为None,则size_px参数必须设置;若size_px为None,则size_percen参数必须设置; - **随机性和可复现性(seed)**:如果需要可复现的结果,应该设置seed参数为一个固定的整数值。这将初始化随机数生成器,使得每次运行增强操作时都能得到相同的结果;
- 与其他增强操作的组合:
iaa.CoarsePepper可以与其他imgaug增强操作组合使用,以创建更复杂的增强管道。在组合多个增强操作时,应注意它们的顺序,因为不同的顺序可能会导致不同的最终效果。 - min_size的设置:合理地设置
min_size可以预防因为错误地设置size_px参数或者size_percent参数导致原图被完全替换为黑椒噪声的问题。 - 谨慎设置per_channel参数:当per_channel设置为True时,RGB的三个通道会独立进行处理,导致出现彩色噪声块,并非常规的黑白黑椒噪声块。
总结
iaa.CoarsePepper是imgaug库中的一个图像增强方法,用于向图像中添加粗糙的黑椒噪声。相比于iaa.Pepper,它的噪声颗粒更大,能够模拟更为粗糙的噪声模式。以下是该方法的总结:
-
作用:通过添加大范围的噪声块,模拟图像在恶劣条件下的噪声模式,或者用于创造特殊的艺术效果。
-
参数:
- p:定义了像素被替换为椒(黑色)的概率。
- size_px:可用于定义噪声块的大小。
- size_percent:可用于定义噪声块的大小。
- per_channel:决定是否对每个通道独立地应用噪声。
- min_size:定义噪声块的最小大小。
- seed:用于设置随机数生成器的种子,以确保结果的可重复性。
- name:增强器的名称。
-
用途:
- 增强大图像的视觉效果:在处理大图像时,通过添加大范围的噪声块来增强图像的细节和纹理。
- 模拟恶劣天气条件下的图像:模拟由于恶劣天气(如雾、沙尘暴等)导致的较大范围的噪声干扰。
- 创造艺术效果:通过控制噪声的大小和密度,在图像中创造特殊的艺术效果。
小结
imgaug是一个顶级的图像增强库,具备非常多的数据增强方法。它为你提供创造丰富多样的训练数据的机会,从而显著提升深度学习模型的性能。通过精心定制变换序列和参数,你能灵活应对各类应用场景,使我们在处理计算机视觉的数据增强问题时游刃有余。随着深度学习的持续发展,imgaug将在未来持续展现其不可或缺的价值。因此,明智之举是将imgaug纳入你的数据增强工具箱,为你的项目带来更多可能性。
参考链接
结尾
亲爱的读者,首先感谢您抽出宝贵的时间来阅读我们的博客。我们真诚地欢迎您留下评论和意见,因为这对我们来说意义非凡。
俗话说,当局者迷,旁观者清。您的客观视角对于我们发现博文的不足、提升内容质量起着不可替代的作用。
如果您觉得我们的博文给您带来了启发,那么,希望您能为我们点个免费的赞/关注,您的支持和鼓励是我们持续创作的动力。
请放心,我们会持续努力创作,并不断优化博文质量,只为给您带来更佳的阅读体验。
再次感谢您的阅读,愿我们共同成长,共享智慧的果实!
相关文章:
imgaug库指南(28):从入门到精通的【图像增强】之旅(万字长文)
引言 在深度学习和计算机视觉的世界里,数据是模型训练的基石,其质量与数量直接影响着模型的性能。然而,获取大量高质量的标注数据往往需要耗费大量的时间和资源。正因如此,数据增强技术应运而生,成为了解决这一问题的…...
精确掌控并发:漏桶算法在分布式环境下并发流量控制的设计与实现
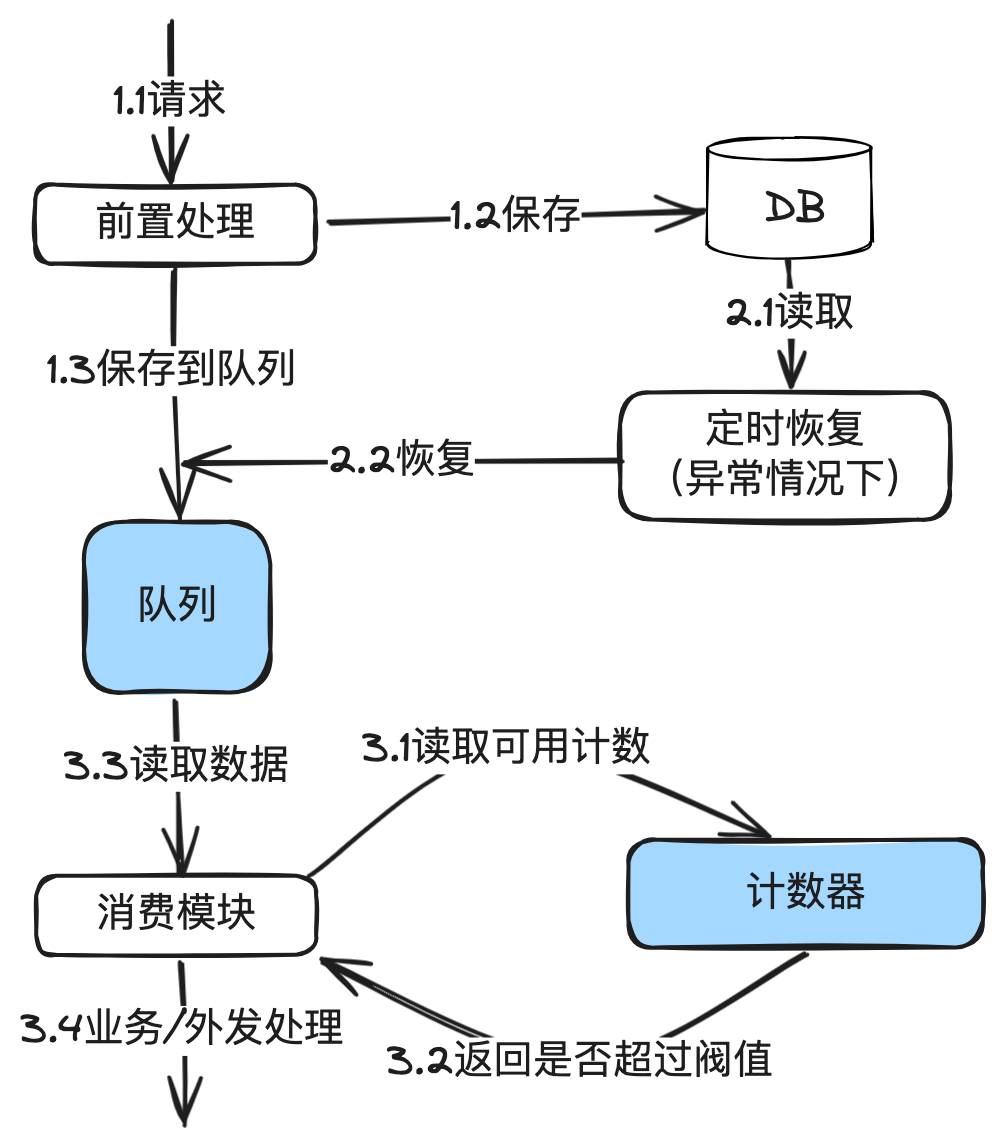
这是《百图解码支付系统设计与实现》专栏系列文章中的第(16)篇,也是流量控制系列的第(3)篇。点击上方关注,深入了解支付系统的方方面面。 本篇重点讲清楚漏桶原理,在支付系统的应用场景&#x…...

