Kafka生产消费流程
Kafka生产消费流程
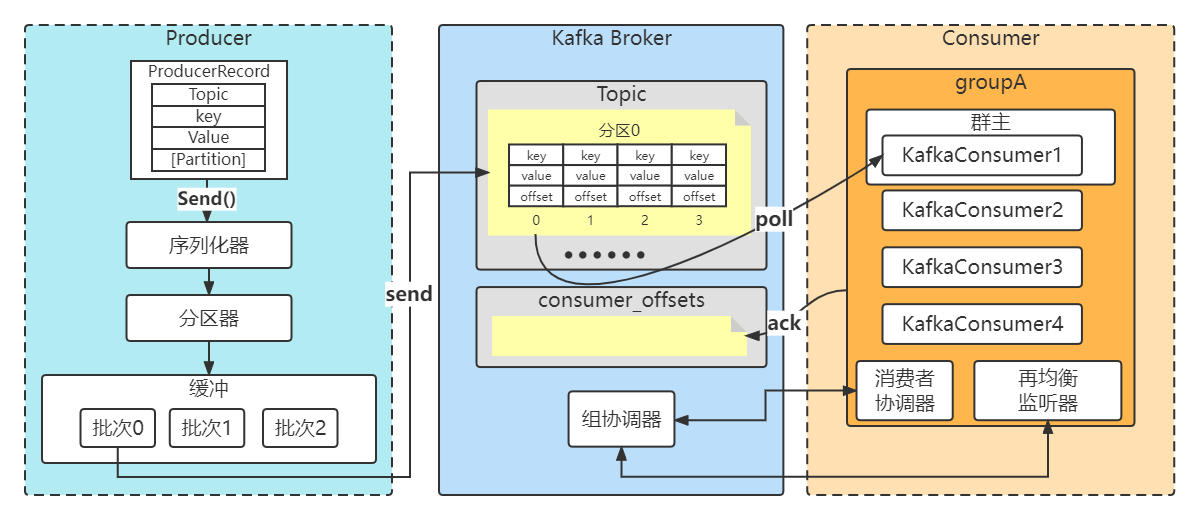
1.Kafka一条消息发送和消费的流程图(非集群)
2.三种发送方式
- 准备工作
创建maven工程,引入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.3.1</version></dependency>
- 消费者
/*** 类说明:消费者入门*/
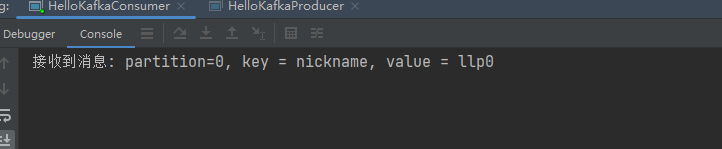
public class HelloKafkaConsumer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","192.168.140.103:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);// 设置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"llp_consumerA");// 构建kafka消费者对象KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);try {//指定消费者订阅的主题consumer.subscribe(Collections.singletonList("llp-topic"));// 调用消费者拉取消息while(true){// 设置1秒的超时时间ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){String key = record.key();String value = record.value();//分区int partition = record.partition();System.out.println("接收到消息: partition="+partition+", key = " + key + ", value = " + value);}}} finally {// 释放连接consumer.close();}}
}
1.1 发送并忘记
忽略send方法的返回值,不做任何处理。大多数情况下,消息会正常到达,而且生产者会自动重试,但有时会丢失消息。
消费者
/*** 类说明:kafak生产者*/
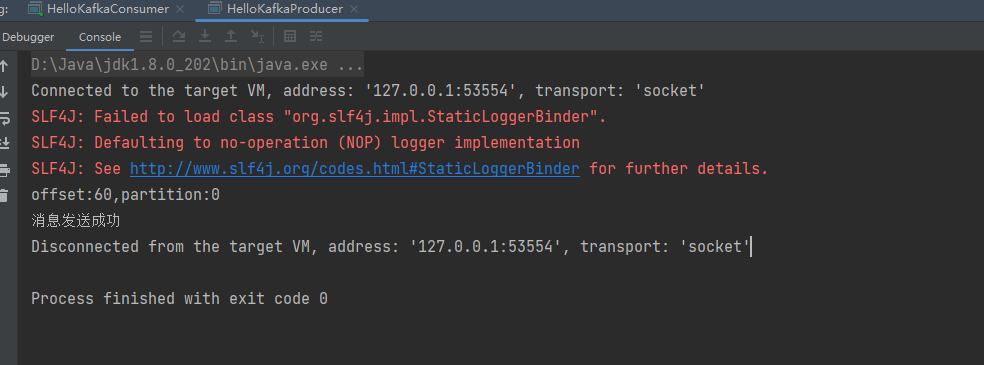
public class HelloKafkaProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址,9092kafka默认端口properties.put("bootstrap.servers","192.168.140.103:9092");//补充一下: 配置多台的服务 用,分割, 其中一个宕机,生产者 依然可以连上(集群)// 设置String的序列化 (对象-》二进制字节数组 : 能够在网络上传输 )properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {ProducerRecord<String,String> record;try {// 构建消息record = new ProducerRecord<String,String>("llp-topic", "nickname","llp0");// 发送消息producer.send(record);System.out.println("消息发送成功");} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}}
测试结果
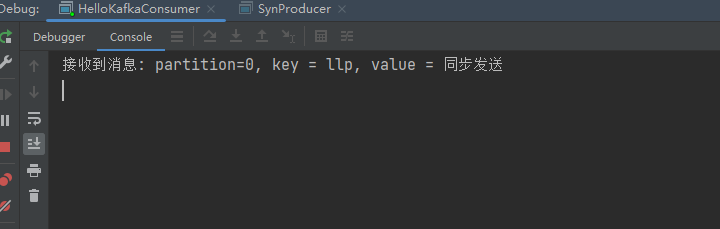
1.2同步发送
/*** 类说明:发送消息--同步模式*/
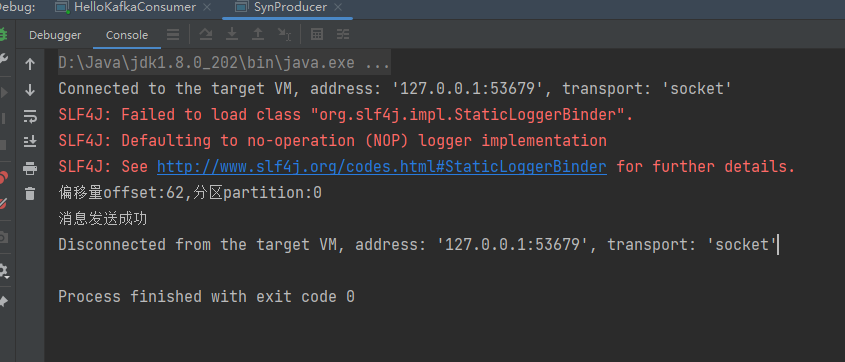
public class SynProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","192.168.140.103:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {ProducerRecord<String,String> record;try {// 构建消息record = new ProducerRecord<String,String>("llp-topic", "llp","同步发送");// 发送消息Future<RecordMetadata> future =producer.send(record);RecordMetadata recordMetadata = future.get();if(null!=recordMetadata){System.out.println("偏移量offset:"+recordMetadata.offset()+","+"分区partition:"+recordMetadata.partition());}System.out.println("消息发送成功");} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}}
