Kafka消费流程
Kafka消费流程
消息是如何被消费者消费掉的。其中最核心的有以下内容。
1、多线程安全问题
2、群组协调
3、分区再均衡
1.多线程安全问题
当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的。
对于线程安全,还可以进一步定义:
当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些线程将如何交替进行,并且在主调代码中不需要任何额外的同步或协同,这个类都能表现出正确的行为,那么就称这个类是线程安全的。
那么如何避免生产者和消费者的线程安全问题呢?
1.1 生产者
KafkaProducer的实现是线程安全的。
KafkaProducer就是一个不可变类。线程安全的,可以在多个线程中共享单个KafkaProducer实例
所有字段用private final修饰,且不提供任何修改方法,这种方式可以确保多线程安全。
如何节约资源的多线程使用KafkaProducer实例
import com.msb.selfserial.User;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;/*** 类说明:多线程下使用生产者*/
public class KafkaConProducer {//发送消息的个数private static final int MSG_SIZE = 1000;//负责发送消息的线程池private static ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());private static CountDownLatch countDownLatch = new CountDownLatch(MSG_SIZE);private static User makeUser(int id){User user = new User(id);String userName = "llp_"+id;user.setName(userName);return user;}/*发送消息的任务*/private static class ProduceWorker implements Runnable{private ProducerRecord<String,String> record;private KafkaProducer<String,String> producer;public ProduceWorker(ProducerRecord<String, String> record, KafkaProducer<String, String> producer) {this.record = record;this.producer = producer;}public void run() {final String ThreadName = Thread.currentThread().getName();try {producer.send(record, new Callback() {public void onCompletion(RecordMetadata metadata, Exception exception) {if(null!=exception){exception.printStackTrace();}if(null!=metadata){System.out.println(ThreadName+"|" +String.format("偏移量:%s,分区:%s", metadata.offset(),metadata.partition()));}}});//执行countDown方法,代表一个任务结束,对计数器 - 1countDownLatch.countDown();} catch (Exception e) {e.printStackTrace();}}}public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {for(int i=0;i<MSG_SIZE;i++){User user = makeUser(i);ProducerRecord<String,String> record = new ProducerRecord<String,String>("concurrent-ConsumerOffsets",null,System.currentTimeMillis(), user.getId()+"", user.toString());executorService.submit(new ProduceWorker(record,producer));}//执行await方法,代表等待计数器变为0时,再继续执行countDownLatch.await();System.out.println("生产者消息发送完毕");} catch (Exception e) {e.printStackTrace();} finally {producer.close();executorService.shutdown();}}}
1.2 消费者
KafkaConsumer的实现不是线程安全的
实现消费者多线程最常见的方式: 线程封闭 ——即为每个线程实例化一个 KafkaConsumer对象,各自消费分配的分区消息
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;/*** 类说明:多线程下正确的使用消费者,一个线程一个消费者*/
public class KafkaConConsumer {public static final int CONCURRENT_PARTITIONS_COUNT = 2;private static ExecutorService executorService = Executors.newFixedThreadPool(CONCURRENT_PARTITIONS_COUNT);private static class ConsumerWorker implements Runnable{private KafkaConsumer<String,String> consumer;public ConsumerWorker(Map<String, Object> config, String topic) {Properties properties = new Properties();properties.putAll(config);//一个线程一个消费者this.consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Collections.singletonList(topic));}public void run() {final String ThreadName = Thread.currentThread().getName();try {while(true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){System.out.println(ThreadName+"|"+String.format("主题:%s,分区:%d,偏移量:%d," +"key:%s,value:%s",record.topic(),record.partition(),record.offset(),record.key(),record.value()));//do our work}}} finally {consumer.close();}}}public static void main(String[] args) {/*消费配置的实例*/Map<String,Object> properties = new HashMap<String, Object>();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"c_test");properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");for(int i = 0; i<CONCURRENT_PARTITIONS_COUNT; i++){//一个线程一个消费者executorService.submit(new ConsumerWorker(properties, "concurrent-ConsumerOffsets"));}}}
测试结果
2.群组协调
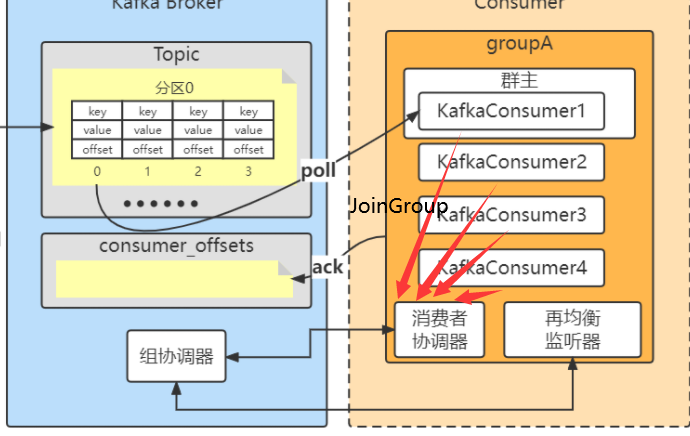
消费者要加入群组时,会向群组协调器发送一个JoinGroup请求,第一个加入群主的消费者成为群主,群主会获得群组的成员列表,并负责给每一个消费者分配分区。分配完毕后,群主把分配情况发送给群组协调器,协调器再把这些信息发送给所有的消费者,每个消费者只能看到自己的分配信息,只有群主知道群组里所有消费者的分配信息。群组协调的工作会在消费者发生变化(新加入或者掉线),主题中分区发生了变化(增加)时发生。
2.1组协调器
组协调器是Kafka服务端自身维护的。
组协调器( GroupCoordinator )可以理解为各个消费者协调器的一个中央处理器, 每个消费者的所有交互都是和组协调器( GroupCoordinator )进行的。
- 选举Leader消费者客户端
- 处理申请加入组的客户端
- 再平衡后同步新的分配方案
- 维护与客户端的心跳检测
- 管理消费者已消费偏移量,并存储至
__consumer_offset中
kafka上的组协调器( GroupCoordinator )协调器有很多,有多少个 __consumer_offset分区, 那么就有多少个组协调器( GroupCoordinator )
默认情况下, __consumer_offset有50个分区, 每个消费组都会对应其中的一个分区,对应的逻辑为 hash(group.id)%分区数。
2.2消费者协调器
每个客户端(消费者的客户端)都会有一个消费者协调器, 他的主要作用就是向组协调器发起请求做交互, 以及处理回调逻辑
- 向组协调器发起入组请求
- 向组协调器发起同步组请求(如果是Leader客户端,则还会计算分配策略数据放到入参传入)
- 发起离组请求
- 保持跟组协调器的心跳线程
- 向组协调器发送提交已消费偏移量的请求
2.3消费者加入分组的流程
1、客户端启动的时候, 或者重连的时候会发起JoinGroup的请求来申请加入的组中。
2、当前客户端都已经完成JoinGroup之后, 客户端会收到JoinGroup的回调, 然后客户端会再次向组协调器发起SyncGroup的请求来获取新的分配方案
3、当消费者客户端关机/异常 时, 会触发离组LeaveGroup请求。
当然有主动的消费者协调器发起离组请求,也有组协调器一直会有针对每个客户端的心跳检测, 如果监测失败,则就会将这个客户端踢出Group。
4、客户端加入组内后, 会一直保持一个心跳线程,来保持跟组协调器的一个感知。
并且组协调器会针对每个加入组的客户端做一个心跳监测,如果监测到过期, 则会将其踢出组内并再平衡。
2.4消费者消费的offset的存储
__consumer_offsets topic,并且默认提供了kafka_consumer_groups.sh脚本供用户查看consumer信息。
__consumer_offsets 是 kafka 自行创建的,和普通的 topic 相同。它存在的目的之一就是保存 consumer 提交的位移。
kafka-consumer-groups.bat --bootstrap-server :9092 --group c_test --describe