【Redis】Redis面试热点
Redis 集群有哪些方案? 主从复制:解决了高并发问题 哨兵模式:解决了高并发,高可用问题 分片集群:解决了海量数据存储,高并发写的问题 主从复制 图示: 主从复制:单节点 Redis 并发…...
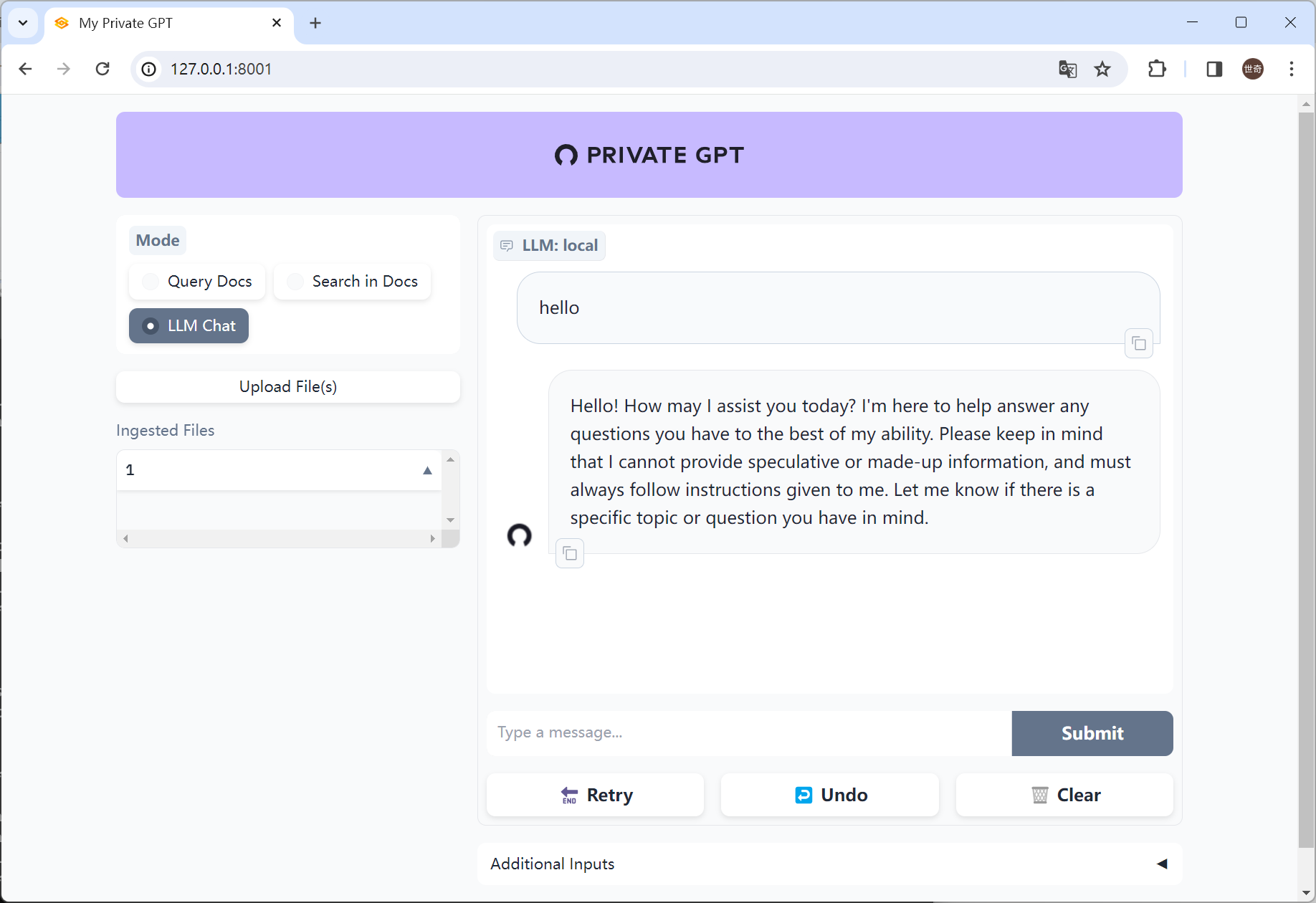
构建中国人自己的私人GPT-有道GPT
创作不易,请大家多鼓励支持。 在现实生活中,很多人的资料是不愿意公布在互联网上的,但是我们又要使用人工智能的能力帮我们处理文件、做决策、执行命令那怎么办呢?于是我们构建自己或公司的私人GPT变得非常重要。 先看效果 一、…...
)
data = self._data_queue.get(timeout=timeout)
