【大数据】Flink 详解(八):SQL 篇 Ⅰ
《Flink 详解》系列(已完结),共包含以下 10 10 10 篇文章:
- 【大数据】Flink 详解(一):基础篇
- 【大数据】Flink 详解(二):核心篇 Ⅰ
- 【大数据】Flink 详解(三):核心篇 Ⅱ
- 【大数据】Flink 详解(四):核心篇 Ⅲ
- 【大数据】Flink 详解(五):核心篇 Ⅳ
- 【大数据】Flink 详解(六):源码篇 Ⅰ
- 【大数据】Flink 详解(七):源码篇 Ⅱ
- 【大数据】Flink 详解(八):SQL 篇 Ⅰ
- 【大数据】Flink 详解(九):SQL 篇 Ⅱ
- 【大数据】Flink 详解(十):SQL 篇 Ⅲ
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
Flink 详解(八):SQL 篇 Ⅰ
- 82.Flink SQL 有没有使用过?
- 83.Flink 被称作流批一体,那从哪个版本开始,真正实现流批一体的?
- 84.Flink SQL 使用哪种解析器?
- 85.Calcite 主要功能包含哪些?
- 86.Flink SQL 处理流程说一下?
- 87.Flink SQL 包含哪些优化规则?
- 88.Flink SQL 中涉及到哪些 Operation?
- 89.Flink Hive 有没有使用过?
- 90.Flink 与 Hive 集成时都做了哪些操作?
- 91.HiveCatalog 类包含哪些方法?
- 92.Flink SQL 1.11 新增了实时数仓功能,介绍一下?
- 93.Flink - Hive 实时写数据介绍下?
- 93.1 Flink-SQL 写法
- 93.2 Flink-Table 写法
- 94.Flink - Hive 实时读数据介绍下?
- 95.Flink - Hive 实时写数据时,如何保证已经写入分区的数据何时才能对下游可见呢?
82.Flink SQL 有没有使用过?
在 Flink 中,一共有四种级别的抽象,而 Flink SQL 作为最上层,是 Flink API 的一等公民。

在标准 SQL 中,SQL 语句包含四种类型
- 数据操作语言(
DML,Data Manipulation Language):用来定义数据库记录(数据)。 - 数据控制语言(
DCL,Data Control Language):用来定义访问权限和安全级别。 - 数据查询语言(
DQL,Data Query Language):用来查询记录(数据)。 - 数据定义语言(
DDL,Data Definition Language):用来定义数据库对象(库,表,列等)。
Flink SQL 包含 DML 数据操作语言、 DDL 数据定义语言, DQL 数据查询语言,不包含 DCL 语言。
🚀 可以参考我的这篇博客:【数据库】DDL、DML、DCL简介
83.Flink 被称作流批一体,那从哪个版本开始,真正实现流批一体的?
从 1.9.0 版本开始,引入了阿里巴巴的 Blink ,对 FIink TabIe & SQL 模块做了重大的重构,保留了 Flink Planner 的同时,引入了 Blink PIanner,没引入以前,Flink 没考虑流批作业统一,针对流批作业,底层实现两套代码,引入后,基于流批一体理念,重新设计算子,以流为核心,流作业和批作业最终都会被转为 transformation。
84.Flink SQL 使用哪种解析器?
Flink SQL 使用 Apache Calcite 作为解析器和优化器。
Calcite 一种动态数据管理框架,它具备很多典型数据库管理系统的功能 如 SQL 解析、 SQL 校验、 SQL 查询优化、 SQL 生成 以及 数据连接查询 等,但是又省略了一些关键的功能,如 Calcite 并不存储相关的元数据和基本数据,不完全包含相关处理数据的算法等。
85.Calcite 主要功能包含哪些?
Calcite 主要包含以下五个部分:
- SQL 解析(
Parser)- Calcite SQL 解析是通过 JavaCC 实现的,使用 JavaCC 编写 SQL 语法描述文件,将 SQL 解析成未经校验的 AST 语法树。
- SQL 校验(
Validato)- 无状态的校验:即验证 SQL 语句是否符合规范。
- 有状态的校验:即通过与元数据结合验证 SQL 中的 Schema、Field、 Function 是否存在,输入输出类型是否匹配等。
- SQL 查询优化
- 对上个步骤的输出(RelNode,逻辑计划树)进行优化,得到优化后的物理执行计划。优化有两种:基于规则的优化 和 基于代价的优化,后面会详细介绍。
- SQL 生成
- 将物理执行计划生成为在特定平台 / 引擎的可执行程序,如生成符合 MySQL 或 Oracle 等不同平台规则的 SQL 查询语句等。
- 数据连接与执行
- 通过各个执行平台执行查询,得到输出结果。 在 Flink 或者其他使用 Calcite 的大数据引擎中,一般到 SQL 查询优化即结束,由各个平台结合 Calcite SQL 代码生成和平台实现的代码生成,将优化后的物理执行计划组合成可执行的代码,然后在内存中编译执行。
86.Flink SQL 处理流程说一下?
下面举个例子,详细描述一下 Flink SQL 的处理流程,如下所示:
SET table.sql-dialect=default;
CREATE TABLE log_kafka (user_id STRING,|order_amount DOUBLE,log_ts TIMESTAMP(3),WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND
) WITH ('connector'='kafka','property-version' = 'universal','topic' = 'test','properties.bootstrap.servers'= 'hlink163:9092','scan.startup.mode' = 'earliest-offset','format' = 'json','json.fail-on-missing-field' = 'false','json.ignore-parse-errors' = 'true','properties.group.id' = 'flink1'
);
我们写一张 Source 表,来源为 Kafka,当执行 create table log_kafka 之后 Flink SQL 将做如下操作:

