【MySQL】数据处理之增删改
文章目录
- 一、增加(插入)INSERT INTO...VALUES(...,...)
- VALUES的方式添加
- 情况一:为表的所有字段按默认顺序插入数据
- 情况二:为表的指定字段插入数据
- 情况三:同时插入多条记录
- 将查询结果插入到表中
- 二、修改(更新)UPDATE...SET...
- 使用 **WHERE** 子句指定需要更新的数据
- 三、删除 DELETE FROM ...
- 使用 WHERE 子句删除指定的记录
- 四、计算列
- 综合案例
一、增加(插入)INSERT INTO…VALUES(…,…)
VALUES的方式添加
情况一:为表的所有字段按默认顺序插入数据
- 一次只能向表中插入一条数据
格式:
INSERT INTO 表名
VALUES (value1,value2,....);
值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同
举例:
INSERT INTO departments
VALUES(5050,'鹅国',NULL,3200);

情况二:为表的指定字段插入数据
- 只向部分字段中插入值,而其他字段的值为表定义时的默认值
- 表名后面指定的列名,在values内要一一对应,否则报错
格式:
INSERT INTO 表名(column1 [, column2, …, columnn])
VALUES (value1 [,value2, …, valuen]);
举例:
INSERT INTO departments(department_id,department_name)
VALUES(404,666);
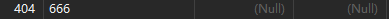
情况三:同时插入多条记录
格式:
所有字段
INSERT INTO table_name
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
部分字段
INSERT INTO table_name(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
举例:
INSERT INTO departments
VALUES
(1017,'散人',NULL,3000),
(1010,'KB',NULL,2800);

总结:
VALUES也可以写成VALUE,但是VALUES是标准写法。字符和日期型数据应包含在单引号中。
将查询结果插入到表中
INSERT还可以将SELECT语句查询的结果插入到表中
格式:
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
- 在 INSERT 语句中加入子查询。
- 不必书写 VALUES 子句。
- 子查询中的值列表应与 INSERT 子句中的列名对应。
举例:
添加所有字段
INSERT INTO emp2
SELECT *
FROM employees
WHERE department_id = 90;

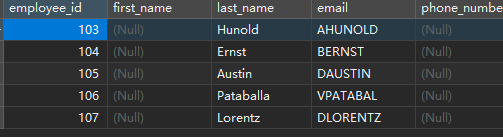
添加部分字段:
INSERT INTO emp1(employee_id,last_name,salary,email,hire_date,job_id)
SELECT employee_id,last_name,salary,email,hire_date,job_id
FROM employees
WHERE job_id LIKE '%IT%';
二、修改(更新)UPDATE…SET…
格式:
UPDATE table_name
SET column1=value1, column2=value2, … , column=valuen
[WHERE condition]
- 可以一次更新多条数据。
- 如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
使用 WHERE 子句指定需要更新的数据
UPDATE departments
SET department_name = '紫色'
WHERE department_id = 404;

如果省略 WHERE 子句,则表中的所有数据都将被更新
这种情况一边查找一边修改,不能这样写:这是错的改不了
UPDATE employees
SET department_id = 4040
WHERE department_id = 404;
三、删除 DELETE FROM …

DELETE FROM table_name [WHERE <condition>];
“[WHERE <condition>]”为可选参数,指定删除条件。
如果没有WHERE子句,DELETE语句将删除表中的所有记录。
举例:
使用 WHERE 子句删除指定的记录

如果省略
WHERE子句,则表中的全部数据将被删除
四、计算列
先定义 两个列 , 第三个列是前两个列的综合(相加的数or…)
CREATE TABLE tb1(
id INT,
a INT,
b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL
);
CREATE TABLE 和 ALTER TABLE 中都支持增加计算列
INSERT INTO tb1(a,b)
VALUES (100,200);

UPDATE tb1
SET a = 500;

