elasticsearch[一]-索引库操作(轻松创建)、文档增删改查、批量写入(效率倍增)
elasticsearch[一]-索引库操作(轻松创建)、文档增删改查、批量写入(效率倍增)
1、初始化 RestClient
在 elasticsearch 提供的 API 中,与 elasticsearch 一切交互都封装在一个名为 RestHighLevelClient 的类中,必须先完成这个对象的初始化,建立与 elasticsearch 的连接。
分为三步:
1)引入 es 的 RestHighLevelClient 依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>2)因为 SpringBoot 默认的 ES 版本是 7.6.2,所以我们需要覆盖默认的 ES 版本:
<properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>3)初始化 RestHighLevelClient:
初始化的代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://xxx.xxx.xxx.xxx:9200")
));这里为了单元测试方便,我们创建一个测试类 HotelIndexTest,然后将初始化的代码编写在 @BeforeEach 方法中:
package cn.itcast.hotel;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.io.IOException;public class HotelIndexTest {private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://xxx.xxx.xxx.xxx:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}1.1、创建索引库
创建索引库的 API 如下:

代码分为三步:
- 1)创建 Request 对象。因为是创建索引库的操作,因此 Request 是 CreateIndexRequest。
- 2)添加请求参数,其实就是 DSL 的 JSON 参数部分。因为 json 字符串很长,这里是定义了静态字符串常量 MAPPING_TEMPLATE,让代码看起来更加优雅。
- 3)发送请求,client.indices() 方法的返回值是 IndicesClient 类型,封装了所有与索引库操作有关的方法。
完整示例
在 hotel-demo 的 cn.itcast.hotel.constants 包下,创建一个类,定义 mapping 映射的 JSON 字符串常量:
package cn.itcast.hotel.constants;public class HotelConstants {public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}在 hotel-demo 中的 HotelIndexTest 测试类中,编写单元测试,实现创建索引:
@Test
void createHotelIndex() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2.准备请求的参数:DSL语句request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}1.2、删除索引库
删除索引库的 DSL 语句非常简单:
DELETE /hotel与创建索引库相比:
- 请求方式从 PUT 变为 DELTE
- 请求路径不变
- 无请求参数
所以代码的差异,注意体现在 Request 对象上。依然是三步走:
- 1)创建 Request 对象。这次是 DeleteIndexRequest 对象
- 2)准备参数。这里是无参
- 3)发送请求。改用 delete 方法
在 hotel-demo 中的 HotelIndexTest 测试类中,编写单元测试,实现删除索引:
@Test
void testDeleteHotelIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);
}1.3、判断索引库是否存在
判断索引库是否存在,本质就是查询,对应的 DSL 是:
GET /hotel因此与删除的 Java 代码流程是类似的。依然是三步走:
- 1)创建 Request 对象。这次是 GetIndexRequest 对象
- 2)准备参数。这里是无参
- 3)发送请求。改用 exists 方法
@Test
void testExistsHotelIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("hotel");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}1.4、总结
JavaRestClient 操作 elasticsearch 的流程基本类似。核心是 client.indices() 方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化 RestHighLevelClient
- 创建 XxxIndexRequest。XXX 是 Create、Get、Delete
- 准备 DSL( Create 时需要,其它是无参)
- 发送请求。调用 RestHighLevelClient#indices().xxx() 方法,xxx 是 create、exists、delete
2、RestClient 操作文档
为了与索引库操作分离,我们再次参加一个测试类,做两件事情:
- 初始化 RestHighLevelClient
- 我们的酒店数据在数据库,需要利用 IHotelService 去查询,所以注入这个接口
package cn.itcast.hotel;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.service.IHotelService;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import java.util.List;@SpringBootTest
public class HotelDocumentTest {@Autowiredprivate IHotelService hotelService;private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}2.1、新增文档
我们要将数据库的酒店数据查询出来,写入 elasticsearch 中。
2.1.1、索引库实体类
数据库查询后的结果是一个 Hotel 类型的对象。结构如下:
@Data
@TableName("tb_hotel")
public class Hotel {@TableId(type = IdType.INPUT)private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String longitude;private String latitude;private String pic;
}与我们的索引库结构存在差异:
- longitude 和 latitude 需要合并为 location
因此,我们需要定义一个新的类型,与索引库结构吻合:
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}2.1.2. 语法说明
新增文档的 DSL 语句如下:
POST /{索引库名}/_doc/1
{"name": "Jack","age": 21
}对应的 java 代码如图:

可以看到与创建索引库类似,同样是三步走:
- 1)创建 Request 对象
- 2)准备请求参数,也就是 DSL 中的 JSON 文档
- 3)发送请求
变化的地方在于,这里直接使用 client.xxx() 的 API,不再需要 client.indices() 了。
2.1.3、完整代码
我们导入酒店数据,基本流程一致,但是需要考虑几点变化:
- 酒店数据来自于数据库,我们需要先查询出来,得到 hotel 对象
- hotel 对象需要转为 HotelDoc 对象
- HotelDoc 需要序列化为 json 格式
因此,代码整体步骤如下:
- 1)根据 id 查询酒店数据 Hotel
- 2)将 Hotel 封装为 HotelDoc
- 3)将 HotelDoc 序列化为 JSON
- 4)创建 IndexRequest,指定索引库名和 id
- 5)准备请求参数,也就是 JSON 文档
- 6)发送请求
在 hotel-demo 的 HotelDocumentTest 测试类中,编写单元测试:
@Test
void testAddDocument() throws IOException {// 1.根据id查询酒店数据Hotel hotel = hotelService.getById(61083L);// 2.转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 3.将HotelDoc转jsonString json = JSON.toJSONString(hotelDoc);// 1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());// 2.准备Json文档request.source(json, XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);
}2.2、查询文档
2.2.1、语法说明
查询的 DSL 语句如下:
GET /hotel/_doc/{id}非常简单,因此代码大概分两步:
- 准备 Request 对象
- 发送请求
不过查询的目的是得到结果,解析为 HotelDoc,因此难点是结果的解析。完整代码如下:
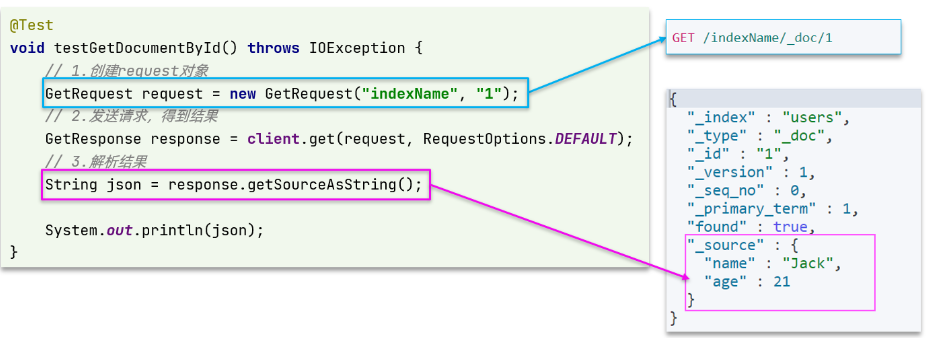
可以看到,结果是一个 JSON,其中文档放在一个_source属性中,因此解析就是拿到_source,反序列化为 Java 对象即可。
与之前类似,也是三步走:
- 1)准备 Request 对象。这次是查询,所以是 GetRequest
- 2)发送请求,得到结果。因为是查询,这里调用 client.get() 方法
- 3)解析结果,就是对 JSON 做反序列化
2.2.2、完整代码
在 hotel-demo 的 HotelDocumentTest 测试类中,编写单元测试:
@Test