目录 解决方法 freeze_support 解决方法 opencv 升级 方法3 OMP_NUM_THREADS: 报错: data self._data_queue.get(timeouttimeout) 解决方法 freeze_support data self._data_queue.get(timeouttimeout)RuntimeError: DataLoader worker (pid(s)…...
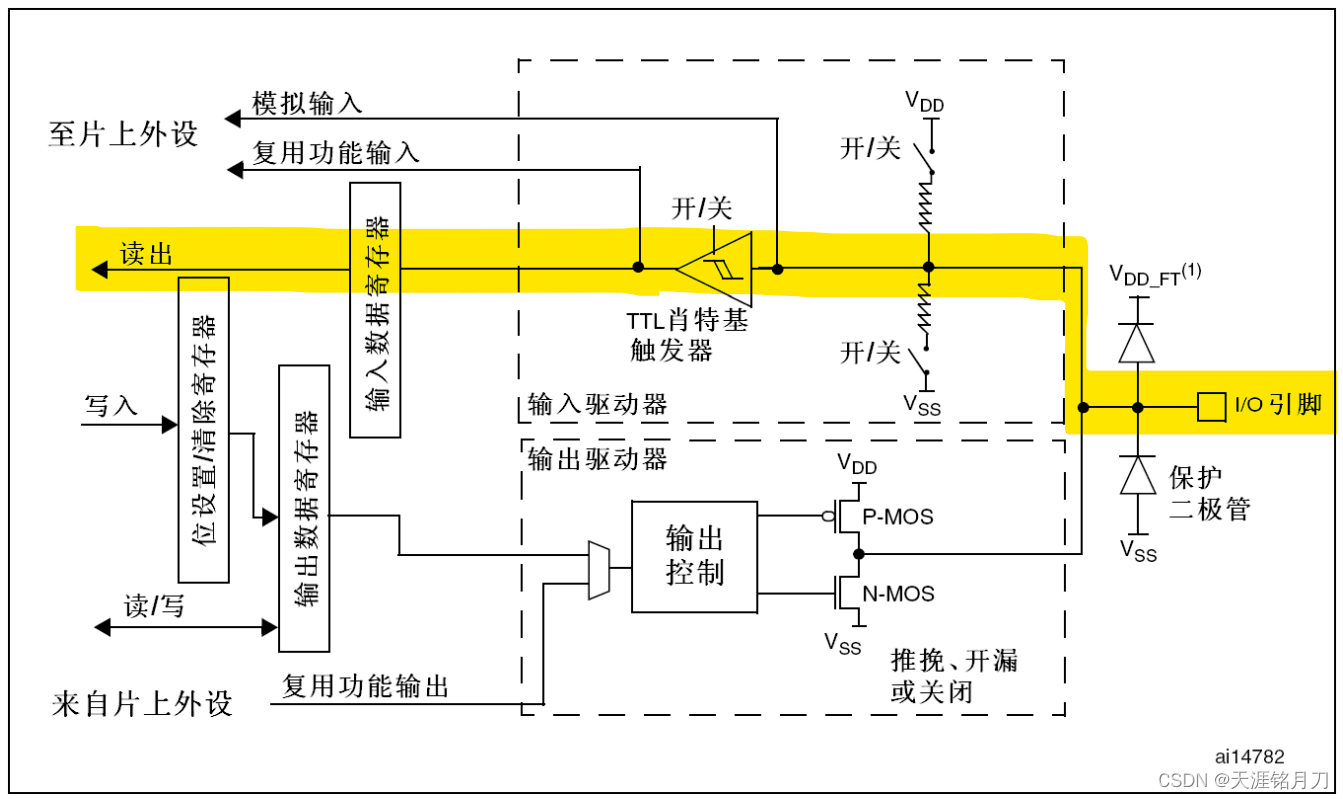
推挽输出、开漏输出、上拉输入、下拉输入、浮空输入。
一、推挽输出 推挽输出的内部电路大概如上图中黄色部分,输出控制内有反相器,由一个P-MOS和一个N-MOS组合而成,同一时间只有一个管子能够进行导通。 当写入1时,经过反向器后为0,P-MOS导通,N-MOS截至…...