- 首先,Flink SQL 底层使用的是 Apache Calcite 引擎来处理 SQL 语句,Calcite 会使用 JavaCC 做 SQL 解析,JavaCC 根据 Calcite 中定义的
Parser.jj文件,生成一系列的 Java 代码,生成的 Java 代码会 把 SQL 转换成 AST 抽象语法树(即 SqlNode 类型)。 - 生成的 SqlNode 抽象语法树,它是一个未经验证的抽象语法树,这时,SQL Validator 会获取 Flink Catalog 中的元数据信息来验证 SQL 语法,元数据信息检查包括表名,字段名,函数名,数据类型等检查。然后生成一个校验后的 SqlNode。
- 到达这步后,只是将 SQL 解析到 Java 数据结构的固定节点上,并没有给出相关节点之间的关联关系以及每个节点的类型信息。所以,还 需要将 SqlNode 转换为逻辑计划,也就是 LogicalPlan,在转换过程中,会使用
SqlToOperationConverter类,来将 SqlNode 转换为 Operation,Operation 会根据 SQL 语法来执行创建表或者删除表等操作,同时FlinkPlannerImpl.rel()方法会将 SqlNode 转换成 RelNode 树,并返回 RelRoot。 - 第 4 步将执行 Optimize 操作,按照预定义的优化规则 RelOptRule 优化逻辑计划。Calcite 中的优化器 RelOptPlanner 有两种,一是基于规则优化(
RBO)的HepPlanner,二是基于代价优化(CBO)的VolcanoPlanner。然后得到优化后的 RelNode, 再基于 Flink 里面的rules将优化后的逻辑计划转换成物理计划。 - 第 5 步,执行 Execute 操作,会通过代码生成
transformation,然后递归遍历各节点,将 DataStreamRelNode 转换成 DataStream,在这期间,会依次递归调用DataStreamUnion、DataStreamCalc、DataStreamScan类中重写的translateToPlan方法。递归调用各节点的translateToPlan,实际是利用 CodeGen 元编成 Flink 的各种算子,相当于直接利用 Flink 的 DataSet 或者 DataStream 开发程序。 - 最后进一步编译成可执行的 JobGraph 提交运行。
87.Flink SQL 包含哪些优化规则?
下图为执行流程图:

总结就是:
- 先解析,然后验证,将 SqlNode 转化为 Operation 来创建表,然后调用
rel方法将 SqlNode 变成逻辑计划(RelNodeTree),紧接着对逻辑计划进行优化。 - 优化之前,会根据 Calcite 中的优化器中的基于规则优化的 HepPlanner 针对四种规则进行预处理,处理完之后得到 Logic RelNode,紧接着使用代价优化的 VolcanoPlanner 使用
Logical_Opt_Rules(逻辑计划优化)找到最优的执行 Planner,并转换为 Flink Logical RelNode。 - 最后运用 Flink 包含的优化规则,如
DataStream_Opt_Rules(流式计算优化)、DataStream_Deco_Rules(装饰流式计算优化),将优化后的逻辑计划转换为物理计划。
优化规则包含如下:
- 子查询优化:
Table_subquery_rules - 扩展计划优化:
Expand_plan_rules - 扩展计划优化:
Post_expand_clean_up_rules - 正常化流处理:
Datastream_norm_rules - 逻辑计划优化:
Logical_Opt_Rules - 流式计算优化:
DataStream_Opt_Rules - 装饰流式计算优化:
DataStream_Deco_Rules
88.Flink SQL 中涉及到哪些 Operation?
先介绍一下什么是 Operation:在 Flink SQL 中,涉及的 DDL,DML,DQL 操作都是 Operation,在 Flink 内部表示,Operation 可以和 SqlNode 对应起来。
Operation 执行在优化前,执行的函数为 executeQperation,如下图所示,为执行的所有 Operation。

89.Flink Hive 有没有使用过?
Flink 社区在 Flink 1.11 版本进行了重大改变,如下图所示:

90.Flink 与 Hive 集成时都做了哪些操作?
如下所示为 Flink 与 Hive 进行连接时的执行图:

- Flink
1.1新引入了 Hive 方言,所以在 Flink SQL 中可以编写 Hive 语法,即 Hive Dialect。 - 编写 Hive SQL 后,FlinkSQL Planner 会将 SQL 进行解析,验证,转换成逻辑计划,物理计划,最终变成 Jobgraph。
- HiveCatalog 作为 Flink 和 Hive 的表元素持久化介质,会将不同会话的 Flink 元数据存储到 Hive Metastore 中。用户利用 HiveCatalog 可以将 Hive 表或者 Kafka 表存储到 Hive Metastore 中。
BlinkPlanner 是在 Flink 1.9 版本新引入的机制,Blink 的查询处理器则实现流批作业接口的统一,底层的 API 都是 Transformation。真正实现流 & 批的统一处理,替代原 FlinkPlanner 将流 & 批区分处理的方式。在 1.11 版本后已经默认为 Blink Planner。
91.HiveCatalog 类包含哪些方法?
重点方法如下:

HiveCatalog 主要是持久化元数据,所以一般的创建类型都包含,如 database、Table、View、Function、Partition,还有 is_Generic 字段判断等。
92.Flink SQL 1.11 新增了实时数仓功能,介绍一下?
Flink 1.11 版本新增的一大功能是实时数仓,可以实时的将 Kafka 中的数据插入 Hive 中,传统的实时数仓基于 Kafka + Flink Streaming,定义全流程的流计算作业,有着秒级甚至毫秒的实时性,但实时数仓的一个问题是历史数据只有 3 − 15 3-15 3−15 天,无法在其上做 Ad-hoc 的查询。
针对这个特点,Flink 1.11 版本将 FlieSystemStreaming Sink 重新修改,增加了分区提交和滚动策略机制,让 HiveStreaming Sink 重新使用文件系统流接收器。
Flink 1.11 的 Table / SQL API 中,FileSystemConnector 是靠增强版 StreamingFileSink 组件实现,在源码中名为 StreamingFileWriter。
只有在 Checkpoint 成功时,StreamingFileSink 写入的文件才会由 Pending 状态变成 Finished 状态,从而能够安全地被下游读取。所以,我们一定要打开 Checkpointing,并设定合理的间隔。
93.Flink - Hive 实时写数据介绍下?
StreamingWrite,从 Kafka 中实时拿到数据,使用分区提交将数据从 Kafka 写入 Hive 表中,并运行批处理查询以读取该数据。
93.1 Flink-SQL 写法
- Source 源