综合案例
# 1、创建数据库test01_library
CREATE DATABASE IF NOT EXISTS test01_library;# 2、使用当前数据库
USE test01_library;# 3、当创建数据库时忘记添加字符集时 -> 修改数据库字符集
ALTER DATABASE test01_library CHARACTER SET 'utf8';# 4、创建表
CREATE TABLE IF NOT EXISTS books
(id INT,name VARCHAR(50),authors VARCHAR(100),price FLOAT,pubdate YEAR,note VARCHAR(100),num INT
);# 5、插入记录
# 1)不指定字段名称,插入第一条记录
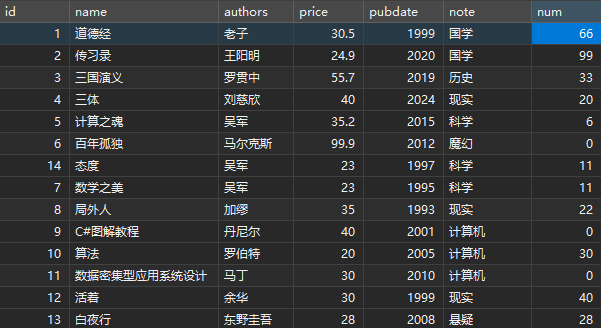
INSERT INTO books
VALUES(1,'道德经','老子',25.5,'1999','国学',66);# 2)指定所有字段名称,插入第二记录
INSERT INTO books(id,name,authors,price,pubdate,note,num)
VALUES(2,'传习录','王阳明',19.9,'2020','国学',99);# 3)同时插入多条记录(剩下的所有记录)
INSERT INTO books
VALUES
(3,'三国演义','罗贯中',55.7,'2019','历史',33),
(4,'三体','刘慈欣',11.8,'2024','科幻',20),
(5,'计算之魂','吴军',35.2,'2015','科学',6);DESC books;# 题目:
# 6、将小说类型('国学')的书的价格都增加5。
UPDATE books
SET price = price + 5
WHERE note = '国学';# 7、将作者为刘慈欣的书的价格改为40,并将说明改为现实。
UPDATE books
SET price = 40,note = '现实'
WHERE authors = '刘慈欣';# 8、删除库存为0的记录。
INSERT INTO books
VALUES(6,'百年孤独','马尔克斯',99.9,'2012','魔幻',0);DELETE FROM books
WHERE num = 0;# 题目:
INSERT INTO books(id,NAME,AUTHORS,price,pubdate,note,num)
VALUES
(7,'数学之美','吴军',23,'1995','科学',11),
(8,'局外人','加缪',35,'1993','现实',22),
(9,'C#图解教程','丹尼尔',40,2001,'计算机',0),