void testGetDocumentById() throws IOException {// 1.准备RequestGetRequest request = new GetRequest("hotel", "61082");// 2.发送请求,得到响应GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.解析响应结果String json = response.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);
}2.3. 删除文档
删除的 DSL 为是这样的:
DELETE /hotel/_doc/{id}与查询相比,仅仅是请求方式从 DELETE 变成 GET,可以想象 Java 代码应该依然是三步走:
- 1)准备 Request 对象,因为是删除,这次是 DeleteRequest 对象。要指定索引库名和 id
- 2)准备参数,无参
- 3)发送请求。因为是删除,所以是 client.delete() 方法
在 hotel-demo 的 HotelDocumentTest 测试类中,编写单元测试:
@Test
void testDeleteDocument() throws IOException {// 1.准备RequestDeleteRequest request = new DeleteRequest("hotel", "61083");// 2.发送请求client.delete(request, RequestOptions.DEFAULT);
}2.4、修改文档
2.4.1、语法说明
修改我们讲过两种方式:
- 全量修改:本质是先根据 id 删除,再新增
- 增量修改:修改文档中的指定字段值
在 RestClient 的 API 中,全量修改与新增的 API 完全一致,判断依据是 ID:
- 如果新增时,ID 已经存在,则修改
- 如果新增时,ID 不存在,则新增
这里不再赘述,我们主要关注增量修改。
代码示例如图:
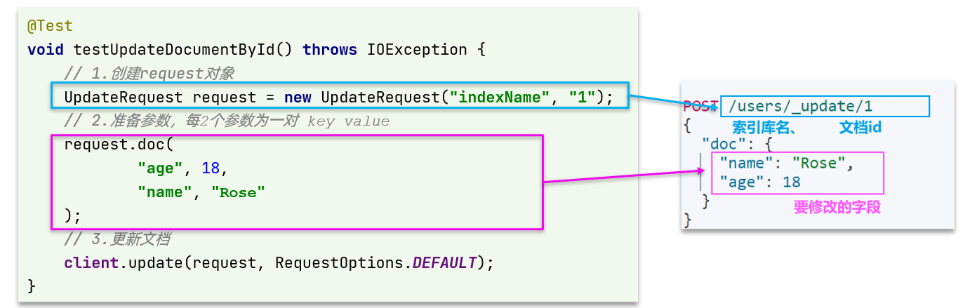
与之前类似,也是三步走:
- 1)准备 Request 对象。这次是修改,所以是 UpdateRequest
- 2)准备参数。也就是 JSON 文档,里面包含要修改的字段
- 3)更新文档。这里调用 client.update() 方法
2.4.2. 完整代码
在 hotel-demo 的 HotelDocumentTest 测试类中,编写单元测试:
@Test
void testUpdateDocument() throws IOException {// 1.准备RequestUpdateRequest request = new UpdateRequest("hotel", "61083");// 2.准备请求参数request.doc("price", "952","starName", "四钻");// 3.发送请求client.update(request, RequestOptions.DEFAULT);
}2.5、批量导入文档
案例需求:利用 BulkRequest 批量将数据库数据导入到索引库中。
步骤如下:
-
利用 mybatis-plus 查询酒店数据
-
将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
-
利用 JavaRestClient 中的 BulkRequest 批处理,实现批量新增文档