测试结果
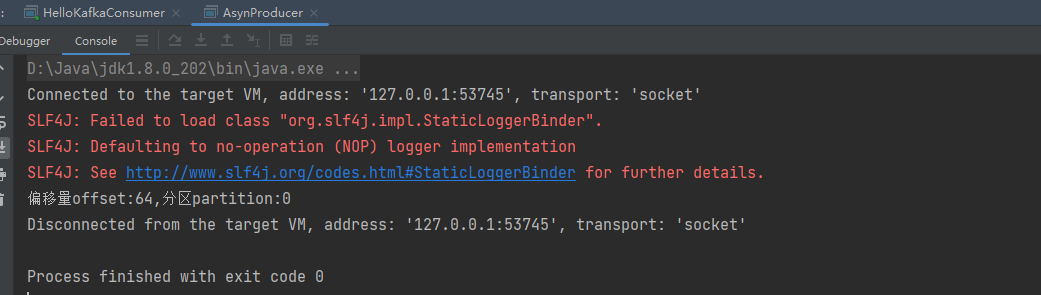
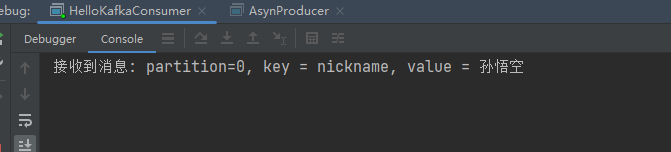
1.3 异步发送
/*** 类说明:发送消息--异步模式*/
public class AsynProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","192.168.140.103:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {ProducerRecord<String,String> record;try {// 构建消息record = new ProducerRecord<String,String>("llp-topic", "nickname","孙悟空");// 发送消息producer.send(record, new Callback() {public void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null){// 没有异常,输出信息到控制台System.out.println("偏移量offset:"+recordMetadata.offset()+"," +"分区partition:"+recordMetadata.partition());} else {// 出现异常打印e.printStackTrace();}}});} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}
}
测试结果
3. 消费者群组
Kafka里消费者从属于消费者群组,一个群组里的消费者订阅的都是同一个主题,每个消费者接收主题一部分分区的消息。
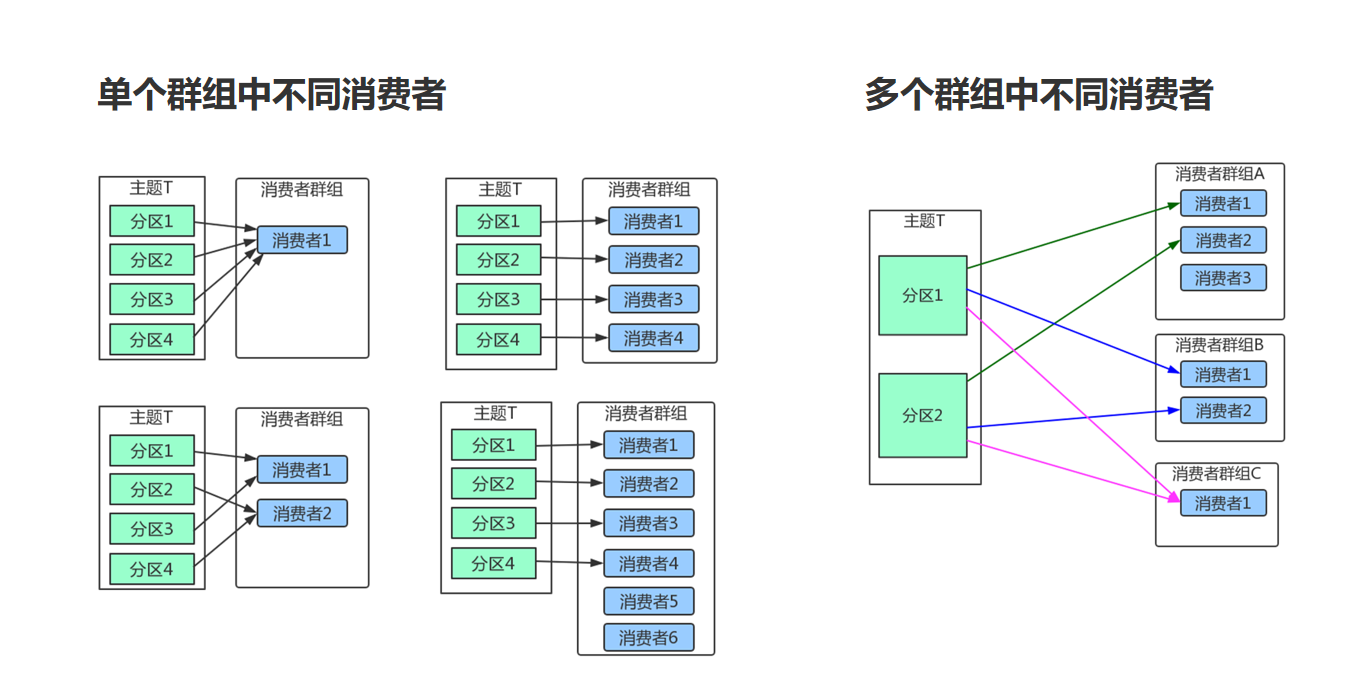
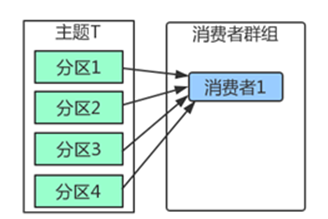
如上图,主题T有4个分区,群组中只有一个消费者,则该消费者将收到主题T1全部4个分区的消息。
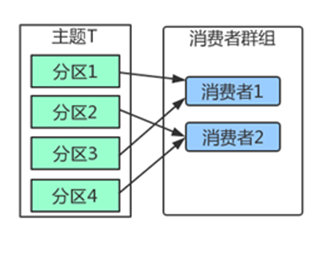
如上图,在群组中增加一个消费者2,那么每个消费者将分别从两个分区接收消息,上图中就表现为消费者1接收分区1和分区3的消息,消费者2接收分区2和分区4的消息。
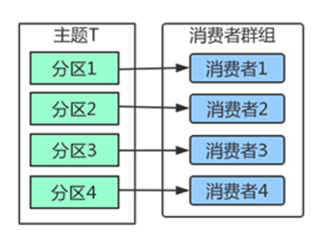
如上图,在群组中有4个消费者,那么每个消费者将分别从1个分区接收消息。
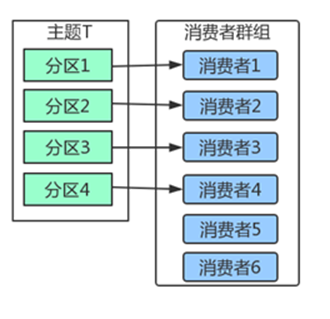
但是,当我们增加更多的消费者,超过了主题的分区数量,就会有一部分的消费者被闲置,不会接收到任何消息。
往消费者群组里增加消费者是进行横向伸缩能力的主要方式。所以我们有必要为主题设定合适规模的分区,在负载均衡的时候可以加入更多的消费者。但是要记住,一个群组里消费者数量超过了主题的分区数量,多出来的消费者是没有用处的。
4.序列化
创建生产者对象必须指定序列化器,默认的序列化器并不能满足我们所有的场景。我们完全可以自定义序列化器。只要实现org.apache.kafka.common.serialization.Serializer接口即可。
- 举个例子,比如我现在需要传输一个user类的实体对象
user实体类
/*** 类说明:实体类*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {private int id;private String name;public User(int id) {this.id = id;}
}
自定义序列化器,在生产者端进行指定
/*** 类说明:自定义序列化器*/
public class UserSerializer implements Serializer<User> {public void configure(Map<String, ?> configs, boolean isKey) {//do nothing}public byte[] serialize(String topic, User data) {try {byte[] name;int nameSize;if(data==null){return null;}if(data.getName()!=null){name = data.getName().getBytes("UTF-8");//字符串的长度nameSize = name.length;}else{name = new byte[0];nameSize = 0;}/*id的长度4个字节,字符串的长度描述4个字节,字符串本身的长度nameSize个字节*/ByteBuffer buffer = ByteBuffer.allocate(4+4+nameSize);buffer.putInt(data.getId());//4buffer.putInt(nameSize);//4buffer.put(name);//nameSizereturn buffer.array();} catch (Exception e) {throw new SerializationException("Error serialize User:"+e);}}public void close() {//do nothing}