(10,'算法','罗伯特',20,2005,'计算机',30),
(11,'数据密集型应用系统设计','马丁',30,2010,'计算机',0),
(12,'活着','余华',30,1999,'现实',40),
(13,'白夜行','东野圭吾',28,2008,'悬疑',28);# 7、统计书名中包含'三'的书
SELECT COUNT(*)
FROM books
WHERE NAME LIKE '%三%';# 8、统计书名中包含'三'的书的数量和库存总量
SELECT COUNT(*),SUM(num)
FROM books
WHERE NAME LIKE '%三%';# 9、找出“计算机”类型的书,按照价格降序排列
SELECT name,note,price
FROM books
WHERE note = '计算机'
ORDER BY price DESC;# 10、查询图书信息,按照库存量降序排列,如果库存量相同的按照note升序排列
SELECT *
FROM books
ORDER BY num DESC,note;# 11、按照note分类统计书的数量
SELECT COUNT(*),note
FROM books
GROUP BY note;# 12、按照note分类统计书的库存量,显示库存量超过30本的
SELECT SUM(num),note
FROM books
GROUP BY note
HAVING SUM(num) > 30;# 13、查询所有图书,每页显示5本,显示第二页
SELECT *
FROM books
LIMIT 0,5; -- 第一页SELECT *
FROM books
LIMIT 5,5; -- 第二页# 14、按照note分类统计书的库存量,显示库存量最多的
SELECT SUM(num),note
FROM books
GROUP BY note
ORDER BY SUM(num) DESC
LIMIT 0,1;# 15、查询书名达到6个字符的书,不包括里面的空格
SELECT name
FROM books
WHERE CHAR_LENGTH(REPLACE(name,' ','')) >= 6;# 16、查询书名和类型,其中note值为计算机显示科学,国学显示历史
SELECT name,CASE noteWHEN '计算机' THEN'科学6666'WHEN '国学' THEN'历史66666666'ELSEnote
END
FROM books; -- 相当于switch语句# 17、查询书名、库存,其中num值超过30本的,显示滞销,大于0并低于10的,显示畅销,为0的显示无货
SELECT name,CASE WHEN num > 30 THEN'滞销'WHEN num > 0 AND num < 10 THEN'畅销'WHEN num = 0 THEN'无货'ELSE'正常'