2.5.1. 语法说明
批量处理 BulkRequest,其本质就是将多个普通的 CRUD 请求组合在一起发送。
其中提供了一个 add 方法,用来添加其他请求:
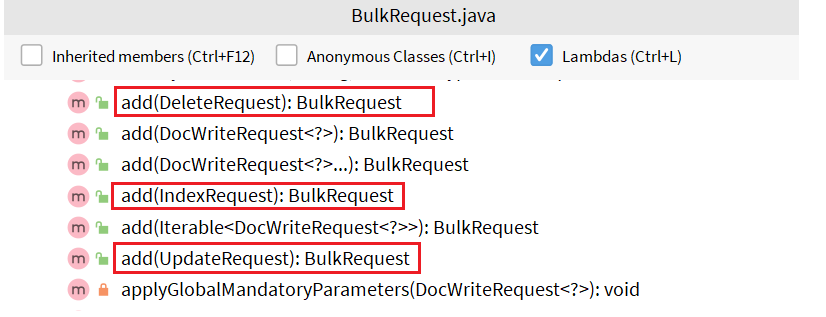
可以看到,能添加的请求包括:
- IndexRequest,也就是新增
- UpdateRequest,也就是修改
- DeleteRequest,也就是删除
因此 Bulk 中添加了多个 IndexRequest,就是批量新增功能了。示例:
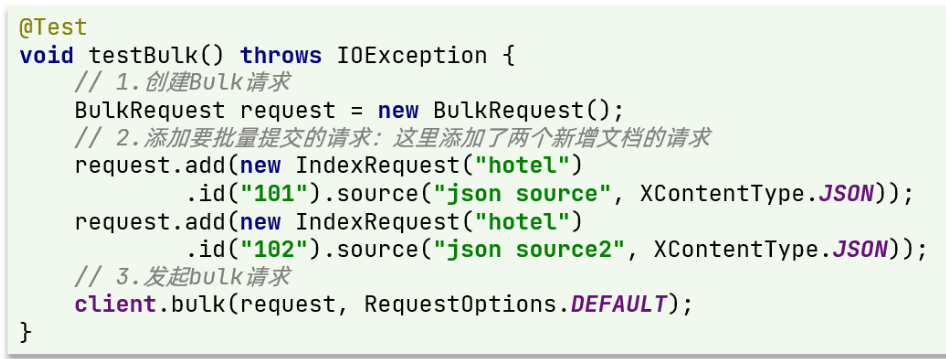
其实还是三步走:
- 1)创建 Request 对象。这里是 BulkRequest
- 2)准备参数。批处理的参数,就是其它 Request 对象,这里就是多个 IndexRequest
- 3)发起请求。这里是批处理,调用的方法为 client.bulk() 方法
我们在导入酒店数据时,将上述代码改造成 for 循环处理即可。
2.5.2. 完整代码
在 hotel-demo 的 HotelDocumentTest 测试类中,编写单元测试:
/*** 批量导入es* @throws IOException*/@Testvoid testBatchImportDocument() throws IOException {// 1、批量查询数据库数据List<Hotel> list = hotelService.list();// 2、创建 request 对象BulkRequest request = new BulkRequest();// 3、转换文档格式for (Hotel hotel : list) {HotelDoc hotelDoc = new HotelDoc(hotel);request.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 4、发送请求client.bulk(request, RequestOptions.DEFAULT);}2.6. 小结
文档操作的基本步骤:
- 初始化 RestHighLevelClient
- 创建 XxxRequest。XXX 是 Index、Get、Update、Delete、Bulk
- 准备参数(Index、Update、Bulk 时需要)
- 发送请求。调用 RestHighLevelClient#.xxx() 方法,xxx 是 index、get、update、delete、bulk
- 解析结果(Get 时需要)
参考链接:https://www.cnblogs.com/DeryKong/p/17002492.html
相关文章:
elasticsearch[一]-索引库操作(轻松创建)、文档增删改查、批量写入(效率倍增)
elasticsearch[一]-索引库操作(轻松创建)、文档增删改查、批量写入(效率倍增) 1、初始化 RestClient 在 elasticsearch 提供的 API 中,与 elasticsearch 一切交互都封装在一个名为 RestHighLevelClient 的类中,必须先完成这个对象的初始化,…...