那么如何使用 kafka 提供的脚本查询某消费者组的元数据信息呢?
/*** 类说明:如何根据消费分组找ConsumerOffsets文件*/
public class ConsumerOffsets {public static void main(String[] args) {String groupID = "c_test";// 4System.out.println(Math.abs(groupID.hashCode()) % 50);}
}
__consumer_offsets 的每条消息格式大致如图所示
可以想象成一个 KV 格式的消息,key 就是一个三元组:group.id+topic+分区号,而 value 就是 offset 的值
2.5分区再均衡
当消费者群组里的消费者发生变化,或者主题里的分区发生了变化,都会导致再均衡现象的发生。从前面的知识中,我们知道,Kafka中,存在着消费者对分区所有权的关系,
这样无论是消费者变化,比如增加了消费者,新消费者会读取原本由其他消费者读取的分区,消费者减少,原本由它负责的分区要由其他消费者来读取,增加了分区,哪个消费者来读取这个新增的分区,这些行为,都会导致分区所有权的变化,这种变化就被称为 再均衡 。
再均衡对Kafka很重要,这是消费者群组带来高可用性和伸缩性的关键所在。不过一般情况下,尽量减少再均衡,因为再均衡期间,消费者是无法读取消息的,会造成整个群组一小段时间的不可用。
消费者通过向称为群组协调器的broker(不同的群组有不同的协调器)发送心跳来维持它和群组的从属关系以及对分区的所有权关系。如果消费者长时间不发送心跳,群组协调器认为它已经死亡,就会触发一次再均衡。
心跳由单独的线程负责,相关的控制参数为max.poll.interval.ms。
2.6消费者提交偏移量导致的问题
当我们调用poll方法的时候,broker返回的是生产者写入Kafka但是还没有被消费者读取过的记录,消费者可以使用Kafka来追踪消息在分区里的位置,我们称之为 偏移量 。消费者更新自己读取到哪个消息的操作,我们称之为 提交 。
消费者是如何提交偏移量的呢?消费者会往一个叫做_consumer_offset的特殊主题发送一个消息,里面会包括每个分区的偏移量。发生了再均衡之后,消费者可能会被分配新的分区,为了能够继续工作,消费者者需要读取每个分区最后一次提交的偏移量,然后从指定的地方,继续做处理。
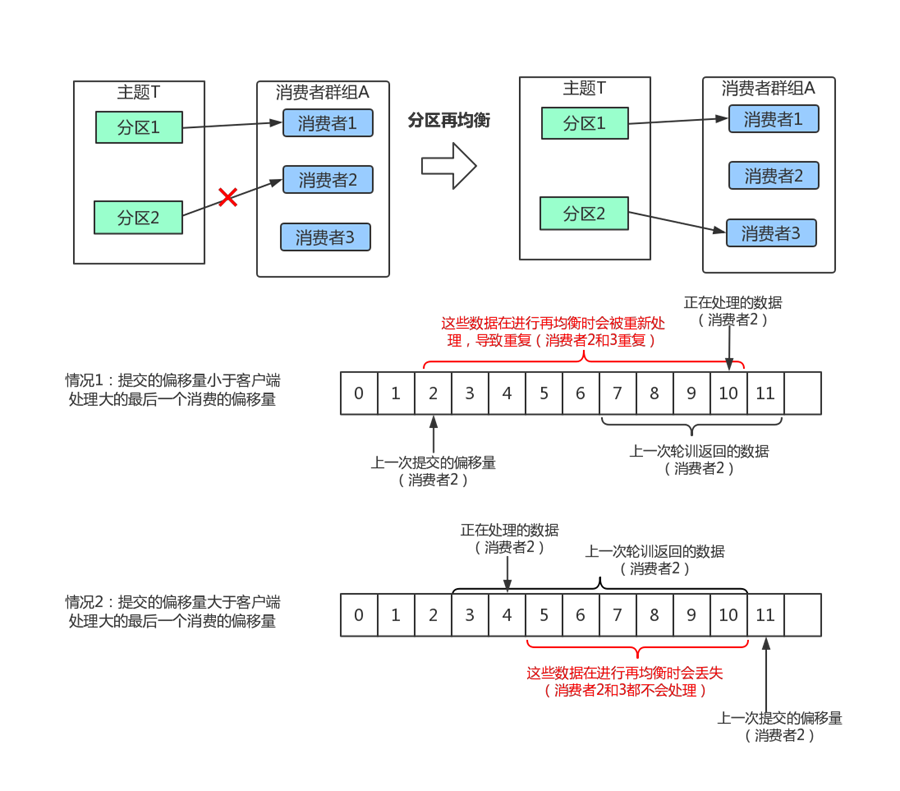
分区再均衡的例子:
某软件公司,有一个项目,有两块的工作,有两个码农,一个小王、一个小李,一个负责一块(分区消费),干得好好的。突然一天,小王桌子一拍不干了,老子中了5百万了,不跟你们玩了,立马收拾完电脑就走了。这个时候小李就必须承担两块工作,这个时候就是发生了分区再均衡。
过了几天,你入职,一个萝卜一个坑,你就入坑了,你承担了原来小王的工作。这个时候又会发生了分区再均衡。
1)如果提交的偏移量小于消费者实际处理的最后一个消息的偏移量,处于两个偏移量之间的消息会被重复处理,
2)如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失
2.7 再均衡监听器示例
我们创建一个分区数是3的主题rebalance
kafka-topics.bat --bootstrap-server localhost:9092 --create --topic rebalance --replication-factor 1 --partitions 3
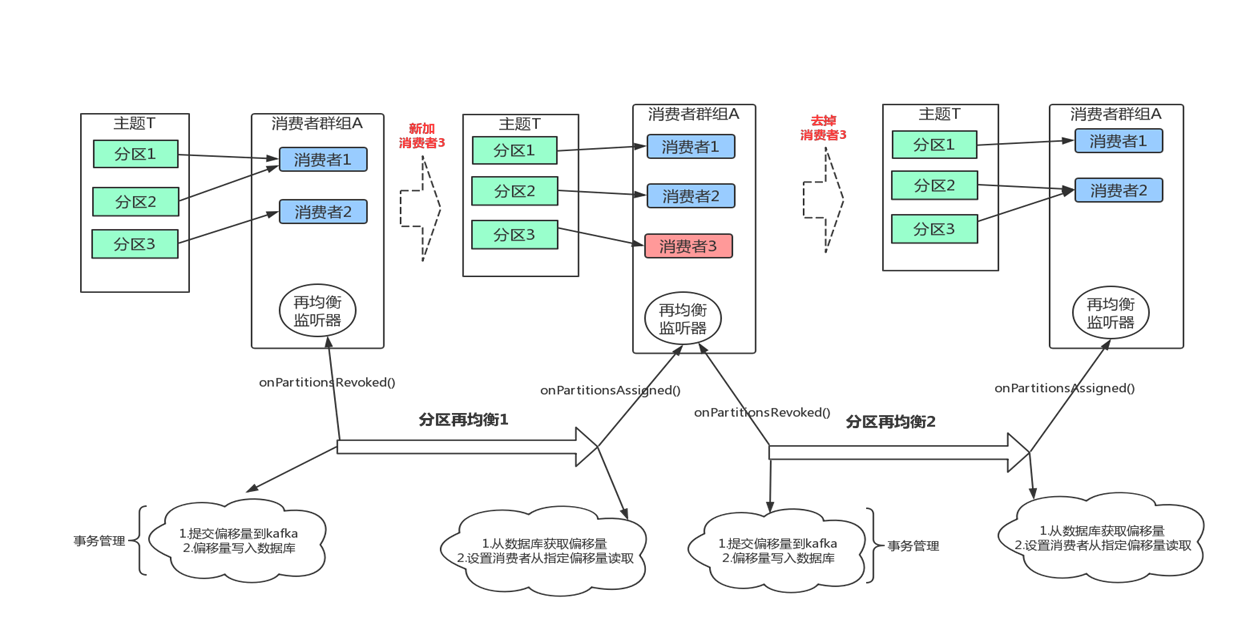
在为消费者分配新分区或移除旧分区时,可以通过消费者API执行一些应用程序代码,在调用 subscribe()方法时传进去一个 ConsumerRebalancelistener实例就可以了。
ConsumerRebalancelistener有两个需要实现的方法。
- public void
onPartitionsRevoked( Collection< TopicPartition> partitions)方法会在
再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,下一个接管分区的消费者就知道该从哪里开始读取了
- public void
onPartitionsAssigned( Collection< TopicPartition> partitions)方法会在重新分配分区之后和消费者开始读取消息之前被调用。
具体使用,我们先创建一个3分区的主题,然后实验一下,
在再均衡开始之前会触发onPartitionsRevoked方法
在再均衡开始之后会触发onPartitionsAssigned方法
生产者
/*** 类说明:多线程下使用生产者*/
public class RebalanceProducer {//发送消息的个数private static final int MSG_SIZE = 50;//负责发送消息的线程池private static ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());private static CountDownLatch countDownLatch = new CountDownLatch(MSG_SIZE);private static User makeUser(int id){User user = new User(id);String userName = "llp_"+id;user.setName(userName);return user;}/*发送消息的任务*/private static class ProduceWorker implements Runnable{private ProducerRecord<String,String> record;private KafkaProducer<String,String> producer;public ProduceWorker(ProducerRecord<String, String> record, KafkaProducer<String, String> producer) {this.record = record;this.producer = producer;}public void run() {final String ThreadName = Thread.currentThread().getName();try {producer.send(record, new Callback() {public void onCompletion(RecordMetadata metadata, Exception exception) {if(null!