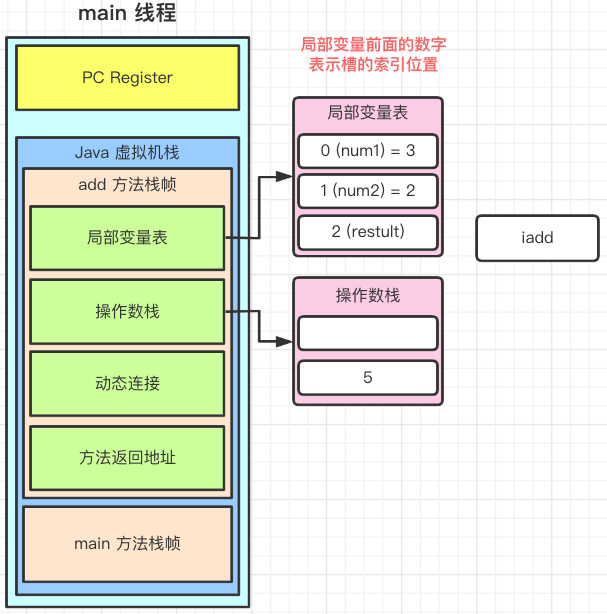
【Java JVM】栈帧
执行引擎是 Java 虚拟机核心的组成部分之一。 在《Java虚拟机规范》中制定了 Java 虚拟机字节码执行引擎的概念模型, 这个概念模型成为各大发行商的 Java 虚拟机执行引擎的统一外观 (Facade)。 不同的虚拟机的实现中, 通常会有 解释执行 (通过解释器执行)编译执行 (通过即时编…...
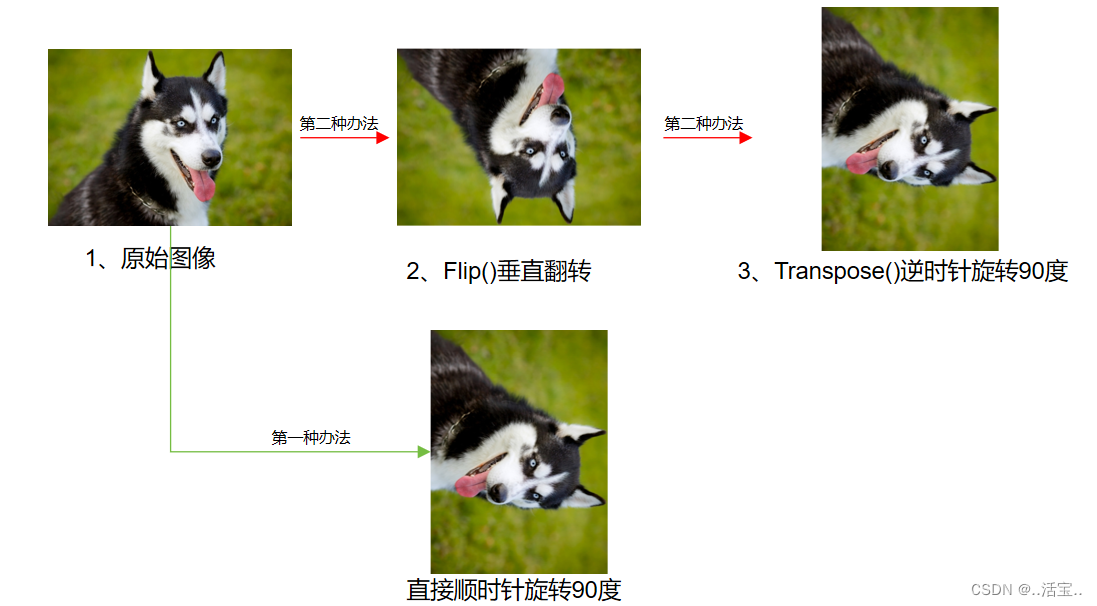
【Emgu CV教程】5.4、几何变换之图像翻转
今天讲解的两个函数,可以实现以下样式的翻转。 水平翻转:将图像沿Y轴(图像最左侧垂直边缘)翻转的操作。原始图像中位于左侧的内容将移动到目标图像的右侧,原始图像中位于右侧的内容将移动到目标图像的左侧。垂直翻转:将图像沿X轴…...