tp6框架中Http类 请求的header、body参数传参 及post、file格式
引入Http类: 在需要使用的地方引入Http类: use think\facade\Http; GET请求示例:$response Http::get(https://example.com/api/resource); 设置Header参数: $headers [ Authorization > Bearer YourAccessToken, Conte…...

基于极限学习机的图像处理,基于ELM的图像分割,基于极限学习机的细胞分割
目录 背影 极限学习机 基于极限学习机的图像,基于ELM的图像分割 主要参数 MATLAB代码 效果图 结果分析 展望 完整代码下载链接:基于极限学习机的图像,基于ELM的图像分割(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.net/download/abc991835105/88759192 背…...

ELAU C400/A8/1/1/1/00嵌入式系统中的模块动态加载技术
ELAU C400/A8/1/1/1/00嵌入式系统中的模块动态加载技术 ... 代码。这些script会根据模块名字查找模块对应的模块声明文件,并根据该 ... 的地址,注册时需提供模块名和模块重定位表的地址。加 ... 。这个表的表项是“模块名”到“模块重定位表地址”…...

github clone Failed to connect to github.com port 443 after xxx ms
最近克隆github项目时老是报超时,可以尝试以下解决方法 如果本地开启了代理还是clone超时,可以尝试最后一种方式解决 1、把 https 换成 http,如: git clone http:xxx2、更新本地hosts配置,可以参考这篇文章获取最新的…...

ARM的一些基础知识
1.低功耗接口 P-CHANNEL和Q-CHANNEL AMBA低功耗接口(一)Q_Channel_q-channel p-channel-CSDN博客 AMBA低功耗接口(二)P_Channel_p channel-CSDN博客 2.WFI和WFE指令 ARM WFI和WFE指令 ARM hint instruction-WFI(Wait For In…...

零售的数字化转型,利用AWS云服务资源如何操作?
国内市场趋于饱满,各行各业的发展接近瓶颈,就连零售行业都竞争激烈,随处可见的零售小店也预示着需要投入大量的人力,而且由于消费者的行为和预期已经发生了根本性变化,这迫使零售商不得不加速整个价值链的数字化转型&a…...

【通知】我的教学文章《Rust跟我学》已全部上线
大家好,我是get_local_info开源库作者带剑书生,现在我的《Rust跟我学》专栏文章已全部上线,它记录了我在写库时获得的重要Rust经验和技巧,是不同于《Rust语言编程》等简单实践的书籍。为您节省了学习时间,让您可以快速…...

Docker安全基线检查需要修复的一些问题
一、可能出现的漏洞 限制容器之间的网络流量 限制容器的内存使用量 为Docker启用内容信任 将容器的根文件系统挂载为只读 审核Docker文件和目录 默认情况下,同一主机上的容器之间允许所有网络通信。 如果不需要,请限制所有容器间的通信。 将需要相互通…...
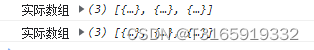
MobX 的 Observable Array,如何转换成一个普通的数组
问题描述 访问mobx store里面的数据时打印结果为如下,是一个 MobX 的 Observable Array,而不是一个普通的数组。MobX 使用 Proxy 来实现响应式数据,因此打印的结果为的是 Proxy 对象。可是我需要的是实际的数组数据。 Proxy {0: Proxy, 1: …...

spring boot集成loback日志配置
1.spring boot中application.properties配置 logging.configclasspath:loback-config.xml 2.配置loback-config.xml <?xml version"1.0" encoding"UTF-8"?> <!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR <…...