=exception){exception.printStackTrace();}if(null!=metadata){System.out.println(ThreadName+"|" +String.format("偏移量:%s,分区:%s", metadata.offset(),metadata.partition()));}}});countDownLatch.countDown();} catch (Exception e) {e.printStackTrace();}}}public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {for(int i=0;i<MSG_SIZE;i++){User user = makeUser(i);ProducerRecord<String,String> record = new ProducerRecord<String,String>("rebalance",null,System.currentTimeMillis(), user.getId()+"", user.toString());executorService.submit(new RebalanceProducer.ProduceWorker(record,producer));Thread.sleep(600);}countDownLatch.await();} catch (Exception e) {e.printStackTrace();} finally {producer.close();executorService.shutdown();}}}
消费者
/*** 类说明:设置了再均衡监听器的消费者*/
public class RebalanceConsumer {public static final String GROUP_ID = "rebalance_consumer";private static ExecutorService executorService = Executors.newFixedThreadPool(3);public static void main(String[] args) throws InterruptedException {//先启动两个消费者new Thread(new ConsumerWorker(false)).start();new Thread(new ConsumerWorker(false)).start();Thread.sleep(5000);//再启动一个消费,这个消费者 运行几次后就会停止消费new Thread(new ConsumerWorker(true)).start();//Thread.sleep(5000000);}
}
/*** 类说明:消费者任务*/
public class ConsumerWorker implements Runnable{private final KafkaConsumer<String,String> consumer;/*用来保存每个消费者当前读取分区的偏移量*/private final Map<TopicPartition, OffsetAndMetadata> currOffsets;private final boolean isStop;public ConsumerWorker(boolean isStop) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,RebalanceConsumer.GROUP_ID);/*取消自动提交*/properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);this.isStop = isStop;this.consumer = new KafkaConsumer<String, String>(properties);//保存 每个分区的消费偏移量this.currOffsets = new HashMap<TopicPartition, OffsetAndMetadata>();System.out.println("consumer-hashcode:"+consumer.hashCode());consumer.subscribe(Collections.singletonList("rebalance"), new HandlerRebalance(currOffsets,consumer));}public void run() {final String id = Thread.currentThread().getId()+"";int count = 0;TopicPartition topicPartition = null;long offset = 0;try {while(true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));//业务处理//开始事务for(ConsumerRecord<String, String> record:records){System.out.println(id+"|"+String.format("处理主题:%s,分区:%d,偏移量:%d," +"key:%s,value:%s",record.topic(),record.partition(),record.offset(),record.key(),record.value()));topicPartition = new TopicPartition(record.topic(), record.partition());offset = record.offset()+1;//获取偏移量currOffsets.put(topicPartition,new OffsetAndMetadata(offset, "no"));count++;//执行业务sql}if(currOffsets.size()>0){for(TopicPartition topicPartitionkey:currOffsets.keySet()){HandlerRebalance.partitionOffsetMap.put(topicPartitionkey, currOffsets.get(topicPartitionkey).offset());}//提交事务,同时将业务和偏移量入库(使用HashMap替代)}if(isStop&&count>=5){ //监听线程System.out.println(id+"-将关闭,当前偏移量为:"+currOffsets);consumer.commitSync();//跳出这个循环,最终执行finally中的关闭,此时消费者关闭break;}consumer.commitSync();}} finally {consumer.close();}}
}
在均衡监听器
/*** 类说明:再均衡监听器*/
public class HandlerRebalance implements ConsumerRebalanceListener {/*模拟一个保存分区偏移量的数据库表*/public final static ConcurrentHashMap<TopicPartition,Long>partitionOffsetMap = new ConcurrentHashMap<TopicPartition,Long>();private final Map<TopicPartition, OffsetAndMetadata> currOffsets;private final KafkaConsumer<String,String> consumer;//private final Transaction tr事务类的实例public HandlerRebalance(Map<TopicPartition, OffsetAndMetadata> currOffsets,KafkaConsumer<String, String> consumer) {this.currOffsets = currOffsets;this.consumer = consumer;}//分区再均衡之前public void onPartitionsRevoked(Collection<TopicPartition> partitions) {final String id = Thread.currentThread().getId()+"";System.out.println(id+"-onPartitionsRevoked参数值为:"+partitions);System.out.println(id+"-服务器准备分区再均衡,提交偏移量。当前偏移量为:"+currOffsets);//我们可以不使用consumer.commitSync(currOffsets);//提交偏移量到kafka,由我们自己维护*///开始事务//偏移量写入数据库System.out.println("分区偏移量表中:"+partitionOffsetMap);for(TopicPartition topicPartition:partitions){partitionOffsetMap.put(topicPartition, currOffsets.get(topicPartition).offset());}consumer.commitSync(currOffsets);//提交业务数和偏移量入库 tr.commit}//分区再均衡完成以后public void onPartitionsAssigned(Collection<TopicPartition> partitions) {final String id = Thread.currentThread().getId()+"";System.out.println(id+"-再均衡完成,onPartitionsAssigned参数值为:"+partitions);System.out.println("分区偏移量表中:"+partitionOffsetMap);for(TopicPartition topicPartition:partitions){System.out.println(id+"-topicPartition"+topicPartition);//模拟从数据库中取得上次的偏移量Long offset = partitionOffsetMap.get(topicPartition);if(offset==null) continue;consumer.seek(topicPartition,partitionOffsetMap.get(topicPartition));}}
}
相关文章:
Kafka消费流程
Kafka消费流程 消息是如何被消费者消费掉的。其中最核心的有以下内容。 1、多线程安全问题 2、群组协调 3、分区再均衡 1.多线程安全问题 当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的。 对于线程安全&…...
)
RPC原理介绍与使用(@RpcServiceAnnotation)
Java RPC(Remote Procedure Call,远程过程调用)是一种用于实现分布式系统中不同节点之间通信的技术。它允许在不同的计算机或进程之间调用远程方法,就像调用本地方法一样。 ** 一.Java RPC的原理如下: ** 定义接口&…...