2024年AMC8历年真题练一练和答案详解(10),以及全真模拟题
六分成长继续为您分享AMC8历年真题,最后两天通过高质量的真题来体会快速思考、做对题目的策略。 题目从575道在线题库(来自于往年真题)中抽取5道题,每道题目均会标记出自年份和当年度的序号,并附上详细解析。【使用六…...

echarts业务中常用属性设置记录
1.legend计算占比 //在data中定义两个字段 total:0, znum:0 //计算上面两个值 this.data.forEach(val > this.total parseInt(val.value)); for (let i 0; i < nv.length; i) {if (i ! nv.length - 1) {this.znum this.znum Number(parseFloat((nv[i].value / this.t…...
Ubuntu 22.04 安装prometheus
服务器监控和报警软件有很多,为什么我们会选择Prometheus而不是其他软件呢? 因为它有以下优点: 自带简易web监控页面,用户可以很方便地查看监控数据和使用仪表盘。能实时收集数据并根据自定义警报规则推送告警;具有丰…...

Django的模板语言
文章目录 模板语法变量标签过滤器注释 组件引擎模板上下文加载器上下文处理器 模板引擎的支持配置用法引擎内置后端 模板 作为一个网络框架,Django 需要一种方便的方式来动态生成 HTML。最常见的方法是依靠模板。一个模板包含了所需 HTML 输出的静态部分࿰…...

