linux内核原理--分页,页表,内核线性地址空间,伙伴系统,内核不连续页框分配,内核态小块内存分配器
1.分页,页表
linux启动阶段,最初运行于实模式,此阶段利用段寄存器,段内偏移,计算得到物理地址直接访问物理内存。
内核启动后期会切换到保护模式,此阶段会开启分页机制。一旦开启分页机制后,内核采用的是线性地址,线性地址通过页表转换得到物理地址,再通过物理地址访问物理内存。
采用分页机制的意义在于,可以为每个进程提供一个独立的页表,这样每个进程将拥有一个独立的线性地址区域。通过页表,在两个进程里使用同一个线性地址,由于页表的作用,可能分别映射到两个不同的物理地址。这样,可使得每个进程可独立管理其线性地址空间的使用,彼此不干扰。分页的另一个好处是,通过页表我们可以将一片连续的线性地址区域映射到若干个不连续的物理地址区域。
值得注意的是,每个进程的线性地址空间会划分成用户态线性地址空间,内核态线性地址空间。
用户态线性地址空间可供用户态进程自主管理和使用。
内核态线性地址空间在该进程需要切换到内核态(遭遇中断,系统调用,异常)时使用。值得注意的是,对内核态线性地址空间对系统所有进程是共享的。共享的意思是,对系统任一一个进程,给定一个属于内核态空间的线性地址,该线性地址均对应到同一个物理地址。
2.内核态线性地址空间划分
我们分别讨论经典32位内核,64位内核下内核态线性地址空间划分。
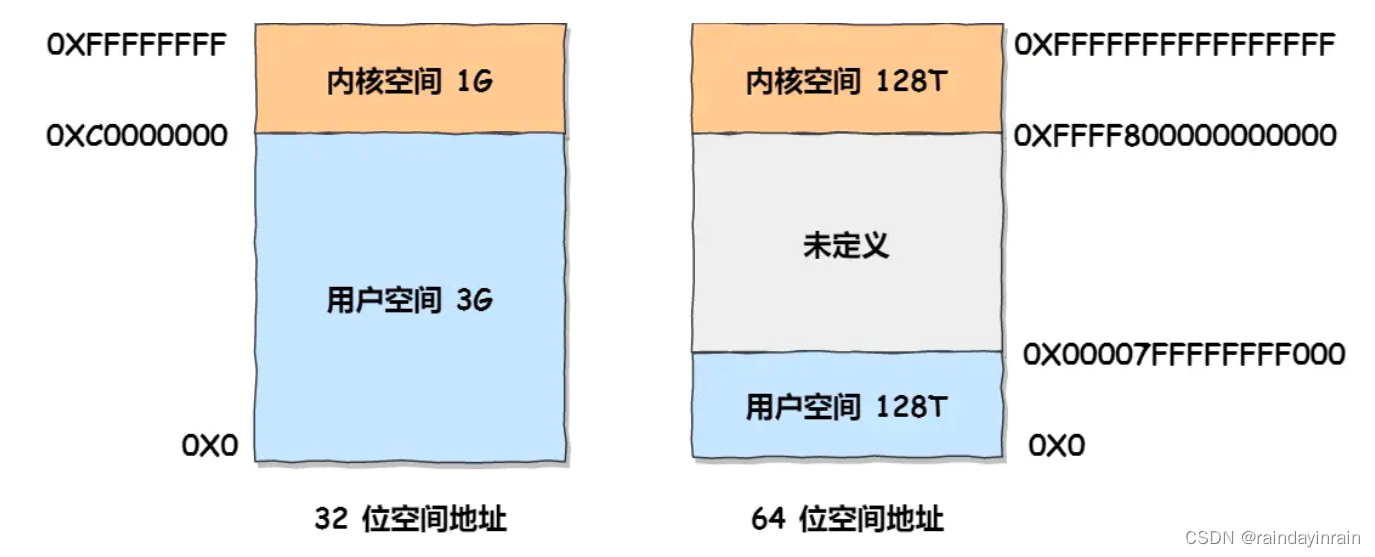
上图是线性地址空间的整体视图,无论在32位还是64位系统下,线性地址空间均划分为用户态,内核态两个部分。
2.1.32位内核下内核态线性地址空间划分
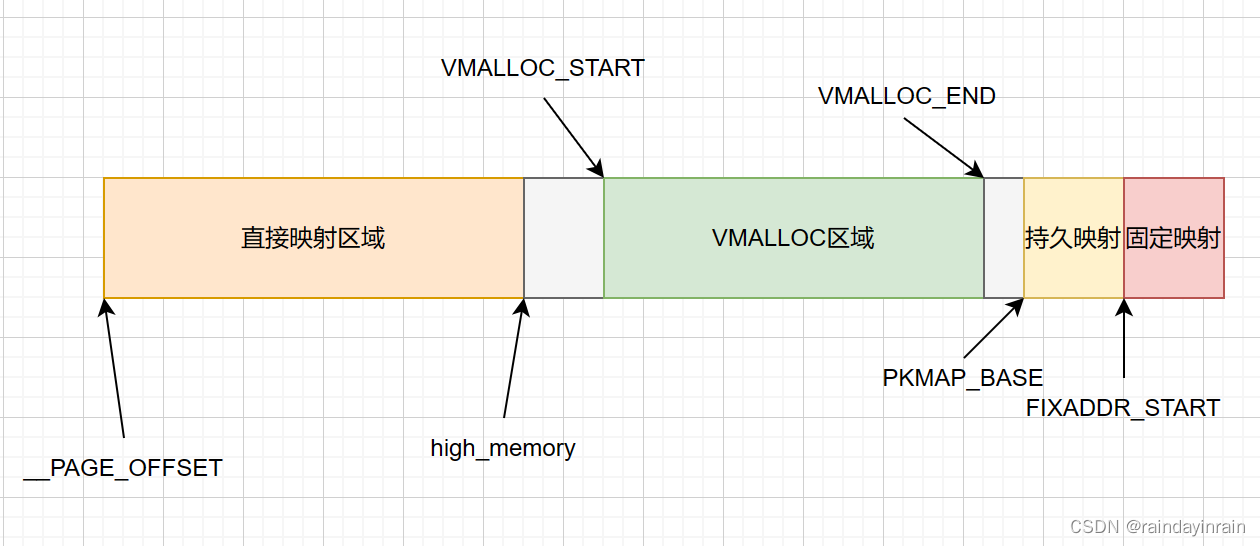
值得注意的是,32位下,直接映射区域尺寸一般是896MB。
2.2.64位内核下内核态线性地址空间划分
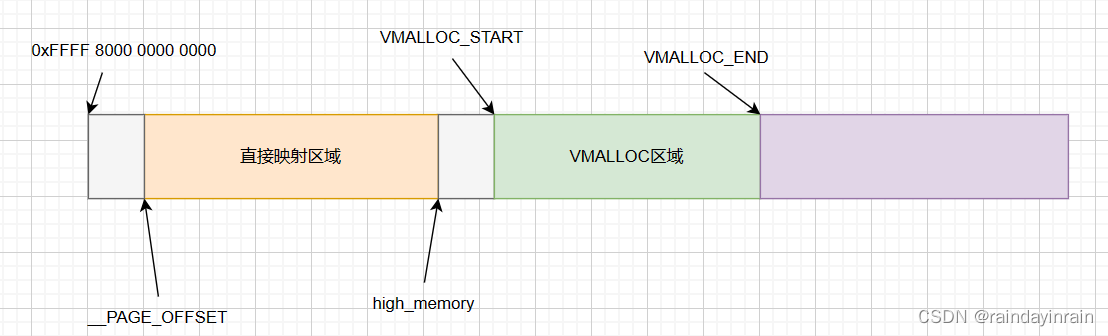
值得注意的是,64位下,直接映射区域一般尺寸可达64T,没有持久映射,固定映射。
2.3.针对直接映射区域的处理
(1). 在系统启动阶段对直接映射区域内所有线性地址会设置好页表。
(2). 直接映射区域会映射到物理地址空间起始部分。
上述处理的意义在于,对于直接映射区域内的线性地址,其线性地址和物理地址的关系是固定的。
假设此区域内某个线性地址vaddr。其物理地址固定为:vaddr - __PAGE_OFFSET。
由于启动阶段已经为此区域的所有线性地址设置好了页表,所以后续通过伙伴系统分配得到此区域的页框后,无需执行页表注册。即可得到对应的线性地址,使用线性地址访问内存。
2.4.针对持久映射区域的处理
(1). 在系统启动阶段对持久映射区域会在多级页表中分别设置好线性地址对应的顶级页表项,上级页表项,中间页表项。这样,后续使用分配页框,并为其映射到持久映射区域时,只需单独准备页表,并设置页表项即可完成页表映射。
内核通过设置一个哈希表,保存映射到此区域的每个page对象及其线性地址。
对某个页框建立持久映射过程可能会阻塞。阻塞一般发生在持久映射区域暂时无空闲区域可供使用时。
2.5.针对固定映射区域的处理
(1).在系统启动阶段对持久映射区域会在多级页表中分别设置好线性地址对应的顶级页表项,上级页表项,中间页表项。这样,后续使用分配页框,并为其映射到持久映射区域时,只需单独准备页表,并设置页表项即可完成页表映射。