力扣labuladong——一刷day94
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言二叉堆(Binary Heap)没什么神秘,性质比二叉搜索树 BST 还简单。其主要操作就两个,sink(下沉…...

Vim 是一款强大的文本编辑器,广泛用于 Linux 和其他 Unix 系统。以下是 Vim 的一些基本用法
Vim 是一款强大的文本编辑器,广泛用于 Linux 和其他 Unix 系统。以下是 Vim 的一些基本用法: 打开文件: vim filename 基本移动: 使用箭头键或 h, j, k, l 分别向左、下、上、右移动。Ctrl f: 向前翻页。Ctrl b: 向后翻页。…...
软件工程:黑盒测试等价分类法相关知识和多实例分析
目录 一、黑盒测试和等价分类法 1. 黑盒测试 2. 等价分类法 二、黑盒测试等价分类法实例分析 1. 工厂招工年龄测试 2. 规定电话号码测试 3. 八位微机测试 4. 三角形判断测试 一、黑盒测试和等价分类法 1. 黑盒测试 黑盒测试就是根据被测试程序功能来进行测试…...

stable-diffusion 学习笔记
必看文档: 万字长篇!超全Stable Diffusion AI绘画参数及原理详解 - 知乎 (提示词)语法控制 常用语法: 加权:() 或 {} 降权:[](word)//将括号内的提示词权重提高 1.1 倍 ((word))//将括号内的提示…...

手写webpack核心原理,支持typescript的编译和循环依赖问题的解决
主要知识点 babel读取代码的import语句算法:bfs遍历依赖图为浏览器定义一个require函数的polyfill算法:用记忆化搜索解决require函数的循环依赖问题 Quick Start GitHub:https://github.com/Hans774882968/mini-webpack npm install npm…...