【mars3d】 graphic.bindPopup(inthtml).openPopup()无需单击小车,即可在地图上自动激活弹窗的效果。
实现效果:new mars3d.graphic.FixedRoute({无需单击小车,即可在地图上实现默认打开弹窗的激活效果。↓↓↓↓↓↓↓↓ 相关链接说明: 1.popup的示例完全开源,可参考:功能示例(Vue版) | Mars3D三维可视化平台 | 火星科…...
工厂企业消防安全AI可视化视频智能监管解决方案
一、方案背景 2023年11月20日下午6时30分许,位于江苏省无锡市惠山区前洲街道的某公司突发严重火灾,共造成7人死亡。这次火灾提醒我们工业安全至关重要,企业都应该时刻保持警惕,加强安全意识和培训,提高应对突发事件的…...
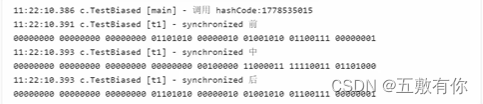
【并发编程】synchornized原理
📝个人主页:五敷有你 🔥系列专栏:并发编程 ⛺️稳重求进,晒太阳 目录 Monitor概念 Java对象头 普通对象 数组对象 Monitor(锁) Monitor结构如下: 注意: 原理之synchornized 轻量…...
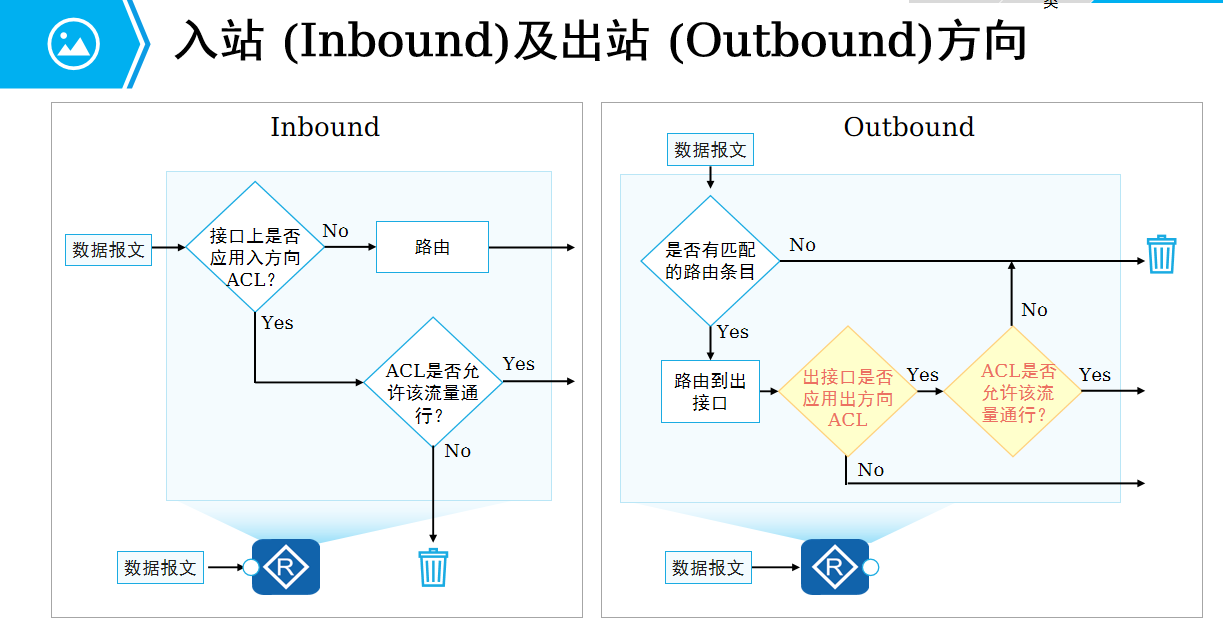
计算机网络-ACL访问控制列表
上一篇介绍NAT时候就看到了ACL这个东西了,这个是什么意思?有什么作用呢? 一、ACL访问控制列表 访问控制列表 (ACL, Access Control List)是由一系列permit或deny语句组成的、有序规则的列表。ACL是一个匹配工具,能够对报文进行匹配…...
论文学习记录之SeisInvNet(Deep-Learning Inversion of Seismic Data)
目录 1 INTRODUCTION—介绍 2 RELATED WORKS—相关作品 3 METHODOLOGY AND IMPLEMENTATION—方法和执行 3.1 方法 3.2 执行 4 EXPERIMENTS—实验 4.1 数据集准备 4.2 实验设置 4.3 基线模型 4.4 定向比较 4.5 定量比较 4.6 机理研究 5 CONCLUSION—结论 1 INTRODU…...

深度学习中的优化方法
深度学习中的优化问题通常指的是:寻找神经网络上的一组参数 θ \theta θ,它能显著地降低代价函数 J ( θ ) J(\theta) J(θ...
【设计模式之美】重构(三)之解耦方法论:如何通过封装、抽象、模块化、中间层等解耦代码?
文章目录 一. “解耦”概述二. 如何给代码“解耦”?1. 封装与抽象2. 中间层2.1. 引入中间层能**简化模块或类之间的依赖关系**。2.2. 引入中间层可以起到过渡的作用,能够让开发和重构同步进行,不互相干扰。 3. 模块化4. 其他设计思想和原则4.…...