}
反序列化器,在消费者端指定
/*** 类说明:自定义反序列化器*/
public class UserDeserializer implements Deserializer<User> {public void configure(Map<String, ?> configs, boolean isKey) {//do nothing}public User deserialize(String topic, byte[] data) {try {if(data==null){return null;}if(data.length<8){throw new SerializationException("Error data size.");}ByteBuffer buffer = ByteBuffer.wrap(data);int id;String name;int nameSize;id = buffer.getInt();nameSize = buffer.getInt();byte[] nameByte = new byte[nameSize];buffer.get(nameByte);name = new String(nameByte,"UTF-8");return new User(id,name);} catch (Exception e) {throw new SerializationException("Error Deserializer DemoUser."+e);}}public void close() {//do nothing}
}
生产者
/*** 类说明:发送消息--value使用自定义序列化*/
public class ProducerUser {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);// 设置value的自定义序列化properties.put("value.serializer", UserSerializer.class);// 构建kafka生产者对象KafkaProducer<String,User> producer = new KafkaProducer<String, User>(properties);try {ProducerRecord<String,User> record;try {// 构建消息record = new ProducerRecord<String,User>("llp-user", "teacher",new User(1,"孙悟空"));// 发送消息producer.send(record);System.out.println("message is sent.");} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}
}
消费者
/*** 类说明:*/
public class ConsumerUser {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);// 设置自定义的反序列化properties.put("value.deserializer", UserDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"ConsumerOffsets");// 构建kafka消费者对象KafkaConsumer<String,User> consumer = new KafkaConsumer<String, User>(properties);try {consumer.subscribe(Collections.singletonList("llp-user"));// 调用消费者拉取消息while(true){// 每隔1秒拉取一次消息ConsumerRecords<String, User> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, User> record:records){String key = record.key();User user = record.value();System.out.println("接收到消息: key = " + key + ", value = " + user.toString());}}} finally {// 释放连接consumer.close();}}
}
测试结果
自定义序列化容易导致程序的脆弱性。举例,在我们上面的实现里,我们有多种类型的消费者,每个消费者对实体字段都有各自的需求,比如,有的将字段变更为long型,有的会增加字段,这样会出现新旧消息的兼容性问题。特别是在系统升级的时候,经常会出现一部分系统升级,其余系统被迫跟着升级的情况。
解决这个问题,可以考虑使用自带格式描述以及语言无关的序列化框架。比如Protobuf,Kafka官方推荐的Apache Avro
5.分区
因为在Kafka中一个topic可以有多个partition,所以当一个生产发送消息,这条消息应该发送到哪个partition,这个过程就叫做分区。
当然,我们在新建消息的时候,我们可以指定partition,只要指定partition,那么分区器的策略则失效。

