探索Python数据结构与算法:解锁编程的无限可能

文章目录
- 一、引言
- 1.1 数据结构与算法对于编程的重要性
- 1.2 Python作为实现数据结构与算法的强大工具
- 二、列表和元组
- 2.1 列表:创建列表、索引、切片和常用操作
- 2.2 元组:不可变序列的特性和使用场景
- 三、字符串操作和正则表达式
- 3.1 字符串的常见操作和方法
- 3.2 正则表达式的基本语法和应用
- 四、字典和集合
- 4.1 字典:键-值对的集合和常见操作
- 4.2 集合:无序不重复元素的集合和常见操作
- 五、栈和队列
- 5.1 栈:后进先出的数据结构和应用场景
- 5.2 队列:先进先出的数据结构和应用场景
- 六、链表
- 6.1 单向链表和双向链表的实现和操作
- 6.2 链表的优势和应用
- 七、树和图
- 7.1 树的基本概念和遍历方法
- 7.2 图的基本概念和常见算法
- 八、排序和搜索算法
- 8.1 常见排序算法:冒泡排序、插入排序、选择排序、快速排序、归并排序
- 8.2 常见搜索算法:线性搜索、二分搜索
- 九、动态规划和贪心算法
- 9.1 动态规划的基本思想和应用
- 9.2 贪心算法的基本思想和应用
- 十、 实践项目 : 实现一个简单的推荐系统
重温Python,适合新手搭建知识体系,也适合大佬的温故知新~
由于涉及到算法,知识深度非常深,本文只讲表层来重温记忆,想要深入需要自行多加了解和刷题哈
一、引言
1.1 数据结构与算法对于编程的重要性
重要性:
- 提高程序效率:优秀的数据结构和算法可以显著提高程序的执行效率。数据结构和算法的选择会直接影响到程序的运行时间和空间复杂度。合理地选择和设计数据结构和算法,可以降低程序的时间和空间开销,从而提高程序的性能。
- 解决复杂问题:数据结构和算法是解决复杂问题的基础。通过选择合适的数据结构和算法,可以将复杂的问题分解为更小的子问题,并通过适当的算法解决这些子问题。通过组合使用不同的数据结构和算法,可以有效地解决各种复杂的计算问题。
- 提升代码质量和可维护性:良好的数据结构和算法设计可以提高代码的质量和可维护性。合适的数据结构可以使代码更加清晰、简洁,并且易于理解和维护。同时,合理的算法设计可以使代码更加可读性高,减少错误和bug的产生。
- 培养编程思维:学习数据结构和算法可以培养良好的编程思维。对于解决问题和优化程序有一定的抽象思考能力、分析和设计能力等都是非常重要的。通过学习数据结构和算法,可以培养这些编程思维,提高解决问题的能力。
- 面试和竞争:在面试和竞争中,数据结构和算法是被广泛考察的内容。很多技术公司在面试过程中会对候选人的数据结构和算法知识进行考察,因为它们认为这是评估候选人编程能力和解决问题能力的重要指标。
综上所述,数据结构和算法对于编程非常重要。它们能够提高程序效率、解决复杂问题、改善代码质量和可维护性,培养编程思维,并在面试和竞争中起到重要作用。因此,掌握数据结构和算法是每个程序员都应该具备的基本技能。
1.2 Python作为实现数据结构与算法的强大工具
Python作为一种高级编程语言,提供了丰富的库和功能,使其成为实现数据结构和算法的强大工具。
Python在这方面的一些优势:
- 内置数据结构:Python提供了许多内置的数据结构,如列表、元组、字典和集合等。这些数据结构的使用非常简单和灵活,可以满足大部分基本的数据存储和操作需求。
- 强大的标准库:Python的标准库提供了许多有用的模块和函数,支持各种常用的数据结构和算法。例如,
collections模块提供了更高级的数据结构,如有序字典、命名元组和堆队列等;heapq模块提供了堆排序相关的函数;itertools模块提供了迭代器和组合函数等。 - 第三方库的丰富性:Python生态系统中存在许多强大的第三方库,如
NumPy、Pandas和SciPy等,它们提供了高效的数据处理和科学计算能力。此外,还有专门用于机器学习和深度学习的库,如TensorFlow和PyTorch。这些库使得在Python中实现复杂的数据结构和算法变得更加容易和高效。 - 简洁易读的语法:Python的语法非常简洁易读,特别适合表达和实现复杂的数据结构和算法。它具有清晰的代码组织风格,使得代码更易于理解、调试和维护。
- 大量的学习资源:Python作为一门广泛使用的编程语言,拥有大量的学习资源和社区支持。有许多优秀的书籍、课程和在线教程,以及活跃的开发者社区,可以帮助初学者快速上手和深入学习数据结构和算法。
总的来说,Python作为实现数据结构和算法的工具具有许多优势,使得Python成为一个受欢迎的选择,无论是在学术研究、工业应用还是个人项目中,都能轻松地实现各种复杂的数据结构和算法。
二、列表和元组
2.1 列表:创建列表、索引、切片和常用操作
列表是一种有序、可变的数据结构。它可以存储多个元素,并且支持索引、切片和常用操作。
-
创建列表:
my_list = [] # 创建一个空列表 my_list = [1, 2, 3] # 创建一个包含三个整数的列表 my_list = ['apple', 'banana', 'orange'] # 创建一个包含三个字符串的列表 -
索引: 列表中的元素通过索引来访问,索引从0开始,负数索引表示从列表末尾开始倒数。
my_list = ['apple', 'banana', 'orange'] print(my_list[0]) # 输出:'apple' print(my_list[-1]) # 输出:'orange' -
切片: 可以使用切片操作获取列表的子集。
my_list = ['apple', 'banana', 'orange', 'grape', 'melon'] print(my_list[1:3]) # 输出:['banana', 'orange'] print(my_list[:2]) # 输出:['apple', 'banana'] print(my_list[2:]) # 输出:['orange', 'grape', 'melon'] -
修改列表元素: 列表的元素是可变的,可以通过索引来修改它们。
my_list = ['apple', 'banana', 'orange'] my_list[1] = 'kiwi' print(my_list) # 输出:['apple', 'kiwi', 'orange'] -
添加元素: 可以使用
append()方法在列表末尾添加一个元素,或使用insert()方法在指定位置插入一个元素。my_list = ['apple', 'banana', 'orange'] my_list.append('grape') print(my_list) # 输出:['apple', 'banana', 'orange', 'grape']my_list.insert(1, 'kiwi') print(my_list) # 输出:['apple', 'kiwi', 'banana', 'orange', 'grape'] -
删除元素: 可以使用
del语句按索引删除元素,或使用remove()方法根据元素的值删除元素。my_list = ['apple', 'banana', 'orange'] del my_list[1] print(my_list) # 输出:['apple', 'orange']my_list.remove('orange') print(my_list) # 输出:['apple'] -
其他常用操作:
- 使用
len()函数获取列表的长度。 - 使用
in关键字检查元素是否存在于列表中。 - 使用
+运算符拼接多个列表。 - 使用
*运算符重复列表。 - 使用
max()和min()函数获取列表中的最大值和最小值。
- 使用
以上只是列表的一些基本操作和常见用法,Python的列表还有很多其他的功能和方法,读者可自行查找资料,深入学习。
2.2 元组:不可变序列的特性和使用场景
元组是一种不可变的有序序列。与列表不同,元组的元素不能被修改、添加或删除。以下是元组的一些特性和使用场景:
- 不可变性: 元组是不可变的,一旦创建后,其元素不能被修改。这意味着你无法对元组进行赋值操作,也无法通过索引来修改元素。这个特性使得元组具有更高的安全性和稳定性,适用于存储不希望被改变的数据。
- 数据保护: 元组的不可变性可以保护其中的数据不被意外修改。这对于存储一些重要的配置信息、常量或敏感数据等很有用。如果你希望某个数据在程序运行过程中不被修改,可以将其放入元组中。
- 作为字典的键: 元组可以作为字典的键,而列表不能。因为字典的键必须是不可变的,而元组的不可变性使得它成为字典中的有效键。这样可以方便地创建包含键值对的数据结构。
- 函数返回值: 元组经常用作函数的返回值,特别是当函数需要返回多个值时。通过返回一个元组,可以方便地将多个值打包起来,并且接收函数返回值的时候可以使用元组的解包操作。
- 解包和迭代: 元组支持解包操作,可以将元组中的元素分别赋值给多个变量。这种方式在函数返回多个值时非常方便。同时,可以使用
for循环来遍历元组的元素,或者使用内置的enumerate()函数同时获取索引和对应的元素。
演示使用元组场景:
# 元组的创建
my_tuple = (1, 2, 3)
print(my_tuple) # 输出:(1, 2, 3)# 元组的索引
print(my_tuple[0]) # 输出:1# 元组的解包
x, y, z = my_tuple
print(x, y, z) # 输出:1 2 3# 元组作为字典的键
my_dict = {(1, 2): 'hello', (3, 4): 'world'}
print(my_dict[(1, 2)]) # 输出:'hello'# 函数返回值为元组
def square_and_cube(x):return x ** 2, x ** 3result = square_and_cube(2)