Spring MVC学习之——Controller类中方法的返回值
Controller类中方法的返回值 1.返回ModelAndView RequestMapping("/hello")public ModelAndView hello(){//封装了页面和数据ModelAndView view new ModelAndView();//对这个请求的页面添加属性(数据)view.addObject("hello",&quo…...
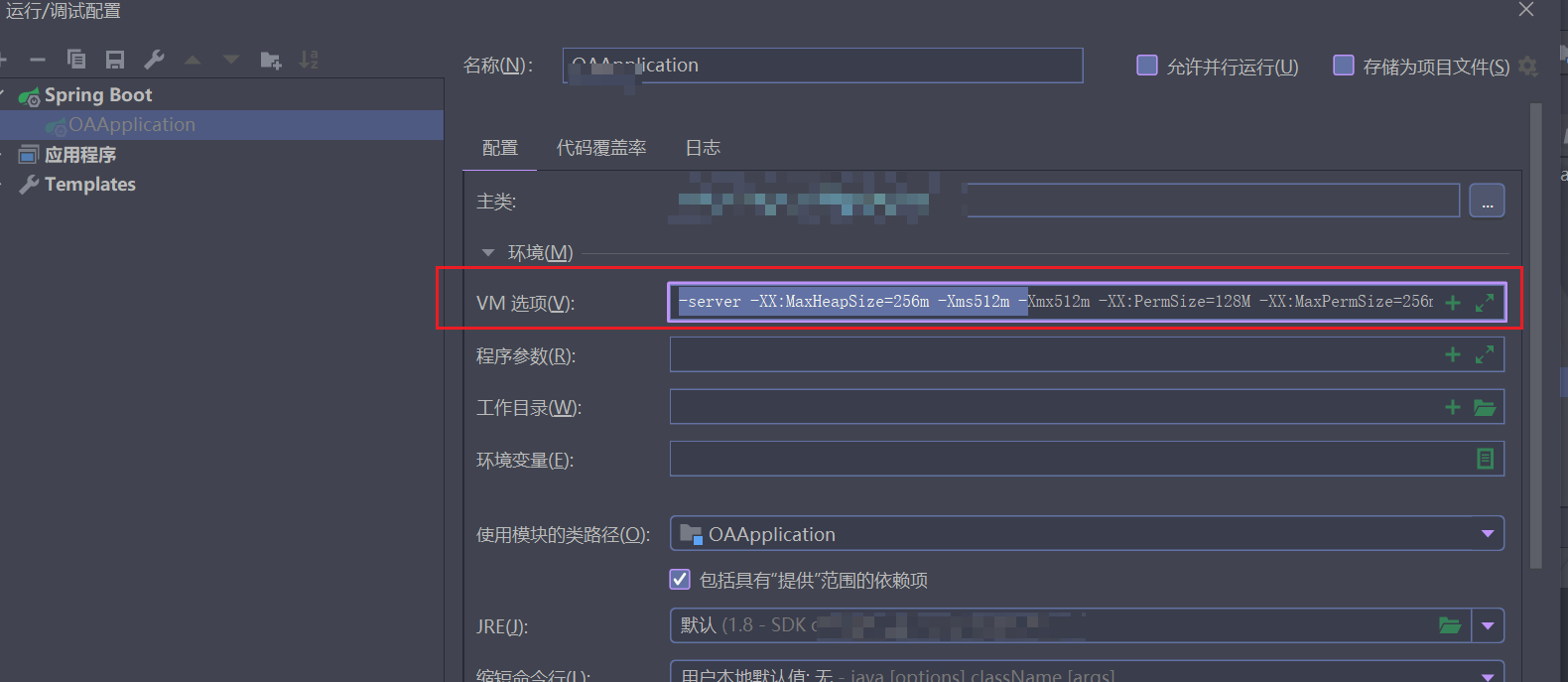
IDEA中启动项目报堆内存溢出或者没有足够内存的错误
1.报错现象 java.lang.OutOfMemoryError: Java heap space 或者 Could not reserve enough space for object heap 2.解决办法 在运行配置中VM选项后加下面的配置: -server -XX:MaxHeapSize256m -Xms512m -Xmx512m -XX:PermSize128M -XX:MaxPermSize256m 3.JVM虚…...

