李沐深度学习-线性回归从零开始
# 核心Tensor,autograd
import torch
from IPython import display
import numpy as np
import random
from matplotlib import pyplot as pltimport syssys.path.append('路径')
from d2lzh_pytorch import *'''
backward()函数:一次小批量执行完在进行反向传播
线性回归模型步骤;1.数据处理2.模型定义:根据矩阵形式运算,模型可以一次计算多个样本,比如X:1000x2, w:2x1 则模型可以一次计算1000个样本3.损失函数:4.优化算法:sgd则是小批量中每个样本loss运行完后,对应参数的梯度进行了累加,得到一个小批量的代表梯度 w1,w2,b然后将每个小批量的参数梯度进行梯度下降5.模型预测
'''
# ------------------------------------------------------------------------
# 生成数据集
'''
样本X=1000,特征=2,w=2,-3.4;b=4.2 随机噪声ξ y=Xw+b+ξ
噪声服从均值为0,标准差为0.01的正态分布 噪声代表了数据集中无意义的干扰
'''
num_inputs = 2 # 特征数
num_examples = 1000 # 样本数量
true_w = [2, -3.4] # w
true_b = 4.3 # b
# 生成所有包含特征 1000x2的样本 向量
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
# 下列运算属于矢量运算 预测y 表达式 是个向量,1000x1
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
# 添加符合正态分布的噪声
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float32)# set_figsize()
# plt.scatter(features[:, 1].numpy(), labels.numpy(), 1)
# plt.savefig('/home/eilab2023/yml/project/limu/picture/picture.png')# 读取数据集# ---------------------------------------------------------------------------------------------# ---------------------------------------------------------------------------------------------
# 定义模型# ---------------------------------------------------------------------------------------------# 损失函数
# ---------------------------------------------------------------------------------------------# 优化算法
# ---------------------------------------------------------------------------------------------# 模型训练
# ---------------------------------------------------------------------------------------------
lr = 0.03
num_epoch = 3
net = linreg
loss = squared_loss
'''
每次返回一个batch-size大小随机样本的特征和标签
'''
batch_size = 10
# 初始化模型参数 w b 都是列矩阵 上面的是确定的公式,x,w,b都是确定的,label确定。这里的参数是初始化模拟的
# 一般是,X确定,label确定,然后初始化w,b,在模型训练寻找最优解,这里提前确定是为了方便
w = torch.tensor((np.random.normal(0, 0.01, (num_inputs, 1))), dtype=torch.float32)
b = torch.tensor(1, dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
# 外部定义了变量w后若在方法内有改变w,则该变量值会随着改变for epoch in range(num_epoch):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y).sum() # 小批量的损失计算完l.backward() # 计算小批量的样本参数梯度,这里每个样本的参数梯度会自动累加sgd([w, b], lr, batch_size) # 一个小批量出一个w,b 梯度下降算法# 一个小批量的参数更新后就要对参数的梯度进行清零操作w.grad.data.zero_()b.grad.data.zero_()train_l = loss(net(features, w, b), labels) # 这里的w,b是一轮所有的批量更新完成之后得到的最新的值,然后用于所有的样本进行损失计算print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item())) # 因为loss是一个1000x1的一个张量相关文章:

李沐深度学习-线性回归从零开始
# 核心Tensor,autograd import torch from IPython import display import numpy as np import random from matplotlib import pyplot as pltimport syssys.path.append(路径) from d2lzh_pytorch import * backward()函数:一次小批量执行完在进行反向传播 线性回归…...
CentOS 8.5 安装图解
特特特别的说明 CentOS发行版已经不再适合应用于生产环境,客观条件不得不用的话,优选7.9版本,8.5版本次之,最次6.10版本(比如说Oracle 11GR2就建议在6版本上部署)! 引导和开始安装 选择倒计时结…...
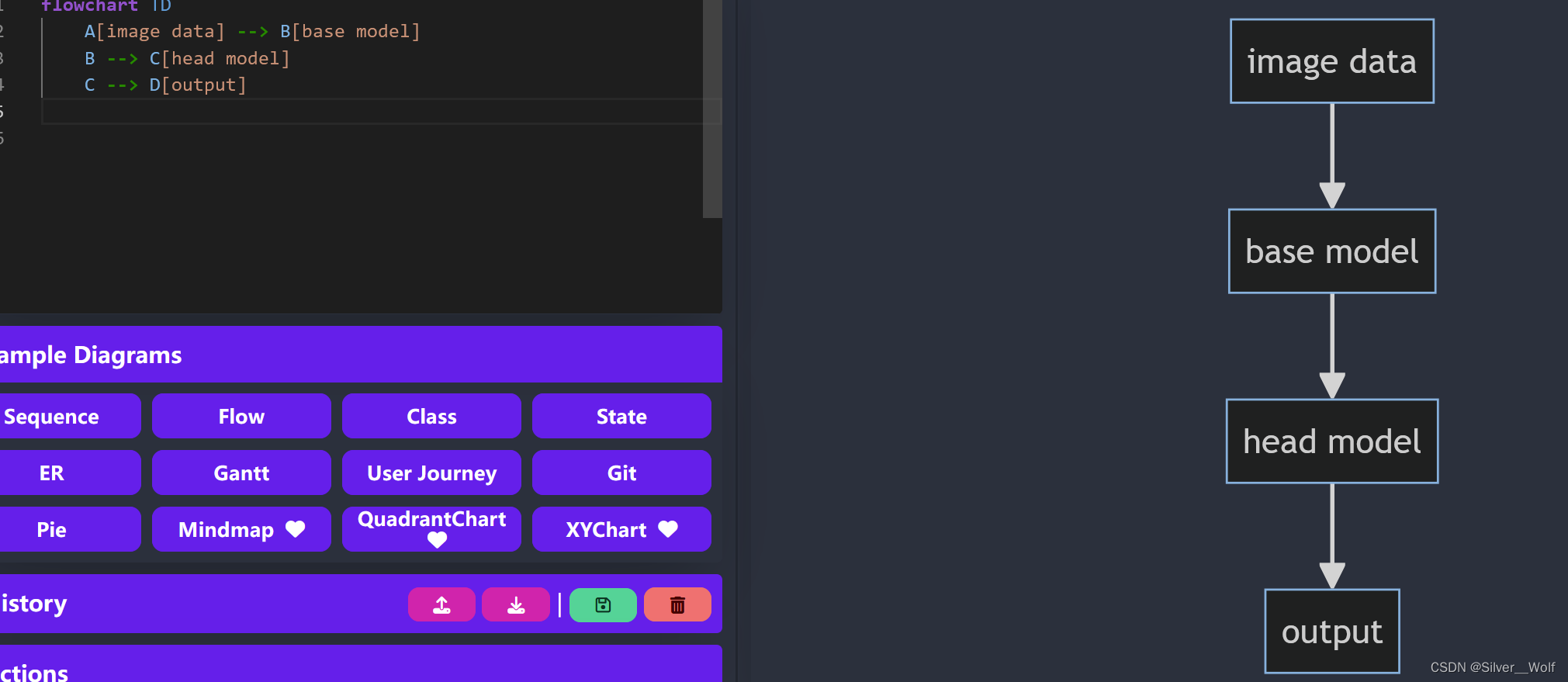
好用的流程图工具
分享工作中常用的装逼工具 目前市面上的流程图或者思维导图工具挺多的,但是有的会限制使用数量或者收费,典型的有processon、Xmind,推荐今天Mermaid(官网)。 快速上手 中文教程:Mermaid 初学者用户指南 | Mermaid 中文网。我们选择…...
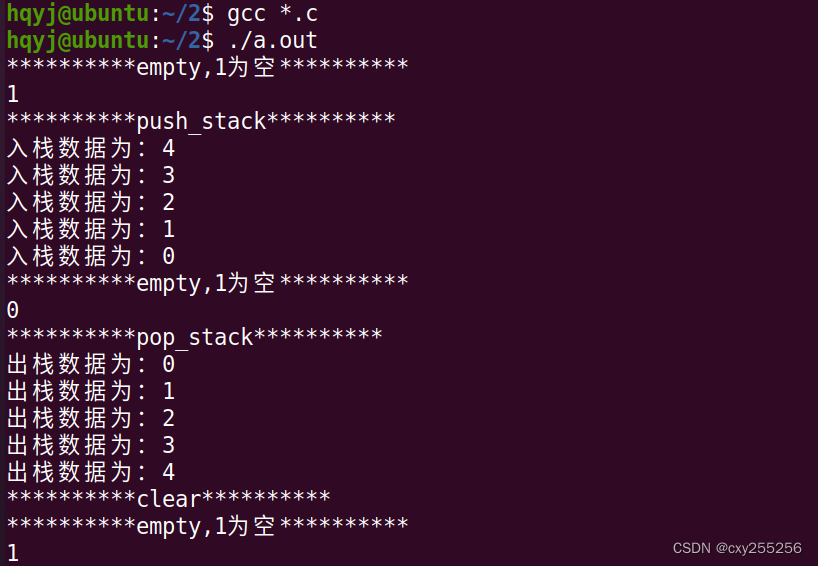
数据结构:链式栈
stack.h /* * 文件名称:stack.h * 创 建 者:cxy * 创建日期:2024年01月18日 * 描 述: */ #ifndef _STACK_H #define _STACK_H#include <stdio.h> #include <stdlib.h>typedef struct stack{int data…...

