pyspark之Structured Streaming file文件案例1
# generate_file.py
# 生成数据 生成500个文件,每个文件1000条数据
# 生成数据格式:eventtime name province action ()时间 用户名 省份 动作)
import os
import time
import shutil
import time
FIRST_NAME = ['Zhao', 'Qian', 'Sun', 'Li', 'Zhou', 'Wu', 'Zheng', 'Wang']
SECOND_NAME = ['San', 'Si', 'Wu', 'Chen', 'Yang', 'Min', 'Jie', 'Qi']
PROVINCE = ['BeiJing', 'ShanDong', 'ShangHai', 'HeNan', 'HaErBin']
ACTION = ['login', 'logout', 'purchase']
PATH = "/opt/software/tmp/"
DATA_PATH = "/opt/software/tmp/data/"
# 初始化环境
def test_Setup():
if os.path.exists(DATA_PATH):
shutil.rmtree(DATA_PATH)
os.mkdir(DATA_PATH)
# 清理数据,恢复测试环境
def test_TearDown():
shutile.rmtree(DATA_PATH)
# 数据保存文件
def writeAndMove(filename,content):
with open(PATH+filename,'wt',encoding='utf-8') as f:
f.write(content)
shutil.move(PATH+filename,DATA_PATH+filename)
if __name__ == '__main__':
test_Setup()
for i in range(500):
filename = "user_action_{}.log".format(i)
"""
验证spark输出模式,complete和update,增加代码,第一个文件i=0时,设置PROVINCE = "TAIWAN"
"""
if i == 0:
province= ['TaiWan']
else:
province = PROVINCE
content = ""
for _ in range(1000):
content += "{} {} {} {}\n".format(str(int(time.time())),random.choice(FIRST_NAME)+random.choice(SECOND_NAME),random.choice(province),random.choice(ACTION))
writeAndMove(filename,content)
time.sleep(10)
# spark_file_test.py
# 读取DATA文件夹下面文件,按照省份统计数据,主要考虑window情况,按照window情况测试,同时针对 outputMode和输出console和mysql进行考虑,其中保存到mysql时添加batch字段
from pyspark.sql import SparkSession,DataFrame
from pyspark.sql.functions import split,lit,from_unixtime
DATA_PATH = "/opt/software/tmp/data/"
if __name__ == '__main__':
spark = SparkSession.builder.getOrCreate()
lines = spark.readStream.format("text").option("seq","\n").load(DATA_PATH)
# 分隔符为空格
userinfo = lines.select(split(lines.value," ").alias("info"))
# 第一个为eventtime 第二个为name 第三个为province 第四个为action
# userinfo['info'][0]等同于userinfo['info'].getIterm(0)
user = userinfo.select(from_unixtime(userinfo['info'][0]).alias('eventtime'),
userinfo['info'][1].alias('name'),userinfo['info'][2].alias('province'),
userinfo['info'][3].alias('action'))
"""
测试1:数据直接输出到控制台,由于没有采用聚合,输出模式选择update
user.writeStream.outputMode("update").format("console").trigger(processingTime="8 seconds").start().awaitTermination()
"""
"""
测试2:数据存储到数据库,新建数据库表,可以通过printSchema()查看数据类型情况
def insert_into_mysql_batch(df:DataFrame,batch):
if df.count()>0:
# 此处将batch添加到df中,采用lit函数
data = df.withColumn("batch",lit(batch))
data.write.format("jdbc"). \
option("driver","com.mysql.jdbc.Driver"). \
option("url","jdbc:mysql://localhost:3306/spark").option("user","root").\
option("password","root").option("dbtable","user_log").\
option("batchsize",1000).mode("append").save()
else:
pass
user.writeStream.outputMode("update").foreachBatch((insert_into_mysql_batch)).trigger(processingTime="20 seconds").start().awaitTermination()
"""
"""
测试3:数据按照省份统计后,输出到控制台,分析complete和update输出模式区别,针对该问题,调整输入,province="TaiWan"只会输入1次,即如果输出方式complete,则每batch都会输出,update的话,只会出现在一个batch
userProvinceCounts = user.groupBy("province").count()
userProvinceCounts = userProvinceCounts.select(userProvinceCounts['province'],userProvinceCounts["count"].alias('sl'))
# 测试输出模式complete:complete将总计算结果都进行输出
"""
batch 0
TaiWan 1000
batch 1
TaiWan 1000
其他省份 sl
batch 2
TaiWan 1000
其他省份 sl
""" userProvinceCounts.writeStream.outputMode("complete").format("console").trigger(processingTime="20 seconds").start().awaitTermination()
# 测试输出模式update:update只输出相比上个批次变动的内容(新增或修改)
batch 0
TaiWan 1000
batch 1 中没有TaiWan输出
userProvinceCounts.writeStream.outputMode("complete").format("console").trigger(processingTime="20 seconds").start().awaitTermination()
"""
相关文章:

pyspark之Structured Streaming file文件案例1
# generate_file.py # 生成数据 生成500个文件,每个文件1000条数据 # 生成数据格式:eventtime name province action ()时间 用户名 省份 动作) import os import time import shutil import time FIRST_NAME [Zhao, Qian, Sun, Li, Zhou, Wu, Zheng, Wang] SEC…...
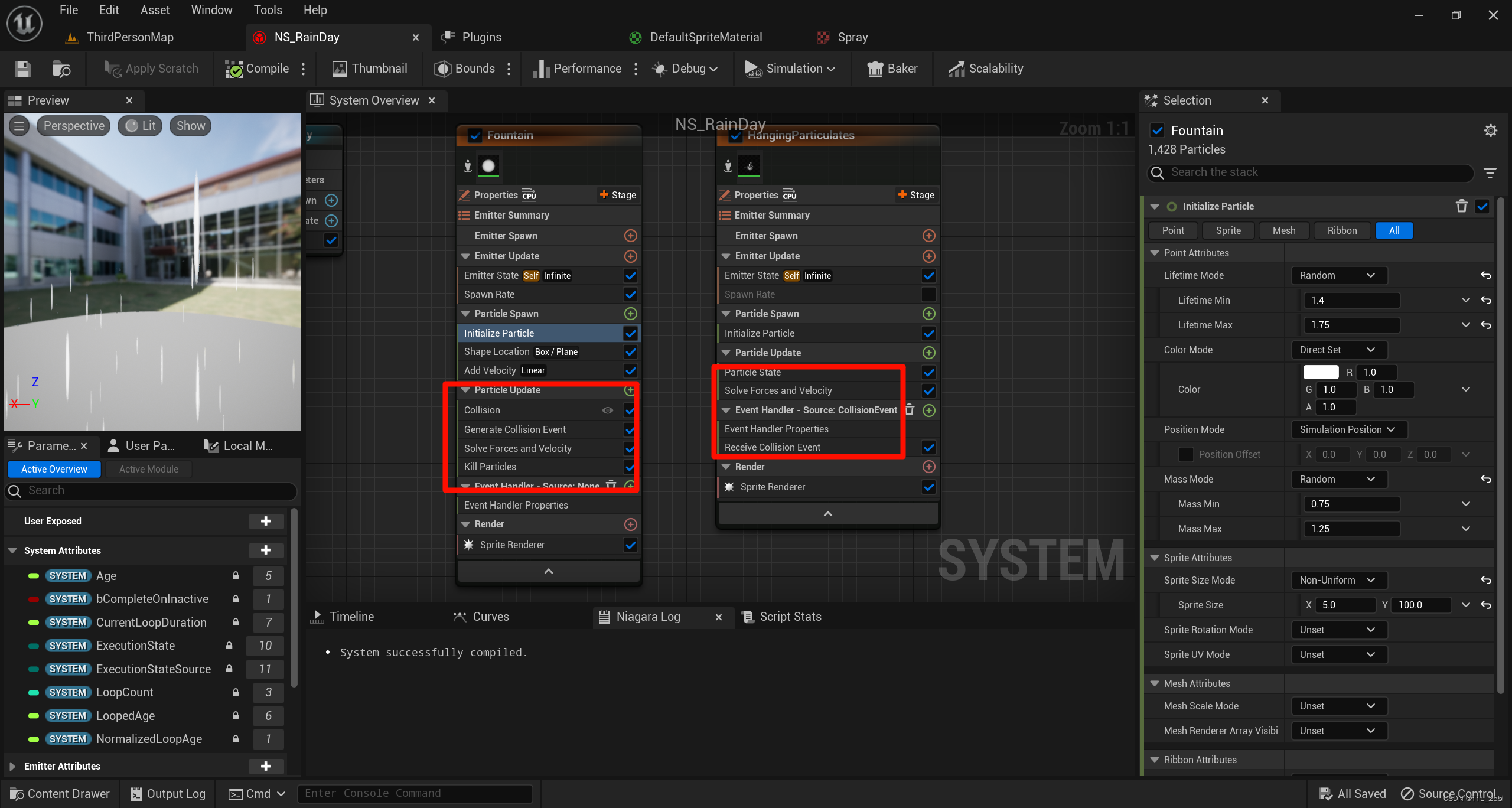
虚幻UE 特效-Niagara特效实战-雨天
回顾Niagara特效基础知识:虚幻UE 特效-Niagara特效初识 其他两篇实战:虚幻UE 特效-Niagara特效实战-火焰、烛火、虚幻UE 特效-Niagara特效实战-烟雾、喷泉 本篇笔记我们再来实战雨天,雨天主要用到了特效中的事件。 文章目录 一、雨天1、创建雨…...