print(result) # 输出:(4, 8)
ps:如果元组只有一个元素,需要在元素后面加上逗号,以确保它被正确地识别为元组:(1,) 。
三、字符串操作和正则表达式
3.1 字符串的常见操作和方法
1.访问字符: 字符串中的每个字符都有一个对应的索引,可以使用索引操作来访问单个字符。
my_str = "Hello"
print(my_str[0]) # 输出:H
2.切片操作: 可以使用切片操作从字符串中提取子字符串。
my_str = "Hello World"
print(my_str[1:5]) # 输出:ello3.连接字符串: 使用加号(+)运算符来连接两个字符串。
str1 = "Hello"
str2 = "World"
print(str1 + " " + str2) # 输出:Hello World4.查询子字符串: 使用in关键字来查询一个子字符串是否在一个字符串中。
my_str = "Hello World"
print("lo" in my_str) # 输出:True5.分割字符串: split()方法可以用于将一个字符串按照指定分隔符分割成多个子字符串,并返回一个列表。
my_str = "Hello,World,How,Are,You"
split_str = my_str.split(",")
print(split_str) # 输出:['Hello', 'World', 'How', 'Are', 'You']6.连接字符串: join()方法可以用于将一个列表中的多个子字符串连接成一个字符串。
split_str = ['Hello', 'World', 'How', 'Are', 'You']
join_str = ",".join(split_str)
print(join_str) # 输出:Hello,World,How,Are,You7.大小写转换和去除空格: upper()方法可以将字符串中的所有字母转换为大写形式,lower()方法可以将其转换为小写形式。strip()方法可以去除字符串两端的空格。
my_str = " Hello World "
print(my_str.upper()) # 输出: HELLO WORLD
print(my_str.lower()) # 输出: hello world
print(my_str.strip()) # 输出:Hello World这些示例涵盖了Python中字符串常见操作和方法的一部分,这里只是提供了一些基本的示例,实际上还有许多其他有用的函数和方法可供使用。
3.2 正则表达式的基本语法和应用
正则表达式(Regular Expression)是一种强大的文本匹配工具,用于在字符串中查找和匹配特定的模式。在Python中,通过re模块可以使用正则表达式。
正则表达式的基本语法和应用的示例和代码演示:
1.导入re模块: 在使用正则表达式之前,需要先导入Python的re模块。
import re2.匹配字符串开头或结尾: 可以使用^符号匹配行的开头,使用$符号匹配行的结尾。
pattern = r"^Hello"
text = "Hello World"
match = re.search(pattern, text)
if match:print("Match found!")
else:print("Match not found.")# 输出结果
Match found!3.匹配任意字符: 使用.匹配任意字符(除了换行符)。
pattern = r"he..o"
text = "hello"
match = re.search(pattern, text)
if match:print("Match found!")
else:print("Match not found.")# 输出结果
Match found!4.匹配多个字符: 使用[]来匹配其中的任意一个字符。
pattern = r"[aeiou]"
text = "hello"
match = re.search(pattern, text)
if match:print("Match found!")
else:print("Match not found.")# 输出结果
Match found!5.匹配重复字符: 使用*匹配零个或多个重复字符。
pattern = r"a*"
text = "aabbb"
match = re.search(pattern, text)
if match:print("Match found!")
else:print("Match not found.")# 输出结果
Match found!6.使用特殊字符: 正则表达式中有一些特殊字符具有特殊的含义,如\d用于匹配数字字符,\w用于匹配字母、数字和下划线等。
pattern = r"\d+"
text = "12345"
match = re.search(pattern, text)
if match:print("Match found!")
else:print("Match not found.")# 输出结果
Match found!7.分组和提取: 可以使用小括号来创建一个组,并通过group()方法提取匹配到的内容。
pattern = r"(hello) (world)"
text = "hello world"
match = re.search(pattern, text)
if match:print(match.group(0)) # 输出:hello worldprint(match.group(1)) # 输出:helloprint(match.group(2)) # 输出:worldps:使用正则表达式时,可以在模式字符串前加上r前缀,表示原始字符串,避免转义字符的问题。
四、字典和集合
4.1 字典:键-值对的集合和常见操作
Python中的字典(Dictionary)是一种用于存储键-值对的数据结构,可以使用键来访问和操作相应的值。
字典的基本操作和示例代码:
1.创建一个字典: 可以使用花括号将键-值对列表括起来,或使用dict()函数来创建一个空字典。
# 使用花括号创建字典
my_dict = {"apple": 1, "banana": 2, "orange": 3}
# 使用dict()函数创建字典
my_dict2 = dict()2.访问字典中的值: 可以使用键来访问相应的值。
my_dict = {"apple": 1, "banana": 2, "orange": 3}
print(my_dict["apple"]) # 输出:13.添加或修改字典中的元素: 可以使用键来添加新的键-值对或修改已有的键-值对。
my_dict = {"apple": 1, "banana": 2, "orange": 3}
# 添加新的键-值对
my_dict["peach"] = 4
# 修改已有的键-值对
my_dict["banana"] = 54.删除字典中的元素: 可以使用del关键字来删除指定键的键-值对。
my_dict = {"apple": 1, "banana": 2, "orange": 3}
del my_dict["apple"]5.字典遍历: 可以使用for循环来遍历字典中的所有键-值对。
my_dict = {"apple": 1, "banana": 2, "orange": 3}
for key, value in my_dict.items():print(key, value)6.检查字典中是否包含指定的键或值: 可以使用in关键字来检查字典中是否包含指定的键或值。
my_dict = {"apple": 1, "banana": 2, "orange": 3}
# 检查是否包含指定的键
if "apple" in my_dict:print("Apple found!")
# 检查是否包含指定的值
if 1 in my_dict.values():print("Value found!")ps:键必须是不可变的类型(如字符串、数字或元组等),因为它们被用作字典中的索引。
4.2 集合:无序不重复元素的集合和常见操作
在Python中,集合(Set)是一种无序且不重复的数据结构,用于存储唯一的元素。
集合的基本操作和示例代码:
1.创建一个集合: 可以使用花括号将元素列表括起来,或使用set()函数来创建一个空集合。
# 使用花括号创建集合
my_set = {1, 2, 3}
# 使用set()函数创建集合
my_set2 = set()2.添加元素到集合中: 可以使用add()方法向集合中添加单个元素,或使用update()方法添加多个元素。
my_set = {1, 2, 3}
my_set.add(4)
my_set.update([5, 6])3.删除集合中的元素: 可以使用remove()方法删除指定的元素,如果元素不存在则会引发KeyError错误;或使用discard()方法删除指定的元素,如果元素不存在则不会引发错误。
my_set = {1, 2, 3}
my_set.remove(2)
my_set.discard(4)4.集合运算: 可以使用集合运算符进行交集、并集、差集和对称差集等操作。
set1 = {1, 2, 3}
set2 = {3, 4, 5}# 交集
intersection = set1 & set2# 并集
union = set1 | set2# 差集
difference = set1 - set2# 对称差集
symmetric_difference = set1 ^ set25.集合遍历: 可以使用for循环遍历集合中的所有元素。
my_set = {1, 2, 3}
for item in my_set:print(item)6.检查集合中是否包含指定的元素: 可以使用in关键字来检查集合中是否包含指定的元素。