开箱即用之MyBatisPlus XML 自定义分页
调用方法 import com.baomidou.mybatisplus.extension.plugins.pagination.Page;public Page<User> queryListByPage(User user) { Page<User> page new Page<>(1, 12); return userMapper.queryListByPage(page, user); } mapper接口 import co…...
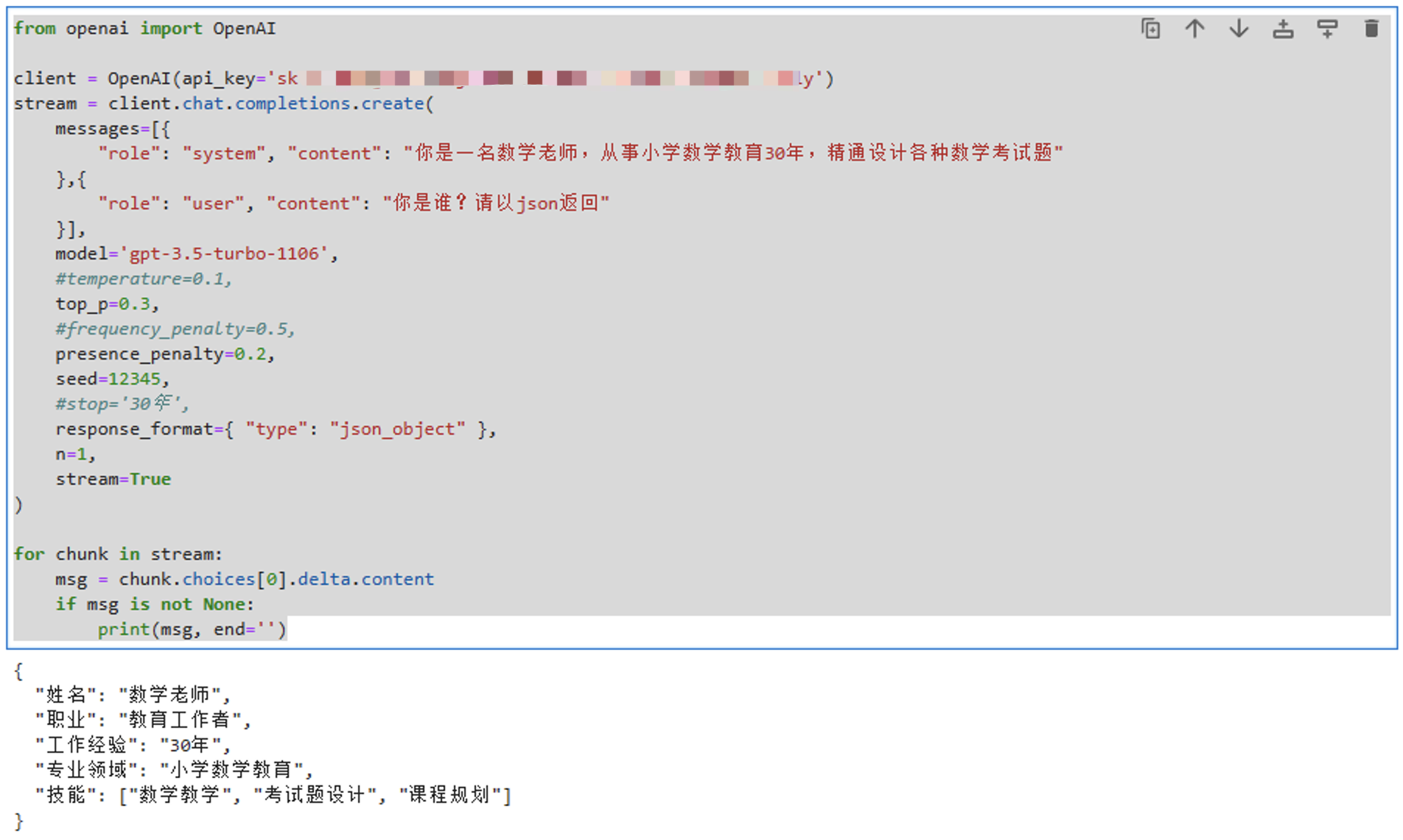
GPT应用开发:运行你的第一个聊天程序
本系列文章介绍基于OpenAI GPT API开发应用的方法,适合从零开始,也适合查缺补漏。 本文首先介绍基于聊天API编程的方法。 环境搭建 很多机器学习框架和类库都是使用Python编写的,OpenAI提供的很多例子也是Python编写的,所以为了…...
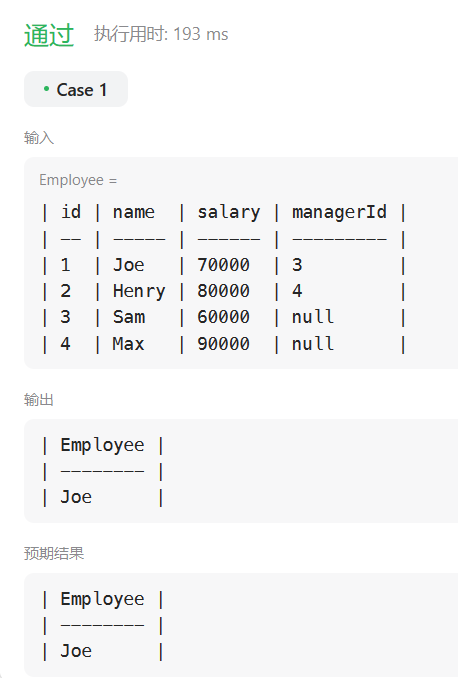
力扣刷MySQL-第一弹(详细解析)
🎉欢迎您来到我的MySQL基础复习专栏 ☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹 ✨博客主页:小小恶斯法克的博客 🎈该系列文章专栏:力扣刷题讲解-MySQL 🍹文章作者技术和水平很有限,如果文中出…...