k8s 集群搭建的一些坑
k8s集群部署的时候会遇到很多的坑,即使看网上的文档也可能遇到各种的坑。 安装准备 1、虚拟机两台(ip按自己的网络环境相应配置)(master/node) 192.168.100.215 k8s-master 192.168.100.216 k8s-node1 2、关闭防火墙(master/node) system…...

SpringMVC传递数据给前台
SpringMVC有三种方式将数据提供给前台 第一种 使用Request域 第二种 使用Model(数据默认是存放在Request域中) 与第一种方式其实是一致的 第三种 使用Map集合(数据默认是存放在Request域中)...
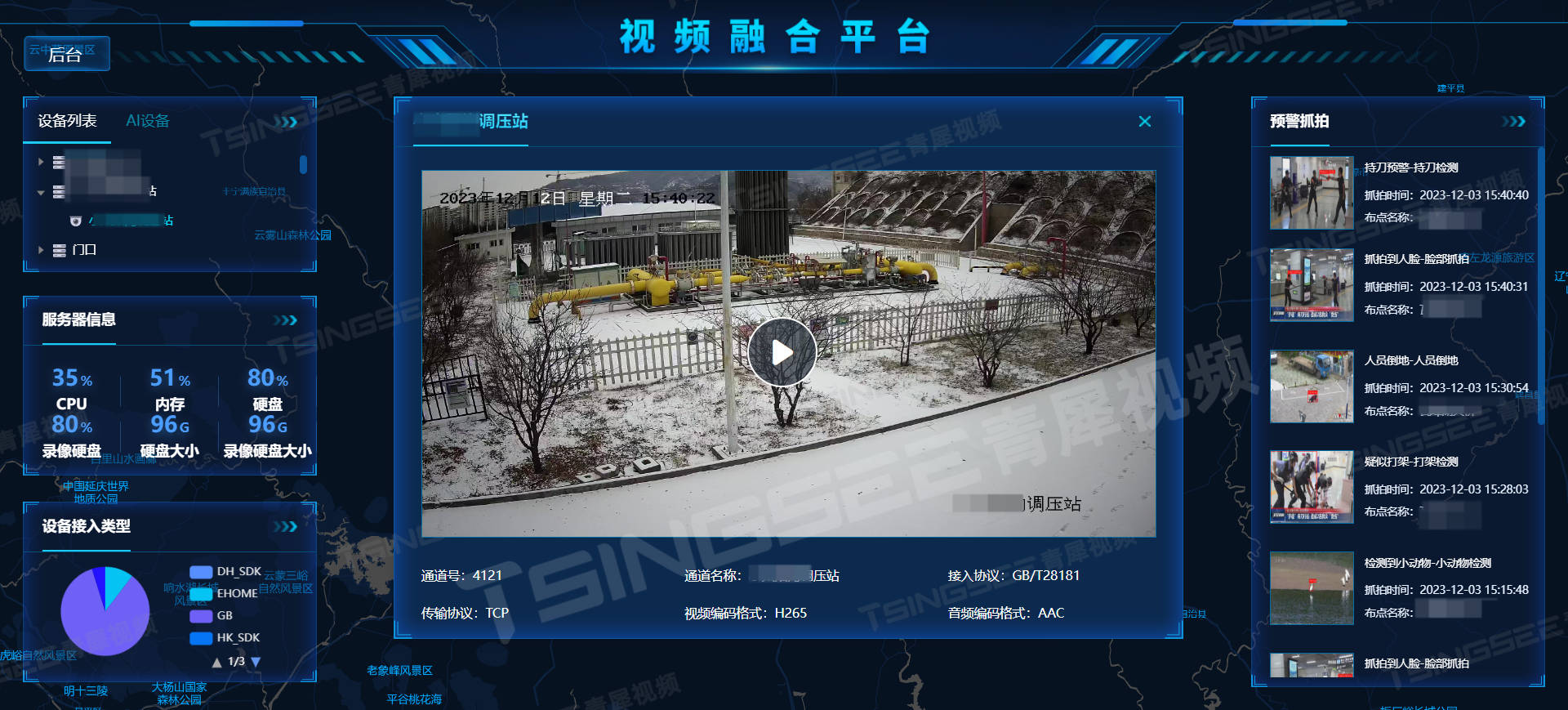
国标GB28181安防视频监控EasyCVR级联后上级平台视频加载慢的原因排查
国标GB28181协议安防视频监控系统EasyCVR视频综合管理平台,采用了开放式的网络结构,可以提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、云存储等丰富的视频能力,同时还…...