- Sink 目的
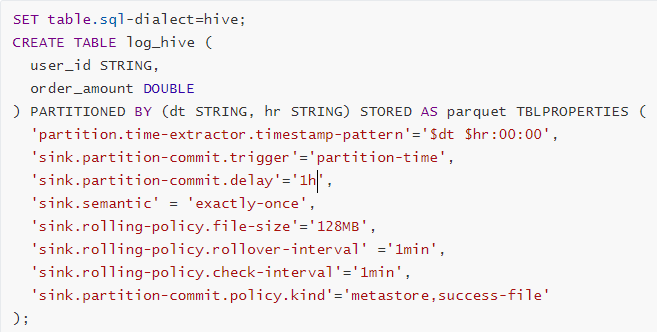
- Insert 插入

93.2 Flink-Table 写法
- Source 源
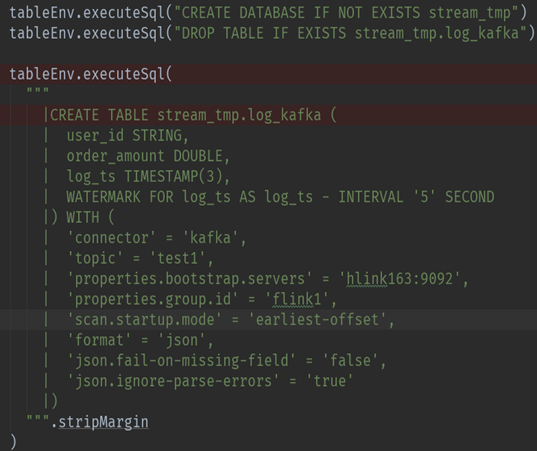
- Sink 目的
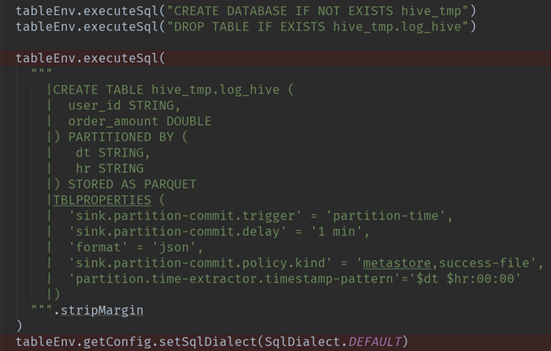
- Insert 插入
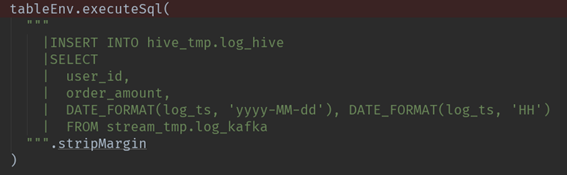
94.Flink - Hive 实时读数据介绍下?

Flink 源码中在对 Hive 进行读取操作时,会经历以下几个步骤:
- Flink 都是基于 Calcite 先解析 SQL,确定表来源于 Hive,如果是 Hive 表,将会在 HiveCatalog 中创建 HiveTableFactory。
- HiveTableFactory 会基于配置文件创建 HiveTableSource,然后 HiveTableSource 在真正执行时,会调用
getDataStream方法,通过getDataStream方法来确定查询匹配的分区信息,然后创建表对应的 InputFormat,然后确定并行度,根据并行度确定slot分发 HiveMapredSplitReader 任务。 - 在 TaskManager 端的
slot中,Split 会确定读取的内容,基于 Hive 中定义的序列化工具,InputFormat 执行读取反序列化,得到value值。 - 最后循环执行
reader.next获取value,将其解析成 Row。
95.Flink - Hive 实时写数据时,如何保证已经写入分区的数据何时才能对下游可见呢?
如下图所示:

首先可以看一下,在实时的将数据存储到 Hive 数仓中,FileSystemConnector 为了与 Flink-Hive 集成的大环境适配,最大的改变就是分区提交,可以看一下左下图,官方文档给出的,分区可以采取 日期 + 小时 的策略,或者 时分秒 的策略。
那如何保证已经写入分区的数据何时才能对下游可见呢? 这就和 触发机制 有关, 触发机制包含 process-time 和 partition-time 以及时延。
partition-time 指的是根据事件时间中提取的分区触发。当 'watermark' > 'partition-time' + 'delay',选择 partition-time 的数据才能提交成功,
process-time 指根据系统处理时间触发,当加上时延后,要想让分区进行提交,当 'currentprocessing time' > 'partition creation time' + 'delay' 选择 process-time 的数据可以提交成功。
但选择 process-time 触发机制会有缺陷,就是当数据迟到或者程序失败重启时,数据不能按照事件时间被归入正确分区。所以一般会选择 partition-time。
相关文章:
【大数据】Flink 详解(八):SQL 篇 Ⅰ
《Flink 详解》系列(已完结),共包含以下 10 10 10 篇文章: 【大数据】Flink 详解(一):基础篇【大数据】Flink 详解(二):核心篇 Ⅰ【大数据】Flink 详解&…...
如何从命令行运行testng.xml?
目录 创建一个新的java项目并从命令行运行testng.xml 使用命令行运行XML文件 从命令行运行现有maven项目的XML文件 在这篇文章中,我们将使用命令行运行testng.xml。有多种场景需要使用命令行工具运行testng.xml。也许您已经创建了一个maven项目,现在想…...
MongoDB-数据库文档操作(2)
任务描述 文档数据在 MongoDB 中的查询和删除。 相关知识 本文将教你掌握: 查询文档命令;删除文档命令。 查询文档 我们先插入文档到集合 stu1 : document([{ name:张小华, sex:男, age:20, phone:12356986594, hobbies:[打篮球,踢足球…...

