YOLOV7剪枝流程
YOLOV7剪枝流程
1、训练
1)划分数据集进行训练前的准备,按正常的划分流程即可
2)修改train.py文件
第一次处在参数列表里添加剪枝的参数,正常训练时设置为False,剪枝后微调时设置为True
parser.add_argument('--pruned', action='store_true', default=True, help='pruned model fine train')
第二处位置在
# Resume
下面修改代码,源代码为:
# Resumestart_epoch, best_fitness = 0, 0.0if pretrained:# Optimizerif ckpt['optimizer'] is not None:optimizer.load_state_dict(ckpt['optimizer'])best_fitness = ckpt['best_fitness']# EMAif ema and ckpt.get('ema'):ema.ema.load_state_dict(ckpt['ema'].float().state_dict())ma.updates = ckpt['updates']# Resultsif ckpt.get('training_results') is not None:results_file.write_text(ckpt['training_results']) # write results.txt
修改为:
# Resumestart_epoch, best_fitness = 0, 0.0if pretrained:if not opt.pruned:# Optimizerif ckpt['optimizer'] is not None:optimizer.load_state_dict(ckpt['optimizer'])best_fitness = ckpt['best_fitness']# EMAif ema and ckpt.get('ema'):ema.ema.load_state_dict(ckpt['ema'].float().state_dict())ema.updates = ckpt['updates']# Resultsif ckpt.get('training_results') is not None:results_file.write_text(ckpt['training_results']) # write results.txt
第三处位置在
# Epochs
源代码为:
# Epochsstart_epoch = ckpt['epoch'] + 1if opt.resume:assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)if epochs < start_epoch:logger.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %(weights, ckpt['epoch'], epochs))epochs += ckpt['epoch'] # finetune additional epochsdel ckpt, state_dict
修改为
# Epochsif not opt.pruned:start_epoch = ckpt['epoch'] + 1if opt.resume:assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)elif opt.pruned:ckpt['epoch'] = 0start_epoch = ckpt['epoch'] + 1if epochs < start_epoch:logger.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %(weights, ckpt['epoch'], epochs))epochs += ckpt['epoch'] # finetune additional epochsif not opt.pruned:del ckpt, state_dictelif opt.pruned:del ckpt
第四处位置在
# Save model
源代码为:
# Save modelif (not opt.nosave) or (final_epoch and not opt.evolve): # if saveckpt = {'epoch': epoch,'best_fitness': best_fitness,'training_results': results_file.read_text(),'model': deepcopy(model.module if is_parallel(model) else model).half(),'ema': deepcopy(ema.ema).half(),'updates': ema.updates,'optimizer': optimizer.state_dict(),'wandb_id': wandb_logger.wandb_run.id if wandb_logger.wandb else None}
修改为:
# Save modelif (not opt.nosave) or (final_epoch and not opt.evolve): # if saveif opt.pruned:ckpt = {'model': deepcopy(model.module if is_parallel(model) else model).half(),}elif not opt.pruned:ckpt = {'epoch': epoch,'best_fitness': best_fitness,'training_results': results_file.read_text(),'model': deepcopy(model.module if is_parallel(model) else model).half(),'ema': deepcopy(ema.ema).half(),'updates': ema.updates,'optimizer': optimizer.state_dict(),'wandb_id': wandb_logger.wandb_run.id if wandb_logger.wandb else None}
修改后的train.py整体代码如下:
import argparse
import logging
import math
import os
import random
import time
from copy import deepcopy
from pathlib import Path
from threading import Threadimport numpy as np
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.utils.data
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdmimport test # import test.py to get mAP after each epoch
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.datasets import create_dataloader
from utils.general import labels_to_class_weights, increment_path, labels_to_image_weights, init_seeds, \fitness, strip_optimizer, get_latest_run, check_dataset, check_file, check_git_status, check_img_size, \check_requirements, print_mutation, set_logging, one_cycle, colorstr
from utils.google_utils import attempt_download
from utils.loss import ComputeLoss, ComputeLossOTA
from utils.plots import plot_images, plot_labels, plot_results, plot_evolution
from utils.torch_utils import ModelEMA, select_device, intersect_dicts, torch_distributed_zero_first, is_parallel
from utils.wandb_logging.wandb_utils import WandbLogger, check_wandb_resumelogger = logging.getLogger(__name__)def train(hyp, opt, device, tb_writer=None):logger.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))save_dir, epochs, batch_size, total_batch_size, weights, rank, freeze = \Path(opt.save_dir), opt.epochs, opt.batch_size, opt.total_batch_size, opt.weights, opt.global_rank, opt.freeze# Directorieswdir = save_dir / 'weights'wdir.mkdir(parents=True, exist_ok=True) # make dirlast = wdir / 'last.pt'best = wdir / 'best.pt'results_file = save_dir / 'results.txt'# Save run settingswith open(save_dir / 'hyp.yaml', 'w') as f:yaml.dump(hyp, f, sort_keys=False)with open(save_dir / 'opt.yaml', 'w') as f:yaml.dump(vars(opt), f, sort_keys=False)# Configureplots = not opt.evolve # create plotscuda = device.type != 'cpu'init_seeds(2 + rank)with open(opt.data) as f:data_dict = yaml.load(f, Loader=yaml.SafeLoader) # data dictis_coco = opt.data.endswith('coco.yaml')# Logging- Doing this before checking the dataset. Might update data_dictloggers = {'wandb': None} # loggers dictif rank in [-1, 0]:opt.hyp = hyp # add hyperparametersrun_id = torch.load(weights, map_location=device).get('wandb_id') if weights.endswith('.pt') and os.path.isfile(weights) else Nonewandb_logger = WandbLogger(opt, Path(opt.save_dir).stem, run_id, data_dict)loggers['wandb'] = wandb_logger.wandbdata_dict = wandb_logger.data_dictif wandb_logger.wandb:weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp # WandbLogger might update weights, epochs if resumingnc = 1 if opt.single_cls else int(data_dict['nc']) # number of classesnames = ['item'] if opt.single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class namesassert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check# Modelpretrained = weights.endswith('.pt')if pretrained:if opt.pruned:from models.yolo import attempt_load#model = attempt_load(weights,map_location=device)ckpt = torch.load(weights, map_location=device)model = ckpt['model']else:with torch_distributed_zero_first(rank):attempt_download(weights) # download if not found locallyckpt = torch.load(weights, map_location=device) # 加载模型# 模型的定义model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # createexclude = ['anchor'] if (opt.cfg or hyp.get('anchors'))else [] # exclude keysstate_dict = ckpt['model'].float().state_dict() # to FP32 获得预权重的权值state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude) # intersect# 将权重加载到模型内model.load_state_dict(state_dict, strict=False) # loadlogger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # report# with torch_distributed_zero_first(rank):# attempt_download(weights) # download if not found locally# ckpt = torch.load(weights, map_location=device) # load checkpoint# model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create# exclude = ['anchor'] if (opt.cfg or hyp.get('anchors')) and not opt.resume else [] # exclude keys# state_dict = ckpt['model'].float().state_dict() # to FP32# state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude) # intersect# model.load_state_dict(state_dict, strict=False) # load# logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # reportelse:model = Model(opt.cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # createwith torch_distributed_zero_first(rank):check_dataset(data_dict) # checktrain_path = data_dict['train']test_path = data_dict['val']# Freezefreeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # parameter names to freeze (full or partial)for k, v in model.named_parameters():v.requires_grad = True # train all layersif any(x in k for x in freeze):print('freezing %s' % k)v.requires_grad = False# Optimizernbs = 64 # nominal batch sizeaccumulate = max(round(nbs / total_batch_size), 1) # accumulate loss before optimizinghyp['weight_decay'] *= total_batch_size * accumulate / nbs # scale weight_decaylogger.info(f"Scaled weight_decay = {hyp['weight_decay']}")pg0, pg1, pg2 = [], [], [] # optimizer parameter groupsfor k, v in model.named_modules():if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):pg2.append(v.bias) # biasesif isinstance(v, nn.BatchNorm2d):pg0.append(v.weight) # no decayelif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):pg1.append(v.weight) # apply decayif hasattr(v, 'im'):if hasattr(v.im, 'implicit'): pg0.append(v.im.implicit)else:for iv in v.im:pg0.append(iv.implicit)if hasattr(v, 'imc'):if hasattr(v.imc, 'implicit'): pg0.append(v.imc.implicit)else:for iv in v.imc:pg0.append(iv.implicit)if hasattr(v, 'imb'):if hasattr(v.imb, 'implicit'): pg0.append(v.imb.implicit)else:for iv in v.imb:pg0.append(iv.implicit)if hasattr(v, 'imo'):if hasattr(v.imo, 'implicit'): pg0.append(v.imo.implicit)else:for iv in v.imo:pg0.append(iv.implicit)if hasattr(v, 'ia'):if hasattr(v.ia, 'implicit'): pg0.append(v.ia.implicit)else:for iv in v.ia:pg0.append(iv.implicit)if hasattr(v, 'attn'):if hasattr(v.attn, 'logit_scale'): pg0.append(v.attn.logit_scale)if hasattr(v.attn, 'q_bias'): pg0.append(v.attn.q_bias)if hasattr(v.attn, 'v_bias'): pg0.append(v.attn.v_bias)if hasattr(v.attn, 'relative_position_bias_table'): pg0.append(v.attn.relative_position_bias_table)if hasattr(v, 'rbr_dense'):if hasattr(v.rbr_dense, 'weight_rbr_origin'): pg0.append(v.rbr_dense.weight_rbr_origin)if hasattr(v.rbr_dense, 'weight_rbr_avg_conv'): pg0.append(v.rbr_dense.weight_rbr_avg_conv)if hasattr(v.rbr_dense, 'weight_rbr_pfir_conv'): pg0.append(v.rbr_dense.weight_rbr_pfir_conv)if hasattr(v.rbr_dense, 'weight_rbr_1x1_kxk_idconv1'): pg0.append(v.rbr_dense.weight_rbr_1x1_kxk_idconv1)if hasattr(v.rbr_dense, 'weight_rbr_1x1_kxk_conv2'): pg0.append(v.rbr_dense.weight_rbr_1x1_kxk_conv2)if hasattr(v.rbr_dense, 'weight_rbr_gconv_dw'): pg0.append(v.rbr_dense.weight_rbr_gconv_dw)if hasattr(v.rbr_dense, 'weight_rbr_gconv_pw'): pg0.append(v.rbr_dense.weight_rbr_gconv_pw)if hasattr(v.rbr_dense, 'vector'): pg0.append(v.rbr_dense.vector)if opt.adam:optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentumelse:optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decayoptimizer.add_param_group({'params': pg2}) # add pg2 (biases)logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))del pg0, pg1, pg2# Scheduler https://arxiv.org/pdf/1812.01187.pdf# https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html#OneCycleLRif opt.linear_lr:lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linearelse:lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)# plot_lr_scheduler(optimizer, scheduler, epochs)# EMAema = ModelEMA(model) if rank in [-1, 0] else None# Resumestart_epoch, best_fitness = 0, 0.0if pretrained:if not opt.pruned:# Optimizerif ckpt['optimizer'] is not None:optimizer.load_state_dict(ckpt['optimizer'])best_fitness = ckpt['best_fitness']# EMAif ema and ckpt.get('ema'):ema.ema.load_state_dict(ckpt['ema'].float().state_dict())ema.updates = ckpt['updates']# Resultsif ckpt.get('training_results') is not None:results_file.write_text(ckpt['training_results']) # write results.txt# Epochsif not opt.pruned:start_epoch = ckpt['epoch'] + 1if opt.resume:assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)elif opt.pruned:ckpt['epoch'] = 0start_epoch = ckpt['epoch'] + 1if epochs < start_epoch:logger.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %(weights, ckpt['epoch'], epochs))epochs += ckpt['epoch'] # finetune additional epochsif not opt.pruned:del ckpt, state_dictelif opt.pruned:del ckpt# start_epoch = ckpt['epoch'] + 1# if opt.resume:# assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)# if epochs < start_epoch:# logger.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %# (weights, ckpt['epoch'], epochs))# epochs += ckpt['epoch'] # finetune additional epochs# del ckpt, state_dict# Image sizesgs = max(int(model.stride.max()), 32) # grid size (max stride)nl = model.model[-1].nl # number of detection layers (used for scaling hyp['obj'])imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples# DP modeif cuda and rank == -1 and torch.cuda.device_count() > 1:model = torch.nn.DataParallel(model)# SyncBatchNormif opt.sync_bn and cuda and rank != -1:model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)logger.info('Using SyncBatchNorm()')# Trainloaderdataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=rank,world_size=opt.world_size, workers=opt.workers,image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr('train: '))mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label classnb = len(dataloader) # number of batchesassert mlc < nc, 'Label class %g exceeds nc=%g in %s. Possible class labels are 0-%g' % (mlc, nc, opt.data, nc - 1)# Process 0if rank in [-1, 0]:testloader = create_dataloader(test_path, imgsz_test, batch_size * 2, gs, opt, # testloaderhyp=hyp, cache=opt.cache_images and not opt.notest, rect=True, rank=-1,world_size=opt.world_size, workers=opt.workers,pad=0.5, prefix=colorstr('val: '))[0]if not opt.resume:labels = np.concatenate(dataset.labels, 0)c = torch.tensor(labels[:, 0]) # classes# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency# model._initialize_biases(cf.to(device))if plots:#plot_labels(labels, names, save_dir, loggers)if tb_writer:tb_writer.add_histogram('classes', c, 0)# Anchorsif not opt.noautoanchor:check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)model.half().float() # pre-reduce anchor precision# DDP modeif cuda and rank != -1:model = DDP(model, device_ids=[opt.local_rank], output_device=opt.local_rank,# nn.MultiheadAttention incompatibility with DDP https://github.com/pytorch/pytorch/issues/26698find_unused_parameters=any(isinstance(layer, nn.MultiheadAttention) for layer in model.modules()))# Model parametershyp['box'] *= 3. / nl # scale to layershyp['cls'] *= nc / 80. * 3. / nl # scale to classes and layershyp['obj'] *= (imgsz / 640) ** 2 * 3. / nl # scale to image size and layershyp['label_smoothing'] = opt.label_smoothingmodel.nc = nc # attach number of classes to modelmodel.hyp = hyp # attach hyperparameters to modelmodel.gr = 1.0 # iou loss ratio (obj_loss = 1.0 or iou)model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weightsmodel.names = names# Start trainingt0 = time.time()nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of trainingmaps = np.zeros(nc) # mAP