React16源码: React中的HostComponent HostText的源码实现
HostComponent & HostText 1 )概述 HostComponent 就是我们dom原生的这些节点, 如: div, span, p 标签这种 使用的是小写字母开头的这些节点一般都认为它是一个 HostComponent HostText,它是单纯的文本节点主要关注它们的一个更新过程 2 …...
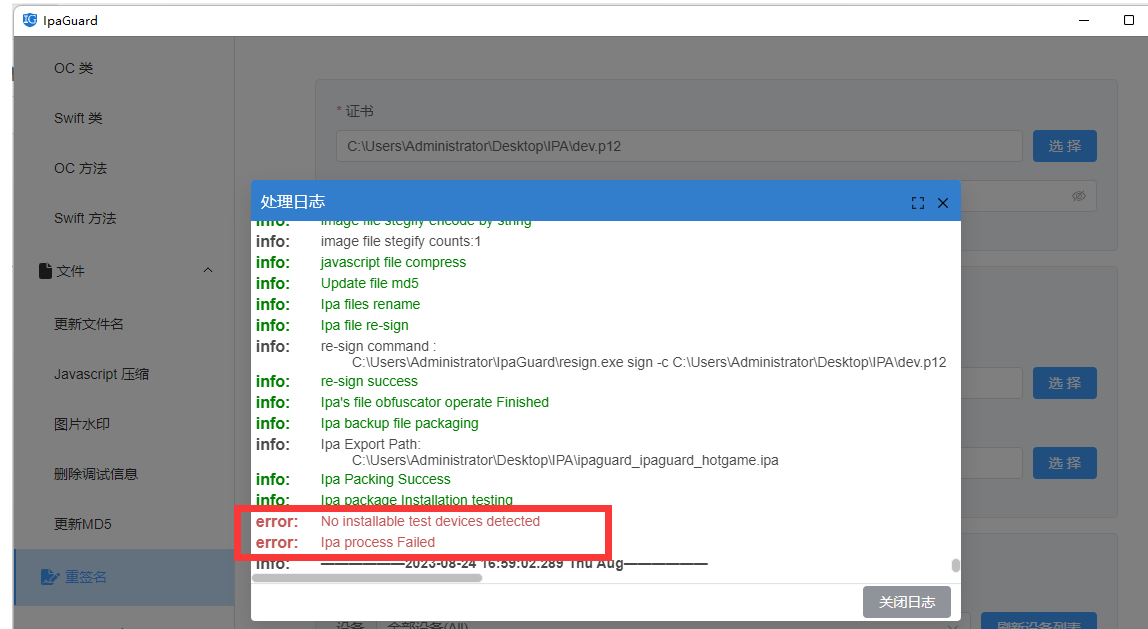
Unity3D代码混淆方案详解