5.1 Kafka3种分区分配策略
在我们的代码中可以看到,生产者参数中是可以选择分区器的。
注意,在测试之前我修改了server.properties中每个主题默认的分区数
# 配置每个主题默认的分区数
num.partitions=4
1.DefaultPartitioner 默认分区策略
全路径类名:org.apache.kafka.clients.producer.internals.DefaultPartitioner
- 如果消息中指定了分区,则使用它
- 如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
- 如果不存在分区或key,则会使用粘性分区策略
采用默认分区的方式,键的主要用途有两个:
一,用来决定消息被写往主题的哪个分区,拥有相同键的消息将被写往同一个分区。
二,还可以作为消息的附加消息。
2.RoundRobinPartitioner 分区策略
全路径类名:org.apache.kafka.clients.producer.internals.RoundRobinPartitioner
- 如果消息中指定了分区,则使用它
- 将消息平均的分配到每个分区中。
即key为null,那么这个时候一般也会采用RoundRobinPartitioner
3.UniformStickyPartitioner 纯粹的粘性分区策略
全路径类名:org.apache.kafka.clients.producer.internals.UniformStickyPartitioner
他跟DefaultPartitioner 分区策略的唯一区别就是。
DefaultPartitionerd 如果有key的话,那么它是按照key来决定分区的,这个时候并不会使用粘性分区
UniformStickyPartitioner 是不管你有没有key, 统一都用粘性分区来分配
另外关于粘性分区策略
在producer.properties中配置
# 配置生产者发送消息之前延迟多长时间在进行发送,默认0
#linger.ms=# 对发送到分区的多个记录进行批处理时的默认批处理大小(以字节为单位)默认16K
#batch.size=# 配置缓冲区的总大小,默认32M
#buffer.memory=
当linger.ms 和 batch.size有一个条件满足时,kafka客户端就会立即推送消息到kafka服务
https://bbs.huaweicloud.com/blogs/348729?utm_source=oschina&utm_medium=bbs-ex&utm_campaign=other&utm_content=content
5.2自定义分区器
在kafka中,我们可以通过实现Partitioner接口来自定义分区规则
/*** 类说明:自定义分区器,以value值进行分区*/
public class SelfPartitioner implements Partitioner {public int partition(String topic, Object key, byte[] keyBytes,Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);int num = partitionInfos.size();// 来自DefaultPartitioner的处理,在存在key值时是根据key值去计算分区的Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;// 我们定义一个分区器,根据value值去做计算消息所属分区int parId = Utils.toPositive(Utils.murmur2(valueBytes)) % num;return parId;}public void close() {//do nothing}public void configure(Map<String, ?> configs) {//do nothing}}
生产者,指定自定义分区器
/*** 类说明:使用value值的分区器*/
public class SelfPartitionProducer {private static KafkaProducer<String,String> producer = null;public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 设置自定义分区器properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, SelfPartitioner.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {ProducerRecord<String,String> record;try {for (int i =0;i<10;i++){// 构建消息record = new ProducerRecord<String,String>("llp-topic1", "teacher","孙悟空"+i);// 发送消息Future<RecordMetadata> future =producer.send(record);RecordMetadata recordMetadata = future.get();if(null!=recordMetadata){System.out.println(i+","+"offset:"+recordMetadata.offset()+","+"partition:"+recordMetadata.partition());}}} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}}
消费者
public class GroupAConusmer1 {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"groupA");// 构建kafka消费者对象KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);try {consumer.subscribe(Collections.singletonList("llp-topic1"));// 调用消费者拉取消息while(true){// 每隔1秒拉取一次消息ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){String key = record.key();String value = record.value();int partition = record.partition();System.out.println("接收到消息:"+",partition ="+partition +", key = " + key + ", value = " + value);}}} finally {// 释放连接consumer.close();}}}
测试结果
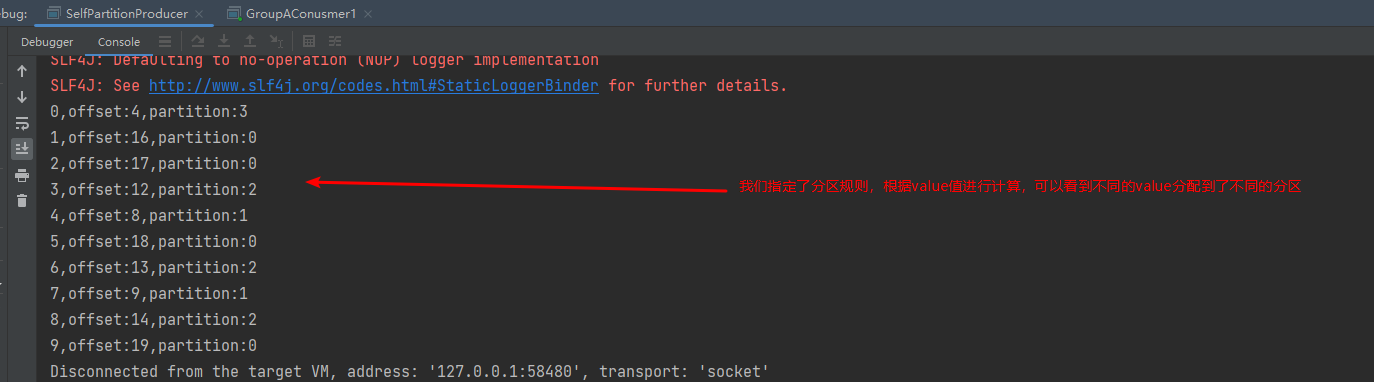
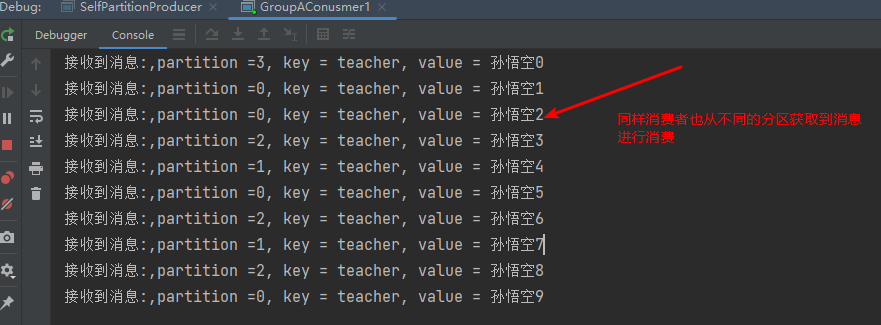
6.生产缓冲机制
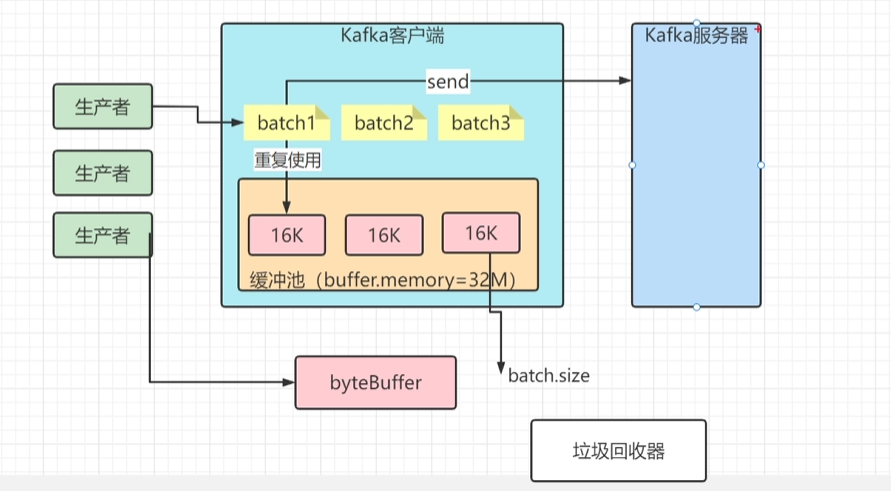
客户端发送消息给kafka服务器的时候、消息会先写入一个内存缓冲中,然后直到多条消息组成了一个Batch,才会一次网络通信把Batch发送过去。producer.properties主要有以下参数:
buffer.memory
设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果数据产生速度大于向broker发送的速度,导致生产者空间不足,producer会阻塞或者抛出异常。缺省33554432 (32M)
buffer.memory: 所有缓存消息的总体大小超过这个数值后,就会触发把消息发往服务器。此时会忽略batch.size和linger.ms的限制。
buffer.memory的默认数值是32 MB,对于单个 Producer 来说,可以保证足够的性能。 需要注意的是,如果您在同一个JVM中启动多个 Producer,那么每个 Producer 都有可能占用 32 MB缓存空间,此时便有可能触发 OOM。