END AS '库存状态'
FROM books; -- 相当于 ifelse# 18、统计每一种note的库存量,并合计总量
SELECT SUM(num),IFNULL(note,'合计总量') AS note
FROM books
GROUP BY note WITH ROLLUP;# 19、统计每一种note的数量,并合计总量
SELECT COUNT(*),IFNULL(note,'合计总量') AS note
FROM books
GROUP BY note WITH ROLLUP;# 20、统计库存量前三名的图书
SELECT SUM(num),name
FROM books
GROUP BY name
ORDER BY SUM(num) DESC
LIMIT 0,3SELECT * FROM books ORDER BY num DESC LIMIT 0,3;# 21、找出最早出版的一本书
SELECT name,pubdate
FROM books
ORDER BY pubdate
LIMIT 0,1;# 22、找出计算机note中价格最高的一本书
SELECT name,price
FROM books
WHERE note = '计算机'
ORDER BY price DESC
LIMIT 0,1;# 23、找出书名中字数最多的一本书,不含空格
SELECT name
FROM books
ORDER BY CHARACTER_LENGTH(REPLACE(name,' ','')) DESC
LIMIT 0,1;
相关文章:
【MySQL】数据处理之增删改
文章目录 一、增加(插入)INSERT INTO...VALUES(...,...)VALUES的方式添加情况一:为表的所有字段按默认顺序插入数据情况二:为表的指定字段插入数据情况三:同时插入多条记录 将查询结果插入到表中 二、修改(…...
利用docker的LNMP
目录 服务器环境 任务需求 服务搭建 Nginx Mysql Php 启动 wordpress 服务 服务器环境 容器 操作系统 IP地址 主要软件 nginx CentOS 7 172.20.0.10 Docker-Nginx mysql CentOS 7 172.20.0.20 Docker-Mysql php CentOS 7 172.2…...
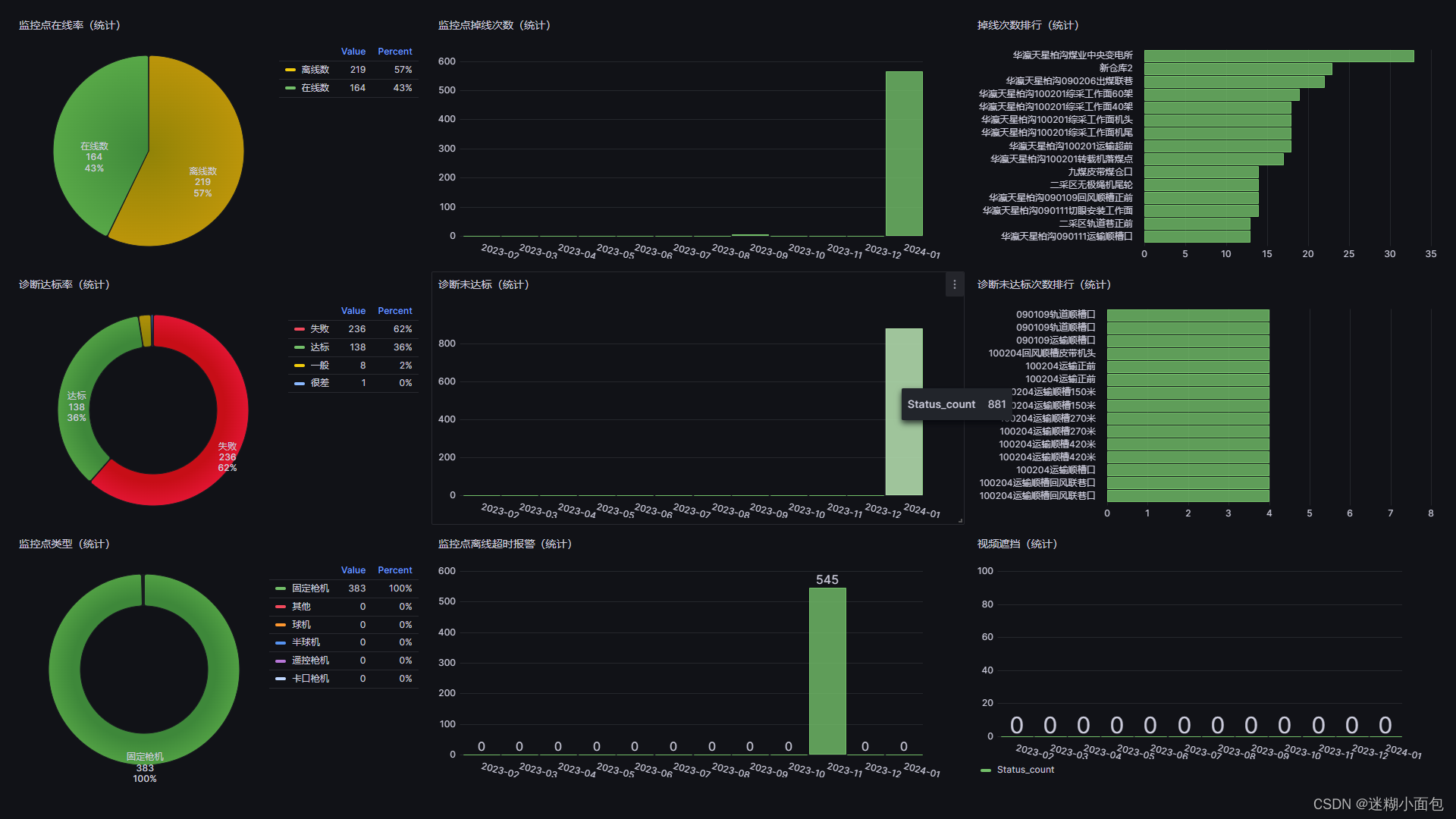
Grafana(二)Grafana 两种数据源图表展示(json-api与数据库)
一. 背景介绍 在先前的博客文章中,我们搭建了Grafana ,它是一个开源的度量分析和可视化工具,可以通过将采集的数据分析、查询,然后进行可视化的展示,接下来我们重点介绍如何使用它来进行数据渲染图表展示 Docker安装G…...