为什么安卓逆向手机要root
安卓逆向工程是指对安卓应用程序进行研究和分析,以了解其内部工作原理、提取资源、修改应用行为、发现漏洞等。在某些情况下,为了进行逆向分析,需要对手机进行Root。 以下是一些安卓逆向中可能需要Root的原因: 获得完全访问权限…...
整合junit与热部署
整合junit <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>2.7.0</version></dependency> 测试类上添加SpringBootTest 如: 注意测试类的…...

C++面试宝典第21题:字符串解码
题目 给定一个经过编码的字符串,返回其解码后的字符串。具体的编码规则为:k[encoded_string],表示方括号内部的encoded_string正好重复k次。注意:k保证为正整数;encoded_string只包含大小写字母,不包含空格和数字;方括号确定是匹配的,且可以嵌套。 示例: 编码字符串为…...

WXUI 基于uni-app x开发的高性能混合UI库
uni-app x 是什么? uni-app x,是下一代 uni-app,是一个跨平台应用开发引擎。 uni-app x 没有使用js和webview,它基于 uts 语言。在App端,uts在iOS编译为swift、在Android编译为kotlin,完全达到了原生应用…...

P9840 [ICPC2021 Nanjing R] Oops, It‘s Yesterday Twice More题解
[ICPC2021 Nanjing R] Oops, It’s Yesterday Twice More 传送门 题面翻译 有一张 n n n\times n nn 的网格图,每个格子上都有一只袋鼠。对于一只在 ( i , j ) (i,j) (i,j) 的袋鼠,有下面四个按钮: 按钮 U:如果 i > 1 …...

OceanBase与MySQL兼容性对比
OB针对于高并发和大数据更有优势,公司的dba让我们把数据从mysql迁移到OceanBase了,这里记录一下OceanBase的MySQL模式。 OceanBase的MySQL模式兼容MySQL5.7的绝大部分功能和语法,兼容MySQL5.7版本的全量以及8.0版本的部分JSON函数。 暂不支持的功能: O…...
【linux】visudo
碎碎念 visudo命令是用来修改一个叫做 /etc/sudoers 的文件的,用来设置哪些 用户 和 组 可以使用sudo命令。并且使用visudo而不是使用 vi /etc/sudoers 的原因在于:visudo自带了检查功能,可以判断是否存在语法问题,所以更加安全 …...
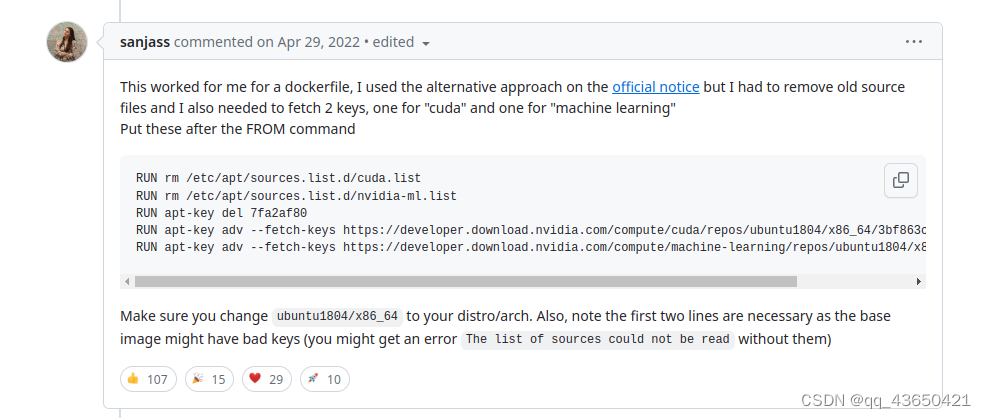
Nvidia-docker的基础使用方法
安装: 安装nvidia-docker: distribution$(. /etc/os-release;echo $ID$VERSION_ID)curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.l…...