背景 Unity引擎使用Mono运行时,而C#语言易受反编译影响,存在代码泄露风险。本文通过《QQ乐团》项目实践,提出一种适用于Unity引擎的代码混淆方案,以保护代码逻辑。 引言 在Unity引擎下,为了防止代码被轻易反编译&a…...
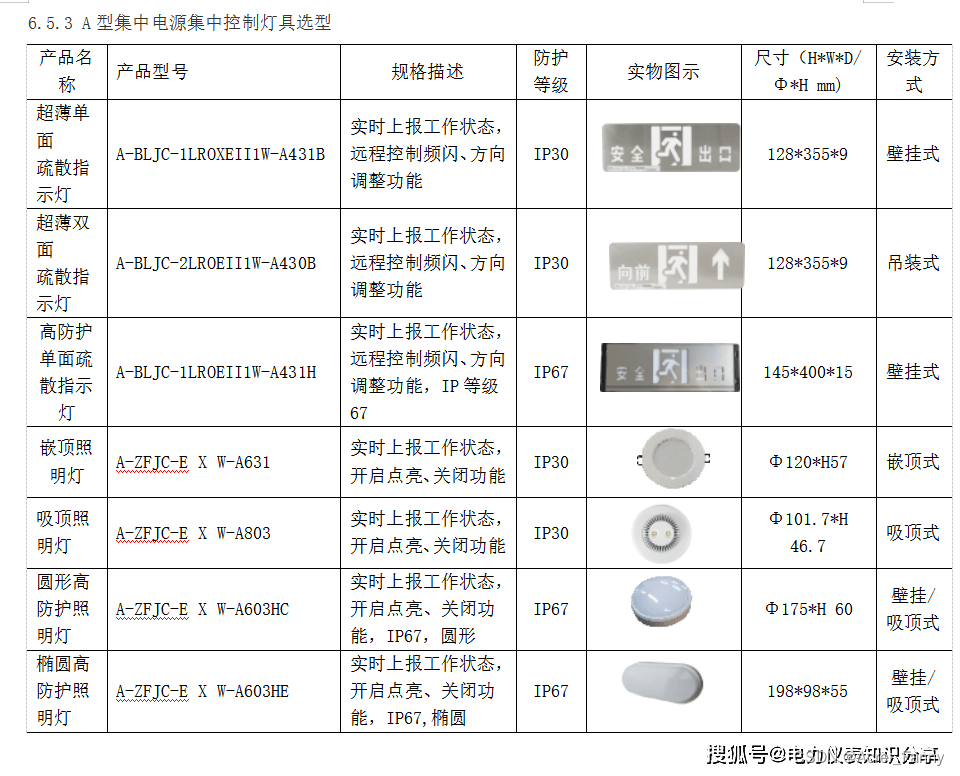
安科瑞应急疏散照明系统在歌舞娱乐等场所的应用
首先必须明确疏散照明并不包含疏散指示标志,疏散照明是为了提供人员疏散时的必要照明,必须达到规定照度,以便逃生时看清逃生的路径,避免出现恐慌及踩踏事故,而疏散指示标志则是提供疏散路径方向引导的,所以…...