Xcode 15 for Mac:超越开发的全新起点
作为一名开发人员,你是否正在寻找一款强大而高效的开发工具,来帮助你在Mac上构建出卓越的应用程序?那么,Xcode 15就是你一直在寻找的答案。 Xcode 15是苹果公司最新推出的一款集成开发环境(IDE)࿰…...
)
2021腾讯、华为前端面试题集(基础篇)
Vue 面试题 生命周期函数面试题 1.什么是 vue 生命周期2.vue 生命周期的作用是什么 3.第一次页面加载会触发哪几个钩子 4.简述每个周期具体适合哪些场景 5.created 和 mounted 的区别 6.vue 获取数据在哪个周期函数 7.请详细说下你对 vue 生命周期的理解? **vue 路由…...
怎么修改或移除WordPress后台仪表盘概览底部的版权信息和主题信息?
前面跟大家分享『WordPress怎么把后台左上角的logo和评论图标移除?』和『WordPress后台底部版权信息“感谢使用 WordPress 进行创作”和版本号怎么修改或删除?』,其实在WordPress后台仪表盘的“概览”底部还有一个WordPress版权信息和所使用的…...

计算机三级(网络技术)——应用题
第一题 61.输出端口S0 (直接连接) RG的输出端口S0与RE的S1接口直接相连构成一个互联网段 对172.0.147.194和172.0.147.193 进行聚合 前三段相同,将第四段分别转换成二进制 11000001 11000010 前6位相同,加上前面三段 共30…...

Node.js基础知识点(四)
本节介绍一下最简单的http服务 一.http 可以使用Node 非常轻松的构建一个web服务器,在 Node 中专门提供了一个核心模块:http http 这个模块的就可以帮你创建编写服务器。 1. 加载 http 核心模块 var http require(http) 2. 使用 http.createServe…...
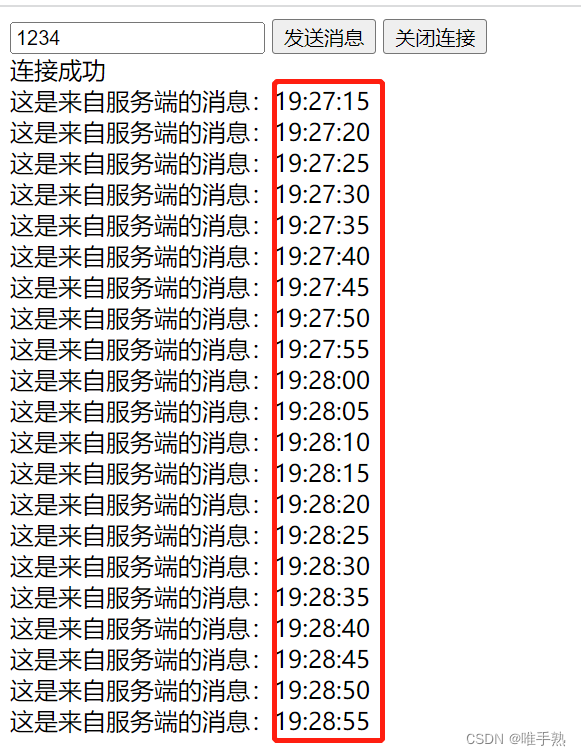
持久双向通信网络协议-WebSocket-入门案例实现demo
1 介绍 WebSocket 是基于 TCP 的一种新的网络协议。它实现了浏览器与服务器全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接, 并进行双向数据传输。 HTTP协议和WebSocket协议对比: HTTP是短连接࿰…...

LV.13 D10 Linux内核移植 学习笔记
具体实验步骤在lv13day10 实验十 一、Linux内核概述 1.1 内核与操作系统 内核 内核是一个操作系统的核心,提供了操作系统最基本的功能,是操作系统工作的基础,决定着整个系统的性能和稳定性 操作系统 操作系统是在内核的基础上添…...