per classresults = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)scheduler.last_epoch = start_epoch - 1 # do not movescaler = amp.GradScaler(enabled=cuda)compute_loss_ota = ComputeLossOTA(model) # init loss classcompute_loss = ComputeLoss(model) # init loss classlogger.info(f'Image sizes {imgsz} train, {imgsz_test} test\n'f'Using {dataloader.num_workers} dataloader workers\n'f'Logging results to {save_dir}\n'f'Starting training for {epochs} epochs...')torch.save(model, wdir / 'init.pt')for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------model.train()# Update image weights (optional)if opt.image_weights:# Generate indicesif rank in [-1, 0]:cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weightsiw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weightsdataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx# Broadcast if DDPif rank != -1:indices = (torch.tensor(dataset.indices) if rank == 0 else torch.zeros(dataset.n)).int()dist.broadcast(indices, 0)if rank != 0:dataset.indices = indices.cpu().numpy()# Update mosaic border# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)# dataset.mosaic_border = [b - imgsz, -b] # height, width bordersmloss = torch.zeros(4, device=device) # mean lossesif rank != -1:dataloader.sampler.set_epoch(epoch)pbar = enumerate(dataloader)logger.info(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'labels', 'img_size'))if rank in [-1, 0]:pbar = tqdm(pbar, total=nb) # progress baroptimizer.zero_grad()for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------ni = i + nb * epoch # number integrated batches (since train start)imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0-255 to 0.0-1.0# Warmupif ni <= nw:xi = [0, nw] # x interp# model.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)accumulate = max(1, np.interp(ni, xi, [1, nbs / total_batch_size]).round())for j, x in enumerate(optimizer.param_groups):# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])if 'momentum' in x:x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])# Multi-scaleif opt.multi_scale:sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # sizesf = sz / max(imgs.shape[2:]) # scale factorif sf != 1:ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)# Forwardwith amp.autocast(enabled=cuda):pred = model(imgs) # forwardif 'loss_ota' not in hyp or hyp['loss_ota'] == 1:loss, loss_items = compute_loss_ota(pred, targets.to(device), imgs) # loss scaled by batch_sizeelse:loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_sizeif rank != -1:loss *= opt.world_size # gradient averaged between devices in DDP modeif opt.quad:loss *= 4.# Backwardscaler.scale(loss).backward()# Optimizeif ni % accumulate == 0:scaler.step(optimizer) # optimizer.stepscaler.update()optimizer.zero_grad()if ema:ema.update(model)# Printif rank in [-1, 0]:mloss = (mloss * i + loss_items) / (i + 1) # update mean lossesmem = '%.3gG' % (torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0) # (GB)s = ('%10s' * 2 + '%10.4g' * 6) % ('%g/%g' % (epoch, epochs - 1), mem, *mloss, targets.shape[0], imgs.shape[-1])pbar.set_description(s)# Plotif plots and ni < 10:f = save_dir / f'train_batch{ni}.jpg' # filenameThread(target=plot_images, args=(imgs, targets, paths, f), daemon=True).start()# if tb_writer:# tb_writer.add_image(f, result, dataformats='HWC', global_step=epoch)# tb_writer.add_graph(torch.jit.trace(model, imgs, strict=False), []) # add model graphelif plots and ni == 10 and wandb_logger.wandb:wandb_logger.log({"Mosaics": [wandb_logger.wandb.Image(str(x), caption=x.name) for x insave_dir.glob('train*.jpg') if x.exists()]})# end batch ------------------------------------------------------------------------------------------------# end epoch ----------------------------------------------------------------------------------------------------# Schedulerlr = [x['lr'] for x in optimizer.param_groups] # for tensorboardscheduler.step()# DDP process 0 or single-GPUif rank in [-1, 0]:# mAPema.update_attr(model, include=['yaml', 'nc', 'hyp', 'gr', 'names', 'stride', 'class_weights'])final_epoch = epoch + 1 == epochsif not opt.notest or final_epoch: # Calculate mAPwandb_logger.current_epoch = epoch + 1results, maps, times = test.test(data_dict,batch_size=batch_size * 2,imgsz=imgsz_test,model=ema.ema,single_cls=opt.single_cls,dataloader=testloader,save_dir=save_dir,verbose=nc < 50 and final_epoch,plots=plots and final_epoch,wandb_logger=wandb_logger,compute_loss=compute_loss,is_coco=is_coco,v5_metric=opt.v5_metric)# Writewith open(results_file, 'a') as f:f.write(s + '%10.4g' * 7 % results + '\n') # append metrics, val_lossif len(opt.name) and opt.bucket:os.system('gsutil cp %s gs://%s/results/results%s.txt' % (results_file, opt.bucket, opt.name))# Logtags = ['train/box_loss', 'train/obj_loss', 'train/cls_loss', # train loss'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95','val/box_loss', 'val/obj_loss', 'val/cls_loss', # val loss'x/lr0', 'x/lr1', 'x/lr2'] # paramsfor x, tag in zip(list(mloss[:-1]) + list(results) + lr, tags):if tb_writer:tb_writer.add_scalar(tag, x, epoch) # tensorboardif wandb_logger.wandb:wandb_logger.log({tag: x}) # W&B# Update best mAPfi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]if fi > best_fitness:best_fitness = fiwandb_logger.end_epoch(best_result=best_fitness == fi)# Save modelif (not opt.nosave) or (final_epoch and not opt.evolve): # if saveif opt.pruned:ckpt = {'model': deepcopy(model.module if is_parallel(model) else model).half(),}elif not opt.pruned:ckpt = {'epoch': epoch,'best_fitness': best_fitness,'training_results': results_file.read_text(),'model': deepcopy(model.module if is_parallel(model) else model).half(),'ema': deepcopy(ema.ema).half(),'updates': ema.updates,'optimizer': optimizer.state_dict(),'wandb_id': wandb_logger.wandb_run.id if wandb_logger.wandb else None}# Save last, best and deletetorch.save(ckpt, last)if best_fitness == fi:torch.save(ckpt, best)if (best_fitness == fi) and (epoch >= 200):torch.save(ckpt, wdir / 'best_{:03d}.pt'.format(epoch))if epoch == 0:torch.save(ckpt, wdir / 'epoch_{:03d}.pt'.format(epoch))elif ((epoch+1) % 25) == 0:torch.save(ckpt, wdir / 'epoch_{:03d}.pt'.format(epoch))elif epoch >= (epochs-5):torch.save(ckpt, wdir / 'epoch_{:03d}.pt'.format(epoch))if wandb_logger.wandb:if ((epoch + 1) % opt.save_period == 0 and not final_epoch) and opt.save_period != -1:wandb_logger.log_model(last.parent, opt, epoch, fi, best_model=best_fitness == fi)del ckpt# end epoch ----------------------------------------------------------------------------------------------------# end trainingif rank in [-1, 0]:# Plotsif plots:plot_results(save_dir=save_dir) # save as results.pngif wandb_logger.wandb:files = ['results.png', 'confusion_matrix.png', *[f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R')]]wandb_logger.log({"Results": [wandb_logger.wandb.Image(str(save_dir / f), caption=f) for f in filesif (save_dir / f).exists()]})# Test best.ptlogger.info('%g epochs completed in %.3f hours.