Shape-IoU——综合考量边框形状与尺度的度量
今天看到一篇文章主要是提出了一种更有效的IOU度量方法,论文地址在这里,如下所示: 摘要 边界盒回归损失作为检测器定位分支的重要组成部分,在目标检测任务中起着重要作用。现有的边界框回归方法通常考虑GT框和预测框之间的几何关…...
)
Stack详解(Java)
Stack Java 中的 Stack 是一种基于后进先出(LIFO)原则的数据结构。Stack 类实现了一个标准的堆栈,它继承自 Vector 类,并提供了一些额外的方法来支持堆栈的操作。 下面是一些 Java Stack 类的详细解释: 构造方法&…...
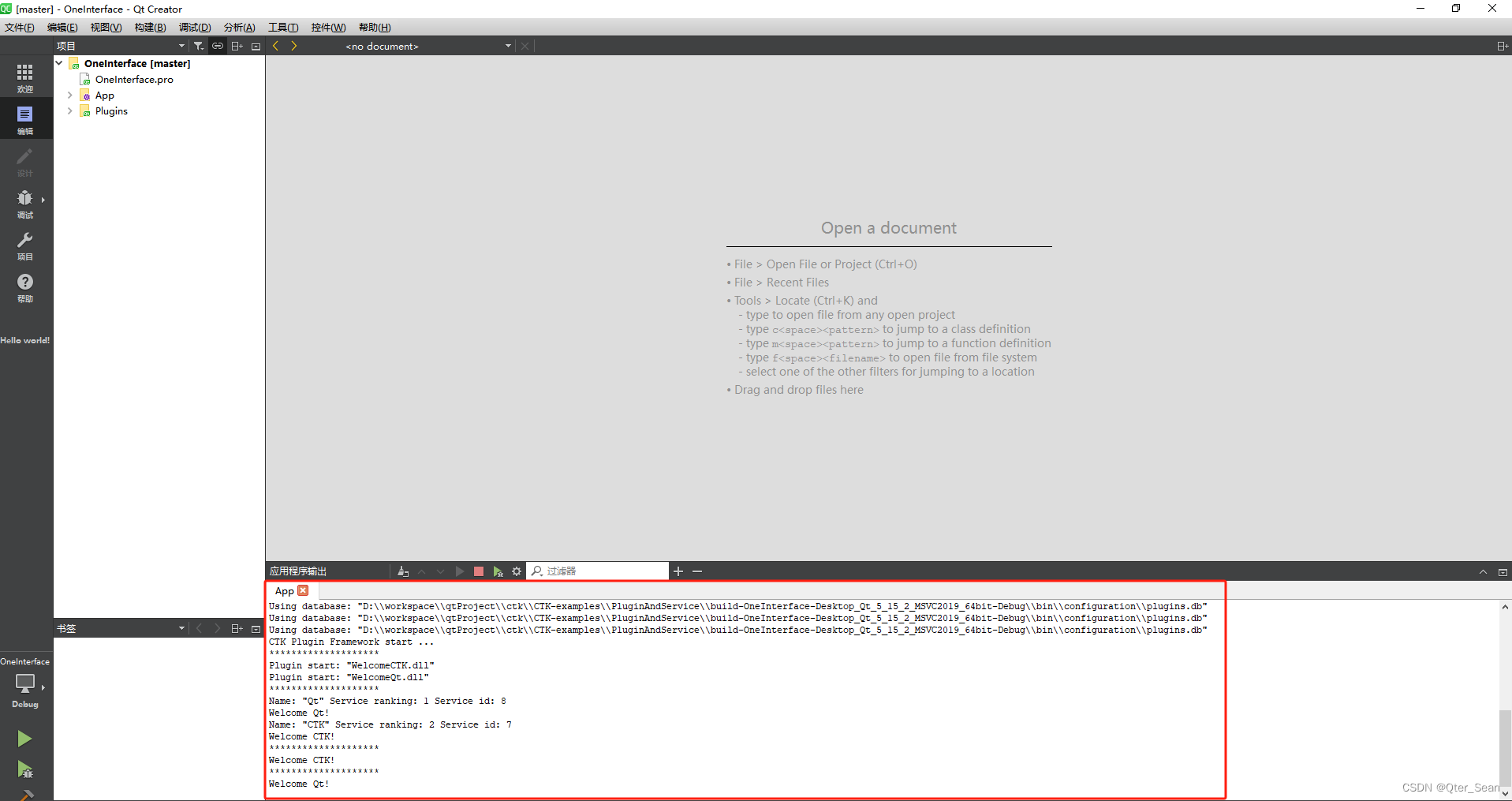
Qt框架学习 --- CTK编译(Qt5.15.2+vs2019+cmake)
系列文章目录 第二章 CTK的测试demo https://blog.csdn.net/yonug1107716573/article/details/135527289 文章目录 系列文章目录前言一、准备工作二、编译步骤1.修改文件2.编译CTK2.1 准备2.2 cmake界面配置2.3 配置编译器2.4 编译的配置设置2.5 选择需要编译的模块2.6 生成2.…...
Flink(十三)【Flink SQL(上)】
前言 最近在假期实训,但是实在水的不行,三天要学完SSM,实在一言难尽,浪费那时间干什么呢。SSM 之前学了一半,等后面忙完了,再去好好重学一遍,毕竟这玩意真是面试必会的东西。 今天开始学习 Flin…...