此区域为每个cpu准备了一个窗口,一个窗口可包含固定数量的页。这样每个cpu需要对页框执行固定映射时,总是可以在自身窗口内寻找一个区域建立映射。
固定映射的分配保证是不阻塞的,分配时不会检测指定的线性区域是否已被使用。
一般只用于临时性为页框建立映射,如中断处理中,使用后,立即撤销映射的场景。
3.利用伙伴系统分配页框,释放页框
3.1.大的背景
从大的层次,可以将内核所管理的内存区域抽象为节点,每个节点下的内存区域又可被划分为不同类型的区域。
现代NUMA系统,通过多节点,每个节点内封装指定数量的内存,处理器来提高并行能力。不支持NUMA的系统,视为拥有一个节点即可。
每个节点下的内存区域划分为不同类型,是因为由于历史原因,某些硬件使用DMA技术只能使用物理地址范围前16M的物理内存。32位系统下,直接映射区域和非直接映射区域由于处理方式不同,也需分为不同类型。这样,典型的32位系统,区域一般由DMA,NORMAL,HIGH三种类型。
我们利用伙伴系统进程页框分配时,首先的指定要在那个节点的那个区域进行分配。
这样,伙伴系统先在此节点此区域下进行分配处理。若无法完成分配,通过设置我们也可继续在备选区域尝试分配。直到分配成功,或最终失败。
3.2.伙伴系统的结构
struct free_area {struct list_head free_list;unsigned long nr_free;
};struct zone {unsigned long free_pages;spinlock_t lock;struct free_area free_area[MAX_ORDER];struct pglist_data *zone_pgdat;struct page *zone_mem_map;unsigned long zone_start_pfn;unsigned long spanned_pages; /* total size, including holes */unsigned long present_pages; /* amount of memory (excluding holes) */char *name;
} ____cacheline_maxaligned_in_smp;struct page {page_flags_t flags; /* Atomic flags, some possibly updated asynchronously */atomic_t _count; /* Usage count, see below. */unsigned long private; /* Mapping-private opaque data:* usually used for buffer_heads if PagePrivate set;* used for swp_entry_t if PageSwapCache* When page is free, this indicates order in the buddy system. */struct list_head lru; /* Pageout list, eg. active_list protected by zone->lru_lock! */
#if defined(WANT_PAGE_VIRTUAL)void *virtual; /* Kernel virtual address (NULL if not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
};
伙伴系统分配页框是在指定类型区域里分配。页框是此区域内的页框。
为了保证频繁的页框分配和释放后,依然有较大的连续物理区域可用,伙伴系统对区域内空间的页框按阶管理。
3.3.伙伴系统页框分配示例
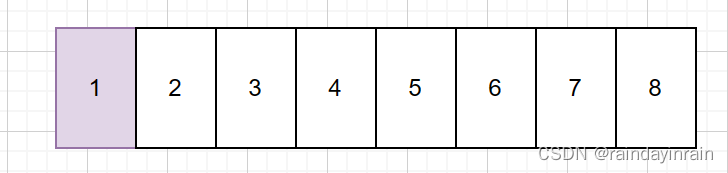
假设我们在一个拥有8个空闲页框的区域使用伙伴系统。
假设伙伴系统使用MAX_ORDER=4,进行页框管理。
假设区域内首个页框的物理地址换算得到的页框编号可被8整除。
假设初始时刻,zone对象的free_area[0],free_area[1],free_area[2]代表的链表均为空。free_area[3]代表的链表有一个元素,此元素指向代表1页框的page对象。
对1页框的page对象,在伙伴系统管理下,其flags将包含SLAB标记,其_count将为-1,因为此page是free_area链表中的元素,所以其flags还将包含PRIVATE标记,其private将为所在链表的阶,这里是3。
其余各个页框对应的page对象,虽在伙伴系统管理下,但不是free_area链表的元素,所以,其flags将包含SLAB标记,其_count将为-1。
3.3.1.向伙伴系统申请2个空闲页框
向伙伴系统申请页框时,只能申请 2 o r d e r 2^{order} 2order个页框。对2个页框order为1。
伙伴系统的处理策略是,对free_area数组,从order开始,依次判断数组元素代表的链表是否存在空闲元素。
若存在,假设对应元素的索引为cur_order。
我们要做的是:
(1). 从链表移除首元素。此元素是一个page指针,这个指针会作为结果返回。表示从此page开始连续 2 o r d e r 2^{order} 2order个page均已经被分配。
(2). 若cur_order>order,意味着此page代表了一个连续尺寸为 2 c u r o r d e r 2^cur_order 2curorder的空闲物理区域。对多余部分,我们将按对半切分策略依次将多余部分加入free_area对应阶数的链表。并相应更新各个字段。
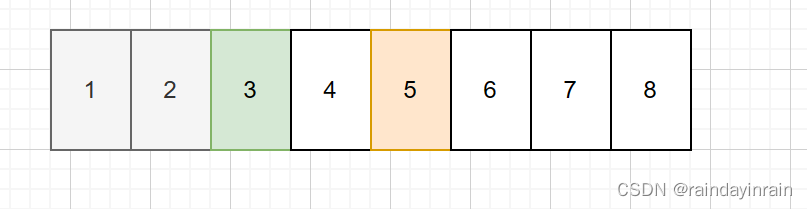
这样处理后,free_area[3]对应的链表为空。free_area[2]对应的链表包含一个元素,即页框5对应的page。free_area[1]对应的链表包含一个元素,即页框3对应的page。
对页框1由于其不再是对应阶的列表元素了,其page的flags将不再包含PRIVATE标记,其private被设置为0。
对页框1,页框2,从伙伴系统返回给外部时,会设置每个page的private为0,_count为0。
对页框3由于其加入了free_area[1]所在链表,所以,所以其flags还将包含PRIVATE标记,其private将为所在链表的阶,这里是1。
对页框5由于其加入了free_area[2]所在链表,所以,所以其flags还将包含PRIVATE标记,其private将为所在链表的阶,这里是2。
伙伴系统对free_area[n]链表内每个元素的要求是此page在区域内索引可被 2 o r d e r 2^order 2order整除。
page在区域内索引=page-区域内首个page。(指针相减得到的是指针间距离)
3.3.2.向伙伴系统释放2个页框
释放页框时,需要提供起始页框的page指针,order。order表示从page开始连续 2 o r d e r 2^order 2order个页框需要释放。
释放过程先递减起始页框page的_count,当其_count递减后变为-1时,实际执行释放流程。
阶为order的连续页框释放需要经过一个与伙伴合并构成更大阶的过程。
直到无法找到伙伴时,才结束。
该过程会将被合并的伙伴从其原来所在阶的链表中移除,并最终在合并后阶的链表里加入合并后阶的首个page。
对由于合并而不再位于链表的page会令其flags将不再包含PRIVATE标记,其private被设置为0。
对最终合并阶的首个page,会令其flags包含PRIVATE标记,其private被设置为最终的阶。
合并的依据是,对于阶为order的链表里每个page,要求此page-区域起始page后得到的索引可被 2 o r d e r 2^order 2order整除。