\n' % (epoch - start_epoch + 1, (time.time() - t0) / 3600))if opt.data.endswith('coco.yaml') and nc == 80: # if COCOfor m in (last, best) if best.exists() else (last): # speed, mAP testsresults, _, _ = test.test(opt.data,batch_size=batch_size * 2,imgsz=imgsz_test,conf_thres=0.001,iou_thres=0.7,model=attempt_load(m, device).half(),single_cls=opt.single_cls,dataloader=testloader,save_dir=save_dir,save_json=True,plots=False,is_coco=is_coco,v5_metric=opt.v5_metric)# Strip optimizersfinal = best if best.exists() else last # final modelfor f in last, best:if f.exists():strip_optimizer(f) # strip optimizersif opt.bucket:os.system(f'gsutil cp {final} gs://{opt.bucket}/weights') # uploadif wandb_logger.wandb and not opt.evolve: # Log the stripped modelwandb_logger.wandb.log_artifact(str(final), type='model',name='run_' + wandb_logger.wandb_run.id + '_model',aliases=['last', 'best', 'stripped'])wandb_logger.finish_run()else:dist.destroy_process_group()torch.cuda.empty_cache()return resultsif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--weights', type=str, default='my_dataset/layer_pruning.pt', help='initial weights path')parser.add_argument('--cfg', type=str, default='cfg/training/yolov7-tiny.yaml', help='model.yaml path')parser.add_argument('--data', type=str, default='my_dataset/coco.yaml', help='data.yaml path')parser.add_argument('--hyp', type=str, default='data/hyp.scratch.p5.yaml', help='hyperparameters path')parser.add_argument('--epochs', type=int, default=600)parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs')parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')parser.add_argument('--rect', action='store_true', help='rectangular training')parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')parser.add_argument('--notest', action='store_true', help='only test final epoch')parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--multi-scale', action='store_true', default=True, help='vary img-size +/- 50%%')parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')parser.add_argument('--workers', type=int, default=16, help='maximum number of dataloader workers')parser.add_argument('--project', default='runs/train', help='save to project/name')parser.add_argument('--entity', default=None, help='W&B entity')parser.add_argument('--name', default='exp', help='save to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')parser.add_argument('--quad', action='store_true', help='quad dataloader')parser.add_argument('--linear-lr', action='store_true', help='linear LR')parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')parser.add_argument('--save_period', type=int, default=2, help='Log model after every "save_period" epoch')parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone of yolov7=50, first3=0 1 2')parser.add_argument('--v5-metric', action='store_true', help='assume maximum recall as 1.0 in AP calculation')parser.add_argument('--pruned', action='store_true', default=True, help='pruned model fine train')opt = parser.parse_args()# Set DDP variablesopt.world_size = int(os.environ['WORLD_SIZE']) if 'WORLD_SIZE' in os.environ else 1opt.global_rank = int(os.environ['RANK']) if 'RANK' in os.environ else -1set_logging(opt.global_rank)#if opt.global_rank in [-1, 0]:# check_git_status()# check_requirements()# Resumewandb_run = check_wandb_resume(opt)if opt.resume and not wandb_run: # resume an interrupted runckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent pathassert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'apriori = opt.global_rank, opt.local_rankwith open(Path(ckpt).parent.parent / 'opt.yaml') as f:opt = argparse.Namespace(**yaml.load(f, Loader=yaml.SafeLoader)) # replaceopt.save_dir = Path(ckpt).parent.parent # increment runopt.cfg, opt.weights, opt.resume, opt.batch_size, opt.global_rank, opt.local_rank = '', ckpt, True, opt.total_batch_size, *apriori # reinstatelogger.info('Resuming training from %s' % ckpt)else:# opt.hyp = opt.hyp or ('hyp.finetune.yaml' if opt.weights else 'hyp.scratch.yaml')opt.data, opt.cfg, opt.hyp = check_file(opt.data), check_file(opt.cfg), check_file(opt.hyp) # check filesassert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # extend to 2 sizes (train, test)opt.name = 'evolve' if opt.evolve else opt.nameopt.save_dir = increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok | opt.evolve) # increment run# DDP modeopt.total_batch_size = opt.batch_sizedevice = select_device(opt.device, batch_size=opt.batch_size)if opt.local_rank != -1:assert torch.cuda.device_count() > opt.local_ranktorch.cuda.set_device(opt.local_rank)device = torch.device('cuda', opt.local_rank)dist.init_process_group(backend='nccl', init_method='env://') # distributed backendassert opt.batch_size % opt.world_size == 0, '--batch-size must be multiple of CUDA device count'opt.batch_size = opt.total_batch_size // opt.world_size# Hyperparameterswith open(opt.hyp) as f:hyp = yaml.load(f, Loader=yaml.SafeLoader) # load hyps# Trainlogger.info(opt)if not opt.evolve:tb_writer = None # init loggersif opt.global_rank in [-1, 0]:prefix = colorstr('tensorboard: ')logger.info(f"{prefix}Start with 'tensorboard --logdir {opt.project}', view at http://localhost:6006/")tb_writer = SummaryWriter(opt.save_dir) # Tensorboardtrain(hyp, opt, device, tb_writer)# Evolve hyperparameters (optional)else:# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1'weight_decay': (1, 0.0, 0.001), # optimizer weight decay'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr'box': (1, 0.02, 0.2), # box loss gain'cls': (1, 0.2, 4.0), # cls loss gain'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight'iou_t': (0, 0.1, 0.7), # IoU training threshold'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)'translate': (1, 0.0, 0.9), # image translation (+/- fraction)'scale': (1, 0.0, 0.9), # image scale (+/- gain)'shear': (1, 0.0, 10.0), # image shear (+/- deg)'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001'flipud': (1, 0.0, 1.0), # image flip up-down (probability)'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)'mosaic': (1, 0.0, 1.0), # image mixup (probability)'mixup': (1, 0.0, 1.0), # image mixup (probability)'copy_paste': (1, 0.0, 1.0), # segment copy-paste (probability)'paste_in': (1, 0.0, 1.0)} # segment copy-paste (probability)with open(opt.hyp, errors='ignore') as f:hyp = yaml.safe_load(f) # load hyps dictif 'anchors' not in hyp: # anchors commented in hyp.yamlhyp['anchors'] = 3assert opt.local_rank == -1, 'DDP mode not implemented for --evolve'opt.notest, opt.nosave = True, True # only test/save final epoch# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indicesyaml_file = Path(opt.save_dir) / 'hyp_evolved.yaml' # save best result hereif opt.bucket:os.system('gsutil cp gs://%s/evolve.txt .' % opt.bucket) # download evolve.txt if existsfor _ in range(300): # generations to evolveif Path('evolve.txt').exists(): # if evolve.txt exists: select best hyps and mutate# Select parent(s)parent = 'single' # parent selection method: 'single' or 'weighted'x = np.loadtxt('evolve.txt', ndmin=2)n = min(5, len(x)) # number of previous results to considerx = x[np.argsort(-fitness(x))][:n] # top n mutationsw = fitness(x) - fitness(x).min() # weightsif parent == 'single' or len(x) == 1:# x = x[random.randint(0, n - 1)] # random selectionx = x[random.choices(range(n), weights=w)[0]] # weighted selectionelif parent == 'weighted':x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination# Mutatemp, s = 0.8, 0.2 # mutation probability, sigmanpr = np.randomnpr.seed(int(time.time()))g = np.array([x[0] for x in meta.values()]) # gains 0-1ng = len(meta)v = np.ones(ng)while all(v == 1): # mutate until a change occurs (prevent duplicates)v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)hyp[k] = float(x[i + 7] * v[i]) # mutate# Constrain to limitsfor k, v in meta.items():hyp[k] = max(hyp[k], v[1]) # lower limithyp[k] = min(hyp[k], v[2]) # upper limithyp[k] = round(hyp[k], 5) # significant digits# Train mutationresults = train(hyp.copy(), opt, device)# Write mutation resultsprint_mutation(hyp.copy(), results, yaml_file, opt.bucket)# Plot resultsplot_evolution(yaml_file)print(f'Hyperparameter evolution complete. Best results saved as: {yaml_file}\n'f'Command to train a new model with these hyperparameters: $ python train.py --hyp {yaml_file}')2、剪枝
剪枝方法
YOLOv4剪枝【附代码】_strategy = tp.strategy.l1strategy()-CSDN博客参考此篇博文进行的通道剪枝。Pruning Filters for Efficient ConvNets这篇论文的技术
添加prunmodel.py文件
下载torch_pruning模块时一定要使用0.2.5版本,
pip install torch_pruning==0.2.7
pip install loguru
把训练好的模型路径放进去
layer_pruning('/home/jovyan/exp_3046/runs/train/best.pt')
定义剪枝后保存的模型路径
torch.save(model_, '/home/jovyan/exp_3047/data/layer_pruning.pt')
修改prunmodel.py文件中需要剪枝的权重路径。重点修改58~62行。这里是以修改model的前10层为例。head层不能剪,我们选择backbone的层。
included_layers = []for layer in model.model[:10]: # 获取backboneif type(layer) is Conv:included_layers.append(layer.conv)included_layers.append(layer.bn)
下面代码是剪枝conv和BN层。【重点是tp.prune_conv】,自己修改amout也就是剪枝率。
if isinstance(m, nn.Conv2d) and m in included_layers:# amount是剪枝率# 卷积剪枝pruning_plan = DG.get_pruning_plan(m, tp.prune_conv, idxs=strategy(m.weight, amount=0.8))logger.info(pruning_plan)# 执行剪枝pruning_plan.exec()if isinstance(m, nn.BatchNorm2d) and m in included_layers:# BN层剪枝pruning_plan = DG.get_pruning_plan(m, tp.prune_batchnorm, idxs=strategy(m.weight, amount=0.8))logger.info(pruning_plan)pruning_plan.exec()
出现以下内容说明剪枝成功
2023-03-15 14:57:40.825 | INFO | __main__:layer_pruning:84 - Params: 37196556 => 36839795
2023-03-15 14:57:41.176 | INFO | __main__:layer_pruning:95 - 剪枝完成
代码如下:
import syssys.path.append("/home/jovyan/exp_3046")
# print(sys.path)import torch_pruning as tp
from loguru import logger
from models.common import *
from models.experimental import Ensemble
from utils.torch_utils import select_device"""
剪枝的时候根据模型结构去剪,不要盲目的猜
剪枝完需要进行一个微调训练
"""# 加载模型
def attempt_load(weights, map_location=None, inplace=True):from models.yolo import Detect, Modelmodel = Ensemble()ckpt = torch.load(weights, map_location=map_location) # load weightsmodel.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().eval()) # without layer fuse 权值的加载# Compatibility updatesfor m in model.modules(): # 取出每一层if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:m.inplace = inplace # pytorch 1.7.0 compatibilityif type(m) is Detect: # 判断是否为目标检测if not isinstance(m.anchor_grid, list): # new Detect Layer compatibilitydelattr(m, 'anchor_grid')setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)elif type(m) is Conv: # 卷积层m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibilityif len(model) == 1:return model[-1], ckpt # return modelelse:print(f'Ensemble created with {weights}\n')for k in ['names']:setattr(model, k, getattr(model[-1], k))model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stridereturn model, ckpt # return ensemble@logger.catch
def layer_pruning(weights):logger.add('../logs/layer_pruning.log', rotation='1 MB')device = select_device('cpu')model, ckpt = attempt_load(weights, map_location=device)for para in model.parameters():para.requires_grad = True# 创建输入样例,可在此修改输入大小x = torch.zeros(1, 3, 640, 640)# -----------------对整个模型的剪枝--------------------strategy = tp.strategy.L1Strategy() # L1策略DG = tp.DependencyGraph() # 依赖图DG = DG.build_dependency(model, example_inputs=x)"""这里写要剪枝的层这里以backbone为例"""included_layers = []for layer in model.model[:41]: # 获取backboneif type(layer) is Conv:included_layers.append(layer.conv)included_layers.append(layer.bn)logger.info(included_layers)# 获取未剪枝之前的参数量num_params_before_pruning = tp.utils.count_params(model)# 模型遍历for m in model.modules():# 判断是否为卷积并且是否在需要剪枝的层里if isinstance(m, nn.Conv2d) and m in included_layers:# amount是剪枝率# 卷积剪枝# 层剪枝(需要筛选出不需要剪枝的层,比如yolo需要把头部的预测部分取出来,这个是不需要剪枝的) pruning_plan = DG.get_pruning_plan(m, tp.prune_conv, idxs=strategy(m.weight, amount=0.4))logger.info(pruning_plan)# 执行剪枝pruning_plan.exec()if isinstance(m, nn.BatchNorm2d) and m in included_layers:# BN层剪枝pruning_plan = DG.get_pruning_plan(m, tp.prune_batchnorm, idxs=strategy(m.weight, amount=0.3))logger.info(pruning_plan)pruning_plan.exec()# 获得剪枝以后的参数量num_params_after_pruning = tp.utils.count_params(model)# 输出一下剪枝前后的参数量logger.info(" Params: %s => %s\n" % (num_params_before_pruning, num_params_after_pruning))# 剪枝完以后模型的保存(不要用torch.save(model.state_dict(),...))model_ = {'model': model.half(),# 'optimizer': ckpt['optimizer'],# 'training_results': ckpt['training_results'],'epoch': ckpt['epoch']}torch.save(model_, '/home/jovyan/exp_3046/my_dataset/layer_pruning.pt')del model_, ckptlogger.info("剪枝完成\n")layer_pruning('/home/jovyan/exp_3046/runs/train/best.pt')
3、微调
运行train.py
权重为剪枝之后的layer_pruning.pt
parser.add_argument('--pruned', action='store_true', default=True, help='pruned model fine train')
4、效果
使用初始训练好的权重进行预测用时 249.217s
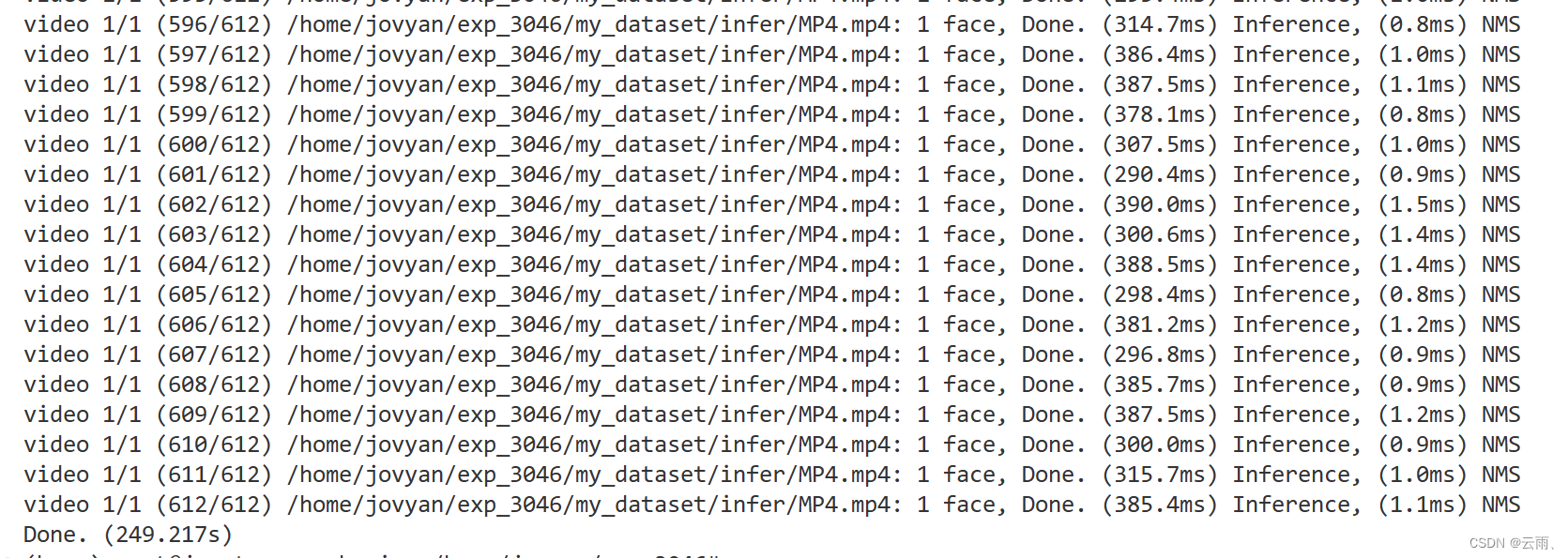
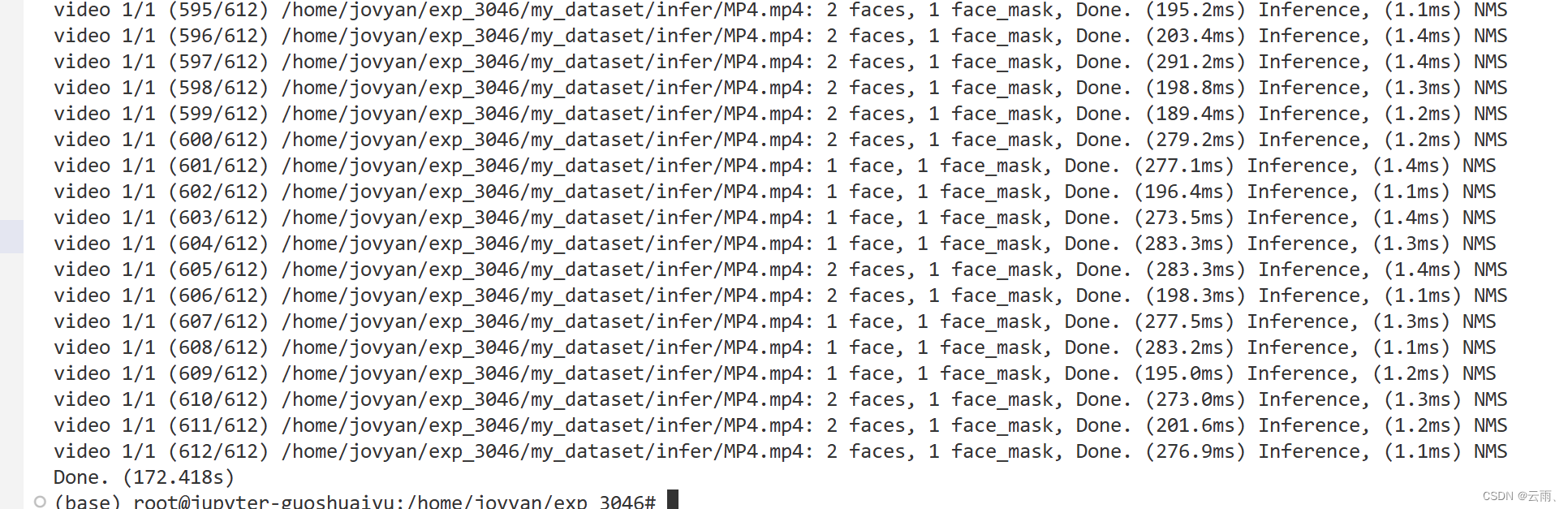
使用剪枝之后的模型进行预测用时172.418s
p.prune_batchnorm, idxs=strategy(m.weight, amount=0.3))logger.info(pruning_plan)pruning_plan.exec()# 获得剪枝以后的参数量num_params_after_pruning = tp.utils.count_params(model)# 输出一下剪枝前后的参数量logger.info(" Params: %s => %s\n" % (num_params_before_pruning, num_params_after_pruning))# 剪枝完以后模型的保存(不要用torch.save(model.state_dict(),...))model_ = {'model': model.half(),# 'optimizer': ckpt['optimizer'],# 'training_results': ckpt['training_results'],'epoch': ckpt['epoch']}torch.save(model_, '/home/jovyan/exp_3046/my_dataset/layer_pruning.pt')del model_, ckptlogger.info("剪枝完成\n")layer_pruning('/home/jovyan/exp_3046/runs/train/best.pt')
3、微调
运行train.py
权重为剪枝之后的layer_pruning.pt
parser.add_argument('--pruned', action='store_true', default=True, help='pruned model fine train')
4、效果
使用初始训练好的权重进行预测用时 249.217s
![[外链图片转存中...(img-BIsS94eN-1705027254462)]](https://img-blog.csdnimg.cn/direct/b3bebe64fff54de59340bdb4e5303486.png)
使用剪枝之后的模型进行预测用时172.418s
![[外链图片转存中...(img-lLdHRbRI-1705027254463)]](https://img-blog.csdnimg.cn/direct/843478b6660341ef945b283a65d4d368.png)
相关文章:
YOLOV7剪枝流程
YOLOV7剪枝流程 1、训练 1)划分数据集进行训练前的准备,按正常的划分流程即可 2)修改train.py文件 第一次处在参数列表里添加剪枝的参数,正常训练时设置为False,剪枝后微调时设置为True parser.add_argument(--pr…...