linux nginx配置链接访问图片
nginx 安装 sudo apt update sudo apt install nginxnginx 启动命令 sudo systemctl restart nginx # 重启 sudo systemctl start nginx #开启 sudo systemctl stop nginx # 关闭 sudo systemctl status nginx # 状态 sudo systemctl restart nginx.service #重启nginx安装成…...
深度学习笔记(二)——Tensorflow环境的安装
本篇文章只做基本的流程概述,不阐述具体每个软件的详细安装流程,具体的流程网上教程已经非常丰富。主要是给出完整的安装流程,以供参考 环境很重要 一个好的算法环境往往能够帮助开发者事半功倍,入门学习的时候往往搭建好环境就已…...

Java实现在线编辑预览office文档
文章目录 1 在线编辑1.1 PageOffice简介1.2 前端项目1.2.1 配置1.2.2 页面部分 1.3 后端项目1.3.1 pom.xml1.3.2 添加配置1.3.3 controller 2 在线预览2.1 引言2.2 市面上现有的文件预览服务2.2.1 微软2.2.2 Google Drive查看器2.2.3 阿里云 IMM2.2.4 XDOC 文档预览2.2.5 Offic…...

阿里云OSS上传视频,可分片上传
uniappH5实现 阿里云OSS上传视频 示例图: 上传视频完整示例代码: 使用npm安装SDK开发包,安装命令为 npm install ali-oss --save accessKeyId 和 accessKeySecret 还有 bucket 替换成你的就行。 multipartUpload 的第一个入参是&#x…...

Linux第三次课后作业
1.使用while和until语句编写脚本程序,计算1到100的和。 i1 s0 while(i<100) {sii} echo(s)sum0 i0 until test $num -eq 101 do #下面两个均为反斜杠 sumexpr $sum $i iexpr $num 1 done echo "the result is $sum"2.编写脚本程序备份用户指定的文件…...
WordPress后台仪表盘自定义添加删除概览项目插件Glance That
成功搭建WordPress站点,登录后台后可以在“仪表盘 – 概览”中看到包括多少篇文章、多少个页面、多少条评论和当前WordPress版本号及所使用的主题。具体如下图所示: 但是如果我们的WordPress站点还有自定义文章类型,也想在概览中显示出来应该…...
.Net6使用SignalR实现前后端实时通信
代码部分 后端代码 (Asp.net core web api,用的.net6)Program.cs 代码运行逻辑: 1. 通过 WebApplication.CreateBuilder(args) 创建一个 ASP.NET Core 应用程序建造器。 2. 使用 builder.Services.AddControllers() 添加 MVC 控…...
基于SpringBoot+Vue的时装服饰商城购物系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

近4w字吐血整理!只要你认真看完【C++编程核心知识】分分钟吊打面试官(包含:内存、函数、引用、类与对象、文件操作)
🌈个人主页:godspeed_lucip 🔥 系列专栏:C从基础到进阶 🏆🏆关注博主,随时获取更多关于C的优质内容!🏆🏆 C核心编程🌏1 内存分区模型🎄…...

pytest学习和使用-pytest如何进行分布式测试?(pytest-xdist)
1 什么是分布式测试? 在进行本文之前,先了解些基础知识,什么是分布式测试?分布式测试:是指通过局域网和Internet,把分布于不同地点、独立完成特定功能的测试计算机连接起来,以达到测试资源共享…...