openssl3.2 - 官方demo学习 - mac - gmac.c
文章目录 openssl3.2 - 官方demo学习 - mac - gmac.c概述笔记END openssl3.2 - 官方demo学习 - mac - gmac.c 概述 使用GMAC算法, 设置参数(指定加密算法 e.g. AES-128-GCM, 设置iv) 用key执行初始化, 然后对明文生成MAC数据 官方注释给出建议, key, iv最好不要硬编码出现在程…...
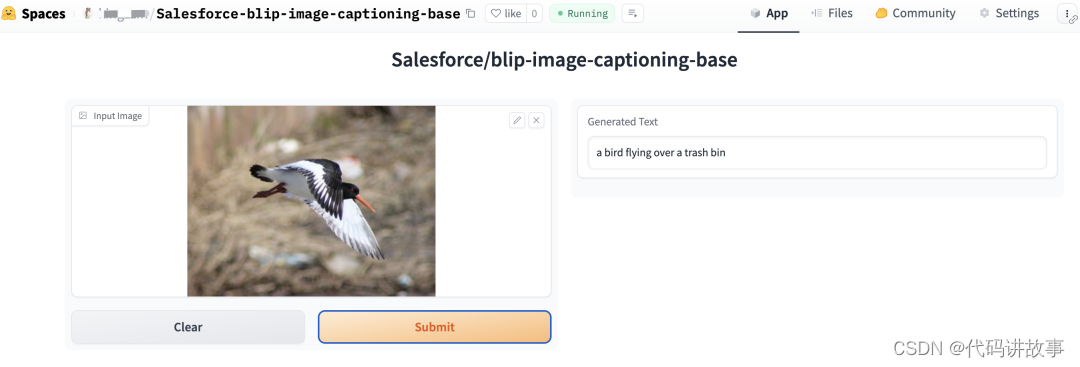
HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍
HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍。 Hugging Face是一家开源模型库公司。 2023年5月10日,Hugging Face宣布C轮1亿美元融资,由Lux Capital领投,红杉资本、Coatue、Betaworks、NBA球星Kevin Durant等跟投…...