【React】组件性能优化、高阶组件
文章目录 React性能优化SCUReact更新机制keys的优化render函数被调用shouldComponentUpdatePureComponentshallowEqual方法高阶组件memo 获取DOM方式refs如何使用refref的类型 受控和非受控组件认识受控组件非受控组件 React的高阶组件认识高阶函数高阶组件的定义应用一 – pro…...
实现文字转语音功能)
前端开发中基于Web Speech API(speechSynthesis接口)实现文字转语音功能
文章目录 一、Web Speech 的概念及用法二、Web Speech 的 API 接口1、SpeechSynthesis属性方法 2、SpeechSynthesisUtterance属性方法 三、Web Speech 的 用法用法演示一用法演示二htmljs 四、扩展 一、Web Speech 的概念及用法 在开发业务系统时,有时候可能需要使…...

C++核心编程之通过类和对象的思想对文件进行操作
目录 一、文件操作 1. 文件类型分类: 2. 操作文件的三大类 二、文本文件 1.写文件 2.读文件 三、二进制文件 1.写二进制文件 2.读二进制文件 一、文件操作 程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放 通过文件可以将…...

Verilog语法——4.Verilog工程模板、相应规范再强调
参考资料 【明德扬_verilog零基础入门语法HDL仿真快速掌握-手把手教你写FPGA/ASIC代码设计流程中的应用】 4. Verilog工程模板、相应规范 4.1 Verilog工程模板 4.1.1 设计模块模板 module module_name(clk,rst_n,//其他信号,举例doutdout };//参数定义parameter …...
CNN:Convolutional Neural Network(下)
目录 1 CNN 学到的是什么 1.1 Convolution 中的参数 1.2 FFN 中的参数 1.3 Output 2 Deep Dream 3 Deep Style 4 More Application 4.1 AlphaGo 4.2 Speech 4.3 Text 原视频:李宏毅 2020:Convolutional Neural Network 本博客属于学…...
FPGA时序分析与时序约束(四)——时序例外约束
目录 一、时序例外约束 1.1 为什么需要时序例外约束 1.2 时序例外约束分类 二、多周期约束 2.1 多周期约束语法 2.2 同频同相时钟的多周期约束 2.3 同频异相时钟的多周期约束 2.4 慢时钟域到快时钟域的多周期约束 2.5 快时钟域到慢时钟域的多周期约束 三、虚假路径约…...