my_set = {1, 2, 3}
if 1 in my_set:print("Element found!")ps:集合中的元素必须是不可变的类型(如数字、字符串或元组等),不能包含可变的类型(如列表或字典)。
五、栈和队列
5.1 栈:后进先出的数据结构和应用场景
栈是一种后进先出(LIFO,Last In First Out)的数据结构,类似于我们平时叠放的一堆盘子,只能从最顶层取出盘子。在Python中,可以使用列表(List)来实现栈的功能。
简单的栈示例代码:
class Stack:def __init__(self):self.stack = []# 判断栈是否为空,返回布尔值def is_empty(self):return len(self.stack) == 0# 将元素item压入栈顶def push(self, item):self.stack.append(item)# 弹出栈顶元素,并返回该元素def pop(self):if self.is_empty():return Nonereturn self.stack.pop()# 返回栈顶元素,但不弹出def peek(self):if self.is_empty():return Nonereturn self.stack[-1]# 返回栈中元素的个数def size(self):return len(self.stack)如何使用栈来判断字符串中的括号是否匹配:
# 遍历了输入的字符串,如果遇到左括号,则将其压入栈中;如果遇到右括号,则从栈顶弹出一个元素。最后,我们只需判断栈是否为空,即可确定括号是否匹配。
def check_brackets(string):stack = Stack()for char in string:if char == '(':stack.push(char)elif char == ')':if stack.is_empty():return Falsestack.pop()return stack.is_empty()# 测试
print(check_brackets("((()))")) # True
print(check_brackets("()()()")) # True
print(check_brackets("()(()))") # False栈还可以用于其他场景,如函数调用栈、表达式求值等。
5.2 队列:先进先出的数据结构和应用场景
队列是一种先进先出(FIFO,First In First Out)的数据结构,类似于我们平时排队等候的场景,先来的人先被服务。在Python中,可以使用列表(List)或者双端队列(deque)来实现队列的功能。
使用列表实现队列:
class Queue:def __init__(self):self.queue = []def is_empty(self):return len(self.queue) == 0def enqueue(self, item):self.queue.append(item)def dequeue(self):if self.is_empty():return Nonereturn self.queue.pop(0)def size(self):return len(self.queue)使用双端队列(deque)实现队列:
from collections import dequeclass Queue:def __init__(self):self.queue = deque()# 判断队列是否为空,返回布尔值def is_empty(self):return len(self.queue) == 0# 将元素item加入队列尾部def enqueue(self, item):self.queue.append(item)# 移除并返回队列的第一个元素def dequeue(self):if self.is_empty():return Nonereturn self.queue.popleft()# 返回队列中元素的个数def size(self):return len(self.queue)使用队列实现打印任务调度:
# 将需要打印的任务加入到队列中,然后从队列中取出任务交给打印机进行打印,实现了一个简单的打印任务调度。
# 打印队列类(PrintQueue)
class PrintQueue:def __init__(self):self.queue = Queue()def enqueue(self, task):self.queue.enqueue(task)def dequeue(self):return self.queue.dequeue()def is_empty(self):return self.queue.is_empty()def size(self):return self.queue.size()# 打印机类(Printer)
class Printer:def __init__(self):self.current_task = Nonedef get_task(self, task):self.current_task = taskdef print_task(self):if self.current_task is not None:print("正在打印任务:", self.current_task)self.current_task = Noneelse:print("没有任务需要打印")def simulate_printing(tasks):printer = Printer()print_queue = PrintQueue()for task in tasks:print_queue.enqueue(task)while not print_queue.is_empty():next_task = print_queue.dequeue()printer.get_task(next_task)printer.print_task()print("打印完成!")# 测试
tasks = ["任务1", "任务2", "任务3", "任务4"]
simulate_printing(tasks)队列还可以用于其他场景,如消息传递、多线程编程等。
六、链表
6.1 单向链表和双向链表的实现和操作
链表是一种常见的数据结构,主要用于存储一系列元素,每个元素都包含一个指向下一个元素的指针。链表可以分为单向链表和双向链表两种类型。
- 单向链表中,每个节点包含一个值和一个指向下一个节点的引用;
- 双向链表中,每个节点不仅包含一个值,还包含一个指向前一个节点的引用。
单向链表的实现:
class Node:def __init__(self, data):self.data = dataself.next_node = Noneclass LinkedList:def __init__(self):self.head = Nonedef is_empty(self):return self.head is Nonedef add(self, data):new_node = Node(data)new_node.next_node = self.headself.head = new_nodedef size(self):count = 0current_node = self.headwhile current_node is not None:count += 1current_node = current_node.next_nodereturn countdef search(self, data):current_node = self.headwhile current_node is not None:if current_node.data == data:return Truecurrent_node = current_node.next_nodereturn Falsedef delete(self, data):previous_node = Nonecurrent_node = self.headwhile current_node is not None:if current_node.data == data:if previous_node is None:self.head = current_node.next_nodeelse:previous_node.next_node = current_node.next_nodereturnprevious_node = current_nodecurrent_node = current_node.next_node双向链表的实现:
class Node:def __init__(self, data):self.data = dataself.previous_node = Noneself.next_node = Noneclass LinkedList:def __init__(self):self.head = Noneself.tail = Nonedef is_empty(self):return self.head is Nonedef add(self, data):new_node = Node(data)if self.is_empty():self.head = new_nodeself.tail = new_nodeelse:new_node.previous_node = self.tailself.tail.next_node = new_nodeself.tail = new_nodedef size(self):count = 0current_node = self.headwhile current_node is not None:count += 1current_node = current_node.next_nodereturn countdef search(self, data):current_node = self.headwhile current_node is not None:if current_node.data == data:return Truecurrent_node = current_node.next_nodereturn Falsedef delete(self, data):current_node = self.headwhile current_node is not None:if current_node.data == data:if current_node.previous_node is None:self.head = current_node.next_nodeelse:current_node.previous_node.next_node = current_node.next_nodeif current_node.next_node is None:self.tail = current_node.previous_nodeelse:current_node.next_node.previous_node = current_node.previous_nodereturncurrent_node = current_node.next_node使用链表实现一个队列:
class Node:def __init__(self, data):self.data = dataself.next_node = Noneclass Queue:def __init__(self):self.head = Noneself.tail = Nonedef is_empty(self):return self.head is Nonedef enqueue(self, data):new_node = Node(data)if self.is_empty():self.head = new_nodeself.tail = new_nodeelse:self.tail.next_node = new_nodeself.tail = new_nodedef dequeue(self):if self.is_empty():return Noneelse:data = self.head.dataself.head = self.head.next_nodereturn datadef size(self):count = 0current_node = self.headwhile current_node is not None:count += 1current_node = current_node.next_nodereturn count6.2 链表的优势和应用
优势和应用:
- 动态性:链表的长度可以根据需要动态变化,不像数组一样需要提前指定大小。这使得链表在需要频繁插入和删除元素的场景下非常高效。
- 内存灵活使用:链表以节点的形式存储元素,每个节点都包含一个指向下一个节点的引用。这种存储方式使得链表可以更灵活地利用内存空间,不需要一段连续的内存空间。
- 插入和删除操作高效:由于链表的动态性和内存灵活使用的特点,插入和删除元素的操作非常高效。
- 对于单向链表,插入和删除操作只需要修改节点的引用,时间复杂度为
O(1); - 对于双向链表,还可以通过修改前后节点的引用来实现插入和删除操作,同样时间复杂度为
O(1)。
- 对于单向链表,插入和删除操作只需要修改节点的引用,时间复杂度为
- 高效的迭代:链表可以通过节点引用顺序访问元素,因此可以很方便地进行迭代操作。与数组不同,链表不需要考虑扩容和缩容的问题,所以在大规模数据处理和遍历操作上更加高效。
- 应用场景:链表在许多场景中都有广泛的应用。
- 例如,
LRU缓存算法中可以使用链表来实现缓存的淘汰策略; - 在图的表示中,可以使用链表来表示图的邻接表;
- 在实现栈、队列等数据结构时,链表也是常用的基础数据结构。
- 例如,
总之,链表作为一种常见的数据结构,在Python中具有动态性、内存灵活使用、插入删除操作高效和高效迭代等优势,并广泛应用于各种场景中。
七、树和图
7.1 树的基本概念和遍历方法
在Python中,树是一种非常常见的数据结构,它由节点组成,每个节点有零个或多个子节点。树的遍历是指按照一定顺序访问树中的所有节点,包括根节点和叶子节点。常用的树的遍历方式有三种:前序遍历、中序遍历和后序遍历。
- 前序遍历:先访问根节点,然后递归地遍历左子树和右子树。
- 中序遍历:先递归地遍历左子树,然后访问根节点,最后递归地遍历右子树。
- 后序遍历:先递归地遍历左子树和右子树,最后访问根节点。
创建树并实现前序遍历和中序遍历:
# 树的节点
class Node:def __init__(self, data):self.data = dataself.left_child = Noneself.right_child = None# 创建一颗树
def build_tree():root = Node(1)root.left_child = Node(2)root.right_child = Node(3)root.left_child.left_child = Node(4)root.left_child.right_child = Node(5)root.right_child.left_child = Node(6)root.right_child.right_child = Node(7)return root# 前序遍历
def preorder_traversal(node):if node is None:returnprint(node.data, end=' ')preorder_traversal(node.left_child)preorder_traversal(node.right_child)# 中序遍历
def inorder_traversal(node):if node is None:returninorder_traversal(node.left_child)print(node.data, end=' ')inorder_traversal(node.right_child)if __name__ == '__main__':root = build_tree()print('前序遍历:', end='')preorder_traversal(root)print('\n中序遍历:', end='')inorder_traversal(root)7.2 图的基本概念和常见算法
在Python中,图是一种非常重要的数据结构,它由节点和边组成。节点代表图中的实体,边表示节点之间的关系或连接。图的遍历是指按照一定顺序访问图中的所有节点和边,包括起始节点和终止节点。常用的图的遍历方式有两种:深度优先搜索和广度优先搜索。
- 深度优先搜索(DFS):从一个起始节点出发,递归地访问它的各个邻居节点,直到所有可达节点都被访问过。
- 广度优先搜索(BFS):从一个起始节点出发,按照距离递增的顺序依次访问其周围的节点,直到所有可达节点都被访问过。
创建图并实现深度优先搜索和广度优先搜索:
from queue import Queueclass Graph:def __init__(self):self.vertices = {}# 添加节点def add_vertex(self, vertex):if vertex not in self.vertices:self.vertices[vertex] = []# 添加边def add_edge(self, v1, v2):self.vertices[v1].append(v2)self.vertices[v2].append(v1)# 深度优先搜索def dfs(self, start, visited=None):if visited is None:visited = set()visited.add(start)print(start, end=' ')for next_vertex in self.vertices[start]:if next_vertex not in visited:self.dfs(next_vertex, visited)# 广度优先搜索def bfs(self, start):visited = set()q = Queue()q.put(start)visited.add(start)while not q.empty():vertex = q.get()print(vertex, end=' ')for next_vertex in self.vertices[vertex]:if next_vertex not in visited:visited.add(next_vertex)q.put(next_vertex)
# 创建了一个图并对其进行深度优先搜索和广度优先搜索
if __name__ == '__main__':g = Graph()for i in range(6):g.add_vertex(i)g.add_edge(0, 1)g.add_edge(0, 2)g.add_edge(1, 2)g.add_edge(2, 3)g.add_edge(3, 4)g.add_edge(3, 5)print('深度优先搜索:', end='')g.dfs(0)print('\n广度优先搜索:', end='')g.bfs(0)八、排序和搜索算法
8.1 常见排序算法:冒泡排序、插入排序、选择排序、快速排序、归并排序
在计算机科学中,排序算法是一种将一组元素按照特定顺序排列的算法。常见的排序算法有冒泡排序、插入排序、选择排序、快速排序和归并排序等。