Go语言协程使用
主协程执行打印,子协程不打印 package main import ("fmt" )func do(i int) {fmt.Println("执行中") } func main() {fmt.Println("main协程")go do(1)fmt.Println("执行完了") }//main协程 //执行完了子协程没有打印输出…...

JAVA如何创建对象
在 Java 中创建对象的步骤如下: 定义一个类:在 Java 中,所有的对象都是通过类来创建的。因此,首先需要定义一个类,即描述对象的属性和行为。 声明变量:要创建一个对象,需要先声明一个变量来保存…...

《WebKit 技术内幕》之五(2): HTML解释器和DOM 模型
2.HTML 解释器 2.1 解释过程 HTML 解释器的工作就是将网络或者本地磁盘获取的 HTML 网页和资源从字节流解释成 DOM 树结构。 这一过程中,WebKit 内部对网页内容在各个阶段的结构表示。 WebKit 中这一过程如下:首先是字节流,经过解码之…...

Spring Boot多环境配置
Spring Boot的针对不同的环境创建不同的配置文件, 语法结构:application-{profile}.properties profile:代表的就是一套环境 需求 application-dev.yml 开发环境 端口8090 application-test.yml 测试环境 端口8091 application-prod.yml 生产环境 端口80…...

常用的目标跟踪有哪些
目标跟踪是计算机视觉领域的一个重要研究方向,主要用于实现视频监控、人机交互、智能交通等领域。下面介绍几种常用的目标跟踪方法: 特征匹配法 特征匹配法是目标跟踪中最基本的方法之一,其基本原理是通过提取目标的特征,然后在…...
python222网站实战(SpringBoot+SpringSecurity+MybatisPlus+thymeleaf+layui)-帖子详情页实现
锋哥原创的SpringbootLayui python222网站实战: python222网站实战课程视频教程(SpringBootPython爬虫实战) ( 火爆连载更新中... )_哔哩哔哩_bilibilipython222网站实战课程视频教程(SpringBootPython爬虫实战) ( 火…...
11、Kafka ------ Kafka 核心API 及 生产者API 讲解
目录 Kafka核心API 及 生产者API讲解★ Kafka的核心APIKafka包含如下5类核心API: ★ 生产者APIKafka 的API 文档 ★ 使用生产者API发送消息 Kafka核心API 及 生产者API讲解 官方文档 ★ Kafka的核心API Kafka包含如下5类核心API: Producer API&#x…...

MySQL 8.3 发布, 它带来哪些新变化?
1月16号 MySQL 官方发布 8.3 创新版 和 8.0.36 长期支持版本 (该版本 没有新增功能,更多是修复bug ),本文基于 官方文档 说一下 8.3 版本带来的变化。 一 增加的特性 1.1 GTID_NEXT 支持增加 TAG 选项。 之前的版本中 GTID_NEXTUUID:number ÿ…...

【数据结构】详谈队列的顺序存储及C语言实现
循环队列及其基本操作的C语言实现 前言一、队列的顺序存储1.1 队尾指针与队头指针1.2 基本操作实现的底层逻辑1.2.1 队列的创建与销毁1.2.2 队列的增加与删除1.2.3 队列的判空与判满1.2.4 逻辑的局限性 二、循环队列2.1 循环队列的实现逻辑一2.2 循环队列的实现逻辑二2.3 循环队…...
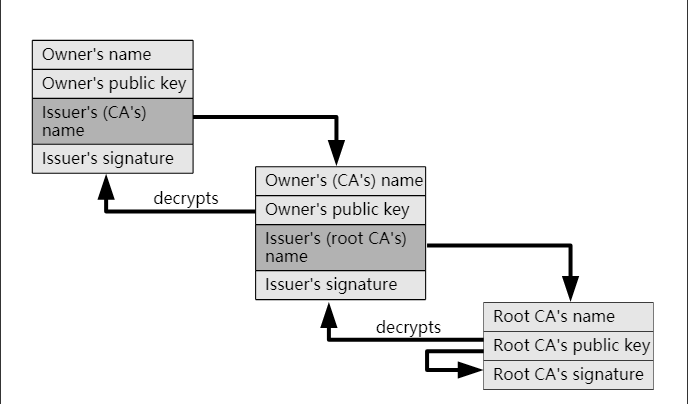
为什么 HTTPS 协议能保障数据传输的安全性?
HTTP 协议 在谈论 HTTPS 协议之前,先来回顾一下 HTTP 协议的概念。 HTTP 协议介绍 HTTP 协议是一种基于文本的传输协议,它位于 OSI 网络模型中的应用层。 HTTP 协议是通过客户端和服务器的请求应答来进行通讯,目前协议由之前的 RFC 2616 拆…...
使用 Node 创建 Web 服务器
Node.js 提供了 http 模块,http 模块主要用于搭建 HTTP 服务端和客户端,使用 HTTP 服务器或客户端功能必须调用 http 模块,代码如下: var http require(http); 以下是演示一个最基本的 HTTP 服务器架构(使用 8080 端口)&#x…...