batch.size
当多个消息被发送同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次内存被填满后,批次里的所有消息会被发送出去。但是生产者不一定都会等到批次被填满才发送,半满甚至只包含一个消息的批次也有可能被发送(linger.ms控制)。缺省16384(16k) ,如果一条消息超过了批次的大小,会写不进去。
linger.ms
指定了生产者在发送批次前等待更多消息加入批次的时间。它和batch.size以先到者为先。也就是说,一旦我们获得消息的数量够batch.size的数量了,他将会立即发送而不顾这项设置,然而如果我们获得消息字节数比batch.size设置要小的多,我们需要“linger”特定的时间以获取更多的消息。这个设置默认为0,即没有延迟。设定linger.ms=5,例如,将会减少请求数目,但是同时会增加5ms的延迟,但也会提升消息的吞吐量。
为何要设计缓冲机制
1、减少IO的开销(单个 ->批次)但是这种情况基本上也只是linger.ms配置>0的情况下才会有,因为默认inger.ms=0的,所以基本上有消息进来了就发送了,跟单条发送是差不多!!
2、减少Kafka中Java客户端的GC。
比如缓冲池大小是32MB。然后把32MB划分为N多个内存块,比如说一个内存块是16KB(batch.size),这样的话这个缓冲池里就会有很多的内存块。
你需要创建一个新的Batch,就从缓冲池里取一个16KB的内存块就可以了,然后这个Batch就不断的写入消息
下次别人再要构建一个Batch的时候,再次使用缓冲池里的内存块就好了。这样就可以利用有限的内存,对他不停的反复重复的利用。因为如果你的Batch使用完了以后是把内存块还回到缓冲池中去,那么就不涉及到垃圾回收了。
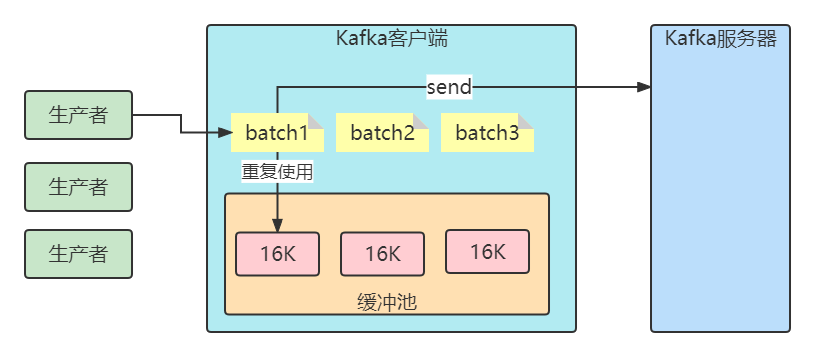
7.消费者偏移量提交
一般情况下,我们调用poll方法的时候,broker返回的是生产者写入Kafka同时kafka的消费者提交偏移量,这样可以确保消费者消息消费不丢失也不重复,所以一般情况下Kafka提供的原生的消费者是安全的,但是事情会这么完美吗?
自动提交
最简单的提交方式是让消费者自动提交偏移量。 如果enable.auto.commit被设为 true,消费者会自动把从poll()方法接收到的最大偏移量提交上去。提交时间间隔由auto.commit.interval.ms控制,默认值是5s。
自动提交是在轮询里进行的,消费者每次在进行轮询时会检査是否该提交偏移量了,如果是,那么就会提交从上一次轮询返回的偏移量。
不过,在使用这种简便的方式之前,需要知道它将会带来怎样的结果。
假设我们仍然使用默认的5s提交时间间隔, 在最近一次提交之后的3s发生了再均衡,再均衡之后,消费者从最后一次提交的偏移量位置开始读取消息。这个时候偏移量已经落后了3s,所以在这3s内到达的消息会被重复处理。可以通过修改提交时间间隔来更频繁地提交偏移量, 减小可能出现重复消息的时间窗, 不过这种情况是无法完全避免的。
在使用自动提交时,每次调用轮询方法都会把上一次调用返回的最大偏移量提交上去,它并不知道具体哪些消息已经被处理了,所以在再次调用之前最好确保所有当前调用返回的消息都已经处理完毕(enable.auto.comnit被设为 true时,在调用 close()方法之前也会进行自动提交)。一般情况下不会有什么问题,不过在处理异常或提前退出轮询时要格外小心。
/*** 类说明:消费者 手动提交: 自定义的方式*/
public class ConsumerSpecial {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"ConsumerOffsets");/*取消自动提交*/properties.put("enable.auto.commit",false);// 构建kafka消费者对象KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);//当前偏移量Map<TopicPartition, OffsetAndMetadata> currOffsets = new HashMap<TopicPartition, OffsetAndMetadata>();int count = 0;try {consumer.subscribe(Collections.singletonList("llp-topic1"));// 调用消费者拉取消息while(true){// 每隔1秒拉取一次消息ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){String key = record.key();String value = record.value();System.out.println("接收到消息: key = " + key + ", value = " + value);currOffsets.put(new TopicPartition(record.topic(),record.partition()),new OffsetAndMetadata(record.offset()+1,"no meta"));count++;if(count%10==0){//每10条提交一次(特定的偏移量),下一次10条数据会接着在上一次提交的偏移量后进行消费consumer.commitAsync(currOffsets,null);}}}}catch (CommitFailedException e) {System.out.println("Commit failed:");e.printStackTrace();}finally {try {consumer.commitSync(currOffsets);//同步提交(这里也可以)} finally {consumer.close();}}}}
消费者的配置参数
auto.offset.reset
earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
只要group.Id不变,不管auto.offset.reset 设置成什么值,都从上一次的消费结束的地方开始消费。
/*** 类说明:消费者入门:自动提交的消费模式*/
public class GroupBConusmer1 {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"groupB");properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); //最早:从头开始消费//properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest"); // 已提交的offset开始消费// 构建kafka消费者对象KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);try {consumer.subscribe(Collections.singletonList("llp-topic1"));// 调用消费者拉取消息while(true){// 每隔1秒拉取一次消息ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){String key = record.key();String value = record.value();int partition = record.partition();System.out.println("接收到消息:"+",partition ="+partition +", key = " + key + ", value = " + value);}}} finally {// 释放连接consumer.close();}}}
相关文章:
Kafka生产消费流程
Kafka生产消费流程 1.Kafka一条消息发送和消费的流程图(非集群) 2.三种发送方式 准备工作 创建maven工程,引入依赖 <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.3.1…...