- 冒泡排序
冒泡排序是一种简单的排序算法,其基本思想是多次遍历待排序序列,每次比较相邻的两个元素,如果顺序错误就交换它们。时间复杂度为O(n^2)。
def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(n-1-i):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]return arr- 插入排序
插入排序是一种简单直观的排序算法,其基本思想是将待排序序列分为已排序区间和未排序区间,每次从未排序区间选择一个元素插入到已排序区间的合适位置。时间复杂度为O(n^2)。
def insertion_sort(arr):n = len(arr)for i in range(1, n):key = arr[i]j = i - 1while j >= 0 and key < arr[j]:arr[j+1] = arr[j]j -= 1arr[j+1] = keyreturn arr- 选择排序
选择排序是一种简单直观的排序算法,其基本思想是将待排序序列分为已排序区间和未排序区间,每次从未排序区间选择一个最小元素放到已排序区间的末尾。时间复杂度为O(n^2)。
def selection_sort(arr):n = len(arr)for i in range(n-1):min_idx = ifor j in range(i+1, n):if arr[j] < arr[min_idx]:min_idx = jarr[i], arr[min_idx] = arr[min_idx], arr[i]return arr- 快速排序
快速排序是一种高效的排序算法,其基本思想是通过一次划分将待排序序列分成两个子序列,左边序列中的所有元素都比右边序列中的元素小,然后对两个子序列进行递归排序。时间复杂度为O(nlogn)。
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr)//2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)- 归并排序
归并排序是一种高效的排序算法,其基本思想是将待排序序列分成若干个子序列,每个子序列都是有序的,然后再将子序列合并成一个有序的序列。时间复杂度为O(nlogn)。
def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):i, j = 0, 0res = []while i < len(left) and j < len(right):if left[i] < right[j]:res.append(left[i])i += 1else:res.append(right[j])j += 1res += left[i:]res += right[j:]return res8.2 常见搜索算法:线性搜索、二分搜索
常见的搜索算法包括线性搜索和二分搜索。
- 线性搜索
线性搜索(也称为顺序搜索)是一种简单直观的搜索算法,其基本思想是从待搜索序列的第一个元素开始逐个比较,直到找到目标元素或者遍历完整个序列。时间复杂度为O(n)。
def linear_search(arr, target):n = len(arr)for i in range(n):if arr[i] == target:return ireturn -1- 二分搜索
二分搜索(也称为折半搜索)是一种高效的搜索算法,其前提是待搜索序列已经按照升序或降序排列。其基本思想是将待搜索序列分成两个子序列,如果目标元素小于中间元素,则在左侧子序列中继续搜索,否则在右侧子序列中继续搜索,直到找到目标元素或者子序列为空。时间复杂度为O(logn)。
def binary_search(arr, target):left, right = 0, len(arr)-1while left <= right:mid = (left + right) // 2if arr[mid] == target:return midelif arr[mid] < target:left = mid + 1else:right = mid - 1return -1九、动态规划和贪心算法
9.1 动态规划的基本思想和应用
动态规划(Dynamic Programming)是一种用于解决具有重叠子问题和最优子结构性质的问题的算法设计方法。其基本思想是将原问题分解为若干个子问题,并先求解子问题的解,然后通过子问题的解推导出原问题的解。动态规划常用于优化问题,可以大大减少重复计算,提高效率。
动态规划的基本步骤:
- 定义状态:将原问题划分成若干个子问题,并定义状态表示子问题的解。
- 确定状态转移方程:根据子问题之间的关系,得到子问题的状态转移方程。
- 确定边界条件:确定最简单的子问题的解,作为边界条件。
- 确定计算顺序:根据状态转移方程,确定子问题的计算顺序,通常采用自底向上的方式进行计算。
- 计算最终结果:根据计算顺序,计算出原问题的解。
动态规划广泛应用于各个领域,包括但不限于以下几个方面:
- 最优化问题:如背包问题、旅行商问题等。
- 路径搜索问题:如最短路径问题、最长公共子序列问题等。
- 字符串处理问题:如编辑距离问题、正则表达式匹配问题等。
- 组合优化问题:如排列组合问题、划分问题等。
- 矩阵链乘法问题、最大子数组和问题等。
动态规划算法的关键是找到合适的状态定义和状态转移方程,通过合理地设计问题的划分和求解顺序,可以高效地解决一些复杂的优化问题。
9.2 贪心算法的基本思想和应用
贪心算法(Greedy Algorithm)是一种在每个阶段选择当前最优解的策略,以希望最终能够得到全局最优解的算法。其基本思想是通过局部最优选择来达到全局最优。
贪心算法的基本步骤:
- 定义问题的子问题和局部最优解的性质。
- 根据局部最优解的性质,构建一个最优解的解空间。
- 通过贪心选择原则,逐步构建问题的最优解。
- 判断最终解是否是全局最优解。
贪心算法的关键是确定选择的贪心策略,即在每个阶段都选择当前最优的解,以期望最终得到全局最优解。然而,贪心算法并不一定能够得到全局最优解,因为当前最优解未必能够导致全局最优解。因此,在使用贪心算法时需要谨慎选择贪心策略,确保其能够满足问题的要求。
贪心算法广泛应用于各个领域,包括但不限于以下几个方面:
- 最小生成树:如Prim算法和Kruskal算法。
- 单源最短路径:如Dijkstra算法。
- 哈夫曼编码:用于数据压缩。
- 区间调度问题:如活动选择问题。
- 背包问题的近似算法:如分数背包问题。
贪心算法的优势在于其简单性和高效性。相对于动态规划等算法,贪心算法通常具有较低的时间复杂度,能够在较短的时间内得到一个可接受的解。然而,贪心算法也存在局限性,不能保证一定能够得到全局最优解,因此在使用时需要根据具体问题进行评估和选择。
十、 实践项目 : 实现一个简单的推荐系统
推荐系统是通过分析用户的历史行为和偏好,给用户提供个性化的推荐内容。
具体步骤:
- 收集用户信息:收集用户的偏好、历史行为等信息,可以使用表格或数据库存储。
- 特征提取:根据用户的信息特征,对内容进行特征提取和表示,例如使用关键词、标签等描述内容。
- 相似度计算:计算不同内容之间的相似度,可以使用余弦相似度等方法。
- 推荐生成:根据用户的偏好和相似度计算,生成推荐列表并呈现给用户。
简单Demo:
# 定义内容和用户信息
content = {'article1': ['Python', '机器学习'],'article2': ['Java', '系统开发'],'article3': ['Python', '深度学习'],'article4': ['C++', '算法'],'article5': ['Python', '数据科学']
}user1 = ['Python', '机器学习']
user2 = ['Java', '系统开发']
user3 = ['Python', '深度学习']# 计算相似度
def similarity(user, content):user_set = set(user)content_set = set(content)intersection = user_set.intersection(content_set)union = user_set.union(content_set)return len(intersection) / len(union)# 生成推荐列表
def generate_recommendations(user, content):recommendations = []for item in content:sim = similarity(user, content[item])recommendations.append((item, sim))recommendations.sort(key=lambda x: x[1], reverse=True)return recommendations# 获取推荐列表
user = user1
recommendations = generate_recommendations(user, content)# 打印推荐列表
print("推荐列表:")
for item, sim in recommendations:print(f"{item},相似度:{sim}")以蝼蚁之行,展鸿鹄之志
相关文章:
探索Python数据结构与算法:解锁编程的无限可能
文章目录 一、引言1.1 数据结构与算法对于编程的重要性1.2 Python作为实现数据结构与算法的强大工具 二、列表和元组2.1 列表:创建列表、索引、切片和常用操作2.2 元组:不可变序列的特性和使用场景 三、字符串操作和正则表达式3.1 字符串的常见操作和方法…...