无需任何三方库,在 Next.js 项目在线预览 PDF 文件
前言: 之前在使用Vue和其它框架的时候,预览 PDF 都是使用的 PDFObject 这个库,步骤是:下载依赖,然后手动封装一个 PDF 预览组件,这个组件接收本地或在线的pdf地址,然后在页面中使用组件的车时候…...

排序问题——晴问题库
排序问题——晴问题库 排序问题是线性数据的常考问题,在解晴问题库时总结归纳以下关于排序的解题方法和思路。 感谢晴神 排序问题是数据结构中十分重点的一部分。 可以分为五个大部分: 插入排序选择排序交换排序基数归并 再具体往下分: 插…...
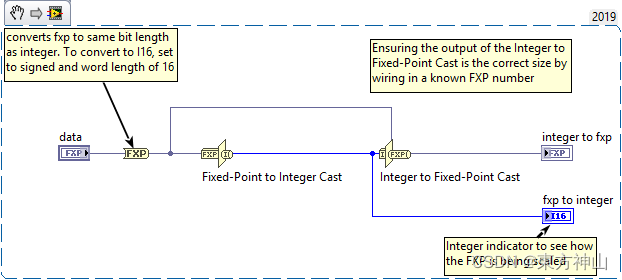
【LabVIEW FPGA入门】FPGA中的数学运算
数值控件选板上的大部分数学函数都支持整数或定点数据类型,但是需要请注意,避免使用乘法、除法、倒数、平方根等函数,此类函数比较占用FPGA资源,且如果使用的是定点数据或单精度浮点数据仅适用于FPGA终端。 1.整数运算 支持的数…...
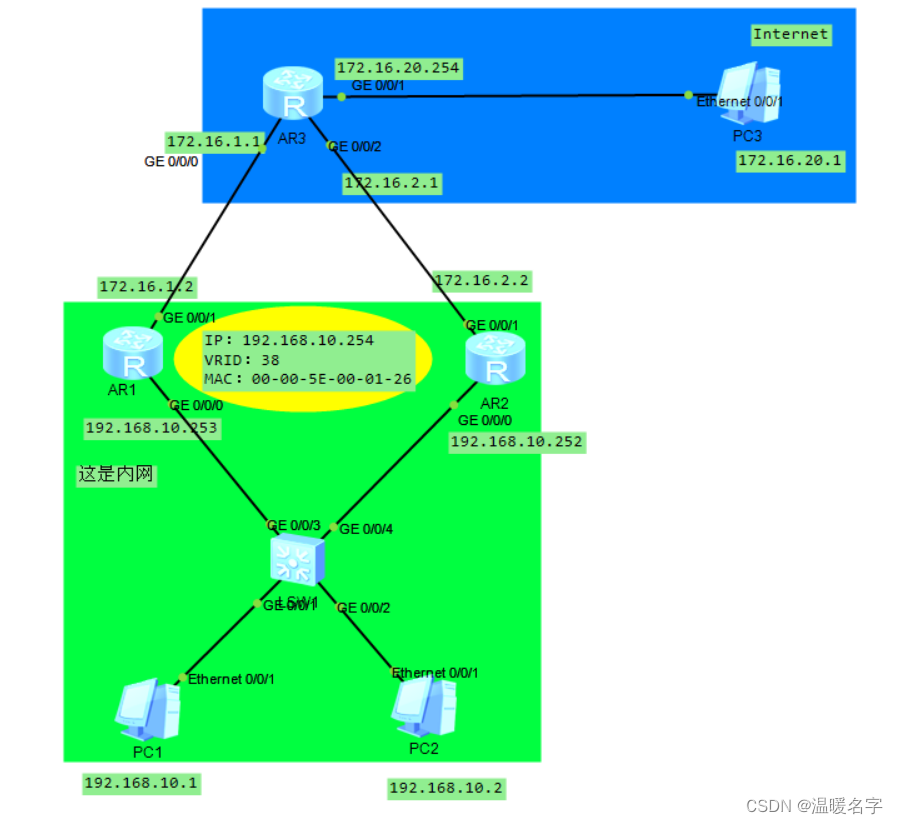
华为设备VRRP配置
核心代码: 需要对所有虚拟路由器设置(要进入到对应的端口) vrrp vrid 38 virtual-ip 192.168.10.254 vrrp vrid 38 priority 120 vrrp vrid 38 track int g0/0/1 reduced 30①mac由vrid生成 ②指定虚拟ip ③虚拟ip作为内部主机的网关&#x…...