虚拟ip可以解决所有的安全问题吗
虚拟IP(Virtual IP)是一种网络技术,可以把多台物理服务器或设备组合成一个逻辑集群,并且使用同一个IP地址对外提供服务。虚拟IP具有负载均衡、故障切换和高可用性等优势,同时还可以作为一种安全措施来增加系统的抗攻击…...

【数据库原理】(27)数据库恢复
在数据库系统中,恢复是指在发生某种故障导致数据库数据不再正确时,将数据库恢复到已知正确的某一状态的过程。数据库故障可能由多种原因引起,包括硬件故障、软件错误、操作员失误以及恶意破坏。为了确保数据库的安全性和完整性,数…...

施工企业工程管理信息化、智能化需求分析
一、引言 随着科技的飞速发展,信息化、智能化技术正在逐步改变各行各业的工作方式。对于施工企业而言,传统的工程管理方式已难以满足现代工程项目的复杂需求。为了提高效率、降低成本并确保工程的安全与质量,施工企业工程管理迫切需要进入信…...

如何快速掌握串口数据可视化:SerialPlot终极完整教程
如何快速掌握串口数据可视化:SerialPlot终极完整教程 【免费下载链接】serialplot Small and simple software for plotting data from serial port in realtime. 项目地址: https://gitcode.com/gh_mirrors/se/serialplot 想象一下,你正在调试一…...

如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南
如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南 【免费下载链接】ColabFold Making Protein folding accessible to all! 项目地址: https://gitcode.com/gh_mirrors/co/ColabFold ColabFold蛋白质结构预测是生物信息学领域的一项革命性技术&a…...

Sunshine游戏串流服务器:如何5分钟内搭建私人云游戏平台?
Sunshine游戏串流服务器:如何5分钟内搭建私人云游戏平台? 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想象一下,将你的高性能游戏PC变成一个…...

STL转STEP格式转换实战指南:如何实现CAD模型的无缝迁移与工程化应用
STL转STEP格式转换实战指南:如何实现CAD模型的无缝迁移与工程化应用 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造与工程设计领域,STL格式作为3D打印的标…...

BarrageGrab:企业级多平台直播弹幕一体化采集解决方案
BarrageGrab:企业级多平台直播弹幕一体化采集解决方案 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在直播电商、游戏…...

HoRain云--AI 底层架构
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

ZIP文件怎么加密?3种方法可行
如果你想给ZIP文件设置密码保护,那就一定要安装解压缩软件,因为Windows自带的ZIP压缩,点右键选“发送到”→“压缩文件夹”——这个功能不支持加密。 那么我们可以选择常用的软件来给ZIP文件加密,方法都很简单,下面分…...

3步掌握DownKyi:让你的B站视频收藏效率提升300%
3步掌握DownKyi:让你的B站视频收藏效率提升300% 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)…...

C++内联函数性能分析
C内联函数性能分析内联函数通过在调用点展开函数体来消除函数调用开销。理解内联机制和使用场景对于编写高性能代码至关重要。inline关键字建议编译器内联函数。#include #includeinline int add(int a, int b) { return a b; }inline int multiply(int a, int b) { return a …...

帕鲁杯第二届应急响应:jumpserver,waf,mysql,sshserver,server01,Palu03,Palu02,每个靶机的漏洞总结
一、题目描述1.提交堡垒机中留下的flag2.提交waf中隐藏的flag3.提交mysql中留下的flag4.提交攻击者的攻击IP5.提交攻击者的最早攻击时间6.提交web服务泄露的关键文件名7.提交泄露的邮箱地址作为flag进行提交8.提交立足点服务器ip地址9.提交攻击者使用的提权用户密码10.提交攻击…...