责任链模式介绍及演示
责任链模介绍 责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,其主要目的是将请求的发送者和接收者解耦。在这个模式中,多个对象有机会处理一个请求,形成一条“责任链”。每个对象在链中检查该请求并…...
表单组件属性说明+代码明细)
智能小程序小部件(Widget)表单组件属性说明+代码明细
在 Tuya MiniApp Tools 中,新建项目并选择小部件(Widget)对应模板即可自动创建小部件(Widget)项目。 button 按钮,用于强调操作并引导用户去点击。 属性说明 属性名类型默认值必填说明sizestringdefault否按钮的大小typestringdefault否按钮的样式类…...

自学Python笔记总结(更新中……)
自学Python笔记总结 网址数据类型类型查看类型,使用type内置类标识符 输出输入语句format函数的语法及用法数据类型的转换运算符算数运算符赋值运算符的特殊场景拆包 比较运算符逻辑运算符 与 短路位运算符运算符优先级 程序流程控制分支语句pass 占位 循环语句 whi…...

十四.变量、异常处理
变量、异常处理 1.变量1.1系统变量1.1.1系统变量分类1.1.2查看系统变量 1.2用户变量1.2.1用户变量分类1.2.2会话用户变量1.2.3局部变量1.2.4对比会话用户变量与局部变量 补充:MySQL 8.0的新特性—全局变量的持久化 2.定义条件与处理程序2.1案例分析2.2定义条件2.3定义处理程序2…...
import { ArrowRight } from “@element-plus/icons-vue“;
今天下午快被这个问题折磨疯了 虽然知道这个问题怎么产生的 但项目里那个碍眼的红线就是去不掉 后来才发现 这是插件的锅 我的心情 你知道我想要说什么的 想必能看到这篇文章的 也知道这个问题是怎么产生的 vue3ts使用的时候 默认是需要带上文件名的 但是引入el组件时 …...