文件包含介绍
本地文件包含 常见的文件包含漏洞的形式为 <?php include("inc/" . $_GET[file]); ?> 考虑常用的几种包含方式为 同目录包含file.htaccess目录遍历?file…/…/…/…/…/…/…/…/…/var/lib/locate.db日志注入?file…/…/…/…/…/…/…/…/…/var/log/a…...
C语言——小细节和小知识9
一、大小端字节序 1、介绍 在计算机系统中,大小端(Endianness)是指多字节数据的存储和读取顺序。它是数据在内存中如何排列的问题,特别是与字节顺序相关。C语言中的数据存储大小端字节序指的是在内存中存储的多字节数据类型&…...
)
uni-app基础详解(组件、弹窗、数据缓存、页面跳转)
uni-app基础详解(组件、弹窗、数据缓存、页面跳转) uni-app组件scroll-viewswipertext 文本button 按钮input 输入框radio 单选checkbox 多选picker 选择器slider 滑块textarea 文本域 弹窗提示框 uni.showLoading提示弹窗 uni.showToast确定取消框 uni.…...
LabVIEW模拟荧光显微管滑动实验
LabVIEW模拟荧光显微管滑动实验 在现代生物医学研究中,对微观生物过程的精准模拟和观察至关重要。本案例展示了如何利用LabVIEW软件和专业硬件平台,创新地模拟荧光显微管在滑动实验中的动态行为,这一过程不仅提升了实验效率,还为…...

Springboot项目:解决@Async注解获取不到上下文信息问题
问题描述 springboot项目中,需要使用到异步调用某个方法,此时 第一个想到的就是 Async 注解,但是 发现 方法执行报错了,具体报错如下: java.lang.NullPointerExceptionat com.ruoyi.common.utils.ServletUtils.getRe…...

国内镜像:极速下载编译WebRTC源码(For Android/Linux/IOS)(二十四)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒体系统工程师系列【原创干货持续更新中……】🚀 人生格言: 人生从来没有捷径,只…...

ThinkPHP为什么用PHP+Swoole协程模式部署运行
看很多ThinkPHP框架的程序商城等系统,现在都用PHPSwoole协程来运行。在说Swoole前我们先了解下传统PHP模式。 PHP-FPM 的对象常驻内存问题 互联网发展早期,大部分项目的业务逻辑并没有那么复杂,技术生态相对比较简单,也没有 Com…...
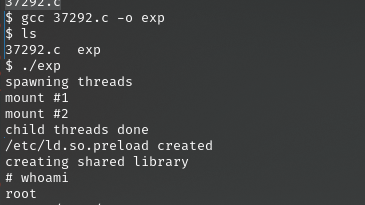
Vulnhub-tr0ll-1
一、信息收集 端口收集 PORT STATE SERVICE VERSION 21/tcp open ftp vsftpd 3.0.2 | ftp-anon: Anonymous FTP login allowed (FTP code 230) |_-rwxrwxrwx 1 1000 0 8068 Aug 09 2014 lol.pcap [NSE: writeable] | ftp-syst: | STAT: | FTP …...