关键是对阶为order的page确定其伙伴的位置。
上述是确定阶为order的page_idx的伙伴的方法。
上述方法的正确性:
(1). 首先我们知道由于一致性要求page_idx必然可被 2 o r d e r 2^order 2order整除。
(2). 再次我们对page_idx它的伙伴有两个。一个是起始page的区域内索引位page_idx+$2^order$,阶为order的page代表的区域。一个是起始page的区域内索引为page_idx-$2^order$,阶为order的page代表的一个区域。
(3). 但我们选取伙伴的目的是为了合并,且对于合并后区域的起始page要求该page的区域内索引需能被 2 o r d e r + 1 2^{order+1} 2order+1整除。
(4). 由于(3)的限制,我们只能选择
buddy_idx = (page_idx ^ (1 << order));
作为合并的伙伴。
若选取的伙伴符合要求,即对应的page位于伙伴系统阶为order的链表。(通过page的PRIVATE标志与private可判断)
则我们需与此伙伴合并得到阶为order+1的新的连续空闲区域。新区域首个page的区域内索引为:
page_idx &= buddy_idx;
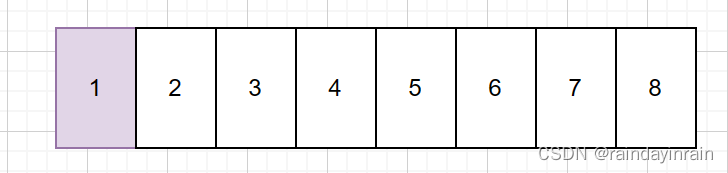
释放页框经过合并处理后,free_area[1],free_area[2]链表将为空。 free_area[3]将包含单个元素,为页框1的page。
3.4.提升伙伴系统性能
linux在伙伴系统使用者和伙伴系统之间额外引入一个中间层。
struct page {struct list_head lru; /* Pageout list, eg. active_list protected by zone->lru_lock! */
};struct per_cpu_pages {int count; /* number of pages in the list */int low; /* low watermark, refill needed */int high; /* high watermark, emptying needed */int batch; /* chunk size for buddy add/remove */struct list_head list; /* the list of pages */
};struct per_cpu_pageset {struct per_cpu_pages pcp[2]; /* 0: hot. 1: cold */
} ____cacheline_aligned_in_smp;struct zone {struct per_cpu_pageset pageset[NR_CPUS];char *name;
} ____cacheline_maxaligned_in_smp;
每次向伙伴系统申请阶为0的空闲页框时,先向中间层申请。中间层无法完成申请时,再向伙伴系统申请。
区域对象为每个cpu准备了一个per_cpu_pageset对象,此对象针对每个cpu支持两类列表,一类列表存储热页集合,一类列表存储冷页集合。page对象的lru可用于构建链表。
3.4.1.申请单独页框的逻辑
依据当前cpu,及申请标志,取得区域相应per_cpu_pageset 的相应per_cpu_pages 对象。
若链表现有元素不足low时,一次向伙伴系统申请batch个单独页框来补充。
若链表存在可用元素,取首个元素。将其移除链表。对应的page作为结果返回。
对返回的page,其_count将为0,其private被设置为0。
3.4.2.释放单独页框的逻辑
页框的page,结合其flags字段可以得到此页所属区域对象的指针。
释放的页框需要满足page的_count为-1。
依据当前cpu,及申请标志,取得区域相应per_cpu_pageset 的相应per_cpu_pages 对象。
若链表现有元素已经达到high,一次向伙伴系统释放batch个单独页框。
将释放的page加入到per_cpu_pages的链表结构即可完成释放。
3.5.页框管理过程一些一致性要求
a. 位于伙伴系统,冷热列表的页框的page的_count均为-1。
b. 页框被分配出去初始时刻,各个页框的page的_count均为0。
c. 位于伙伴系统各个阶的列表的page其flags中需要包含PRIVATE,其private需要设置为所在的阶。
d. 位于伙伴系统各个阶的列表的page其在区域内索引需要可被 2 o r d e r 2^order 2order整除。
e. 伙伴系统内不在各个阶的列表的page及冷热,热页列表的page,其flags不应包含PRIVATE,其private应该为0。
3.6.伙伴系统存在必要性
伙伴系统用于实现内核页框分配器。
内核线性区域的绝大部分都是直接映射的,这意味着,分配连续的线性区域要求对应的物理区域也得是连续的。
伙伴系统实现的页框分配可以有效保证始终存在较大的连续物理区域可供分配。
4.利用VMALLOC区域实现vmalloc,vfree
4.1.背景
内核线性区域的绝大部分是直接映射的,但直接映射下,要求连续的线性地址必须映射到连续的物理地址,且直接映射的物理区域是固定的物理区域起始部分。
为了解除上述两个限制,我们需要vmalloc区域。vmalloc区域的每个线性页可通过页表映射到任意的物理页。这样一方面解除了连续的线性区域需要连续的物理区域的限制,另一方面也解除了物理区域必须是物理区域起始部分的限制。
4.2.结构
struct vm_struct {void *addr;// 起始线性地址unsigned long size;// 区域尺寸unsigned long flags;// 标志。VM_ALLOC,VM_MAP,VM_IOREMAPstruct page **pages;// 页面集合unsigned int nr_pages;// 数量unsigned long phys_addr;// ioremap时需要struct vm_struct *next;
};
我们只考虑VM_ALLOC下的使用。
4.3.vmalloc
利用vmalloc从vmalloc区域的指定区间申请一个尺寸为size的可用区域并完成页表注册的步骤如下:
(1). 首先vmalloc分配尺寸以页框为单位,所以对size会按页框取整。
(2). 由于内核会将VMALLOC区域所有已经分配出去的区域加入一个单向链表结构。对链表内每个区域,内核保证,区域之间无重叠部分。区域按起始地址递增有序组织。所以,我们很容易可以利用此链表寻找在我们要求的区间内是否存在一个可满足要求尺寸的空间区域。
(3).若区域存在,我们利用内核小块内存分配器为管理此区域的vm_struct 结构分配空间。
a. 进一步,我们为此vm_struct结构内的pages数组分配空间。
b. 进一步,通过伙伴系统完成指定数量页框的分配。
c. 进一步,对vm_struct各个字段进行初始化设置。
d. 进一步,将vm_struct结构加入内核单向链表合适位置。
e. 进一步,执行页表注册,以便建立线性地址和物理地址间的映射关系。页表更新后需相应的刷新TLB。
f. 用分配区域的起始线性地址作为结果返回。
(4). 若区域不存在,则无法完成分配。
4.4.vfree
利用vfree,向vmalloc区域释放起始线性地址为addr的一片已经分配区域。
(1). 首先,内核从单向链表结构寻找匹配的区域对象。
(2). 找到时,执行释放流程
a. 从单向链表移除指定vm_struct实例。
b. 对释放区域执行页表映射取消。页表更新后需相应的刷新TLB。
c. 向伙伴系统释放pages数组中的每个页框。
d. 释放vm_struct实例的pages数组的空间。
e. 释放vm_struct实例的空间。
(3). 找不到时,无需释放。