AMD游戏本ChinaJoy三连发:从3D V-Cache到性价比旗舰的全面解析
1. 项目概述:ChinaJoy 2023上的AMD游戏本盛宴每年ChinaJoy不仅是游戏玩家的狂欢,更是硬件厂商展示肌肉的舞台。今年,这个舞台的主角无疑是AMD。当大家还在讨论移动端处理器核心数大战时,AMD直接甩出了“缓存为王”的王炸ÿ…...
)
定义查询≠复制粘贴:Perplexity定义功能的稀缺性使用手册(仅限前500名深度用户验证的6条黄金规则)
更多请点击: https://intelliparadigm.com 第一章:定义查询≠复制粘贴:Perplexity定义功能的本质再认知 Perplexity 的“定义查询”(Define Query)并非对搜索引擎结果的简单抓取与拼接,而是一种基于语义理…...

别再死记硬背了!用这5个Shapely实战案例,轻松搞定GIS数据处理
用5个实战案例解锁Shapely:告别枯燥API,玩转GIS数据处理 第一次接触Shapely时,我也曾被那些晦涩的几何术语和冰冷的API文档劝退。直到接手一个城市绿化分析项目,被迫在三天内完成公园边界处理,才真正体会到这个库的魔力…...

深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱
深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱 【免费下载链接】IDR Interactive Delphi Reconstructor 项目地址: https://gitcode.com/gh_mirrors/id/IDR 你是否曾经面对一个Delphi编译的程序,却无法理解它的内部逻辑?或者需要…...

IPXWrapper终极指南:让90年代经典游戏在现代Windows上重生联机对战
IPXWrapper终极指南:让90年代经典游戏在现代Windows上重生联机对战 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 对于许多怀旧游戏玩家来说,最大的遗憾莫过于那些经典的《星际争霸》、《帝国时代》、《…...

UML类图实战:从设计到代码的精准映射
1. 为什么需要从UML类图到代码的精准映射? 第一次接触UML类图时,我总觉得它像是一张"纸上谈兵"的设计稿。直到在实际项目中踩过几次坑才明白,类图与代码之间的精准映射能力,是区分普通程序员和架构师的关键技能之一。 …...

2026年最新推荐 很多一线老师都在用的英语作文批改工具
行业共性痛点拆解我们团队做英语教育技术落地5年,接触过全国上千位初高中英语老师,发现作文批改是大家公认的效率洼地。人工批改模式下,一个45人班的作文,每篇要改语法、逻辑、表达、扣题四个维度,最少花3分钟…...

RT-Thread开发者大会技术解析:从RTOS内核到AIoT平台实战指南
1. 项目概述:一场国产嵌入式技术的年度盛会 2021年的RT-Thread开发者大会,对于当时国内嵌入式软件圈的从业者来说,绝对是一个绕不开的关键节点。那一年,整个行业正处在一个微妙的转折期:一方面,芯片供应链…...

3分钟快速激活Windows和Office:KMS智能激活工具终极指南
3分钟快速激活Windows和Office:KMS智能激活工具终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成…...

Escrcpy终极指南:简单高效的Android图形化投屏完整方案
Escrcpy终极指南:简单高效的Android图形化投屏完整方案 【免费下载链接】escrcpy 📱 Display and control your Android device graphically with scrcpy. 项目地址: https://gitcode.com/GitHub_Trending/es/escrcpy 你是否厌倦了复杂的命令行操…...