服务器和电脑有啥区别?
服务器可以说是“高配的电脑”,两者都有CPU、硬盘、电源等基础硬件组成,但服务器和电脑也是有一定区别的,让小编带大家了解一下吧! #秋天生活图鉴# 1、稳定性需求不同:服务器是全年无休,需要高稳定性&…...
C语言——编译和链接
(图片由AI生成) 0.前言 C语言是最受欢迎的编程语言之一,以其接近硬件的能力和高效性而闻名。理解C语言的编译和链接过程对于深入了解其运行原理至关重要。本文将详细介绍C语言的翻译环境和运行环境,重点关注编译和链接的各个阶段…...
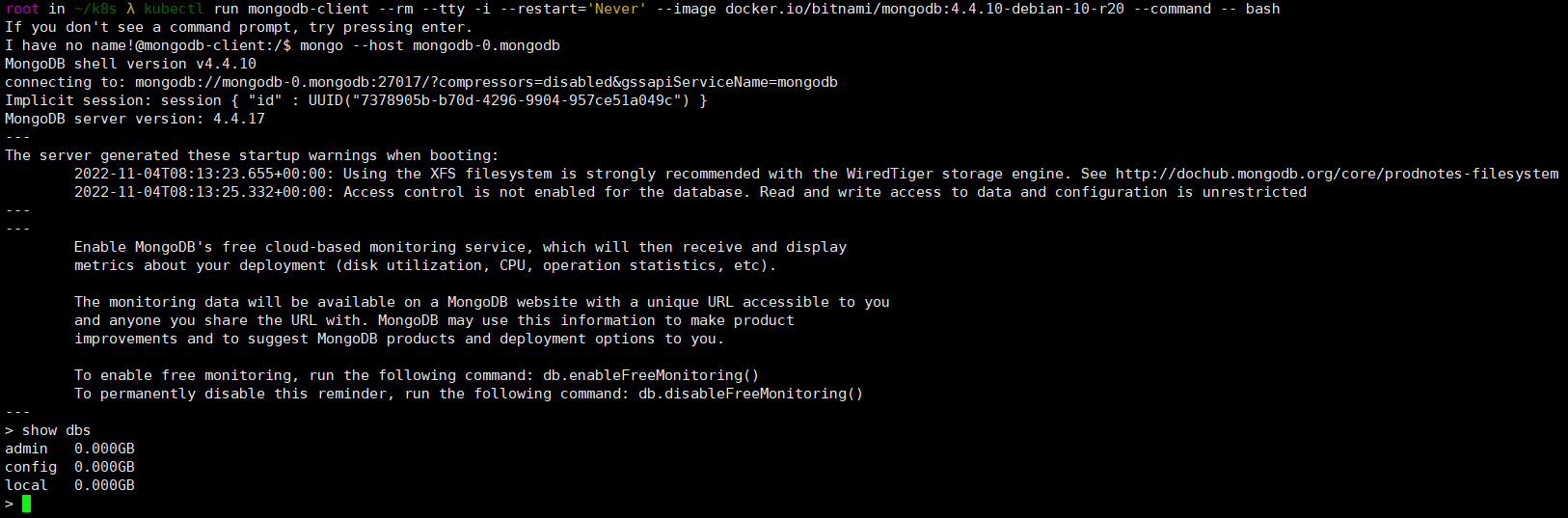
Kubernetes (K8S) 3 小时快速上手 + 实践
1. Kubernetes 简介 k8s即Kubernetes。其为google开发来被用于容器管理的开源应用程序,可帮助创建和管理应用程序的容器化。用一个的例子来描述:"当虚拟化容器Docker有太多要管理的时候,手动管理就会很麻烦,于是我们便可以通…...
如何画出优秀的系统架构图-架构师系列-学习总结
--- 后之视今,亦犹今之视昔! 目录 早期系统架构图 早期系统架构视图 41视图解读 41架构视图缺点 现代系统架构图的指导实践 业务架构 例子 使用场景 画图技巧 客户端架构、前端架构 例子 使用场景 画图技巧 系统架构 例子 定义 使用场…...

VR转接器:打破界限,畅享虚拟现实
你是否曾梦想过踏入另一个世界,体验那种仿佛置身其中的感觉?随着科技的飞速发展,虚拟现实(VR)已经成为了现实。而VR转接器,正是让你畅享虚拟现实的关键所在。 添加图片注释,不超过 140 字&…...

C++学习笔记——用C++实现树(区别于C)
树是一种非常重要的数据结构,它在计算机科学中的应用非常广泛。在本篇博客中,我们将介绍树的基本概念和C中如何实现树。 目录 一、树的基本概念 2.C中实现树 2.1创建一个树的实例,并向其添加节点 2.2三种遍历方式的实现代码 3.与C语言相…...

工业平板定制方案_基于联发科、紫光展锐平台的工业平板电脑方案
工业平板主板采用联发科MT6762平台方案,搭载Android 11.0操作系统, 主频最高2.0GHz,效能有大幅提升;采用12nm先进工艺,具有低功耗高性能的特点。 该工业平板主板搭载了IMG GE8320图形处理器,最高主频为680MHz, 支持108…...