python的tabulate包在命令行下输出表格不对齐
用tabulate可以在命令行下输出表格。 from tabulate import tabulate# 定义表头 headers [列1, 列2, 列3]# 每行的内容 rows [] rows.append((张三,数学,英语)) rows.append((李四,信息科技,数学))# 使用 tabulate 函数生成表格 output tabulate(rows, headersheaders, tab…...
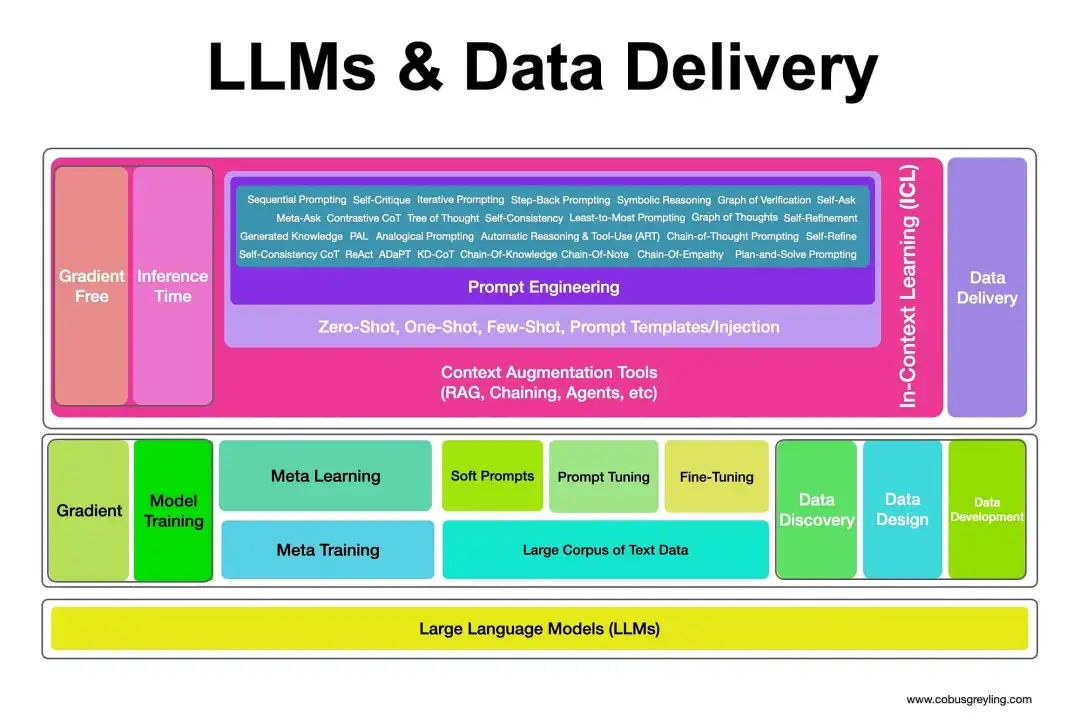
LLM之幻觉(二):大语言模型LLM幻觉缓减技术综述
LLM幻觉缓减技术分为两大主流,梯度方法和非梯度方法。梯度方法是指对基本LLM进行微调;而非梯度方法主要是在推理时使用Prompt工程技术。LLM幻觉缓减技术,如下图所示: LLM幻觉缓减技术值得注意的是: 检索增强生成&…...

C# 使用多线程,关闭窗体时,退出所有线程
this.Close(); 只是关闭当前窗口,若不是主窗体的话,是无法退出程序的,另外若有托管线程(非主线程),也无法干净地退出;Application.Exit(); 强制所有消息中止,退出所有的窗体&…...

数据结构实验6:图的应用
目录 一、实验目的 1. 邻接矩阵 2. 邻接矩阵表示图的结构定义 3. 图的初始化 4. 边的添加 5. 边的删除 6. Dijkstra算法 三、实验内容 实验内容 代码 截图 分析 一、实验目的 1.掌握图的邻接矩阵的存储定义; 2.掌握图的最短路径…...

Spring Boot整合JUnit
引言 测试是软件开发过程中不可或缺的一环,而JUnit作为Java生态中最流行的测试框架之一,与Spring Boot的整合为开发者提供了一套强大的测试工具。本文将讨论Spring Boot整合JUnit的技术细节、最佳实践以及测试驱动开发(TDD)的优雅…...
)
uniapp写小程序实现清除缓存(存储/获取/移除/清空)
在uni-app中,可以使用uni.setStorageSync和uni.getStorageSync来进行数据的存储和获取。而移除缓存数据可以使用uni.removeStorageSync,清空缓存数据可以使用uni.clearStorageSync。 以下是使用示例: 存储数据: uni.setStorage…...