c 小熊猫 c++ IDE编译ffmpeg 设置
菜单-》运行-》运行参数->编译器->编译器配置集->链接时加入下列选项 : -I /usr/local/ffmpeg/include -L /usr/local/ffmpeg/lib -lavformat -lavdevice -lavfilter -lavcodec -lavutil -lswscale -lswresample -lm 本机ffmpeg存储位置:inclu…...

【Java】十年老司机转开发语言,新小白从学习路线图开始
欢迎来到《小5讲堂》 大家好,我是全栈小5。 这是《Java》序列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握…...
5.3 Verilog 带参数例化
5.3 Verilog 带参数例化 分类 Verilog 教程 关键词: defparam,参数,例化,ram 当一个模块被另一个模块引用例化时,高层模块可以对低层模块的参数值进行改写。这样就允许在编译时将不同的参数传递给多个相同名字的模块…...

边缘计算的挑战和机遇
边缘计算是一种分布式计算框架,它将应用程序、数据和计算服务带离集中式数据中心,靠近用户和数据源的位置。这种方法可以减少延迟,提高服务速度,并可能改善数据安全性和隐私性。然而,边缘计算同时也面临着挑战…...

Mybatis基础---------增删查改
目录结构 增删改 1、新建工具类用来获取会话对象 import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.apache.ibatis.io.Resources;import java.io…...

CentOS查看修改时间
经常玩docker的朋友应该都知道,有很多的镜像运行起来后,发现容器里的系统时间不对,一般是晚被北京时间8个小时(不一定)。 这里合理怀疑是镜像给的初始时区是世界标准时间(也叫协调世界时间)。 有…...
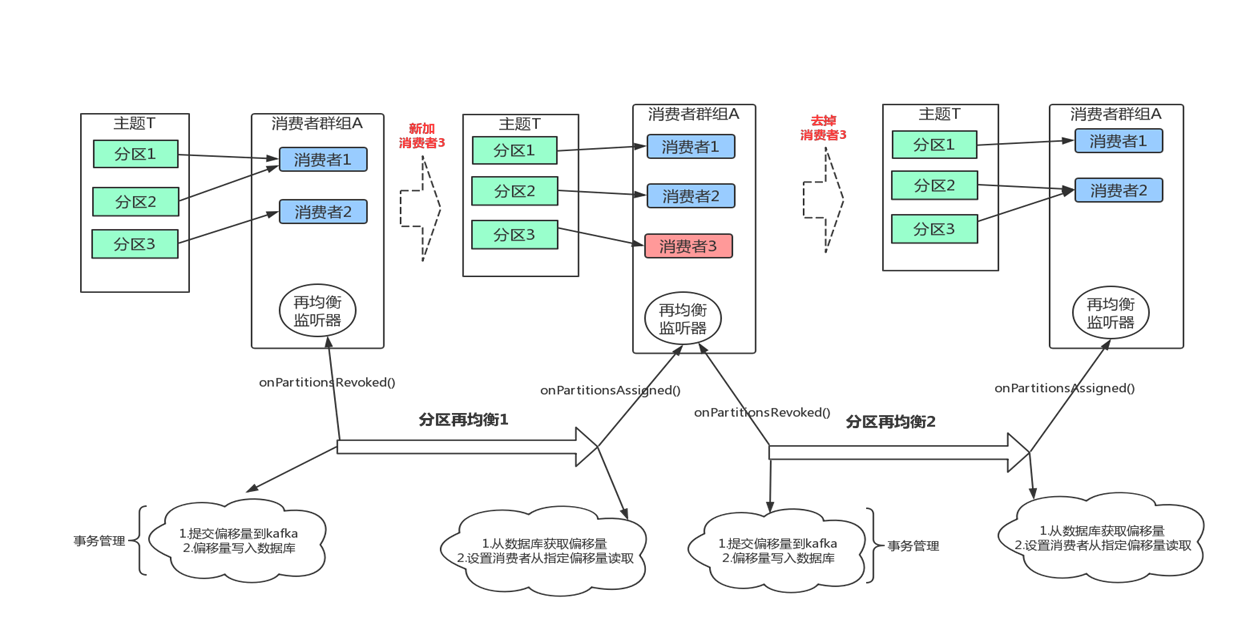
Kafka消费流程
Kafka消费流程 消息是如何被消费者消费掉的。其中最核心的有以下内容。 1、多线程安全问题 2、群组协调 3、分区再均衡 1.多线程安全问题 当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的。 对于线程安全&…...
)
RPC原理介绍与使用(@RpcServiceAnnotation)
Java RPC(Remote Procedure Call,远程过程调用)是一种用于实现分布式系统中不同节点之间通信的技术。它允许在不同的计算机或进程之间调用远程方法,就像调用本地方法一样。 ** 一.Java RPC的原理如下: ** 定义接口&…...

力扣labuladong——一刷day94
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言二叉堆(Binary Heap)没什么神秘,性质比二叉搜索树 BST 还简单。其主要操作就两个,sink(下沉…...