JPA查询PostgreSQL行排序问题
文章目录 问题处理PostgreSQL排序相关JPA相关介绍 问题 我们项目使用Spring Boot构建,使用JHipster生成业务代码,包含基础的增删改查代码使用PostgreSQL作为业务数据库,使用自动生成的JPA构建数据更新语查询在查询某个实体类的列表时&#x…...

【css】渐变效果
css渐变效果 使用 CSS 渐变可以在两种颜色间制造出平滑的渐变效果。 用它代替图片,可以加快页面的载入时间、减小带宽占用。同时,因为渐变是由浏览器直接生成的,它在页面缩放时的效果比图片更好,因此你可以更加灵活、便捷的调整页…...

中关村、首体院、京奥电竞三方签约,共探AI+电竞产学研一体化突破
AI电竞:三方签约开启产学研新篇在今日的大会上,中关村人工智能研究院、首都体育学院、京奥电竞(北京)科技有限公司举行了一场重量级的三方签约。中关村人工智能研究院专注于具有产业价值和颠覆意义的人工智能与交叉学科领域探索&a…...
)
告别滑动窗口!用Python手把手复现红外小目标检测的LCM算法(附完整代码)
告别滑动窗口!用Python手把手复现红外小目标检测的LCM算法 红外小目标检测在军事侦察、安防监控等领域具有重要应用价值。传统滑动窗口方法计算量大、效率低下,而局部对比度测量(LCM)算法通过巧妙设计实现了高效检测。本文将带您从…...

从LR寄存器到问题函数:一次完整的Cortex-M HardFault调试实录与内存分析心得
从LR寄存器到问题函数:一次完整的Cortex-M HardFault调试实录与内存分析心得 引言:当MCU突然"罢工"时 那是一个周五的深夜,产品量产前的最后一周。测试工程师突然报告设备在特定操作序列下会无规律死机,串口日志最后一行…...

如何为SUSI ViberBot添加自定义功能:扩展按钮与交互体验的完整指南
如何为SUSI ViberBot添加自定义功能:扩展按钮与交互体验的完整指南 【免费下载链接】susi_viberbot Viberbot for SUSI AI http://susi.ai 项目地址: https://gitcode.com/gh_mirrors/su/susi_viberbot 想要为你的SUSI ViberBot添加个性化功能吗?…...

UDS_自动化脚本生成_10服务_V01
1、原子元素 1.1 会话原子 Session.Default() Session.Extended() Session.Programming() Session.Developer() 1.2 请求原子 10 01 10 02 10 03 10 76 10 81 10 82 10 83 10 F6 10 04 10 84 10 / 10 01 00 / 10 02 00 / 10 03 00 / 10 76 00 1.3 响应原子 50 01 00 32 01 F4 …...

调查研究-142 全球机器人产业深度调研报告【04篇】机器人产业利润池全景:谁最容易赚钱与十大判断指标
TL;DR 场景:关注机器人产业投资、创业、就业方向的投资者、从业者、分析师结论:医疗机器人耗材/服务>高端核心零部件>系统集成>物流RaaS>工业本体>软件AI平台;人形机器人长期空间大但短期商业化仍早产出:三档利润池…...

AI赋能·精准适配——API风险监测系统筑牢教育数据流转安全防线
一、概要提示:本文围绕数据流转安全与静态数据安全的核心差异,结合教育行业数字化转型特性,系统阐述API风险监测系统的核心逻辑、核心能力、常见疑问及发展趋势,全面呈现系统在教育场景中的数据化应用成效,凸显“AI赋能…...

别再瞎找了!AI论文写作软件2026最新测评与推荐
2026年真正好用的AI论文写作软件,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

SAR ADC工作原理、设计挑战与工程实践全解析
1. 项目概述:从“快枪手”到“精算师”的转换艺术在模拟信号与数字世界之间架起桥梁,是ADC(模数转换器)的核心使命。而在众多ADC架构中,SAR ADC(逐次逼近寄存器型模数转换器)因其独特的“二分搜…...

核心代码编程-多模态版本的最优调度-200分
在大语言模型推理服务中,有多个不同大小的模型版本可供选择。每个模型版本有不同的准确率和推理延迟。给定查询次数N和总时间预算T,为每个查询选择一个模型版本,使得在不超过时间预算的前提下,总准确率最大。输入 ﹣查询…...