js菜单隐藏显示
1、树状结构对应的表: 2、生成menulist的SQL语句 select {"id":"MenuID","parent":"ParentID","FirstLvMenu":"FirstLvMenu", "text":"MenuName","url":"MenuUrl",&quo…...
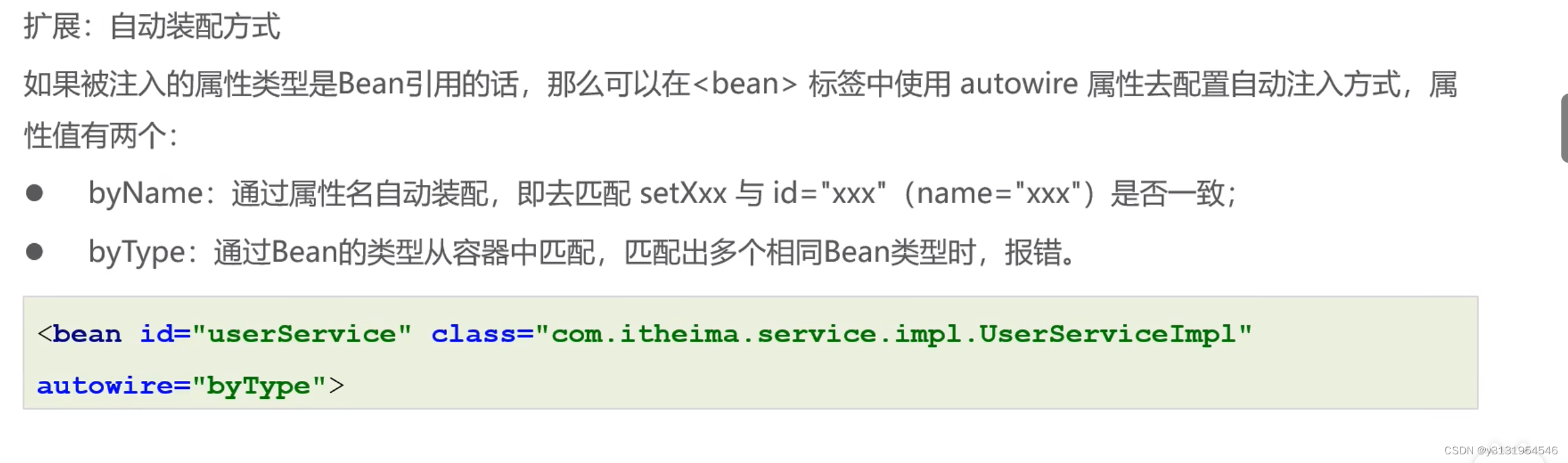
学习Spring的第五天(Bean的依赖注入)
Bean的依赖注入有两种方式: 一 . 常规Bean的依赖注入 很简单,不过多赘述了,注意ref: 是构造函数或set方法的参数,一般为对象, value: 是构造函数或set方法的参数,一般为值. 看下图 1.1 下面来演示一下集合数据类型的关于Bean的依赖注入 1.1.1这是List的注入(演示泛型为Strin…...

GAN在图像数据增强中的应用
在图像数据增强领域,生成对抗网络(GAN)的应用主要集中在通过生成新的图像数据来扩展现有数据集的规模和多样性。这种方法特别适用于训练数据有限的情况,可以通过增加数据的多样性来提高机器学习模型的性能和泛化能力。 以下是GAN在…...

Git推送本地文件到仓库
1. 在 Gitee 上创建一个新的仓库: 登录到 Gitee(https://gitee.com)账号。在 Gitee 主页上选择 "新建仓库" 或类似选项。输入仓库名称和描述,并选择其他相关选项(如公开/私有)。确认创建仓库 …...

Django笔记(一):环境部署
目录 Python虚拟环境 安装virtualenv 创建环境 激活环境 关闭: 安装Django VSCode配置 Python插件 Django插件 解释器选择 Django部署 创建项目 创建app 创建模板 编写视图 编写路由 启动服务器 访问 Python虚拟环境 安装virtualenv pip i…...
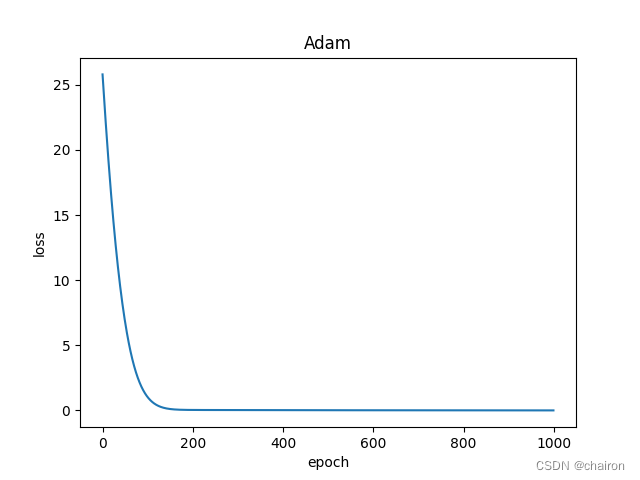
用Pytorch实现线性回归模型
目录 回顾Pytorch实现步骤1. 准备数据2. 设计模型class LinearModel代码 3. 构造损失函数和优化器4. 训练过程5. 输出和测试完整代码 练习 回顾 前面已经学习过线性模型相关的内容,实现线性模型的过程并没有使用到Pytorch。 这节课主要是利用Pytorch实现线性模型。…...