2024年艺术发展与文化产业国际会议(ICADCI 2024)
2024年艺术发展与文化产业国际会议(ICADCI 2024) 2024 International Conference on Art Development and Cultural Industry(ICADCI 2024) 数据库:EI,CPCI,CNKI,Google Scholar等 一、【会议简介】 2024年艺术发展与文化产业国际会议(ICADCI 2024)将于丽江这座美丽…...
获取心率_java 华为手表获取心跳)
华为手表开发:WATCH 3 Pro(10)获取心率_java 华为手表获取心跳
华为手表开发:WATCH 3 Pro(10)获取心率_java 华为手表获取心跳 Excerpt 文章浏览阅读1.2k次。鸿蒙开发,获取手表心跳,按钮点击后触发的方法,我们将跳转页面的代码写在这个位置就可以实现点击按钮进行跳转页面的动作。在HTML文件“index.hml”,添加按钮,这里按钮用到是标…...

使用企业订货软件的担忧与考虑|网上APP订货系统
使用企业订货软件的担忧与考虑|网上APP订货系统 网上订货系统担心出现的问题 1,如果在订货系统中定错(多)货物了该怎么办 其实这也是很多人在网购或者是现实中经常会犯的一个错误,但是网上订货平台为大家提供了很多的解决方案,其中对于订单的…...

Java-集合-Collection类
1 需求 2 接口 Interface Collection<E> public interface Collection<E> extends Iterable<E> 2.3 Method Detail int size()boolean isEmpty()boolean contains(Object o)Iterator<E> iterator()Object[] toArray()<T> T[] toArray(T[] a)…...
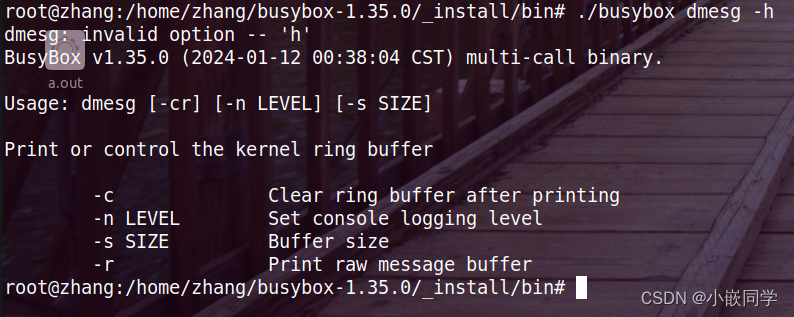
Linux:/proc/kmsg 与 /proc/sys/kernel/printk_xxx
目录 前言一、/proc/kmsg1、简介2、如何修改内核日志缓冲区3、dmesgklogctl 函数(来源于 man 手册) 4、扩展阅读 二、 /proc/sys/kernel/printk_xxx三、/dev/kmsg 前言 本篇文章将为大家介绍与 Linux 内核日志相关的一些控制文件,共同学习&am…...

使用 Postman 发送 get 请求的简易教程
在API开发与测试的场景中,Postman 是一种普遍应用的工具,它极大地简化了发送和接收HTTP请求的流程。要发出GET请求,用户只需设定正确的参数并点击发送即可。 如何使用 Postman 发送一个GET请求 创建一个新请求并将类型设为 GET 首先&#…...
【网站项目】基于jsp的拍卖网站设计与实现
🙊作者简介:多年一线开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

为什么洗衣机会每天自动上传3.6GB数据?
“为什么我家的LG洗衣机每天都会上传3.6GB的数据?” 一位名为Johnie用户发现他家电设备的异常行为后表示很不理解,随后他把相关信息发布在X平台,很快这篇帖子就收获了超过1700万次的浏览量,并迅速变成一场争议和网络安全battle。…...

word写标书的疑难杂症总结
最近在解决方案工作,与office工具经常打交道,各种问题,在此最下记录: 1.word中文档距离文档顶端有距离调整不了 1.疑难杂症问题1,多个空格都是不能解决 #解决办法:word中--布局-下拉框---“版式”--“垂直…...

EASY-HWID-SPOOFER:Windows硬件指纹保护终极方案
EASY-HWID-SPOOFER:Windows硬件指纹保护终极方案 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字时代,您的电脑硬件信息正在被悄无声息地追踪。无论是…...

基于 Python 有限元法的光子微腔仿真:从理论到代码实现
引言:光子微腔与有限元法的结合实例# 安装基础依赖 pip install numpy matplotlib scipy# 安装GMSH网格生成器 pip install gmsh# 安装FEMWELL光子学有限元库 pip install femwell# 安装FEniCSx(FEMWELL的底层依赖) # 对于Ubuntu/Debian系统 …...

启XX辰-头部安全公司面试提问
自我介绍 对称加密有哪些,非对称加密有哪些,两者之间的主要差异 有过JS逆向的经验吗 非对称加密如何获取加密前的内容,已知公钥 如果就给你一个登录框,给出你的测试思路 对于在工作时,给你一个企业名,给出你…...
)
别再只会画矩形了!用Leaflet+L.geoJSON搞定复杂行政区遮罩(含飞地处理)
突破Leaflet遮罩技术瓶颈:复杂行政区与飞地处理的终极方案 当我们面对真实世界中的行政区划数据时,理想化的矩形遮罩显得力不从心。中国行政区划的复杂性——飞地、嵌套洞、不规则边界——要求开发者掌握更高级的地图遮罩技术。本文将带您深入Leaflet的L…...

第10章:自动化运维体系
第10章:自动化运维体系 10.1 为什么需要自动化运维 在大规模ES集群运维中,手动运维面临以下挑战: 手动运维的痛点: 效率低下: 100个集群,手动配置耗时巨大 配置不一致: 手动配置容易出错,配置不一致 响应慢: 故障时手动操作响应慢,影响SLA 不可追溯: 手动操作难以追溯,无法回…...

明日方舟智能基建管理终极指南:5分钟实现全自动资源生产
明日方舟智能基建管理终极指南:5分钟实现全自动资源生产 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 还在为《明日方舟》繁琐的基建管理而头疼吗?每天花费大量时间手动…...

Python开发者快速上手,十分钟完成Taotoken API第一个聊天调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者快速上手,十分钟完成Taotoken API第一个聊天调用 对于希望快速体验不同大语言模型能力的Python开发者来说…...

Real-ESRGAN终极指南:5分钟掌握AI图像超分辨率技术,让模糊照片秒变高清
Real-ESRGAN终极指南:5分钟掌握AI图像超分辨率技术,让模糊照片秒变高清 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real…...

架构解密:如何通过FastExcel流式处理引擎重塑Java Excel操作效率标准
架构解密:如何通过FastExcel流式处理引擎重塑Java Excel操作效率标准 【免费下载链接】fastexcel Generate and read big Excel files quickly 项目地址: https://gitcode.com/gh_mirrors/fas/fastexcel 在当今数据驱动的企业环境中,Excel文件处理…...

Win11Debloat:Windows 11系统优化终极指南,免费提升电脑性能50%
Win11Debloat:Windows 11系统优化终极指南,免费提升电脑性能50% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes…...