5.内核中的小块内存分配器
5.1.背景
无论是伙伴系统,还是vmalloc,vfree,这些内核中的空间分配器执行空间分配和释放时,对尺寸的要求均是页框的倍数。但实际上,绝大部分空间分配场景要求的尺寸都小于一个页框。为了避免空间的浪费,我们需要实现小块内存分配器来满足小块空间的分配需求。
5.2.结构
5.2.1.分配器结构
struct kmem_list3 {// 将服务于分配器的slab对象分成三类,分别放置到三个链表struct list_head slabs_partial; // 此链表中slab内的对象部分已经分配,部分可供继续分配struct list_head slabs_full; // 此链表中slab内的对象已全部分配出去struct list_head slabs_free;// 此链表中slab内的对象全部可供继续分配unsigned long free_objects;// 分配器整体的可供继续分配对象数
};// 固定尺寸空间分配器类型
struct kmem_cache_s {struct kmem_list3 lists;unsigned int objsize; // 对象尺寸unsigned int flags; // 标志信息unsigned int num; // 服务于此分配器的slab所包含的对象数量unsigned int free_limit; // 分配器内空闲对象数量限制spinlock_t spinlock;unsigned int gfporder; // 服务于此分配器的每个slab对象需要$2^gfporder$个页框unsigned int gfpflags; // 用于指示从NORMAL还是DMA区域类型获取页框size_t colour; // 颜色数 unsigned int colour_off; // 颜色偏移unsigned int colour_next; // 分配器内下个slab应该采用的颜色索引kmem_cache_t *slabp_cache; // 当服务此分配器的slab对象的管理区域需要在外部分配空间时,所需采用的分配器对象指针unsigned int slab_size; // 服务于此分配器的slab对象的管理区域尺寸void (*ctor)(void *, kmem_cache_t *, unsigned long);// 允许提供构造函数对此分配器的slab下每个对象通过构造初始化void (*dtor)(void *, kmem_cache_t *, unsigned long);// 允许提供析构函数对此分配器的slab下每个对象在释放阶段析构来清理const char *name; // 分配器的名称struct list_head next; // linux内核所有分配器对象实例均位于单一链表
};
5.2.2.服务于分配器的slab结构
typedef unsigned short kmem_bufctl_t;
struct slab {struct list_head list;// 用于链表组织unsigned long colouroff;// 页框空间内首个数据对象的相对于页框空间起始的偏移void *s_mem;// slab内首个对象线性地址unsigned int inuse;// slab内已分配对象数kmem_bufctl_t free;// slab内首个空闲对象索引。从0开始。
};
5.2.3.linux内核的cache_cache
linux内核static struct list_head cache_chain;是持有系统所有分配器对象的链表哨兵节点。
我们为了使用linux内核的小块内存分配器,首先需要一个分配器用于动态分配尺寸为sizeof(kmem_cache_s)的对象,这个分配器是
static kmem_cache_t cache_cache = {.lists = LIST3_INIT(cache_cache.lists),.batchcount = 1,.limit = BOOT_CPUCACHE_ENTRIES,.objsize = sizeof(kmem_cache_t),.flags = SLAB_NO_REAP,.spinlock = SPIN_LOCK_UNLOCKED,.name = "kmem_cache"
};
该分配器对象要正常使用首先得进行正确的初始化:
// 全局的固定尺寸分配器后续初始u哈
cache_cache.colour_off = cache_line_size();// 缓存行大小
cache_cache.objsize = ALIGN(cache_cache.objsize, cache_line_size());
// 取得slab可容纳对象数,扣除管理区域,数据区域后剩余部分尺寸
cache_estimate(0, cache_cache.objsize, cache_line_size(), 0, &left_over, &cache_cache.num);
// 可用颜色数--剩余部分/缓存行。
cache_cache.colour = left_over/cache_cache.colour_off;
// 分配器下个颜色
cache_cache.colour_next = 0;
// 这是将slab放在所管理页框内时候,管理区域尺寸
cache_cache.slab_size = ALIGN(cache_cache.num*sizeof(kmem_bufctl_t) + sizeof(struct slab), cache_line_size());
其中cache_estimate为:
static void cache_estimate (unsigned long gfporder, size_t size, size_t align, int flags, size_t *left_over, unsigned int *num)
{int i;size_t wastage = PAGE_SIZE<<gfporder;size_t extra = 0;size_t base = 0;if (!(flags & CFLGS_OFF_SLAB)) {// 不含此标志,表示slab管理信息放在slab管理的页框里。base = sizeof(struct slab);extra = sizeof(kmem_bufctl_t);}i = 0;// 这是在试探一个slab内可容纳的对象数量while (i*size + ALIGN(base+i*extra, align) <= wastage)i++;if (i > 0)i--;// 一个slab内对象数量存在上限if (i > SLAB_LIMIT)i = SLAB_LIMIT;*num = i;// slab内可放置的对象数量wastage -= i*size;wastage -= ALIGN(base+i*extra, align);*left_over = wastage;// 扣掉管理区域,数据区域后剩余部分尺寸。
}
上述过程的意思是,针对此分配器对象:
(1). 将其objsize设置为ALIGN(cache_cache.objsize, cache_line_size())。
这样的目的是,我们可以保证此分配器对象的slab内的每个对象的起始地址(无论线性地址还是物理地址)均是高速缓存行对齐的。这有助于高效利用硬件高速缓存。
(2). 通过不断试探的方式试探出来在服务于此分配器的每个slab的 2 0 2^0 20个页框构成的可用空间里,可容纳多少个对象。
这样试探的结果就是,尽可能利用每个slab内的可用空间来放置尽可能多的对象。
分配器的slab支持将管理区域空间放在服务于自身的页框空间内或外,对cache_cache我们选择将其放在所管理页框空间内。
这样针对服务此分配器的一个颜色索引为2的slab,其所管理的页框空间的划分细节就是:

上图是一个完整的slab所管理页框空间的划分。
a.最开始是2*colour_off 构成的颜色偏移区域。为slab引入颜色偏移机制,是为了使得服务于分配器的各个slab通过不同的偏移,获得更好的硬件高速缓存使用效果(降低硬件高速缓存冲突的概率)。
b.接下来是容纳一个slab对象实例的区域,再接下来是num个kmem_bufctl_t对象构成的区域。每个slab用于slab自身的管理。num个kmem_bufctl_t对象则用于将数据区域的空闲对象组织成单向链表,以便快速实现slab内对象释放,对象分配逻辑。
c. 接下来是数据区域。用于存储num个此slab所管理的对象。
值得注意的是:
a. 黄色部分结尾和红色部分开始可能存在间隙。
这主要由于sizeof(slab)+num*sizeof(kmem_bufctl_t)不可被cache_line_size()整除。而我们又需要数据区域内每个对象起始地址可被cache_line_size()整除时的填充。
b. 红色部分结尾和页框空间尾部可能存在间隙。
这主要由于我们的页框空间尺寸 - 对齐后的管理区域 - 数据区域 - 颜色偏移区域后依然存在余量造成余量部分。
(3). 一旦完成num的设置,相应的,便可算出余量部分,并依据余量部分计算并设置colour ;也能算出slab_size 。
5.2.4.linux内核的通用尺寸分配器
linux内核提供了一组通用尺寸分配器用于尽可能覆盖到每种尺寸
#if (PAGE_SIZE == 4096)CACHE(32)
#endifCACHE(64)
#if L1_CACHE_BYTES < 64CACHE(96)
#endifCACHE(128)
#if L1_CACHE_BYTES < 128CACHE(192)
#endifCACHE(256)CACHE(512)CACHE(1024)CACHE(2048)CACHE(4096)CACHE(8192)CACHE(16384)CACHE(32768)CACHE(65536)CACHE(131072)
#ifndef CONFIG_MMUCACHE(262144)CACHE(524288)CACHE(1048576)
#ifdef CONFIG_LARGE_ALLOCSCACHE(2097152)CACHE(4194304)CACHE(8388608)CACHE(16777216)CACHE(33554432)
#endif /* CONFIG_LARGE_ALLOCS */
#endif /* CONFIG_MMU */
linux会为每个尺寸提供一个分配器用于对应尺寸的空间分配。
5.2.5.分配器初始化
一个分配器实例需要先正确初始化,才能用于执行空间分配和释放。前面5.2.2里面我们介绍了linux内核cache_cache这个分配器实例的初始化过程。
更一般化的,现在我们分析一个对象尺寸为cs_size,希望对象满足高速缓存对齐的分配器的初始化流程。
(1). 确立分配器内对象的对齐要求
前面对于cache_cache,其对齐要求为cache_line_size(),即对齐硬件高速缓存行尺寸。
但考虑,如果我们现在要分配的对象尺寸为32,高速缓存行尺寸为128。
如果将对齐要求定位128,很明显造成极大的空间浪费。
我们既希望高效的利用硬件高速缓存,杜绝一个对象部分存在于高速缓存行的情况,又希望尽可能的避免空间浪费。两者结合,我们对尺寸cs_size,我们采用如下方式确定对齐要求:
ralign = cache_line_size();
while (size <= ralign/2)ralign /= 2;
这样对我们的例子,最终得到的对齐要求将是32。这个对齐要求下我们既保证了空间的高效使用,有保证了硬件高速缓存的高效。
如我们要分配的尺寸为12,高速缓存行尺寸为128,则得到对齐要求将是16。依然是既可保证空间的高效使用,又保证硬件高速缓存高效的最优选择。
(2). 调整对象尺寸
为了保证每个对象均满足对齐要求需调整对象尺寸为:
size = ALIGN(size, align);
(3). 决定slab的管理区域是位于所管理页框空间的外部还是内部
策略是
if (size >= (PAGE_SIZE>>3))flags |= CFLGS_OFF_SLAB;
即对象尺寸达到页框/8时,就应将管理区域放在外部。
当对象尺寸较小时按照用户选择的方式放置。这样考量,主要是为了避免因为在内部放置了管理区域而影响内部可放的对象数量。在单个对象尺寸较大时,影响造成的空间浪费也越明显。
(4). 接下来,我们需要确定gfporder
即确定每个服务于此分配器的slab需要多少个页框来提供空间支持。
我们的策略依然是逐步尝试,先试探gfporder为0,再逐步增加,直到找到一个满意的选择。
这里选择时,必须满足的是:
gfporder下,可使得页框空间至少可容纳一个对象。
其他限制考量是:
gfporder不能超过限制。
为了更好搭配伙伴系统,在能容纳一个对象下,gfporder几乎总是在0,1间选择。
当gfporder选举下,余量空间不足页框空间1/8时,也应选择此gfporder,停止试探。
(5). 现在我们确定了以下信息
a. 此分配器下slab里所需页框数量的阶gfporder。
b. 此分配器下slab的管理区域放置在外部还是内部。
c. 此分配器下slab的页框空间可分配对象数。
d. 此分配器下slab的页框空间里对象对齐值。
e. 此分配器下slab的页框空间里颜色数。
f. 此分配器下slab的管理区域尺寸。
g. 此分配器下可分配对象的尺寸。
有了以上信息,我们即可完成分配器对象的初始化。一旦外层分配器对象的初始化,就可通过其分配对象空间了。
5.3.分配
5.3.1.通过分配器分配指定数量对象空间
现在我们分析外部向分配器申请数量为batchcount的对象空间的场景。
策略是,从分配器对象的lists的部分空闲链表取slab节点,从取得的slab节点执行对象分配。
slabp->s_mem + slabp->free*cachep->objsize;// 这样可以快速得到此slab内首个空闲对象地址
slabp->inuse++;
next = slab_bufctl(slabp)[slabp->free];
slabp->free = next;// 这样在对象分配后,更新slab中首个空闲对象索引。
若已经分配了batchcount个对象,则结束。
若未分配到,继续对链表其余slab节点执行分配处理。
对分配处理中slab节点由存在部分对象可分配变为不存在可分配对象的情况,需将其从部分链表移除,加入满链表。
若部分链表全部节点处理完,依然未分配到指定数量,继续对空闲链表每个节点执行分配处理。
分配后需要将节点从空闲链表移除,移入部分链表。
当空闲链表全部处理完,依然未分配到指定数量时,我们需要为此分配器分配新的slab对象,分配后再次尝试上述分配逻辑,直到分配了直到数量对象为止。
5.3.2.为分配器分配新的slab对象
首先,我们需从分配器得到此slab的颜色数,计算颜色偏移。
spin_lock(&cachep->spinlock);
/* Get colour for the slab, and cal the next value. */
offset = cachep->colour_next;
cachep->colour_next++;// 颜色的意义,在于为服务于同一缓存对象的多个slab确定不同的对象起始偏移。
if (cachep->colour_next >= cachep->colour)cachep->colour_next = 0;
offset *= cachep->colour_off;// 这样得到起始对象偏移
spin_unlock(&cachep->spinlock);
然后,我们借助伙伴系统为其分配 2 g f p o r d e r 2^gfporder 2gfporder个连续页框。对分配给slab的每个页框需在page的flags中添加SLAB标记。
然后,我们需要为slab的管理区域分配空间和初始化。
针对管理区域在外部的情况,需借助分配器中slabp_cache指定的分配器为管理区域分配空间。
针对管理区域在外部的情况,直接在slab的页框空间内为其分配空间。
然后,对slab内的每个页框,对其page,我们设置其lru.next指向隶属的分配器对象,我们设置其lru.prev指向隶属的slab对象。
然后,对slab内每个对象初始化,将管理区域的空闲对象链表初始化
static inline kmem_bufctl_t *slab_bufctl(struct slab *slabp)
{return (kmem_bufctl_t *)(slabp+1);
}int i;
for (i = 0; i < cachep->num; i++) {void* objp = slabp->s_mem+cachep->objsize*i;if (cachep->ctor)cachep->ctor(objp, cachep, ctor_flags);// 缓存对象支持对每个slab内对象通过构造初始化slab_bufctl(slabp)[i] = i+1;// 管理区域中空闲链表初始化
}
slab_bufctl(slabp)[i-1] = BUFCTL_END;// 下以空闲对象索引为BUFCTL_END时,表示不存在。
slabp->free = 0;// 首个空闲对象索引。
最后,将此slab加入隶属分配对象的对应链表结构。
这样,我们便为分配器对象新分配了一个slab对象并完成了初始化。一旦完成初始化,我们通过此slab执行对象分配和回收了。
5.4.释放
5.4.1.向分配器释放对象
现在我们分析外部向分配器释放数量为batchcount的对象空间的场景。
cachep->lists.free_objects += nr_objects;
for (i = 0; i < nr_objects; i++) {void *objp = objpp[i];struct slab *slabp;unsigned int objnr;slabp = GET_PAGE_SLAB(virt_to_page(objp));// 从对象地址找到隶属的page,再找到隶属的slablist_del(&slabp->list);objnr = (objp - slabp->s_mem) / cachep->objsize;// 定位到对象在slab内的索引slab_bufctl(slabp)[objnr] = slabp->free;// 释放的对象成为空闲链表首个元素。链表头插法。slabp->free = objnr;// 首个空闲对象索引。slabp->inuse--;if (slabp->inuse == 0) {// 这是释放后,使得slab变为完全空闲。// 当slab因释放变为完全空闲,且缓存对象里空闲对象数又很多时。if (cachep->lists.free_objects > cachep->free_limit) {cachep->lists.free_objects -= cachep->num;// 释放此空闲的slab对象。slab_destroy(cachep, slabp);} else {list_add(&slabp->list, &list3_data_ptr(cachep, objp)->slabs_free);// 否则将slab加入空闲链表}} else {list_add_tail(&slabp->list, &list3_data_ptr(cachep, objp)->slabs_partial);// 将slab加入部分空闲链表}