Vim 是一款强大的文本编辑器,广泛用于 Linux 和其他 Unix 系统。以下是 Vim 的一些基本用法
Vim 是一款强大的文本编辑器,广泛用于 Linux 和其他 Unix 系统。以下是 Vim 的一些基本用法: 打开文件: vim filename 基本移动: 使用箭头键或 h, j, k, l 分别向左、下、上、右移动。Ctrl f: 向前翻页。Ctrl b: 向后翻页。…...
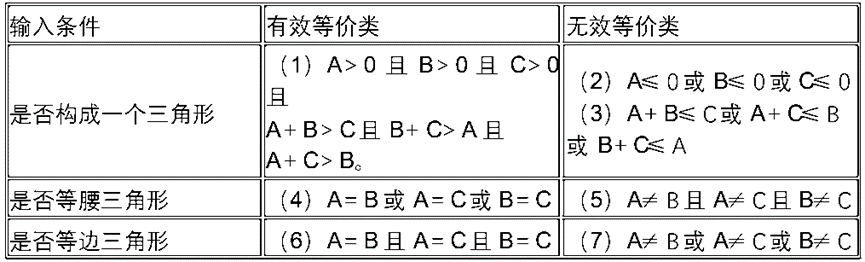
软件工程:黑盒测试等价分类法相关知识和多实例分析
目录 一、黑盒测试和等价分类法 1. 黑盒测试 2. 等价分类法 二、黑盒测试等价分类法实例分析 1. 工厂招工年龄测试 2. 规定电话号码测试 3. 八位微机测试 4. 三角形判断测试 一、黑盒测试和等价分类法 1. 黑盒测试 黑盒测试就是根据被测试程序功能来进行测试…...

stable-diffusion 学习笔记
必看文档: 万字长篇!超全Stable Diffusion AI绘画参数及原理详解 - 知乎 (提示词)语法控制 常用语法: 加权:() 或 {} 降权:[](word)//将括号内的提示词权重提高 1.1 倍 ((word))//将括号内的提示…...

手写webpack核心原理,支持typescript的编译和循环依赖问题的解决
主要知识点 babel读取代码的import语句算法:bfs遍历依赖图为浏览器定义一个require函数的polyfill算法:用记忆化搜索解决require函数的循环依赖问题 Quick Start GitHub:https://github.com/Hans774882968/mini-webpack npm install npm…...

开箱即用之MyBatisPlus XML 自定义分页
调用方法 import com.baomidou.mybatisplus.extension.plugins.pagination.Page;public Page<User> queryListByPage(User user) { Page<User> page new Page<>(1, 12); return userMapper.queryListByPage(page, user); } mapper接口 import co…...
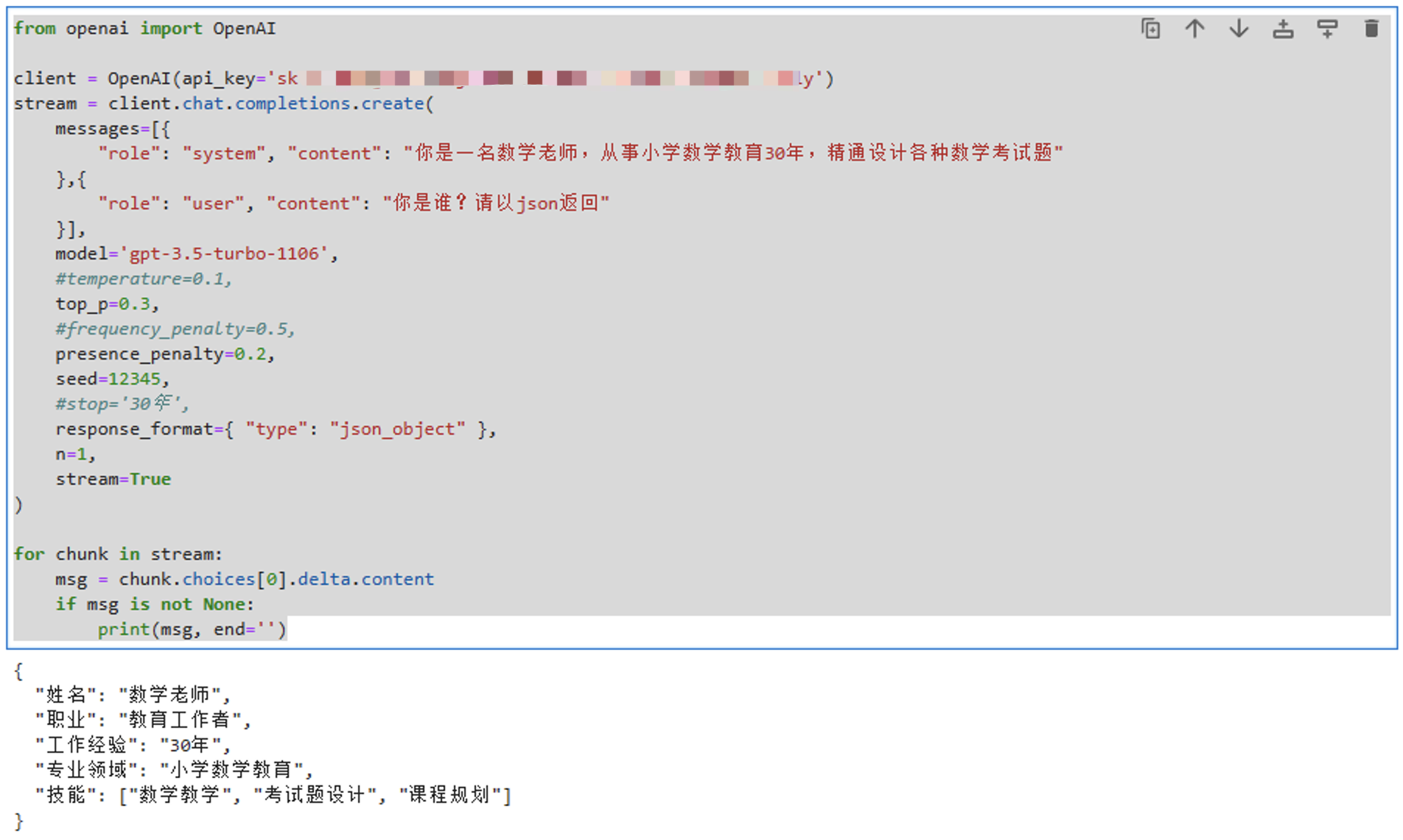
GPT应用开发:运行你的第一个聊天程序
本系列文章介绍基于OpenAI GPT API开发应用的方法,适合从零开始,也适合查缺补漏。 本文首先介绍基于聊天API编程的方法。 环境搭建 很多机器学习框架和类库都是使用Python编写的,OpenAI提供的很多例子也是Python编写的,所以为了…...
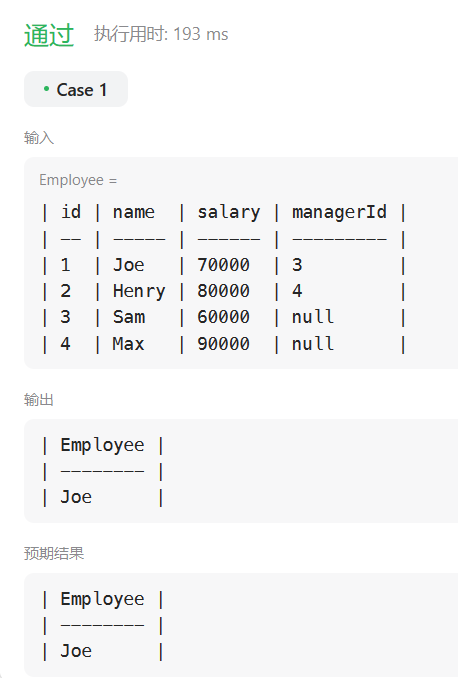
力扣刷MySQL-第一弹(详细解析)
🎉欢迎您来到我的MySQL基础复习专栏 ☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹 ✨博客主页:小小恶斯法克的博客 🎈该系列文章专栏:力扣刷题讲解-MySQL 🍹文章作者技术和水平很有限,如果文中出…...