WordPress模板层次与常用模板函数
首页: home.php index.php 文章页: single-{post_type}.php – 如果文章类型是videos(即视频),WordPress就会去查找single-videos.php(WordPress 3.0及以上版本支持) single.php index.php 页面: 自定义模板 – 在WordPre…...
HarmonyOS应用开发者高级认证试题库(鸿蒙)
目录 考试链接: 流程: 选择: 判断 单选 多选 考试链接: 华为开发者学堂华为开发者学堂https://developer.huawei.com/consumer/cn/training/dev-certification/a617e0d3bc144624864a04edb951f6c4 流程: 先进行…...
)
用Matlab的ode45求解器,手把手教你搭建传染病SEID模型(附完整代码)
基于Matlab的SEIR模型构建与传染病动力学仿真实战指南 在当今数据驱动的时代,数学建模已成为研究传染病传播规律不可或缺的工具。本文将带您深入探索如何利用Matlab这一强大的工程计算平台,从零开始构建专业的传染病动力学模型。不同于简单的教程式教学&…...

LabVIEW字符串处理保姆级教程:从长度计算到日期格式化,13个实例带你玩转
LabVIEW字符串处理实战指南:从基础操作到高级应用 在工业自动化、测试测量和仪器控制领域,LabVIEW作为图形化编程的标杆工具,其字符串处理能力直接影响着数据解析、通信协议实现等核心功能。本文将通过13个典型场景,系统讲解如何高…...

帆软FineReport 10升级实战:从路径映射到安全配置的完整指南
1. 从FineReport 9到10的升级背景与准备工作 最近接手了一个企业级报表系统的升级项目,需要将现有的FineReport 9环境迁移到最新的10版本。在实际操作过程中发现,这不仅仅是简单的版本替换,而是涉及到路径映射、参数调整、安全配置等多个关键…...

告别混乱!用这6个SAP屏幕跳转语句,让你的Fiori应用底层逻辑更清晰
告别混乱!用这6个SAP屏幕跳转语句,让你的Fiori应用底层逻辑更清晰 在SAP的演进历程中,从传统的ABAP Dialog编程到现代的Fiori/UI5应用开发,屏幕导航逻辑始终是系统交互设计的核心。对于同时维护传统模块和开发新Fiori界面的开发者…...

PFC2D5.0_从零构建边坡开挖与稳定性分析模型
1. PFC2D5.0边坡建模基础入门 第一次接触PFC2D5.0时,我被它强大的颗粒流分析能力震撼到了。这个软件就像是用数字乐高搭建地质模型,每个颗粒都像真实的砂石一样可以自由运动。记得刚开始做边坡模拟时,我连最简单的矩形试样都建不好࿰…...

STR71X芯片JTAG失效分析与Bootloader恢复指南
1. STR71X设备JTAG接口失效的典型场景分析当使用Keil MDK开发环境和ULINK2调试器连接STR71X系列芯片时,开发者常会遇到"Couldnt stop ARM device"的错误提示。这种情况通常发生在两种典型场景:芯片意外进入了低功耗模式(Power-down…...

手机店还会存在吗
这两年买手机,有个很常见的小场景:人先进店,把样机拿起来拍几张照片,摸一下边框,试试重量,再问店员有没有现货。问完价格以后,很多人会低头打开电商平台。 门店最尴尬的地方就在这里。它承担了体…...

为什么你的Perplexity搜索总返回噪音结果?7步精准提示工程诊断流程
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索结果噪音现象的本质剖析 Perplexity 作为基于大语言模型的语义搜索引擎,其结果页中高频出现的“噪音”并非传统关键词匹配失准所致,而是源于其底层推理机制与用户…...

FPGA超声波测距项目优化:从50MHz到17kHz时钟分频,聊聊资源与精度的权衡
FPGA超声波测距的时钟优化艺术:从50MHz到17kHz的工程哲学 在资源受限的嵌入式系统中,每一个逻辑单元和存储位都显得弥足珍贵。当我们在Cyclone IV这类中低端FPGA上实现超声波测距功能时,时钟管理策略往往成为决定项目成败的关键因素之一。本文…...

如何用Univer在3小时内构建企业级电子表格应用?5个实战技巧分享
如何用Univer在3小时内构建企业级电子表格应用?5个实战技巧分享 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsh…...