Kubernetes 面试宝典
创建 Pod的主要流程? 客户端提交 Pod 的配置信息(可以是 yaml 文件定义的信息)到 kube-apiserver. Apiserver 收到指令后,通知 controllr-manager 创建一个资源对象 controller-manager 通过 apiserver 将 pod 的配置信息存储到 ETCD 数据中薪心中 kube-scheduler 检查到 p…...

c语言二维数组
系列文章目录 c语言二维数组 c语言二维数组 系列文章目录一、二维数组的定义一、二维数组的内存模型 一、二维数组的定义 int main() {//二维数组的定义int arr[3][4];arr[0][0]; arr[0][1]; arr[0][2]; arr[0][3]; arr[0][4];arr[1][0]; arr[1][1]; arr[1][2]; arr[1][3]; ar…...
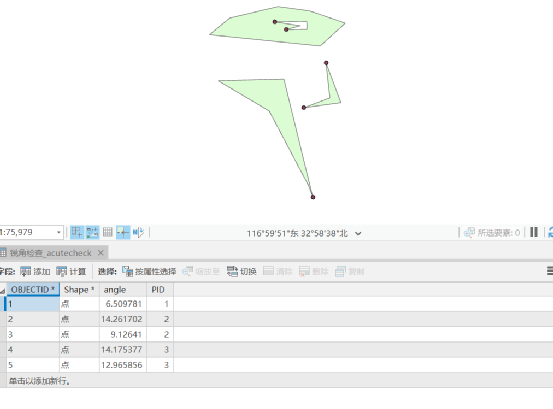
ArcGIS Pro 拓扑编辑和常见一些拓扑错误处理
7.4 拓扑编辑 拓扑编辑也叫共享编辑,多个数据修改时,一块修改,如使用数据:chp7\拓扑检查.gdb,数据集DS下JZX、JZD和DK,加载地图框中,在“地图”选项卡下选择“地图拓扑”或“ds_Topology(地理数据库)”&…...
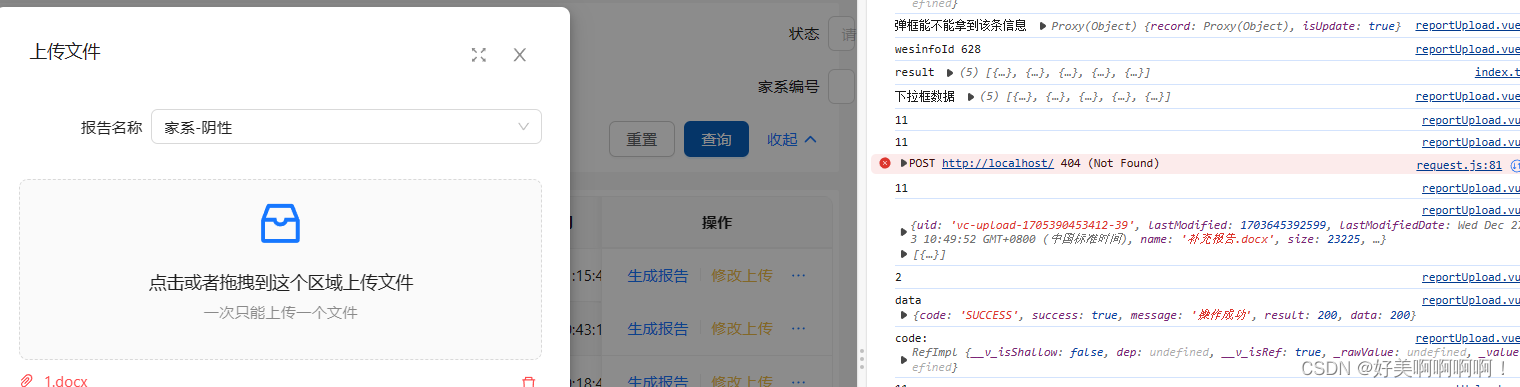
前端踩坑之——antDesignVue的upload组件
本地启动时控制台会报404,放到服务器上控制台会报405(多发一个请求) 原因:upLoad有默认的上传事件 解决:阻止默认事件即可 beforeUpload Hook function which will be executed before uploading. Uploading will be stopped with false or …...

设计模式——策略模式
策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列算法,并将每一个算法封装起来,使它们可以相互替换。策略模式让算法独立于使用它的客户端代码,使得算法的变化不会影响到使用该算法的客户端…...