Xcode 15 for Mac:超越开发的全新起点
作为一名开发人员,你是否正在寻找一款强大而高效的开发工具,来帮助你在Mac上构建出卓越的应用程序?那么,Xcode 15就是你一直在寻找的答案。 Xcode 15是苹果公司最新推出的一款集成开发环境(IDE)࿰…...
)
2021腾讯、华为前端面试题集(基础篇)
Vue 面试题 生命周期函数面试题 1.什么是 vue 生命周期2.vue 生命周期的作用是什么 3.第一次页面加载会触发哪几个钩子 4.简述每个周期具体适合哪些场景 5.created 和 mounted 的区别 6.vue 获取数据在哪个周期函数 7.请详细说下你对 vue 生命周期的理解? **vue 路由…...
怎么修改或移除WordPress后台仪表盘概览底部的版权信息和主题信息?
前面跟大家分享『WordPress怎么把后台左上角的logo和评论图标移除?』和『WordPress后台底部版权信息“感谢使用 WordPress 进行创作”和版本号怎么修改或删除?』,其实在WordPress后台仪表盘的“概览”底部还有一个WordPress版权信息和所使用的…...

RefineDet检测结果可视化:使用refinedet_demo.py轻松实现目标标注
RefineDet检测结果可视化:使用refinedet_demo.py轻松实现目标标注 【免费下载链接】RefineDet Single-Shot Refinement Neural Network for Object Detection, CVPR, 2018 项目地址: https://gitcode.com/gh_mirrors/re/RefineDet RefineDet是一种高效的单阶…...
LibreSprite:为什么这款开源像素动画软件能成为独立开发者的首选?
LibreSprite:为什么这款开源像素动画软件能成为独立开发者的首选? 【免费下载链接】LibreSprite Animated sprite editor & pixel art tool -- Fork of the last GPLv2 commit of Aseprite 项目地址: https://gitcode.com/gh_mirrors/li/LibreSpri…...

Gemini3.1Pro和GPT5.5写代码到底谁更强五类任务实测数据说
做多模型编码能力横向对比测试时用了AI模型聚合平台,一站接入两个模型方便跑同一套编码任务。Gemini 3.1 Pro在SWE-Bench Verified拿到80.6%。GPT-5.5在Terminal-Bench拿到82.7%。分数接近但写代码的实际体验和分数不是一回事。这次用五类真实开发任务做了一轮系统对…...

AI如何重塑移动App开发:从功能交付到智能服务的范式跃迁
1. 项目概述:当手机App开发不再只是“写代码”,而变成一场数据驱动的智能进化“How AI and ML are Turning the Mobile App Development Industry into a Smart Industry?”——这个标题不是一句空泛的行业口号,而是我过去三年深度参与17个中…...

ops-math:昇腾 NPU 的数学算子库
ops-math:昇腾 NPU 的数学算子库 之前帮朋友看一个数学密集型模型(做科学计算的,不是 AI 模型)的适配代码,发现他自己手写了很多数学函数(Sin/Cos/Exp/Log 等)——在 NPU 上跑,性能只…...

河北邯郸职称评审的方式有哪几种?
1、以考代评以考代评就是指有些专业技术岗位可以通过参加考试而不是递交繁琐的材料来获得专业技术职务资格。只要顺利通过国家指定的科目考试,你就可以获得专业技术资格,省去了各种审核流程的烦恼。2、只评不考只评不考是目前zui常见、适用范围zui广的一…...

基于MAX 10 FPGA的Z80与8051双核单板计算机设计与实现
1. 项目概述与核心价值最近在整理工作室的旧物,翻出了一堆老古董——Z80和8051的芯片。看着这些曾经叱咤风云的处理器,一个念头冒了出来:能不能用现代的技术,把它们“复活”在一块板子上,做一个集成的单板计算机&#…...

【能力边界】大模型到底不能做什么?盘点AI在软件测试中的7个致命缺陷
开篇:为什么“会用大模型”≠“会用大模型做测试”? 2026年5月,AI编程工具的渗透速度超乎想象——GitHub Copilot推出永久免费个人版,Cursor的Composer 2让Agent模式成为日常开发标配,Claude Code用终端交互重新定义人与AI的协作方式。据实测对比,Cursor在一次跨模块任务…...

王炸!史上最强的智慧园区管理系统,java最新技术栈,支持信创!
一、项目简介本软件是一款面向智慧园区与智慧楼宇的综合管理系统,采用先进的微服务架构(SpringCloud)、JDK 17、Spring Boot 3.2、MySQL、Vue3、Vite 和 UniApp 技术栈,支持小程序、H5、公众号、App 多端适配,前后端分…...

机器学习驱动的中微子-核散射截面建模:从数据学习到振荡分析
1. 项目概述与核心价值 中微子物理正步入一个前所未有的“精密测量”时代。像DUNE(深地下中微子实验)这样的下一代长基线实验,目标是将中微子混合参数的测量精度推至百分之一量级。然而,一个长期存在的“拦路虎”限制了这一目标的…...