STM32面试体验和题目
目录 一、说一下你之前的工作主要干了什么? 二、stm32有关的知识点 1.stm32的外设有哪一些 2.你的毕业论文的项目里面是怎么设计的 三,C语言的考察 1.写一个结构体(结构体的内容自由发挥) 2.写一个指针型的变量 3.结构体是…...
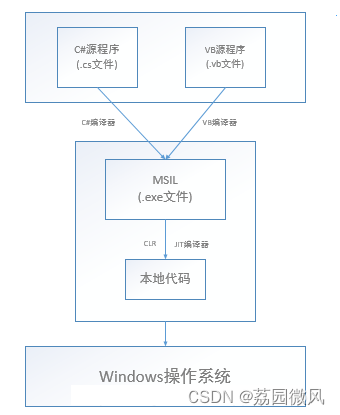
微软.NET、.NET Framework和.NET Core联系和区别
我是荔园微风,作为一名在IT界整整25年的老兵,看到不少初学者在学习编程语言的过程中如此的痛苦,我决定做点什么,我小时候喜欢看小人书(连环画),在那个没有电视、没有手机的年代,这是…...

Shell脚本同时调用#!/bin/bash和#!/usr/bin/expect
如果你想在一个脚本中同时使用bash和expect,你可以将expect部分嵌入到bash脚本中。以下是一个示例: #!/bin/bash# 设置MySQL服务器地址、端口、用户名和密码 MYSQL_HOST"localhost" MYSQL_PORT"3306" MYSQL_USER"your_usernam…...

ARM处理器命名后缀解析与技术演进
1. ARM处理器命名后缀解析:从TDMI-S到T2F-S的技术演进作为一名长期从事嵌入式开发的工程师,我经常需要查阅ARM处理器的技术文档。初次接触ARM7TDMI-S、ARM926EJ-S这类命名时,那些神秘的字母后缀确实让人困惑。今天我们就来彻底拆解这些命名背…...

向量化映射框架优化图着色问题的FPGA实现
1. 问题背景与核心挑战图着色问题作为组合优化领域的经典NP难问题,在集成电路布局分解、寄存器分配、逻辑最小化等场景中具有广泛应用。传统Ising机采用独热编码(one-hot encoding)方案,将每个节点的q种颜色状态映射为q个物理比特…...

MySQL调优实战:MySQL日志机制深入解析,redo/undo/binlog/slow/error日志底层全通透
一、MySQL五大日志总览(全局认知)MySQL 日志严格分为两层:Server层日志 InnoDB引擎层日志。这是90%人混淆的根源:1.1 Server层日志(所有引擎通用)Binlog(二进制日志):主…...

2026年南京Geo公司将有何新动态?一起探寻其发展新方向!
在数字化浪潮汹涌澎湃的当下,AI智能营销领域正经历着前所未有的变革。顺炫科技作为该领域的深耕者,一直致力于为全球客户提供高效、智能的数字化推广解决方案。随着2026年的到来,顺炫科技又将有哪些新动态,其发展新方向又将指向何…...

苹果CMS V10终极指南:3步打造专业视频网站,新手也能轻松上手
苹果CMS V10终极指南:3步打造专业视频网站,新手也能轻松上手 【免费下载链接】maccms10 苹果cms-v10,maccms-v10,麦克cms,开源cms,内容管理系统,视频分享程序,分集剧情程序,网址导航程序,文章程序,漫画程序,图片程序 项目地址: https://gitcode.com/gh…...

利用 AI 导出鸭将 DeepSeek 内容一键转为 PDF
在日常使用 AI 助手进行技术调研或文档整理时,我们常常会遇到一个痛点:生成的优质内容往往停留在网页对话框中,难以直接转化为便于归档、打印或离线阅读的格式。尤其是像 DeepSeek 这样输出结构清晰、代码片段丰富的长文,如果只能…...

MoE架构揭秘:万亿参数大模型如何实现2%活跃率
1. 项目概述:当“参数规模”不再等于“实际计算量”你可能已经看过不少标题党文章,比如“GPT-4参数量突破1.8万亿!”——但真正值得细品的,是后半句:“它每处理一个词(token),只动用…...

蜂窝物联网设计的全能选手:NRF9151-LACA-R7开发全攻略
前言在蜂窝物联网技术飞速发展的今天,设备的小型化、低功耗和全球化部署已成为不可逆转的趋势。Nordic Semiconductor推出的nRF9151系统级封装(SiP)解决方案,正是响应这一趋势的旗舰级产品。作为nRF91系列的最新一代成员ÿ…...

百考通:AI一键生成论文降重与去AI痕迹,提供双重优化保障,让学术成果更合规
在学术写作与论文发表的过程中,重复率过高、AI生成痕迹明显,是困扰无数学生与科研工作者的核心难题。不仅可能导致查重不通过,更会影响学术诚信与成果认可度。百考通(https://www.baikaotongai.com) 凭借智能文本优化技…...

【DeepSeek事实准确性测试权威报告】:2024年7大维度实测数据揭穿幻觉率真相
更多请点击: https://intelliparadigm.com 第一章:DeepSeek事实准确性测试权威报告总览 本报告基于2024年Q3由AI Safety Benchmark Consortium(ASBC)主导的跨模型事实一致性评估项目,对DeepSeek-V2、DeepSeek-Coder-3…...