}
整个过程是:
首先,由于slab下的页框均位于内核直接映射区域。所以,易于基于对象线性地址得到对象所在页框起始线性地址,由页框起始线性地址易于得到此页框的page对象为止,通过page对象的lru.prev易于找到隶属的slab对象。
然后,就可计算出分配对象在slab对象页框空间中的索引,并更新slab的空闲对象链表。
再向slab释放对象引起其从部分可分配到空闲变化时,需将其从分配器的部分空闲链表移除,移入分配器的空闲链表。
若变为空闲后,发现分配器内空闲对象数量过多,则直接释放此slab对象,即可。
5.4.2.销毁slab对象
void *addr = slabp->s_mem - slabp->colouroff;
if (cachep->dtor) {int i;for (i = 0; i < cachep->num; i++) {void* objp = slabp->s_mem+cachep->objsize*i;(cachep->dtor)(objp, cachep, 0);// 释放时允许对每个对象执行析构来清理}
}
kmem_freepages(cachep, addr);// 先是将slab下的页框释放到伙伴系统
if (OFF_SLAB(cachep))kmem_cache_free(cachep->slabp_cache, slabp);// 若服务区域在外部,需单独释放。
首先,对slab内每个对象执行析构。
然后,向伙伴系统释放此slab的页框空间。
如果,此slab的管理区域位于外部,还需向对应分配器释放此部分空间。
5.5.小块内存分配器和用户的中间层
为了提升小块内存分配器的使用效率。linux中为小块内存分配器提供了两级缓存机制。
一级是cpu独占缓存,一级是cpu共享缓存,最底层才是内存分配器。
5.5.1.结构
struct array_cache {unsigned int avail;unsigned int limit;unsigned int batchcount;
};#define BOOT_CPUCACHE_ENTRIES 1
struct arraycache_init {struct array_cache cache;// 控制区域void * entries[BOOT_CPUCACHE_ENTRIES];// 数据区域
};struct kmem_cache_s {struct array_cache *array[NR_CPUS];struct kmem_list3 lists;
};struct kmem_list3 {struct array_cache *shared;
};
上述结构里,kmem_cache_s 的array用于实现每cpu缓存。
kmem_cache_s 的lists的shared用于实现cpu共享缓存。
针对每个array和shared中指向array_cache的指针,指向区域先是一个array_cache实例对象,再是一个对象指针数组用于缓存释放的对象和用于分配。
针对array_cache,其各个字段含义如下:
limit表示实例后紧跟的对象指针数组的容量。
avail表示数组最后一个有效元素索引。向指针数组释放对象总是放到avail之后,从指针数组取元素总是取avail位置的。
batchcount表示当数组为空时,向下级缓存一次请求填充的空闲对象数。数组满时,需一次性向下级缓存释放的空闲对象数。
以下是linux中一些对象尺寸下,limit和batch设置的经验值:
if (cachep->objsize > 131072)limit = 1;else if (cachep->objsize > PAGE_SIZE)limit = 8;else if (cachep->objsize > 1024)limit = 24;else if (cachep->objsize > 256)limit = 54;elselimit = 120;
batch = (limit+1)/2;
针对shared设置limit和batch时应放大适当倍数。
5.5.2.动作
5.5.2.1.初始化
我们需要在完成对象分配器初始化后,为对象分配器的array和lists中的shared按分配器支持的分配尺寸进行空间分配和初始化。
5.5.2.3.在分配对象中插入缓存
分配过程将现在一级缓存分配,一级缓存为空时,先补充一级缓存再分配
/*static inline struct array_cache *ac_data(kmem_cache_t *cachep)
{return cachep->array[smp_processor_id()];
}*/
local_irq_save(save_flags);// 保存标志,禁止中断
ac = ac_data(cachep);
if (likely(ac->avail)) {STATS_INC_ALLOCHIT(cachep);ac->touched = 1;objp = ac_entry(ac)[--ac->avail];
} else {STATS_INC_ALLOCMISS(cachep);objp = cache_alloc_refill(cachep, flags);
}
local_irq_restore(save_flags);// 恢复标志
一级缓存不足时,会在共享缓存有空闲对象下,使用共享缓存中空闲对象来填充一级缓存。
在共享缓存没有空闲对象下,直接使用对象分配器下的slab来完成一级缓存的填充。
// 多次缓存
spin_lock(&cachep->spinlock);
if (l3->shared) {struct array_cache *shared_array = l3->shared;if (shared_array->avail) {if (batchcount > shared_array->avail)batchcount = shared_array->avail;shared_array->avail -= batchcount;ac->avail = batchcount;memcpy(ac_entry(ac), &ac_entry(shared_array)[shared_array->avail], sizeof(void*)*batchcount);shared_array->touched = 1;goto alloc_done;}
}
spin_unlock(&cachep->spinlock);
上述是尝试采用共享缓存来填充一级缓存的逻辑实现。
5.5.2.4.在对象释放中插入缓存
一级缓存未满时,先释放到一级缓存
一级缓存满了,先清理一部分空间,再释放。
local_irq_save(flags);
if (likely(ac->avail < ac->limit)) {STATS_INC_FREEHIT(cachep);ac_entry(ac)[ac->avail++] = objp;// 向中间层释放对象return;
} else {STATS_INC_FREEMISS(cachep);cache_flusharray(cachep, ac);ac_entry(ac)[ac->avail++] = objp;// 向中间层释放对象
}
local_irq_restore(flags);// 恢复标志
以下是清理逻辑
// 多核下防止并发用自旋锁&互斥锁
spin_lock(&cachep->spinlock);
// 先释放到下一级
if (cachep->lists.shared) {struct array_cache *shared_array = cachep->lists.shared;int max = shared_array->limit-shared_array->avail;// 最多可放入的if (max) {if (batchcount > max)batchcount = max;// 释放多余资源memcpy(&ac_entry(shared_array)[shared_array->avail], &ac_entry(ac)[0], sizeof(void*)*batchcount);shared_array->avail += batchcount;goto free_done;// 允许释放数不足batchcount}
}
free_block(cachep, &ac_entry(ac)[0], batchcount);// 这里是下一级不存在或已经满了时,直接释放到slab
free_done:spin_unlock(&cachep->spinlock);ac->avail -= batchcount;// 完成了释放// 保证缓存中数据永远存储在起始部分memmove(&ac_entry(ac)[0], &ac_entry(ac)[batchcount], sizeof(void*)*ac->avail);
5.5.3.多级缓存引入意义
(1). 每cpu缓存引入意义
由于每cpu缓存的并发保护只要关中断即可。无需引入自旋锁来保护并发访问。所以,降低锁竞争开销。
(2). 共享cpu缓存引入意义
共享cpu缓存直接采用指针数组管理,管理策略上相比slab更简单。有注意提升速度。
相关文章:
linux内核原理--分页,页表,内核线性地址空间,伙伴系统,内核不连续页框分配,内核态小块内存分配器
1.分页,页表 linux启动阶段,最初运行于实模式,此阶段利用段寄存器,段内偏移,计算得到物理地址直接访问物理内存。 内核启动后期会切换到保护模式,此阶段会开启分页机制。一旦开启分页机制后,内…...
【MongoDB】下载安装、指令操作
目录 1.下载安装 2.指令 2.1.基础操作指令 2.2.增加 2.3.查询 2.4.修改 2.5.删除 前言: 关于MongoDB的核心概念请移步: 【文档数据库】ES和MongoDB的对比-CSDN博客 1.下载安装 本文以安装Windows版本的mongodb为例,Linux版本的其实…...