用一块老芯片玩转计数器:手把手教你用74390与非门搭一个24小时制时钟电路
用一块老芯片玩转计数器:手把手教你用74390与非门搭一个24小时制时钟电路 记得大学时第一次在实验室看到LED数字管跳动的那种兴奋感吗?那种从抽象理论到具象显示的魔法时刻,正是电子设计的魅力所在。今天我们就用上世纪70年代诞生的74390这块…...

Open WebUI企业级部署指南:全功能AI平台架构与生产环境实践
Open WebUI企业级部署指南:全功能AI平台架构与生产环境实践 【免费下载链接】open-webui User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 项目地址: https://gitcode.com/GitHub_Trending/op/open-webui Open WebUI是一个功能强大的自托管A…...

FModel终极指南:3步快速掌握游戏资源提取与创作应用
FModel终极指南:3步快速掌握游戏资源提取与创作应用 【免费下载链接】FModel Unreal Engine Archives Explorer 项目地址: https://gitcode.com/gh_mirrors/fm/FModel 你是否曾想过提取游戏中的精美模型、纹理和音频,用于自己的创作项目ÿ…...

基于EM9283与FPGA的工业便携式WiFi数据终端设计实战
1. 项目概述:一个工业现场的便携式WiFi数据终端在工业现场,数据采集与无线传输的需求无处不在,但环境往往复杂多变:布线困难、设备需要移动、供电不便。传统的方案要么是拖着长长的线缆,要么是依赖工控机加外置模块&am…...

别再让FFT精度拖后腿了!手把手教你用三点插值法把频率估计误差降到最低
别再让FFT精度拖后腿了!手把手教你用三点插值法把频率估计误差降到最低 在音频调谐器里校准乐器音高时,工程师发现440Hz的标准音高在1024点FFT中总是显示为439.2Hz;5G基站接收端解调时,载波频率的微小偏移导致误码率飙升ÿ…...

ARGUS:视觉中心化多模态推理框架,实现像素级可验证Chain-of-Thought
1. 项目概述:这不是又一个“多模态大模型”,而是一次视觉推理范式的重新校准ARGUS这个名字,乍看像某个军事侦察系统代号,其实它精准指向了当前多模态AI领域最棘手的痛点——视觉信息在推理链中长期处于“失语”状态。你肯定见过这…...
:键入模式——在桌面上直接打字讲解的最佳实践)
《Sysinternals实战指南》ZoomIt 学习笔记(11.10):键入模式——在桌面上直接打字讲解的最佳实践
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

S200驱动器报A1489故障
安全配置未受保护A01637报警处理方法(西门子S200驱动器UMAC详细配置) https://rxxw-control.blog.csdn.net/article/details/157173145?spm=1011.2415.3001.5331https://rxxw-control.blog.csdn.net/article/details/157173145?spm=1011.2415.3001.5331 1、连接驱动器...

美股软件股反弹:AI 重塑软件未来,谁能成为时代赢家?
美股软件股遭遇“集体误杀”去年 10 月底开始,美股软件股经历罕见“集体误杀”。以软件 ETF——IGV 为代表,软件板块从高位显著回撤,跌幅接近 40%。曾经的高质量成长资产软件公司,沦为 AI 浪潮下的“旧世界遗产”。恐慌源于 DeepS…...

Windows热键冲突终极指南:如何用Hotkey Detective一键精准定位占用程序
Windows热键冲突终极指南:如何用Hotkey Detective一键精准定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detecti…...