Ubuntu12.0安装g++过程及其报错
Ubuntu12.0安装g过程及其报错 https://blog.csdn.net/weixin_51286763/article/details/120703953 https://blog.csdn.net/dingd1234/article/details/124029945 2.报错二: [41/80] Building CXX object absl/synchronization/CMakeFiles/graphcycles_internal.di…...
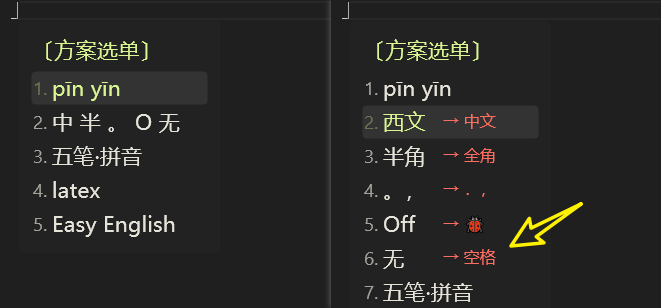
rime中州韵小狼毫 汉语拼音输入方案
教程目录:rime中州韵小狼毫须鼠管安装配置教程 保姆级教程 100增强功能配置教程 在word中,我们可以轻易的给汉字加上拼音,如下👇: 但是,如何单独的输入拼音呢?例如输入 pīn yīn, 再如 zhōn…...

网页设计(八)HTML5基础与CSS3应用
一、当当网企业用户注册页面设计 当当网企业用户注册页面 改版后当当网企业用户注册页面 <!-- prj_8_1.html --> <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>当当网企业用户注册页面设计</title><s…...
模拟瑞幸小程序购物车
是根据渡一袁老师的大师课写的,如有什么地方存在问题,还请大家指出来哟ど⁰̷̴͈꒨⁰̷̴͈う♡~ index.html <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta http-e…...

react js自定义实现状态管理
redux基础实现 myRedux export const createStore (reduce) > {if (typeof reduce ! function) throw new Error(Expected the reducer to be a function.)let state,listeners []state reduce()const getState () > stateconst dispatch (action) > {if(typeo…...

行为型设计模式——中介者模式
中介者模式 中介者模式主要是将关联关系由一个中介者类统一管理维护,一般来说,同事类之间的关系是比较复杂的,多个同事类之间互相关联时,他们之间的关系会呈现为复杂的网状结构,这是一种过度耦合的架构,即…...

通信行业无线基本概念
fast roaming(快速漫游):使用户在不同的基站(access point)间可以平滑的切换,在802.11r协议标准中定义。band steering(波段转向):在双频段(2.4G和5G…...
grep 在运维中的常用可选项
一、对比两个文件 vim -d <filename1> <filename2> 演示: 需求:~目录下有两个文件一个test.txt 以及 text2.txt,需求对比两个文件的内容。 执行后会显示如图,不同会高亮。 二、两次过滤 场景:当需要多…...

python读取Dicom文件
文章目录 1. pydicom Library2. SimpleITK Library3. ITK Library (Insight Toolkit)4. GDCM Library (Grassroots DICOM) 下面提供几种用python方法读取Dicom文件 1. pydicom Library import pydicom # Read DICOM file dataset pydicom.dcmread("path_to_dicom_file.d…...

0522晨间日记
# 0522晨间日记 - 关键词 - 上午- 过站的问题- 昨天有一个产品卡在母子码绑定了- 早晨的各类菜单没有同步,不知道怎么做。- 最终明确是: 因为一个产品对应2种的条码导致的卡住了- 需要在条码规则上增加多个检查对应的- 总结- 最近一周西门子遇到的问题- …...

战略视角:如何用AI自动化重构团队工作流
战略视角:如何用AI自动化重构团队工作流 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在数字化加速的时代,企业面临的核心挑战不再是技…...

终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案
终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows…...

告别臃肿!G-Helper:华硕笔记本用户的终极轻量级控制神器
告别臃肿!G-Helper:华硕笔记本用户的终极轻量级控制神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook…...

UE5 BaseInput.ini源码级解读:输入配置的底层原理与实战调优
1. 为什么一个INI文件值得花三天逐行精读?在UE5项目刚启动的第三天,我遇到一个看似微不足道却卡住整个输入调试流程的问题:手柄右摇杆的Y轴输入,在PC编辑器里始终返回0,但同一套蓝图逻辑在打包后的Windows平台却完全正…...

全周期陪伴式服务成行业趋势,墨石教育以 “录取即终点” 定义管理类联考服务新标准
随着考研培训行业从流量竞争转向服务竞争,《人民日报》《新华网》多次倡导 **“全周期、结果导向”的教育服务模式。管理类联考作为系统性工程,从择校、笔试、面试到调剂,任何环节缺失都可能导致落榜。墨石教育率先打破 “重授课、轻服务” 的…...

C++函数对象与仿函数
C函数对象与仿函数函数对象是重载了函数调用运算符operator()的类对象,也称为仿函数。它们可以像函数一样被调用,但比普通函数更灵活,可以保存状态和配置。函数对象的基本实现通过重载operator()实现。#include #include #includeclass Multi…...

AI API 中转站完全指南:从 Claude、GPT 到“满血”“翻车”,一次搞懂整个 AI API 圈子
如果你刚开始接触 AI API,大概率会在各种开发者群、论坛或者教程里看到一堆让人摸不着头脑的词,比如“满血”“阉割”“翻车”“官转”“上车”“池子”“逆向”等等。很多新人第一次看这些内容的时候,基本都是每个字都认识,但连在…...

2026年想做美缝施工?专业靠谱的美缝施工究竟哪家好?
在装修领域,美缝施工虽看似是小工程,却对家居整体美观度和实用性影响重大。然而,美缝行业乱象丛生,让众多业主在选择美缝施工团队时犯了难。2026年若想做美缝施工,怎样才能选到专业靠谱的团队呢?下面为大家…...

为什么你的ElevenLabs马来文输出总像“机器人朗读”?资深语音架构师拆解4层韵律建模断层与3个修复级prompt模板
更多请点击: https://intelliparadigm.com 第一章:为什么你的ElevenLabs马来文输出总像“机器人朗读”?资深语音架构师拆解4层韵律建模断层与3个修复级prompt模板 马来语(Bahasa Melayu)虽属声调中性语言,…...