k8s-pvc/pv扩容记录
背景 一次聊天过程中,对方提及pvc的扩容,虽然有注意过 storageclass 有个AllowVolumeExpansion的配置(有些csi插件是不支持该配置的,比如local-volume-provisoner),但是没有实际用过,所以还是心…...

关于Unity插件TriLib使用的一点儿心得
最近做一个项目的时候,由于要求动态加载fbx或者glb等格式文件,而我们自己开发加载插件难度又有点大,所以最后使用了TriLib这个插件,现在说一点使用心得。 由于文件加载之后要对加载的内容进行复制,比如加载一个柱子&am…...
)
计算机二级Python基本排序题-序号45(补充)
1. 文件"singup.txt”中保存了若干条参加运动会学生的报名记录,每条记录的形式为“班级号_学号”,例如"A1_12”,将每个班级报名情按参加运动会人数从多到少排列(假设不存在人数相同的情况)并输出,…...

响应式Web开发项目教程(HTML5+CSS3+Bootstrap)第2版 例4-6 fieldset
代码 <!doctype html> <html> <head> <meta charset"utf-8"> <title>fieldset</title> </head><body> <form action"#"><fieldset><legend>学生信息</legend>姓名:&…...

html渲染优先级
在前端开发中,优先布局是指在设计和构建页面时,将页面的各个部分按照其重要性和优先级进行排序,并依次进行布局和开发。这种方法可以帮助开发团队在项目初期就确定页面结构的核心部分,从而更好地掌控项目的整体进度和优先级。且确…...

linux 更新镜像源
打开终端,备份一下旧的 源 文件,以防万一 cd /etc/apt/ ls sudo cp sources.list sources.list.bak ls然后打开清华大学开源软件镜像站 搜索一下你的linux发行版本,我这里是ubuntu发行版本 点击这个上面图中的问号 查看一下自己的版本号&a…...
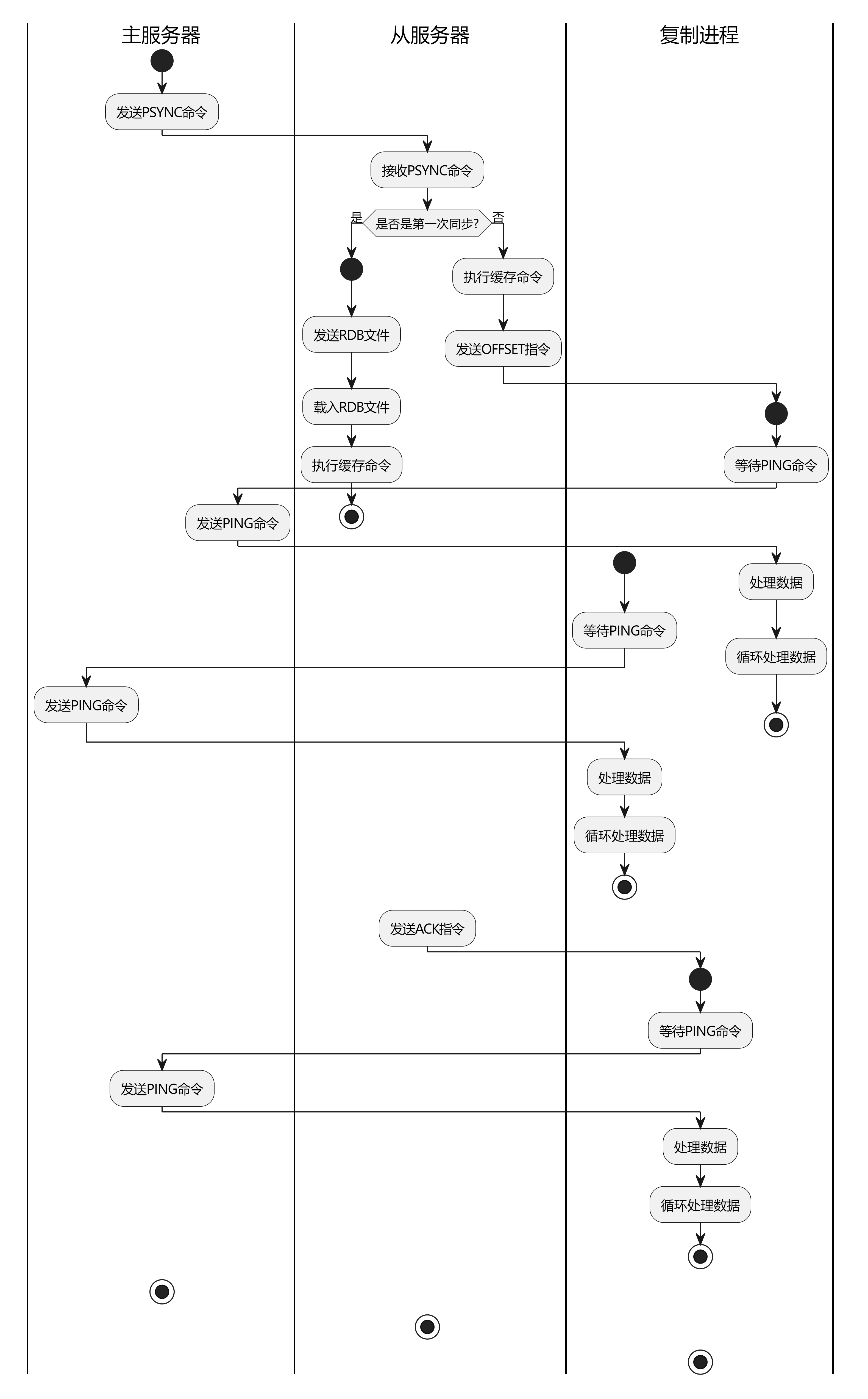
【征服Redis12】redis的主从复制问题
从现在开始,我们来讨论redis集群的问题,在前面我们介绍了RDB和AOF两种同步机制,那你是否考虑过这两个机制有什么用呢?其中的一个重要作用就是为了集群同步设计的。 Redis是一个高性能的键值存储系统,广泛应用于Web应用…...

php函数 一
一 自动加载 1.1 __autoload(string $class) 类自动加载,7.2版本之后废弃。可使用sql_autoload_register()注册方法实现。 类自动加载,无返回值。 #php7.2之前function __autoload($class) {if(strpos($class, CI_) ! 0){if (file_exists(APPPATH . …...
)
监督学习 - 梯度提升回归(Gradient Boosting Regression)
什么是机器学习 梯度提升回归(Gradient Boosting Regression)是一种集成学习方法,用于解决回归问题。它通过迭代地训练一系列弱学习器(通常是决策树)来逐步提升模型的性能。梯度提升回归的基本思想是通过拟合前一轮模…...
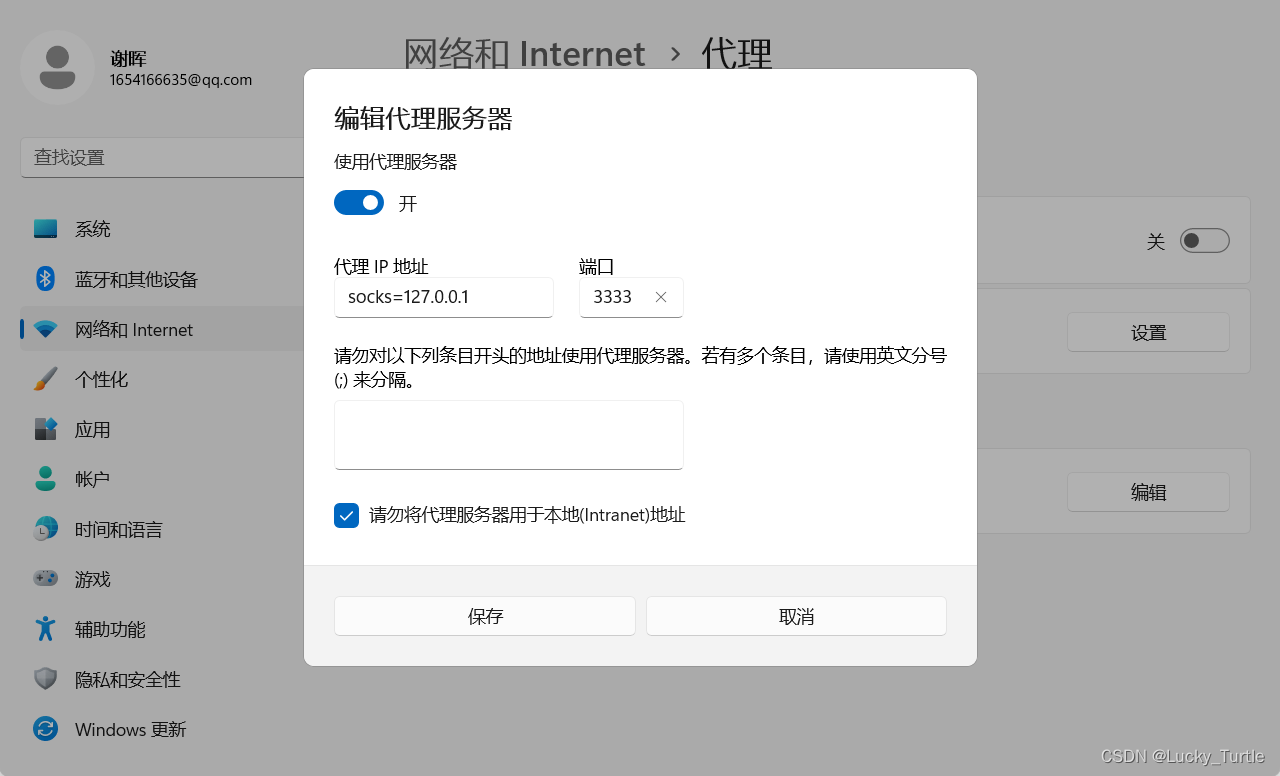
【工具】使用ssh进行socket5代理
文章目录 shellssh命令详解正向代理:反向代理:本地 socks5 代理 shell ssh -D 3333 root192.168.0.11 #输入密码 #3333端口已经使用远程机进行转发设置Windows全局代理转发 socks127.0.0.1 3333如果远程机为公网ip,可通过搜索引擎查询出网…...
 Object Pascal 学习笔记---第2章第六节(类型转换))
(delphi11最新学习资料) Object Pascal 学习笔记---第2章第六节(类型转换)
Object Pascal 学习笔记,Delphi 11 编程语言的完整介绍 作者: Marco Cantu 笔记:豆豆爸 2.6 类型转换和类型转换 正如我们所见,不能将一种数据类型的变量赋值给另一种类型的变量。原因在于,根据数据的实际表示,你…...