leetcode 151反转字符串如何原地去除多余空格
题目:https://leetcode.cn/problems/reverse-words-in-a-string/description/ 完整题解:https://leetcode.cn/problems/reverse-words-in-a-string/solutions/2611893/chu-li-kong-ge-ku-han-shu-reversefan-zhu-bioo 思路来自代码随想录,对其中的除去多…...

大疆L1点云与ContextCapture融合实战:从Sbet轨迹到三维实景模型的完整数据流
1. 大疆L1点云与ContextCapture融合的核心价值 如果你手头有大疆L1激光雷达采集的点云数据,想要在ContextCapture(现在叫iTwin Capture)里生成高精度三维模型,但卡在了轨迹文件转换这一步,那这篇文章就是为你准备的。…...

告别Minecraft模组英文界面:MASA全家桶汉化包完全指南
告别Minecraft模组英文界面:MASA全家桶汉化包完全指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 你是否曾经在Minecraft中面对满屏的英文模组界面感到困惑?…...

CANN/asc-devkit SoftMax接口
SoftMax 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

Zynq UltraScale+ MPSoC SoM选型与开发实战:从异构计算到嵌入式系统设计
1. 项目概述:为什么选择Zynq UltraScale MPSoC SoM? 在嵌入式系统开发,尤其是需要高性能计算、实时处理与灵活硬件加速的领域,选型往往是决定项目成败的第一步。过去几年,我经手过不少项目,从简单的微控制器…...

掌握FreeRDP的5个核心场景:从基础连接到企业级部署实战指南
掌握FreeRDP的5个核心场景:从基础连接到企业级部署实战指南 【免费下载链接】FreeRDP FreeRDP is a free remote desktop protocol library and clients 项目地址: https://gitcode.com/gh_mirrors/fr/FreeRDP 作为开源远程桌面协议的标杆实现,Fr…...

基于8ms平台的嵌入式GUI开发实践:智能家居86盒UI设计与实现
1. 项目概述:当智能家居遇上8ms,一个86盒的UI革命 最近在折腾一个智能家居的改造项目,核心是想把家里那些老旧的开关面板,换成能联网、能自定义、还能显示点信息的“智能大脑”。市面上现成的智能开关要么功能固化,要么…...

第八章:AI产品的技术尽调——如何评估AI供应商
本章难度:★★★★☆ | 预计阅读时间:10分钟 你将学到:AI供应商评估的八大维度、安全认证与AI特有风险、2026年合规框架(EU AI Act/ISO 42001/GDPR)、数据隐私条款、模型能力评估方法、以及PM可操作的技术尽调清单 引言:为什么AI供应商需要"特殊体检" 老板说:…...

如何在macOS上轻松运行Windows应用:Whisky终极指南
如何在macOS上轻松运行Windows应用:Whisky终极指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在苹果电脑上使用Windows专属的软件和游戏吗?厌倦了虚拟…...

5分钟快速上手WuWa-Mod:解锁《鸣潮》游戏无限潜能的终极指南
5分钟快速上手WuWa-Mod:解锁《鸣潮》游戏无限潜能的终极指南 【免费下载链接】wuwa-mod Wuthering Waves pak mods 项目地址: https://gitcode.com/GitHub_Trending/wu/wuwa-mod 还在为《鸣潮》游戏中的技能冷却时间烦恼吗?想要体验无限体力、自动…...

5种文本切块策略大解析:从字符到语义,打造高效检索系统!
文本切块是构建向量索引前的重要环节,避免语义切断和检索效果冲淡。文章详细解析了五种常见切块策略:按字符长度切分、按Token长度切分、按句子语义切分、按段落结构切分(含默认语法和自定义语法)以及混合方式切分。每种策略都有其…...