计算机服务器中了mallox勒索病毒怎么办,mallox勒索病毒解密数据恢复
企业的计算机服务器存储着企业重要的信息数据,为企业的生产运营提供了极大便利,但网络安全威胁随着技术的不断发展也在不断增加,近期,云天数据恢复中心接到许多企业的求助,企业的计算机服务器中了mallox勒索病毒&#…...

CPU相关专业名词介绍
CPU相关专业名词 1、CPU 中央处理器CPU(Central Processing Unit)是计算机的运算和控制核心,可以理解为PC及服务器的大脑CPU与内部存储器和输入/输出设备合称为电子计算机三大核心部件CPU的本质是一块超大规模的集成电路,主要功…...

VRRP协议负载分担
VRRP流量负载分担 VRRP负载分担与VRRP主备备份的基本原理和报文协商过程都是相同的。同样对于每一个VRRP备份组,都包含一个Master设备和若干Backup设备。与主备备份方式不同点在于:负载分担方式需要建立多个VRRP备份组,各备份组的Master设备可以不同;同一台VRRP设备可以加…...

maven 基本知识/1.17
maven ●maven是一个基于项目对象模型(pom)的项目管理工具,帮助管理人员自动化构建、测试和部署项目 ●pom是一个xml文件,包含项目的元数据,如项目的坐标(GroupId,artifactId,version )、项目的依赖关系、构建过程 ●生命周期&…...
【Java】HttpServlet类简单方法和请求显示
1、HttpServlet类简介🍀 Servlet类中常见的三个类有:☑️HttpServlet类,☑️HttpServletRequest类,☑️HttpResponse类 🐬其中,HttpServlet首先必须读取Http请求的内容。Servlet容器负责创建HttpServlet对…...

使用Rancher管理Kubernetes集群
部署前规划 整个部署包括2个部分,一是管理集群部署,二是k8s集群部署。管理集群功能主要提供web界面方式管理k8s集群。正常情况,管理集群3个节点即可,k8s集群至少3个。本文以3节点管理集群,3节点k8s集群为例 说明部署过…...
QT中操作word文档
QT中操作word文档: 参考如下内容: C(Qt) 和 Word、Excel、PDF 交互总结 Qt对word文档操作总结 QT中操作word文档 Qt/Windows桌面版提供了ActiveQt框架,用以为Qt和ActiveX提供完美结合。ActiveQt由两个模块组成: QAxContainer模…...

广州初创公司,办公家具租还是买?我帮你算了一笔账
广州很多初创公司都会面临一个真实问题:现金流紧张、抗风险能力弱,办公家具采购却是一笔不小的开支。租划算,还是买划算?结合广州初创公司的经营特点和现金流需求,我从成本、灵活性、风险、售后四个维度对比后得出的结…...

RISC-V PMP物理内存保护:硬件级隔离机制与嵌入式系统实战配置
1. 项目概述:为什么我们需要物理内存保护?在嵌入式系统、实时操作系统乃至一些对可靠性要求极高的服务器场景里,系统崩溃往往不是由复杂的逻辑错误直接导致的,而是源于一些看似“低级”的内存访问越界。想象一下,你正在…...

告别键盘鼠标切换烦恼:开源KVM软件Input Leap让你一套键鼠控制多台电脑
告别键盘鼠标切换烦恼:开源KVM软件Input Leap让你一套键鼠控制多台电脑 【免费下载链接】input-leap Open-source KVM software 项目地址: https://gitcode.com/gh_mirrors/in/input-leap 你是否经常在Windows、macOS和Linux多台电脑之间来回切换,…...

FF14副本动画跳过插件终极指南:3分钟告别冗长等待
FF14副本动画跳过插件终极指南:3分钟告别冗长等待 【免费下载链接】FFXIV_ACT_CutsceneSkip 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_ACT_CutsceneSkip 你是否曾在《最终幻想14》国服副本中,看着那些无法跳过的动画感到无比焦虑&…...
)
保姆级教程:用YOLOv8和Pyside6从零搭建一个火焰烟雾检测桌面应用(附完整源码和数据集)
从零构建火焰烟雾检测桌面应用:YOLOv8与Pyside6实战指南 在工业安全、家庭监控和实验室防护场景中,火焰与烟雾的早期检测至关重要。传统监控系统依赖人工值守或简单传感器,难以实现精准的实时预警。本文将带你用Python生态中最前沿的YOLOv8目…...

云端开发新体验:code-server部署与多场景应用指南
1. 为什么你需要一个云端开发环境? 记得去年我同时参与三个项目时,每天要在办公室台式机、家里笔记本和平板电脑之间来回切换。每次换设备最头疼的就是开发环境不一致——Node.js版本不同、Python包缺失、配置文件没同步...有次紧急修复线上bug时&#x…...

集成SERDES+RGMII双接口:BCM54616SC0KFBG在背板与光纤应用中的灵活连接方案
BCM54616SC0KFBG:集成 SERDES 的低功耗单口千兆以太网 PHY在数据中心的服务器接入、企业级交换机上行链路以及工业自动化控制系统中,物理层芯片是实现网络通信的基石。随着网络设备向高密度、低功耗演进,传统的以太网 PHY 面临连接灵活性受限…...
)
保姆级教程:用PHPStudy+Nginx一键部署新麦同城V3开源版(附数据库配置避坑点)
零基础30分钟部署新麦同城V3:PHPStudyNginx全流程避坑指南 第一次接触本地部署开源系统时,最怕的不是代码复杂,而是明明按教程操作却卡在某个配置环节。本文将以真实踩坑记录为核心,手把手带你在Windows环境下用PHPStudy快速搭建…...

如何打破课堂限制?JiYuTrainer让您的电脑重获自由
如何打破课堂限制?JiYuTrainer让您的电脑重获自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 当您在计算机课堂上被极域电子教室完全控制时,是否感到学…...

FreeRDP 终极指南:如何构建跨平台远程桌面解决方案
FreeRDP 终极指南:如何构建跨平台远程桌面解决方案 【免费下载链接】FreeRDP FreeRDP is a free remote desktop protocol library and clients 项目地址: https://gitcode.com/gh_mirrors/fr/FreeRDP FreeRDP 是一款功能强大的开源远程桌面协议实现库&#…...